Применение онтологий в семантических информационных системах

Автор: Копайгородский А.Н.
Журнал: Онтология проектирования @ontology-of-designing
Рубрика: От редакции
Статья в выпуске: 4 (14) т.4, 2014 года.
Бесплатный доступ
В работе рассмотрены проблемы проектирования и реализации информационных систем и предлагается подход к разработке семантических информационных систем. Одной из главных проблем при создании информационных систем является изменение требований к ней уже после ее проектирования и реализации. Предложено ввести в архитектуру информационных систем некоторую «вариативную часть», которая определяет специфику предметной области, методов и задач. Эта часть может быть представлена в виде семантической сети или онтологии. Интерпретация онтологии позволяет выполнять конфигурирование информационной системы статически или динамически. Настройке могут подвергаться поведение, интерфейсы, модели данных или правила взаимодействия с другими смежными системами. Таким образом, семантические информационные системы обладают новыми свойствами и гибкостью поведения. Изложенные идеи были реализованы на практике и хорошо себя зарекомендовали. Рассмотрен методический подход, позволяющий быстро и легко разрабатывать семантические информационные системы, основанные на Репозитарии ИТ-инфраструктуры исследований энергетики. Репозитарий может настраиваться on-line на представление и обработку информации в соответствии с онтологиями.
Семантические информационные системы, онтологии, статическое и динамическое конфигурирование информационных систем, поддержка научных исследований
Короткий адрес: https://sciup.org/170178682
IDR: 170178682 | УДК: 004.[415.26:822:896]
Use of ontologies in semantic information systems
The article describes some problems of design and implementation of informational systems. An approach towards building semantic informational systems is proposed. The problem of systems requirements evolution after it was already implemented is stated as a key problem in informational systems creation. It is proposed to include into the system a special variative part, that would specify the subject domain, methods and tasks. This part might be in a form of semantic web or ontology. Ontology interpretation might allow configuring the information system statically or dynamically. It would be possible to correct behavior, interfaces, data models or the interaction rules with related systems. Thus, semantic information systems possess new qualities and behavioral flexibility. These ideas have been implemented in practice and are well proven. Methodical approach that allows to quickly and easily develop semantic information systems based on the Repository of IT-Infrastructure Energy research is described. The Repository can be configured online to process and represent information in accordance with ontology.
Текст научной статьи Применение онтологий в семантических информационных системах
В условиях развития современного общества информационные системы сопровождают нас повсюду, очень трудно найти сферу человеческой жизнедеятельности, в которой они не используются. Научные достижения последних лет в областях представления и управления знаниями, искусственного интеллекта активно используются в информационных системах, значительно расширяя круг пользователей и делая их интуитивно понятными. Под информационной системой понимается совокупность информации, содержащейся в базах данных, и информационных технологий и технических средств, обеспечивающих ее обработку [1]. Основной задачей информационных систем является удовлетворение конкретных информационных потребностей в рамках определенной предметной области. Для эффективного управления, обработки и использования информации требуется применение современных информационных технологий, методов и средств, которые позволяют преодолеть экспоненциальный рост объемов представленной в корпоративных базах данных информации. Отличительной особенностью семантических информационных систем является возможность обработки (изменение формы представления, поиск и др.) семантической информации (выраженной знаками сведений о выделенных сторонах объектов) [2].
Процессы проектирования, реализации и внедрения информационных систем являются продолжительными по времени и затратными по используемым ресурсам, поэтому в последние годы активно развиваются различные подходы, позволяющие минимизировать риски создания систем с завышенным бюджетом, с недостаточной функциональностью или не в установленные сроки.
1 Семантические технологии и информационные системы
Семантические технологии достаточно давно применяются при проектировании и реализации информационных систем, они нашли свое отражение в различных подходах и методиках. Семантика – это раздел лингвистики, устанавливающий отношения между символами и объектами, которые они обозначают. Другими словами, под семантикой понимают науку, определяющую смысл знаков [3]. Семантической сетью обычно называют «смысловую сеть», представленную в виде ориентированного графа, вершинами которого являются объекты предметной области, а дугами – отношения между ними. Объектами такой сети могут быть понятия, события, свойства, процессы и др. Семантическая сеть является информационной моделью, которая представляет знания определенной предметной области. В общем случае количество типов отношений между объектами в семантической сети достаточно большое и может стремиться к бесконечности, однако авторы, руководствуясь конкретными целями создания сетей, сознательно их ограничивают. Чаще всего в семантических сетях используются следующие классы отношений [4]:
-
■ связи «часть - целое» / «is - а» (например, «элемент - класс»);
-
■ функциональные связи (определяются глаголами «производит», «влияет» и т.д.);
-
■ количественные отношения («больше», «меньше», «равно» и т.д.);
-
■ пространственные отношения («далеко от», «близко от» и т.д.);
-
■ временные отношения («раньше», «позже», «в течение» и т.д.);
-
■ атрибутивные связи («имеет свойство», «имеет значение» и т.д.);
-
■ логические связи (И, ИЛИ, НЕ); ■ лингвистические связи.
В методических подходах, связанных с проектированием информационных систем, используются семантические сети, построенные по определенным правилам. Эти правила выражаются в строгом использовании графических элементов и построении связей между ними. Примерами таких подходов являются UML и IDEF: в методологии IDEF1x описывается моделирование данных на основе модели «сущность–связь», определены правила для описания сущностей, атрибутов и отношений.
В процессе проектирования информационных систем их авторы строят модели для улучшения понимания предметной области и уменьшения вероятности возникновения ошибок на различных этапах реализации системы. Моделирование позволяет решить четыре класса различных задач:
-
1) визуализировать систему в ее текущем или желательном состоянии;
-
2) определить структуру или поведение создаваемой системы;
-
3) получить шаблон, позволяющий затем сконструировать систему;
-
4) документировать принимаемые решения на разных этапах, используя полученные модели.
Достаточно часто при разработке, особенно простых проектов, этап моделирования отсутствует, хотя неформальные методы моделирования, такие как рисование квадратиков на доске или бумаге, разработчики всё же применяют. Правильно построенные модели позволяют разрешить множество потенциальных проблем в будущей информационной системе еще до написания ее первых строк кода. Модели, построенные на этапе проектирования, часто имеют большую ценность, чем конкретная реализация: создание моделей сложной системы может потребовать много месяцев обследования и анализа предметной области, консуль- таций с экспертами и обработки тысяч страниц документации. После их построения они могут быть воплощены в виде программного продукта на каком-либо языке программирования. Если понадобится реализовать этот продукт, например, в виде Web-сервиса или выполнить его модернизацию, то построенные ранее модели позволят значительно сэкономить время и упростить реализацию новой системы.
В последние годы ведутся активные исследования по развитию модельноориентированного подхода к разработке программного обеспечения (MDA – Model Driven Architecture) с использованием онтологического подхода (ODSE – Ontology-Driven Software Engineering). В научном сообществе не сложилось единого мнения по применению термина ODSE, данное понятие объединяет различные методы применения онтологий в процессе разработки программного обеспечения. Усилиями международных консорциумов W3C и OMG создан ряд спецификаций, открывающий путь к использованию онтологий в процессе разработки программного обеспечения.
В работе Т.А. Гавриловой и В.Ф. Хорошевского [5] онтология формально определена как O = < С , R , F >, где
С – конечное множество концептов (понятий) предметной области,
R – конечное множество отношений между концептами,
F – конечное множество функций интерпретации, заданных на концептах и/или отношениях.
Онтологии используют предопределенный зарезервированный словарь терминов для определения концептов отношений между ними для конкретной предметной области. С помощью онтологий можно автоматизировать обработку семантики данных с целью ее эффективного использования (представления, преобразования, поиска). Соответствующий принцип обработки данных базируется на представлении описания предметной области как базы знаний, содержащей понятия и взаимосвязи, и ориентирован, в первую очередь, не на осмысление информации человеком, а на автоматизированную интерпретацию и обработку информации. Применение онтологий в информационных системах позволяет отразить реальную картину мира в виде понятий, отношений и выполнять различную интерпретацию [6, 7].
2 Проблемы проектирования и реализации информационных систем
Как уже отмечалось выше, разработка информационной системы начинается с процесса анализа предметной области и построения ансамбля моделей, описывающих с разных сторон предметную область, поставленные задачи и ограничения (требования), выдвигаемые заказчиком. Построенные модели подвергаются ревизии со стороны заказчика, обычно немного корректируются и передаются в реализацию. Команда программистов создает на основе моделей и описаний, собранных аналитиками на первом этапе, программный код информационной системы, выполняется его верификация и начинается этап внедрения системы. Взаимосвязь основных этапов проектирования и реализации информационной системы показана на рисунке 1.
Заказчик, получив законченный с точки зрения группы специалистов разработчика программный продукт, как правило, вспоминает о некоторых «особенностях» и «мелочах», которые обязательно должны быть реализованы, но которым не было уделено достаточно внимания группой аналитиков, работавших на первом этапе. Такая «забывчивость» со стороны заказчиков и исполнителей объясняется, в первую очередь, не наличием злого умысла, а отсутствием на первоначальном этапе у обеих сторон точного представления о том, как же должна выглядеть законченная информационная система, какие задачи и как должны с помощью нее решаться, каким образом будут отражаться результаты ее функционирования и др. Кроме того, команда разработчика, достаточно долго проработав над проектом, улучши- ла свои представления о предметной области и о поставленных перед ней задачах, а заказ- чик, ознакомившись с полученными результатами, может не только более четко сформули- ровать требования, но и в некоторых случаях радикально пересмотреть цели, которые необ- ходимо достичь с помощью внедрения и использования информационной системы.
Модели
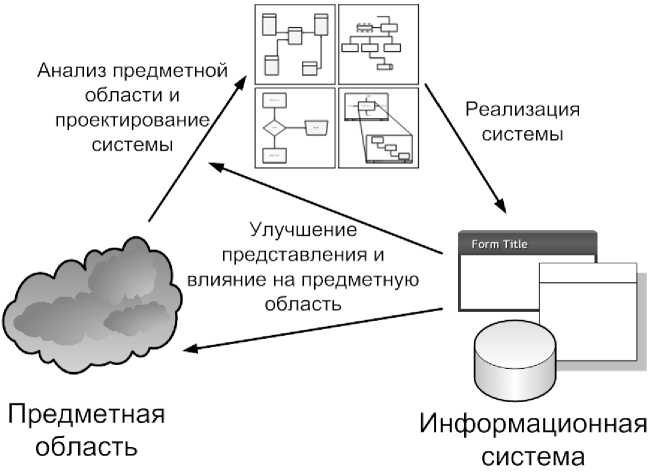
Рисунок 1 – Схема взаимосвязи проектирования и реализации информационной системы
Таким образом, одной из основных проблем реализации любой достаточно сложной информационной системы является ее тесная взаимосвязь с предметной областью. Изменения представлений о предметной области вызывает как сам факт появления информационной системы, так и улучшение субъективного понимания предметной области и выделенных в ней задач.
3 Модель предметной области как компонент информационной системы
Большинство программных систем претерпевает изменения, как во время разработки, так и в течение своей эксплуатации. Появляются новые требования, обнаруживаются ошибки реализации, становятся очевидными недостатки текущего дизайна. К сожалению, для небольших изменений часто возникает соблазн их исправить на этапе реализации, не возвращаясь к этапам анализа и дизайна. Это может потенциально усложнить процесс поддержки развития и модификации информационной системы в будущем, так как текущая модель не соответствует текущему коду. Но если проектировать информационные системы с использованием семантических сетей и технологий как частей этих информационных систем, то данной проблемы можно избежать, так как при изменении семантической сети будут изменяться и модель, и поведение системы. Предлагается ввести в архитектуру информационных систем некоторую легко изменяемую «вариативную часть», определяющую специфику предметной области, методов и задач, и представленную в виде семантической сети (рисунок 2). Ввиду достаточно широкого распространения онтологий для описания предметной области целесообразно применять именно их. В процессе работы семантическая информационная система должна использовать набор правил и интерпретировать сеть (онтологию) для ввода, обра- ботки, хранения и выдачи информации пользователям. Полное представление предметной области и решаемых в ней задач не обязательно – в виде онтологий может быть представлена лишь часть системы: модели хранения, алгоритмы преобразования или отображение данных.
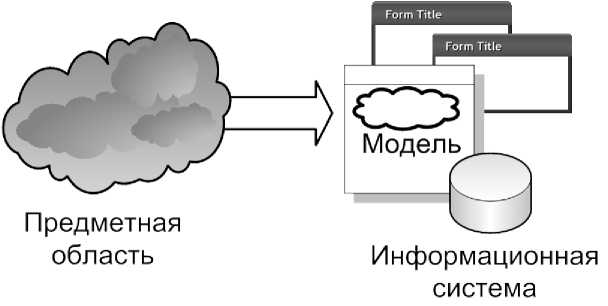
Рисунок 2 – Модель предметной области как компонент информационной системы
Информационные системы, созданные на основе семантических технологий, должны обладать новыми свойствами, которые, в первую очередь, будут проявляться в возможности быстрой их адаптации к изменяющимся условиям внешней среды: возможности модификации как моделей функционирования системы, представления и обработки данных, так и моделей взаимодействия со смежными системами.
Отличительной особенностью рассматриваемого подхода от MDA является применение онтологии не только для изменения архитектуры информационной системы, но и в процессе ее непосредственной работы. В отличие от MDA архитектура системы и порядок вызовов компонентов не изменяются в процессе её работы. В первую очередь при использовании предлагаемого подхода должны проявляться изменения в поведении самих компонентов, а не в структуре системы: рефлексия направлена не столько на «внутренний мир» программной системы, сколько на «понимание» семантики предметной области и её обработку.
Онтология, включенная в качестве компонента в информационную систему, в процессе интерпретации влияет на изменяемое поведение других компонентов. Таким образом, с помощью онтологии может задаваться конфигурация. Процесс конфигурирования семантической информационной системы может быть статическим (по запросу) или динамическим (постоянное конфигурирование). Статическое конфигурирование должно выполняться специальными средствами информационной системы, результатом работы которых являются пользовательские интерфейсы, модели хранения, правила взаимодействия и другие элементы. При динамическом конфигурировании интерпретация онтологии выполняется постоянно компонентами, ответственными за отображение информации пользователям, управление данными, взаимодействие с другими системами и пр. Неоспоримым преимуществом статического конфигурирования является скорость работы элементов (например, интерфейсов), однако такой подход уступает динамическому в гибкости. Применение смешанного конфигурирования, при котором настройки одной части компонентов задаются статически, а другой – динамически, позволяет сбалансировать требования производительности и гибкости.
4 Семантическая Web-система на базе компонентов ИТ-инфраструктуры исследований энергетики
Описанный выше подход нашел применение при проектировании и реализации ИТ-инфраструктуры в Институте систем энергетики им. Л.А. Мелентьева (ИСЭМ) СО РАН.
Создаваемая ИТ-инфраструктура исследований энергетики призвана облегчить разработку и использование различных информационных и вычислительных ресурсов. ИТ-инфраструктура, являясь интеграционной информационной и вычислительной средой для поддержки проведения исследований в энергетике, облегчает построение распределенных баз данных и программных комплексов, создание Web-ориентированных программных комплексов и оказание информационных услуг на основе наукоемких информационных и программных продуктов. ИТ-инфраструктура включает интеллектуальную инфраструктуру , интеграционную информационную инфраструктуру , распределённую вычислительную инфраструктуру и телекоммуникационную инфраструктуру [8, 9].
Одним из основных компонентов ИТ-инфраструктуры исследований энергетики является реализованный в рамках информационной инфраструктуры Репозитарий, который содержит информацию обо всех других компонентах, их местоположении и о способах доступа к ним [8]. Информационная инфраструктура интегрирует как информационновычислительные, так и интеллектуальные ресурсы. В информационной инфраструктуре выделяются три уровня (слоя): уровень модели метаданных информационной инфраструктуры, уровень метаданных и данных ИТ-инфраструктуры. Для построения модели информационной инфраструктуры используются онтологии, объекты ИТ-инфраструктуры описываются метаданными на основе созданной онтологии [6, 8, 10]. В Репозитарии ИТ-инфрастурктуры также представлены онтологии предметных областей (исследований энергетики), онтологии задач, онтологии хранилищ данных (описания баз данных). Основываясь на этой системе онтологий, можно достаточно легко находить «родственные данные» (морфологически близкие данные) в смежных программных системах, а онтологии использовать для автоматизации доступа к ним [10, 11].
Технологию использования информационной инфраструктуры можно разбить на четыре этапа: построение модели метаданных – на этом этапе определяются «правила хранения» метаданных; внесение метаданных – производится описание информационных ресурсов в информационной инфраструктуре; извлечение метаданных и извлечение данных – использование инфраструктуры для поддержки проведения исследований как интегрированного источника получения информации.
Модель метаданных Репозитария ИТ-инфраструктуры исследований энергетики (правила построения отношений и описаний объектов) была реализованы в виде онтологии, которая представлена на рисунке 3. Следует отметить, что эта модель не является жесткой и может изменяться в зависимости от структуры метаданных, которые предполагается хранить. Описания информационных ресурсов (метаданные) в Репозитарии представлены в виде онтологии экземпляров, связанной с описывающей модель онтологией. Физически эти онтологии хранятся во внутреннем представлении Репозитария и могут быть преобразованы в XML, RDF и др.
Доступ к представленной в Репозитарии информации может осуществляться через Web-интерфейс или с помощью программного интерфейса (API), позволяющего получить как модель хранения, так и данные, связанные с ней. Web-интерфейс также строится на основе модели метаданных, что позволяет достаточно легко адаптировать Репозитарий к специфике предметной области.
Репозитарий ИТ-инфраструктуры применяется в качестве ядра семантической информационной системы в двух проектах: для поддержки коллективной экспертной деятельности в области энергетики, для представления в сети Интернет информации о деятельности научнопедагогических работников (НПР) Национального исследовательского Иркутского государственного технического университета.
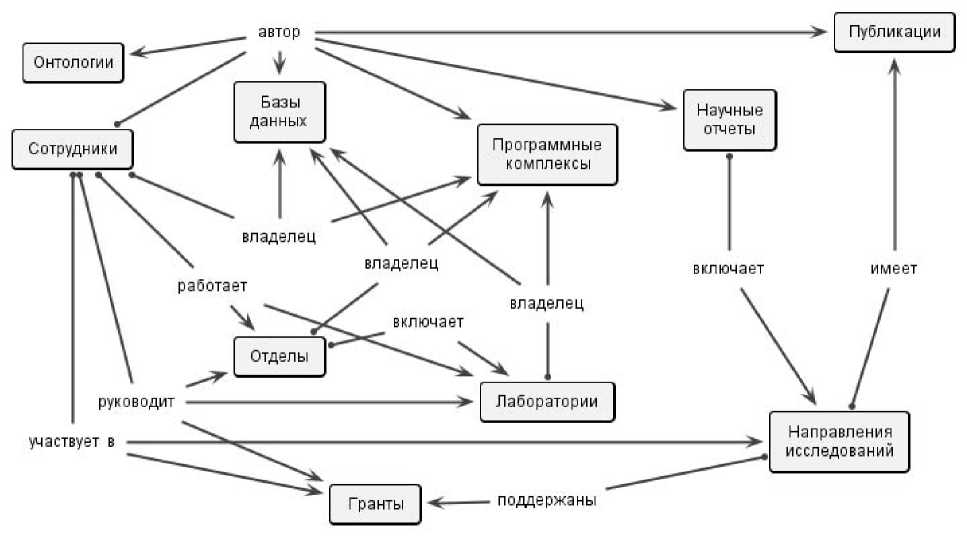
Рисунок 3 – Модель метаданных ИТ-инфраструктуры в виде онтологии для описания научной деятельности НПР
Согласно представленной технологии использования информационной инфраструктуры на первом этапе необходимо построение модели метаданных для представления информации в Репозитарии. Для моделирования метаданных разрабатываемой семантической информационной системы может быть использована среда построения онтологий GrM OntoMap, разработанная на основе ядра системы графического моделирования GrModeling [12]. Моделирование структуры хранения и представления информации на первом этапе значительно упрощает построение моделей преобразования данных из СУБД в XML-документы.
Обобщённая архитектура семантической информационной системы на основе Репозитария представлена на рисунке 4. Данные обрабатываются и загружаются компонентом, на вход которого поступают XML-документы, описывающие атрибуты, объекты и связи между ними. Ввиду того, что большая часть накопленной информации может содержаться в различных базах данных, была выполнена реализация компонента преобразования и выгрузки данных из СУБД. XML-документы, подлежащие загрузке, должны быть построены в соответствии с определёнными правилами, которые могут быть выражены в виде модели построения таких документов.
Для автоматизации построения последних был реализован компонент преобразования и выгрузки данных, интерфейс которого представлен на рисунке 5. Основное назначение этого компонента: преобразование данных, полученных посредством SQL-запроса, в один или несколько связанных объектов с атрибутами, представленных в виде документа XML, в соответствии с моделью. Модель результирующего XML-документа описывается с помощью правил формирования его элементов.
В общем случае загрузка любых XML-документов в Репозитарий допустима, однако их структура должна соответствовать «ожиданиям» компонента загрузки. Для преобразования структуры документов целесообразно использовать технологию XSL Transformations (XSLT). Преобразование, выраженное через XSLT, описывает правила построения конечного дерева XML-документа на основе другого исходного XML-дерева.
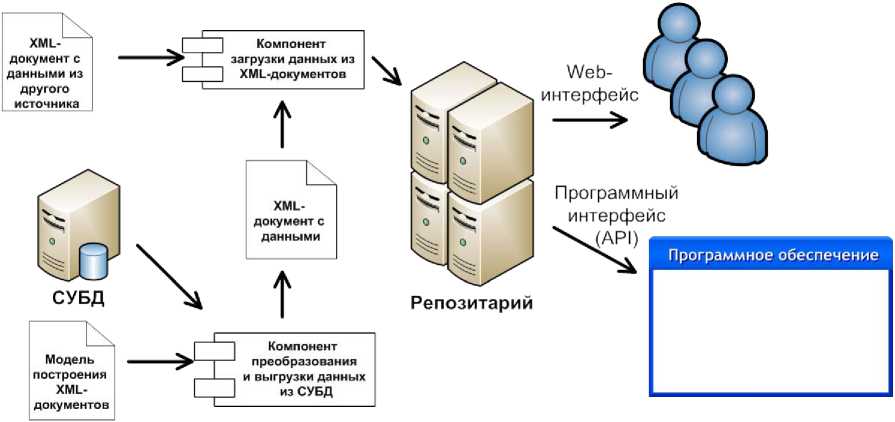
Рисунок 4 – Архитектура семантической информационной системы на основе Репозитария
Jnj2£ nje ке
□ Убрать пробелы в начале и в конце
□ Убрать двойные пробелы к Удалить ВСЕ пробелы
□ Ё-коррекция
□ Коррекция текста в "хорошем стиле"
ОК
Saia ct * fiго m [С отрудн и к и]
| Сотрудник?
Класс
Наименование объекта ФИО
Правила Результат Г
/-object = ФИО of Сотрудни | attr 'Фамилия Имя Отчее | те1 'Должность','’Сотрудж | ге1 'Ученая степеньТСоц: | ге1 'Ученое звание'ГСотт I attr'Телефон'= Телефот | rel 'Кабинет'ГСотрудники' '-object
0 Внешняя ссылка
Хранилище
0 Идентици
□ Только обого
Тип значения Строка (любые символы)
Коррекция регистра
О Не изменять Регистр
О Только первое слово с заглавной
О все прописные
@ ВСЕ СТРОЧНЫЕ
О Каждое Слово С Заглавной Буквы
Отмена
Выполнить
Авто правила
It-Мастер построения XML-документов - С:\РепозитЛаб34\2014РеЬР1ап\5о1:гисЫккх1:с
(ф Правило: Заголовок объекта
ЕВ Преобразование данных
Рисунок 5 – Компонент преобразования и выгрузки данных из СУБД
Таким образом, для построения семантической информационной системы на основе Репозитария необходимо:
-
1) выполнить моделирование структуры хранения и представления семантической информации будущей системы;
-
2) определить источники данных для загрузки (СУБД и пр.);
-
3) определить модели преобразования данных СУБД в XML-документы;
-
4) для загрузки XML-данных из других источников необходимо выполнить XSLT-преобразование;
-
5) выполнить загрузку сформированных XML-документов в Репозитарий.
После окончания загрузки пользователи получают доступ через Web-интерфейс к представленным в Репозитарии данным. Построение семантической информационной системы на основе Репозитария имеет два основных преимущества: во-первых, пользователи и другое программное обеспечение получают доступ к семантически связанным и описанным данным; во-вторых, данные могут быть относительно легко получены из различных источников, в том числе из СУБД, и описаны с помощью моделей. Кроме того, создание семантического описания данных и их привязка к онтологиям упрощает процесс интеграции и повышает используемость данных в различных информационных системах [11].
Пример интерфейса одной из разработанных систем представлен на рисунке 6. С помощью онтологий в данной системе задаются элементы пользовательского интерфейса (структуры меню), модель данных (14 концептов) и данные (более 50 000 концептов и более 250 000 отношений).

НАЦИОНАЛЬНЫЙ
ИССЛЕДОВАТЕЛЬСКИЙ
ИРКУТСКИЙ ГОСУДАРСТВЕННЫЙ
ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ

Модель метаданных
NATIONAL RESEARCH ИрГТУ в лицах
IRKUTSK STATE TECHNICAL UNIVERSITY
|
Подразделения Сотрудники Научные труды |
Инновации |
|
Факультеты НИ ИрГТУ |
Объекты интеллектуальной собственности |
|
• Геологоразведочный техникум |
Направления |
|
• Заочно-вечерний |
|
|
• Институт авиамашиностроения и транспорта • Институт архитектуры и строительства |
Приоритетные направления развития РФ |
• Институт изобразительных искусств и социально-гуманитарных наук
• Институт недропользования
• Институт экономики, управления и права
Рисунок 6 – Web-интерфейс информационной системы для представления информации о НПР Национального исследовательского Иркутского государственного технического университета
Заключение
Применение семантических технологий дает неоспоримое преимущество на всех основных этапах анализа, проектирования, реализации, тестирования и сопровождения информационных систем, в том числе описание семантики предметной области с использованием онтологий, как вариативной части информационной системы. Представленные в работе идеи были реализованы на практике и достаточно хорошо себя зарекомендовали. Подход к по- строению семантических информационных систем на основе Репозитария ИТ-инфраструктуры исследований энергетики позволяет достаточно быстро и относительно просто их разрабатывать. Естественным недостатком изложенного подхода являются ограниченные возможности по изменению конфигурации компонентов информационных систем, вследствие этого семантические информационные системы способны решать лишь тот класс задач, для которого они разрабатывались. Кроме того отказ от классического подхода вызывает некоторые трудности в проектировании и реализации компонентов систем из-за необходимости придерживаться абстрактного представления о предметной области. Однако возможность адаптации систем к изменяющимся условиям среды функционирования и приме-нениея их для решения задач определенного класса позволяет значительно сэкономить время и ресурсы.
Разработанный методический подход, технологии и инструментальные средства применяются в работах, выполняемых по грантам РФФИ №12–07–00359, №13–07–00140, №13–07– 00422, №14–07–00116, гранту программы Президиума РАН №229, а также в работах, выполняемых в рамках интеграционного проекта СО РАН №131. Автор выражает признательность этим организациям за частичную финансовую поддержку исследований.
Список литературы Применение онтологий в семантических информационных системах
- Федеральный Закон РФ от 27 июля 2006 г. № 149-ФЗ «Об информации, информационных технологиях и о защите информации».
- Соломатин, Н.М. Перспективы развития вычислительной техники: В 11 кн.: Справ. пособие / Под ред. Ю.М. Смирнова. Кн. 1: Информационные семантические системы / Н.М. Соломатин. - М.: Высш.шк., 1989. - 127 с.
- Люггер, Д.Ф. Искусственный интеллект: стратегии и методы решения сложных проблем. 4-е изд.: Пер. с англ. / Д.Ф. Люггер. - М.: Издательский дом «Вильямс», 2003. - 864 с.
- Тузовский, А.Ф. Системы управления знаниями (методы и технологии) / А.Ф. Тузовский, С.В. Чириков, В.З. Ямпольский / Под общ. ред. В.З. Ямпольского. - Томск: Изд-во НТЛ, 2005. - 260 с.
- Гаврилова, Т.А. Базы знаний интеллектуальных систем / Т.А. Гаврилова, В.Ф. Хорошевский. - СПб.: Питер, 2001. - 384 с.
