Проект создания китайско-русского параллельного корпуса официально-деловых текстов с дискурсивно-структурной разметкой

Автор: Мухин Михаил Юрьевич, Ян И
Журнал: Вестник Южно-Уральского государственного университета. Серия: Лингвистика @vestnik-susu-linguistics
Рубрика: Прикладная лингвистика и лингводидактика
Статья в выпуске: 4 т.13, 2016 года.
Бесплатный доступ
Статья посвящена проекту создания китайско-русского параллельного корпуса официально-деловых текстов с дискурсивно-структурной разметкой. Данная разметка заключается в описании структуры каждого абзаца в виде сети дискурсивных единиц, соединенных дискурсивными отношениями. Основу первичного наполнения корпуса составляют доклады о работе правительства КНР на китайском языке и их официальные переводы на русский. Выравнивание китайских и русских текстов в корпусе, т. е. их синтаксическое соотнесение, проводится по структуре каждого абзаца. В статье представлены история разработки проблемы создания синтаксических корпусов, общие задачи проекта, его теоретические основания и прикладные перспективы, критерии отбора текстов для корпуса, принципы разметки и выравнивания текстов, а также программное обеспечение для разметки и хранения данных (общая схема данных и интерфейс). Создаваемый корпус может быть в дальнейшем использован для решения задач машинного перевода и других алгоритмов автоматической обработки текста, обучения иностранным языкам, сопоставительной лингвистики, теории перевода и т. д.
Корпусная лингвистика, параллельный корпус, дискурсивно-структурная разметка, трибанк, китайско-русский корпус, дискурсивное выравнивание, автоматическая об работка текста, машинный перевод
Короткий адрес: https://sciup.org/147154030
IDR: 147154030 | УДК: 81'322 | DOI: 10.14529/ling160404
Building a Chinese-Russian parallel discourse structure corpus of official texts
This paper is devoted to building a Chinese-Russian Parallel Discourse Structure Corpus of Official Texts (CRPDT) that aims at producing a discourse treebank, in which Chinese and Russian parallel texts are manually annotated and aligned at the level of discourse structure. In this corpus, discourse units and their discourse relations are annotated for each paragraph in the parallel texts. Experimental research is based on the material of 4 Chinese source texts “Reports on the work of the Government” and their Russian translations. The paper presents the history and development of building discourse treebanks, the principles of annotation for building parallel discourse treebanks. This paper shows how to work on the discourse segmentation for Chinese-Russian parallel texts. Annotation and alignment tools take from Chinese-English Parallel Discourse Treebank. We postulate that the corpus might be useful for machine translation, language learning, translation studies, discourse analysis of Chinese and Russian texts and future Natural Language Processing.
Текст научной статьи Проект создания китайско-русского параллельного корпуса официально-деловых текстов с дискурсивно-структурной разметкой
Дискурсивно-структурная разметка в лингвистическом корпусе включает информацию о структуре дискурса, в том числе информацию об идентификации элементарных дискурсивных единиц, дискурсивных отношений, организации текста и т. д. Согласно теории риторической структуры, структура дискурса, или «структура связей», отвечает за организацию собственно текста и превращает его из простой последовательности предложений в некое единое целое [3, с. 159; 10]. Перед дискурсивной разметкой, или дискурсивным парсингом, стоит, таким образом, задача идентификации между различными дискурсивными единицами в тексте. На данном этапе теория анализа структуры дискурса, обращенная к обработке естественного языка, главным образом существует в английской исследовательской традиции.
В начале XXI века был создан первый корпус с дискурсивной разметкой – RST Discourse Treebank [5], основанный на теории риторической структуры [11] – далее ТРС. Разработанная в 1980-е годы американскими лингвистами У. Манном и С. Томпсон ТРС предлагает описание структуры дискурса в виде сети дискурсивных единиц, соединенных семантическими отношениями, причем, как правило, дискурс имеет древовидную структуру [3, с. 159], что определило появление и дальнейшее использование интернационального термина «дискурсивный трибанк». Иными словами, в дискурсивном трибанке на основе ТРС структура целого текста представлена в виде дерева.
Другой известный проект, Penn Discourse Treebank (PDTB), был создан в 2004 г. [13]. В 2008 году был представлен PDTB 2.0, состоящий из 2 304 текстов, в том числе 40 600 маркеров [15]. В этом корпусе были размечены дискурсивные связки, или коннекторы (discourse connectives), и их аргументы (arguments), что обеспечило более детальное описание структуры дискурса. Наряду с термином «дискурсивная связка» употребляются различные синонимы: «дискурсивный маркер», «метка» «связка клауз» и т. д. Под всеми этими терминами подразумеваются слова и фразы, которые необходимы для организации дискурса (состоящего по меньшей мере из двух связанных клауз), а их семантика является частью дискурса [7, 8, 16].
По модели Penn Discourse Treebank были созданы корпуса разных языков: Arabic Discourse Treebank [4], Prague Discourse Treebank [14], Chinese Discourse Treebank [17]. Модифицированная Теория риторической структуры была использована для описания структуры русского дискурса [3], устного дискурса в проекте Корпуса устной русской монологической речи [2], а также в проекте Корпуса текстов на русском языке [1].
Для разметки китайского дискурса предложена схема «Connective-driven Dependency Tree» – далее CDT, на которую повлияла Теория риторической структуры (идея древовидной структуры и центрального положения дискурсивных единиц), PDTB (участие дискурсивных связок) и китайские традиционные синтаксические теории [9]. Схема описывает структуру каждого абзаца китайского текста в виде сети клауз, соединенных дискурсивными связками, и применяется в процессе создания Китайского дискурсивного трибанка (Chinese Discourse Corpus with Connective-driven Dependency Tree Structure).
Появление дискурсивных трибанков повлияло и на развитие параллельных корпусов. Их создание является важным направлением, связанным с изучением современного переводоведения и совершенствованием машинного перевода. Сегодня параллельные корпуса используются для решения самых разных теоретических и прикладных задач. В соответствии с требованиями машинного перевода в параллельных корпусах должна проводиться более глубокая синтаксическая разметка.
Первый параллельный корпус с дискурсивноструктурной разметкой был создан в 2000 г. на основе ТРС [12]. Разметка в этом корпусе производится отдельно для исходных и переводных текстов. Следует отметить, что выравнивание текстов в этом корпусе, как и в других параллельных корпусах, проводится исключительно по единицам синтаксического уровня (предложениям и абзацам). Для создания более эффективной дискурсивной структуры в Chinese-English Discourse Structure Parallel Corpus (Китайско-английский параллельный корпус с дискурсивно-структурной разметкой) Feng предлагает новые принципы выравнивания текстов [6]. Общая идея заключается в том, что «выравнивание структуры двух текстов проводится по дискурсивным единицам и отношениям, а также по их иерархическим структурам» и осуществляется одновременно с процессом разметки [6, с. 159].
Проект создания китайско-русского параллельного корпуса официально-деловых текстов с дискурсивно-структурной разметкой, о котором идет речь в этой статье, основан на опыте Китайского дискурсивного трибанка [9] и Китайско-английского параллельного трибанка [6]. Мы используем платформу для разметки и параллельных текстов, созданную Feng Wenhe в 2013 г. [6]. Однако для нового проекта необходимо уточнить принципы разметки и выравнивания китайско-русских текстов, а также выработать особые принципы, определяемые особенностями китайского и русского дискурса.
-
1. Выбор текстов для корпуса
Различные параллельные корпуса создаются на материале официально-деловых текстов, особенно государственного и межгосударственного уровня – например, корпус слушаний Европарламента и др. Требования к точности перевода, к максимально полной соотнесенности таких текстов формализуют задачу и облегчают выравнивание корпуса.
На экспериментальном этапе в корпусе размещены четыре «Доклада о работе правительства КНР (с 2012 г. по 2015 г.)» на китайском языке и их переводы на русский. В будущем мы планиру- ем расширить корпус и включить в него еще шесть докладов, а также законы и официально-деловые тексты других жанров. На сегодняшний день объем корпуса составляет 931 абзац текста, 116 668 текстоформ, в том числе 46 190 текстоформ в русской части и 70 478 – в китайской.
При отборе источников учитываются следующие факторы:
-
1. Чтобы обеспечить качество перевода, исходные документы должны быть переведены известными специалистами или официальными учреждениями. Основной источник нашего материала – официальный сайт правительства КНР ( http://cn.theorychina.org/ ), который обслуживает Central Compilation & Translation Bureau , что в значительной степени гарантирует качество переводных текстов.
-
2. Выбранные документы должны характеризоваться относительной устойчивостью в структурно-семантическом плане. В частности, в «Докладах», с которыми ежегодно выступает премьер-министр, содержится много повторяющихся элементов (от слов до текстовых структур), что имеет большое значение для анализа языков оригинала и перевода и дальнейшего осуществления автоматической разметки в параллельном корпусе.
-
3. В отличие от перевода художественных произведений, при переводе правительственных документов большое внимание уделяется сохранению исходного смысла и структуры текста. Поэтому в исходном и переводном текстах совпадает порядок следования предложений, а структурные отношения в большинстве случаев являются взаимно-однозначными. Таким образом, облегчается задача выравнивания текстов оригинала и перевода.
-
2. Принципы разметки в корпусе
Вначале приведем в качестве примера размеченные параллельные тексты (1).
Исходный Текст (а):
а1[ 在 财政收支矛盾较大的 情况下 ,我们竭诚 尽力, ] @||@ a2[ 始终把改善民生作为工作的出发 点和落脚点, ] @| a3[ 注重制度建设, ] @||@ a4 [ 兜住民生底线, ] @||@ a5[ 推动社会事业发展。 ]
Переводной Текст (б):
б1[ При наличии довольно крупных противоречий между финансовыми доходами и расходами мы со всей искренностью] ||@ б2[неизменно брали за исходную точку и конечную цель всей своей работы улучшение народной жизни,] @| б3[уделяя особое внимание институциональному строительству,] @||@ б4[не допуская выхода за нижний предел обеспечения народной жизни] @||@ б5[ и стимулируя развитие социальных сфер.]
(«Доклад о работе правительства КНР», 2014 г.)
Квадратными скобками в этом примере выделены элементарные дискурсивные единицы (ЭДЕ); буквы и цифры между ними обозначают китайские клаузы, соотносимые с ними русские синтаксические единицы и их порядок. Количество вертикальных черт (знак «|») перед клаузой указывает на уровень иерархии в структурном дереве, к которому она относится. Дискурсивные связки подчеркнуты, а знак «@» обозначает центральное положение ЭДЕ в отношении между клаузами.
По этому примеру видно, что разметка в Китайско-русском параллельном корпусе включает такие параметры, как элементарные дискурсивные единицы и типы отношений между ними, дискурсивные связки и их семантические характеристики, центральное положение ЭДЕ, а также другую информацию об иерархической структуре. Теперь рассмотрим параметры разметки более детально.
Деление на элементарные дискурсивные единицы
В ТРС дискурсивная единица определяется рекурсивно: это либо любой отрывок текста, имеющий ТРС-структуру, либо элементарная дискурсивная единица [3, с. 163]. В дальнейшем, как правило, мы будем употреблять термины «элементарная дискурсивная единица» (unit), далее – ЭДЕ, говоря о единицах самого низкого уровня, и «дискурсивная единица» (text span), говоря о единицах любого объема.
В нашем корпусе ЭДЕ представляют собой конечные узлы в структурном дереве. Согласно англоамериканской традиции, ЭДЕ обычно равна клаузе [3, c. 163; 11, c. 245]. В русском традиционном синтаксисе термин «клауза» почти не используется; и в русской, и в китайской синтаксической науке единого определения клаузы не существует. На сегодняшний день единых критериев универсальных принципов выделения ЭДЕ для текстов, написанных на различных языках (в данном случае на китайском и русском), нет.
Перед нами стоит задача сегментации и выравнивания параллельных текстов. Если в исходном тексте членение на ЭДЕ совпадает с членением на клаузы, то в переводном тексте такое совпадение необязательно. Рассмотрим пример (2):
(А1) 这将鼓舞我们砥砺前行, (А2) 不断创造新 的辉煌。
-
(Б1 ) А это не может не вдохновить нас на неуклонное движение вперед (Б2) к новым блестящим успехам.
В исходном тексте компоненты А1 и А2 являются клаузами, а в переводном соотносимый с А2 компонент Б2 ( к новым блестящим успехам ) клаузой не является. Если наша задача заключается в обработке параллельных текстов, то их членение должно быть взаимообусловлено. С учетом теоретической базы и практического опыта при разметке корпуса мы выделяем ЭДЕ в исходном тексте, исходя из трех параметров:
-
1) грамматическая структура (ЭДЕ обязательно состоит из одной глагольной группы и одной или нескольких именных групп);
-
2) семантическая структура (в ЭДЕ содержится как минимум одно суждение);
-
3) формально-пунктуационная структура (между ЭДЕ обычно ставится знак препинания (запятая, точка с запятой, точка и т. д.), но не любое предложение со знаком препинания членится на ЭДЕ – например, 过去一年, ( в прошлом году ).
Выделение дискурсивных связок (коннекторов)
Дискурсивные связки в структурном дереве представляют собой узловые точки, которые соединяют дискурсивные единицы. В отличие от традиционного понимания функций союзов и союзных слов, дискурсивные связки соединяют разные типы конструкций – не только клаузы и предложения, но и сверхфразовые единства (например, вводное слово в частности ). Функцию дискурсивной связки могут также выполнять не только традиционные союзы и союзные слова, но и предлоги, наречия (в том числе неоднословные), вводные конструкции. Например, в примере (1), предлог при считается дискурсивной связкой, потому что функционально соотнесен с китайским аналогом « 在 ... 情况下 » в исходном тексте и так же указывает на отношение условия между клаузами б1 и б2.
Итак, при разметке исходного текста дискурсивная связка считается языковой единицей, которая соединяет клаузы или сверхфразовые единства и указывает на дискурсивное отношение между ними.
Функция дискурсивной связки может быть выражена и имплицитно, поэтому дискурсивные связки делят на эксплицитные и имплицитные. Эксплицитные связки подразделяются далее на одиночные (например, и, но, при, в частности, 并且 , 但是 , 尤其是 и т. д.) и двойные ( не только... но и..., хотя...но..., 不 ... 不 ... 而是 , 既 ... 又 ..., 虽然 ... 但是 .. . и т. д.).
Логико-семантические отношения в дискурсивном корпусе
В отличие от синтаксических отношений, дискурсивные отношения обладают прежде всего логико-семантическим характером. Li в докторской диссертации предложила классификацию, включающую 4 группы отношений (в их числе 17 разновидностей), с учетом асимметричности отношений, выделяемых в ТРС, и роли дискурсивных связок. Эта классификация основана на традициях китайских синтаксических теорий. Перечислим виды дискурсивных отношений, выделяемых Li.
-
1. Параллельные отношения (5): соединительные, последовательные, прогрессивные, альтернативные и сравнительные.
-
2. Противительные отношения (2): противопоставительные и уступительные.
-
3. Каузальные отношения (6): собственно каузальные, целевые, обстоятельственные, условные, гипотетические, а также отношения умозаключения.
-
4. Расширительные отношения (4): изъяснительные, заключительные, иллюстрационные и оценочные [9].
-
4. Принципы выравнивания текстовв корпусе
Эта классификация отношений была использована для выполнения разметки не только корпуса исключительно китайских текстов, но китайско-английского параллельного корпуса [6]. В существующую платформу для выполнения разметки, которая была создана Feng [6], интегрирован именно такой список отношений. Создавая подобный, но уже китайско-русский корпус, мы решили принять эту классификацию дискурсивных отношений за основу. Однако на практике различные виды отношений приходится адаптировать к материалу (официально-деловым текстам) и понимать расширительно (в особенности это касается русских переводных текстов).
Структурный анализ дискурса при разметке
Размеченная дискурсивная структура представляется в виде дерева зависимостей – иерархического графа, например, тексты (1) можно представить в следующей форме (рис. 1). В сущности, структурный анализ дискурса показывает степень близости соседних дискурсивных единиц в семантическом и грамматическом отношении. Такой подход к анализу параллельных текстов совпадает с общим пониманием структуры текста и процесса перевода, а также обеспечивает выравнивание исходного и переводного текстов по дискурсивной структуре.
Как показано на рис. 1, после членения текстов (1) на ЭДЕ, в данном случае на клаузы, приведенные ранее тексты можно представить иерархически. В узловых точках содержатся дискурсив- ные связки, которые репрезентируют дискурсивные отношения в текстах.
Поскольку оригинальный и переводной тексты проявляют структурную асимметричность, для построения корпуса необходимо обеспечить выравнивание текстов и их структуры. Мы берем за основу принципы выравнивания структуры дискурса для английского и китайского языков [6] и, модифицируя их, предлагаем конкретные принципы выравнивания для китайских и русских текстов, которые касаются параллельных дискурсивных структур, особенностей сегментации текста (т. е. выделения в нем элементарных дискурсивных единиц) и разметки логико-семантических отношений между ЭДЕ.
Дискурсивные структуры и элементарные дискурсивные единицы
Выравнивание структуры параллельных текстов начинается с членения параллельных текстов на ЭДЕ. По естественным причинам набор словоформ и устойчивых выражений в результате членения оригинальных и переводных тексты на ЭДЕ не совпадают. Например, в (1) структура дискурса оригинального текста (а) была представлена в следующей форме:
(а1), || (а2), | (а3), || (а4), || (а5).
Если не учитывать китайский оригинальный текст, деление русского переводного текста следовало бы представить в другом виде:
-
(б1 ) (б2), | (б3), || (б4), || (б5).
По этой причине наш анализ дискурсивных единиц начинается с исходного текста, что обеспечивает общую сегментацию параллельных текстов. Это означает, что сначала необходимо разбить оригинальный (китайский) текст на клаузы, а потом выделять в переводном (русском) тексте соотносимые фрагменты. Поскольку в нашем при-
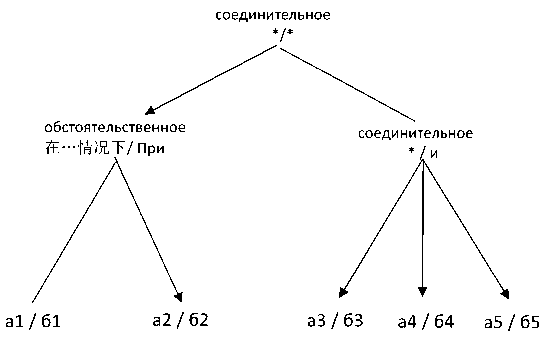
Рис. 1. Результат разметки и выравнивания текстов (1) в корпусе (Примечание: буквы и цифры обозначают китайские (а) и русские клаузы (б) и их порядок; в каждой узловой точке указан тип отношений и дискурсивная связка; звездочка (*) указывает на наличие имплицитной связки)
ме ре в ориги на л ь ном текс т е (а 1) и (а 2) явл яю тся двумя клаузам, иерархическая о рг ан и за ц ия в ко р пус е б у д е т пре дста вл е на сл ед ую щим обра з ом :
( а 1/ б 1), || (а2/б2), | (а 3/ б3), || ( а 4/ б4), || (а 5/ б5).
С ущ н ость в ыра в н ив ани я по Э Д Е з а ключа е тся в об щей пробл е м е с е гм е нт а ци и текс та , а в опрос о п ре де л е н ия грани ц Э Д Е с в оди тс я к тому, н асколько кру п н ыми и л и м е лким и м ог у т быть е д иницы разметки.
Выравнивание по дискурсивным отношениям между ЭДЕ
И с х од ный те кст явл яе тся для пе ре в одчи ка о б ъ е кти в н ой да н нос тью, п оэ том у с ре дс тв а в ыр а ж ен и я диск урс и в н ы х отн оше ни й в н ем та к ж е можно считать объективными. П ос кол ьк у пе ре в од о с у ще с твл яет с пе ц иа лис т, обл а дающи й и нд ивиду ал ьной яз ы ков ой спос обностью, пе ре в одной текс т в оп ред е л е н ной сте пен и от ра ж а е т поним ание п е р е в од чиком и с х од н ого текста . Иным и с л ов а ми, в пе рев од ном т е кс те в ы бор с ре дс тв в ыра ж ен ия логико-семантич е с к и х отнош е ни й субъ ект ив ен. Пе р е в од чик м ож е т и зм е н ить не тол ько с а м набор кл а у з и порядок и х сл е дова ни я, но и отношен ия ме ж д у н им и. Соотв е тс т в е н н о, на бор дис к у рс и в ны х о т ноше н ий м ы опре де ляе м п о пе рев од ному текст у . Т а ка я м е тодика с оотнос и т ра з м е тк у корп у с а со стра те гией п ере в ода . С р. п рим еры (3) и (4 ):
-
(3) Исходный текст (а) :
[ 在 财政收支矛盾较大的 情况下 ,我 们 竭 诚尽 力, ] [ 始终把 改 善 民 生 作为 工 作的 出 发 点和 落 脚点, ]...
Переводной Текст (б): [При наличии довольно крупных противоречий между финансовыми доходами и расходами мы со всей искренностью] [брали за исходную точку и конечную цель всей своей работы улучшение народной жизни,]...
«Доклад о работе правительства КНР», 2014 г.
-
(4) Исходный Текст (в) :
-
5. Программное обеспечение корпуса
[ 在 结构性矛盾突出的 情况下 ,我们积极作为, 有扶有控, ] [ 多办当前急需又利长远的事, ] ...
Переводной Текст (г) : [ В связи с острыми структурными противоречиями] [мы действовали активно и принимали поощрительные либо ограничительные меры,] ...
«Доклад о работе правительства КНР», 2015 г.
Китайская дискурсивная связка « 在 … 情况下 » употребляется в одном и том же значении при соединении клауз в исходных текстах (а) и (в). В переводных текстах (б) и (г) она переведена разными способами – дискурсивными связками (в данном случае предлогами) « При... » и « В связи с... », которые актуализируют обстоятельственное и каузальное отношения соответственно. Это означает, что и переводчик воспринял дискурсивную связку « 在 … 情况下 » в тексте (3) как выразитель обстоятельственного отношения, а в тексте (4) – каузального.
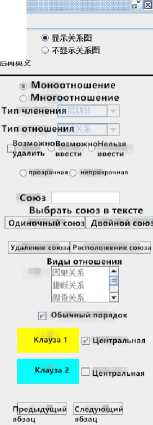
Разметка в данном корпусе проводится вручную с использованием специального программного обеспечения. Интерфейс платформы для структурной разметки параллельного корпуса, разработанный китайским ученым Feng [6], представлен на рис. 2. С помощью этого интерфейса можно пополнять корпус параллельными текстами и выполнять необходимую разметку и выравнивание конкретной пары языков (многоязыковая платформа поддерживает различные шрифты без ограничений в плане кодировки).
j
P.tM.»>|c«,TH. .,.»'"-<'•'"
™Hfc№*S№ggggE*6... К""”г каталог ।----- сохранении
| я®- I
ЗОНА 1
файл |(01).doc
- Qarpy^g
ЗОНА 2
® *ФЙЁ5вЙ
О ФЙ^»±йД*5
ЗОНА 3
ЗОНА 4
Исходный текст
Л№№$#.6ЙА;Й№)ЖТ, МЧММйО, й^№гК:№А 1^Ш1№.й№$№, аеадййй, .мж^^, йй^» ».$к„
Переводной текст
I [ри наличии довольно крупных противоречии между финансовыми доходами тт расходами мы со всей искретпгостыо неизменно брали за исходную точку и конечную цель всей своей работы улучшение народной жизни, уделяя особое внимание институциональному строительству, не допуская выхода за нижний предел обеспеченна народной лагиш и стимулируя развитие социальных сфер.
Удалить отношение
Поправить отношени(
Сохранить правку
ЗОНА 5
Рис. 2. Платформа китайско-русского параллельного корпуса с дискурсивно-структурной разметкой
В з оне 1 с ос ре доточе ны три ф ун к ци и п л атф орм ы: ра з м е тка , с та тис т и ка и у н иф икаци я разме тки (с ра в нен ие ра з м е тк и, котора я пров е де на р а з ным и пол ьз ов ате лям и). Зона 2 поз в ол яе т з агрузи ть текс т и в ыбра ть катал ог с ох ра не н ия ра з меч е н ны х д анн ых . Зон а 3 предс та вл яе т собой редактор отн ошен и й, которые м ож но с оз да в а ть, с ох р анять, у да л ять и ре дакт иров а ть. В в е рхней ча с т и зон ы 3 м ож но в и де ть ра з ме че нные о тношени я. В зон е 4 пре дс та вл е ны ис х од ный и пе ре в од ной те ксты. Зона 5 пре дна з на че на дл я в ы бора ра з м е ча емых свойств диску р си в ной стр ук т уры: диск урсивна я св язка , ти п отн ошен и я и д ру гие па ра м етры. Размеченные данные на ос нов е р ус ского и к ита йского текстов хранятся в XML- ф а й л ах . На р ис . 3 пре дс тавл ены фра гм е нты таки х фа й л ов .
Ф
орм
а
т х
ра
не
н
ия
да
н
ны
х на
чи
на
е
тс
я
с
им
волом и
-
• StructureType – т и п ч л ен е н и я ( пос л е дов ательное и параллельное);
-
• ConnectiveType – тип дискурсивной связки (эксплицитная или имплицитная);
-
• Connective – дискурсивная связка;
-
• RelationType – вид отношения (вышеуказанные 17 видов отношений – см. ранее);
-
• ConnectivePosition – место дискурсивной связки (если во фразе можно усмотреть имлицит-ную связку, то надо также указать ее место).
Такая платформа дает возможность одновременно выполнять разметку и выравнивание структур дискурсов для китайского и русского параллельных дискурсов. Она обеспечивает ввод двух параллельных текстов, деление на ЭДЕ, разметку и выравнивание структуры дискурса, разметку дискурсивных связок и дискурсивных отношений. Накопленная информация, которая хранится в формате XML, обеспечивает дальнейший поиск в корпусе.
Заключение
В данной работе мы представили новый современный проект – китайско-русский параллельный корпус официально-деловых текстов с дис-
-
-
Layer—"3" ConnectiveTvoe-'B^dtaeS" StructureType-"gEt№'/>
Connecti veTyре = '8Уёё,^'' StructureType-"#ЖОЙ'/ >
Рис. 3. Формат хранения данных в корпусе
курсивно-структурной разметкой. На сегодняшний день определены критерии отбора текстов для корпуса, принципы их разметки и выравнивания, а также особенности программного обеспечения. На этой базе создание такого корпуса представляется вполне осуществимым.
Мы предполагаем, что данный корпус может быть использован для машинного перевода, обучения иностранному языку (в данном случае русскому и китайскому), сопоставительного анализа структуры и перевода двух языков и решения других актуальных задач.
Способы разработки параллельного корпуса с дискурсивно-структурной разметкой еще нельзя назвать совершенными. Подлежит уточнению классификация типов логико-семантических отношений с точки зрения китайской и русской лингвистической традиции. Пока не однозначно формализована сегментация текстов и выделение ЭДЕ, а текстовая вариативность заставляет уточнять и принципы выравнивания исходного и переводного текстов. Кроме того, сама платформа должна быть более свободной, т. е. давать возможность аннотаторам добавлять в нее дополнительные виды дискурсивных отношений.
В ближайшем будущем мы постараемся решить указанные проблемы и пополнить корпус новыми текстами с переводом не только в направлении «китайский → русский», но и «русский → китайский».
Исследование выполнено при поддержке Программы повышения конкурентоспособности Уральского федерального университета (номер соглашения 02.А03.21.0006) и «China Scholarship Council».
