Применение большой языковой модели для уменьшения ложнопозитивных срабатываний в задачах выявления аномалий в сетевом трафике

Автор: Болодурина И.П., Нефедов Д.А.
Рубрика: Информатика и вычислительная техника
Статья в выпуске: 4 т.24, 2024 года.
Бесплатный доступ
С каждым годом сетевые угрозы становятся все более изощренными и сложными, что требует от исследователей сферы сетевой безопасности искать и разрабатывать новые и более совершенные методы по обнаружению угроз безопасности. Несмотря на то, что ведутся постоянные исследования в данной области и исследователи совершенствуют алгоритмы машинного обучения, значительной проблемой остаются ложноположительные срабатывания систем обнаружения вторжений. В связи с этим разработка способов и подходов по уменьшению количества ложноположительных срабатываний является одной из наиболее актуальных задач. Цель исследования: изучить эффективность и возможности применения больших языковых моделей для снижения ложноположительных срабатываний систем обнаружения вторжений.
Большие языковые модели, нейронные сети, системы обнаружения вторжений, сетевой трафик, машинное обучение
Короткий адрес: https://sciup.org/147245999
IDR: 147245999 | УДК: 004.056 | DOI: 10.14529/ctcr240401
The application of a large language model for reducing false positives in anomaly detection tasks in network traffic
Every year, network threats become more sophisticated and complex, which requires researchers in the field of network security to seek and develop new and more advanced methods for detecting security threats. Despite the fact that constant research is being conducted in this area and researchers are improving machine learning algorithms, false positive triggers of intrusion detection systems remain a significant problem. In this regard, the development of methods and approaches to reduce the number of false positive positives is one of the most urgent tasks.
Текст научной статьи Применение большой языковой модели для уменьшения ложнопозитивных срабатываний в задачах выявления аномалий в сетевом трафике
За последнее десятилетие в интернете наблюдался экспоненциальный рост сетевого трафика и данных, чему способствовало распространение подключенных устройств, облачных вычислений и появление сервисов потокового видео, а также постепенное внедрение удаленной работы и дистанционного образования. Из-за совокупности этих, а также других неучтенных факторов вырос объем и ценность трафика, что и привело к увеличению количества и сложности сетевых атак [1]. В то же время сами вредоносные атаки стали более изощренными, поэтому сейчас основная задача заключается в выявлении неизвестных и запутанных вредоносных действий, так как злоумышленники начали использовать различные методы уклонения для сокрытия своих действий, чтобы предотвратить их обнаружение. Кроме того, наблюдается рост числа угроз безопасности, таких как атаки нулевого дня, нацеленные на пользователей Интернета. Следовательно, компьютерная безопасность приобрела важное значение, поскольку использование информационных технологий стало частью нашей повседневной жизни. В связи с этим вопросы обеспечения защиты данных и устойчивость информационных систем требуют особой проработки и внимания со стороны исследований.
Системы обнаружения вторжений (IDS) стали наиболее широко используемыми компонентами обеспечения безопасности современных компьютерных систем. Эти системы используют ряд разнообразных механизмов реагирования для обнаружения уязвимостей, выявления незаконных действий и вторжений, а также принятия соответствующих мер для противодействия данным угрозам [2]. Данные системы могут использовать различные алгоритмы для обнаружения вторжений, например методы, основанные на статистических данных, методы, основанные на знаниях, а также методы, основанные на машинном обучении.
Однако на сегодняшний день не существует ни одной системы, которая обеспечивала бы 100%-ную защиту и надежность работы [3]. В большинстве случаев IDS подвержены ложнопозитивным и ложнонегативным срабатываниям, что создает определенные сложности для фирм и бизнеса, а также информационной инфраструктуры. Ложнонегативными срабатываниями называются события, когда реальная угроза не была замечена системой обнаружения вторжения и проникла в контур защищаемой системы. Ложнопозитивное срабатывание – это ситуация, когда система посчитала безопасную активность за вредоносную.
Основное негативное влияние ложнопозитивных срабатываний заключается в дополнительной нагрузке на бизнес и фирмы, вызванной постоянными прерываниями активности систем, дополнительной нагрузкой на персонал и потерей денежных ресурсов, поэтому уменьшение таких срабатываний является важной задачей для повышения эффективности и надежности систем обнаружения вторжений [4].
Цель исследования
Ложнопозитивные срабатывания приводят к проблемам с бесперебойной работой фирм и вызывают дополнительную финансовую нагрузку. В рамках данной статьи проведено исследование возможности использования быстро развивающихся и постоянно совершенствующихся больших языковых моделей (LLM) для задач обнаружения угроз и уменьшения ложнопозитивных срабатываний [5].
Особенность данной работы заключается в подходе к противодействию ложнопозитивным срабатываниям с использованием связки из рекуррентной нейронной сети с долговременной краткосрочной памятью (LSTM), которая позволяет быстро классифицировать входящий сетевой пакет как угрозу, а также большой языковой модели (LLM), которая подтверждает или отвергает результат классификации нейронной сети. LSTM эффективно анализирует временные последовательности данных [6], позволяя классифицировать данные, и находит в них аномалии, затем LLM используется для дополнительного анализа и проверки результатов классификации, обеспечивая дополнительный уровень точности и снижая количество ложнопозитивных срабатываний. Данный подход позволяет более эффективно противодействовать угрозам в реальном времени и минимизировать финансовые потери, связанные с ложными срабатываниями.
Обзор исследований по данному направлению
Исследованиями по созданию эффективных систем обнаружения вторжений занимаются ученые по всему миру. В последние пять лет благодаря бурному развитию больших языковых моделей (LLM) исследователи обратили активное внимание на эти модели и пытаются различными способами применять их для улучшения систем обнаружения вторжений. Основная причина этого интереса заключается в том, что LLM обладают значительными возможностями для обработки и анализа больших объемов данных, что критично для задач сетевой безопасности. Данные модели способны выявлять скрытые паттерны и аномалии в сетевом трафике, которые могут быть неочевидны при использовании традиционных методов анализа.
В данном исследовании [7] авторы рассмотрели возможность применения больших языковых моделей в кибербезопасности. Авторы рассмотрели используемые LLM и их уникальные свойства для каждой модели, возможность применения их в различных задачах безопасности, а также специализированные техники для этих задач. Особое внимание было уделено качественным данным. Авторы пришли к выводу, что использование больших языковых моделей – перспективная область, требующая тщательной проработки и анализа.
Команда исследователей в статье [8] рассмотрела эволюцию систем обнаружения вторжений (IDS) с момента их появления в 1980-х годах до современного использования совместно с методами искусственного интеллекта. Традиционные методы IDS, такие как сигнатурные и аномальные обнаружения, имеют ограничения перед новыми и сложными киберугрозами. Введение
AI-основанных IDS, использующих машинное обучение и модели, такие как ChatGPT, показало улучшение в адаптивности, распознавании паттернов и способности к реальному времени обнаружения и реагирования на атаки.
Авторы статьи [9] представили инновационную систему автоматического исправления программ с использованием больших языковых моделей (LLM), таких как GPT, в сочетании с формальной верификацией. Их инструмент демонстрирует значительные улучшения по сравнению с существующими работами, достигая 99,9 % компилируемости кода и успешно исправляя уязвимый код с буферными переполнениями и ошибками разыменования с успехом до 80 %. Интеграция LLM и формальной верификации является многообещающим направлением для будущих исследований, хотя требует решения проблем, таких как высокие вычислительные ресурсы и возможное введение непреднамеренных уязвимостей.
В статье [11] авторы исследуют использование больших языковых моделей (LLMs), таких как ChatGPT, для повышения эффективности защиты от киберугроз. Авторами рассматриваются различные уровни угроз – от простых атак с использованием доступных скриптов до сложных атак APT-групп. Основное внимание в работе уделялось тому, как большие языковые модели могут помочь на различных этапах атаки, предлагая интеллектуальные команды, интерпретируя результаты и моделируя будущие решения злоумышленников. Исследование показывает, что эти модели могут значительно улучшить процесс обнаружения и реагирования на угрозы.
Исследователями работы [12] рассмотрена возможность использования языковой модели ChatGPT в фазе предварительной разведки при тестировании информационных систем на проникновение. В работе авторы анализируют, как ChatGPT может быть использован для получения различных типов разведывательных данных, необходимых для идентификации потенциальных уязвимостей в системах организаций. Типы данных, которые ChatGPT может предоставить для фазы разведки, – IP-адреса, технологические стеки, используемые вендорами, информация о доменных именах и протоколы сети, также авторами уделено особое внимание примерам конкретных запросов к данной модели и ожидаемые ответы для каждого типа информации.
Таким образом, анализ работ в области кибербезопасности показал, что использование больших языковых моделей является актуальной темой исследования. Кроме того, в настоящее время существует большое множество разных подходов по применению больших языковых моделей для повышения кибербезопасности, но для уменьшения ложнопозитивных срабатываний данные модели еще не использовались, поэтому в ходе данного исследования будет рассмотрено применение большой языковой модели для уменьшения ложнопозитивных срабатываний систем обнаружения вторжений.
Архитектура программного решения
Для реализации данного программного комплекса были разработаны отдельные модули, которые взаимодействуют между собой. Первый модуль – система, разработанная для отбора ключевых признаков и нормализации обучающей выборки [13]. Данный модуль обеспечивает улучшение качества данных, используемых в процессе обучения модели. Второй модуль – классификатор, в ядре которого находится обученная нейронная сеть, которая способна классифицировать сетевой трафик как вредоносный или безопасный. Нейронная сеть обладает высокой скоростью обнаружения аномалий в трафике и быстрой выдачей результатов распознавания. Результат работы данного модуля – отнесение каждого сетевого пакета к определенному классу – вредоносный или безопасный. Таким образом, второй модуль служит для первичного выявления аномалий в трафике.
Основой третьего модуля является система преобразования текста в векторное пространство для последующего использования его в большой языковой модели (LLM). Этот модуль преобразует текстовые данные в формат, удобный для обработки языковой моделью, что, в свою очередь, позволяет эффективно использовать семантическую информацию о трафике. Четвёртый модуль – большая языковая модель, которая повторно анализирует сетевые пакеты, в которых была обнаружена угроза. Данная модель обрабатывает текстовые данные и выполняет задачи семантического анализа. На вход модель получает результаты классификации из второго модуля, текстовые команды и данные из семантического векторного пространства [14]. Семантическое векторное пространство представляет различные типы угроз и их характеристики. Это пространство строится на основе данных о вредоносном трафике и позволяет моделировать и понимать различные угрозы на семантическом уровне. LLM анализирует, соответствует ли результат классификации из второго модуля известным паттернам и характеристикам угроз для повышения точности и надежности в обнаружении сетевых угроз.
Да н н ый п о дх од к п ос т ро ен ию системы обнаружения вторжений обеспечи л к омп ле к с ный а на л и з се те вого т ра фик а , о б ъ ед и н яя преи м у щ е ств а ра з ли чн ых методов обработки данных и глубоко го обу че н и я, чт о зн а чи тельн о п овышает эффективность и точность выявлен и я у гроз в сете во м трафике.
Архитектура LTSM-сетей
В ка че с тве м ет ода к лас с ифи кации угроз в исследовании используются ре ку р ре н тн ые н е й ро нные сети (RNN ) , а и ме н но реку ррентные сети с долговременной краткосрочной п а мятью ( LSTM). Если с р а в н и вать архи т екту р у ре куррентных сетей с архитектурой стандартных н ейр он н ых с е те й, и спо л ьзующ и х о д и н о чны е в х о дные данные, рекуррентные нейронные сети и с п о льзу ют се рию истор ичес к и х д а н н ых в к а че с тве входных значений [15]. Эта архитектура сет и п озво ляе т хра н и т ь и звле ченн у ю ин фо р м а ц ию о п р едыдущих входных данных в своей памяти дл я п ос л ед у ю щ его и с п о ль зова н и я в п рогн ози р ова н и и и классификации. В стандартных рекуррентн ых се т ях е с ть толь ко оди н с лой акти ва ц и и, кот оры й обновляет состояние памяти на каждом шаге . Т и п ова я а рхи т ек т у ра ра зв ерну тых ре курр е н тн ых се те й п редст а влен а н а ри с . 1. В стандартных RNN есть только о дин слой ак ти ва ц и и , который об н ов ляе т с ост о ян ие п а мяти н а кажд ом ша ге.
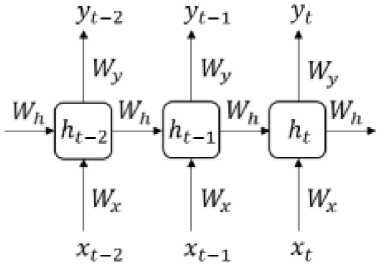
Рис. 1. Типовая архитектура рекуррентной нейронной сети Fig. 1. Typical architecture of a recurrent neural network
Состояние пространства ht в момент времени t можно рассматривать как память сети, вычисленную следующим о бра з о м:
h = f ( Whht -1 + КЛ), (1) где xt – входные данные; ht – ск ры т о е с ос т оян и е; yt – выходные данные; Wx , Wh , Wy – соответствующие веса.
Основное преимущество LS TM -сетей – во внутреннем строении повторяющихся ячеек памя ти . Э ти с е ти в кл ю чаю т допо лн и тельные компоненты, такие как «ячейки па мят и » и ра зли чн ы е « в х о д н ые », « в ых о д н ые » и « за б ы в аю щие» гейты, которые помогают эффективно управлять гради ен т а ми и с охранять до л г ос рочн ы е зависимости в данных. Также в данной ар хи те к т у ре се т ей до ба вляютс я с ос т оян и я ячей к и памя ти , обозн а ча е мы е к а к сt , которые взаимодействуют с четырьмя слоями:
c t = ft ° c t -1 + i t ° tanh ( W ch h t - 1 + W cx x t + b c ) , (2)
слоем забывания ft , и с п ользуемым для принятия решения о том, какую и н фо рм а ц и ю и з пр едыд у щ е й яче й к и с л ед уе т за б ыть :
ft = < Wfc ° Ct-1 + Wfh-1 + WfxXt + bf),(3)
слоем входных данных it , который решает какую часть информации стоит сохранить:
it =^( Wic ° ct-1 + Wihht-1 + Wixxt + bi), слоем гиперболического тангенса tanh для извлечения информации в новое состояние ячейки:
, . sinh ( x )
tanh (x )=- ,(5)
cosh ( x )
слоем выходных данных ot , который действует как фильтр для извлечения информации из сос т оян ия яче й к и д л я форми рова н и я в ых о д н о го с и г н ала:
ot = °(Wcc°ct + Wohht-1 + Woxxt + bo ), скрытым состоянием h(t) :
ht = ot ° tanh (ct).(7)
Архитектура LSTM с е ти п ред ст а в ле н а н а ри с . 2.
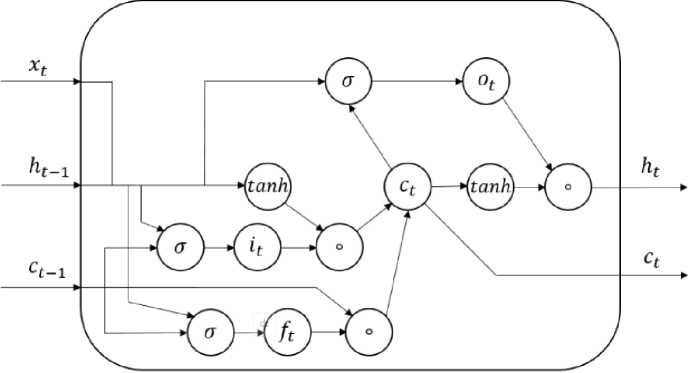
Рис. 2. Архитектура рекуррентной сети с долгой краткосрочной памятью Fig. 2. Recurrent network architecture with long short-term memory
Бл аг о д аря э тим ос о бе н нос т ям LS TM-сети значительно превосходят стандартные RNN при р а б о те с п о с ле д ова т е льными д анными, делая их идеальным выбором для з ад а ч п рогн ози рова н и я и к лас с ифи к а ц и и в у с лови ях н али чи я д ли те л ьн ых временных зависимостей. Таким образом, архитектура LSTM- с е те й п озвол ила в данной работе с высокой эффективност ью кла сс и фи ц и ров а т ь в редоно с н ые с е те в ые п аке ты, что является важным шагом для их последу ю щ е й п рове рк и с п омощью б о л ьш ой яз ы ков о й мо д е л и.
Большая языковая модель
В ка че с тве бол ьш ой я зы ковой модели в данном исследовании используе т с я Mix tra l 8 x7B . Особе н но с ть да н н ой мо де ли за ключается в использовании архитектуры раз ряж е н н о го э к с пе р тн ого со с т а ва ( S par se M ixtu re of Exper ts ) . В о тли чи е о т к л а с с и ческой архитектуры, основанной на тра н сфо рмера х, д а н н а я м о д е ль разделяет прямую нейронную связь на набо р э к с пе р т ов [ 16 ] . Д анн ая а рхи те к т ура позво ляе т су щ ественно снизить вычислительную нагрузку н а с и с те му. В ме с т о ак ти ва ц и и всех н е й рон ов мо д е л ь актив и р уе т т олько те нейроны, которые необходимы для выполн ени я кон к ре тн ой за дачи. Э т о приводит к уменьшению количества парамет ров , у ча с тв у ю щ и х в в ы числе н и ях, чт о, в с вою оче редь, повышает скорость работы модели. Бла годаря э т ом у м о де ль, и ме ющ а я 42 ми ллиа р да па ра ме т ров , функционирует со скоростью модели с 7 миллиардами параметров.
Общую модель архитектуры разряженного экспертного состава можно представить следующим образом:
y = X G i ( x ) E i ( x ) , (8)
i e S ( x )
где y – выход модели; S ( x ) – подмножество выбранных экспертов для входного сигнала xi ; G ( x ) - функция гейта, которая определяет вес i -го эксперта для выходного сигнала x i ; E i ( x ) -выход i -го эксперта для входного сигнала x .
Данные преимущества делают данную модель подходящим инструментом для обработки и анализа данных в задачах обнаружения сетевых угроз, обеспечивая высокую точность и скорость работы. Архитектура Mixtral 8x7B в рамках данной системы позволила с высокой эффективностью и наименьшими затратами ресурсов системы использовать все преимущества больших языковых моделей для обработки и анализа данных.
Подготовка данных и обучение системы
Для обучения модели LTSM использовалась выборка сетевого трафика CIC-IDS2017 [17]. Набор данных CICIDS2017 содержит как безопасные сетевые пакеты, так и современные распространенные атаки, собранные в течение длительного времени. Объем обучающей выборки составляет более трех миллионов сетевых пакетов. Данные представлены в формате CSV с разделителем и 78 полями, где каждое поле представляет определенную характеристику сетевого трафика. Этот набор данных также включает результаты анализа сетевого трафика с использованием CICFlowMeter и маркировкой потоков на основе отметки времени, IP-адресов источника и назначения, портов источника и назначения, протоколов и атак (файлы CSV) и др., а также присутствует текстовая метка для классификации трафика как вредоносного или безопасного.
Поскольку данная обучающая выборка содержит множество параметров, использование их всех для обучения нейронной сети приведет к перегрузке модели и снижению ее эффективности [18]. Для решения этой проблемы воспользуемся методами отбора признаков. Эти методы позволят выделить наиболее значимые поля в сетевой выборке, что, в свою очередь, улучшает качество обучения классификатора и помогает избегать перегрузки модели. Для отбора признаков мы применили три метода: метод взаимной информации, метод оценки важности признаков с помощью случайного леса, а также рекурсивное устранение признаков. Для получения окончательного набора признаков берется пересечение результатов всех трех методов с добавлением небольшого зазора в 0,05 % для учета погрешностей и возможных вариаций в данных.
В результате отбора были выделены и отобраны наиболее значимые характеристики сетевых пакетов, такие как заголовки, содержимое пакетов, временные метки и другие метаданные. Это позволило уменьшить размерность данных и улучшить качество классификации.
Обучение системы происходило с помощью алгоритма машинного обучения на Python с использованием библиотеки scikit-learn. Данные были разделены на обучающую и тестовую выборки в соотношении 75 % на обучение и 25 % – на тестирование модели. Для решения задачи распознавания угроз была построена модель рекуррентной сети с долгой краткосрочной памятью (LSTM) с использованием следующих слоев:
Bidirectional(LSTM) – двунаправленный LSTM-слой, состоящий из двух LSTM-слоёв, работающих в противоположных направлениях. Этот слой позволяет модели захватывать контекст из обеих сторон временной последовательности;
BatchNormalization – нормализует активации батчей, уменьшая внутренние ковариационные сдвиги и ускоряя обучение;
Dropout – слой регуляризации, обнуляющий часть входных нейронов с заданной вероятностью;
LTSM – слой, предназначенный для работы с временными последовательностями;
Dense – полносвязный слой.
Архитектура LSTM сети представлена на рис. 3.
model = Sequential()
model.compile(loss='categoricalcrossentropy', optimizer=Adam(learning_rate=0.001), metrics=['accuracy'])
Рис. 3. Архитектура сети
Fig. 3. Network architecture
Фун к ц и я а кти ва ц и и s oft ma x преобразует необработанные выходные дан ные н е й рон н ой се ти в ве кт ор ве роятн ос те й , п о су ти выполняя распределение вероятностей по вх од н ым к л а с с а м:
softmax( z ) i
i
I zzl
\.
v^—1 J =1 7
,
где z – в ект ор н е об р а бот а н н ых вы х о д н ых да н н ы х н е й рон н ой се ти ; N – количество выходных классов; softmax( z ) i – пр о г но з ируемая вероятность того, что тестовый вход п р инадл еж ит кл асс у i .
Обу че н и е мо д е ли за н яло 8 ча с ов п ри коли че с тве 50 э п ох обучения.
По те ри п ри о бу че н и и , а т а кже точность обучения представлена на рис. 4.
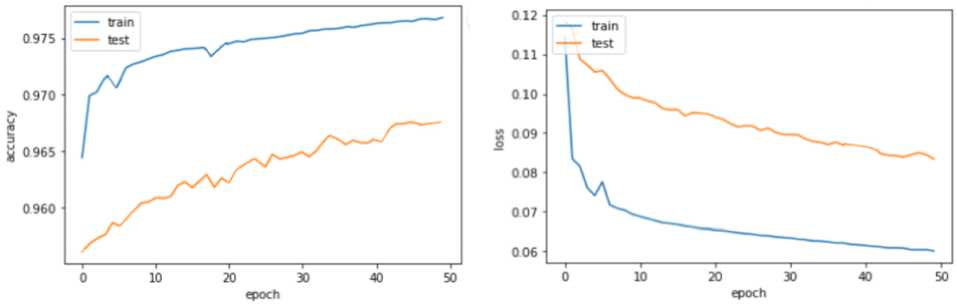
Рис. 4. Потери при обучении и точность Fig. 4. Learning losses and accuracy
Из результата обучения можно сделать вывод: LSTM-сеть демонстрирует высокую точность и низкие потери на обучающей и тестовой выборках, что указывает на её эффективность в классификации сетевых пакетов как вредоносных или безопасных. Из графика на рис. 4 можно увидеть, что точность модели составила 0,9689. Наблюдается небольшое переобучение, выражающееся в небольшом расхождении точности и потерь между обучающими и тестовыми данными, однако это расхождение незначительно и некритично. В целом обученная модель показывает хорошие результаты и обладает способностью к обобщению.
Результаты экспериментального исследования
Для проверки возможности снижения количества ложнопозитивных срабатываний проведен эксперимент, в котором сравнивалась работа классической архитектуры нейронной сети LSTM (Long Short-Term Memory) с добавлением модуля большой языковой модели (LLM). Коэффициент ложнопозитивных срабатываний (FP rate) вычислялся по формуле
FP rate =
FP
FP + TN,
где FP – количество ложнопозитивных срабатываний; TN – количество верно классифицирован- ных вредоносных пакетов.
Эксперимент проведен пять раз, и усредненные значения по пяти экспериментам представлены в таблице.
Результат сравнения The result of the comparison
|
Модель |
Входящие пакеты |
Верно классифицированные пакеты |
Ложнопозитивные срабатывания |
Коэффициент ложнопозитивных срабатываний |
|
LTSM |
150 000 |
14 879 |
843 |
0,05361 |
|
LTSM + LLM |
150 000 |
15 124 |
514 |
0,03286 |
Результаты показывают, что использование большой языковой модели в качестве дополнительного этапа проверки срабатываний системы обнаружения вторжений действительно позволяет снизить количество ложноположительных срабатываний на 38,64 %. Это значительное улучшение позволяет повысить надёжность системы обнаружения вторжений, уменьшая количество ложных тревог и, соответственно, снижая нагрузку на аналитиков безопасности. Проверено, может ли большая языковая модель улучшить работу системы обнаружения вторжений.
Заключение
В рамках данного исследования проведено экспериментальное исследование возможности использования больших языковых моделей (LLM) для снижения ложнопозитивных срабатываний в системах обнаружения вторжений (IDS). Важность данной темы продиктована стремительным ростом объема и сложности сетевых атак, что обусловлено экспоненциальным ростом сетевого трафика и данных в последние годы.
В ходе эксперимента построена и обучена базовая модель нейронной сети для быстрой классификации пакетов в сетевом трафике на вредоносные и безопасные. Особое внимание уделено архитектуре и работе LSTM-сетей, а также особенностям использования большой языковой модели Mixtral 8x7B, основанной на архитектуре разряженного экспертного состава. Для подготовки данных и обучения системы использовался набор данных CIC-IDS2017. Для улучшения обучения модели проведен отбор ключевых признаков из данной выборки. В ходе обучения LSTM-сети достигнуты высокие показатели точности и низкие потери, что свидетельствует об эффективности модели в классификации сетевых пакетов как вредоносных или безопасных.
Экспериментальные исследования подтвердили, что добавление модуля большой языковой модели позволяет значительно снизить количество ложнопозитивных срабатываний. Коэффициент ложнопозитивных срабатываний снизился на 38,64 %, что свидетельствует о существенном улучшении надежности системы обнаружения вторжений. Однако существенным недостатком является долгий ответ модели, который необходимо будет уменьшать в будущих исследованиях.
Список литературы Применение большой языковой модели для уменьшения ложнопозитивных срабатываний в задачах выявления аномалий в сетевом трафике
- Odlyzko A.M. Internet Traffic Growth: Sources and Implications. Proceedings of SPIE - The International Society for Optical Engineering. 2003;5247. DOI: 10.1117/12.512942
- Khraisat A., Gondal I., Vamplew P., Kamruzzaman J. Survey of intrusion detection systems: techniques, datasets and challenges. Cybersecurity. 2019;2:20. DOI: 10.1186/s42400-019-0038-7
- Ho C.Y., Lin Y.R., Lai Y.C., Chen I.W., Wang F.Y., Tai W.H. False Positives and Negatives from Real Traffic with Intrusion Detection/Prevention Systems. International Journal of Future Computer and Communication. 2012;1(2):87-90. DOI: 10.7763/IJFCC.2012.V1.23
- Naveed H., Khan A.U., Qiu S., Saqib M., Anwar S., Usman M., Akhtar N., Barnes N., Mian A. A Comprehensive Overview of Large Language Models. Preprint submitted to Elsevier, 2024.
- Wan X., Liu H., Xu H., Zhang X. Network Traffic Prediction Based on LSTM and Transfer Learning. IEEE Access. 2022;10:86181-86193. DOI: 10.1109/ACCESS.2022.3199372
- Xu H., Wang S., Li N., Wang K., Zhao Y., Chen K. et al. Large Language Models for Cyber Security: A Systematic Literature Review. arXiv preprint arXiv:2405.04760, 2024.
- Markevych M., Dawson M. A Review of Enhancing Intrusion Detection Systems for Cybersecurity Using Artificial Intelligence (AI). International Conference Knowledge-Based Organization. 2023;29(3). DOI: 10.2478/kbo-2023-0072
- Charalambous Y., Tihanyi N., Jain R., Sun Y., Ferrag M.A., Cordeiro L.C. A New Era in Software Security: Towards Self-Healing Software via Large Language Models and Formal Verification. arXiv:2305.14752 [cs.SE], 2023. DOI: 10.48550/arXiv.2305.14752
- Alkhatib N., Mushtaq M., Ghauch H., Danger J.L. CAN-BERT do it? Controller Area Network Intrusion Detection System based on BERT Language Model. arXiv:2210.09439 [cs.LG], 2022. DOI: 10.48550/arXiv.2210.09439
- Moskal S., Laney S., Hemberg E., O'Reilly U.M. LLMs Killed the Script Kiddie: How Agents Supported by Large Language Models Change the Landscape of Network Threat Testing. arXiv preprint arXiv:2310.06936v1 [cs.CR], 2023.
- Temara S. Maximizing Penetration Testing Success with Effective Reconnaissance Techniques using ChatGPT. arXiv preprint arXiv:2307.06391 [cs.CR], 2023.
- Pudjihartono N., Fadason T., Kempa-Liehr A.W., O'Sullivan J.M. A Review of Feature Selection Methods for Machine Learning-Based Disease Risk Prediction. Front Bioinform. 2022;2:927312. DOI: 10.3389/fbinf.2022.927312
- Xu S., Wu Z., Zhao H., Shu P., Liu Z., Liao W., Li S., Sikora A., Liu T., Li X. Reasoning Before Comparison: LLM-Enhanced Semantic Similarity Metrics for Domain Specialized Text Analysis. arXiv preprint arXiv:2402.11398v2 [cs.CL], 2024.
- Van Houdt G., Mosquera C., Napoles G. A Review on the Long Short-Term Memory Model. Artificial Intelligence Review. 2020;53(1). DOI: 10.1007/s10462-020-09838-1
- Staudemeyer R.C., Morris E.R. Understanding LSTM - a tutorial into Long Short-Term Memory Recurrent Neural Networks. arXiv preprint arXiv: 1909.09586v1, 2019.
- Jiang A.Q., Sablayrolles A., Roux A., Mensch A., Savary B., Bamford C., Chaplot D.S., de las Casas D., Bou Hanna E., Bressand F., Lengyel G., Bour G., Lample G., Lavaud L.R., Saulnier L., Lachaux M.-A., Stock P., Subramanian S., Yang S., Antoniak S., Le Scao T., Gervet T., Lavril T., Wang T., Lacroix T., El Sayed W. Mixtral of Experts. arXiv preprint arXiv:2401.04088 [cs.LG], 2024.
- Intrusion Detection Evaluation Dataset (CIC-IDS2017). Available at: https://www.unb.ca/cic/ datasets/ids-2017.html/ (accessed 12.04.2023).
- Cai J., Luo J., Wang S., Yang S. Feature selection in machine learning: A new perspective. Neurocomputing. 2018;300:70-79.
