Развертывание кластера для хранения и обработки статистики с помощью Yandex Clickhouse

Автор: Терских М.Г.
Журнал: Теория и практика современной науки @modern-j
Рубрика: Математика, информатика и инженерия
Статья в выпуске: 11 (29), 2017 года.
Бесплатный доступ
Описаны ключевые возможности Yandex Clickhouse. Приведены основные преимущества Yandex Clickhouse. Приведено краткое описание Apache ZooKeeper. Показаны настройки и конфигурации составляющих кластера. Проведено сравнение двух систем управления базами данных Clickhouse и PostgreSQL. Сделаны выводы о целесообразности использования системы управления базами данных Yandex Clickhouse.
Кликхауз (clickhouse), зокипер (zookeeper), база данных (database), система управления базами данных (database management system), репликация (replication), шардирование (sharding)
Короткий адрес: https://sciup.org/140270404
IDR: 140270404
Deploying a cluster for storing and processing via Yandex Clickhouse
The article is devoted to deploying a cluster for storing and processing. The key features of Yandex Clickhouse are described. The main advantages of Yandex Clickhouse are showed. The article gives a brief description of Apache ZooKeeper. The setup and configuration of the cluster components are presented. There is a comparison of two database management systems Clickhouse and PostgreSQL in this article. Conclusions about the feasibility of using a database management system Yandex Clickhouse is done.
Текст научной статьи Развертывание кластера для хранения и обработки статистики с помощью Yandex Clickhouse
Одним из наиболее продуктивных и доступных решений для хранения и обработки статистических данных на рынке, является СУБД Clickhouse от российской компании Yandex. На данной СУБД на текущий момент времени работают такие сервисы как Yandex Метрика, Yandex Маркет и другие крупные проекты от Yandex. В объединение с другим открытым проектом Apache Zookeeper, появляется возможность развернуть высокодоступный, распределенный кластер под любую задачу, связанную с хранением и обработкой статистики.
Немного о Yandex Clickhouse и Zookeper
Clickhouse – полностью столбцовая система управления базами данных (СУБД) для аналитической обработки в реальном времени (англ. online analytical processing OLAP).
На данный момент существует много других технологий для работы с большими данными. Ниже приведена их классификация и отмечены преимущества Clickhouse перед каждой их технологий.
-
1. Коммерческие OLAP СУБД для использования в собственной инфраструктуре.
-
2. Облачные решения.
-
3. Надстройки над Hadoop.
Примеры: HP Vertica, Actian Vector, Actian Matrix, EXASol, Sybase IQ и другие.
Отличия Clickhouse: открытая и бесплатная технология.
Примеры: Amazon Redshift и Google BigQuery.
Отличия Clickhouse: возможность использовать ClickHouse в своей инфраструктуре, не оплачивая облака.
Примеры: Cloudera Impala, Spark SQL, Facebook Presto, Apache Drill.
Отличия Clickhouse:
-
• ClickHouse позволяет обслуживать аналитические запросы даже в рамках массового сервиса, доступного публично, такого как Яндекс.Метрика;
-
• для функционирования ClickHouse не требуется разворачивать Hadoop инфраструктуру, он прост в использовании, и подходит даже для небольших проектов;
-
• ClickHouse позволяет загружать данные в реальном времени и самостоятельно занимается их хранением и индексацией;
-
• в отличие от Hadoop, ClickHouse работает в географически распределённых датацентрах.
-
4. Open-source OLAP СУБД.
-
5. Open-source системы для аналитики, не являющиеся Relational OLAP СУБД.
Примеры: InfiniDB, MonetDB, LucidDB.
Разработка всех этих проектов заброшена, они никогда не были достаточно зрелыми и, по сути, так и не вышли из альфа-версии. Эти системы не были распределёнными, что является критически необходимым для обработки больших данных. Активная разработка ClickHouse, зрелость технологии и ориентация на практические потребности, возникающие при обработке больших данных, обеспечивается задачами Яндекса. Без использования «в бою» на реальных задачах, выходящих за рамки возможностей существующих систем, создать качественный продукт было бы невозможно.
Примеры: Metamarkets Druid, Apache Kylin.
Отличия Clickhouse: ClickHouse не требует предагрегации данных. ClickHouse поддерживает диалект языка SQL и предоставляет удобство реляционных СУБД.
В рамках той достаточно узкой ниши, в которой находится ClickHouse, у него до сих пор нет альтернатив. В рамках более широкой области применения, ClickHouse может оказаться выгоднее других систем с точки зрения скорости обработки запросов, эффективности использования ресурсов и простоты эксплуатации.
Ключевые особенности СУБД:
-
• Все столбцы хранятся в отдельных файлах, что позволяет
прочитывать только те столбцы, по которым построен аналитический запрос. В случае, когда в таблице больше 100 столбцов, а запрос строится по 5 из них, то количество операций ввода/вывода уменьшается в 20 раз.
-
• СУБД использует векторный движок, позволяющий производить обработку данных по столбцам. В качестве вектора выступает столбец.
-
• Clickhouse строго использует значения постоянной длины, чтобы очистить данные от мусора в виде специальных символов. Что приводит к уменьшению нагрузки на CPU и повышает пропускную способность.
-
• Clickhouse СУБД является многопоточным, и обработка запросов распараллеливаются естественным образом.
-
• Первичный ключ обязателен и должен является датой. Каждый пулл данных с одинаковым первичным ключём Clickhouse хранит в одном образе.
-
• Существует возможность в реализации репликации и шардировании данных.
Для работы репликации (хранение метаданных и координация действий) требуется ZooKeeper. ClickHouse будет самостоятельно обеспечивать консистентность данных на репликах и производить восстановление после сбоев [1, с. 10].
Apache ZooKeeper - распределенный сервис конфигурирования и синхронизации. Говоря более подробно, это распределенное key/value хранилище со следующими свойствами:
-
• пространство ключей образует дерево (иерархию, подобную файловой системе);
-
• значения могут содержаться в любом узле иерархии, а не только в листьях (как если бы файлы одновременно были бы и каталогами), узел иерархии называется znode;
-
• между клиентом и сервером двунаправленная связь, следовательно, клиент может подписываться как изменение конкретного значения или части иерархии;
-
• возможно создать временную пару ключ/значение, которая
существует, пока клиент, её создавший, подключен к кластеру;
-
• все данные должны помещаться в память;
-
• устойчивость к смерти некритического количества узлов
кластера.
Apache ZooKeeper - сервис, используемый кластером (группой узлов) для согласования друг с другом и поддержания общих данных с надежными методами синхронизации. ZooKeeper сам по себе является распределенным приложением, предоставляющим услуги для написания распределенных приложений. Основные услуги, предоставляемые ZooKeeper:
-
• Служба имен - идентификация узлов в кластере по имени. Очень
похоже на DNS, но только для узлов.
-
• Управление конфигурацией - последняя и актуальная
информация о системе новому подключаемому узлу.
-
• Управление кластером - добавление/удаление узла в\из кластера
и статус узла в реальном времени.
-
• Выбор лидера - выбор узла в качестве лидера в целях
согласования.
-
• Служба блокировки и синхронизации - блокировка данных в
момент их изменения. Механизм помогает пользователю в автоматическом восстановлении в случае ошибки при подключении других распределенных приложений, таких как Apache HBase.
-
• Высоконадежная регистрация данных - доступ к данным даже в
случае, когда один или несколько узлов упали [2, с. 15].
Выгоды использования ZooKeeper:
-
• Процесс простой распределенной координации.
-
• Синхронизация - взаимное исключение и сотрудничество между
серверными процессами. Этот процесс помогает в Apache HBase для управления конфигурациями.
-
• Упорядоченные сообщения.
-
• Сериализация - кодирование данных в соответствии с
определенными правилами. Необходимо убедиться, что приложение работает стабильно. Этот подход может быть использован в MapReduce для координации очереди для выполнения запущенных потоков.
-
• Надежность.
-
• Атомарность - передача данных либо завершается успешно
полностью, либо терпит неудачу. Транзакции не осуществляются частично [3, с. 50].
Разворачивание кластера
Для реализации минимального возможного хранилища отвечающего по надежности, высокой доступности и скорости обработки, необходимо 5 серверов. Данные будут разделены на 2 части, и каждая часть будет храниться в двух экземплярах. Минимальные требования к серверу: 512MB RAM, 1 CPU, 2GB SWAP, Ubuntu 14.04 x64.
На рисунке 1 изображена архитектура кластера.
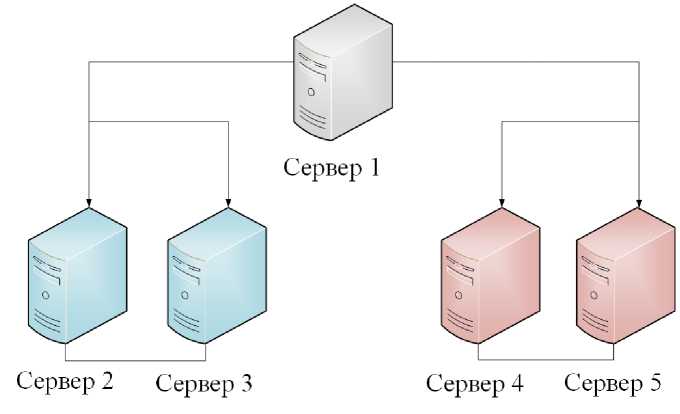
Рисунок 1 – Архитектура кластера
Сервер 1 - обеспечивает обработку данных, занимается распараллеливанием задач между репликами. Он собирает данные присланные от подчиненных серверов и формирует ответ на запрос. На этом сервере данные не хранятся.
-
С ервер 2,3 - хранит первую половину данных. Оба сервера хранят одинаковые данные и постоянно синхронизируются. Они образуют 1-ый шард.
-
С ервер 3,4 - хранит вторую половину данных. Оба сервера хранят одинаковые данные и постоянно синхронизируются. Они образуют 2-ой шард.
Далее приведем необходимые конфигурации для каждого из серверов.
На каждом сервере в файле etc/hosts для удобства пропишем IP адреса всех пяти серверов и дадим им имена:
Для сервера 1: 46.101.170.74 clickhouse-master
Для сервера 2: 138.68.89.230 clickhouse-replica1-slave1
Для сервера 3: 138.68.85.48 clickhouse-replica2-slave1
Для сервера 4: 138.68.85.96 clickhouse-replica1-slave2
Для сервера 5: 138.68.85.172 clickhouse-replica2-slave2
Напомним, что на данном сервере будет создана распределяющая таблица, которая не будет хранить никаких данных, а будет заниматься их распределением [4, с. 65].
Из листинга видно, что имеется 2 шарда, на каждом из которых по 2 реплики: сервер 2,3 и сервер 4,5.
Приведем пояснение некоторых тэгов.
my_cluster – имя кластера.
weight – вес шарда, данные будут распределяться по шардам в количестве, пропорциональном весу шарда. В данном случае данные будут распределены равномерно меду двумя шардами.
host – адрес удалённого сервера. Может быть указан домен, или IPv4 или IPv6 адрес. В данном случае указывается имя сервера, которое заранее было прописано в ect/hosts.
< weight }K/weight}
plica}
< weight >K/weight>
plica}
plica}
Напомним, что на данном сервере будет создана реплицируемая таблица, которая является одной из реплик 1-ого шарда. Поэтому, укажем адрес ZooKeeper кластера. Им является IP адрес сервера 1. Также укажем секцию macros, из которой будут доставаться подставляемые значения при создании таблицы с движком такого типа.
Далее, когда все необходимые настройки и конфигурации совершены, можно создавать самим таблицы. На рисунке 4 приведен листинг создания распределяющей таблицы на сервере 1.
CREATE TABLE inbound_call_data(
ENGINE = Distributed(my_cluster, default, inbound_call_data, rand())
Рисунок 4 – Листинг создания таблицы на сервере 1.
Таблица на сервере 1 создается со специальным движком Distributed.
Поясним параметры, указываемые при создании таблицы с таким движком:
-
• my_cluster – имя кластера в конфигурационном файле сервера 1;
-
• default – имя базы данных (по умолчанию default);
-
• inbound_call_data – имя таблицы;
-
• rand() – рандомная генерация ключа шардирования.
На рисунке 5 приведен листинг создания репликационных таблиц на серверах 2, 3, 4 и 5.
CREATE TABLE inbound_call_data(
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/inbound_call_data', '{replica}', created_ts_date, (sipHash64(concat(project_id,session_id)),created_ts), 8192)
Рисунок 5 – Листинг создания таблицы на серверах 2, 3, 4 и 5.
Таблицы на серверах 2, 3, 4 и 5 создаются с движком ReplicatedMergeTree. Поясним параметры, указываемые при создании таблицы с таким движком:
-
• /clickhouse/tables/{layer}-{shard}/inbound_call_data – путь к таблице в ZooKeeper
-
• {replica} – имя реплики в ZooKeeper
Как видно, эти параметры могут содержать подстановки в фигурных скобках. Подставляемые значения достаются из конфигурационного файла, из секции macros. Описание конфигурационного файла и секции macros приведено выше.
Далее указываются следующие параметры:
-
• created_ts_date – имя столбца типа Date, содержащего дату;
-
• (sipHash64(concat(project_id,session_id)),created_ts) – кортеж,
определяющий первичный ключ таблицы;
-
• 8192 – гранулированность индекса.
Список литературы Развертывание кластера для хранения и обработки статистики с помощью Yandex Clickhouse
- Руководство Yandex Clickhouse. URL: https://clickhouse.yandex/reference_ru.html (дата обращения: 15.10.2016).
- Руководство Apache ZooKeeper. URL: https://zookeeper.apache.org/doc/r3.5.2-alpha/ (дата обращения: 10.10.2016).
- Flavio Junqueira, Benjamin Reed. ZooKeeper Distributed Process Coordination. USA, O’Reilly Media, 2014, 246 p.
- Григорьев Ю.А., Ревнуков Г.И. Банки данных. Москва, МГТУ им. Н.Э. Баумана, 2002, 320 с. Оглавление
