Применение больших языковых моделей для анализа вредоносности характера текста

Автор: Алиев К. К. О., Козин Г. А., Мишкин А. Д.
Журнал: Международный журнал гуманитарных и естественных наук @intjournal
Рубрика: Технические науки
Статья в выпуске: 6-1 (105), 2025 года.
Бесплатный доступ
Большие языковые модели в настоящее время достигли высоких результатов в широком спектре задач обработки естественного языка, продемонстрировав высокую эффективность при нулевом и ограниченном количестве примеров. Такие задачи, как анализ тональности и распознавание именованных сущностей, особенно выиграли от этих достижений, подчеркнув потенциал моделей в выполнении задач без обширных наборов данных, специфичных для конкретных сфер. В настоящее время исследовали нацелились на применение больших языковых моделей в текстовой модерации, которая играет важную роль в управлении пользовательским контентом в различных форматах, включая выявление вредоносного и токсичного текста в социальных сетях, сообщениях в онлайн-чатах, обсуждениях на форумах, комментарих на веб-сайтах и т.д. В статье рассмотрены особенности использования различных больших языковых моделей для выявления вредоносного текста и представлены результаты их сравнения как с моделями из одной группы, так и с другими подходами обнаружения враждебного контента.
Токсичный текст, языковая модель, контекст, данные
Короткий адрес: https://sciup.org/170210611
IDR: 170210611 | DOI: 10.24412/2500-1000-2025-6-1-265-270
Application of large language models for analysing the malicious nature of text
Large language models have now achieved impressive results across a wide range of natural language processing tasks, demonstrating high performance with zero or limited training data. Tasks such as sentiment analysis and named entity recognition have particularly benefited from these advances, highlighting the potential of models to perform tasks without extensive task-specific data sets. Currently, research has focused on the application of large language models in text moderation, which plays an important role in managing user content in various formats, including the detection of malicious and toxic text in social media, online chat messages, forum discussions, website comments, etc. This article examines the features of using various large language models to detect harmful text and presents the results of their comparison with both similar models and other approaches to detecting hostile content.
Текст научной статьи Применение больших языковых моделей для анализа вредоносности характера текста
Существующие традиционные детекторы вредоносного текста, которые опираются на информационные фильтры, встроенные в сервер, а также встроенные алгоритмы или черные списки, несовершенны и допускают ошибки. В реальных приложениях токсичные примеры встречаются редко, и большинство подсказок являются безобидными, поэтому тестовые данные демонстрируют высокий дисбаланс классов: даже небольшой показатель ложных срабатываний (FPR) может вызвать много ложных тревог в этом сценарии [3]. Также следует отметить, что обычные методы модерации контента и детекторы ток- сичности не способны достичь высоких показателей истинных срабатываний (TPR) и очень низких показателей FPR. Они испытывают трудности с некоторыми входными данными. Кроме того, использование традиционных детекторов также связано со значительными дополнительными расходами [4].
Для решения вышеуказанных задач в последнее время особую популярность приобрели большие языковые модели (LLM), благодаря их высокой производительности при обучении без примеров и с небольшим количеством примеров в контексте. Современные работы, описывающие LLM для обнаружения токсичного контента, сосредоточены на разработке новых подходов к подсказкам и обучению моделей для повышения их производительности. Поэтому данная проблематика имеет высокую научно-практическую значимость, что и предопределило выбор темы данной статьи.
Над формализацией характеристик вредоносного текста, которые имеют значение для разработки тестов, трудятся Браницкий А.А., Тушканова О.Н., Огольцова Н.Д., Литвинова Т.А., Alexandru Capatina, Adrian Micu, Angela-Eliza Micu, Samuel Ribeiro-Navarrete.
Возможности текущих моделей LLM, в фазу обучения которых включено выравнивание безопасности, в результате чего они, как правило, настроены на отказ отвечать на токсичные запросы, описывают Замолоцких В.С., Сидоренко В.Г., Самарин Н.Н., Белоножко П.Е., Белов Ю.С., Suhaima Jamal, Hayden Wimmer, Iqbal H. Sarker.
Подходы к обучению LLM, позволяющие им классифицировать тексты как нейтральные, вредные или токсичные, разрабатывают Куртукова А.В., Романов А.С., Шелупа-нов А.А., Ruohan Tang, Joonho Moon, Gyeong Ryun Heo.
Несмотря на то, что сегодня широкий круг исследователей и экспертов занимается рассматриваемой проблематикой, еще ряд сложных вопросов не нашли своего должного отражения в литературе и требуют более детальной проработки. Так, например, в более действенных механизмах противодействия нуждаются лазейки, которые могут быть использованы пользователями со злым умыслом, что подрывает эффективность моделей и схем распознавания вредоносного текста.
Кроме того, в уточнении и дальнейшем развитии нуждаются методы разработки новых подходов к подсказкам для повышения производительности LLM при выявлении токсичного контента.
Таким образом, цель выполненного исследования заключается в рассмотрении особенностей применения больших языковых моделей для анализа вредоносности характера текста.
Результаты исследования. Существующие на сегодняшний день методы по обнаружению токсичного контента можно разделить на два типа: классические методы машинного обучения, включая традиционные и глубокие модели обучения и большие языковые модели.
Традиционные модели машинного обучения (например, Support Vector Machine (SVM), Random Forest, Naive Bayes, Logistic Regression (LR) основаны на ручной инженерии признаков и не способны улавливать контекстуальные особенности токсичных комментариев. Однако, несмотря на рост популярности моделей глубокого обучения, традиционные модели не исчезли. Несколько исследований показывают, что LR работает лучше в условиях ограниченных ресурсов, в то время как мощность глубокого обучения может быть полностью раскрыта только при наличии достаточного количества аннотированных обучающих данных [5]. Кроме того, традиционные методы, основанные на признаках, в некоторой степени сохраняют интерпретируемость модели, чего не можно сказать о большинстве моделей глубокого обучения.
Что касается моделей глубокого обучения, то RNN, длинная кратковременная память (LSTM) и гейтированная рекуррентная единица (GRU), на сегодняшний день являются популярными вариантами обнаружения вредоносного текста благодаря своей способности преодолевать проблему взрывного роста градиента и исчезновения. Bi-LSTM и BiGRU также известны своим потенциалом для захвата обратных и прямых контекстуальных особенностей [6].
Защитные механизмы LLM позволяют выявлять токсичный контент в основном с помощью комбинации классификаторов машинного обучения и систем на основе правил. Эти системы анализируют как ввод пользователей, так и вывод модели, чтобы обнаружить вредный контент, такой как язык ненависти, домогательства или откровенные материалы. Защитные механизмы действуют как фильтр, перехватывая запросы или ответы, которые нарушают заранее определенные правила безопасности. Например, если пользователь просит LLM сгенерировать уничижительный комментарий о конкретной группе, защитный механизм может полностью заблокировать запрос или переписать результат, удалив токсичный язык. Этот процесс гарантирует, что модель соответствует этическим принципам, сохраняя при этом удобство использования [7].
Механизмы обнаружения в значительной степени полагаются на обученные классификаторы, часто построенные с использованием таких моделей, как BERT или RoBERTa, и настроенные на основе помеченных наборов данных, например, Jigsaw’s Toxic Comments.
На рисунке 1 на основе открытых данных систематизированы результаты сравнения различных подходов и моделей к обнаружению вредоносного текста.
1 0,9 0,8 0,7 0,6 0,5 0,4 0,3 0,2 0,1
о
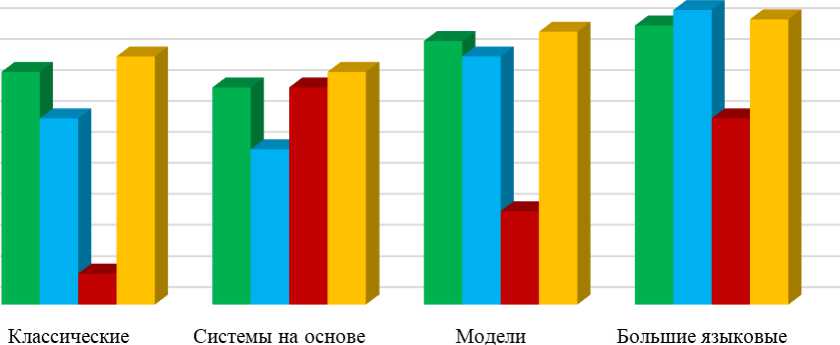
методы машинного обучения (TF-IDF + опорные векторы, логрегрессия)
трансформерной архитектуры (дообученные модели типа BERT, RoBERTa, Т5)
правил (лексиконы, шаблоны, регулярные выражения)
модели общего назначения (GPT-3.5,GPT-4, РаЕМи
ДР-)
■ Точность ■ Гибкость ■ Независимость от обегающих данных Низкий уровень пропуска вредоносности
Рис. 1. Сравнение различных подходов к анализу вредоносности текста
Теперь рассмотрим более подробно механизм обнаружения вредоносного текста с использованием LLM.
Для создания надежной модели LLM, которая позволит более точно выявлять вредный текст эксперты рекомендуют проводить проактивную оценку как входных, так и выходных данных на каждом этапе разработки, что по сути является многоэтапным подходом [8]:
-
1. Курация набора данных для обучения, часть которой включает поиск и удаление токсичных или дискриминационных данных из текста.
-
2. Проверка входных данных во время интерпретации.
-
3. Проверка ответов модели в процессе выявления и классификации текста.
-
4. Усиленное обучение на основе обратной связи от человека (RLHF) с использованием наборов данных о предпочтениях ответов.
-
5. Внутреннее тестирование методом «красной команды» с помощью скоординированных и целенаправленных входных данных для выявления вредных результатов, с целью обнаружения и оценки слабых мест в модели.
Набор данных для обучения и формулировка наиболее релевантных подсказок для модели имеет решающее значение. При разработке подсказок для LLM возникают две проблемы:
-
1) установление того, является ли ответ LLM достоверным;
-
2) определение, какой тип более детального контекста следует выбрать для повторного запроса LLM.
Для решения первой проблемы разработан инструмент проверки достоверности, который измеряет степень уверенности LLM в своем ответе. Для решения второй может быть использован селектор контекста, который выбирает подходящий более точный и мелкий контекст из дерева контекстов [9].
В целом, подсказки состоят из четырех модулей:
-
1) проверка уверенности;
-
2) дерево контекстов;
-
3) селектор контекста;
-
4) генератор подсказок, который можно использовать как для LLM типа «черный ящик», так и для LLM типа «белый ящик».
В качестве метрики токсичности в моделях LLM часто используется LATTE. Суть использования данной метрики заключается в следующем.
Имея квалифицированные модели ( М), формат ( s ), содержание ( c ) и интервал ( i ), необходимо найти переменные, которые максимизируют следующее уравнение с помощью эмпирических экспериментов:
argmax Р (у \х, М, s, с, i)
где x - входная фраза, а у - метка.
После определения оптимальных переменных (*) вывод формулируется следующим образом:
score1 = M*(x1\s*,c*,i*),x1 G Dtest class-1
(1: score-1 > t {0:score1 < t где Dtest - тестовый набор данных, t - пороговое значение.
Вселенная контекстов представлена множеством C. Дерево контекстов может быть определено как Tc: C ^ LIST[C], которое является отображением из контекста родительского узла ct G C списка контекстов его дочерних узлов [c1+1, _, ct+c‘], где NCt - общее количество дочерних узлов ct, а c{+1 G С - j-й контекст дочернего узла ct. Кроме того, категория каждого контекста дочернего узла явля- ется подкатегорией его родительского узла, таким образом, контекст дочернего узла является более детализированным, чем контекст родительского узла. Например, c0 предоставляет определение токсичного контента, который включает язык ненависти, сексуальный контент и т.д. Тогда c1 может быть более детализированным определением языка ненависти, а c2 может быть более детализированным определением предвзятого контента (рис. 2).
Токсичный контент включает в себя язык ненависти, предвзятый контент, контент сексуального характера, контент с насилием и ...
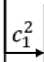
Контент, содержащий ненависть и нетерпимость, относится к любой форме коммуникации, СМИ пли выражения, которые пропагандируют или подстрекают к насилию, враждебности, ...
Предвзятый и дискриминационный контент может выражать неуважение, стереотипы или пропагандировать предвзятость и дискриминацию в отношении отдельного человека или группы люден с ...
Рис. 2. Пример контекстного дерева
После определение дерева контекста задействуется модуль выбора контекста, который принимает в качестве входных данных обоснование r t и контекст c t в подсказке на шаге t , а также дерево контекстов T c , чтобы выбрать более детальный контекст c t+1 для шага t + 1. Всякий раз, когда ответ на этапе итерации t считается недостоверным, селектор контекста выбирает новый контекст из дерева контекстов для повторного запроса LLM. В частности, он измеряет релевантность между обоснованием r t и каждым дочерним узлом контекста с^ г, а затем выбирает i *
наиболее релевантный ct+1 = ct+1
Возможности LLM по обучению в контексте позволяют значительно повысить качество определения вредоносного текста с помощью всего нескольких релевантных примеров. Так, в ходе экспериментов было установлено, что большинство LLM имеют тенденцию к аномально высокому уровню ложных срабатываний [10]. Чтобы смягчить эту проблему, в систему подсказок включаются примеры текста, который был неправильно классифицирован в контексте, тем самым напоминая модели о необходимости избегать чрезмерно строгой классификации.
На основании уже разработанных и протестированных моделей, в таблице 2 представлены данные, позволяющие сравнить эффективность различных LLM для идентификации вредоносного текста.
Таблица 2. Эффективность применения больших языковых моделей для анализа вредоносности текста
|
Модель / Система |
Точность (Precision) |
Полнота (Recall) |
F1-мера (F1-score) |
AUC (ROC) |
Примечания |
|
Perspective API (Google) |
= 0.85 |
= 0.80 |
= 0.82 |
= 0.90 |
Используется в индустрии для модерации текста |
|
GPT-3.5 (zero/few- shot) |
0.83–0.87 |
0.78–0.84 |
0.80–0.85 |
Без дополнительного обучения, но с текстовыми запросами работает хорошо |
|
|
GPT-4 (zero-shot) |
0.88–0.92 |
0.82–0.88 |
0.85–0.90 |
= 0.92 |
Очень высокая способность выявления скрытой токсичности |
|
BERT / T5 дообученные |
0.86–0.90 |
0.84–0.89 |
0.85–0.89 |
= 0.91 |
Отличные результаты при наличии размеченных данных |
Заключение. Вредоносный, токсичный текст демонстрирует присущую естественному языку гибкость, что делает его обнаружение постоянной проблемой для исследователей и важной практической задачей, подлежащей решению. Принимая во внимание тот факт, что большие языковые модели быстро развиваются, их можно использовать для про- текстов, включая дискриминационный, непристойный и ненавистнический контент.
В статье описаны особенности использования различных LLM для выявления вредоносного текста и представлены результаты их сравнения как с моделями из одной группы, так и с другими подходами обнаружения враждебного контента.
верки и выявления широкого спектра вредных
