Помехоустойчивое кодирование

Автор: Головин П.Б.
Журнал: Мировая наука @science-j
Рубрика: Естественные и технические науки
Статья в выпуске: 9 (9), 2017 года.
Бесплатный доступ
В статье рассматривается помехоустойчивое кодирование,как кодируется сообщение,как найти и исправить ошибку в сообщение.А также на примере рассматривается,как работает декодер.
Кодирование, ошибка, код, проверочный бит, код хэмминга
Короткий адрес: https://sciup.org/140262979
IDR: 140262979
Error-correction coding
The article considers noise-immune encoding, how the message is encoded, how to find and correct the error in the message. And also, for example, it examines how the decoder works.
Текст научной статьи Помехоустойчивое кодирование
Когда мы передаем сообщение от источника к приемнику, при передаче данных может произойти ошибка (помехи, неисправность оборудования и пр.). Чтобы обнаружить и исправить ошибку, применяют помехоустойчивое кодирование, т.е. кодируют сообщение таким образом, чтобы принимающая сторона знала, произошла ошибка или нет, и при могла исправить ошибки в случае их возникновения.
По сути, кодирование — это добавление к исходной информации дополнительной, проверочной, информации. Для кодирования на передающей стороне используются кодер , а на принимающей стороне — используют декодер для получения исходного сообщения.
Избыточность кода — это количество проверочной информации в сообщении. Рассчитывается она по формуле:
k/(i+k), где k — количество проверочных бит, i — количество информационных бит. Например, мы передаем 3 бита и к ним добавляем 1 проверочный бит — избыточность составит 1/(3+1) = 1/4 (25%).
Код с проверкой на четность
Проверка четности – очень простой метод для обнаружения ошибок в передаваемом пакете данных. С помощью данного кода мы не можем восстановить данные, но можем обнаружить только лишь одиночную ошибку.
В каждом пакет данных есть один бит четности , или, так называемый, паритетный бит . Этот бит устанавливается во время записи (или отправки) данных, и затем рассчитывается и сравнивается во время чтения (получения) данных. Он равен сумме по модулю 2 всех бит данных в пакете. То есть число единиц в пакете всегда будет четно . Изменение этого бита (например с 0 на 1) сообщает о возникшей ошибке.
Ниже показана структурная схемы кодера для данного кода входной
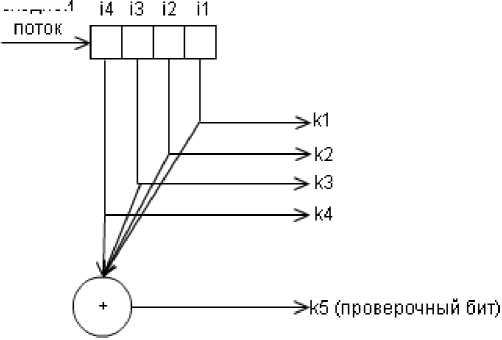
и декодера
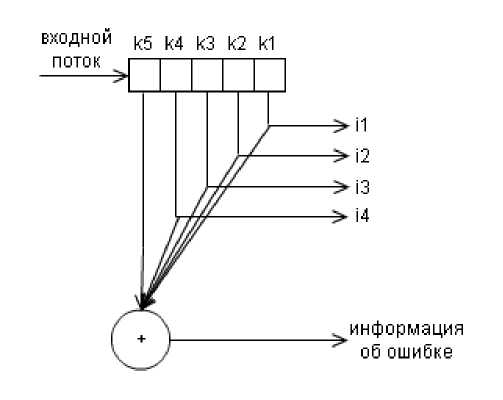
Пример:
Начальные данные: 1111
Данные после кодирования: 11110 ( 1 + 1 + 1 + 1 = 0 (mod 2) )
Принятые данные: 10110 (изменился второй бит)
Как мы видим, количество единиц в принятом пакете нечетно, следовательно, при передаче произошла ошибка.
Как говорилось ранее, этот метод служит только для определения одиночной ошибки. В случае изменения состояния двух битов, возможна ситуация, когда вычисление контрольного бита совпадет с записанным. В этом случае система не определит ошибку, а это не есть хорошо. К примеру:
Начальные данные: 1111
Данные после кодирования: 11110 ( 1 + 1 + 1 + 1 = 0 (mod 2) ) Принятые данные: 10010 (изменились 2 и 3 биты)
В принятых данных число единиц четно, и, следовательно, декодер не обнаружит ошибку.
Так как около 90% всех нерегулярных ошибок происходит именно с одиночным разрядом, проверки четности бывает достаточно для большинства ситуаций.
Код Хэмминга
Как говорилось в предыдущей части, очень много для помехоустойчивого кодирования сделал Ричард Хэмминг. В частности, он разработал код, который обеспечивает обнаружение и исправление одиночных ошибок при минимально возможном числе дополнительных проверочных бит. Для каждого числа проверочных символов используется специальная маркировка вида (k, i), где k — количество символов в сообщении, i — количество информационных символов в сообщении. Например, существуют коды (7, 4), (15, 11), (31, 26). Каждый проверочный символ в коде Хэмминга представляет сумму по модулю 2 некоторой подпоследовательности данных. Рассмотрим сразу на примере, когда количество информационных бит i в блоке равно 4 — это код (7,4), количество проверочных символов равно 3. Классически, эти символы располагаются на позициях, равных степеням двойки в порядке возрастания:
первый проверочный бит на 20 = 1;
второй проверочный бит на 21 = 2;
третий проверочный бит на 22 = 4;
но можно и разместить их в конце передаваемого блока данных (но тогда формула для их расчета будет другая).
Теперь рассчитаем эти проверочные символы:
r1 = i1 + i2 + i4
r2 = i1 + i3 + i4
r3 = i2 + i3 + i4
Итак, в закодированном сообщении у нас получится следующее: r1 r2
i1 r3 i2 i3 i4
Приведу в пример структурную схему кодера:
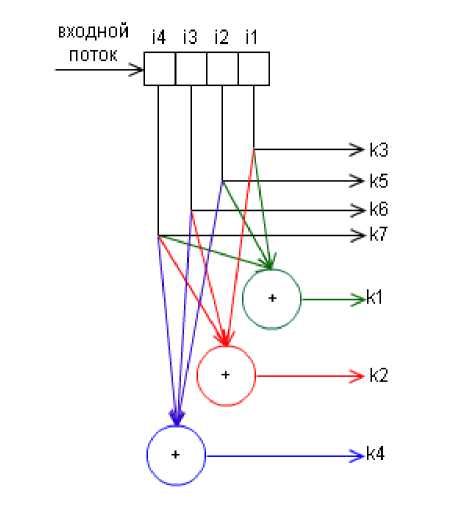
и декодера
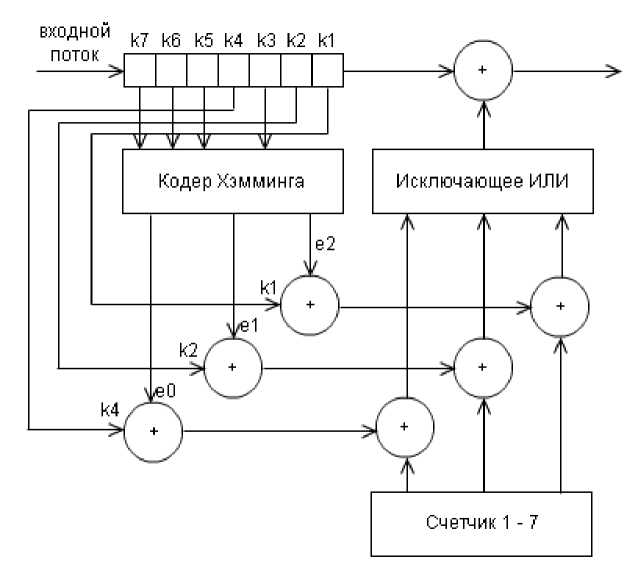
e0,e1,e2 опрделяются как функции, зависящие от принятых декодером бит k1 — k7:
e0 = k1 + k3 + k5 + k7 mod2
e1 = k2 + k3 + k6 + k7 mod2
e2 = k4 + k5 + k6 + k7 mod2
Набор этих значений e2e1e0 есть двоичная запись позиции, где произошла ошибка при передаче данных. Декодер эти значения вычисляет, и если они все не равны 0 (то есть не получится 000), то исправляет ошибку.
Коды-произведения
В канале связи кроме одиночных ошибок, вызванных шумами, часто встречаются пакетные ошибки, вызванные импульсными помехами, замираниями или выпадениями (при цифровой видеозаписи). При этом пораженными оказываются сотни, а то и тысячи бит информации подряд. Ясно, что ни один помехоустойчивый код не сможет справиться с такой ошибкой. Для возможности борьбы с такими ошибками используются коды-произведения. Принцип действия такого кода изображён на рисунке:

Передаваемая информация кодируется дважды: во внешнем и внутреннем кодерах. Между ними устанавливается буфер, работа которого показана на рисунке:
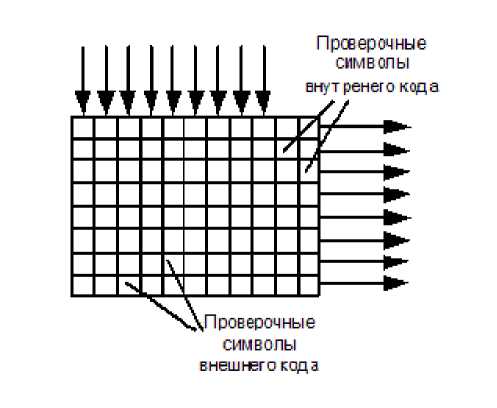
Информационные слова проходят через первый помехоустойчивый кодер, называемый внешним, т.к. он и соответствующий ему декодер находятся по краям системы помехоустойчивого кодирования. Здесь к ним добавляются проверочные символы, а они, в свою очередь, заносятся в буфер по столбцам, а выводятся построчно. Этот процесс называется перемешиванием или перемежением .
При выводе строк из буфера к ним добавляются проверочные символы внутреннего кода. В таком порядке информация передается по каналу связи или записывается куда-нибудь. Условимся, что и внутренний, и внешний коды – коды Хэмминга, с тремя проверочными символами, то есть и тот, и другой могут исправить по одной ошибке в кодовом слове (количество «кубиков» на рисунке не критично — это просто схема). На приемном конце расположен точно такой же массив памяти (буфер), в который информация заносится построчно, а выводится по столбцам. При возникновении пакетной ошибки (крестики на рисунке в третьей и четвертой строках), она малыми порциями распределяется в кодовых словах внешнего кода и может быть исправлена.
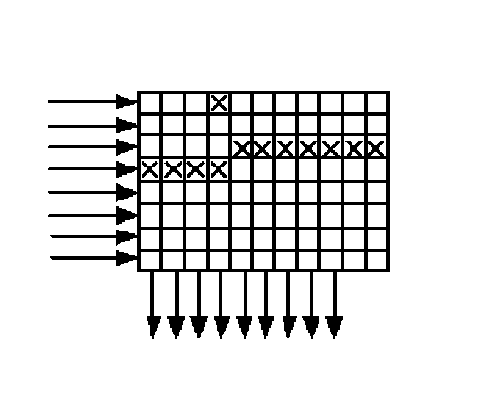
Назначение внешнего кода понятно – исправление пакетных ошибок. Зачем же нужен внутренний код? На рисунке, кроме пакетной, показана одиночная ошибка (четвертый столбец, верхняя строка). В кодовом слове, расположенном в четвертом столбце — две ошибки, и они не могут быть исправлены, т.к. внешний код рассчитан на исправление одной ошибки. Для выхода из этой ситуации как раз и нужен внутренний код, который исправит эту одиночную ошибку. Принимаемые данные сначала проходят внутренний декодер, где исправляются одиночные ошибки, затем записываются в буфер построчно, выводятся по столбцам и подаются на внешний декодер, где происходит исправление пакетной ошибки. Использование кодов-произведений многократно увеличивает мощность помехоустойчивого кода при добавлении незначительной избыточности.
Список литературы Помехоустойчивое кодирование
- Гладких А.А., Климов Р.В., Чилихин Н.Ю. Методы эффективного декодирования избыточных кодов и их современные приложения. - Ульяновск: УлГТУ, 2016. - 258 с.
- Скляр Б. Цифровая связь. Теоретические основы и практическое применение: изд. 2-е, испр. пер. с англ. - М.: Издательский дом «Вильямс», 2003. - 1104 с.
- Питерсон У., Уэлдон Э. Коды, исправляющие ошибки, пер. с англ.; под ред. Р. Л. Добрушина и С. Н. Самойленко. - М.: Мир, 1976. - 594 с.
