Подход к моделированию процесса извлечения информации из текста на основе онтологии

Автор: Сидорова Е.А.
Журнал: Онтология проектирования @ontology-of-designing
Рубрика: Инжиниринг онтологий
Статья в выпуске: 1 (27) т.8, 2018 года.
Бесплатный доступ
В статье рассматриваются модели и методы представления знаний, ориентированные на задачи автоматической обработки текста и извлечения информации. В рамках предлагаемого подхода извлечение информации рассматривается как процесс пополнения онтологии информацией, представленной в виде объектов - экземпляров понятий предметной области. Для описания данного процесса предложены три базовые модели. Модель представления текста задаёт общую схему обработки текста и обеспечивает отображение полученной информации на текст. Модель представления знаний включает описание предметной лексики, жанровые модели текста и модели фактов, которые позволяют смоделировать процессы извлечения информации в терминах семантических классов предметной лексики и онтологии предметной области. Используемая атрибутивная модель представления данных обеспечивает сохранение информационных потоков данных, возникающих в процессе извлечения информации, и позволяет применять онтологические методы для решения задач снятия неоднозначности интерпретации текста и разрешение кореференции. Таким образом, предложена оригинальная методика, позволяющая пользователям проектировать систему анализа текста и моделировать процессы извлечения информации на основе онтологии предметной области.
Извлечение информации, модель текста, словарь предметной лексики, модель факта, пополнение онтологии
Короткий адрес: https://sciup.org/170178773
IDR: 170178773 | УДК: 004.82:004.912 | DOI: 10.18287/2223-9537-2018-8-1-134-151
Ontology-based approach to modeling the process of extracting information from text
The article deals with models and methods of knowledge representation, focused on tasks of automatic text processing and information extraction. In the framework of our approach, information extraction is considered as a process of ontology population with information represented as instances of domain concepts. To describe this process three basic models are proposed. The model of the text representation defines the general scheme of text processing and provides the mapping of the received information on the text. The knowledge representation model includes a description of the subject vocabulary, genre models of the text and the models of facts, which allow modeling the processes of information extraction in terms of semantic classes of subject vocabulary and ontology of the subject domain. The attributive model of data representation ensures the preservation of information streams of data that arise in the process of extracting information, and allows the use of ontological methods for solving ambiguity problems and resolving the coreference. Thus, an original technique that allows users to design a text analysis system and simulate the information extraction based on the domain ontology is proposed.
Текст научной статьи Подход к моделированию процесса извлечения информации из текста на основе онтологии
Автоматическая обработка и анализ разнородной информации, представленной на естественном языке, является одним из самых востребованных на сегодняшний день направлений исследований. Отдельное положение в ряде решаемых задач в рамках данного направления занимает задача извлечения информации из предметно-специфического контента, представленного текстами, поскольку данная задача плохо разрешима статистическими методами и, как правило, требует привлечения знаний специалистов как о предметной области (ПрО), так и об особенностях языка.
Данная задача тесно связана с задачей пополнения онтологии [1]. Под пополнением онтологии понимается автоматический анализ различных источников и наполнение найденной информацией контента информационной системы, база данных которой опирается на онтологию ПрО. Извлекаемая информация в таких системах представляется экземплярами понятий и отношений заданной онтологии. Для решения данных задач, как правило, используют разнообразные знания в формализованном виде, такие как тезаурусы (WordNet, RusNet), толково-комбинаторные словари [2], аннотированные корпуса текстов (например, Национальный корпус русского языка - и т.п. Работа со знаниями в свою очередь требует создания технологий, которые автоматизируют процессы проектирования и разра- ботки программных систем посредством предоставления пользователям (в том числе не программистам) средств моделирования, которые позволяют абстрагироваться от непосредственной разработки программных компонент и сконцентрироваться на вопросах обеспечения системы всеми необходимыми знаниями и моделирования непосредственно процессов извлечения информации в предметных терминах.
Вопросам моделирования процессов извлечения информация уделяется мало внимания, как правило, рассматриваются решения конкретных задач, что не позволяет выделить технологические и методологические аспекты решения подобных задач в целом. Целью данной работы является попытка восполнить этот пробел с помощью ряда модельных описаний процессов на различных уровнях представления.
Наиболее изученными являются онтологии и тезаурусы [3]. Онтология, как инструмент моделирования ПрО, является основой для формализации интересов пользователя, формирования словаря и представления конечного результата работы создаваемой системы, а также содержит необходимые знания для этапа семантического анализа текста [4]. Тезаурус, как инструмент описания предметной лексики, позволяет характеризовать термин и его связи с точки зрения особенностей употребления в данной ПрО [5, 6]. Для того, чтобы зафиксировать формально-лингвистические свойства, обусловленные языковой практикой описания объектов и ситуаций данной ПрО, необходимо использовать модели, которые бы с одной стороны описывали различные варианты представления в тексте одной и той же информации, с другой – моделировали бы процесс извлечения данной информации. К моделям данного класса можно отнести синтаксические или семантико-синтаксические модели управления [7, 8], лексико-синтаксические правила и шаблоны [9, 10], правила на основе онтологии [11] и т.п.
Указанные выше модели позволяют формировать в первую очередь базу знаний разрабатываемой системы, т.е. моделировать «заранее» заданные параметры системы или входные данные. Для моделирования целостного процесса извлечения информации их оказывается недостаточно, необходимо указать структуры данных для представления информации на всех промежуточных этапах обработки текста, а также обеспечить решения «специализированных» для данной проблемной области задач, связанных с неоднозначностью, присущей естественному языку.
В данной работе предложен подход к моделированию процессов извлечения информации из текста, который включает компоненты моделирования базы знаний системы, модели представления текста в процессе его обработки, а также способы описания информационных потоков данных, возникающих в процессе извлечения информации, которые позволяют применять онтологические методы для решения задач снятия неоднозначности и разрешение кореференции.
1 Модель представления знаний
Особенностью развиваемого подхода к извлечению информации из текста является применение знаний о ПрО, преимущественное использование лексико-семантической информации и жанровых особенностей документов.
Рассматриваемая лингвистическая модель знаний включает три компонента. Словарь ПрО задаёт лексическую модель подъязыка ПрО, жанровая модель текста формирует жанровую структура рассматриваемого текстового источника, сужая область поиска определённой информации, и модели фактов, связывающие семантико-синтаксические модели, описывающие структуру выражений, принятых в данной области для описания информации, с формальным представлением этой информации, определяемым онтологией ПрО.
-
1.1 Словарь предметной лексики
В рамках предлагаемого подхода в качестве лексической модели языка рассматриваются информационно-поисковые словари ПрО. Такого рода словари ориентированы на автоматическую обработку текста и содержат дополнительную информацию, позволяющую распознавать термины в текстах.
Формально предметный словарь определяется системой вида < V, M, Т, S >, где
V = W и P и L - множество предметных терминов, включающих:
-
■ W - множество лексем (каждой лексеме сопоставлена информацию обо всей совокупности её форм;
-
■ P - множество словокомплексов или многословных терминов, характеризующихся высокой частотностью в анализируемом подъязыке (словокомплекс описывается парой
, где L-грамма задаёт последовательность лексем, а тип структуры определяет вершину и правила согласования элементов L-граммы); -
■ L - множество лексических конструкций, каждая из которых описывается с помощью шаблонов, используемых для распознавания регулярных текстовых фрагментов (лексические конструкции предназначены для распознавания таких структур как сокращения, аббревиатуры, численные или буквенно-численные обозначения объектов ПрО или значения их атрибутов).
M - морфологическая модель языка, включающая описание морфологических классов и атрибутов (атрибуты в рамках каждого класса делятся на словообразующие, присущие всем формам лексемы данного класса, и словоизменительные, различающие формы одной лексемы).
Т - множество тематических признаков, организованных в иерархию (каждому термину может быть сопоставлен набор признаков с указанием веса связи, где вес - это значение из интервала [0,1], отражает степень принадлежности термина признаку).
S - лексико-семантическая модель ПрО.
Рассмотрим подробнее последний компонент, который является особенно важным при моделировании процесса извлечения информации.
Модель предметной лексики должна включать описание структуры семантики терминов и позволять, в конечном итоге, сопоставлять текстовым единицам их смысловые эквиваленты. Предложенная модель включает грамматическую, тезаурусную и семантическую информацию о термине, а также необходимые данные для описания валентностной структуры предикатных слов.
Для кодирования семантической информации о слове предусмотрены следующие возможности (см. рисунок 1).
Семантический класс . Термин может быть отнесён к определённому семантическому классу. Иерархия классов позволяет отнести термин к определённому уровню иерархии, более общему или конкретному с наследованием свойств общего класса.
Семантический атрибут . Для представления лексического значения термина используются семантические атрибуты. Совокупность значений атрибутов, приписанных слову, в определённой мере моделирует компонентную семантическую структуру слова. Основные компоненты семантической структуры термина могут рассматриваться как тезаурусные дескрипторы.
Группировка семантических классов и атрибутов для описания многозначного слова. Если термин имеет более одного формально различимого контекстом значения, формируется соответствующее число семантических статей слова, объединяющих в себе с помощью механизма группировки семантический класс и совокупность семантических атрибутов с их значениями.
Словарь предметной лексики - Анализ
сценариями.vc
Словарь Правка Сервис Вид Настройки О программе
Признак
Термины Словокомплексы Стоп-термины Стоп-словокомплексы При:
|
Лексема |
Часть речи |
|
операция |
Сущ |
|
описание |
Сущ |
|
описать |
Прич |
|
опять |
Нар |
останавливаться Глаг
|
отключать |
Глаг |
|
отключаться |
Глаг |
|
открываться |
Глаг |
|
открытие |
Сущ |
|
отсутствие |
Сущ |
|
падать |
Глаг |
|
падение |
Сущ |
|
первый |
Порядк_Числ |
|
перемещение |
Сущ |
|
переполнение |
Сущ |
|
пид-регулятор |
"Сущ |
|
по |
Предл |
|
повторяться |
Глаг |
|
под |
Предл |
|
подаваться |
Глаг |
|
подача |
Сущ |
|
поддержание |
Сущ |
|
поддерживаться |
Глаг |
|
поддерживаться |
Инф |
|
Гл эг |
|
|
< II ► |
|
Термин:
Нормальная Форма:
останавливаться
Ochoi
остан
Морфологические признаки лек:
Вид: нс, Переходность: нп
Значимые
Э Объект
Э Состояние
В Параметр
В Оценка
3 Процесс
Количественное изменен \ © Перемещение предмета
Перемещение вещества
Изменение температуры
Объект
Состояние
Оценка
Процесс
предмета
вещества
Парадигма (41):
вшаяся, вшегося, вшееся, вшей вшимися, вшимся, вшись, вших< лась, лись, лось, лея, ться, юс>/
Statistic | Semantic
Alternative Groups
inyms
{Управляющее действие, ser Управляющее действие $ет.действие sem. состояние
{Перемещение предмета, sem. Перемещение предмета sem. процесс sem. отр процесс
Терминов: 176 (176)
СЮ 26 (26)
Перемещение вещества до уровня [Управление:
Действие
Исполняющее действие
Контролирующее действие
Управляющее действие
Фаза
Отрицание sem. атрибут
$ет.параметр-кач
$ет.параметр-колич

sem.
sem.
sem. отр-
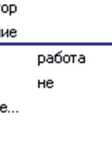
перемещение не
Стоп-терминов: 60 (60) Стоп-СК
Рису н ок 1 – Прим е р описания с емантики т е рмина
Сема н тика найденного в т е ксте тер м ина обеспечивает ф о рмирован и е лексич е ского объекта. Структуру лексического о бъекта м о жно представить сле д ующим о б разом:
LexOb j ect
Name: string; // название те р мина
Descri p tor: string; // имя дескрип т ора
Seman t ic: set of LexClass; // м ножество л ексико-сем а нтических классов
Neg: b o ol; // наличие отр и цания
Attrib u tes: set of Semantic_attr i bute; // множество атрибут о в
Value: string; // з н ачение ил и форма, в к оторой вст р етился тер м ин в текст е
Positio n : int; // позиция тер м ина в тексте
Gram m atics: set of gram_para m eters; // граммат и ческие характеристик и термина
Пара м етр Name задаёт но р мализова н ную форму термин а , получен н ую либо в соответствии с п р авилами морфологи ч еской но р мализации (в случае однослов н ого терми н а), либо в соответствии с правилами со г ласования слов в с л овосочета н ии (для м ногослов н ых терминов), либ о как имя лексическо г о шаблон а (для символьно-чи с ловых ко н струкций). Параметр
Descriptor определяет имя понятия, к которому относится термин. В частности, дескриптор служит для формирования синсетов или групп синонимов, когда все термины с одинаковым дескриптором являются синонимами или квазисинонимами в данной ПрО. Поле Semantic определяет лексико-семантический класс(ы) термина. Наличие нескольких значений в поле Semantic лексического объекта соответствует составному значению термина (например, сложносоставное слово пятиметровый имеет лексическое значение Числа и Единицы измерения ) в отличие от неоднозначности, когда формируется несколько лексических объектов LexObject (например, по термину останавливаться будут созданы объекты с семантикой Действия и Процесса ). Отметим, что морфологическая омонимия не порождает отдельных лексических объектов, а разрешается, если необходимо, в рамках одного объекта. Поле Neg задаёт наличие отрицания при значении термина, которое в тексте может выражаться, например, приставкой не . Поле Attributes задаёт множество семантических атрибутов для представления структуры семантики термина. Поля Grammatics , Position и Value определяются словарными и текстовыми характеристиками термина.
-
1.2 Жанровая модель текста
Предлагаемые решения по анализу и извлечению информации из текстов опираются на понятие жанра как совокупности содержательных и формально-лингвистических (логикокомпозиционных и лексико-грамматических) аспектов.
Жанровая модель текста представляется системой вида GMT = < g, F s , LC, V G , M G , P G >, где:
g - жанровый тип документа;
F S - множество формальных жанровых сегментов (каждый сегмент, найденный в тексте в соответствии с жанровой моделью, определяется типом t f ^ F s и начальной и конечной текстовой позицией);
LC - логико-композиционная структура текста, определяемая множеством взаимосвязей между текстовыми фрагментами;
-
V G - словарь жанровой лексики;
M G - множество жанровых маркеров, которые задаются с помощью терминов из V G ;
P G : M G ^ F S - множество жанровых шаблонов, которые связывают маркеры и структурные блоки текста.
Таким образом, жанровые особенности текста передаются его разбиением на содержательные блоки, которые:
-
■ включают определённую жанровую лексику,
-
■ имеют определённую структурную организацию,
-
■ реализуются в рамках определённых формальных сегментов.
Логико-композиционная структура текста выявляется с помощью лексикона жанровых маркеров и шаблонов, выделяющих содержательные блоки. Маркеры извлекаются из текстов, и прежде всего - из заголовков подразделов, вводных предложений и списков, включенных в состав документа. Простые маркеры сопоставляются терминам предметного словаря или группе терминов (синонимы). Более сложные формируются на основе простых: поддерживаются альтернативы, совместная встречаемость, а также вложенное использование маркеров.
На рисунке 2 в качестве примера приведён фрагмент жанровой модели текста стандартного протокола клинических испытаний. Данные тексты включают жанровые сегменты, маркированные жанровыми тегами, на основе которых могут извлекаться фрагменты текста для поиска той или иной информации.
Выяв л енные на основе жа н ровых м о делей значимые сег м енты мог у т в даль н ейшем использова т ься в качестве услов и я поиска о пределён н ой инфор м ации.
|
TextGenre Block genre segment Block genre_segment Block genre_segment Block genre segment |
Outcomes Assessor)
|
Рису н ок 2 - Фрагмент жанров о й модели т е кста, описы в ающего диз а йн клиниче с кого исслед о вания
-
1.3 Модель факта
Моде л ь факта является о с новой для моделирования про ц есса изв л ечения информации. Каждая м о дель задаёт схему и звлечения единицы информац и и или еди н ичного ф а кта, представленного связанным языко в ым выра ж ением. Пр и извлече н ии факта и з текста н е обходимо учитыват ь множество языков ы х способ о в репрезентации да н ного фак т а носите л ями подъязыка и обеспечивать их трансформаци ю в формальную структуру. С о вокупнос т ь моделей должна описывать процесс це л иком, нач и ная с ини ц иализаци и объекто в , заполне н ия атрибутов и установления онтологич е ских отно ш ений между объект а ми.
Факт, представляя собой з а фиксиров а нное в в ы сказывании (языков о м выраже н ии) эмпирическое знание об объектах, их свойст в ах и ситуациях, мо ж ет быть ф ормализо в ан в виде когнитив н ой схемы, соотнося щ ей его с п онятиями и отношениями он т ологии. Т а ким образом, модель фактов формируе т знания о с огласова н ии имеющихся линг в истическ и х знаний с предметн ы ми знаниями и фи к сирует ф ор мально-л и нгвистич е ские сво й ства, обусловленные языковой практикой описания объектов и ситуаций данной П р О.
Предлагаемый способ мо д елирован и я обеспе ч ивает преимуществ е нное исп о льзование лексико-семантической инфор м ации, чт о не исключает применения ча с тичного с и нтаксического ана л иза и синтаксическ и х ограни ч ений, накладываемых на сема н тический к аркас моделей фа к тов. Известные сист е мы отлич а ются полнотой и ро л ью синта к сическог о анализа в процессе и звлечения фактичес к ой инфор м ации из текстов. Та к , техноло г ия [12] пр е дполагает построение полного семантик о -синтакс и ческого д е рева пред л ожения, к котором у применяются шаблоны (своего рода ф и льтры), о п исывающие иском ы е факты. В предлаг а емом подходе, как и в [13], синтаксический анали з атор применяется л о кально (п р и обнару ж ении ключевых единиц и их конфигураций), в ча с тности, предусмотр е но опред е ление акт а нтных позиций пр е дикатных слов [14].
Основой лингвистическог о описани я факта является сем а нтико-си н таксическая модель, которая о граничивает синтак с ическую с очетаемость и согл а сованнос т ь грамма т ических и семантич е ских признаков тер м инов (вер ш ин синтаксических групп) в с о ответств и и с правилами согласования и управле н ия. Такие модели описываются в виде а ктантной с труктуры, связанно й с одной или нескол ь кими обо б щёнными лексемам и [9, 15]. П од обобщ ё нной лексемой понимается либо термин словаря (или его форма), ли б о группа л ексем, о п исанных в терминах грамматических и с е мантичес к их категорий без ук а зания но р мальной ф ормы. Актантная структура описывает набор акт а нтов, хар а ктеризую щ их соотв е тствующ у ю валентность, в т е рминах семантичес к их и гра м матических характе р истик, ко т орые являются ограничениям и для зависимых сло в .
Сема н тико-синтаксическа я модель х а рактеризуется парой вида < lg, M A >, где:
ig =
Предложенная структура семантико-синтаксических моделей предоставляет широкие возможности моделирования языковых связей в тексте. Так, модель может не содержать синтаксических ограничений и представлять собой онтологические отношения или описываться без семантических характеристик и соответствовать чисто синтаксическим моделям управления. Обобщение лексем в моделях позволяет компактно определить многие языковые конструкции, варианты взаимосвязи слов в выражениях и словарные группы.
Модель фактов задаётся структурой, аналогичной актантной структуре, которая описывается либо в терминах классов онтологии, либо в терминах семантических признаков словаря и связывается с фрагментом онтологии. Дополнительно накладываются ограничения на онтологические признаки элементов структуры и их взаиморасположение в тексте.
Формально модель фактов – это система вида
F =
M AF – последовательность аргументов факта;
M SS – множество семантико-синтаксических моделей, которым должны удовлетворять аргументы на уровне лексического состава;
Cs – множество семантических ограничений;
C P – множество структурных ограничений;
O Res – фрагмент онтологии, в соответствии с которым формируется результат применения модели фактов - новые объекты и/или изменения атрибутов уже существующих объектов, которые являются экземплярами понятий онтологии (относящихся к заданному фрагменту).
Выделяются два основных типа моделей фактов: модели, служащие для начальной инициализации объектов, и модели для выявления связей. Модели первой группы необходимы для начального формирования онтологических сущностей на основании словарных признаков. Модели второй группы моделируют процессы «обнаружения» фрагментов онтологии.
Рассмотрим эти два типа на примерах.
Система семантических признаков словаря формируется на основе онтологических сущностей, что позволяет инициализировать начальное формирование объектов непосредственно на основании словарных признаков. Рассмотрим пример описания модели для инициализации объектов класса Препарат , которые могут быть представлены в тексте аппозитивной именной группой. В этой группе опорным словом является родовое слово или словоком-плекс (тип), а имя примыкает к нему в постпозиции.
Scheme Препарат3 : segment Клауза arg1: Term::Препарат(SemClass: тип)
arg2: Term:: Препарат(SemClass: имя)
Condition PrePos(arg1,arg2), Contact(arg1,arg2)
В данной модели термины должны иметь семантических класс Препарат , с учётом иерархии наследования признаков в словаре, а также первый термин должен обладать семантическим признаком тип , а второй – имя . При применении данной модели, например, к фразе:
вакцина < Препарат, SemClass: тип> "ACAM2000" < Препарат , SemClass: имя>1
создаётся объект – экземпляр понятия онтологии Препарат , тип препарата (например, фармакологическая группа) может уточниться в соответствии с семантическим признаком первого или второго термина, атрибут Наименование у объекта заполняется наименованием второго термина Norm .
В качестве другого примера инициализирующей модели рассмотрим случай, когда на основе лексического шаблона (LexTerm) выделяется фрагмент текста в кавычках и формируется гипотеза о том, что это имя объекта, но уточнение его класса возможно только при наличии термина-классификатора:
Scheme Новый_объект : segment Клауза arg1: Term:: (SemClass: тип)
arg2: LexTerm::Именованный объект()
Condition PrePos(arg1,arg2), Contact(arg1,arg2)
Формирование объекта с помощью данной модели осуществляется аналогично предыдущей.
При поиске и выявлении характеристик объектов и их связей, как правило, требуется проверить сочетаемость семантических и/или грамматических признаков объектов.
Рассмотрим примеры модели, используемой для извлечения атрибутов объектов.
Scheme ТипКогорты: genre_segment
Данная модель позволяет уточнить тип группы на основе информации о жанровой структуре документа, которая в соответствии с принятым стандартом содержится строго в определённых жанровых фрагментах.
Рассмотрим пример модели для построения отношения в соответствии с рассматриваемой ситуацией.
Scheme УсловияПримененияПрепарата: genre_segment
arg2: Object::Препарат()
arg3: Term::Параметр(SemClass: кратность)
arg4: LexTerm::Доза()
arg5*: Term::Параметр(SemClass: время)
Condition
genre_segment (arg2, arg3, arg4, arg5)
Contact(arg2, arg3), Contact_weak(arg2, arg4), Contact_weak(arg2, arg5)
Условия назначения препарата для конкретной группы людей описываются такими характеристиками, как наименование препарата, его дозировка, кратность применения и время приёма. Данная информация в соответствии с принятым стандартом содержится строго в определённых жанровых фрагментах, однако в рамках фрагмента description описание пара- метров разворачивается в виде текста, что требует применения более сложного лингвистического анализа. В результате применения модели создается описание ситуации терапевтического вмешательства.
Приведённый набор моделей фактов демонстрирует подход к извлечению информации о проводимом клиническом исследовании на основе структуры протокола.
2 Модель представления текста
Важным компонентом моделирования процесса извлечения информации является модель представления текста, которая последовательно изменяется, обогащаясь на каждом этапе анализа новыми знаниями. Для описания происходящих изменений предложена модель, близкая по смыслу к схемам, используемым при создании размеченных корпусов текстов [16]. Отличия заключаются в:
-
■ единообразной поддержке всех этапов обработки текста, включая семантический;
-
■ использовании «внешнего» аннотирования (а не систему тэгов), синхронизированного с текстом [17];
-
■ ориентации на объектно-ориентированное представление данных.
Модель представлена набором покрытий текста , когда промежуточные результаты обработки представляются однотипными объектами с заданной проекцией на текст (текстовыми интервалами), что позволяет наглядно интерпретировать полученные результаты и выделять контекстно связанные с каждым элементом знания.
Модель текста определяется пятеркой < C A , C L , C G , C Th , C IO >, где:
C
A
= {atom
1
, ..., atom
n
}
- графематическое покрытие, содержащее множество атомов
atom
i
=
C
L
= {lex
i
, .., lex
n
}
- терминологическое покрытие, содержащее множество лексических объектов вида
lex
i
=
C
G
= {s
i
, ., s
n
}
- сегментное (или жанровое) покрытие, отражающее логикокомпозиционную структуру текста и включающее множество сегментов вида
s
i
=
C Th = {st 1 , -., st n } - тематическое покрытие, которое определяется множеством тематических фрагментов вида st i =
C IO = {IO i , ., IO n } - информационное покрытие, содержащее множество найденных в тексте информационных объектов вида IO i = I>, где I - онтологический объект или экземпляр понятия, определённого онтологией ПрО, Pos - текстовая позиция (в общем случае разрывная, т.е. определяемая множеством неразрывных позиций pos), RI - множество информационных зависимостей объекта, полученных в процессе обработки текста при использовании информации из одного объекта для генерации или обновления другого.
В зависимости от решаемой задачи могут быть выделены и другие типы покрытий. При- ведённая модель ориентирована в первую очередь на задачи семантического анализа и извлечения информации. На рисунке 3 представлена общая схема преобразования входящих текстовых данных и промежуточные результаты в виде покрытий.
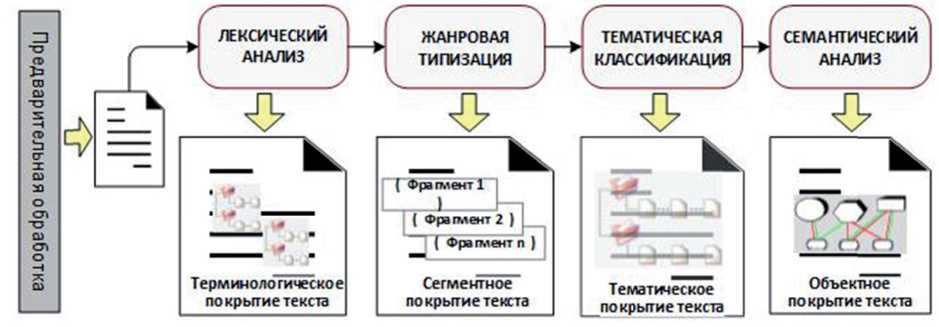
Рисунок 3 – Э тапы форм и рования модели предста в ления текс т а
Графематическое покрытие текста я вляется результатом его графе м атическо г о анализа, в процессе которого входящи й линейны й текст ра з бивается н а элемент а рные ато м ы. Основная задача данного этапа – сгр у ппироват ь символы одного ти п а в после д овательн о сти и дать им необх о димую интерпретац и ю: слово определённого алфа в ита, числ о , знак пр е пинания и т.п. Для решателей, работающ и х с разме т кой (напр и мер, html - тексты), м ожно доп о лнительно задать типизацию тэгов или п о мет. Важ н ым свойством данн о го предс т авления я в ляется то, что элем е нты покрытия зада ю т все воз м ожные границы элементов дл я всех по с ледующих представ л ений, т.е. при дальнейшей обработке ни один атом н е может б ы ть «разде л ён».
Терминологическое покры т ие состо и т из словарных терм и нов, най д енных в д а нном тексте, с уче т ом возможной омон и мии и пе р есечений многослов н ых терм и нов. Терм и нологическое покрытие текста – это ле к сическая м одель те к ста, которая строит с я на осно в е лексической мод е ли подъязыка ПрО, и включает найденные в тексте т ермины с привязкой к позиции в тексте. П осле того, как терм и н найден в тексте, формирует с я лексиче с кий объек т , который снабжается набором семантич е ских атр и бутов, зад а нных в п р едметном словаре д л я найденного термина (см. раздел 1.1).
Сегментное покрытие отражает стр у ктурное деление текста на лог и ческие (а б зац, предложение, з аголовок и т.п.) и ж а нровые ф р агменты. Ж анровое покрытие я вляется р е зультатом сегментации текста и одним и з способов отражения его форм а льной стр у ктуры. С е гментация рассматривается на макроуров н е, т.е. на у ровне всего текста ( в отличие о т локаль н ого анализа предложения и выделения совокупнос т и взаимосвязанных фрагмент о в (клауз), р ассматриваемых в рамках синтаксиче с кого анал и за предл о жения) и опираетс я как на ф ормальнотекстовы е , так и на жанровые особенно с ти документа (см. р а здел 1.2), которые п ередаются разбиени е м текста на концеп т уальные ч асти. При анализе т екста раз б иение на жанровые фрагменты помогает сузить о б ласть пои с ка инфор м ации определённог о вида и, т ем самым, повысить качество анализа. С помощью жанровой структур ы текста м о гут реша т ься задачи определе н ия жанровой релева н тности д о кументов, полученн ы х из неи з вестных и с точников, например, при поиске в Интер н ет [18].
Тематическое покрытие определяет текстовые границы тематически-связанных областей текста для каждой рассматриваемой тематики. Формирование таких областей осуществляется на основе словаря, в котором задано соответствие между термин ами и тематическими признаками. Тематическое покрытие стр оится над терминологическим и жанровым покры- тием. Здесь элемент тематического покрытия определяется как фрагмент текста, включающего кластер терминов, относящихся к одной теме, в границах формального сегмента (или последовательности сегментов) жанрового покрытия. Аналогично сегментам, тематические сегменты могут сужать область поиска информации определённого вида.
Информационное (объектное) покрытие описывает найденную информацию в виде семантической сети объектов ПрО. Информационное покрытие текста является самым информационно-насыщенным и представляет результаты семантической обработки документа. Чтобы построить информационное покрытие необходимо представить содержание документа в понятной компьютеру форме. Условием этого является наличие формата данных, задающего строгую структуру представления и хранения полученной информации. Данная структура должна быть «заранее» осмыслена, т.е. иметь заранее заданную семантическую интерпретацию. В современных подходах для этого используют онтологии ПрО [19].
В упрощённом виде онтологию можно представить как
O =
C – множество классов, описывающих понятия ПрО;
T = U T i - множество типов данных и V i - множество значений типа T i ;
A - множество атрибутов, F A : C ^ 2 a ^ t u :c - функция, которая определяет имена и типы атрибутов классов C ; выделяются атрибуты простых типов (owl:DataProperty) и связи (owl:ObjectProperty), также определяется подмножество ключевых атрибутов A K с A, которые служат для однозначной идентификации объектов.
Контент информационной системы, построенной на основе онтологии O , представляется множеством экземпляров классов онтологии и описывается как I = {I 1 ,..,I n } , где I i класса C i представляется набором атрибутов со значениями Av i = {(a 1 ,v 1 ), …, (a k ,v k )} .
Объектное покрытие описывает информационный контент текста в терминах информационных объектов, которые формируются на основе онтологических понятий и должны быть сопоставлены определённому экземпляру онтологии, который либо уже присутствует в контенте информационной системы, либо будет добавлен в результате анализа текста. Таким образом, информационные объекты являются своего рода «вхождениями» или упоминаниями онтологических объектов, обнаруженными в тексте.
Информационные объекты формируются на основе моделей фактов (см. раздел 1.3.), при этом порождаются информационные зависимости между объектами, выступающими в качестве аргументов модели, и её результатом. Для точного описания данных зависимостей используется атрибутивная модель извлечения информации.
Преимущество предложенной модели текста заключается: во-первых, в наглядном представлении результатов работы анализатора; во-вторых, предложенное описание может являться основой для формального описания алгоритмов и доказательства их свойств, а также служить в качестве абстракции верхнего уровня для программной реализации; в-третьих, использование данного представления в рамках информационных систем обеспечит достоверность результата, подтверждаемого непосредственно текстовым источником, что позволит проводить широкий спектр корпусных исследований.
3 Атрибутивная модель извлечения информации
При описании последовательных процессов извлечения информации с помощью моделей фактов интенсивно используются атрибуты объектов и связи между ними. Поэтому для детального представления происходящих процессов и отражения возникающих информационных зависимостей не только на уровне объектов, но и между их атрибутами, решено воспользоваться подходом к моделированию процессов на основе атрибутной конвейерной модели (АКМ).
Атрибутная модель - это логическая модель данных, предназначенная для отображения связей между свойствами или атрибутами объектов, участвующих в одном процессе. Для корректного моделирования процессов извлечения информации модели должны обладать свойством конвейерности, т.е. позволять описывать процессы, внутри которых не возникают циклы. Такого рода модели широко используются в различных ПрО, например, при описании технологических процессов с помощью диаграмм сборки Сервис-Компонентной Архитектуры SCA [20]. Использование АКМ позволяет выстраивать общую схему процесса с зависимостями по атрибутам.
В общем виде модель АКМ можно описать системой вида < O M , A, L >, где:
O M - множество объектов моделирования;
A - множество атрибутов объектов (подразумеваются атрибуты простых типов данных);
L - множество направленных связей между атрибутами объектов.
При моделировании процесса извлечения информации связь между атрибутами интерпретируется как передача значения от одного атрибута к другому. Для обеспечения целостности модели на связи накладываются следующие ограничения:
-
■ атрибут может иметь только одну входящую связь и множество исходящих связей;
-
■ связь можно установить только между атрибутами одного типа.
Для поддержки моделирования процессов извлечения информации на основе онтологии и моделей фактов было необходимо расширить АКМ таким образом, чтобы она поддерживала следующие возможности:
-
■ в качестве атрибута объекта может выступать другой объект, и, соответственно, модель должна предоставлять возможность устанавливать связь между объектом и атрибутом другого объекта (соответствующего типа);
-
■ возможность устанавливать значение атрибута напрямую без использования связей, т.е. без передачи значения от другого объекта;
-
■ в случае порождения нового объекта (в соответствии с моделями фактов) возможность устанавливать связи между аргументами факта и порождаемым объектом.
Для реализации первой возможности была расширена типизация свойств АКМ - добавлена возможность использовать класс онтологии в качестве типа данных атрибута (аналогично онтологическому объекту), также в модель введены соответствующие связи между объектом и атрибутом, которые обладают теми же возможностями и ограничениями, что и исходящие связи. Для поддержки второй возможности были добавлены независимые атрибуты - атрибуты, значения которых можно изменять напрямую, не используя соединения (при этом возникают неявные зависимости между аргументами факта и независимым атрибутом, которые пока не моделируются). И, наконец, в случае если других связей не установлено, между объектом-аргументом и результирующим объектом устанавливается объектная связь , которая реализуется на уровне имён классов, т.е. имя класса объекта в данной модели рассматривается как его атрибут.
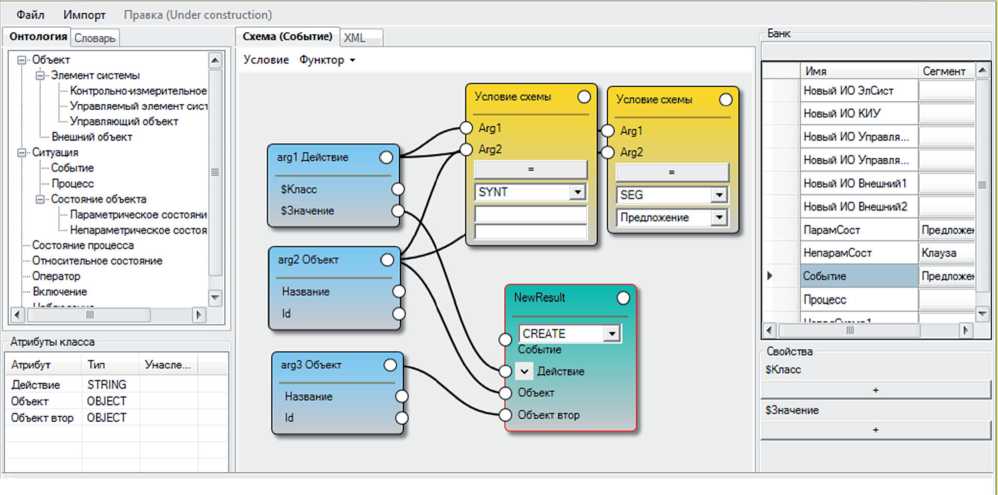
Предложенная модель имеет два практических применения. В первом случае АКМ является основой (метамоделью) для моделирования процессов с помощью моделей фактов: как для описания единичных моделей (см. рисунок 4), так и для их совокупности. В другом случае в процессе обработки текста она используется для сохранения информационных зависимостей между объектами информационного покрытия текста (данные информационные зависимости согласуются с зависимостями, заданными в моделях фактов) и, тем самым, представляет «историю» создания объектов. Эта информация позволяет, в частности, оценить степень связности объекта с контекстом и осуществить корректное удаление объекта из системы.
FATON Scheme Editor
SYNT
Свойства
SKnacc
ЗЗначение
Атрибуты класса
NewResult О
Объект втор
| CREATE Событие
) v Действие
) Объект
Атрибут
Действие
Объект
Объект втор
Тип Унасле...
STRING OBJECT OBJECT агдЗ Объект Q
Название
Условие схемы Q
Агд1
Агд2
Схема (Событие) XML
Файл Импорт Правка (Under construction)
Условие Функтор ▼ агд1 Действие
$Класс
ЗЗначение агд2 Объект
Название
Id
Объект
Элемент системы
|~ Контрольно-измерительное Управляемый элемент сист Управляющий объект
Внешний объект
Ситуация
Событие
Процесс
В Состояние объекта
Параметрическое состояни Непараметрическое состоя
Состояние процесса Относительное состояние
Оператор Включение
В-
В
Сегмент
Новый ИО КИУ
Новый ИО Управля...
Новый ИО Управля...
Новый ИО Внешний)
Новый ИО Внешний 2
ПарамСост
НепарамСост
Предложе!
Событие
Процесс
Предложе!
Клауза
Имя __________
Новый ИО ЭлСист
Arg1
Arg2
Условие схемы О
|SEG _£]
| Предложение
Проект загружен.
Рисунок 4 – Пр и мер использ о вания АК М для модели р ования про ц есса из в лечения ин ф ормации о единичном ф а кте
4 Извлечение информации
Задач а извлечения инфор м ации в со о тветствии с предло ж енными м оделями п редставления текст а сформулирована в о бщем вид е следующим образо м .
Для заданной четверки < O , I, LM, T > , где: O – онтология П рО, I – и н формаци о нный контент сист е мы, LM – модель по д ъязыка П р О, T – те к стовый и с точник, п о строить и н формационное по к рытие текста C IO , об л адающее с войством однознач н ости и со п оставимо с ти с I . Под однознач н остью понимается н аличие не более од н ой интер п ретации л ю бого фр а гмента заданного т екста T . Это означ а ет, что п р и наличии несколь к их вариа н тов разб о ра текста, например, в случае омонимии, должен б ы ть выбран один вар и ант. Сво й ство сопо с тавимости с контен т ом системы означае т , что каж д ому информационному объе к ту, входя щ ему в результирующее информационн о е покрыт и е C IO , должен быть о днозначн о сопоста в лен экземпляр онтологии O, что обеспечивается н аличием заданных к лючевых а трибутов. Сопоставляемый экземпляр, по сути, я в ляется он т ологическим рефер е нтом най д енного в т ексте объекта.
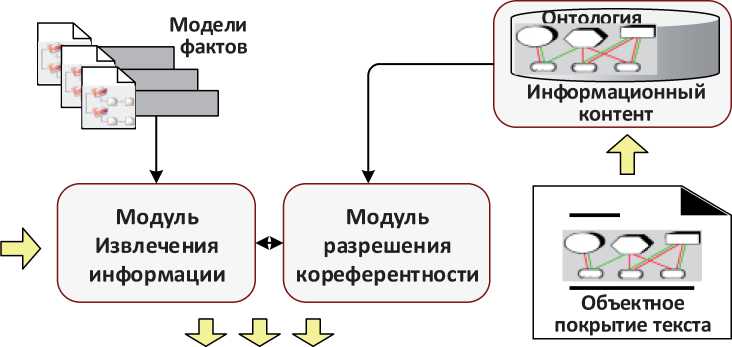
На рисунке 5 представлен а общая с х ема реали з ации сем а нтическог о этапа ан а лиза и извлечения информации из текс т а. На вхо д системы основного анализа п о ступают р езультаты предвари т ельного этапа обраб о тки текст а в виде те р минолог и ческого, с е гментног о и тематического п о крытия текста. Баз а знаний с и стемы вк л ючает зна н ия об он т ологии П р О и моделях фактов, заданных для дан н ой онтол о гии. Результатом ра б оты сист е мы являе т ся объектное покрытие текста, на осно в е которог о формируется результирующе е множест в о онтологических объектов, описываю щ их конте н т докумен т а в терми н ах онтол о гии ПрО.
В про ц ессе основного ана л иза можн о выделить следующ и е три осно в ных зада ч и:
-
1) Непосредственно извлече н ие фактов на основе моделей фактов.
-
2) Разрешение кореференци и и поиск р еферентов объектов в онтолог и ческом к о нтенте системы.
-
3) Разрешение неоднозначно с ти.

Варианты объектного покрытия текста
Рисунок 5 – Схема извлечения информации из текста


Модуль


разрешения
конфликтов
Решение первой задачи моделируется пользователем при разработке моделей фактов. Технологическая поддержка данного процесса осуществляется системой, которая по моделям фактов формирует правила и применяет их к входным данным (одна из возможных реализаций данной системы представлена в [21]). Качество извлечения информации в большой степени зависит от качества модели процесса, созданной пользователем. В результате формируется АКМ процесса извлечения информации для данного текста.
От решения второй задачи во многом зависит полнота анализа. В работе [22] предложен метод разрешения кореференции на основе онтологии, в рамках которого осуществляется семантическое сравнение найденных в текстах объектов с учётом их онтологических свойств. На данном этапе ищутся все упоминания каждого онтологического объекта, формируются кореферентные группы информационных объектов и разрешаются возможные конфликты. На качество решения данной задачи влияют степень проработанности заданной пользователем онтологии и наполненность информационного контента системы.
Решение третьей задачи обеспечивает формирование конечного варианта объектного покрытия текста для размещения в информационном контенте системы. Неоднозначности при анализе текста возникают вследствие особенностей естественного языка. Языковая неоднозначность — это способность слова или выражения иметь различные интерпретации, в результате которой порождаются различные варианты разбора текста, конфликтующие между собой. В разрабатываемом подходе конфликты рассматриваются на уровне проекции результатов анализа текста на ПрО, т.е. в контексте заданной онтологии. Полученная при извлечении фактов АКМ характеризует информационные зависимости, возникшие в процессе формирования данной модели. Предлагаемый метод основан на идее вычисления степени информационной связанности информационных объектов, извлечённых из заданного текста [23]. Модуль разрешения конфликтов должен разрешить все неоднозначности таким обра- зом, чтобы система была свободной от конфликтов и при этом сохранила максимально возможное количество объектов и связей.
Результат работы системы анализа помещается в информационное хранилище, предварительно обеспечив однозначную идентификацию найденных объектов методом, предложенным в работе [24].
Заключение
Представленный в работе подход к моделированию процессов извлечения информации существенным образом опирается на знания о ПрО, явно формализованные в виде онтологии, что позволяет применять методы локального семантического и синтаксического анализа, не требуя наличия полного корректного синтаксического разбора и грамматически правильно построенного текста. Сужение области значения предметных терминов значительно уменьшает неоднозначность текста. Использование информационного контента онтологии при идентификации и сравнении объектов, найденных в тексте, позволяет использовать неявные знания, т.е. информацию, не содержащуюся в тексте.
Рассмотренные модели и их технологическое обеспечение предоставляют конечным пользователям – экспертам в ПрО, лингвистам и инженерам знаний – инструменты для моделирования процессов извлечения информации и их отладки, а разработчикам информационных систем – инструменты для проектирования систем автоматической обработки текста и концептуальные схемы представления данных.
Работа выполнена при финансовой поддержке Президиума СО РАН (Блок 36.1. Комплексной программы ФНИ СО РАН II.1) и РФФИ (грант № 17-07-01600).
Список литературы Подход к моделированию процесса извлечения информации из текста на основе онтологии
- Petasis, G. Ontology Population and Enrichment: State of the Art/G. Petasis, V. Karkaletsis, G. Paliouras, A. Krithara, E. Zavitsanos//In Knowledge-driven multimedia information extraction and ontology evolution. -LNAI 6050. -Springer-Verlag Berlin, 2011. -P.134-166.
- Мельчук, И.А. Опыт теории лингвистических моделей: «Смысл-Текст». Семантика, синтаксис/И.А. Мельчук. -М.: Школа «Языки русской культуры», 1999. -992 с.
- Нариньяни, А.С. ТЕОН-2: от Тезауруса к Онтологии и обратно/А.С. Нариньяни//Труды международного семинара Диалог'2002 по компьютерной лингвистике и ее приложениям. -М.: Наука, 2002. -Т.1. -С.307-313.
- Загорулько, Ю.А. Семантическая технология разработки интеллектуальных систем, ориентированная на экспертов предметной области/Ю.А. Загорулько//Онтология проектирования. -2015. -Т.5. -№1 (15). -С.30-46.
- Добров, Б.В. Онтологии и тезаурусы: модели, инструменты, приложения: учебное пособие/Б. В. Добров, В. В. Иванов, Н.В. Лукашевич, В.Д. Соловьев. -М.: Интернет-университет информационных технологий; БИНОМ. Лаборатория знаний, 2009. -173 с.
