Семантическое ядро цифровой платформы

Автор: Максимов Н.В., Голицына О.Л., Ганченкова М.Г., Санатов Д.В., Разумов А.В.
Журнал: Онтология проектирования @ontology-of-designing
Рубрика: Инжиниринг онтологий
Статья в выпуске: 3 (29) т.8, 2018 года.
Бесплатный доступ
Дано обобщённое описание интегрированного комплекса декларативных и процедурных средств, в совокупности обеспечивающих согласованное информационное (семантическое) представление сложных объектов на всех этапах их жизненного цикла. Знания (факты) представляются системой онтологий разного уровня, а структура - таксономиями и классификациями. Онтология определяется как система трёх взаимосвязанных систем (функциональной, понятийной и знаковой), а система таксономий представляет классы объектов и процессов, характерных для основных «координат» деятельности. Информационный поиск, как компонент семантического ядра, рассматривается как сложный самосогласованный процесс конструирования нового знания, где знание - это информация (тексты находимых документов), связываемая с контекстом задачи и представлениями пользователя. Такой контекст целенаправленно или косвенно задаётся пользователем посредством предопределённых семантических структур (таксономий, онтологий) либо посредством динамически формируемых компонентов (словников, выборок и т.д.). Это составляет существо семантического когнитивного поиска, когда система не только реализует отбор документов традиционными методами поиска, но и формирует образ информационной потребности, что, в свою очередь, позволит системе синтезировать комплексные, аспектно-ориентированные ответы. Предлагаются автоматизированные технологии поддержки лингвистического обеспечения, основанные на дистрибутивно-статистическом анализе как потоков объектного знания и неявного знания (извлекаемого системой в процессе взаимодействия), так и компонентов понятийно-терминологических систем. Представленные в статье средства апробированы в рамках разработанного программного комплекса xIRBIS-ML, предназначенного для организации семантического поиска в массивах данных сложных инженерных объектов.
Семантическое ядро, цифровые платформы, семантический поиск, онтологии
Короткий адрес: https://sciup.org/170178795
IDR: 170178795 | УДК: 004:81’37 | DOI: 10.18287/2223-9537-2018-8-3-412-426
Semantic core of digital platform
This article gives a generalized description of the integrated complex of declarative and procedural means, which together provide a consistent information (semantic) representation of complex objects at all stages of their life cycle. Knowledge (facts) is represented by a system of ontologies of different levels, and the structure - by taxonomies and classifications. Ontology is defined as a system of three interrelated systems (functional, conceptual and sign), and the system of taxonomies represents classes of objects and processes’ characteristic of the main "coordinates" of activity. Information retrieval, as a component of the semantic core, is considered as a complex self-consistent process of constructing new knowledge, where knowledge is information (texts of found documents) associated with the context of the task and the user's views. Such context is purposefully or indirectly determined by the user by means of predefined semantic structures (taxonomies, ontologies) or by means of dynamically formed components (dictionaries, samples, etc.). This is the essence of the semantic cognitive search, where the system not only implements the selection of documents by traditional retrieval methods, but also forms an image of information needs, which, in turn, will allow the system to synthesize complex, aspect-oriented answers. Automated technologies of linguistic support based on distributive-statistical analysis of both object knowledge and implicit knowledge flows (extracted by the system in the interaction process) and components of conceptual-terminological systems are proposed. Scientific and educational potential can be widely used to create a basic component of information and linguistic support in the early stages. The tools presented in the article are tested in the framework of the developed software xIrbis-ML, designed for semantic search of data in knowledge bases for complex engineering objects.
Текст научной статьи Семантическое ядро цифровой платформы
Согласно государственной программе « Цифровая экономика Российской Федерации» [1] эффективное развитие рынков и отраслей (сфер деятельности) в цифровой экономике возможно только при наличии развитых платформ, технологий, институциональной и инфраструктурной сред.
Для сложных технических и социальных систем, к которым относятся и указанные в упомянутой государственной программе цифровые платформы (ЦП), характерно то, что они состоят из большого числа неоднородных элементов и подсистем, которые обладают значительным разнообразием внутренних и внешних связей и могут находиться во множестве состояний, в том числе в процессах становления и эволюции. Поэтому важнейшей подзадачей задачи управления жизненным циклом (ЖЦ) сложных систем является, с одной стороны, развитие Интернета вещей, а с другой - управление знаниями на всех этапах ЖЦ этих систем. Именно последнее обеспечит возможность саморазвития сложных систем, синтетически включающих компоненты уровня вещей и уровня знаний. То есть управление знаниями на базе общей информационной ЦП в течение всего ЖЦ – это то, что обеспечивает единый, интегрированный подход к созданию, сбору, организации, распределению знаний, а в итоге приведёт к эффективному взаимодействию и использованию информационных и технологических ресурсов.
Рост актуальности вопросов развития ЦП, трансформация рынков проектирования и эксплуатации сложных инженерных объектов в таких отраслях, как атомная промышленность (где в настоящее время идёт активный поиск новых технологий управления знаниями), авиа-и судостроение, энергетика, существенно повысил актуальность тематики семантического поиска и сформировал запрос на соответствующие промышленные технологии.
Настоящая статья представляет собой обобщённое описание семантического ядра - комплекса декларативных, процедурных и информационных средств, которые в совокупности могут обеспечить согласованное семантическое представление сложных объектов, к множеству которых относятся и системы представления и управления знаниями. Разработанные1 и использованные подходы и решения представлены кратко, в объёме, который необходим для указания места и роли компонентов.
1 Цифровая платформа и семантическое ядро
ЦП – система алгоритмизированных взаимоотношений значимого количества участников рынка, объединённых единой информационной средой, приводящая к снижению транзакционных издержек за счёт применения пакета цифровых технологий и изменения системы разделения труда [1]. Другими словами, ЦП – это площадка, поддерживающая комплекс автоматизированных процессов и согласованное использование широкого спектра цифровых продуктов (услуг) значительным количеством потребителей.
Одним из вопросов развития ЦП является взаимодействие технологических платформ между собой и взаимодействие ЦП с экосистемой. Основой такого взаимодействия являются декларативные и процедурные средства, обеспечивающие интероперабельность информационных систем (ИС), а также стандартизация информационных технологий (ИТ). При этом, согласно [2], одним из ключевых условий интероперабельности современных платформ является наличие семантического слоя организации данных.
Функциональность семантического слоя определяется характеристиками семантического ядра, которое представляет собой систему декларативных и процедурных средств, обеспечивающих согласованную автоматическую и автоматизированную (в том числе и интерактивную) идентификацию, поиск и анализ информации и знаний.
Семантический слой организации данных, по сути являющийся субплатформой, – это синтетическое соединение трёх компонентов:
-
■ документальных информационно-поисковых систем и баз данных, обеспечивающих углублённый семантический поиск и анализ разнородной информации;
-
■ человеко-машинных информационных интерфейсов, обеспечивающих персонифицируемое представление познавательной траектории пользователя;
-
■ лингвистического обеспечения, построенного на базе гибридных методов лингвистического, лингво-статистического и структурного анализа текстов, обеспечивающих построение адекватных смысловому содержанию документов их формализованных семантических образов, над которыми определены операции, в том числе, корреспондирующие с процессами познания.
Это триединство рассматривается в контексте общего процесса синтеза, представления и поиска знаний.
Для современного состояния рынка ИТ-продуктов, ориентированных на работу с семантикой (цифровой инжиниринг, управление знаниями, семантическая обработка текстов) характерно то, что эти системы, как правило, создаются либо как закрытые проприетарные промышленные продукты, либо как узкоспециализированные решения, либо как академические проекты, что накладывает существенные ограничения на интероперабельность и, как следствие, на их широкое или совместное использование. Например, для полноценной цифровизации проектов атомной энергетики необходимо в части семантики совместить решения систем проектирования от Intergraf, Siemens, Dassault Systems, информационные системы, ориентированные на сохранение и управление знаниями, как например, Temelin knowledge management system [3] или система сохранения знаний по быстрым реакторам [4], а также функциональные технологии, ориентированные на обработку текстов и извлечение знаний, как ABBYY Compreno [5] или RCO Fact Extractor [6], технологии OSTIS [7].
Особенно острой эта проблема становится в условиях смещения границы отраслевых рынков и связанных с этим смещений границ семантического описания предметных областей (ПрО). Необходимо создание семантической инфраструктуры, способной интегрировать семантические данные из разных отраслей промышленности и областей знаний, а значит быть открытой для использования различными компаниями и способной интегрировать сторонних поставщиков семантического программного обеспечения.
Другая проблема, преодоление которой обеспечит выход ЦП на новый уровень, - высокая динамика изменения данных и связанных с ними метаданных. То есть семантическое ядро ЦП должно обладать свойствами, обеспечивающими саморазвитие. В частности, в контексте задач семантического поиска и управления знаниями система должна идентифицировать (индексировать) информацию «на лету» в зависимости от специфики задачи пользователя, отражаемой в когнитивных инфраструктурах.
2 Основные принципы разработки и функционирования ЦП
Семантическая платформа xIRBIS-ML – ориентированная на управление знаниями информационно-аналитическая система, разрабатываемой коллективом специалистов НИЯУ МИФИ, Фонда «Центр стратегических разработок «Северо-Запад» и ООО «Медиа-Лаб». Семантическое ядро ЦП xIRBIS-ML проектируется как система, обладающая свойствами функциональной полноты по отношению к среде, включая пользователей, а с точки зрения наполнения – как способная гармонично представлять знания разных отраслей и на разных уровнях общности/детализации. Основными принципами разработки и функционирования являются:
-
■ взаимодополнительность процессов анализа/синтеза восходящих/нисходящих информационных потоков (знаний/информационных потребностей);
-
■ интеграция функций и основных элементов информационного сопровождения этапов цикла генерации-использования знаний/данных на основе модели информационных представлений, основанной на принципах общей теории систем;
-
■ полнота и избирательность информационного поиска, обеспечиваемые системой механизмов поиска и поиском в ассоциированных внешних информационных ресурсах (ИР);
-
■ динамическая синхронизация взаимосвязи информационных и метаинформационных компонентов, основанная на общесистемной модели информационных представлений когнитивных процессов и управления;
-
■ технологии оперативного построения и анализа лингвистического обеспечения (словников, рубрикаторов, тезаурусов, онтологий ПрО).
3 Интерактивный семантический поиск
Одной из основных и сложных задач семантики является смысловое отождествление содержания документов поисковым запросам. Такие подходы основываются на тезисе «смысл слова определяется его окружением» и, по существу, реализуют выявление контекста и, таким образом - определение (выбор) смысла слова.
При этом, говоря о семантическом поиске, необходимо понимать две особенности, которые важны для такого рода систем.
Первая – это то, что слово (словосочетание, выражение и даже весь текст) из найденного документа будет восприниматься в контексте пользователя . То есть смысл будет формироваться преимущественно на основе ПрО решаемой пользователем задачи и зависеть от полноты и специфики представления ПрО. При этом контекст ПрО, а именно общепринятые понятия и отношения между ними, может быть взят из базы знаний в общем случае интегрированной онтологии ПрО. Контекст пользовательского представления может быть сформирован динамически в процессе поиска путём построения виртуальной онтологии задачи из базовых онтологий и онтологических описаний отдельных решений [8]. Это помогает учитывать знания, которые в явном виде не присутствуют в конкретном высказывании/запросе, но существенно влияют на его смысл.
Вторая - это то, что пользователь «выстраивает» образ искомого решения, извлекая из текстов смысловые (и текстовые) фрагменты и связывая их таким образом, чтобы получаемая понятийная конструкция была непротиворечивой и обеспечивала бы решение его проблемы.
Технологической основой реализованной в xIRBIS-ML среды информационного взаимодействия «пользователь-система» является поисковый интерфейс, представляющий обобщённое рабочее пространство пользователя, ориентированное на процессы генерации знаний. Принципиально рабочее пространство включает две составляющие: собственно интерфейс формирования/развития запроса и обработки выдачи, а также структуру систематизации знаний пользователя – так называемый когнитивный рубрикатор (КР).
Поисковый интерфейс, помимо фактографического, тематического, семантического поиска с использованием чётких и нечётких механизмов отбора, вербальных или гипертекстовых технологий, позволяет пользователю осуществлять комплексный поиск (мультиобъект-ный, многоэтапный), например, для задач мониторинга проекта. Система, формируя поисковые образы и выдачи, готовит альтернативы, а структуры систематизации, протоколирующие поиск и идентифицирующие результаты, - задают направления «предпочтительного» развития. Эта задача решается как традиционными механизмами поиска, так и за счёт интерактивных средств визуального пространства, процедурно связывающих операционные объекты разного типа. В последнем случае поисковая траектория реализуется путём перемещения по ассоциированным визуальным элементам в находимых документах. Элементами могут быть слова или фрагменты текста, выделяемые по критерию соответствия понятиям, присутствующим в запросе или в профиле пользователя, а также динамически генерируемые гипертек- стовые ссылки. Движущей силой, инициирующей очередные шаги поиска, является проблемная ситуация – информационная неопределённость, осознаваемая пользователем, а также дисбаланс в наполнении тематических подразделов проблемы. Автоматическое «отслеживание» таких дисбалансов обеспечивается использованием в качестве интегральной информационной структуры КР, включающего как информационные (документы, запросы, ссылки на ассоциированные ресурсы и т.п.) и метаинформационные (словари ПрО, классификации, рубрикаторы, тезаурусы, онтологии) компоненты, так и результаты аналитической обработки [9]. То есть поисковая система, помимо собственно отбора документов по заданному пользователем запросу, может способствовать выявлению предмета поиска (технологии извлечения и идентификации неявных знаний), а также обеспечить согласование на концептуальном и лингвистическом уровнях представления предмета поиска на стороне системы и пользователя.
Такая структура, соединяющая интенсиональное и экстенсиональное начала процесса познания отдельного субъекта и при этом представленная в распределённой сетевой среде, позволит осуществлять управляемый мониторинг как документальной, так и понятийнотерминологической составляющей. Это по сути является реализацией системного подхода и даёт возможность видеть в явной форме новые характеристические признаки, определять способы выделения подсистем и на основе свойств соответствия и симметрии обнаруживать связи (в т.ч. и противоречия) с другими системами классификации. Пользователь, осуществляющий поиск интересующей его информации, получает «многослойную» картину ПрО, что в итоге позволит ему систематизировать найденное и сделать более обоснованный выбор «траектории» поиска, учитывающий не только его представление о предмете поиска, но и сопоставительные оценки состояния и тенденций ПрО.
4 Информационные и лингвистические компоненты
Блок ЦП, практически представляющий собственно семантику в реализации xIRBIS-ML, содержит два типа логически взаимосвязанных компонентов.
Первый тип – это собственно «рабочая» информация, использование которой в сфере основной деятельности обеспечивает воспроизводство целевого продукта по его описанию (документации, схеме и т.п.). Это т.н. задокументированные знания (зафиксированные на носителе определённым способом), включая фактографические (таблицы данных, свойств и т.д.) и документальные виды информации (статьи, монографии, учебные пособия и т.д.), представляющие теории, гипотезы, эксперименты, критический опыт.
Второй тип – это информация справочного характера, обеспечивающая, в основном, представление и нахождение целевой (рабочей) информации. Сюда относятся:
-
■ понятийно-терминологические системы (словари, тезаурусы, онтологии, глоссарии), являющиеся инструментами познания и средствами фиксирования знаний на носителях;
-
■ классификационные схемы (таксономии, рубрикаторы и т.д.), обеспечивающие единообразие «членения» ПрО, исходя из целевых, организационных или методологических представлений.
Перечисленные и другие виды и формы вторичной информации представляют объективно-исторически и технологически сложившийся ряд [10] функционально-ориентированных инструментальных форм представления существа (семантики) информационных единиц с той или иной полнотой и точностью [11]. При этом с точки зрения характера источника смысла – определений, гипотез, теорий, базовых методов, частных решений и т.п. - различаются онтологии задач, решений, онтологии физических свойств и единиц измерения и т.д.
Кроме того, существуют и развиваются онтологии терминосистем, как, например, проекты WordNet [12], РуТез [13], FrameNet [14].
Практически построение онтологий осуществляется на базе следующих трёх блоков - источников информации:
-
■ первый блок - фундаментальные знания, которые составляют статьи, монографии, отчёты, диссертации и т.п., представляющие объекты модельного уровня;
-
■ второй блок - базовые компетентностные знания, в том числе учебная и методическая информация, которая представлена учебниками, пособиями, методическими указаниями, хрестоматиями и т.п., содержащими описание существа (содержания) предмета. Кроме того, в этот блок входят справочно-методические материалы – учебные программы, оценочные средства, которые определяют структуру знания и технологию познания, в том числе опорные и контрольные точки;
-
■ третий блок - знания практического уровня, которые представлены проектной, конструкторской, технологической, нормативной документацией, экономическими, экологическими, аналитическими отчётами и т.п.
При этом в практике ИС понятийная основа устойчиво фиксируется в информационнопоисковых тезаурусах – наиболее известной и технологичной упорядоченной форме понятийно-знаковых систем.
Таксономические системы через упорядоченность концептуальных (классов) и реальных (экземпляров) составляющих, а также признаков классификации (существенных свойств) представляют целостность семантического пространства. В свою очередь онтологии различных уровней дискретно представляют «фрагменты» ПрО через ситуативные связи экземпляров объектов (знаний) различного уровня.
Роли лингво-семантических компонентов определяются исходя из того, что основными пространствами жизни объекта являются:
-
■ пространство основной деятельности субъекта, где по форме существования выделяются два подпространства – абстрактных объектов (концептуальные модели, теории, составляющие предмет деятельности) и конкретных объектов (физические объекты ЖЦ);
-
■ пространство информационной деятельности субъекта, предопределяющее способы и формы представления объекта в виде информационных сообщений;
-
■ время как фактор, обусловливающий изменение знания и условий его применения, и как свойство, позволяющее фиксировать знание в виде дискретных макрообъектов.
Таким образом, для структурно-систематизированного представления состоявшегося (сгенерированного, систематизированного, проверенного, задокументированного) знания используется следующая «сетка координат»:
-
■ координата «объект», задаваемая структурной таксономией, представляющей составные части объекта (узлы, детали, технологии и т.п.) с точки зрения совокупного процесса ЖЦ;
-
■ координата «предмет», задаваемая функциональной таксономией (как «абстрактная модель ПрО») – структурой, представляющей теоретические и иные знания, относящиеся к этапам ЖЦ изделия;
-
■ координата этапов работ (как фактор, отражающий разделение работ, предопределяемое специализацией субъекта, в процессах ЖЦ), задаваемая таксономией стадий и этапов ЖЦ и так или иначе связанной с ней таксономией форм представления знания – типов и видов документов как специфических форм и способов описания объекта.
При этом, подобно соотношению практической и модельной составляющих в целенаправленной деятельности в информационной деятельности выделяются ситуационная (на вторичном уровне наиболее полно представлена онтологиями) и структурно-концептуальная (на вторичном уровне представлена таксономиями) составляющие. Первая отражает комбинаторную природу деятельности и языка, позволяющую выражать (обозначать) новые смыслы «старыми» знаками. Вторая представляет базис, который обеспечивает преемственность и «вектор» развития ПрО, а в части процессов информационных коммуникаций является основой для «узнавания» нового за счёт апелляций к общим смыслам.
С точки зрения идентификации информации и знаний важным и перспективным свойством онтологического представления семантики является то, что, в отличие от линейного поискового образа в нём представлены ситуации (факт имманентной или ситуативной взаимосвязи двух объектов).
Онтология с точки зрения общей теории систем определена в [15] как совокупность трёх взаимосвязанных систем:
O =< Sf, Sc, St ≡>, где Sf - функциональная система (объекты и связи действительности) определяется как
Sf =< Mf, Af, Rf, Zf >, где Mf множество объектов, Af множество характеристических свойств, Rf – множество функциональных отношений, Zf закон композиции, т.е., правил и схем упорядочения объектов (таксономия ПрО);
S c - понятийная система, определённая как
Sc =< Mc, Ac, Rc, Zc >, где Mc – множество понятий ПрО, Ac – множество признаков систематизации понятий (ме-рономия), Rc – классы/подклассы парадигматических отношений, Zc – закон композиции (схема упорядочения);
S t - терминологическая система, определённая как
St =< Mt, At, Rt, Zt >, где Mt - множество терминов, At – множество свойств, Rt – множество отношений эквивалентности и включения, а также лингвистических отношений, Zt – закон композиции (грамматика);
≡ - операция сопоставления элементов различных систем на уровне знаков, обеспечивающая их тождество в функциональной, понятийной и терминологической системах.
Автоматическое построение онтологий на основе представленных на естественном языке текстов, т.е. формирование связей между выделенными в тексте понятиями, основывается на преобразовании лингвистических отношений в функциональные. При этом набор типовых, так называемых функциональных, связей для ПрО обычно ограничен (подробно см. [16, 17]).
Автоматически построенные понятийно-терминологические графы могут быть отредактированы средствами интерактивных человеко-машинных процедур, которые в этом случае реализуют принцип дополнительности: представление знания в виде извлекаемых из текста ключевых слов и отношений система осуществляет с «устоявшейся» точки зрения (статистической значимости), а человек, внося изменения и дополнения в построенный системой образ (список терминов, граф), фиксирует отличия, характеризующие новизну и специфику по отношению к устоявшемуся и усредненному представлению знаний.
Однако при практическом построен и и таких объектов во з никают с у щественн ы е сложности. Бога т ство лексики естест в енного я з ыка приводит к том у , что пр им енение к построенным по текстам онтологиям т е оретико-г р афовых операций ( н апример, о бъедине н ие или пересечение) для определения и х семантич е ской бли з ости не д а ёт резуль та та: понят и я (точнее, обознача ю щие их знаки), выд е ленные в сопоставл я емых тек с тах, не п е ресекаются. Определённый выход из этой ситуац и и заключ а ется в приведении л е ксики по с троенных онтологий к лексике согласованной поня т ийно-тер м инологической стру к туры (нап р имер, тез а уруса).
Представление систем, вх о дящих в о пределение онтолог и и, в виде графов п о зволит использова т ь при формализаци и выполне н ия операций над он т ологиями аксиомы т еоретикографовых операций. В качест в е основн ы х операц и й использ у ются бин а рные опе р ации объединения и пересечения и уна р ные - пос т роения аспектного п редставле н ия и мас ш табирования онтологий, с помощью ко т орых мож н о, в том числе, синт е зировать н овые онт о логии (так называем ы е прикладные онто л огии), от р ажающие ПрО в за д анном ас п екте. Отл и чительной особенностью реализации опе р аций над онтологиями является возмо жн ость исп о льзования для повы ш ения семантическо й связност и структур понятийн о го и терм и нологиче с кого уровней [18].
На р и сунке 1 представле н фрагмен т результа т а операц и и объеди н ения онт о логий, построенных по текстам конструкторских документ о в ПрО « А томная э н ергетика » : «Компоновка основного оборудова н ия», «Пр о чность и сейсмос т ойкость», «Внутри к орпусные устройст в а», «Технические ре ш ения при модерниз а ции реакторной уст а новки», « И сточники излучения». Общие узлы, вхо д ящие в не с кольких онтологий ф ункциона л ьного ур о вня, выделены на рисунке темно-серы м фоном, а узлы, соответствующие поня т ийной си с теме – серым. Тез а урусные связи обозначены: RТ (Related T erm) – свя з ь с ассоц и ативным д ескриптором, BТ ( B roader Term) – связ ь с вышес т оящим дескрипторо м , NT (Nar r ower Ter m ) – связь с нижестоящим дескриптором. В результ а те использования в качестве о бщего п о нятийного базиса тезауруса INIS МАГА Т Э [19] уд а лось пов ы сить сема н тическую связность объединения путё м добавления тезауру с ных мар ш рутов.
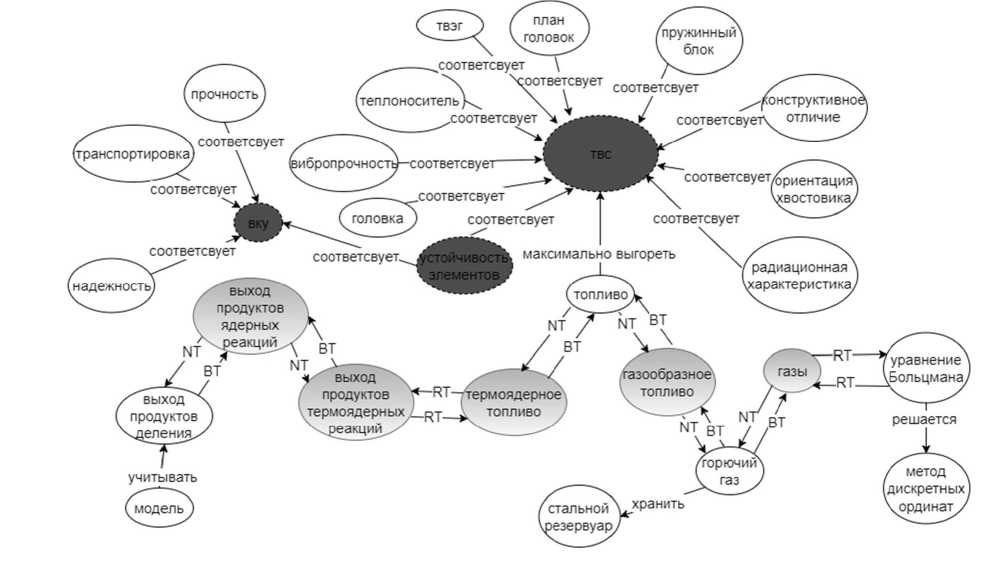
Рисунок 1 – Фраг м ент графа - р езультата о п ерации объединения онт о логий
След у ет отметить, что пр и построе н ии онтол о гии не вс е гда удаёт с я передат ь контекст конкретн о го термина, если на структур н ом уровне этот термин (как о тд ельная в е ршина) не будет свя з ан доопределяющи м термино м . Для пре о доления подобных п роблем п р едлагается использо в ать взвешенный ори е нтирован н ый метаг р аф
MG f = (V f , V f M ,X f ), где Vf - м ножество вершин (т е рминов); V ^ - мно ж ество ме т авершин, к аждая из которых в свою оче р едь может быть ме т аграфом; X f - мно ж ество дуг (отношен и й), опред е лённых на множеств е Vf U V “ , и Vx; е X f :x; = {vb t , ve;, {tr i , Л ;)}, где tr i е TR ( TR - множе с тво типов отношен и й), А ( - множество х арактери с тических атрибутов отношен и й, соотве т ствующих дугам.
На ри с унке 2 приведён пр и мер мета гр афа, пос т роенного д ля следу ю щего фра г мента текста: « Кла п аны на вертикальн ы х сосудах с ледует у с танавлив а ть на вер х нем днищ е . Клапаны не допуск а ется использовать д ля регули р ования д а вления в с о суде или г руппе сос у дов. Изготовитель обязан поставлять к лапаны с п аспорто м и руководством по э ксплуата ц ии ».
Выше отмечалось, что он т ология о б ладает св о йствами системы. О пределяя с истемный базис - п о дмножества свойств и типов о т ношений, соответст в ующих а с пекту, ил и функцию отображе н ия на другую онтол о гию, мож н о постро и ть подсис т емы и пр о екции, ко т орые сами являются системами. Это озн а чает, что п риведённ о е выше г р афовое п р едставлен и е онтологии обла д ает характерным свойством м ультигра ф ов. Отмет и м также, что поск о льку пара объектов П рО может быть св я зана неск о лькими т и пами отн о шений, то граф мо ж но классифицирова т ь как гиперграф.
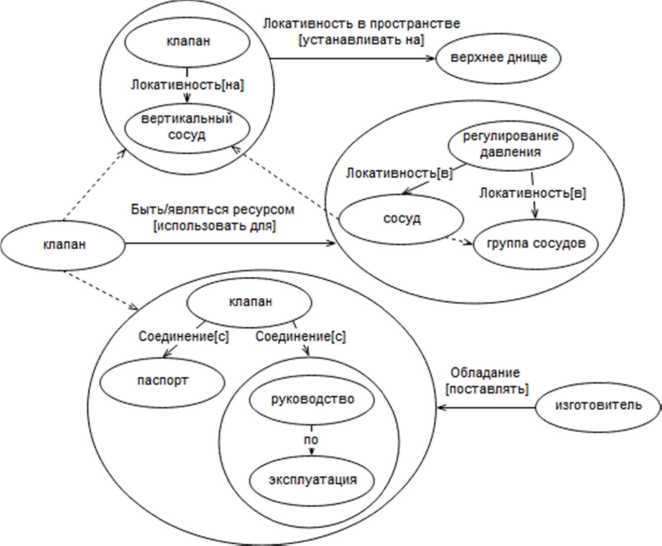
Рису н ок 2 - Пример метаграф а с типизиро в анными отн о шениями (в квадратных скобках при в едена линг в истическая конструкци я из текста, п у нктирными линиями об о значены ие р архические с вязи)
5 Архитектура и функциональные подсистемы
ИТ-среда всегда отличалась своей гетерогенностью, несмотря на многочисленные попытки её глобальной стандартизации. Современная тенденция, диктуя свои требования, за- ставляет отвечать на подобный вызов созданием кроссплатформенных систем, способных работать с одинаковой эффективностью независимо от ИТ-инфраструктуры конечного пользователя. Одним из ответов на подобное требование является агентный принцип и наличие развитого программного интерфейса, позволяющего гибко и эффективно подстраиваться под текущие пользовательские тренды и ставшего неотъемлемой частью сложных систем. В частности, платформа xIRBIS-ML позволяет интегрировать лингвистические компоненты нескольких производителей.
Основными отличиями xIRBIS-ML являются:
-
■ семантическая интеграции информации, относящейся к разным видам деятельности и всем этапам ЖЦ, при которой информационные объекты рассматриваются как имеющие двойное назначение: порождаются и используются в целевой деятельности пользователя и являются метаинформацией в процессах информационного обеспечения этой деятельности;
-
■ ориентированное на задачи когнитивного поиска многоаспектное индексирование разнородной информации, в том числе с использованием взаимодополняющих технологий лингвистических процессоров и эвристических методов, обеспечивающих глубокое семантическое индексирование и последующее выделение аспектов (динамическое индексирование);
-
■ комплексное использование разнотипных методов и моделей отбора документов;
-
■ гибкий поисковый интерфейс, ориентированный на задачи анализа и синтеза информации;
-
■ объединённая объектно-ориентированная модель, совмещающая как данные информационных процессов, так и метаданные, определяющие параметры обработки.
-
5.1 Основные подсистемы xIRBIS-ML
-
5.2 Объектная модель xIRBIS-ML
Подсистема сбора и обработки документов обеспечивает импорт документов с преобразованием в унифицированный хорошо структурированный формат путём выделения структурных элементов, а также многоаспектное индексирование содержания, в том числе с возможностью интерактивного редактирования автоматически приписываемых классификационных кодов, списков ключевых слов и онтологий. Построение многоаспектного понятийного образа документа производится путём представления содержания в виде гиперграфа извлекаемых из текста понятий и типизируемых отношений, что позволяет не только динамически формировать онтологию знаний и выявлять новые понятия и связи, но также перейти к графически управляемым навигационным технологиям концептуального поиска. В итоге это обеспечивает более точный поиск, а интерактивные технологии индексирования – извлечение экспертных знаний для актуализации семантических компонентов.
Подсистема информационного поиска в распределённых ресурсах, помимо классических механизмов поиска по чётким/нечётким критериям и с реформулированием запроса по обратной связи, также обеспечивает переадресацию и адаптацию запроса для проведения поиска во внешних Интернет-ресурсах с учётом их особенностей, в том числе синтаксиса поисковых языков, что обеспечит более точный индивидуализируемый отбор информации.
Подсистема статистического анализа документальных потоков и лексики обеспечивает формирование распределений различных информационных срезов, а также построение и комплексный анализ временных рядов профилированных потоков документов и лексики. Это позволяет средствами комплексного дистрибутивно-статистического анализа потоков документов и запросов выявлять тенденции, источники и взаимозависимости, свойственные ПрО. Для отображения и анализа используются компоненты деловой графики.
Подсистема анализа и ведения лингвистического обеспечения ориентирована на поддержку пользовательского информационного пространства и обеспечивает построение и ведение иерархических терминологических (словарных и классификационных) структур ПрО, которые могут быть использованы в качестве средств систематизации ПрО, а также для автоматической классификации документов. Динамическое обновление состава и связей терминов основано на лингвистическом и статистическом анализе текстов документов и баз данных.
Подсистема мониторинга хода выполнения и анализа содержания проектов реализует: мониторинг показателей по всем этапам ЖЦ проекта; статистический анализ и систематизацию информацию о проекте и ассоциированных ПрО в локальной БД, а также в других ИР; автоматическое формирование сводных статистических портретов основных действующих лиц и т.п.
Основу интеграции информационной среды и управления поисковой навигацией xIRBIS-ML составляет объектная модель информационной среды, включающая расширенную объектную модель документа. Структура среды определяется трёхзвенностью совокупной ИС « пользователь – автоматизированная ИС (АИС) – ИР », где АИС, как промежуточное звено, должна обеспечивать согласование сторон – пользователя и ИР – каждая из которых имеет свою специфику организации и поведения.
Объектная модель трёхзвенной информационной среды специфицирует взаимодействие рабочего пространства пользователя (объект КР) и пользовательского интерфейса системы (задаваемого матрицей взаимосвязи функций поиска и обработки с интерфейсными операционными объектами).
Информационный ресурс, как объект рабочего пространства, характеризуется тремя группами параметров, определяющими:
-
■ собственно ресурс (идентификация, адрес, метод доступа, тип);
-
■ содержание ИР (тематика и характер ресурса, а также метаданные об элементах данных, документах и справочных ресурсах);
-
■ взаимодействие с ИР (поисковый вход и метод; синтаксис поискового языка; метод доступа к содержанию).
Базовым объектом является документ, характеризующийся формой представления (так называемой схемой документа), которых может быть несколько. Документ представляет собой иерархию элементов данных, для каждого из которых специфицируются: идентифика-тор(ы), тип, метод(ы) преобразования на входе/выходе, метод(ы) индексирования.
Заключение
Семантическое ядро, назначением которого является обеспечение семантически согласованной идентификации, поиска и анализа информации и знаний, в итоге должно обеспечивать «содержательное» отождествление текстов, сходных по смыслу, но вариантно представленных (описаний объекта в разных аспектах, разными словами, в разных формах и т.п.). В рамках сформулированных выше предложений это достигается использованием системного подхода: состоявшееся знание (факты) представлено онтологиями разного уровня, а его структура - таксономиями и классификациями. Причём онтология – это, в соответствии с семиотической моделью, система трёх взаимосвязанных систем (функциональной, понятийной и знаковой), а система таксономий представляет классы объектов и процессов, характерных для основных «координат» деятельности. Исходя из того, что новое знание всегда связано с известным, с помощью введённых операций над онтологиями становится возможным приведение описаний (их онтологических образов) к сопоставимым формам. Процесс конструирования нового знания, где знание – это информация, связанная с контекстом, реализуется средствами информационного поиска как компонента семантического ядра.
В рамках предложенных решений контекст явно или неявно определяется пользователем с помощью либо семантических структур (таксономий, онтологий ПрО), либо динамических компонентов (словников, КР), что позволяет говорить о полноценном семантическом поиске, когда система не только реализует более или менее интеллектуальный отбор документов, но и формирует выражения самой информационной потребности (в терминах, понятных системе), что позволит синтезировать комплексные , аспектно-ориентированные ответы.
Изложенные положения и решения семантического ядра в той или иной степени были использованы при разработке ряда опытных образцов и промышленных систем.
Список литературы Семантическое ядро цифровой платформы
- Государственная программа «Цифровая экономика Российской Федерации». Утверждена распоряжением Правительства Российской Федерации от 28 июля 2017 г. № 1632-р.
- ГОСТ Р 55062-2012 Информационные технологии (ИТ). Системы промышленной автоматизации и их интеграция. Интероперабельность. Основные положения. Утвержден и введен в действие Приказом Федерального агентства по техническому регулированию и метрологии от 13 ноября 2012 г. № 751-ст. Дата введения 2013-09-01.
- Kostiha, F. Knowledge management at Czech nuclear power plants / F. Kostiha // Bezpecnost Jaderne Energie, 2010, 18(7-8), P.203-209.
- Pryakhin, A. Fast reactor knowledge inventory / A. Pryakhin, A. Stanculescu, Y. Yanev // International Journal of Nuclear Knowledge Management, 2009, 3.2, P.199-209.
- Технология анализа и понимания текстов на естественном языке ABBYY Compreno. -https://www.abbyy.com/ru-ru/infoextractor/compreno/.
