Разложение весов на интерпретируемые компоненты и их связь сo статистиками слоя нормализации

Автор: Шокоров В.А., Самосюк А.В.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Информатика и управление
Статья в выпуске: 4 (68) т.17, 2025 года.
Бесплатный доступ
В линейных пространствах существует определенный порог, описывающий уровень шума или уровень случайной корреляции. Линейные слои нейросетевых моделей, векторы (фичи) которых работают на взаимодействие с определенными фичами данных, также подвержены данному эффекту. Это позволяет OOD данным демонстрировать активации в пределах дисперсии обучающего домена в слоях нормализации (BatchNorm). Для оценки уровня случайного срабатывания используется декомпозиция матрицы весов линейного слоя на интерпретируемые компоненты: сигнальную (𝑊Δ) и шумовую (𝑊𝑟𝑎𝑛𝑑), основанная на границах распределении Марченко – Пастура. Эксперименты на ResNet-50 (обученная за счет ArcFace на MS1Mv3) с OOD-данными (COCO) показывают, что: (1) Взаимодействие обучающих данных с 𝑊Δ значимо выше, чем с 𝑊𝑟𝑎𝑛𝑑; (2) Распределение активаций OOD-данных при взаимодействии с 𝑊𝑟𝑎𝑛𝑑 и 𝑊Δ статистически неразличимо, что соответствует уровню случайного срабатывания. Мы заключаем, что 𝑊𝑟𝑎𝑛𝑑 служит эффективным индикатором порога случайной активации.
Статистики BatchNorm, спектральное разложение весов, объяснимый искусственный интеллект, распределение Марченко – Пастура
Короткий адрес: https://sciup.org/142247122
IDR: 142247122 | УДК: 004.93’1, 004.825
Decomposition of weights into interpretable components and its relation to normalization layer statistics
In linear spaces, a specific threshold describes the noise-level correlation. Linear layers in neural network models, whose feature vectors are designed to interact with particular data features, are also susceptible to this effect. This allows Out-of-Distribution (OOD) data to produce activations within the variance of the training domain in normalization layers (BatchNorm). To estimate the degree of random activation, we employ a decomposition of the linear layer’s weight matrix into interpretable components: a signal component (𝑊Δ) and a noise component (𝑊𝑟𝑎𝑛𝑑), based on the bounds of the Marchenko – Pastur distribution. Experiments on ResNet-50 (trained with ArcFace on MS1Mv3) with OOD data (COCO) demonstrate that: (1) The interaction of training data with (𝑊Δ) is significantly stronger than with (𝑊𝑟𝑎𝑛𝑑); (2) The distribution of OOD data activations when interacting with (𝑊𝑟𝑎𝑛𝑑) and (𝑊Δ) is statistically indistinguishable, corresponding to the level of random activation. We conclude that (𝑊𝑟𝑎𝑛𝑑) serves as a reliable indicator for the threshold of random activation.
Текст научной статьи Разложение весов на интерпретируемые компоненты и их связь сo статистиками слоя нормализации
В данной работе рассматривается поведение OOD (Out-of-Distribution) в контексте статистик слоя нормализации, в частности, BatchNorm (BN). Данные, явно не принадлежащие обучающему распределению (OOD и шум), демонстрируют активации попадающие в пределы дисперсии обучающего датасета. Существующие подходы, использующие статистики BN (анализ патчей [1], Mixture BN [2] или иные [10-13, 15-19]), не объясняют природу данного эффекта.
Таким образом, несмотря на значительный прогресс в понимании механизма работы BN, статистики BN могут работать не совсем так, как предполагается. Исследователи опираются на общую интерпретацию, что скрытое представление данных описывается гауссианой, через бегущие статистики (среднее и дисперсия). Такая постановка неявно предполагает, что в центре распределения, то есть в части пространства, наиболее вероятной для обучающих данных, будут лежать наиболее типичные представители обучающего домена.
Мы выдвигаем гипотезу, что подобное поведение обусловлено особенностью линейных слоев в условиях ограниченной размерности скрытых представлений: неизбежным возникновением случайных корреляций (случайных срабатываний) между весами сети и входными данными. Однако сеть способна проводить предсказание, а значит распределение активаций обучающих данных есть смесь двух распределений, одно описывает шумовые или случайные активации, второе описывает значимые признаки. Мы предполагаем, что предсказание на OOD-данных в значительной степени сводится именно к случайным срабатываниям. Для проверки данной гипотезы мы рассматриваем декомпозицию матрицы весов линейного слоя на две компоненты, вдохновленную работами по анализу спектра весов [3]. Первая компонента соответствует сигнальной компоненте, ответственной за извлечение значимых признаков обучающих данных, вторая — шумовой компоненте, описывающей случайные корреляции внутри обучающих данных. Распределение взаимодействия данных с шумовой компонентой используется как граница случайного срабатывания.
Основной вклад данной работы:
• Экспериментально показано, что OOD-данные и шум имеют активации, лежащие внутри распределения обучающего домена, сохраненного в статистиках BN.
• Вводится и проверяется гипотеза о взаимодействии OOD-данных с весами модели на уровне случайного срабатывания.
2. Обзор литературы
3. Постановка задачи
Анализ весов через сингулярное разложение представлен в [3-7]. Авторы [4] показали, что низкие сингулярные значения более подвержены шуму, когда высокие сингулярные значения выучиваются быстрее и напрямую влияют на обобщаемоств модели [5,6]. В [3,7] авторы анализируют распределение сингулярных значений, показывают, что данное распределение показывает качество обученности каждого слоя модели.
Применение SVD также позволяет дообучатв модель на новых данных, авторы [8] показывают, что дообучение низкорангового адаптера позволяет эффективно повышать качество модели на новом домене. Авторы [9] предлагают выборочно модифицировать малые сингулярные компоненты, при этом сохраняя остальные замороженными.
Статистики BN используются во многих задачах. Ключевое утверждение, на которое авторы опираются в работах, это то, что статистики BN описывают распределение обучающего домена. На этой идеи основываются: подходы доменной адаптации [10-12], переноса стиля [13], генерации изображений [14]; методы повышение генерализации модели, например ТТА (time test adaptaion) [15,16], или за счет повышения ее устойчивости [17,18].
В работе [2] авторы предлагают использовать Mixture BN для разделения смеси распределения. Разные классы и домены одного датасета не обязаны описываться единым гауссовым распределением. В работе [19] данная идея получила развитие, авторы показали, что различные каналы сети имеют разную чувствительность к разным классам, причем более поздние слои гораздо более чувствительны к изменениям в распределении меток классов.
Подход, описанный в [18], позволяет повысить качество модели за счет добавления шума в данные, который влияет только на статистики BN.
Рассмотрим промежуточный линейный слой модели. Каждая фича данного слоя предназначена для взаимодействия с определенным паттерном в данных. Однако, вследствие ограниченной емкости низкоразмерного представления и линейности пространства, неизбежно возникновение случайных корреляций между фичами весов и данными. Таким образом, внутри сети существует определенный порог шума, случайного срабатывания.
В работе [3] анализируются сингулярные значения весовых матриц, которые частично описываются распределением Марченко - Пастура (М-П). Авторы подчеркивают, что во время обучения веса представляются в терминах «noise plus signal», и отмечают, что хорошее соответствие распределению М-П не означает, что весовая матрица является случайной, а только выглядит как случайная.
Мы используем шумовую компоненту в качестве индикатора для оценки порога случайного срабатывания. Предполагается, что случайные срабатывания имеют гауссово распределение вокруг нуля (схожее с распределением корреляции двух случайных векторов).
3.1. Декомпозиция весовых матриц на компоненты
Пусть ТУ есть тензор весов свертки размером (Gout х С™ х К х К), где С™ — число входных каналов, Gout — выходньie каналы, К — размер ядра свертки. Для деком-позпщш W. W трансформируется в матрицу W m размером (Cuut х Cin • К 2). Для данной матрицы применяется нормировка каждой строки, затем спектральное разложение (SVD) W m ~ diag(a) • U • diag(s) • Н, где вектор & — есть коэффициенты нормировки. Рассчитываются правая ( Xmax) граница распределения М-П для матрицы с заданными размерностями ( п = См • К 2. m = Gout) ii пара.метром с = min(n,m)/max(n, m):
Xmax = (1 + Vе)2.
Вектора srand и 5Д описывают используемые направления. Они имеют только два значения: 0 ii а. а определяется так. чтобы норм а каждого вектора равнялась 1.
Г Si >Amax ^ .- =0,
|^ Si < Amax ^ S^ = 0
для Vi < min(n,m). Весовые матрицы, соответствующие каждой группе сингулярных значений, реконструируются с использованием матриц U и Н:
Wrand = diag(a) • U • diag(srand) • Н, W д = diag(a) • U • diag(s^ • Н. (1)
Равенство норм srand 11 sa обеспечивает равенство норм операторов Wrand 11 W A. Данные компоненты используются для анализа взаимодействия данных с направлениями сохраненными в W.
4. Методология
Используется модель сверточной нейронной сети ResNet-50 [21]. Модель была обучена на задаче распознавания лиц, на датасете MSlMv3 [20], функция потерь ArcFace [14]. Используется SGD с линейным понижением 1г с 0.1 до 0, величина weight decay 5е-4, размер батча 512, 20 эпох. Все тесты основываются на обученной модели, веса которой заморожены. Слои BatchNorm используют накопленные статистики, за исключением самого первого слоя нормировки для балансировки цветовой гаммы изображений.
На графиках (4, 5) используется дополнительная аннотация архитектуры сети, представленная в виде схемы внизу графика. На схеме отображается последовательность прохождения вдоль сети, причем на схеме отображены только слои свертки. Модель состоит из четырех ступеней (stage). В начале каждой ступени используется блок снижения размером (downsample), свертки с номерами: 2, 9, 18, 47. Также в модели используются SkipConnection-ы, представленные в виде огибающих снизу дуг.
Для тестирования используется два домена:
• In-Distribution (ID): изображения лиц из обучающего датасета (MSlMv3), принадлежащие часто встречающимся классам.
• Out-of-Distribution (OOD): кропы объектов (без класса «Person») из датасета СОСО [22].

а)
Рис. 2. Пример тестовых данных: ID-данные (а), OOD-данные (б)

б)
5.1. Взаимодействие данных с Жrand и Wл
исходными компонентами. Авторы предложили метод, где задают каждому объекту некоторый вектор из высокоразмерного пространства ( d ~ 104). После чего, группируя (суммируя) вектора объектов каждого класса, получают вектор класса, который имеет bbicokoio корреляцию (т.е. описывает) с каждым из объектов данного класса, сохраняя околонулевое значение с остальными данными.
Предполагается, что Тд имеет схожий механизм формирования и работы. За счет градиента аккумулирует значимые признаки обучающих данных как взвешенную сумму, демонстрируя свойства, аналогичные VSA. Ведь градиент для линейного слоя есть линейная комбинация данных пришедших в данный слой. На этапе тестирования модели высокое значение активации соответствующего нейрона - значит сходство тестового объекта с набором обучающих данных. Если тестовый объект не относится к обучающему домену, то не может быть высокой активации.
Прохождение обучающих данных через W л в терминах VSA приводит к изменению взаимных углов, а также снижению локальной размерности (ранга). Это является следствием второга свойства высокоразмерных пространств, ведь данное преобразование делает далекие объекты близкими. Ортогональная матрица сохраняет расстояние.
В промежуточных слоях данные представляются в виде векторов, которые являются суммой определенного набора фичей (подвекторов). Интенсивность фичей в данных определяет направления векторов (скрытых представлений сети, эмбеддингов). Фичи, которые сохранены в весах слоя, разбиваются по направлениям на две группы: Wrand и W Л (метод разложения см. в и. 3.1)
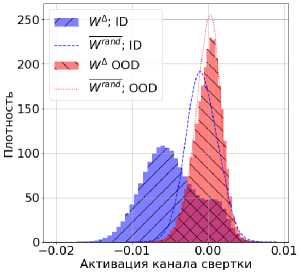
Рассмотрим распределение косинусной близости ID-данных (рис. 3). Так как Wrand и W Л имеют различный ранг, то для получения сопоставимого результата используется модификация матрицы Wrand. После перемножения эмбеддингов и низкоранговой матрицы, дисперсия распределения косинусной близости вырастет, причем низкие ранги обеспечивают высокие значение дисперсии. Для компенсации данного эффекта, из Wrand случайным образом выкидываются направления так, чтобы ее ранг совпадал с рангом W Л, например, за счет зануления ячеек в srand (1), с последующей перенормировкой. Модифицированную матрицу обозначим как Wrand.
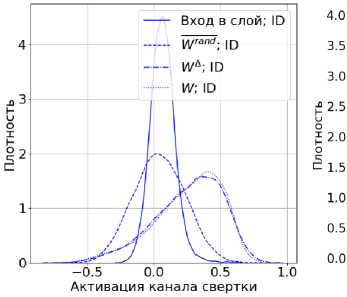
На рис. За, б представлены распределения косинусной близости данных после взаимодействия с различными направлениями. Наблюдения и выводы:
-
• Мода распределения входных ID-данных совпадает с Wrand ID (дисперсия растет из-за того, что Wrand не имеет полный ранг). Следовательно, Wrand не содержит значимых фичей данных.
-
• Мода распределения входных ID-данных значительно отличается от WЛ ID. Значит WЛ содержит значимые фичи данных.
-
• Распределения Wд ID-схоже с W ID. Следовательно, W Л обеспечивает ключевой вклад в трансформацию сигнала при прохождении через слой.
-
• Распределения, соответствующие OOD, имеют совпадающие моды, а, значит, OOD не содержит фичей, сохраненных в весах.
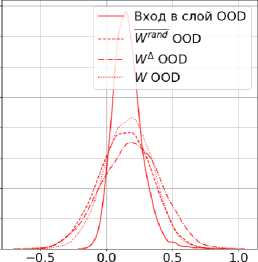
Помимо изменения взаимных распределений, поведение Wrand и W Л отличается на уровне активаций нейронов. На рис. Зв представлено распределение одного из каналов свертки. Выбран презентабельный канал. Распределение взаимодействия с Wrand OOD-данных незначительно отличается от распределения взаимодействия с WЛ. Значит OOD-данные взаимодействуют с данными направлениями одинаково, то есть на уровне корреляции со случайными направлениями.
Графики (рис. 3) интерпретируем так, что данные OOD не имеют соответствующих фичей с которыми взаимодействует W д. Данная степенв взаимодействия описв1вает уровенв случайного срабатывания. 1И-даннв1е ведут себя ожидаемым образом, имеют значительные различия в распределениях.
а)
Рис. 3. Распределения косинусной близости данных ID (а) и OOD (б), распределение активации капала свертки (в) после применения различных матриц. Вход в слой — данные па входе в слой. W rand — модифицироваииая W rand с усеченным рантом до ранга W Л. W — матрица сохраненная в весов свертки
Активация канала свертки
б)
в)
На рис. 4 представлен график близости распределений взаимодействия данных с WЛ и W rand для каждой свертки вдоль всей модели. В качестве меры близости используется симметричная дивергенция Кульбака-Лейблера. Данный график подтверждает наше утверждение, что OOD взаимодействует с W значительно хуже, чем ID.
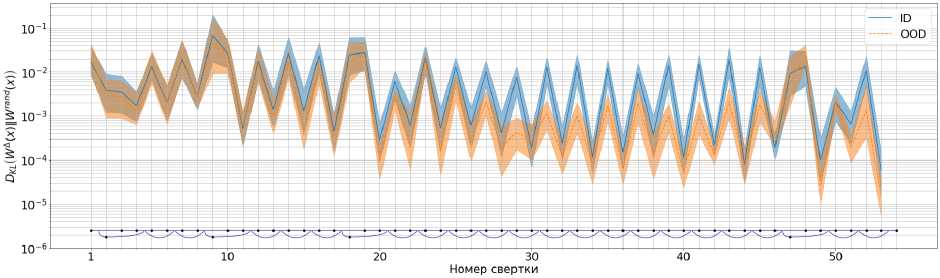
Рис. 4. График близости распределений взаимодействия данных с W л и W rand для каждой свертки вдоль модели. В качестве метрики близости используется симметричная KL-дивергенция. Для визуализации используются заполнение между 25-м и 75-м квантилями значений каналов. Сплошная линия соответствует 50-му квантилю
Важным отличием случайного взаимодействия является то, что оно должно быть распределено вокруг нуля. На рисунке 5 представлено среднее значение активаций по всем каналам свертки при взаимодействии с W л и Wrand. Как и ожидалось, среднее значение взаимодействия с Wrand находится вокруг нуля.
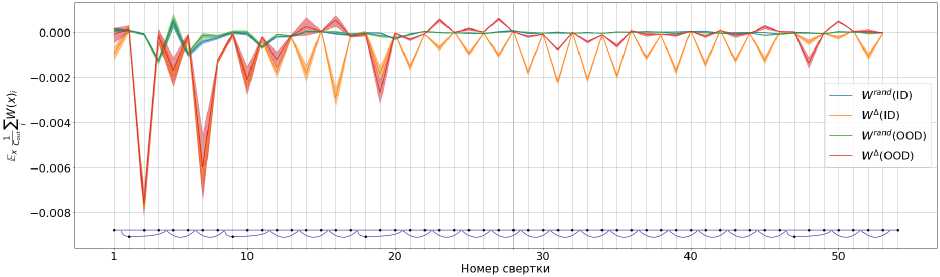
Рис. 5. Среднее значение активаций по всем каналам свертки при взаимодействии с W Л и W rand для каждой свертки вдоль модели. Для визуализации используются заполнение между 25-м и 75-м квантилями значений каналов. Сплошная линия соответствует 50-му квантилю. На графике представлены значения для двух доменов: реальные лица и OOD. Отношение среднего значения близости
6. Заключение
В данной работе мы демонстрируем, что статистики BatchNorm (BN), традиционно интерпретируемые как дескрипторы распределения обучающих данных (ID), систематически включают активации, порожденные шумом и случайной корреляцией с векторами весов. OOD-данные активируют именно подобного рода активации. Ключевой парадокс заключается в том, что такие данные концентрируются внутри дисперсии ID-распределения -преимущественно вблизи нуля, соответствуют шумовым активациям.
Для анализа активаций используется разложение весов на две компоненты: направления, отвечающие за значимые фичи W Л и второстепенные направления Wrand. Установлено, что Wrand служит эффективным индикатором порога случайного срабатывания, демонстрируя взаимодействия, подобные гауссовому распределению с центром в нуле. Мы показываем, что WЛ взаимодействует с OOD-данными значительно хуже, чем с W rand^ таким образом, взаимодействие OOD-данных с весами нейронной сети описывается в терминах случайного срабатывания, неизбежного в линейных пространствах скрытых представлений.
Предложенный метод разделения весов на компоненты обеспечивает способ проведения границы между значимыми и незначимыми фичами. Это может быть важно в задачах интерпретации. Полученные результаты также предлагают новый подход к OOD-детекции -через мониторинг расстояния (W ^(x);Wrand(x)) на скрытых слоях.
Наблюдаемые циклические паттерны на рис. 4, которые синхронизированы с блочной структурой ResNet, могут указывать на функциональную специализацию слоев. Предполагаем, что первый сверточный слой блока выделяет релевантные признаки. Второй слой регрессирует и выравнивает данные для интеграции в Residual Stream (минимальное расстояние распределений после второй свертки, рис. 4).
Дополнительно, заметна разница между ступенями модели. На рисунке 4 распределения расстояний ID и OOD-данных близки в первых двух ступенях, где происходит подготовка фичей данных для последующего анализа. В третьей ступени происходит ключевой процесс предсказания модели. Также отметим, что блоки снижения размерности не проводят предсказания, а только снижают размерность. Данные наблюдения согласуются с графиком и общей интуицией, но требуют более детального анализа.
