Применение графических ускорителей для обработки запросов над сжатыми данными в параллельных системах баз данных

Автор: Приказчиков Степан Олегович, Костенецкий Павел Сергеевич
Рубрика: Информатика, вычислительная техника и управление
Статья в выпуске: 1 т.4, 2015 года.
Бесплатный доступ
Работа посвящена вопросам применения графических процессоров для обработки запросов в параллельных системах баз данных. Целью данной работы является оценка эффективности выполнения запросов к сжатой базе данных без предварительной распаковки с использованием графических ускорителей, поддерживающих технологию CUDA. Объем внутренней памяти ГПУ на порядки меньше, чем объем оперативной памяти современных вычислительных систем. Это ограничивает размер базы данных, которую можно загрузить в память ГПУ и как следствие не позволяет раскрыть весь вычислительный потенциал графического процессора. Предлагается подход для обработки запросов над сжатыми данными на ГПУ. На основе предложенного подхода реализован эмулятор параллельной СУБД. Аналогичный эмулятор разработан для ЦПУ. Приведены результаты вычислительных экспериментов и произведена оценка эффективности данного подхода.
Графические процессоры, параллельная обработка запросов
Короткий адрес: https://sciup.org/147160557
IDR: 147160557 | УДК: 004.65 | DOI: 10.14529/cmse150106
Using graphics accelerators for query processing over compressed data in parallel database systems
This article talks about using graphics processors for query processing in parallel database systems. The goal is to evaluate query execution efficiency over compressed database without decompression on multicore GPUs which support CUDA technology. GPU's memory size is significantly smaller than modern computer system's RAM size. This fact affects database's size can be loaded into GPU's internal memory, thus computing potential of GPU can not be used efficiently. The new approach presented in this article allows query processing over compressed data on GPU. An emulator of parallel DBMS is developed based on this approach. The similar emulator for a CPU is designed. Results of computational experiments are presented and analysis of efficiency of the proposed approaches is performed.
Текст научной статьи Применение графических ускорителей для обработки запросов над сжатыми данными в параллельных системах баз данных
В настоящее время известно большое количество исследований обработки запросов к базам данных в оперативной памяти [4, 5, 9, 12], но использование графических ускорителей (ГПУ) и многоядерных сопроцессоров [11] открывает новые перспективы исследований в этой области [1, 2, 7]. Целью данной работы является оценка эффективности выполнения запросов к сжатой базе данных без предварительной распаковки с использованием графических ускорителей, поддерживающих технологию CUDA. Объем внутренней памяти ГПУ на порядки меньше, чем объем оперативной памяти современных вычислительных систем. Это ограничивает размер базы данных, которую можно загрузить в память ГПУ и как следствие не позволяет раскрыть весь вычислительный потенциал ГПУ. Для снижения влияния объема видеопамяти на возможность хранения в ней больших баз данных применяется сжатие. Предполагается, что сжатие позволит не только увеличить объем хранимой базы данных, но и повысит производительность по сравнению с обработкой несжатых данных.
Статья организована следующим образом. В разделе 1 описана реализация алгоритма выборки для ГПУ и ЦПУ. Раздел 2 описывает проводимые вычислительные эксперименты. В заключении подведены итоги исследования.
-
1. Реализация
-
2. Вычислительные эксперименты
На текущий момент разработан эмулятор СУБД [6], позволяющий выполнять запрос SELECT над сжатыми данными, непосредственно на ГПУ с использованием технологии CUDA и, для сравнения, эмулятор для ЦПУ, работающий по технологии OpenMP.
Для сжатия был выбран и реализован алгоритм RLE [8, 10]. Основным преимуществом использования данного алгоритма в СУБД является возможность выполнения многих реляционных запросов без предварительной распаковки данных.
Реляционное отношение базы данных хранится в сжатом виде в памяти ГПУ. Кортежи отношения имеют по два атрибута, первый атрибут — номер кортежа (идентификатор), второй атрибут — значение (строка символов). На первом этапе алгоритм производит поиск строк, длина которых совпадает с размером искомой строки. Так, каждый блок производит выборку из нескольких подряд идущих кортежей. Каждый поток блока выполняет сравнение одного символа искомой строки с символом в строке базы данных. При такой организации распараллеливания соблюдается принцип memory coalescing [3], что позволяет свести к минимуму влияние латентности доступа к памяти ГПУ. Для распараллеливания на ГПУ используется разбиение кортежей реляционного отношения по блокам CUDA. На конечном этапе номера кортежей, содержащих совпавшие строки, записываются в выходной массив. Передаются не кортежи целиком, а только их номера с целью уменьшить объем передаваемых данных по шине PCI Express. Шина PCI Express имеет на несколько порядков меньшую скорость передачи данных, чем оперативная память и внутренняя память ГПУ, поэтому данный подход позволяет значительно повысить общую производительность при обработке данных.
Вычислительные эксперименты проводились с использованием разработанного эмулятора СУБД на оборудовании, характеристики которого приведены в табл. 1.
Оборудование для экспериментов
Таблица 1
|
Оборудование |
Характеристики |
|
|
Процессор |
Intel Core i7-3610QM 2.3 ГГц |
|
|
ОЗУ |
8 Гб DDR3-1600 |
|
|
Твердотельный накопитель |
Plextor M5 Pro PX-128M5P, 128 Гб, SATA III |
|
|
Системная шина |
PCI Express 2.0 |
|
|
Графический ускоритель |
Модель |
NVIDIA GeForce GTX 670M |
|
Объем видеопамяти |
3 072 Мб |
|
|
Ядер CUDA |
336 |
|
|
Тактовая частота ядра |
620 МГц |
|
|
Тактовая частота памяти |
3 000 МГц |
|
|
Пропускная способность памяти |
72 Гб/с |
|
|
Разрядность памяти |
192-bit |
|
Для проведения вычислительных экспериментов было сгенерировано 4 тестовых отношения. Размер отношений, а также коэффициент сжатия строк в кортежах представлены в табл. 2.
Таблица 2
Характеристики тестовых отношений
|
№ тестовой БД |
Размер отношения (количество кортежей) |
Коэффициент сжатия |
Объем в сжатом виде, Мб |
|
1 |
33 000 000 |
4 |
519 |
|
2 |
2 |
1 039 |
|
|
3 |
1,33 |
1 562 |
|
|
4 |
1 |
2 077 |
2.1. Исследование эффективности операции выборки над сжатыми данными
Было произведено исследование эффективности операции выборки над сжатыми дан- ными в сравнении с обработкой несжатых данных.
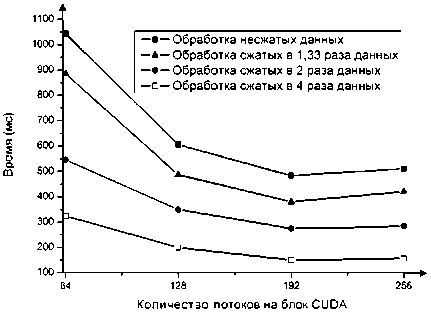
а) Время
Рис. 1. Выполнение алгоритма ГПУ SELECT на одном вычислительном узле
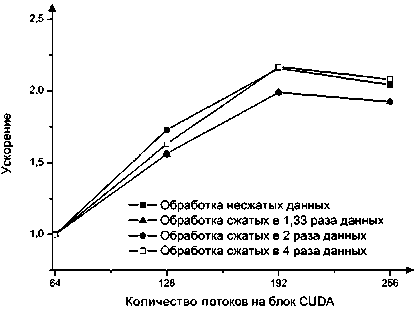
б) Ускорение
Как видно из графиков времени выполнения операции выборки из тестовых баз данных с использованием ГПУ (см. рис. 1а) и с использованием ЦПУ (см. рис. 2а), при применении сжатия мы получаем максимальный прирост скорости в 3,2 раза на ГПУ и в 3 раза на ЦПУ.
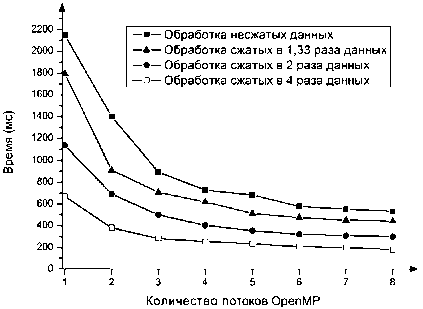
а) Время
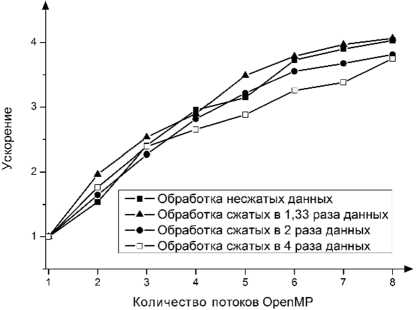
б) Ускорение
Рис.2. Выполнение алгоритма ЦПУ SELECT на одном вычислительном узле
На графике сравнения времени выполнения операции выборки на ГПУ и на ЦПУ (см. рис. 5) видно, что при использовании ГПУ выборка выполняется быстрее независимо от размера базы данных.
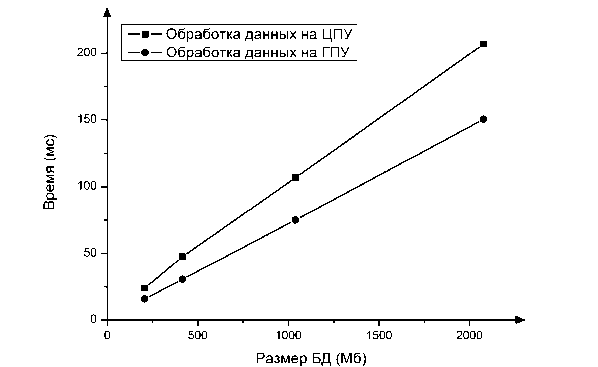
Рис. 3. Время выполнения алгоритмов ЦПУ и ГПУ SELECT на одном вычислительном узле над сжатыми в 4 раза данными
Заключение
В работе рассматривались вопросы применения графических процессоров для обработки запросов в параллельных системах баз данных. Предложен подход для обработки запросов над сжатыми данными на ГПУ. На основе предложенного подхода реализован эмулятор параллельной СУБД. Аналогичный эмулятор разработан для ЦПУ. Приведены результаты вычислительных экспериментов и произведена оценка эффективности данного подхода. Установлено, что выполнение выборки над сжатыми данными на ГПУ эффективнее, чем на ЦПУ в 1,2 раза. Небольшое преимущество ГПУ объясняется тем, что в качестве тестовой конфигурации имелся достаточно производительный процессор Intel Core i7-3610QM и не очень производительный графический ускоритель NVIDIA GeForce GTX 670M. На следующем этапе исследования тестирование будет произведено на новейших ГПУ NVIDIA Tesla K40 и многоядерных сопроцессорах Intel Xeon Phi.
Работа выполнена при финансовой поддержке Минобрнауки РФ в рамках ФЦП «Исследования и разработки по приоритетным направлениям развития научно-технологического комплекса России на 2014–2020 годы» (Соглашение № 14.574.21.0035).
Список литературы Применение графических ускорителей для обработки запросов над сжатыми данными в параллельных системах баз данных
- Беседин, К.Ю. Моделирование обработки запросов на гибридных вычислительных системах с многоядерными сопроцессорами и графическими ускорителями/К.Ю. Беседин, П.С. Костенецкий//Программные системы: теория и приложения: электрон. научн. журн. Института программных систем им. А.К. Айламазяна РАН. -2014. -T. 5, № 1(19). -С. 91-110.
- Беседин, К.Ю. Применение многоядерных сопроцессоров в параллельных системах баз данных/К.Ю. Беседин, П.С. Костенецкий//Параллельные вычислительные технологии (ПаВТ'2013): труды международной научной конференции (1-5 апреля 2013 г., г. Челябинск). -Челябинск: Издательский центр ЮУрГУ, 2013. -С. 583.
- Боресков, А.В. Параллельные вычисления на GPU. Архитектура и программная модель CUDA/А.В. Боресков, Н.Д. Марковский, Д.Н. Микушин и др. -М.: Издательство Московского университета, 2012. -336 с.
- Костенецкий, П.С. Технологии параллельных систем баз данных для иерархических многопроцессорных сред/П.С. Костенецкий, А.В. Лепихов, Л.Б. Соколинский//Автоматика и телемеханика. -2007. -№ 5. -C. 112-125.
- Костенецкий, П.С. Моделирование иерархических многопроцессорных систем баз данных/П.С. Костенецкий, Л.Б. Соколинский//Программирование. -Москва: МАИК «Наука/Интерпериодика». -2013. -Т. 39, № 1. -С. 3-22.
- Костенецкий, П.С. Моделирование параллельных систем баз данных: учебное пособие/П.С. Костенецкий, Л.Б. Соколинский -Челябинск: Фотохудожник, 2012. -78 с.
- Сафина, Ю.Н. Моделирование аппаратной архитектуры и коммуникационных сетей вычислительных кластеров с гибридными узлами для параллельных систем баз данных/Ю.Н. Сафина, П.С. Костенецкий//Параллельные вычислительные технологии (ПаВТ'2012): Труды международной научной конференции (г. Новосибирск, 26-30 марта 2012 г.). -Челябинск: Издательский центр ЮУрГУ, 2012. -С. 741.
- Abadi, D. Integrating compression and execution in column-oriented database systems/D. Abadi, S. Madden, M. Ferreira//Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data, 2006. -P. 671-682.
- Пан, К.С. Разработка параллельной СУБД на основе последовательной СУБД PostgreSQL с открытым исходным кодом/К.С. Пан, М.Л. Цымблер//Вестник ЮУрГУ. Серия «Математическое моделирование и программирование». -2012. -№ 18(277). Вып. 12. -С. 112-120.
- Костенецкий, П.С. Исследование эффективности различных методов сжатия при передаче данных из основной памяти в память сопроцессора Intel Xeon Phi/П.С. Костенецкий, К.Ю. Беседин//Вычислительные методы и программирование. -2014. -Т. 15, № 4. -С. 593-601.
- Иванова, Е.В. Использование распределенных колоночных индексов для выполнения запросов к сверхбольшим базам данных/Е.В. Иванова, Л.Б. Соколинский//Параллельные вычислительные технологии (ПаВТ'2014): труды международной научной конференции (1-3 апреля 2014 г., г. Ростов-на-Дону). -Челябинск: Издательский центр ЮУрГУ, 2014. -С. 270-275.
- Соколинский, Л.Б. Параллельные машины баз данных/Л.Б. Соколинский//Природа. -2001. -№ 8. -C. 10-17.
