Running Google Colaboratory as a server – transferring dynamic data in and out of colabs

Author: Samarth V. Halyal
Journal: International Journal of Education and Management Engineering @ijeme
Article in issue: 6 vol.9, 2019.
Free access
Mainly all the hype in the field of Machine Learning and Neural Network has led the students of this century learn and research in this field, and the primary issue faced by lot of students and researchers is the availability of proper infrastructure. The complex algorithms need good quality and quantity of CPU’s and GPU’s. Fortunately Google has an aid for such demand, They named it Google Colaboratory. which they provide free of cost. But has lesser flexibility for the user to pass data required for computational purposes. This paper talk about a way in which researchers may feed/retrieve data dynamically without using the manual upload feature of google colaboratory. This will help the researcher or student to concentrate more on their thesis rather than pay attention on data.
Google colaboratory, shell script, ipython notebook, google drive
Short address: https://sciup.org/15017020
IDR: 15017020 | DOI: 10.5815/ijeme.2019.06.04
Text of the scientific article Running Google Colaboratory as a server – transferring dynamic data in and out of colabs
Published Online September 2019 in MECS
Available online at
-
1. Introduction
-
2. Methodology
The Field of Neural Networks and Artificial Intelligence is a fast growing area which has been giving enthusiasm to lot of students who have developed a aim to pursue their careers in this field. Not only the students but also the experienced fellows in the field who look forward for further research in these fields have been in constant look up for better self-performance.
* Corresponding author.
E-mail address:
But the main problem that is hindering most of the people is proper access to tools and hardware infrastructure to aid the study of the algorithms involved in these fields, but google has been helpful in providing this need for them through their project named as google colaboratory, an iPython notebook webapp. This webapp comes as an extension for the google chrome browser that gives users access to high end central processing unit (CPU), Tensor processing unit (TPU) and an graphics processing unit (GPU) with good amount of random access memory (RAM) and Video RAM (VRAM). This the users can select accordingly. But a slight problem now was that the user (Student/research person) has very less flexibility of training over the data he has, as the system refreshes every 12 hours or something and the actual maximum space on the system is also less. And also that the user is allowed to input the data into the working environment only through the manual button that exist on the webapp.
This paper discusses about a method (usually a series of code) that allows the user have complete control about the amount of data he/she needs to transfer and where and how to transfer. Google drive was a possible buffer that was used in this method to work around as a channel.
The paper released at IEEE spoke mainly on how colabs was used as performance analyzer as a tool for accelerating deep learning applications. It also gave a in-depth information on usage and technical aspects of google colaboratory (a.k.a. colabs)[1].
To show the working and actual methodology let us consider a simple web application that generates a story given some seed text, this is working using recurrent neural network on long short term memory units that was trained on google colabs, its simple interface is as shown in Figure 1.
Seed Text
Fig. 1. The simple interface
Now after every line of story generated the current story in updated and given to the algorithm as seed text. This web application is hosted on Heroku and serves only as an user interface, the real computation occurs on colabs. This specific application is a working model on the more general topic of ours that is the way of sending unconditional data to and from colabs, so a very small amount of data travels in this exhibition. This similar idea can be extended to any amount of data with proper careful changes.
So the basic technique that we can use here is keeping the colabs notebook always ready to accept input, this can be done using the “inotifywait” command on linux[2]. As colabs can run linux commands just by using an exclamation mark(!) this becomes easy to install and use “inotifywait” command. Figure – 2 shows the shell script implemented to do so.
inotifywait -e modify -m . | while read -r drive events filename; do
#fi
Fig. 2. the shell script implemented
What this script does is that is watches over the current directory and triggers the code written after the pipeline whenever there is a modification to current directory. Different options and arguments to be passed for this command can be seen at its documentation page referred in the reference section. This shell script after the pipeline, states that read all the files in the current directory till we find the file named input1.txt, then check whether it is updated. This logic to check whether it is updated in written in another subroutine as per Figure 3.
}
Fig. 3. This logic to check whether it is updated in written in another subroutine
This subroutine as can be seen has a background command which has a shell script as its first line. This shell script is nothing but the code we saw earlier in Figure 2. In this we are running a command “diff” on two files “$1” at two different folders. What this “diff” does is it gives output as null if both files are similar and some information as in word of mismatch if both files are dis-similar. The one in current directory is the one we need to check whether is updated?. This argument $1 is taken from previous code where the input file was passed with subroutine call. We store this difference in a file named “check.txt” and on next line check whether its Not empty. If yes then the file was updated so we print “modified” and copy the “modified” file. And the further steps are user depended, And is not related much to current discussion. Till now we have seen how to keep running colabs as a server ready to accept input. Figure 4 shows how these files are kept ready on colabs to run at every 12 hours when data in refreshed and everything is rewritten.
Every step is numbered (1) to (7), these work with the project in discussion. But the one that’s most important is the one that is not commented out. “Test.sh” is the name of the code shown in Figure 3. As we could see the drive word being used, this is the google drive that needs to be authenticated before using it as shown in the figures. This can be done using the code shown in Figure 5. This is the colabs specific code that mounts the google drive into our working directory, specifically in this example we are refreshing this every 4 seconds(totally user standard).
-
• free google.colab iaport drive
-
• drive.»ount(' /contont/drive",forcereeount-True)
-
• !apt-get install inotify-toole
-
• I ir.otifyvalt -e eodity -• output.txt
-
• Ichnod u»x beck.eh
-
*••••••••• MMK4S RUN THIS AT THE END •••♦»••••••••••••••••••••♦••••••♦••
•••••••♦•• KLUKt^ RUN THIS AT THE END ••••••••••••••••••••••♦♦•••••••••••
-
• Icat /uer/local/lib/python3.6/dist-packagea/google/colab/drive.py
-
• (•)
-
• Iphp ./project_xip/teet.php
-
• Iphp --version
-
• (SI
-
• I apt-get update
-
• lapt-get install php
-
• luntip ./drive/Hy\ Drive/Colab\ Kotebooks/project_tip.tip
-
Fig. 5. the drive word being used
{fileid = -14YcSsO-_hlTCIBYgWhoS$Cjpq6iiqvdr;
// {client ■ getClientO;
// {service = new Google_Service_Drive({client);
// {file ■ |$eгvlce->files->9et($fileid,errey(,alt, ■> •■edia*));
// print({flie->get8ody( )->qetContent$()."\n");
-
Fig. 6. The one simple way
-
3. Flowchart
-
4. Result
Figure 7 shows the flow of control from beginning of the application to the end, as can be seen our sample application when started and data is passed to google drive, drive stores it as buffer and if this new data is not the already existing data and is modified, it is passed to google colabs for processing else we wait looking in drive. We poll the google drive using the inotify command till there is some updation at google drive, this triggers copy of the new updated data to colabs and the user may work on it as intended. So the flowchart explains this process respectively i.e., from start of the application the google drive is polled for data update and further process is shown accordingly in flowchart.
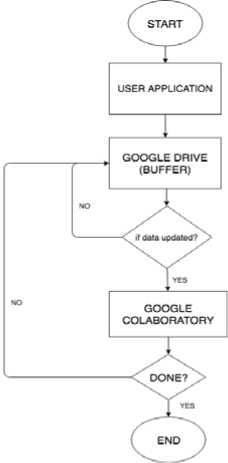
Fig. 7 the flow of control
-
1. data is transferred from storage location where user wants, to google colabs without loss of any data.
-
2. Unlimited and unconditional flow of data, generally needed for training purpose.
-
3. Stored results are also transferred back to local disk and any location user wants by small possible modification in the code.University backed Business Incubator
-
5. Conclusion and Recommendation
This paper showed how using this small code snippet can one convert google colabs into a temporary server waiting for input. How this can be used to transfer huge amounts of data every time colabs refresh every 12 hours using the above mentioned technique. This provided shell script also showed how data can be taken from anywhere independent of the manual way google colabs grants us(through use of button).
References Running Google Colaboratory as a server – transferring dynamic data in and out of colabs
- Tiago Carneiro , Raul Victor Medeiros Da Nóbrega, Thiago Nepomuceno , Gui-Bin Bian , Victor Hugo C. De Albuquerque , And Pedro Pedrosa Rebouças Filho : Performance Analysis of Google Colaboratory as a Tool for Accelerating Deep Learning Applications.
- inotifywait documentation https://linux.die.net/man/1/inotifywait
- Introduction to google drive API - https://developers.google.com/drive/api/v3/about-sdk
- Uploading files to google drive https://developers.google.com/drive/api/v3/reference/files/update
- Blog post for the same topic - https://medium.com/@samarthhalyal/uncloaking-google-collaboratory -8c52e0ecd55b
- HAROON SHAKIRAT OLUWATISON : Client-Server Model
- HIROSHI NISHIDA, THINH NGUYEN : Optimal Client-Server Assignment for Internet Distributed Systems
- LEEJA JOSEPH : Real Time Communication with Client/Server Architecture Using Secure Shell Protocol
