Разработка моделей на основе методов машинного обучения для оценки кредитного риска банка

Автор: Муминова С.Р., Малышев А.А., Феоктистова В.М.
Журнал: Сервис в России и за рубежом @service-rusjournal
Рубрика: Инновации и технологии
Статья в выпуске: 4 (119), 2025 года.
Бесплатный доступ
Данная статья посвящена применению методов машинного обучения для реализации подхода на основе внутренних рейтингов (ПВР), называемого также IRB-подходом. Важно понимать, что переход на модельный метод оценки кредитных рисков сокращает размер необходимого резерва банка по сравнению со стандартизированным подходом, что приводит к более выгодному распределению активов банка, также подход развивает качество человеческого капитала, повышает устойчивость банковской отрасли. Для обеспечения функционирования ПВР-подхода необходима повсеместная интеграция языков программирования (Python / SQL), развитая IT-инфраструктура, позволяющая хранить и обрабатывать большие объемы данных в реальном времени, ежемесячный мониторинг ключевых показателей (LGD, Default Rate, CCF и др.) для контроля отклонения фактических значений от модельных, выражающееся через коэффициент Parity. В банке также должна существовать мастершкала кредитных рейтингов для розничного и корпоративного кредитования, соответствующая национальным и международным рейтинговым агентствам, определяющая бакеты вероятности дефолта. Для разработки моделей банк должен иметь соответствующее структурное подразделение, а также отдел валидации, проверяющий точность моделирования. Авторы статьи знакомят читателя с основными риск-метриками, использующимися в моделях, включая вероятность дефолта, уровень потерь при дефолте, величину кредитного требования, ожидаемые и неожидаемые потери. Задача статьи заключается в разработке кредитных моделей и интерпретации их результатов. Проект реализуется в интересах тех системно значимых банков, которые еще не перешли на IRB-подход.
Машинное обучение, подход на основе внутренних рейтингов, кредитный риск, вероятность дефолта, логистическая регрессия
Короткий адрес: https://sciup.org/140313779
IDR: 140313779 | УДК: 338.48 | DOI: 10.5281/zenodo.17600794
Development of a machine learning model for bank credit risk assessment
The paper deals with implementation of machine learning methods for realization of IRBapproach. One should note that the application of model method for credit risk assessment reduces the amount of necessary bank reserve compared to standard approach. That causes more profitable distribution of bank actives. In addition, the approach improves the quality of human capital as well as increases the stability of bank industry. To provide stable functioning of IRB-approach one should have total integration of programming languages (Python / SQL), developed IT-infrastructure for storage and processing big data in real time, monthly monitoring key indicators (LGD, Default Rate, CCF et al.) to control deviation of actual values from model ones, expressed by Parity coefficient. The authors observe principle risk-metrics, used in models, such as default probability, level of losses under default, amount of credit, expected and unexpected losses. There should be also master scale of credit ratings for private and corporate crediting in bank. The scale is to be corresponded to national and international rating agencies that determines buckets of default probabilities. To develop the models there should be a special department in bank as well as the department of validation that is responsible for controlling model accuracy. The authors present the principle riskmetrics used in models, such as default probability, default losses level, credit requirement, expected and unexpected losses. The aim of the paper was to develop credit models and to interpret their results. The study can be useful for those banks that have not integrated IRB-approach in operation processes yet.
Текст научной статьи Разработка моделей на основе методов машинного обучения для оценки кредитного риска банка
To view a copy of this license, visit
Ранее, в работе [8], было отмечено: один из самых существенных рисков, с которыми приходится сталкиваться банкам в рамках своей деятельности – это кредитный риск. Построение кредитных моделей было рассмотрено в рамках IRB-подхода (от англ. Internal Ratings-Based Approach – подход на основе внутренних рейтингов (ПВР)). В рамках регуляторных документов российского рынка разработка моделей покрывается Положением Банка России от 6 августа 2015 г. N 483-П «О порядке расчета величины кредитного риска на основе внутренних рейтингов».
Модели для оценки кредитного риска основаны на использовании статистических, эконометрических методах и машинном обучении (например, для моделей дефолта – это логистические регрессии, для моделей потерь от дефолтов – логистические регрессии и деревья решений). Машинное обучение (МО) – это совокупность математических алгоритмов, которые способны выявить закономерности в огромных массивах информации и на их основе построить прогнозные модели. Рыночная практика разработки подобных моделей зависит от размера штата отделов, специализирующихся на разработке кредитных моделей, наличием достаточного объема свободных средств для оплаты консультационных услуг, размером банка и числом кредитных продуктов, типа банка (розничный или универсальный) – то есть наличием как розничных, так и корпоративных моделей, основанных на разных предпосылках. В данной работе рассматривается исключительно розничный пример моделей для ознакомления с базовыми концепциями без трудоемких, но порой необходимых блоков (ввиду отсутствия необходимых выборок), включая рыночную поправку экономического спада downturn, моделей longrun для невызревших дефолтов, построением recovery rate и учетом характера взыскания дефолтных кредитов.
В данной работе была использована база данных Американской компании Lending Club, по сути, являющейся микрофинансовой организацией и занимающейся P2P-кредито-ванием (одноранговое кредитование) – схема кредитования, альтернативная традиционной банковской, отличающаяся высокой диверсификацией активов [1]. Процесс выдачи кредитов основан на прямом взаимодействии между физлицами. База данных содержит исторические наблюдения за 2007–2015 г., 75 переменных, 466 282 наблюдения.
Исторические наблюдения включают множество показателей, например, ежегодный доход заемщика, просроченная сумма задолженности по счетам, цель взятия кредита, стаж работы в годах, статус домовладения, следующая запланированная дата платежа, количество активных сделок, оставшаяся непогашенная основная сумма кредита, количество счетов с просрочкой платежа более 120/90/30 дней и др. Как видно из вышеприведенных показателей, их вполне достаточно для создания модели вероятности дефолта, оценки EAD и LGD. Также в базе данных достаточно много показателей, которые не участвуют в расчете EAD и LGD напрямую, но которые могут быть заложены в модель машинного обучения по оценке дефолтности с отбором факторов по степени их значимости. В конечном счете итоговая модель вероятности дефолта (PD) будет использоваться для расчета регуляторного капитала банка для покрытия кредитного риска.
Моделирование вероятности дефолта.
Модель вероятности дефолта является логистической (бинарной) регрессией, поэтому для определения зависимой переменной, т.е. переменной, отражающей факт свершения дефолта (0 – нет, 1 – да), используется переменная статуса кредита, которая включает в том числе определения дефолта – списан, просрочка 90+ дней, банкротство. Статусы действующего кредита, выплаченного и продленного исключаются из определения банкротства. Наибольшая удельная доля кредитов является действующей (48,09 %), далее идут полностью выплаченные кредиты (39,62 %) и списанные (9,11 %). Уровень дефолтности равняется 0,18 %, однако это не является объективной оценкой в виду требований Базельского комитета и Центрального банка РФ. Необходимо внести в статус дефолта вышеприведенные составляющие согласно определению дефолта.
Первым этапом является проверка на отсутствующие и пропущенные значения, а также трансформация качественных переменных в бинарные [2]. В случае, если показатели являются критически важными для расчетов (сумма кредита, ежемесячный платеж), то данное кредитное наблюдение по заемщику либо заполняется средним значением по данному показателю, либо заполняется нулем. Был проведен анализ по показателям с числом пропущенных значений. В частности, пропущенные значения по годовому доходу и кредитному лимиту заполняются средними значениями, а значение числа месяцев с момента открытия кредитной линии, количество счетов, по которым заемщик в настоящее время имеет просрочку, число оскорбительных комментариев заемщика в сети Интернет, количество случаев просрочки платежа более чем на 30 дней в кредитной истории заемщика за последние два года, стаж работы – заполняются нулем.
Прежде чем включать переменные в модель PD, необходимо провести проверку на мультиколлинеарность факторов [10]. На рис. 1 представлены некоторые из переменных кредитного портфеля, с остальными переменными, не отраженными на рисунке, проведены аналогичные расчеты. Например, очевидно, что корреляция между суммой кредита и месячным платежом высока (95 %), учитывая, что месячный платеж рассчитывается как доля от суммы кредита в зависимости от срока кредита и процентной ставки. Соответственно,
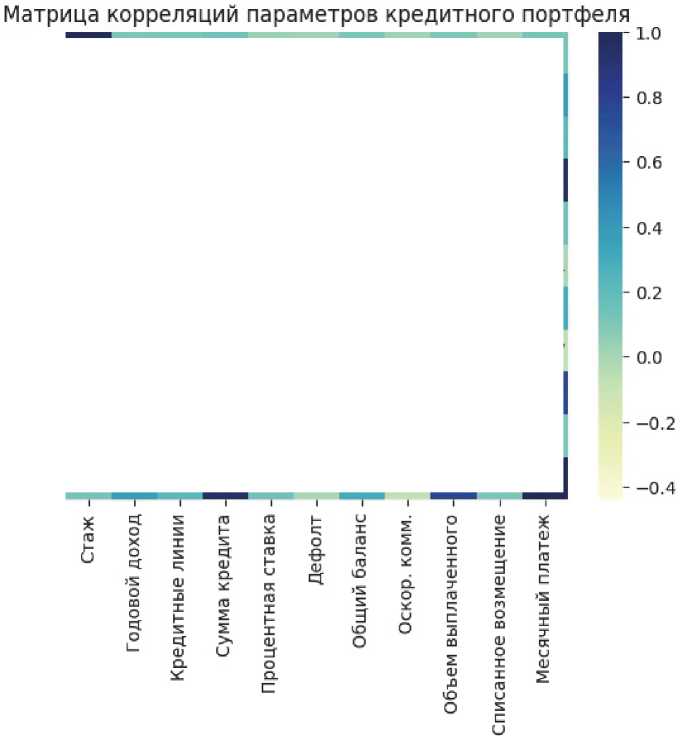
Рис. 1. Матрица корреляций основных параметров кредитного портфеля, составлено авторами
Fig. 1. Correlation matrix of credit portfolio general parameters, composed by authors
|
Стаж |
1 |
0.1 |
0.11 |
0.14 |
0.03 |
0.02 |
0.11 |
0.02 |
0.1 |
0.01 |
0.12 |
|
Годовой доход - |
0.1 |
1 |
0.22 |
0.37 |
-0.05 0.05 |
0.49 |
-0.02 |
0.3 |
0.02 |
0.37 |
|
|
Кредитные линии - |
0.11 |
0.22 |
1 |
0.24 |
-0.03 0.02 |
0.32 |
0.01 |
0.17 |
0.02 |
0.22 |
|
|
Сумма кредита - |
0.14 |
0.37 |
0.24 |
1 |
0.17 |
-0.01 |
0.33 |
-0.08 |
0.74 |
0.11 |
0.95 |
|
Процентная ставка - |
0.03 |
-0.05 |
-0.03 |
0.17 |
1 |
-0.17 |
-0.1 |
0.07 |
0.13 |
0.13 |
0.15 |
|
Дефолт - |
0.02 |
0.05 |
0.02 |
-0.01 |
-0.17 |
1 |
0.05 |
0.01 |
0.19 |
-0.44 |
-0.01 |
|
Общий баланс - |
0.11 |
0.49 |
0.32 |
0.33 |
-0.1 |
0.05 |
1 |
-0.08 |
0.26 |
0.01 |
0.3 |
|
Оскор. комм. - |
0.02 |
-0.02 0.01 |
-0.08 |
0.07 |
0.01 |
-0.08 |
1 |
-0.09-0.01 |
-0.07 |
||
|
Объем выплаченного - |
0.1 |
0.3 |
0.17 |
0.74 |
0.13 |
0.19 |
0.26 |
-0.09 |
1 |
-0.02 |
0.76 |
|
Списанное возмещение - |
0.01 |
0.02 |
0.02 |
0.11 |
0.13 |
-0.44 |
0.01 |
-0.01 |
-0.02 |
1 |
0.11 |
|
Месячный платеж - |
0.12 |
0.37 |
0.22 |
0.95 |
0.15 |
-0.01 |
0.3 |
-0.07 |
0.76 |
0.11 |
1 |
наблюдается функциональная зависимость и мультиколлинеарность в случае построения регрессионной модели. Исключим один из факторов пары, в которой наблюдается корреляция выше 0,5.
Далее была создана функция для определения веса значимости и ценности информации, Wo E. Вес значимости показывает, до какой степени независимая переменная сможет предсказать зависимую переменную, давая инсайт по тому, насколько данная категория независимой переменной полезна. Похожим образом ценность информации определяется в интервале от 0 до 1 и показывает, сколько информации несет исходная независимая переменная для объяснения зависимой переменной, помогая предварительно выбрать несколько лучших предикторов. Такая процедура производится для каждой качественной и числовой переменной. Рассчитанные значения весов значимости переменной наличия имущества расположены в табл. 1.
Табл. 1. Веса значимости для переменной качества кредита, составлено авторами
Table 1. Weights for credit quality variable, composed by authors
|
Владение имуществом Другое Аренда Владение Ипотека |
Число наблюдений 137 150 599 33 295 188 956 |
Вес значимости –0,74 –0,16 0,02 0,14 |
На примере владения имуществом мы делим их на три группы и объединяем в новые фиктивные переменные в зависимости от значимости и числа наблюдений: отрицательные значения показателя (аренда и другое), владение, ипотека.
Далее производится процесс применения логистической регрессии всех фиктивных переменных к целевой переменной – качеству кредита (плохой, хороший). Фиктивные переменные являются независимыми переменными, а показатель качества (дефолтности) кредита является зависимой переменной. Результатом расчетов является костанта модели, коэффициенты для каждой фиктивной переменной и p-значения (p- уровни значимости). На первой итерации используются все 104 переменных на обучаемой выборке 2007–2014 гг. После отсечения по принципу превышений модельных p-значений (0,05) при каждой переменной остается 85 переменных – незначимые переменные также отсекаются на тестовой выборке 2015 г. Повторяем процедуру расчета логистической регрессии уже с отсеченными незначимыми факторами и сохраняем результаты для дальнейших расчетов. Переходим к тестовому набору данных, который изначально был выделен из общей базы данных с размером в 20 % от первоначальной. Из тестового набора независимых переменных мы исключаем незначимые переменные, определенные на тестовом (тренировочном) наборе данных. И уже на отобранных тестовых переменных мы используем прогноз, основанный на показателях коэффициентов логистической регрессии, созданной на обучаемой части переменных показателей. Для каждого кредитного требования мы получаем прогноз в виде 0 или 1, которые обозначают факт дефолта или его отсутствие. Далее происходит похожий прогноз, но уже прогноз вероятности, где итоговое значение представляет собой значение вероятности от 0 до 1. Функция выдает двухсоставной вектор, который включает как саму вероятность положительного прогноза, так и вероятность некачественного прогноза (их сумма равна единице), оставляем вектор положительного прогноза. В результате мы получаем таблицу со значением дефолт / не дефолт (0 и 1 соответственно) и значение вероятности данного события для каждого кредитного требования.
Для проведения анализа качества построенной модели необходимо составить матрицу ошибок предсказанных значений с определенной точностью, в данном случае на уровне 0,9 (единица, если вероятность выше 0,9; ноль, если вероятность ниже 0,9), где для факта дефолта или отсутствия дефолта подсчитывается количество совпадений и несовпадений (табл. 2, 3) [4].
Табл. 2. Матрица ошибок логистической регрессии PD, составлено авторами
Table 2. Matrix of logistic PD regression errors, composed by authors
|
Фактическое/ Предсказанное |
0 |
1 |
|
0 |
7 361 |
2 829 |
|
1 |
35 786 |
47 281 |
Табл. 3. Матрица долей совпадений логистической регрессии PD, составлено авторами
Table 3. Matrix of tie deals of logistic PD regression, composed by authors
|
Фактическое/ Предсказанное |
0 |
1 |
|
0 |
0,079 |
0,03 |
|
1 |
0,384 |
0,507 |
Складываем диагональные значения и получаем общую точность предсказанной вероятности как дефолта, так и отсутствия дефолта логистической регрессии. Значение равно 0,586. Это означает, что если установлена граница в 0,9, то модель может правильно классифицировать примерно 59 % заемщиков. Поскольку вероятность выше 50 %, то это также значит, что вероятность не случайна (не равна 50 %). Однако если будет установлена другая граница, точность предсказания соответствующим образом изменится. Поэтому необходимы другие методы оценки качества модели.
На основании вектора с предсказанным значением факта наличия или отсутствия де-фолтности и вероятностью для обоих случаев можно построить ROC-кривую – кривую ошибок [3]. Данный график позволяет оценить качество данной бинарной классификации, отображает соотношение между долей объектов от общего количества носителей признака, верно классифицированных как несущие признак (чувствительность алгоритма классификации) и долей объектов из общего количества объектов, не несущих признака, ошибочно классифицированных как несущие признак при варьировании порога решающего правила. Каждая точка на кривой представляет собой различные матрицы совпадений в зависимости от выбранной границы (рис. 2).
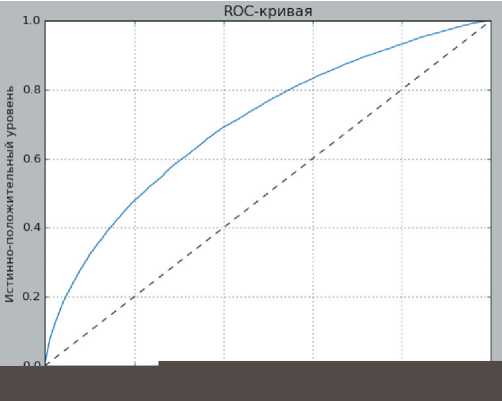
Рис. 2. ROC-кривая логистической регрессии PD, составлено авторами
Fig. 2. Logistic PD regression ROC-curve, composed by authors
С точки зрения количественной интерпретации ROC-кривой она представляет собой показатель AUC (Area Under Curve), который в свою очередь означает площадь, ограниченной ROC-кривой и осью ложно-положительных классификаций. В данной модели показатель AUC равен 0,702. Значение AUC, равное 0,702, означает, что модель обладает справедливой предсказательной возможностью. Не совсем идеальной, но пригодной для использования.
Также был визуализирован нормализованный коэффициент Джинни [6]. В машинном обучении он представляет собой метрику, выражающуюся как отношение коэффициента обученной модели к коэффициенту идеальной модели. Кумулятивная доля объектов – это количество объектов в отранжированном ряду. Коэффициент Джинни оценивает неравенство между хорошими и плохими заемщиками в популяции. Алгебраическое представление коэффициента Джинни представляет собой качество предсказания алгоритма. Коэффициент Джинни равен 0,404 (рис. 3).
Глядя на график Джинни, можно понять, что с ростом границы все большее число заемщиков отсекается. К примеру, если мы решим отсечь 20 % заемщиков (основываясь на нашей модели), то тем самым 40 % плохих заемщиков будут исключены, что означает, что модель времени. Такими показателями с учетом новых данных за 2015 год являются статус кредита, число прошедших месяцев после выдачи кредита и групповая оценка по остальным показателям, не включенных в таблицу. Необходимо избавиться от данных показателей в модели. Таким образом, модель вероятности дефолта построена.
Моделирование уровня потерь при дефолте
Оценка LGD представляет собой возможную долю потерь от суммы под риском, то есть той оставшейся суммы, которую заемщику еще предстоит выплатить банку. Информационная база для расчетов берется только за 2007– 2014 гг., поскольку оценка LGD должна строится именно на исторических значениях за прошедшие периоды. Зависимой переменной, то есть LGD, будет являться как раз процент возврата по просроченным выплатам, рассчитанный как отношение вернувшегося объема списанного кредита (в результате взыскания) к объему самого кредита. При этом важно учитывать, что в оценку закладываются только статусы кредита, которые были списаны. Полученная оценка процента возврата по просроченным выплатам превращается в фиктивную переменную со значением 1, если значение превышает 1, и 0, если менее единицы.
Построим график исторического распределения доли возврата по просроченным выплатам (рис. 5). Поскольку большая часть распределения говорит о том, кредитная организация имеет огромную долю нулевой доли возврата по просроченным выплатам, то формирование данной целевой переменной для LGD строилось по принципу: 0, если доля возврата была равна 0, единица в противном случае.
Для построения LGD модели также была применена логистическая регрессия, получены коэффициенты для каждой независимой переменной и определены p-значения. И уже на отобранных тестовых переменных мы используем прогноз, основанный на показателях коэффициентов логистической регрессии, созданной на обучаемой части переменных показателей. Для каждого кредитного требования мы получаем прогноз в виде 0 или 1, который обозначает факт равенства доли возврата по просроченным выплатам нулю в случае 0 и неравенства нулю в случае 1 соответственно. Далее для каждого такого прогноза высчитывается вероятность данного события.
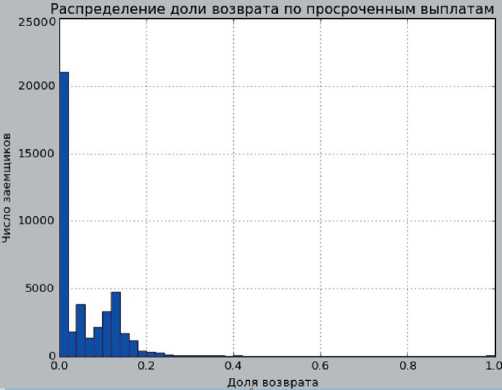
Рис. 5. Распределение доли возврат а по просроченным выплатам, составлено авторами
Fig. 5. Distribution of redemption deal of delinquent payments, composed by authors
На основании фактического прогноза переменной и вероятности, заранее выбранной на уровне не менее 0,5, рассчитывается число совпадений и несовпадений прогноза с данным уровнем вероятности (табл. 5). Значения вероятностей суммируются по диагонали и находится точность модели LGD, равная 0,62. Классификационный отчет модели представлен в таблице 10. Корреляция тестовых и прогнозных значений модели равна 0,52.
Табл. 5. Матрица долей совпадений логистической регрессии LGD, составлено авторами
Table 5. Matrix of tie deals of logistic PD regression, composed by authors
|
Фактическое/ Предсказанное |
0 |
1 |
|
0 |
0,177 |
0,257 |
|
1 |
0,123 |
0,442 |
Ниже представлен график ROC-кривой по модели логистической регрессии LGD и классификационный отчет. Показатель площади AUC равен 0,658.
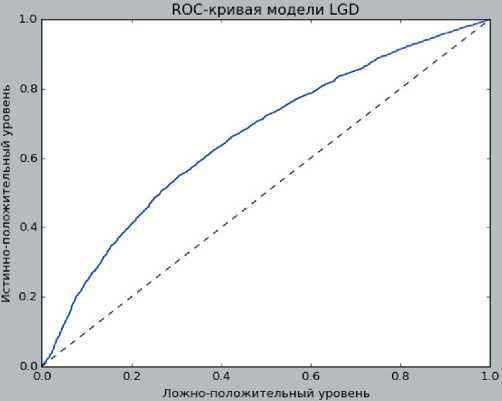
Рис. 6. ROC-кривая модели LGD, составлено авторами,
Fig. 6. ROC-curve of LGD model, composed by authors
Табл. 6. Классификационный отчет модели LGD, составлено авторами
Table 6. Classification report of LGD model, composed by authors
|
Показатель/Переменная |
0 |
1 |
|
Precision |
0,59 |
0,63 |
|
Recall |
0,41 |
0,78 |
|
F1-score |
0,48 |
0,70 |
|
Точность |
0,62 |
|
|
Число наблюдений |
3762 |
4886 |
Моделирование величины кредитного требования
Ввиду того, что компонентами величины кредитного требования (EAD) являются коэффициент кредитной конверсии (CCF) и сумма взятого кредита, только CCF является неизвестной моделируемой величиной, поскольку в его состав входит выплаченная сумма кредита, которая не определяется без факта дефолта заемщика. Зависимой переменной линейной регрессии являются исторические значения CCF (рис. 7).
По результатам модели линейной регрессии были получены новые значения коэффициента CCF для расчета EAD для каждого кредитного требования. Полученное распределение значений CCF (рис. 8) приводится к значениям в интервале [0, 1] – если значение CCF ниже 0, присваивается значение ноль, если выше единицы, присваивается значение единицы, во всех остальных случаях значение показателя остается неизменным. Распределение похоже на нормальное, медиана равна 0,01, что говорит о хорошей предсказательной силе.
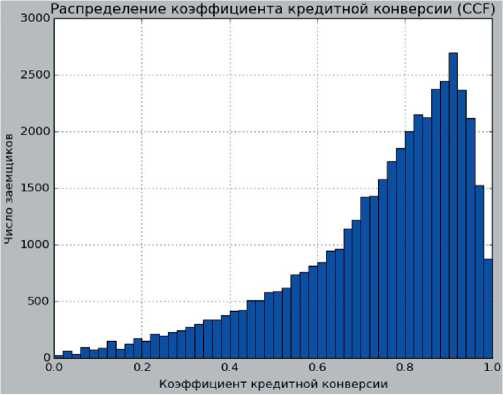
Рис. 7. Историческое распределение коэффициента кредитной конверсии CCF, составлено авторами
Fig. 7. Historical distribution of CCF credit conversion coefficient, composed by authors
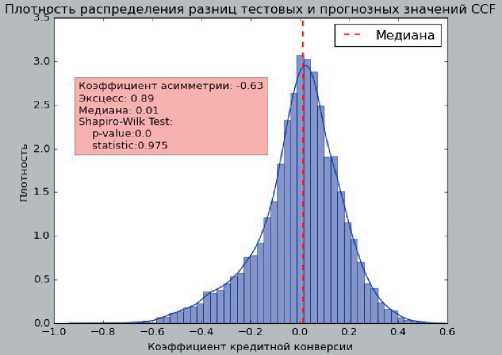
Рис. 8. Плотность распределения разниц тестовых и прогнозных значений CCF, составлено авторами
Fig. 8. Density of distribution of test and prognostic CCF values, composed by authors
Также была проанализирована автокорреляция остатков графическим методом (рисунок 9) и критерием Дарбина – Уотсона (DW) [5].
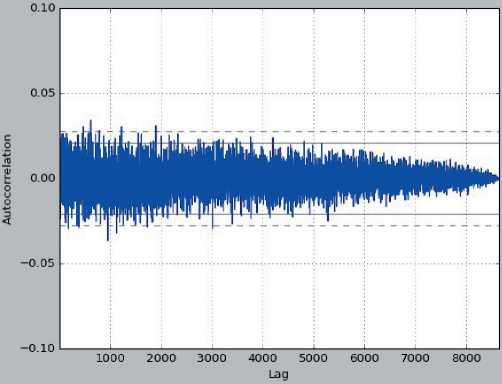
Рис. 9. Автокорреляция остатков модели CCF, составлено авторами
Fig. 9. Autocorrection of rest of CCF models, composed by authors
Для каждой переменной был рассчитан коэффициент линейной регрессии и p-значения. Было отсечено 11 переменных с p-значениями, превышающими 0,05. Статистика и тесты по модели расположены в таблице 7.
Оценка потерь и кредитного риска IRB-подхода
В результате расчета показателей PD, LGD, и EAD открывается возможность для расчета ожидаемых и неожидаемых потерь и общей оценки данных показателей по кредитному портфелю (рис. 10, табл. 8).
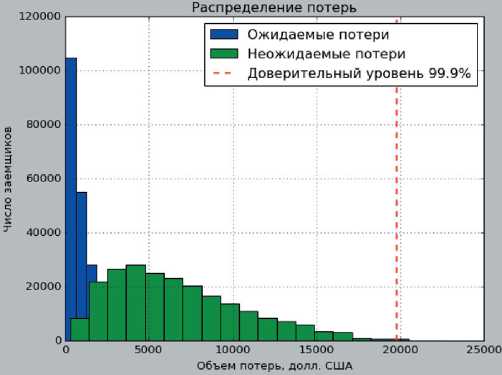
Рис. 10. Распределение ожидаемых и неожидаемых потерь кредитного портфеля, составлено авторами
Fig. 10. Distribution of expected and unexpected losses of credit portfolio, composed by authors
Табл. 7. Статистика и тесты по модели CCF, составлено авторами
Table 7. Statistics and test results for CCF model, composed by authors
|
Показатель |
Значение |
|
Корреляция теста и прогноза |
0,75 |
|
R2 |
0,83 |
|
Средняя абсолютная ошибка (MAE) |
0,129 |
|
Среднеквадратическая ошибка (MSE) |
0,03 |
|
Квадратный корень из MSE (RMSE) |
0,17 |
|
DW |
1,991 |
|
F stat; F crit |
73,07; 1,35 |
Далее для определения модельных значений EAD необходимо умножить получившиеся значения CCF для каждого кредитного требования на сумму кредита. Полученная оценка будет равна модельному результату суммы под риском (EAD).
Табл. 8. Сводные результаты расчетов риск-пока-зателей, составлено авторами
Table 8. Overall results for calculation of risk-indicators, composed by authors
|
Показатель |
Значение |
|
Активы портфеля |
3204,13 млн долл. США |
|
Ожидаемые потери (EL) |
235,93 млн долл. США |
|
Неожидаемые потери (UL) |
1509,32 млн долл. США |
|
Общие потери (EL+UL) |
1745,26 млн долл. США |
|
Величина кредитного риска (КРП) |
18 866,54 млн долл. США |
|
Модельный средневзвешенный PD |
9,25 % |
|
Модельный средневзвешенный LGD |
93,09 % |
|
Средневзвешенная доля EL |
6,93 % |
|
Средневзвешенная доля UL |
44,36 % |
|
Средневзвешенная доля потерь (EL+UL) |
51,29 % |
|
Отношение активов к КРП |
18,03 % |
Средневзвешенное модельное значение вероятности дефолта равняется 9,25 %, что ниже исторического значения в 10,93 %. В свою очередь средневзвешенное значение LGD по текущим действующим кредитам составляет 93,09 %, что является достаточно высоким показателем, которое значительно влияет как на величину ожидаемых потерь, так и на величину кредитного риска. Это означает, что 93,09 % суммы невыплаченных заемщиков средств будет потеряно в случае его дефолта.
Заключение
В результате работы мы получили оценку вероятности дефолтности (PD), долю возможных потерь (LGD), величину кредитных требований, подверженных риску (EAD), ожидаемые потери (EL), неожидаемые потери (UL) и объем риск-взвешенных активов по кредитному риску. Показатели ожидаемых и неожи-даемых потерь могут использоваться также и во внутренней отчетности банка для принятия управленческих решений, в том числе для расчета экономического капитала.
Актуальность использования подхода обосновывается новыми регуляторными требованиями ЦБ РФ, а также необходимостью автоматизации бизнес-процессов для экономии как человеческих ресурсов, так и капитала финансовой организации [7].
