Robust Price Tag Recognition Using Optimized Detection Pipelines

Author: Anatolii Ivanov, Viktoriia Onyshchenko
Journal: International Journal of Intelligent Systems and Applications @ijisa
Article in issue: 4 vol.17, 2025.
Free access
This study investigates the enhancement of the YOLOv5 model for price tag detection in retail environments, aiming to improve both accuracy and robustness. The research utilizes the "Price Tag Detection" dataset from SOVAR, which contains 1,073 annotated images covering four classes: price tags, labels, prices, and products and is split into training, validation, and test sets with extensive preprocessing and augmentation such as resizing, rotation, color adjustments, blur, noise, and bounding box transformations. Several modifications to the YOLOv5 architecture were proposed, including advanced image augmentation techniques to simulate real-world variations in lighting and noise, enhanced anchor box optimization through K-means clustering on the dataset annotations to better fit typical price tag shapes, and the integration of the Convolutional Block Attention Module (CBAM) to enable the model to selectively focus on relevant spatial and channel-wise features. The combined application of these enhancements resulted in a substantial improvement, with the model achieving a mean Average Precision (mAP) of 96.8% at IoU 0.5 compared to the baseline YOLOv5's 92.5%. The attention mechanism and optimized anchor boxes notably improved detection of small, partially occluded, and diverse price tags, highlighting the effectiveness of combining data-driven augmentation, architectural tuning, and attention mechanisms to address the challenges posed by cluttered and dynamic retail scenes.
Image Recognition, Computer Vision
Short address: https://sciup.org/15019922
IDR: 15019922 | DOI: 10.5815/ijisa.2025.04.04
Text of the scientific article Robust Price Tag Recognition Using Optimized Detection Pipelines
Published Online on August 8, 2025 by MECS Press
Artificial intelligence (AI) and neural networks are increasingly applied across diverse industries, including retail, where many routine tasks, such as price management and inventory tracking, are still performed manually. In particular, the process of monitoring and updating price tags remains time-consuming, error-prone, and labor-intensive. Automating this task using computer vision offers the potential to reduce operational costs, minimize human error, and improve consistency across retail networks.
Price tag recognition refers to the automatic identification and reading of price information directly from product labels using a combination of computer vision and optical character recognition (OCR). This technology enables faster price verification, more efficient inventory management, and supports real-time competitive analysis. By automating price tag processing, retailers can not only enhance in-store productivity but also ensure pricing accuracy and alignment with backend systems.
Although price tag recognition is gaining relevance in the retail sector, dedicated academic research on this problem remains limited. Most existing approaches adapt general-purpose object detection frameworks, such as Faster R-CNN or YOLO, which often involve trade-offs between detection accuracy and computational efficiency. High-accuracy models may suffer from slow inference times, while lightweight models often underperform in complex retail environments, especially when detecting small, partially occluded, or irregularly shaped price tags.
In addition to architectural trade-offs, retail environments introduce several technical challenges, such as diverse lighting conditions, visual clutter, variable tag orientations, and inconsistent label designs. These factors complicate reliable price tag detection and require models to generalize well to unseen conditions. Although recent advancements in deep learning have led to improvements in small object detection and real-time processing, specific adaptations are still needed to address the nuanced demands of retail use cases.
The main technologies used in price tag recognition are optical character recognition (OCR), computer vision, and machine learning. OCR is responsible for extracting textual content from images, converting it into structured digital information that can be processed by inventory and pricing systems. Computer vision techniques are primarily used to detect and isolate the price tag regions in images, even under suboptimal conditions such as low lighting, partial occlusion, or varied perspectives. Machine learning, particularly deep learning using convolutional neural networks (CNNs), plays a key role in learning the complex features associated with different price tag styles. These methods can improve detection accuracy significantly by learning from a diverse dataset, enabling the system to adapt to different tag layouts, fonts, colors, and visual backgrounds found in real-world retail environments.
This article focuses specifically on the first and foundational step in the price tag recognition pipeline: identifying and localizing price tags within images. This detection stage is critical, as the performance of all downstream tasks, such as text recognition, information parsing, and price verification, depends on its reliability. In this context, the problem is approached as an object detection task, where models are trained to recognize and draw bounding boxes around price tags of various forms. By improving this detection stage, the system can provide more reliable inputs to subsequent modules.
2. Main Challenges
Price tag detection in retail environments introduces a unique set of challenges that go beyond those typically encountered in general object detection tasks. One of the primary difficulties is the small size of price tags, which often occupy only a tiny fraction of the image area. This makes them especially hard to detect without the use of high-resolution inputs, multi-scale detection strategies, and carefully designed feature pyramids. Furthermore, price tags are frequently partially occluded by products, packaging, human hands, or shopping carts, which can obscure key visual features needed for reliable detection.
Another significant factor is the high variability in lighting conditions across retail environments, including artificial lighting, shadows, glare from glossy packaging, and uneven exposure. These variations demand robust data augmentation techniques during training to ensure the model can generalize to different visual scenarios. Moreover, retail shelves and store environments typically feature cluttered backgrounds, filled with competing text, logos, packaging elements, and shelf labels. This visual noise makes it difficult to distinguish actual price tags from similarlooking but irrelevant regions, calling for detectors with strong localization and non-maximum suppression (NMS) capabilities.
In addition, price tags exhibit substantial diversity in terms of shape, color, font, language, and layout. Some tags are printed in bright, highly readable formats, while others use faint or low-contrast text. Tags may be placed horizontally, vertically, or at oblique angles, requiring the detection system to handle varying orientations and perspectives. The presence of non-standard or promotional tags further complicates the detection task, often demanding that models learn subtle visual cues rather than rely solely on consistent patterns.
Addressing these multifaceted challenges necessitates the use of large, diverse, and well-annotated datasets, along with the application of specialized model modifications. While modern deep learning detectors such as the YOLO family [2] have achieved significant success due to their balance of speed and accuracy, they can still struggle with edge cases, including densely packed shelves, overlapping tags, or low-resolution input data. Therefore, continual improvement in data preprocessing, architectural tuning, and loss function design remains essential for advancing the state of the art in this practical and complex detection domain.
3. Overview of Existing Models and Methods
Automated price tag detection is a domain-specific task within object detection, where the goal is to localize and extract pricing information from images of retail shelves. This task presents added complexity due to visual clutter, occlusion, and small object sizes. While it shares similarities with general object detection, its unique characteristics demand more specialized approaches.
Recent advances in deep learning, particularly convolutional neural networks (CNNs), have significantly enhanced such detection capabilities. These models have gradually replaced traditional computer vision techniques by learning hierarchical feature representations directly from data, improving generalization and robustness in real-world retail environments.
-
3.1. Traditional Computer Vision Techniques
-
3.2. Deep Learning-based Object Detection
Before the widespread adoption of deep learning, object detection primarily relied on manually engineered features and heuristic image processing methods. Early attempts incorporated edge detection to highlight object boundaries, aiming to isolate price tags based on intensity changes. However, these methods were highly sensitive to noise, lighting variations, and background clutter, limiting their reliability in complex retail scenes.
Next try was to use template matching, which involves sliding a predefined template across the image to find matching regions. While straightforward, template matching lacks robustness against occlusion, scale changes, and rotation, making it inadequate for real-world retail environments where price tags vary widely.
The introduction of more sophisticated descriptors like the Histogram of Oriented Gradients (HOG) marked a significant improvement. HOG captures local shape by pooling gradient orientations, providing a richer representation of object structure. Combined with classifiers such as Support Vector Machines (SVMs), HOG-based detectors achieved state-of-the-art results on benchmark datasets like PASCAL VOC [5]. Despite their success in controlled settings, these approaches struggled with generalization, especially in detecting small, partially obscured, or variably styled price tags common in retail environments.
By the early 2010s, further progress with handcrafted features reached a plateau, motivating the transition to data-driven deep learning models capable of learning features directly from annotated images.
The advent of deep convolutional neural networks (CNNs) marked a significant breakthrough in object detection, enabling models to learn hierarchical and complex features directly from large datasets without relying on handcrafted descriptors. Early deep learning object detectors adopted a two-stage approach: the first stage generated candidate regions likely to contain objects, while the second stage classified these regions using CNNs. Such implementation, which was done in the original R-CNN, resulted in a remarkable improvement in detection accuracy, achieving a mean Average Precision (mAP) of 53.3% on the PASCAL VOC dataset, substantially outperforming traditional feature-based methods [6].
Based on this success, subsequent models integrated the region proposal and classification processes into a single, unified network, thereby improving computational efficiency and enabling end-to-end training. Fast R-CNN introduced Region of Interest (ROI) pooling to extract fixed-size feature maps from variable-sized candidate regions, which streamlined processing. Faster R-CNN further advanced the approach by incorporating a Region Proposal Network (RPN) that generates object proposals internally within the CNN, eliminating the need for slower external proposal algorithms like selective search. This design pushed detection performance even further, with Faster R-CNN using a VGG-16 backbone achieving 73.2% mAP on VOC 2007, demonstrating the power of deep end-to-end detectors [7].
Despite their accuracy, two-stage detectors often require considerable computational resources and tend to be slower, which limits their applicability in real-time or resource-constrained environments. To address this limitation, single-stage detectors were developed. These models aim to perform object localization and classification in one forward pass, dramatically increasing inference speed at some cost to accuracy. YOLO (You Only Look Once), which was introduced in 2016 was the first to use this approach by dividing the input image into a grid and predicting bounding boxes and class probabilities directly from each grid cell. YOLOv1 achieved an unprecedented 45 frames per second (FPS) while maintaining a competitive 63.4% mAP on VOC 2007 [8]. However, YOLOv1 struggled with detecting small objects and handling multiple objects close together, which impacted its accuracy relative to two-stage detectors.
Subsequent single-stage models like SSD (Single Shot MultiBox Detector) and later versions of YOLO have worked to close this accuracy gap. YOLOv2, for example, introduced several key improvements such as batch normalization to stabilize training, higher resolution input images to better detect small objects, and the use of anchor boxes optimized via k-means clustering to better capture object shapes and sizes. These enhancements allowed YOLOv2 to achieve higher accuracy, reaching 76.8% mAP on VOC 2007, while running at real-time speeds [8]. YOLOv3 built upon this by employing a deeper backbone network (Darknet-53) and a multi-scale feature pyramid approach. It made predictions at three different scales to better detect small, medium, and large objects simultaneously. This multi-scale detection strategy substantially improved performance on challenging datasets, especially for small objects such as price tags in retail scenes, achieving superior mAP values while maintaining inference speeds suitable for near real-time deployment [9].
Table 1 provides a comparative overview of representative object detection models on the PASCAL VOC 2007 benchmark, illustrating the rapid progress from early handcrafted feature-based methods to modern CNN-based detectors. It highlights the trade-offs between accuracy and speed that have shaped the evolution of these models.
Table 1. Performance of object detection models on PASCAL VOC 2007 dataset
|
Model & Reference |
mAP (VOC2007) |
Speed (FPS) |
|
HOG + SVM (DPM, 2010) |
~30–35% (estimated) |
~1 FPS |
|
Faster R-CNN (VGG-16, 2015) |
73.2% |
~7 FPS |
|
YOLOv1 (2016) |
63.4% |
45 FPS |
|
YOLOv2 416×416 (2017) |
76.8% |
67 FPS |
|
YOLOv2 544×544 (2017) |
78.6% |
40 FPS |
|
YOLOv3 (2018) |
57.9% (COCO AP) |
~30 FPS |
-
3.3. The YOLO Family of Detectors
-
3.4. Comparison with Existing Methods
The YOLO (You Only Look Once) family revolutionized object detection by framing it as a single regression problem. Instead of the two-stage process of generating proposals and then classifying them, YOLO predicts bounding boxes and class probabilities from the entire image in one forward pass. This end-to-end approach greatly improves inference speed, making YOLO ideal for real-time applications.
YOLOv1 divides the input image into a grid where each cell predicts bounding boxes and class probabilities. Although fast (~45 FPS), it struggled with small objects and detecting multiple adjacent objects within a single cell, resulting in lower accuracy compared to two-stage detectors [8].
YOLOv2 introduced major improvements including a fully convolutional backbone, batch normalization, and anchor boxes optimized via k-means clustering to better fit object shapes. Multi-scale training further improved robustness to varying input sizes. These changes boosted accuracy to about 78.6% mAP on PASCAL VOC, while maintaining high speed [8].
YOLOv3 enhanced detection with a multi-scale feature pyramid approach using a deeper backbone (Darknet-53). It predicts at three scales, detecting small, medium, and large objects more effectively, important for small targets like price tags. It uses nine anchor boxes tailored for different scales and retains near real-time speed [9,15].
Subsequent versions like YOLOv4, YOLOv5, YOLOv7, and YOLOv8 brought further advances. YOLOv4 added mosaic augmentation and cross-stage partial networks for better feature extraction. YOLOv5, popular due to ease of use and multiple size variants, introduced automated anchor tuning. YOLOv7 optimized training and network scaling for state-of-the-art results. YOLOv8 simplified architecture and offers an anchor-free mode, predicting object centers directly to reduce hyperparameter tuning. It still defaults to anchor boxes with auto-selection and separates detection heads for classification and localization [9,10].
Overall, YOLO detectors balance speed, accuracy, and deployment ease, making them highly effective for realtime detection tasks like price tag localization in challenging retail scenes.
Price tag detection presents unique challenges in retail environments, including varying lighting conditions, occlusions, and cluttered backgrounds. Classical computer vision techniques relying on handcrafted features and OCR pipelines offer low computational cost but lack robustness against such diverse conditions commonly encountered in real-world retail settings. Deep learning-based detectors, such as Faster R-CNN and SSD, provide improved accuracy but either incur significant inference delays or suffer from reduced performance on small or partially obscured price tags.
More recent advances, including the YOLO model and its different versions, strike a balance between speed and accuracy, enabling real-time deployment. YOLO (You Only Look Once) models are particularly well-suited for price tag detection due to their one-stage detection pipeline, which allows for fast inference while maintaining competitive accuracy. Unlike two-stage detectors such as Faster R-CNN, YOLO models unify detection and classification into a single network pass, significantly reducing latency, which is an important factor for practical retail applications requiring real-time responsiveness. Moreover, the evolution of YOLO architectures has brought improvements such as adaptive anchor box optimization, advanced augmentation techniques (e.g., mosaic augmentation), and architectural enhancements (like CSPDarknet backbone), all of which improve detection performance on small and diverse objects like price tags. YOLO’s flexibility also facilitates integration of additional modules such as attention mechanisms, which can focus the model on relevant features amid cluttered backgrounds and occlusions typical in retail images. These characteristics make YOLO an ideal foundation for proposed modifications, enabling a practical, high-performing solution for price tag detection that balances accuracy, speed, and robustness.
Table 2. Comparative overview of existing price tag detection methods
|
Method |
Architecture |
Strengths |
Weaknesses |
Applicability to Price Tags |
|
Classical CV + OCR |
Handcrafted features |
Low computational cost, interpretable |
Sensitive to lighting, occlusion, clutter |
Limited robustness in real-world images |
|
Faster R-CNN |
Two-stage CNN |
High accuracy, good for small objects |
Relatively slow inference |
Moderate, struggles with real-time needs |
|
SSD |
Single-shot detector |
Real-time capable, balanced accuracy |
Less precise localization, small object detection weaker |
Moderate |
|
YOLOv3 / YOLOv4 |
One-stage detector |
Real-time speed, good generalization |
Challenges with occlusion and tag diversity |
Widely used baseline |
|
YOLOv5 |
One-stage detector |
Improved anchor auto-learning, mosaic augmentation, optimized backbone |
Baseline model, which may miss small or partially occluded tags |
Strong baseline |
|
Attentionbased models |
CNN + attention modules |
Improved focus on relevant features |
Increased complexity and training time |
Promising for cluttered scenes |
The incorporation of attention mechanisms, optimized anchor boxes, and advanced augmentation techniques, as proposed in this work, addresses the limitations of existing methods by enhancing feature representation and better aligning detection priors to the dataset-specific object distributions.
Table 2 summarizes the comparative performance and key characteristics of existing approaches applied to price tag detection and related small object tasks. The table highlights the architecture, strengths, weaknesses, and applicability to price tags for each method.
This comparison underscores the complementary advantages and limitations of current methods. Classical approaches offer simplicity but limited adaptability; Faster R-CNN and SSD improve detection quality with trade-offs in speed or precision. YOLO models offer an effective baseline for real-time detection but can benefit from enhancements to address occlusions and tag variability. Attention mechanisms and optimized anchors, as introduced here, provide promising solutions to these challenges, improving both robustness and accuracy in retail price tag detection.
-
3.5. Evaluation Metrics
Accurate evaluation of object detection algorithms is crucial for quantifying model performance. The most widely used metric for this purpose is mean Average Precision (mAP) [18].
Mean Average Precision (mAP) provides an aggregated measure of detection performance across different classes and confidence thresholds. It combines precision (the ratio of correctly identified detections to the total number of detections) and recall (the ratio of correctly identified detections to all ground-truth instances). Precision and recall are calculated as follows:
TruePositives
Precision =----------------------------
TruePositives + FalsePositives
Recall =
TruePositives
TruePositives + FalseNegatives
The Average Precision (AP) for a single class is calculated by plotting precision against recall values and integrating precision values over recall levels, formally defined as:
AP = precision (recall) d (recall)(3)
Mean Average Precision (mAP) is the average of AP across all classes:
mAP = — У* AP(4)
N^i=1 i where N represents the number of classes. In single-class detection tasks, such as price tag detection, AP and mAP values coincide. mAP is commonly reported at an IoU threshold of 0.5 or averaged across multiple IoU thresholds, typically ranging from 0.5 to 0.95, as adopted by the MS COCO benchmark [11]. These metrics are fundamental for ensuring reliable comparisons of object detection algorithms.
The mean Average Precision metric was selected as the main one due to its widespread acceptance and its ability to comprehensively reflect both precision and recall across varying confidence thresholds. Unlike single-threshold metrics, mAP provides a balanced measure of a model’s detection accuracy, considering false positives and false negatives, which is critical for assessing performance in complex detection tasks such as price tag recognition. Moreover, evaluating mAP at different IoU thresholds offers insights into the model’s localization precision and detection quality. Alternative metrics like F1-score or IoU alone do not fully capture this balance, making mAP the most suitable metric for detailed and reliable evaluation in this context.
4. Dataset Selection
Selecting an appropriate dataset is crucial for effectively training and evaluating price tag detection models. Ideally, such datasets should be diverse, encompassing various price tag styles, environmental conditions, lighting scenarios, and retail backgrounds to ensure robust model training and reliable evaluation. For this research, the Roboflow Price Tag Dataset was specifically chosen due to its focus on price tag detection in retail settings, making it well-suited for object detection and segmentation tasks. This dataset contains images annotated with bounding boxes around price tags, enabling models to accurately learn the task of localizing price tags.
The Roboflow Price Tag Dataset includes 1,073 annotated images, containing a total of 5,134 price tags showing a variety of retail scenarios. It contains considerable diversity in price tag designs, with variations in size, shape, font style, and color, reflecting real-world retail conditions. Images present a wide range of challenges such as varying lighting environments, different viewing angles, partial occlusions, and cluttered backgrounds, all of which increase the complexity of detection tasks. Moreover, the image resolutions and quality vary across the dataset, further enhancing its representativeness of real-world conditions.
To improve dataset diversity while relying on a limited number of real images, several augmentations were applied. These include rotations, hue and saturation adjustments, as well as blur and noise effects. Additionally, augmentations were applied specifically to the price tag bounding boxes, involving changes in brightness, blur, and exposure, which help simulate a variety of visual conditions.
The dataset captures diverse retail scenarios, offering variation in lighting conditions, tag orientations, sizes, and backgrounds. This diversity supports better model generalization to new, unseen retail environments. The careful annotation of images facilitates accurate training and evaluation of detection models. Furthermore, the dataset covers a range of price tag designs and labeling styles common in practice. Overall, utilizing this dataset provides comprehensive coverage of key challenges, offering valuable insights into the robustness and adaptability of the proposed detection model and supporting its reliable deployment in practical retail applications.
5. Proposed Changes
After analyzing different existing models, it was decided to select YOLOv5 [2] model due to its significant popularity, high usability, and well-documented effectiveness in diverse object detection tasks. At the same time its capability to balance speed and accuracy is particularly beneficial for real-time applications common in retail settings. According to research [12] this model shows a performance of 81.49% mAP on some similar price tag datasets.
Different tests were made with this model, trying to get better results. The first proposed modification involves an adjustment of image augmentation parameters, specifically brightness, shadows, and noise. It should help better introduce real-time conditions and show better results overall. Adjusting brightness and contrast helps the model recognize price tags under varying illumination, shadow augmentation prepares it for partial occlusion scenarios, and noise injection increases resilience against visual distortions. Thus, it addresses common environmental challenges leading to significantly improved generalization and detection accuracy.
The second proposed change focuses on Enhanced Anchor Box Optimization [13,16]. By using K-means clustering directly on the price tag dataset annotations, optimal anchor boxes adapted to typical price tag shapes can be determined. This method ensures that the network's predictions better match the actual dimensions of price tags, leading to increased accuracy and precision in object detection. Properly optimized anchors reduce localization errors and improve the model’s ability to accurately capture the diverse dimensions of price tags.
The third enhancement involves integrating the Convolutional Block Attention Module (CBAM) [14,17] into YOLOv5. CBAM is an attention mechanism designed to help neural networks selectively focus on important spatial and channel-wise information within feature maps. Specifically, CBAM consists of two sequential attention modules: channel attention and spatial attention. The channel attention module determines which channels contain more informative features by applying global pooling and a shared multi-layer perceptron, this way amplifying meaningful channels while suppressing less relevant ones. Following this, the spatial attention module assesses which spatial regions within each feature map carry essential features by utilizing a convolution operation that emphasizes regions critical for accurate prediction. Integrating CBAM into YOLOv5 allows the model to dynamically prioritize regions containing price tags over surrounding clutter.
The final test combines the benefits of advanced image augmentation and Enhanced Anchor Box Optimization to evaluate whether their simultaneous application yields superior detection performance compared to individual applications. By employing extensive image augmentation alongside optimized anchor boxes, the model experiences a comprehensive and enriched training environment. This synergy maximizes the model's ability to generalize across diverse and challenging retail scenarios. Such combined approach is expected to provide a balanced, powerful, and reliable detection model capable of high performance in practical, real-world deployments.
In conclusion, these proposed modifications collectively aim to significantly improve YOLOv5’s effectiveness and robustness in detecting price tags within retail images, directly addressing critical environmental challenges and maximizing the model's overall performance through targeted augmentation, training strategies, and enhanced network architecture.
6. Validating Results
Proposed modifications described above were evaluated through a series of structured tests, comparing their performance to a baseline YOLOv5 model. To clearly illustrate the impacts of each modification, a summary of key performance metrics is presented in Table 3.
Further insights can be gained through visual examination of the validation examples, showcasing how each model performs on detecting price tags. Each example consists of 16 images, highlighting differences in model predictions (Fig. 1). As it can be seen, the default model provides a basic performance baseline, showing generally good but inconsistent results, occasionally failing to detect some of the smaller or partially obscured price tags. The CBAM- enhanced model demonstrates noticeable improvements by giving higher scores to some challenging price tags, suggesting the benefits of employing attention mechanisms. The model combining both enhanced augmentation and optimized anchor boxes yielded the most robust performance. It consistently and accurately identified all price tags across diverse scenarios, though it occasionally assigned lower confidence scores to uncommon tag designs, indicating room for further optimization or additional training examples for rarer tag variations.
Table 3. Comparative overview of performance metrics for baseline and modified YOLOv5 models
|
Test Run |
mAP@0.5 |
mAP@[0.5:0.95] |
Precision |
Recall |
|
Default |
92.5% |
72.8% |
90.2% |
91.3% |
|
Augmentation |
95.7% |
70.3% |
91.4% |
90.5% |
|
Anchors |
93.8% |
70.1% |
90.4% |
92.1% |
|
CBAM |
95.8% |
67.4% |
94.1% |
89.3% |
|
Combined |
96.8% |
69.1% |
96.4% |
88.5% |

Fig.1. Validation example images from each model variant (left to right: baseline, CBAM-enhanced, combined), with detection results as red rectangles with found accuracy. Demonstrates model prediction of some of the price tags in training set
To assess training effectiveness and convergence behavior, a comparative analysis of mean Average Precision (mAP) over epochs was conducted. The mAP charts illustrate how each model variant adapts to the dataset and augmentation strategies during training (Fig. 2). The baseline model shows steady but slower improvements in detection performance. The CBAM-enhanced model achieves higher mAP earlier, reflecting better feature learning from attention mechanisms. The combined model demonstrates the fastest convergence and highest final mAP, highlighting the cumulative benefit of integrating augmentation, anchor optimization, and attention modules.
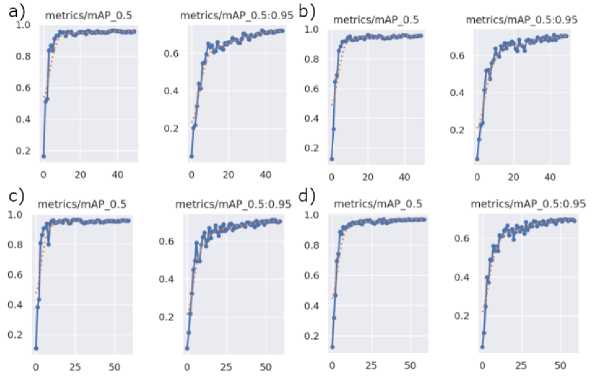
Fig.2. Mean Average Precision (mAP) performance curves comparing the baseline YOLOv5 model with models incorporating individual enhancements (augmentation, anchor optimization, CBAM) and their combined configuration. The chart plots mAP values over training epochs, emphasizing the progressive improvements achieved. (a – default, b – Augmentation, c – CBAM, d – Combined)
As a result, all four proposed modifications demonstrated incremental improvements over the baseline model, although certain individual adjustments showed limited standalone efficacy. The evaluation of each model variant yielded the following insights:
• Baseline Model provided reasonable detection performance, accurately identifying the majority of price tags. However, its effectiveness was somewhat inconsistent, particularly in detecting atypical or less frequent tag designs, despite their presence in the training dataset.
• Augmented Model by incorporating advanced image augmentation strategies it resulted in improved detection performance for non-standard price tags. Nevertheless, the overall quality of detection for typical tags remained largely unchanged. This model exhibited performance similar to the baseline, primarily due to the minimal extent of applied modifications.
• Anchor-Optimized Model has significantly increased training duration but produced notable improvements in detecting standard price tags, reflected by higher confidence scores. However, this variant struggled to correctly detect non-standard or uncommon price tags, indicating limited adaptability to variations not well represented by the optimized anchor boxes.
• CBAM enhanced model resulted in moderate improvements over the baseline one, successfully identifying some previously missed price tags. Nevertheless, detection remained imperfect, as several tags continued to be overlooked.
• Combined Model exhibited the most substantial improvement, achieving a 4% increase in mean Average Precision (mAP) relative to the baseline. It successfully detected all price tags within the evaluation set. However, it occasionally yielded confidence scores below the standard threshold of 0.5 for certain uncommon tags, highlighting potential areas for further refinement.
7. Conclusions
Table 4. Performance comparison of model variants
|
Model Variant |
Training Time |
Detection Strengths |
Detection Weaknesses |
Key Observations |
mAP Improvement |
|
Baseline |
Standard |
Good general detection of common tags |
Inconsistent on atypical/non-standard tags |
Reasonable baseline |
- |
|
Augmented |
Slightly increased |
Better detection of nonstandard tags |
Overall detection similar to baseline |
Minimal augmentation impact |
+1% |
|
Anchor-Optimized |
Significantly longer |
Higher confidence on standard tags |
Poor adaptability to uncommon tag variations |
Improved localization, limited flexibility |
+2.5% |
|
CBAM-Enhanced |
Slightly increased |
Improved detection on missed tags |
Some tags still overlooked |
Better focus on relevant features |
+2% |
|
Combined |
Longest |
Best overall detection and robustness |
Occasional low confidence on rare tags |
Synergistic effects of all modifications |
+4% |
Results underscore the individual strengths and limitations of each modification, while demonstrating that their combined approach delivers the most consistent and substantial improvements. This comprehensive evaluation confirms the effectiveness of integrating advanced augmentation and anchor optimization to address the challenges of price tag detection in complex retail environments. These insights provide a solid foundation for further refinement and development of robust object detection models tailored to real-world applications.
Despite these encouraging results, several limitations remain. Notably, the detection of uncommon or atypical price tags continues to present challenges, as evidenced by occasional lower confidence scores and missed detections. This suggests that while the combined model improves overall robustness, it still struggles with rare tag variations and complex visual conditions such as heavy occlusions or extreme lighting. Additionally, the increased computational complexity from anchor optimization and attention mechanisms may impact real-time deployment in resource-constrained settings. Addressing these limitations requires further exploration of more diverse training data, adaptive model architectures, and potential trade-offs between accuracy and efficiency. Future work should focus on enhancing generalization to rare cases and optimizing inference speed to enable practical deployment in diverse retail environments.
This study investigated modifications aimed at improving the accuracy and robustness of price tag detection in real-world retail environments, where factors such as occlusions, lighting variability, and tag diversity present considerable challenges. A YOLO-based object detection architecture was selected as the experimental foundation due to its favorable trade-off between real-time performance and detection accuracy, particularly suitable for deployment in dynamic retail settings.
By systematically addressing common issues, such as the small size of price tags, their partial occlusion, and their occurrence in cluttered and visually complex backgrounds, the proposed improvements demonstrated measurable benefits to model performance. The use of advanced image augmentation techniques not only enhanced generalization under variable conditions but also contributed for better recognition of rare or atypical tag styles. Anchor box optimization enabled the model to align more closely with dataset-specific object scales, thus improving localization performance. Furthermore, the inclusion of a lightweight attention mechanism, specifically the CBAM module, improved the model’s ability to emphasize relevant features while suppressing distracting background elements.
Experiments showed that each individual enhancement contributed to performance gains under specific conditions. However, the most notable results were observed in the combined model, which integrated all proposed modifications and achieved the most stable and comprehensive detection outcomes across diverse test cases. This confirms that performance in object detection tasks, especially those involving small, variable objects like price tags, can benefit from a holistic approach that merges data augmentation, architecture-level optimization, and attention-guided feature refinement.
Beyond its practical implications, this work contributes to the relatively underexplored area of retail-focused computer vision by highlighting the effectiveness of tailored modifications applied to a widely adopted detection framework. The methodology and findings provide a useful foundation for future research and deployment in automated retail monitoring and shelf management systems.
Future work may investigate integration with end-to-end OCR pipelines to extract and verify textual price information from detected tags. Evaluating the generalizability of the model across geographically diverse retail datasets, or in low-resource environments (e.g., mobile devices), would also provide valuable insights. Moreover, incorporating anchor-free architectures (such as CenterNet or YOLOv8 variants) could reduce dependency on anchor configuration; while exploring transformer-based modules or lightweight attention layers like SimAM or Efficient Channel Attention (ECA) may offer better accuracy-speed trade-offs for edge deployment.
