Построение модели многосвязного объекта на основе совместного использования данных и экспертных оценок

Автор: Гвоздев В.Е., Мунасыпов Р.А., Бежаева О.Я., Ахметова Д.Р.
Журнал: Онтология проектирования @ontology-of-designing
Рубрика: Инжиниринг онтологий
Статья в выпуске: 3 (33) т.9, 2019 года.
Бесплатный доступ
Рассматривается метод построения статистических моделей многосвязных объектов в виде многомерных регрессионных зависимостей на основе совместного использования измерительных данных и экспертных оценок. Основная идея метода заключается в преобразовании независимо полученных экспертных оценок и измерительных данных к единому виду - закону распределения непрерывной случайной величины. Это делает возможным сформировать корреляционную таблицу на основе решения обратной задачи определения закона распределения функции случайного аргумента. Сформированная корреляционная таблица служит основой построения регрессионной зависимости известными методами регрессионного анализа. Главным результатом работы является впервые предложенный метод построения многомерных регрессионных зависимостей за счѐт совместного использования экспертных оценок и измерительных данных.
Многосвязный объект, многомерная регрессионная зависимость, закон распределения, случайная величина, экспертная оценка
Короткий адрес: https://sciup.org/170178829
IDR: 170178829 | УДК: 519.711.3 | DOI: 10.18287/2223-9537-2019-9-3-361-368
Construction of a multi-connected object model object based on joint use of data and expert evaluations
The article discusses a method for constructing statistical models of multi-connected objects in the form of multidimensional regression dependencies based on the joint use of measurement data and expert assessments. The main idea of the method is to convert independently obtained expert estimates and measurement data to a single type - the law of distribution of a continuous random variable. This makes it possible to form a correlation table based on the solution of the inverse problem of determining the distribution law of the function of a random argument. The formed correlation table serves as the basis for the construction of the regression dependence by the known methods of regression analysis. The main result of the work is the first proposed method for constructing multidimensional regressive dependencies by sharing expert estimates and measurement data.
Текст научной статьи Построение модели многосвязного объекта на основе совместного использования данных и экспертных оценок
Одной из задач построения дескриптивных статических моделей многомерных многосвязных объектов является задача построения многомерных регрессионных зависимостей. Классический подход к решению этой задачи основан на использовании таблицы совместно наблюдаемых значений независимой и зависимой случайных величин.
На практике формирование таблицы совместно наблюдаемых значений может встречать определённые трудности. Это обусловлено, например, тем, что сбор различных данных осуществляется несколькими организациями, деятельность которых регламентируется разными документами. Либо тем, что происходят потери архивных данных. Либо вследствие того, что измерения параметров состояния сложных систем ранее не осуществлялись, но для их оценки можно использовать мнение экспертов. В качестве примера можно привести задачи, связанные с управлением дефектами в программных компонентах аппаратно-программных комплексов на разных стадиях их жизненного цикла [1].
Значения независимых и зависимых параметров могут задаваться в виде измерительных данных и в виде экспертных оценок разного вида: в виде ожидаемых значений; интервала возможных значений; совокупности ожидаемых значений и интервала возможных значений случайной величины. Разработка метода преобразования измерительных данных и экспертных оценок, задаваемых в разных формах, к виду таблицы совместно наблюдаемых значений, послужит основой построения многомерных регрессионных зависимостей.
1 Методы построения функциональных зависимостейна основе измерительных данных и экспертных оценок
Классическому подходу к построению регрессионных зависимостей можно поставить в соответствие схему
-
(1) Л < 0 > :{х,у} " ^у = ф 0( х, 9).
Здесь { х, z } " - множество совместно наблюдаемых значений компонент векторов независимой х и зависимой у величин;
ф0 ( х , 9) - функциональная зависимость, задаваемая в параметрической форме;
N - число пар значений х и у.
В литературе описаны различные операторы Д(0), например, реализующие метод наименьших квадратов [2], либо метод наименьших модулей [3].
При решении практических задач, вследствие сложности организации сбора исходных данных, формирование {х, у} " может встретить серьёзные трудности.
В работе [4] описан подход к построению одномерных непараметрических строгих функциональных зависимостей на основе решения обратной задачи построения закона распределения функции случайного аргумента (прямая задача описана в [5]).
Схема решения обратной задачи имеет вид
-
(2) Д(1): №), F(y')} ^ у = ф 1 (х),
где F(x), F(y) - оценки одномерных законов распределения независимой и зависимой случайных величин соответственно, определяемые на основе обработки выборочных данных
-
(3) Д(2): {х} " ^ х = F(х), Д(2): {у} ^ ^ у = F(y).
Особенностью схемы (2) является то, что свойства выборочных данных {х} " , {у} ^ (объём, точность регистрации) могут быть различными. Ограничением схемы (2) является необходимость обоснования самого факта наличия строгих зависимостей, например, исходя из физического содержания задачи. В работе [5] приведены результаты исследования свойств оценок строгих функциональных зависимостей ^1(х), получаемых посредством (2).
Если объёмы выборочных данных {х} " , {у} ^ являются большими в статистическом смысле, то в качестве Д(2) могут использоваться «традиционные» методы, описанные, например, в [2, 5, 6]. Если же объём выборочных данных мал, а тип закона распределения априорно неизвестен, то в качестве Д(2) целесообразно использовать методы, основанные на принципе максимизации энтропии [7-9]. Построение оценки закона распределения непрерывной случайной величины сводится к определению параметров ^ j выражения
-
(4) f(z = ехр^.^ zj) , j = 1n
в результате решения системы уравнений вида
-
(5) J ^zk ехр(^ ;^ j z^dz = v. ( k) ,
где z - непрерывная случайная величина;
{az , bz } - границы интервала физически возможных значений случайной величины;
v(k^- начальный момент к -го порядка, определяемый по выборочным данным.
При решении практических задач целесообразно ограничиться двумя первыми моментами [4]. Широко используемые на практике нормальный, показательный и равномерный законы распределения случайных величин, являются частным случаем выражения (4).
Экспертные оценки представляются в виде оценки ожидаемого значения случайной величины M[ z] и/или интервала возможных значений случайной величины Z (возможны следующие варианты представления интервалов: ze[az , bz ]; ze[az, ^)) [10].
Если известны лишь границы интервала возможных значений случайной величины, т.е. ze [ az, bz],то
-
(6) Д(3 ) :[ az, b z] ^ F(3)(z).
Здесь Д(3 ) представляет собой частный случай (5), когда k=0. В этом случае оптимальной оценкой F(3)(z) является равномерный закон распределения.
Если известны ожидаемые значения M\ z], а интервал возможных значений случайной величины представляется в виде [az, го), то построение оценки сводится к решению задачи
-
(7) Д (4): {M[z], [ az, го)} ^ F(4)(z).
Здесь Д(4) представляет собой частный случай (5) при k=1. Оптимальной оценкой F(4)(z) в этом случае является показательный закон распределения
-
(8) F(4 ) (z) = 1 — е- Zz .
Параметр закона распределения определяется соотношением Л = (М [z] — a z)-1.
Если известны М [z] и границы интервала [az, bz], то оценка закона распределения ищет- ся в результате решения задачи
-
(9) Д(5): {M(z), [az,bz]} ^ F(5 ) (z).
Оценка представляется в виде
-
(10) F(5 ) (z) = J^e м о +м i T dr,
причём параметры модели ц0, цt находятся в результате решения системы уравнений
J^e м о +м 1 dr = 1
| J^r е м о + м i T dT = M[z].
В частном случае, если дополнительно известно, что F(5 )(az) = 0, F(5 )(_bz) = 1, F(5)(z)
представляет собой треугольное распределение.
Преобразование экспертных оценок к виду законов распределения непрерывных случайных величин делает возможным расширить схему (2) на случай построения одномерных не- параметрических регрессионных зависимостей на основе совместного использования изме- рительных данных и экспертных оценок.
Вместе с тем, методы построения функциональных зависимостей на основе решения обратной задачи построения закона распределения функции случайного аргумента, в том числе на основе совместного использования измерительных данных и экспертных оценок, ориентированы на исследование одномерных зависимостей и не адаптированы к исследованию поведения многомерных систем.
2 Построение многомерных регрессионных зависимостейна основе одномерных непараметрических регрессионных моделей
К числу статических моделей, используемых для описания многомерных безынерционных многосвязных объектов относятся многомерные регрессионные зависимости
-
(12) У / = Ф j(xj ■ 1 ,-Xj к у ) J = 1T/V,
где yj - компоненты вектора Y зависимой переменной;
xj ij , ^' = 1; ^ 7 — компоненты вектора независимой переменной;
Ф5 (•) - зависимость (параметрическая либо непараметрическая) значений j -й компоненты вектора зависимой переменной от значений компонент вектора независимой переменной.
Классический подход к построению многомерных регрессионных зависимостей основан на обработке совместно наблюдаемых значений [5, 6], представленной в табличной форме (см. таблицу 1).
Таблица 1 – Головка таблицы совместно наблюдаемых значений независимой и зависимой переменных
|
Номер измерения |
Независимые переменные |
Зависимая переменная |
|||
|
Xji |
Xj2 |
xJlj |
|||
Многомерные уравнения регрессии ассоциируются с многомерными многосвязными объектами, модель которого представлена на рисунке 1. Построение соотношения вида (12) в
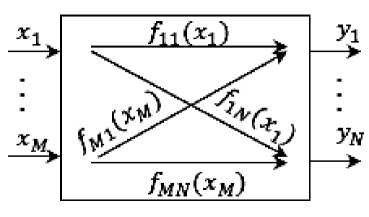
Рисунок 1 – Модель многомерного многосвязного объекта
зависимости от формы представления компонент вектора независимой переменной и зависимой переменной
(измерительные данные, экспертные оценки) сводится к использованию одного из преобразований (6), (8), (10) для построения одномерных законов распределения случайных величин с последующей оценкой непараметрических функциональных зависимостей на основе (2).
Наличие одномерных функциональных зависимостей у j = f t j (X j) позволяет свести формирование таблицы 1 к последовательной реализации следующих шагов.
Шаг 1. Посредством датчиков равномерно распре- деленных случайных чисел хt Е [0,1] методом обратных преобразований [11] генерируются независимые q (q = 1; Q) значения случайных величин fj9), соответствующие оценкам законов распределения F (Xj )
-
(13) $) = F -1 (xjt), i = 1?M .
Шаг 2. По значениям f(9), используя построенные одномерные параметрические зави симости ftj (Xj) рассчитываются значения у j по правилам
-
(14) yf= ^ f t (fj,”) .
Шаг 3. Значения {f (9\ у j (q) } заносятся в виде строки в таблицу 1.
В последующем на основе сформированной таблицы, используя известные методы мно- гомерного регрессионного анализа, строится параметрическая многомерная регрессионная зависимость.
Пример. Допустим, имеется двумерный многосвязный объект. Первому входному пара- метру ставится в соответствие экспертная оценка вида хг Е [0; 8]. Второму входному параметру ставится в соответствие выборка случайных величин, которая может быть аппрокси- мирована нормальным законом распределения М(4,1). Зависимой переменной у 1 ставится в соответствие выборка случайных величин, которая может быть аппроксимирована нормаль- ным законом распределения V(8,2). Зависимой переменной у2 ставится в соответствие экс пертная оценка вида {2, [0, го)}.
Зависимые и независимые переменные связываются соотношениями
pl = f 1 1( X 1 ) +f 21 (X 2 ) ly 2 = f2 2(х2 ) + f12(х1 )
С учётом формы представления экспертной оценки, соответствующей , в качестве F1 (х) используется равномерный закон распределения F(xf) = 1^ 1 dr. С учётом, что F(yT ) описывается нормальным законом распределения, непараметрическая оценка в соответствии с (2) приобретает вид, представленный на рисунке 2.
С учётом формы представления экспертной оценки, соответствующей , в соответствии с (8) в качестве F(y2) используется показательный закон распределения с параметром
X = 0,5. Учитывая, что закон распределения F(%2) является N (4,1), непараметрическая оценка Д 2(%2) в соответствии с (2) приобретает вид, представленный на рисунке 3.
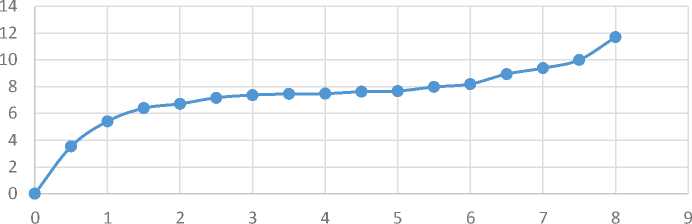
Рисунок 2 - Непараметрическая оценка ^ 1(хх)
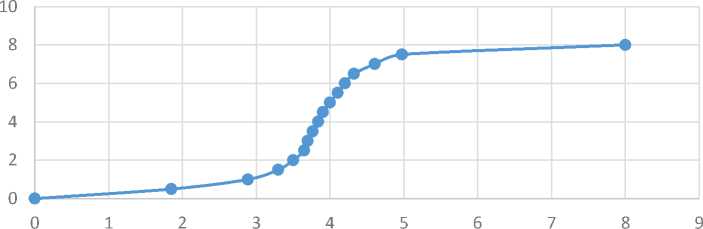
Рисунок 3 - Непараметрическая оценка f2 2(х2)
С учётом того, что закон распределения FC^y) является равномерным, а F(y2) - показательным, использование (2) позволяет получить оценку Д 2(%1), представленную на рисунке 4. Учитывая, что F(y2) имеют одинаковый тип, использование (2) приводит к представлению Д2 1(%2 ) в виде линейной зависимости (рисунок 5).
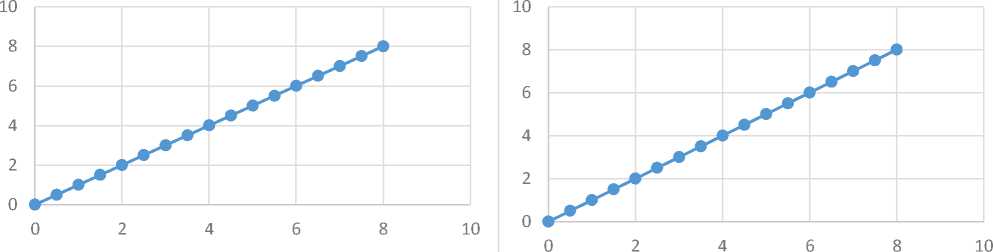
Рисунок 4 - Непараметрическая оценка ^2 (х1) Рисунок 5 - Непараметрическая оценка f2 1(х2 )
Используя описанный трёхшаговый алгоритм, сформированная таблица, содержащая значения независимых x 1 и x 2 и зависимых и переменных. Фрагмент её представлен в таблице 2. При построении таблицы значение Q принималось Q= 1000 .
На основе этой таблицы с использованием пакета Matlab построены двумерные регрессионные зависимости, представленные на рисунках 6 и 7.
Описанный подход может быть перенесён на случай, когда N в соотношении (12) больше двух.
Таблица 2 – Фрагмент таблицы совместно наблюдаемых значений независимых и зависимых переменных
|
Номер измерения |
Xi |
X2 |
У1 |
у2 |
|
1 |
0 |
0 |
0 |
0 |
|
2 |
0,5 |
1,84 |
3,52 |
0,5 |
|
3 |
1 |
2,88 |
5,40 |
1 |
|
4 |
1,5 |
3,29 |
6,38 |
1,5 |
Заключение
Предложен подход к построению многомерных регрессионных зависимостей для случая, когда исходные данные, соответствующие разным компонентам векторов независимой и зависимой переменных, представляются либо в виде результатов измерений, либо в виде разных по форме экспертных оценок. Основу метода составляет преобразование исходных данных, представляемых в разной форме, к виду закона распределения непрерывной случайной величины. Это делает возможным построение совокупности одномерных монотонных на интервале непараметрических регрессионных зависимостей на основе попарного исследования законов распределения независимых и зависимых случайных величин. Полученные регрессионные зависимости служат основой формирования таблицы совместно наблюдаемых значений независимых и зависимых случайных величин, что делает возможным строить многомерные регрессионные зависимости известными методами. Ограничением подхода является, во-первых, необходимость априорного логического обоснования наличия связи между независимыми и зависимыми переменными. Во-вторых, метод ориентирован на построение лишь монотонных на интервале регрессионных зависимостей.
Работа поддержана грантом 19-08-00177 Методологические, теоретические и модельные основы управления функциональной безопасностью аппаратно-программных комплексов в составе распределенных сложных технических систем.
Список литературы Построение модели многосвязного объекта на основе совместного использования данных и экспертных оценок
- Гвоздев, В.Е. Предупреждение дефектов на ранних стадиях проектирования аппаратно-программных комплексов на основе положений теории интерсубъективного управления / В.Е. Гвоздев, Д.В. Блинова, Л.Р. Черняховская // Онтология проектирования. - 2016. - Т. 6, №4(22). - С. 452-464. - DOI: 10.18287/2223-9537-2016-6-4-452-464
- Линник, Ю.В. Метод наименьших квадратов и основы математико-статистической теории обработки наблюдений. - Изд. 2-е, доп. и испр. - М.: Гос. изд-во физ. мат. лит., 1962. - 349 с.
- Мудров, В.И. Метод наименьших модулей / В.И. Мудров, В.Л. Кушко. - М.: Радио и связь, 1983. - 304 с.
- Гузаиров, М.Б. Статистическое исследование территориальных систем: монография / М. Б. Гузаиров и др.- Москва: Машиностроение, 2008.- 187 с.
- Пугачев, В.С. Теория вероятностей и математическая статистика. - М.: Физматлит, 2002.- 496 с.
