Разработка методов интеллектуального анализа научных публикаций для мониторинга приоритетных направлений развития превентивной и персонализированной медицины

Автор: Золотарев Олег Васильевич, Хакимова Аида Хатифовна, Шарнин Михаил Михайлович
Рубрика: Управление сложными системами
Статья в выпуске: 1, 2019 года.
Бесплатный доступ
В статье рассматриваются вопросы интеллектуального анализа научных публикаций для мониторинга приоритетных направлений развития превентивной и персонализированной медицины. Показано динамичное развитие методов определения современных тенденций в развитии медицины. Рассматриваются различные методы интеллектуального анализа научных публикаций. Проведен анализ публикаций медицинского электронного ресурса PubMed. Предложен метод выделения трендов в развитии направлений превентивной и персонализированной медицины на основе нейронных сетей.
Интеллектуальный анализ данных, приоритетные направления, прогнозирование, нейронные сети, векторное представление слов
Короткий адрес: https://sciup.org/148309514
IDR: 148309514 | УДК: 004.91; | DOI: 10.25586/RNU.V9187.19.01.P.109
Development of methods of intellectual analysis of scientific publications for monitoring the priority directions of development of preventive and personalized medicine
Keywords: data mining, priority directions, prediction, neural networks, vector word representation
Текст научной статьи Разработка методов интеллектуального анализа научных публикаций для мониторинга приоритетных направлений развития превентивной и персонализированной медицины
В настоящее время большое внимание уделяется вопросам прогнозирования и оценки развития научных дисциплин, выявления новых областей науки, выделения приоритетных научных направлений. Вычислительное моделирование эволюции науки, отслеживание «взлетов и падений» научных тем со временем приобретает значение для финансирования перспективных направлений исследований, для организации научных мероприятий, для корректировки стратегий развития технологических компаний.
В медицине для прогнозирования развития новых направлений используется широкий спектр методов и моделей, включая поточечные оценки, регрессионные и авторегрессионные модели, методы машинного обучения, основанные на байесовских сетях, искусственных нейронных сетях, методы фильтрации и др. Важную роль играет анализ публикаций, связанных с новыми направлениями в науке. В связи с громадным потоком неструктурированной информации и необходимостью обобщения результатов исследований в данной работе предлагается использовать методы анализа научных публикаций, основанные на рекуррентных нейронных сетях, с целью выделения наиболее приоритетных направлений развития превентивной и персонализированной медицины.
Методы прогнозирования в медицине
На основе анализа совместной встречаемости слов различных категорий и корреляции между ними был создан метод «co-word analysis» [8]. Он способствует выявлению ассоциаций среди терминов и на их базе построению сетей, отражающих картину эволюции любой дисциплины.
Метод семантического спектра позволяет исследовать динамику ключевых слов во времени и рассматривать аспекты структурных изменений в различных областях на основании анализа частот встречаемости ключевых слов [1]. По мере развития научного направления их частота растет, прекращение работ по какому-либо научному направлению приводит к уменьшению частоты встречаемости определенных терминов. Например, анализ по ключевым словам изменения тематики публикаций авторов из Казахстана
Золотарев О.В., Хакимова А.Х., Шарнин М.М. Разработка методов... 111
с 2004 по 2014 гг. показал, что темы «моделирование» и «астрофизика» в Казахстане находятся в развитии и в то же время отмечается снижение интереса к экологии водных ресурсов [2].
M. Steyvers и другие [12] предложили модель «автор – тема» (ATM) [14]. Она представляет документ как продукт смеси тем авторов, где каждое слово генерируется при активации одной из тем автора этого документа, но временное упорядочение отсутствует. D.M. Blei и другие [7] на базе модели АТМ предложили сегментированную модель «автор – тема» (S-ATM), которая интегрирует временные характеристики коллекции документов в генеративный процесс. S-ATM показывает возможность выявления эволюции тем с течением времени.
DTM (динамическая тематическая модель) разработана для отслеживания эволюции темы путем последовательного группирования совокупности документов на базе предположения так, что темы в текущем временном интервале плавно эволюционировали из соответствующих тем в предыдущем временном интервале (Wang и McCallum, 2006 [14]; Blei и Lafferty, 2006 [7], Wang, Zhai и Roth, 2013 [15], Tang и другие, 2013 [13]).
Электронные ресурсы в области медицины
PubMed – один из ведущих мировых медицинских ресурсов, он ежедневно обрабатывает миллионы запросов и является важным инструментом для исследователей в области здравоохранения во всем мире [11].
Научные исследования в медицине очень активны, количество журналов и проиндексированных ссылок в MEDLINE, крупнейшей библиографической базе статей по медицинским наукам, увеличивается со значительной скоростью. PubMed (http://www. является крупнейшим доступным ресурсом с 1996 г. Более 26 миллионов ссылок из MEDLINE, журналов по естественным наукам и онлайн-книг включены в PubMed в области биомедицины. На рисунке 1 представлены накопленные в MEDLINE и PubMed ссылки в период с 2013 по 2018 гг., по данным MEDLINE® STATISTICS . С ростом объема публикаций в медицинских науках отслеживание эволюции научных областей и прогнозирование будущих тенденций исследований имеют большое значение для ученых.
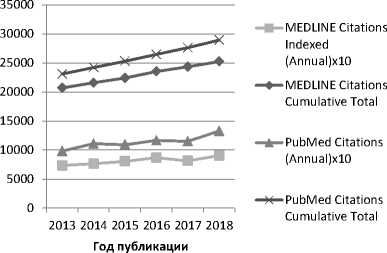
Рис. 1. Количество проиндексированных ссылок, накопленных, а также добавляемых в MEDLINE и PubMed в течение каждого года с 2013 по 2018 гг., по данным MEDLINE® STATISTICS
112 Выпуск 1/2019
Метод анализа научных публикаций: тренд-генерация
При обработке текста публикации формируются словари слов (общий словарь слов словарь слов предметной области, словарь текста), встречающихся в тексте, за исключением так называемых стоп-слов, т.е. общеупотребительных слов, таких как «также» «скорее всего», «может быть» и др. [4; 5]. При формировании словарей производится нормализация слов (перевод слов в единичное число, настоящее время, именительный падеж, неопределенную форму – для глаголов и т.д.) [3]. Далее подсчитывается частота встречаемости слова в тексте, формируются векторы слов. Структура словаря определятся следующим образом. Каждое слово в словаре представляется как вектор:
D = ((Main W , h ), ( W„ np v 1 ), ( Wv n 2, v 2), _, ( W k , nk , vk )), (1)
где Main W - основное слово словаря; h - частота встречаемости основного слова в текстах; Wk – k -е слово, стоящее в анализируемом тексте рядом с основным словом (парное слово); nk – количество раз, которое парное слово встретилось рядом с основным словом; v k - относительная частота встречаемости пары слов - основного и парного ( v k / h ).
Каждый словарь представляется в виде матрицы векторов. Обычно при формировании матрицы векторов слов выбирается размерность вектора в зависимости от задачи от 300 до 500, размер словаря (множества векторов) неограничен.
В результате формируются три словаря слов (множества векторов): словарь текста словарь предметной области, общий словарь.
Dgen – общий словарь;
D sub = { D i s , D 2 , -"’D k } - множество словарей предметных областей;
D doc = { D d , D d , •" , D dm } - множество словарей документов.
На основе этих словарей можно предсказывать наиболее вероятное следующее слово при анализе текстов. Наиболее популярные направления могут рассчитываться на основе вычисления максимального градиента относительной частоты встречаемости слов (терминов). Частота встречаемости пар терминов (частота события) называется статистической вероятностью. Для расчета градиента статистической вероятности необходимо ввести интервал дискредитации времени – частоту семплирования. Минимальный интервал семплирования устанавливается в размере одного месяца.
Для определения тенденций развития перспективных направлений может использоваться показатель частоты встречаемости терминов, что уже было описано. В данной работе предлагается использовать подход, основанный на увеличении частоты встречаемости множеств связанных пар терминов, которые образуют тему. Выделение тем может осуществляться разными способами. Один из наиболее употребительных на сегодня подходов – использование методов тематического моделирования. Эта методика основана на вероятностном определении множества тем документа.
В нашей работе для выделения наиболее перспективных направлений используется градиент статистической вероятности изменения частоты встречаемости пар терминов во времени (с учетом частоты семплирования). Чтобы добиться этого, необходимо формировать множество общих словарей попарной встречаемости терминов { D gen } в соответствии с частотой семплирования. В результате можно будет вычислять градиенты изменения статистической вероятности между множествами пар терминов по времени.
Золотарев О.В., Хакимова А.Х., Шарнин М.М. Разработка методов... 113
Для построения градиента сравниваются частоты встречаемости пар слов для последовательных во времени общих словарей – Dj и Dj +1 . Для устойчивых фраз градиенты изменения для пар связанных терминов будут похожими (термины связаны, если градиент изменения больше нуля). Анализ выполняется последовательно, сначала для первого главного термина, затем для связанного с ним парного термина, который выбирается далее в качестве главного слова. Так как векторы слов строятся последовательно, то максимальная цепочка слов, соответствующая ненулевому градиенту, и будет перспективной или развивающейся темой, фразой, направлением.
Если обозначить частоту встречаемости парного термина с основным термином как njk для текущего варианта словаря Dj , то nj +1, k будет определять ту же частоту для варианта словаря для следующего периода семплирования. Тогда для любого главного слова необходимо найти градиент возрастания частоты употребления указанной пары терминов:
grad ( Dj +1 ( Wk , nk , vk ), Dj ( Wk , nk , vk )). (2)
Множества пар связанных терминов образуют рекуррентную нейронную сеть. На входе нейронной сети – связанные пары терминов, на выходе – темы, фразы, наиболее динамично развивающиеся направления в различных отраслях знаний. Входными вершинами нейронной сети служат термины, веса – градиенты возрастания частоты использования пары терминов.
На рисунке 2 представлена рекуррентная нейронная сеть с входным, выходным и скрытым слоем, которая используется для поиска новых направлений исследований. На рисунке представлен один уровень скрытого слоя. Входной слой представляет однословные термины, несколько скрытых слоев образуют сочетание нескольких терминов в единое высказывание. При этом, как уже упоминалось, объединяются термины, соответствующие увеличению градиента частоты совместной встречаемости. Количество скрытых слоев определятся длиной высказывания. Если высказывание состоит из двух слов, то скрытый слой совпадает с выходным слоем, который представляет собой окончательное высказывание (фразу, набирающую популярность идею и т.д.).
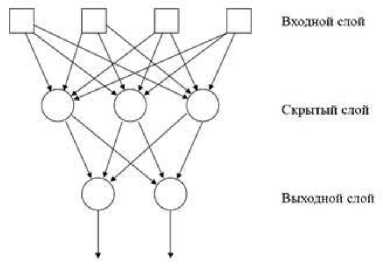
Рис. 2. Структура рекуррентной сети
Аналогичным образом можно строить словари предложений, но при этом не выполняется нормализация каждого слова и не удаляются стоп-слова. Каждое предложение входит в словарь в том виде, в котором оно встретилось в тексте. Подобный подход используется в современных системах автоматического перевода (Google, Яндекс и др.)
114 Выпуск 1/2019
Настройка сети происходит на основе большого количества параллельных текстов на разных языках, при этом настраивается перевод между парами языков. В результате сопоставления появляется возможность опосредованного перевода с одного языка на другой (если нет прямой настроенной сети для перевода с одного языка на другой, но есть опосредованная связь через пары других языков).
Как уже было сказано, для анализа развития новых направлений можно использовать подход на основе методов тематического моделирования. В зависимости от длины текста может генерироваться заданное количество тем документа.
Аналогичным образом, как уже отмечалось, строятся три словаря тем, подсчитывается частота встречаемости конкретной темы в документе, в словаре предметной области в общем словаре тем. Если частота встречаемости темы растет, то ее популярность увеличивается, в противном случае – уменьшается.
Описанные методы могут дополнять друг друга при сравнении результатов выделения определения тенденций при анализе публикаций.
Анализ тенденций публикаций PubMed
Мы провели анализ трендов в области 4Р-медицины (4П – на русском языке) и медицинской генетики за период с 1940 по 2018 г. [10].
В медицинской среде есть такое понятие – «Медицина 4П» , или «Медицина – 2030» «4П» – это аббревиатура от первых букв основных векторов новой медицины: предсказание, профилактика, персонализация и партисипативность (участие пациента).
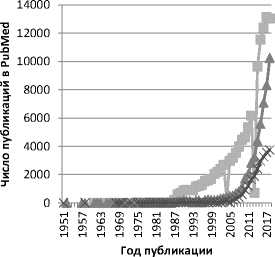
Анализ тенденций публикаций PubMed, демонстрирующий возросший научный интерес к области 4Р-медицины, охватывает период 1950–2018 гг. Использовались ключевые слова поиска: predictive medicine, personalized medicine, personalized treatment. Из графика (рис. 3) очевиден резкий рост числа публикаций в перечисленных областях, по-ви-димому, благодаря деятельности созданной в 2008 г. Европейской ассоциации предиктивно-превентивной и персонализированной медицины (EPMA – European Association for Predictive, Preventive and Personalised Medicine), активно продвигающей идеологию 4Р-медицины [9].
В работе [6] была показана возможность визуализации связанных объектов, выделенных из научных текстов с использованием A-Frame технологии.
- ■ - predictive medicine
—*—personalized medicine personalized treatment
Рис. 3. Статистика публикаций PubMed в области предиктивной и персонализированной медицины
Золотарев О.В., Хакимова А.Х., Шарнин М.М. Разработка методов... 115
Заключение
В результате анализа научных публикаций в области медицины показано, что предсказательная и профилактическая медицина становятся реальным трендом современности. Дальнейшее развитие медицины неотрывно связано с развитием новых перспективных направлений.
В данной работе описан метод определения трендов при анализе научных публикаций в области медицины.
Описанный в данной статье метод тренд-генерации предполагается использовать в целях анализа научных публикаций для мониторинга приоритетных направлений развития превентивной и персонализированной медицины.
Список литературы Разработка методов интеллектуального анализа научных публикаций для мониторинга приоритетных направлений развития превентивной и персонализированной медицины
- Courtial J.P. Is indexing trustworthy -classification of articles through co-word analysis/M. Callon, M. Sigogneau//J. Inf. Sci. 1984. Vol. 9, № 2. P. 47-56.
- Агеев Б.А., Черноног С.Б., Розуменко С.Б. Анализ развития научных направлений методом «семантического спектра»//НТИ. Сер. 1: Организация и методика информационной работы. 1990. № 5. С. 16-18.
- Акоев М.А. Картирование науки и технологии, прогноз развития//Руководство по наукометрии: индикаторы развития науки и технологии. Екатеринбург: Изд-во Урал. ун-та, 2014. С. 164-200.
- Rosen-Zvi M., Griffiths T., Steyvers M., Smyth P. The author-topic model for authors and documents. In: Proceedings of the 20th conference on uncertainty in artificial intelligence. Banff, Canada: AUAI Press, 2004. Р. 487-494.
- Wang X., McCallum A. Topics over time: a non-markov continuous-time model of topical trends//Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2006. Р. 424-433.
