Повышение достоверности ответов диалоговой модели с использованием формальных грамматик и теории категорий

Автор: Антонов В.В., Родионова Л.Е., Пальчевский Е.В., Суворова В.А.
Журнал: Онтология проектирования @ontology-of-designing
Рубрика: Методы и технологии принятия решений
Статья в выпуске: 1 (59) т.16, 2026 года.
Бесплатный доступ
Работа посвящена повышению достоверности ответов диалоговой модели для задач, требующих высокой точности. Предложен гибридный подход, сочетающий дообучение модели на специализированных данных с интеграцией формальных грамматик Хомского в процесс обработки запроса. Предложена архитектура, объединяющая формальный синтаксический контроль с генеративными возможностями дообученной модели ГигаЧат 2.0. В процесс обработки запроса включѐн модуль, реализующий предварительный анализ и фильтрацию запросов на основе контекстно-свободных грамматик Хомского. Для согласования работы генеративной модели с выявленной синтаксической структурой предложен двухуровневый механизм контроля. На входе синтаксическиобогащѐнный запрос направляет процесс на структурные паттерны запроса. На выходе модуль проверки осуществляет выбор и коррекцию ответа на основе формальных критериев. Для повышения объяснимости и формального анализа потоков данных использована теория категорий, где запросы, промежуточные представления и ответы моделируются как морфизмы и объекты категории. Для улучшения логической связности и учѐта контекста предложено геометрическое представление семантики в пространстве Минковского, метрика которого позволяет разделять инвариантное значение слова и его контекстуально-временную динамику. Экспериментальная оценка на специализированном наборе из 500 фактологических и структурированных запросов показала, что предложенный метод снижает уровень генерации вымышленных утверждений на 22% по сравнению с базовой моделью ГигаЧат 2.0. Показано, что совместное использование формальных грамматик, категориального формализма и геометрической модели семантики позволяет повысить достоверность ответов в предметно-ориентированных диалогах.
Достоверность ответов, диалоговая модель, трансформер, формальные грамматики Хомского, теория категорий, пространство Минковского, семантическое пространство
Короткий адрес: https://sciup.org/170211640
IDR: 170211640 | УДК: 004.6 | DOI: 10.18287/2223-9537-2026-16-1-125-138
Enhancing the reliability of dialogue model responses using formal grammars and category theory
This study is devoted to enhancing the reliability of dialog model responses in tasks requiring high accuracy. A hybrid approach is proposed that combines fine-tuning the model on domain-specific data with the integration of Chomsky formal grammars into the query processing pipeline. An architecture is introduced that unifies formal syntactic control with the generative capabilities of the fine-tuned GigaChat 2.0 model. The query processing workflow incorporates a module for preliminary analysis and filtering of user queries based on Chomsky context-free grammars. To align the operation of the generative model with the identified syntactic structure, a two-level control mechanism is proposed. At the input stage, a syntactically enriched query guides the generation process toward appropriate structural query patterns. At the output stage, the verification module performs selection and correction of the generated response based on formal criteria. To enhance explainability and enable formal analysis of data flows, category theory is employed, in which queries, intermediate representations, and responses are modeled as objects and morphisms of a category. To improve logical coherence and contextual awareness, a geometric representation of semantics in Minkowski space is proposed, whose metric makes it possible to separate the invariant meaning of a word from its contextual and temporal dynamics. Experimental evaluation on a specialized set of 500 factual and structured queries demonstrates that the proposed method reduces the generation of fabricated statements by 22% compared to the baseline GigaChat 2.0 model. The results show that the combined use of formal grammars, categorical formalism, and a geometric model of semantics enhances the reliability of responses in domain-specific dialogues.
Текст научной статьи Повышение достоверности ответов диалоговой модели с использованием формальных грамматик и теории категорий
Современный этап развития науки о данных характеризуется прогрессом в области обработки естественного языка (ЕЯ), ключевым элементом которого стали большие языковые модели (БЯМ) на основе трансформеров , , и др.) [1]. Российская модель ГигаЧат 2.0 оптимизирова- на для работы с русскоязычным контентом и предоставляет возможности для её дообучения, что обусловило её выбор в качестве базовой.
Основой развития трансформеров стало применение механизмов внимания, позволивших учитывать зависимости между словами и конструкциями текста. Благодаря этому удалось обеспечить «понимание» контекста и повысить точность моделей при выполнении сложных задач обработки ЕЯ. Примером является Funnеl-Тrаnsfоrмеr [2], который показал превосходство над другими моделями в ряде задач, требующих анализа семантики текста. Особенностью данной модели является способность вначале сформировать обобщённое высокоуровневое представление контекста, а затем, при детальном анализе, извлекать необходимые подробности из первичного представления.
Распространение получили подходы, основанные на предобучении БЯМ, такие как ВЕRТ, GPT и др. Модели обучаются на больших объёмах неразмеченных данных, усваивая общие закономерности языка, и затем применяются для решения специфических задач. Это позволяет многократно использовать знания, заложенные в предобученных моделях, для адаптации их к прикладным задачам. Недостатком современных БЯМ является склонность к «галлюцинациям» – генерации правдоподобной, но фактически неверной (вымышленной) информации [1, 3]. В образовательных, экспертных и прикладных сценариях цена ошибки высока. Известные подходы к устранению проблемы требуют огромных затрат на разметку и не гарантируют достижения цели [4].
Методы повышения достоверности БЯМ можно разделить на классы с разным балансом между точностью, контролируемостью и вычислительной эффективностью.
-
■ Тонкая настройка с использованием обучения с подкреплением на основе человеческих оценок ( RLHF) -стандартный подход для моделей типа ГигаЧат [2, 4, 5].
-
■ Генерация, дополненная поиском ( RAG ) - подход, при котором модели дополняют процесс генерации текста поиском информации во внешних базах знаний [5].
-
■ Нейро-символьные гибриды - интеграция нейросетей с формальными системами [6, 7].
-
■ Геометрические модели семантики - использование неевклидовых пространств (гиперболических, сферических) для представления иерархий и аналогий [8].
-
■ Применение теории категорий в машинном обучении - категориальный подход используется для формализации архитектур, например, с применением математического аппарата к сложным структурам в [8].
Для диалоговых систем, основанных на БЯМ, необходимо обеспечить предсказуемость, контролируемость и достоверность генеративных компонент в условиях открытых предметных областей. Подходы к проектированию систем обработки ЕЯ, основанные на обучении на данных, не обеспечивают необходимый уровень формальной гарантии корректности. Существует потребность в методологиях проектирования, сочетающих гибкость нейросетевых моделей с детерминизмом формальных методов.
Настоящая работа направлена на разработку гибридного метода, который дополняет возможности генеративной трансформер-архитектуры (ГигаЧат 2.0) формальными механизмами контроля. В качестве таких механизмов предлагается использовать:
-
■ формальные грамматики Хомского для синтаксического анализа и фильтрации входных запросов и выходных ответов;
-
■ аппарат теории категорий для формализации процесса обработки данных и анализа потоков информации;
-
■ геометрическую модель семантики на основе пространства Минковского для улучшения учёта контекста и логической связности.
1 Теоретические основы архитектуры трансформеров
Трансформеры представляют собой архитектурный паттерн для нейронных сетей, основанный на механизме самовнимания [9].
-
1.1 Общие положения
Базовый механизм внимания представляет собой следующее: для входной последовательности в виде матрицы векторные представления (слов, предложений, изображений и др.) X вычисляются три матрицы: запросов Q = X * WQ , ключей K = X * WK и значений V = X * WV , где Wq , WK и WV - обучаемые матрицы параметров (весов) , выполняющие роль линейных проекций . Веса внимания рассчитываются по формуле (1) скалярного произведения с последующим применением функции Softmax [9]:
Attention ( Q, K, V ) = V • Soft max( QK— ),
где dk - размерность ключей, W_Q, W_K и W_V - обучаемые матрицы параметров (весов), выполняющие роль линейных проекций; масштабирующий множитель 1 стабилизирует градиенты.
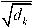
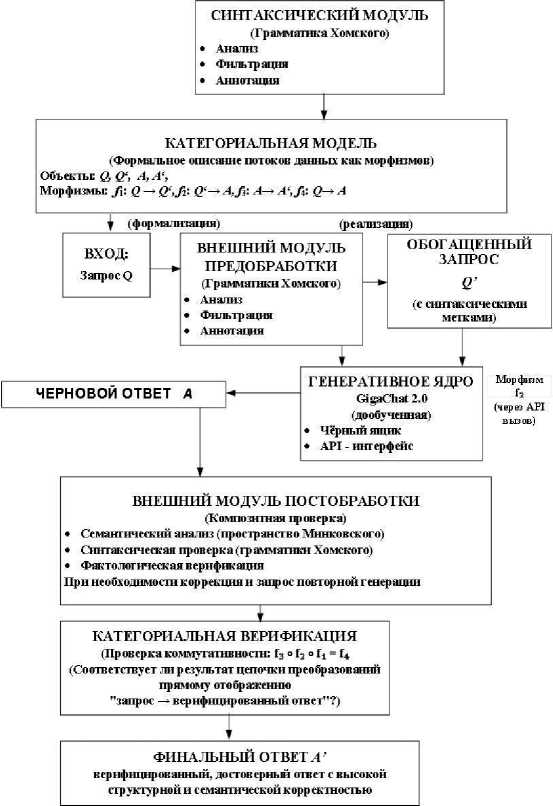
Рисунок 1 – Схема архитектуры гибридной системы с внешним контролем
Архитектура трансформера включает эн-кодер и декодер. Для задач генерации текста, включая диалоговые системы, наибольшее распространение получили авторегрессионные модели на основе декодера (например, семейство GPT [5]).
Такие модели, предобученные на корпусах текстов, научились генерировать связные, грамматически правильные и контекстуально уместные ответы. Категориальная модель системы с внешним контролем (см. рисунок 1) оперирует четырьмя ключевыми объектами: Q (исходный запрос), Q' (запрос, обогащённый синтаксическими аннотациями), A (черновой ответ генеративной модели) и A' (финальный верифицированный ответ).
Модуль постобработки представлен в модели морфизмом f s : A ^ A' . Такой подход позволяет сохранить наглядность категориального описания, фокусируясь только на входных и выходных состояниях системы.
Funnel-Transformer можно представить в виде двух частей: первая из них начинается с большого количества узлов, которое постепенно уменьшается, достигая самой узкой точки, после чего последующие слои вновь увеличивают количество узлов (см. рисунок 2): сначала происходит глобальное сжатие информации, затем добавляется локальная детализация. Эта архитектура обеспечивает баланс между скоростью обработки и точностью результата.
Для моделирования процесса предобработки данных применяется аппарат теории категорий [10, 11]. В данном подходе теория категорий служит для формального описания преобразований между различными представ- лениями данных, где основное внимание уде ляется морфизмам. В контексте обработки данных трансформером процесс перехода от исходных данных к подготовленным объектам формализуется через категорию C, объектами которой являются:
-
■ Ki - входные компоненты (слова, фразы, предложения);
-
■ K 2 - правила формальных грамматик Хомского;
-
■ K 3 - результаты предобработки.
Преобразования между этими объектами задаются морфизмами:
-
■ fi: Ki ^ K2 - применение грамматических правил к входным данным;
■ /г: Кг ^ Кз — преобразование синтаксических структур в векторные представления;
■ /з = /г ° fi-' Ki ^ Кз — композиция преобразований морфизмов, удовлетворяющих условию коммутативно сти.
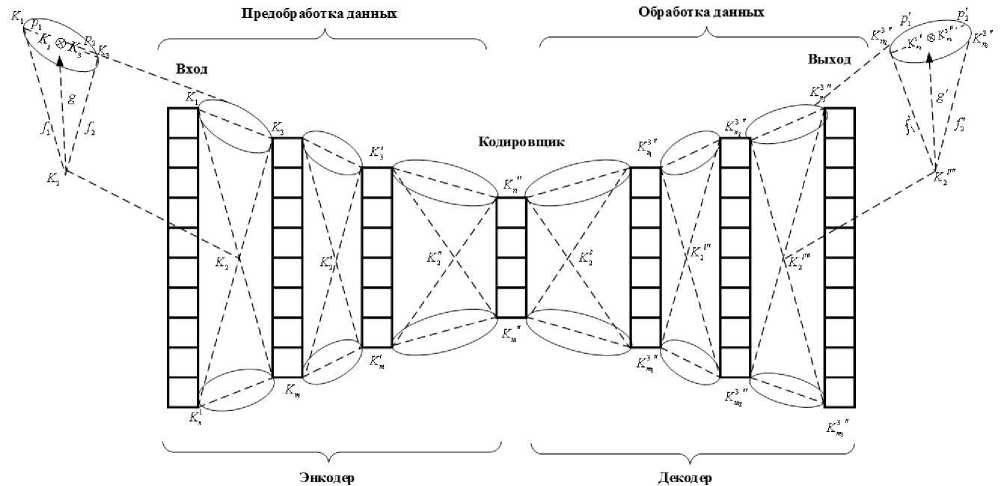
Рисунок 2 - Структура модели Funnel-TransforMer
Данный процесс может быть представлен последовательностью коммутативных диаграмм, приведённых на рисунке 2. Процесс предобработки может быть описан через декартово произведение Ki * Кг, представляющее все возможные пары «входной компонент - грамматическое правило». Морфизм g: Ki * Кг ^ Кз, являющийся результатом процесса предобработки, обеспечивает переход к конечному представлению данных. Такой формализм позволяет:
-
■ единообразно описывать этапы обработки данных;
-
■ анализировать свойства композиции преобразований;
-
■ выявлять инварианты архитектуры обработки.
В итоге переходы от одной диаграммы к следующей можно выражать через новую категорию C, включающую множество объектов O ={ К 1 , К2, К 3}. Множество взаимодействий между этими категориями, внутри которых расположены информационные объекты, представимо коммутативным треугольником по категории и отдельным подкатегориям.
Категория К2 образует класс объектов с заданным отношением для любых пар ( К2, К 1 ) и ( К2, К 3 ), отношения которых определены множеством морфизмов (связи между элементами объектов ): {/ 1 , f2, p 1 , p2} . Процессы предобработки данных по правилам К 2 рассматриваются как взаимосвязанные процессы между входными компонентами К 1 и результатом предобработки данных К 3 . Объект, являющийся результатом такого взаимодействия, представляется декартовым произведением g-К 2 ^ К 1 ® К 3 , где ® - декартово произведение, g - единственный морфизм, связывающий результаты с процессом предобработки данных.
Процесс предобработки данных первого слоя нейронной сети соответствует отношениям, формализованным в виде морфизмов. Данные отношения обладают свойствами: результат взаимодействия информационных объектов может быть представлен декартовым произведением к 1 ® К 3 с морфизмами p 1 -К 1 ® К 3 ^ К 1 и p 2 :К J ® К 1 ^ К з такими, что для любого объекта К2 с морфизмами / 1 : К 2 ^ К 1 и f , ■ К2 ^ К 3 существует единственный морфизм g:K 2 ^ К 1 ® К3 , при котором выделяется диаграмма в форме коммутативного треугольника.
Таким образом, обработка запроса формализована в терминах теории категорий, где объекты - ключевые представления данных в системе, морфизмы - преобразования между объектами, коммутативные диаграммы позволяют наглядно отследить соответствие между альтернативными путями обработки.
-
1.2 Физико-математический подход к обработке текстов
Физико-математический подход основывается на введении геометрических характеристик для анализа текстовых данных. Одним из центральных понятий здесь является про- странство Минковского, где каждое слово или предложение представлено точкой в четырёхмерном пространстве.
Использование пространственно-временной размерности Минковского позволяет выстраивать пространственную конфигурацию, в которой каждая точка представляет собой событие, связанное с определённым входным компонентом (или результатом его предобработки). Такой подход обеспечивает построение набора данных на основе описания категориальных связей. Выстраивание пространственной конфигурации по Минковскому позволяет получить параллельное соотношение всех модулей и правил с использованием результатов предобработки в любой момент времени в виде набора данных, а выстраивание отношений с другими конусами позволяет определить новые правила, которые необходимы для предобработки следующих входных компонентов [12]. В таком пространстве каждому событию можно сопоставить точку, пространственные координаты которой описывают место, где событие произошло, а временная координата - временный компонент, когда оно случилось:
K1 = {C1, C2, C3,...,Cn} — входные компоненты, представляющие множество вариантов запросов (текст, картинки, звуки, чертежи, алфавит и т.п.);
K2 = { р , P2, P3,...,P l } - множество правил по формальным грамматикам Хомского;
K 3 = { R 1 , R 2, R 3,..., R m } - множество вариантов ответов.
Здесь n, l, m - мощности соответствующих множеств.
При анализе моделей обработки ЕЯ целесообразно классифицировать их по классам задач (классификация текста, анализ семантического сходства, машинный перевод, обработка разговорного языка) для решения которых они предназначены [13, 14].
Обучение представлений подразумевает извлечение и преобразование дискретных или сложных объектов, например, слов, предложений, изображений, в числовые векторные представления фиксированной размерности, которые могут быть перенастроены под различные задачи. Это свидетельствует о том, что модель может адаптироваться к требованиям конкретной предметной области. В результате снижается потребность в обширных размеченных данных для каждой задачи, поскольку базовые репрезентации уже содержат ключевые аспекты языка и его использования. Модели становятся более универсальными, способными решать сложные задачи с высокой степенью точности, опираясь на предшествующий опыт.
-
1.3 Семиотические аспекты обработки текста
ЕЯ задачи могут быть представлены семиотической системой связи [15, 16], которая представляет собой совокупность элементов, позволяющих передавать и интерпретировать информацию посредством символов, изображений, звуков, жестов и других знаковых форматов. В семиотических системах представлен обширный контекст, и результаты запросов могут быть разными, но сохранять основной смысл. При обратном запросе оригинальный текст не получится [17].
Семантическое пространство представляется формулой S =( W, V) , где: S - семантическое пространство, W - словарь, V - векторное пространство, в котором каждому слову сопоставляется вектор, отражающий его смысловые характеристики. Каждое слово w представляется точкой в пространстве Минковского с координатами ( x , y , z , t ), где: x , y , z - пространственные координаты, зависящие от семантического смысла слова, t - временная координата, отражающая эпоху или контекст использования слова [12]. Пространство Минковского представляет собой четырёхмерное псевдоевклидово пространство-время, где метрика задаётся как: ds 2 = dt 2 - dx 2 - dy 2 - dz 2 , где dx , dy , dz - разности пространственных координат (семантических измерений), dt - разность временной координаты (временного аспекта).
В контексте семантического пространства координаты x , y , z представляют семантическую близость слов (например, синонимия, родственные отношения, тематическая принадлежность) и зависят от семантических признаков. Чем ближе точки, тем более близкими по смыслу считаются слова, координата t отражает исторический контекст или временной период, в течение которого слово употреблялось или приобрело популярность. Большое значение t может означать, что слово старое или давно вышло из активного употребления.
Пусть имеется два слова w 1 и w2 с координатами: w 1 =(x 1 ,y 1 ,z 1 ,t 1 ) и w 2 =(x 2 ,y 2 ,z 2 ,t 2 ) . Интервал между ними составит: ds2(w 1 ,w 2 )=(x 2 -x 1 )2+(y 2 -y 1 )2+(z 2 -z 1 )2-(t 2 -t 1 )2 . Пространственные координаты кодируют инвариантные семантические признаки слова, временная координата является мерой его контекстуальной, диахронической или прагматической модификации. Особенностью метрики является её способность различать два типа семантических отношений:
-
■ Смысловая близость (положительный ds 2) достигается, когда совпадение по инвариантным семантическим признакам (x 2 -x 1 )2+(y 2 -y 1 )2+(z 2 -z 1 )2 перевешивает контекстуально -временной разрыв (t 2 -t 1 )2 . Это соответствует случаю, когда слова являются синонимами или принадлежат одному семантическому полю.
-
■ Смысловой разрыв или сдвиг (отрицательный ds 2) возникает, когда различия в контексте,
эпохе или прагматике использования (t 2 -t 1 )2 становятся настолько значимыми, что преобладают над формальной семантической схожестью.
Метрика Минковского расширяет модель семантического пространства, вводя в него конфликтующее измерение. Это позволяет более адекватно отражать сложность и нелинейность семантических связей в ЕЯ.
Пусть дано семантическое пространство S , представленное как векторное пространство над полем вещественных чисел. Вводится метрика, аналогичная метрике Минковского, и применяется к векторам слов. Тогда расстояние между двумя словами w 1 и w 2 определяется следующим образом [9]:
-
2 т -1 т
d(wi, w2) = Wwi A tw2w2 - sw 1 Bsw2 , где tw - представляет временную компоненту слова w, Sw - пространственный компонент (семантический вектор), A и B - положительно определённые матрицы, характеризующие влияние временной и пространственной компонент соответственно.
На рисунке 3 представлена структура объектов с правилами поиска и запроса для конкретного языка. Ответ осуществляется на языке запроса с возможностью перевода по лингвистическим правилам на другой язык [6, 18].
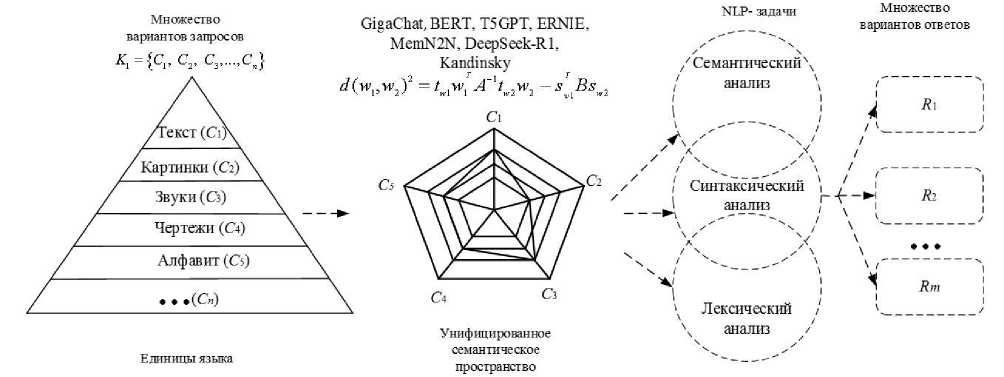
Рисунок 3 - Единое семантическое пространство для различных языковых структур
Исходный текст подаётся модели на начальном этапе обработки и преобразуется моделью в числовое представление в виде набора векторов, удобных для последующей обработки. Применяя ранее полученные знания с помощью механизма внимания, модель изменяет структуру полученного вектора таким образом, чтобы он соответствовал структуре текста на требуемом языке перевода. Итоговый вектор подвергается обратному преобразованию в читаемый текст на целевом языке. Модель выводит готовый перевод на целевом языке.
Формальные грамматики обеспечивают основу для анализа и генерации предложений, разбивая их на составляющие элементы и определяя правила их сочетания [19]. Грамматики Хомского могут применяться в контексте современных языковых моделей на основе трансформеров. Единицы языка состоят из компонентов: G = { N , T , P , S } , где: N - алфавит конкретных символов, формирующий конечный алфавит нетерминальных символов; T – конечный алфавит терминальных символов (совпадает с алфавитом языка, задаваемого грамматикой); P – правила вывода, морфология; S – начальный нетерминал грамматики G .
Грамматики Хомского могут оказать существенную поддержку в снижении генерации недостоверных сведений.
-
1.4 Модели трансформеров
Модели, такие как BERT , используют только компонент энкодера. Это позволяет им эффективно выполнять задачи, такие как текстовая классификация, распознавание именованных сущностей и ответы на вопросы [20] .
Модели типа GPT функционируют на основе декодера, что позволяет им успешно справляться с задачами, связанными с продолжением текста, ведением диалогов и оценкой вероятности текстов.
Таким образом, BERT ориентирован на анализ и классификацию, GPT специализируется на генерации текста и взаимодействии [21, 22].
Недостатки известных моделей: неустойчивость (потеря качества при изменении данных); предвзятость (модель даёт ответы, не соответствующие этике); нестабильность вывода (получение разных результатов запроса).
2 Особенности и результаты тестирования диалоговой модели
Для создания диалоговой модели использована БЯМ ГигаЧат 2.0, предназначенная для работы с ЕЯ. Модель основана на архитектуре трансформеров, схожей с семейством GРТ , и способна решать широкий спектр задач [20].
Для работы с различной длиной входных данных и сохранения контекста в продолжительных диалогах применяется механизм направленного внимания, реализованный через синтаксически-обогащённый запрос. Модель включает внешние модули проверки достоверности, взаимодействующие с дополнительными источниками данных для верификации фактов. Механизм внимания предлагается использовать на этапе предобработке данных [23]. Это упрощает и ускоряет обработку, но появляется риск потери деталей и возможного ухудшения качества на коротких текстах. Важно внимательно подбирать архитектуру и настраивать гиперпараметры для оптимального баланса между скоростью и точностью обработки.
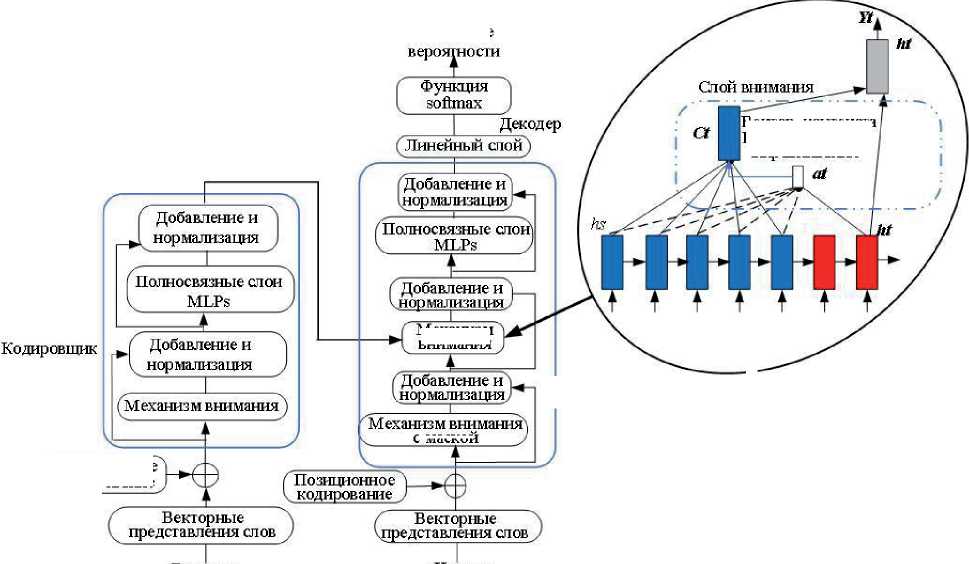
Построение компактного представления текста осуществляется через каскад блоков компрессии, которые уменьшают длину последовательности, при сохранении существенных признаков. Это может быть достигнуто введением функции компрессии L(x) (см. рисунок 4). На каждом временном шаге t глобальная модель внимания вычисляет вектор веса выравнивания переменной длины at на основе текущего состояния цели ht и всех состояний источ- ника hs [24]. Глобальный вектор контекста Ct вычисляется как средневзвешенное значение, согласно at по всем состояниям источника. Цель - получить вектор контекста на основе всех скрытых состояний кодирующей рекуррентной нейронной сети. Этот тип внимания охваты вает всё пространство входных состояний [25, 26].
Выходные
Позиционное кодирование
с маскон
Целевая послед ов ат ельностъ
Входная последовательность
Рисунок 4 - Структура языковой модели с архитектурой трансформера
Вектор контекста Глобальные веса выравнивания
Механизм внимания
Алгоритм работы БЯМ включает: сбор данных; предобработку данных; работу диалоговой модели, имеющей архитектуру трансформера.
В ходе тестирования проверялись ключевые характеристики модели: качество генерации текста и правильность понимания вопросов; временные показатели откликов на запросы; надёжность предоставляемой информации.
Дообучение проведено на специализированном наборе данных объёмом около 15 000 пар «вопрос-ответ» из образовательной сферы (учебники по гуманитарным наукам, сборники задач). Для процесса дообучения модели использовался оптимизатор AdamW [27]. Для интеграции грамматических правил в процесс генерации использован механизм синтаксически-обусловленного внимания, который на этапе предобработки формирует синтаксические признаки размерностью 128 и использует их для направления фокуса модели на структурно корректные паттерны. Достоверность ответов определялась сочетанием трёх показателей: фактологическая точность - соответствие утверждений в ответе проверяемым фактам из авторитетных источников; логическая связность - отсутствие противоречий в ответе, соблюдение причинно-следственных связей и правил логики; синтаксическая и семантическая корректность - грамматическая правильность предложений и соответствие смысла запросу.
В качестве тестового использовался набор данный из 500 запросов трёх категорий: фактологические (200) - вопросы с однозначным проверяемым ответом; структурирован-ные/логические (200) - математические задачи, задачи на логику, запросы на построение алгоритма; провоцирующие (100) - запросы, содержащие противоречия или отсылающие к несуществующим фактам (для оценки склонности к галлюцинациям).
Для оценки использовались следующие метрики: доля фактологически верных утверждений в ответе, доля вымышленных или неподтверждённых утверждений в ответе, оценка логической связности и последовательности ответа, среднее время генерации ответа. Результаты приведены в таблице 1.
Таблица 1 – Результаты экспериментального сравнения
|
Модель |
Доля фактологически верных утверждений в ответе |
Доля вымышленных или неподтвержденных утверждений в ответе |
Оценка логической связности и последовательности ответа |
Среднее время генерации ответа |
|
Baseline (ГигаЧат 2.0) |
78.5% |
18.2% |
3.8 |
0.45 |
|
Предложенная модель |
91.3% |
7.1% |
4.4 |
0.68 |
Полученные результаты позволяют сопоставить предлагаемую модель с другими подходами (см. таблица 2).
Таблица 2 –Качественное сопоставление подходов к обеспечению достоверности языковых моделей
|
Критерий / Метод |
RLHF [4, 5] |
RAG [5] |
Нейро-символьные гибриды [6, 7] |
Предлагаемый гибридный метод |
|
Основной механизм |
Смещение выхода через предпочтения |
Поиск по внешним БЗ |
Интеграция нейросетей с ло-гич. правилами |
Тройная интеграция: грамматики + категории + геом. модель |
|
Фактологическая точность |
Косвенно, через обратную связь |
Высокая (за счёт БЗ) |
Зависит от системы правил |
Высокая (контроль на входе/выходе + RAG-верификация) |
|
Синтаксический/ структурный контроль |
Отсутствует |
Отсутствует |
Частичный (зависит от грамматик) |
Высокий (формальные грамматики Хомского) |
|
Объяснимость |
Низкая («чёрный ящик») |
Средняя (можно указать источник) |
Высокая (логический вывод) |
Высокая (категориальная модель потоков) |
|
Учёт контекста/связность |
Высокий (за счёт обучения) |
Ограничен контекстом запроса |
Жёсткий (правила) |
Высокий (геом. модель Минковского + генеративная БЯМ) |
|
Вычислительная сложность |
Очень высокая (обучение с подкр.) |
Высокая (поиск + генерация) |
Средняя-высокая |
Средняя (увеличение ~50% к baseline, см. таблица 1) |
|
Ключевое ограничение |
Затраты на разметку, галлюцинации |
Качество БЗ, связность текста |
Жёсткость, сложность интеграции |
Время отклика, творческие задачи |
В отличие от RLHF и RAG предлагаемый метод обеспечивает системное преимущество в задачах, требующих одновременно высокой структурной корректности, фактологической точности и объяснимости. По вычислительной сложности метод занимает промежуточное положение: он легче масштабируемого сбора человеческих предпочтений ( RLHF ), но требует больше ресурсов, чем RAG . Таким образом, метод заполняет нишу проектирования контролируемых и верифицируемых диалоговых систем для предметно-ориентированных областей, где цена ошибки высока, а требования к корректности преобладают над требованиями к минимальной задержке.
Добавление модуля на основе грамматик Хомского даёт значительный прирост точности и снижает уровень галлюцинаций. Это подтверждает гипотезу о важности синтаксической фильтрации. Улучшение качества сопровождается увеличением времени ответа (на ~50% с 0.45 до 0.68 с).
Эффективность предложенного подхода снижается в следующих условиях.
-
■ При работе с творческими задачами (написание эссе, генерация художественных текстов), где строгий синтаксический контроль может ограничивать творчество.
-
■ В условиях неопределённых или противоречивых запросов, когда грамматический анализ не позволяет однозначно классифицировать намерение пользователя.
-
■ При обработке специализированной терминологии, не охваченной правилами грамматик Хомского.
-
■ В сценариях реального времени с жёсткими требованиями к задержке, поскольку дополнительный модуль предобработки увеличивает время отклика на 15-20%.
Наибольшая эффективность достигается при работе со структурированными запросами: решение математических задач, проверка грамматики, фактологический поиск, технические консультации.
Заключение
Основными результатами работы являются следующие:
-
■ разработана гибридная архитектура диалоговой модели на основе ГигаЧат 2.0 и интегрирующая формальные грамматики Хомского для синтаксического контроля на входе и выходе;
-
■ предложено формальное описание работы диалоговой модели на языке теории категорий, что упрощает анализ потоков данных;
-
■ осуществлено моделирование семантики в пространстве Минковского для отделения инвариантного значения языковых единиц от их контекстуально-временной динамики, что улучшает логическую связность ответов;
-
■ предложенный гибридный метод может снижать уровень галлюцинаций и повышать фактологическую точность и логическую связность ответов.
