Совместный анализ рентгенологических протоколов и компьютерных томограмм для автоматического уточнения патологических состояний головного мозга

Автор: Агафонова Юлия Дмитриевна, Гайдель Андрей Викторович, Зельтер Павел Михайлович, Капишников Александр Викторович, Кузнецов Андрей Владимирович, Суровцев Евгений Николаевич, Никоноров Артем Владимирович
Журнал: Компьютерная оптика @computer-optics
Рубрика: Обработка изображений, распознавание образов
Статья в выпуске: 1 т.47, 2023 года.
Бесплатный доступ
Рассматривается задача валидации радиологических медицинских протоколов и изображений компьютерной томографии для автоматизированного анализа состояния головного мозга. Предлагается два метода решения задачи: метод на основе мультимодальной модели ruCLIP и метод, основанный на совместном использовании двух отдельных классификаторов - для текстового отчета и для изображения КТ головного мозга. Обсуждаются способы оценки полученных результатов. Предложенные подходы позволяют верно классифицировать на 15 возможных диагнозов 99,6 % радиологических отчётов из контрольной выборки.
Глубокое обучение, компьютерная томография, автоматизация диагностики, распознавание образов, обработка естественного языка
Короткий адрес: https://sciup.org/140296252
IDR: 140296252 | DOI: 10.18287/2412-6179-CO-1201
Joint analysis of radiological reports and ct images for automatic validation of pathological brain conditions
We consider a problem of validation of radiological medical reports and computed tomography images for an automated analysis of brain structures. Two methods for solving the problem are proposed: a method based on the ruCLIP multimodal model, and a method based on the joint use of two separate classifiers - for a text report and for a brain CT image. We discuss methods evaluation and the obtained results. The proposed approaches make it possible to correctly classify 99.6 % of radiological reports from a test sampling into 15 possible diagnoses.
Текст научной статьи Совместный анализ рентгенологических протоколов и компьютерных томограмм для автоматического уточнения патологических состояний головного мозга
В настоящее время всё активнее развиваются методы автоматизированной медицинской диагностики заболеваний, поскольку они позволяют повысить скорость и эффективность работы медицинских учреждений по всему миру [1]. Для разработки систем поддержки принятия решений при медицинской диагностике требуются большие объёмы данных, которые зачастую вручную проходят предварительную обработку и разметку. Автоматизация этого процесса могла бы существенно расширить возможности разработчиков подобных информационных систем.
Между тем медицинские лаборатории по всему миру хранят огромные объёмы данных, включая радиологические изображения различной природы, в специальных базах данных, таких как PACS [2]. Эти данные хранятся в изначальном виде, без какой бы то ни было предварительной обработки и разметки, но зачастую изображения в таких базах сопровождаются радиологическими отчётами, написанными профессиональными радиологами при первичном анализе исследования.
Автоматическое сопоставление изображений в таких базах с радиологическими отчётами могло бы позволить уточнять имеющиеся диагнозы в режиме реального времени: если система обнаруживает несовпадение изображения и текста к нему, то она сигнализирует об этом с целью получения мнения ещё одного медицинского специалиста. Это могло бы значительно повысить эффективность диагностики, не требуя при этом значительных массивов размеченных данных для обучения.
Существует множество программ и систем, обеспечивающих классификацию медицинских данных по изображениям либо на основе медицинских протоколов.
Так, в [3] упоминается программная система для автоматизированного мониторинга данных в произвольном формате в медицинской информационной системе. Данная система использует инструмент обработки медицинского языка и правила, полученные на основе статистического анализа базы данных, для обработки протоколов о рентгенографии грудной клетки (CXR) в произвольном тексте и выявления протоколов, описывающих новые или расширяющиеся новообразования, с целью мониторинга состояния пациента. Однако данный метод опирается только на классификацию самих протоколов, не анализируя соответствующие им изображения.
Существуют также программы, которые классифицируют в основном изображения. В работе [4] упоминается классификация магнитно-резонансных томограмм головного мозга с помощью методов глубокого обучения. В качестве методов глубокого обучения используются методы на основе свёрточной нейронной сети (CNN), глубокой нейронной сети (DNN) и такие архитектуры нейронных сетей, как LeNet, AlexNet, ResNet. Особенность данного метода заключается в том, что при классификации учитываются дополнительные параметры, такие как возраст и пол. В данной работе изображения разбиваются всего на два класса: норма и патология, то есть дифференциальный диагноз не ставится.
В источнике [5] поднимается еще одна важная проблема – выбор конкретных двумерных срезов из всего множества изображений, которые появляются в результате проведения МРТ-диагностики. В данной работе также поднимается вопрос по выбору двумерных срезов из трехмерных. По исследованию можно сделать вывод о том, что авторы количественно оценили эффект утечки данных, вызванный разделением данных 3D-МРТ на основе уровня 2D-срезов, с использованием трех 2D-моделей CNN для классификации пациентов с болезнью Альцгеймера и болезнью Паркинсона. Однако данный метод решает только предварительный отбор используемых снимков для решения, при этом метод достаточно объемный, так как содержит множество операций для предобработки изображений, что негативно сказывается на скорости получения ответа от системы.
Стоит отметить, что в медицинских наблюдениях важно оценивать не только состояние пациентов на данный момент времени, но и отслеживать динамику изменения их состояния и проблемных областей. Однако пациентам зачастую не проводятся контрольные исследования или они проводятся нерегулярно, отчасти из-за отсутствия инструментов для лечения и времени, необходимого для обновления результатов исследования. Авторы [6] предлагают на основе обработки естественного языка (NLP) извлекать информацию из клинических документов с произвольным текстом. Идея подхода заключается в обнаружении отчёта, в котором описывается впервые выявленная опухоль, однако дифференциальная диагностика не производится.
Нельзя не отметить, что достоверная классификация изображений и медицинских протоколов важна не только для постановки диагноза, но и для поиска похожих клинических случаев, и для получения релевантных документов. Клинические медицинские записи содержат большое количество информации, которая обычно пишется в свободной текстовой форме и без лингвистического стандарта. Существуют алго- ритмы, позволяющие восстанавливать знания из текстовой информации в медицинских документах [7]. То есть данные алгоритмы помогают искать похожие клинические случаи на основе различных медицинских протоколов от разных врачей, несмотря на индивидуальный стиль написания протоколов и различные сокращения. Однако авторы данных алгоритмов не уточняют точную архитектуру использованных нейронных сетей.
В работе [8] совместный анализ радиологических отчётов и изображений использовался для выявления патологических изменений лёгких. Было показано, что использование информации о локализации патологии из радиологических отчётов позволяет повысить эффективность обнаружения эмфиземы.
Целью работы является повышение эффективности диагностики патологических изменений головного мозга за счет уточнения диагнозов с помощью автоматического сопоставления рентгенологических протоколов и компьютерных томограмм.
1. Совместная классификация текстов и изображений
В качестве базового подхода к совместной классификации текстов и изображений можно предложить классифицировать отдельно изображения и отдельно текстовые описания диагнозов, с последующей оценкой соответствия между результатом предсказания класса для изображений и для текстов.
Для решения этой задачи был использован набор данных из 978 изображений компьютерной томографии головного мозга и 978 соответствующих им текстовых радиологических отчётов. Изображения были получены в ходе клинической практики сотрудниками ФГБОУ ВО СамГМУ Минздрава России. На рис. 1 представлены примеры изображений из выборки.
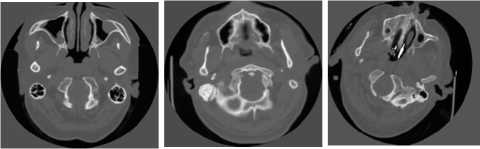
Рис. 1. Пример изображений из выборки
Изображения представляли собой избранные срезы компьютерной томографии мозга с медианным разрешением 512 на 512 отсчётов и 256 каналами яркости. Тексты отчётов были написаны в свободной форме на русском языке и содержали различное количество слов.
По описаниям изображения были разделены на классы. Классом является диагноз, который был указан пациенту в заключении рентгенолога. В том случае, если диагнозов было несколько, то брался первый диагноз из заключения. Таким образом, все изображения были поделены на 15 классов, они приведены в табл. 1.
Табл. 1. Количество изображений каждого класса
|
Наименование класса |
Количество изображений |
|
Патологии не выявлено |
179 |
|
Ишемический инсульт |
165 |
|
Дисциркуляторная энцефалопатия |
160 |
|
Отек головного мозга |
91 |
|
Геморрагический инсульт |
82 |
|
Субарахноидальное кровоизлияние |
54 |
|
Черепно-мозговая травма |
50 |
|
Положительная динамика |
44 |
|
Ликворная киста |
42 |
|
Лакунарный инсульт |
28 |
|
Атрофия головного мозга |
25 |
|
Гидроцефалия |
16 |
|
Эпидуральная гематома |
15 |
|
Аневризма |
14 |
|
Объемное образование головного мозга |
13 |
Всё множество имеющихся пациентов Q было разбито на обучающую выборку U и контрольную выборку Ũ в соотношении примерно 3:1. Для каждого пациента юе О в выборке содержалось изображение компьютерной томографии головного мозга этого пациента x ю ( n , m ):[0; N -1]x[0; M -1] о Z 2 ^ [0; Q -1] о Z , текст радиологического отчёта у ю ( t ):[0;| у ю |-1] о Z ^ W и диагноз z ю е [0; L –1] о Z , где N - высота изображения, M – ширина изображения, Q =256 – количество уровней яркости, L = 15 – количество различных диагнозов, | у ю | - количество слов в отчёте для пациента ю , Z - множество целых чисел, W - множество возможных слов в языке. Под словами понимаются последовательности подряд идущих букв, отделённых друг от друга любыми другими символами.
Классификатор изображений – это функция Ф ( x ):{ x ю | ю е Q } ^ [0; L -1] о Z , которая ставит в соответствие изображению компьютерной томографии некоторый номер диагноза. Классификатор текстов – это аналогичная функция V ( у ):{ у ю | юеО } ^ [0; L -1] о Z , которая ставит в соответствие тексту радиологического отчёта некоторый номер диагноза. И ту и другую функцию предлагается реализовать в виде нейронной сети с использованием подходов глубокого обучения. Разумеется, для обучения нейронных сетей следует использовать только обучающую выборку U , а для проверки эффективности её работы – контрольную выборку Ũ .
Достоверностью классификации будем называть отношение количества правильно классифицированных объектов из контрольной выборки к её общему объёму:
J a ^ Ф ) = | U| { фФ ^ x “ ) = z “^ е U }| , (1) J a ( Т ) = U { Т ( У “ ) = z “ | юе ° }| . (2)
Здесь и далее под обозначением | A | для конечного множества A имеется в виду количество элементов в этом множестве.
Нейронные сети на выходе имеют не номер класса, а значение дискриминантной функции для каждого класса, то есть они отображают объект распознавания в множество [0; 1]L. Если на выходе получен вектор F(ю) = ие[0;1]L, то сам предсказанный класс может быть определён как номер элемента этого вектора с наибольшим значением, то есть c = argmax ul .
l е [ 1; L ] о Z
В качестве альтернативного показателя качества работы нейронной сети можно использовать среднюю точность ранжирования классов (LRAP). Если занумеровать элементы из контрольной выборки ю i е U , то ответ нейронной сети можно представить в виде матрицы
Y = (FН,. ;uQ^z е[0;1]И"L, тогда идеальным ответом была бы матрица
Y = ( zю, = j)/е[1;иl]°Z е[0;1]U^L, j е[1; L ]n Z представляющая собой унитарный код для номеров классов объектов распознавания.
В этом случае LRAP оценивается по формуле:
J LRAP
и и f
I U - IE L= Y ( :, к )
„ |{ к е [ 1; L ] о Z | Y ( i , к ) = 1 л Y ( i , к ) > Y ( i , j ) }| Х j ^ Y - t 1 | { к е [ 1; L ] о Z\Y ( i , к ) > Y ( i , j ) }|
Этот показатель качества основан на среднеобратном ранге [9].
В качестве функции потерь при обучении этой нейронной сети использовалась категориальная кросс-энтропия [10]:
-
1 U.L.
J н ( Y , Y ) = -^EE y ( i , j ) log Y ( i , j ) ■
I U I i =l j =1
Для классификации изображений была построена простейшая свёрточная нейронная сеть, содержащая пять свёрточных слоёв. Для всех пяти сверточных слоев была использована функция активации ReLu. Общая архитектура этой нейронной сети представлена на рис. 2 и напоминает упрощённую AlexNet [11]. Число эпох для обучения было подобрано экспериментально.
Для классификации текстов была использована рекуррентная нейронная сеть на основе LSTM [12]. Архитектура отдельного блока LSTM хорошо извест- на и представлена на рис. 3. В настоящей работе на основе такого блока была построена простейшая нейронная сеть для классификации текстов, архитектура которой представлена на рис. 4. Следует ещё раз заметить, что набор классов для обеих нейронных сетей одинаковый и на выходе они выдают одинаковые по смыслу вектора дискриминантных значений.
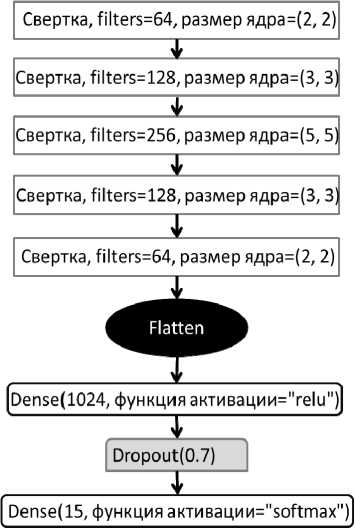
Рис. 2. Архитектура нейронной сети для классификации изображений
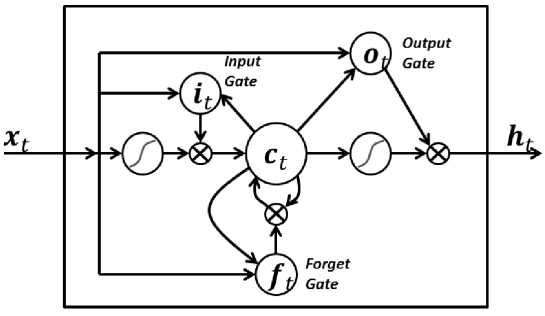
Рис. 3. Блок LSTM
Как известно, LSTM позволяет обучаться долгосрочным зависимостям, что позволяет использовать её для последовательностей токенов, таких как тексты. Кроме слоя LSTM, в архитектуре классификатора также можно заметить слой Embedding, который в качестве входных параметров принимал максимальную длину слова и максимальную длину всего описания в целом. Затем шел слой LSTM с числом нейронов 64. Далее было использовано два слоя субвекторизации, функция активации была выбрана ReLU и один полносвязный слой.
Предварительная обработка текста заключалась в замене слов на их номера в словаре, так что W с Z . После этого последовательность y ш ( t ) разбивалась на n-граммы по 150 слов, так что на вход нейронной сети подавалась последовательность векторов
Y „( k ) = ( y „( k + j ) ) j ,,; nb Z .
Для обучения этой нейронной сети использовалась функция потерь MSE:
UL 2
J mse ( Y , Y ) = ^ z L z ( Y ( i , j ) - Y ( i , j ) ) . (4)
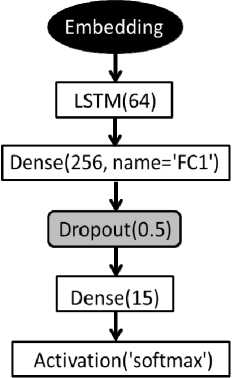
Рис. 4. Архитектура нейронной сети для классификации текстов
2. Мультимодальная модель ruCLIP
Нейросетевая модель ruCLIP (Russian Contrastive Language – Image Pre-training) – это мультимодальная модель русского языка, способная переводить изображения и тексты в единое векторное пространство. Она обучена для русского языка на открытых данных, собранных из Рунета. Всего для обучения использовалось около 240 млн уникальных пар «изображение – описание на естественном языке». Модель была представлена сотрудниками компании SberDevices, входящей в группу компаний Сбер [13]. Модель ruCLIP, в свою очередь, с незначительными изменениями основана на модели CLIP, разработанной сотрудниками компании OpenAI [14].
На рис. 5 схематично представлена работа ruCLIP. Видно, что модель состоит из двух частей (нейронных сетей). Image Encoder – это часть для кодирования изображений и перевода их в общее векторное пространство. В качестве архитектуры в оригинальной работе берутся ResNet разных размеров и Visual Transformer – тоже разных размеров. В ruCLIP Base в качестве image encoder используется ViT-B/16. Text Encoder – часть для кодирования текстов и перевода их в общее векторное пространство. В качестве архитектуры используется текстовый Transformer.
Таким образом, модель ruCLIP можно рассматривать как функцию F CLIP ( x , y ), переводящую изображение x ш ( n , m ) и текст y ш ( t ) в некоторый вещественный показатель их близости из множества [0;1]. Если же имеется множество занумерованных пациентов ш i е Q , для каждого из которых существуют томограммы этого пациента x ш i ( n, m ) и соответствующий ему текст радиологического отчёта y ю ( t ), то на выходе можно получить целую матрицу
Y CLIP( i,j ) = ( ^ CLIP ( x „, y ш , )) ,j ,[ 1;!^ ]п z е [ 0;1 ]'Ух|4 .
Показателем эффективности работы модели в этом случае можно считать, например, среднее зна- чение на диагонали этой матрицы. Чем больше среднее значение на диагонали, тем лучше.
J CLIP ( ^ CLIP ) = |^| tr ^ CLIP .
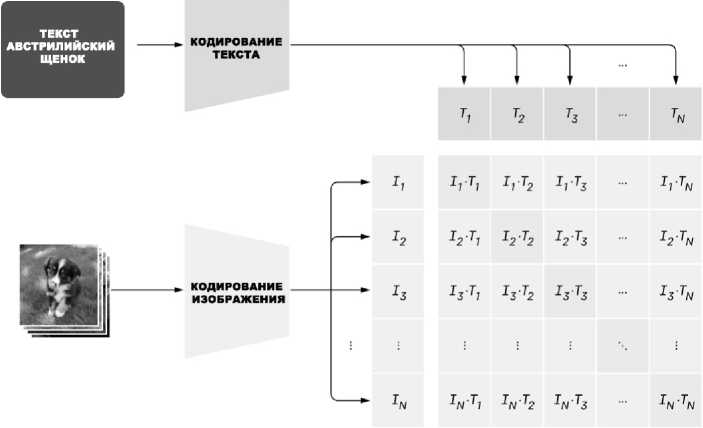
Рис. 5. Схема работы ruCLIP
В данной работе использовано две версии ruCLIP: оригинальная, выложенная её авторами, и дополнительно обученная на обучающей выборке U .
3. Результаты вычислительных экспериментов
В ходе экспериментов предложенные предсказательные модели были обучены на обучающей выборке, после чего эффективность их работы оценивалась на контрольной выборке. Для совместной классификации текстов и изображений классификаторы обучались по-разному.
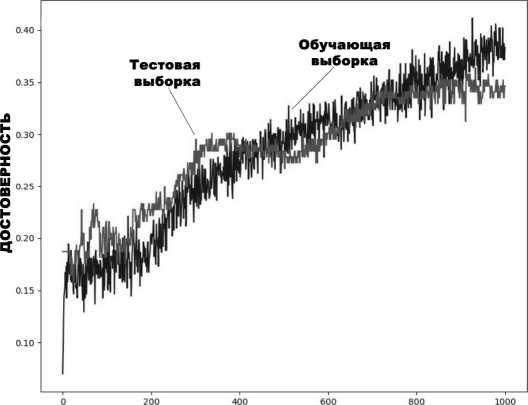
Выборка для классификатора изображений состояла из 978 изображений, 75% из которых было использовано для обучения классификатора и 25 % для проверки его работы. Обучение изначально длилось 1000 эпох. На рис. 6 представлено значение достоверности классификации (1) для обучения классификатора изображений в течение 1000 эпох.
ДОСТОВЕРНОСТЬ В ЗАВИСИМОСТИ от эпохи
число эпох
Рис. 6. Изменение достоверности классификации изображений для 1 000 эпох обучения
Значение достоверности составило 0,346, а LRAP – 0,533. Было приято решение увеличить число эпох, так как 15 классов – это достаточно много, и предсказательная модель может улучшиться в результате дальнейшего обучения.
На рис. 7 приведено значение достоверности классификации (1) во время обучения классификатора изображений, которое уже длилось 10000 эпох. Параметры нейронной сети остались без изменений.
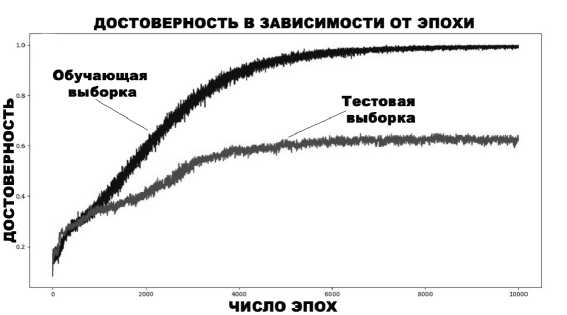
Рис. 7. Изменение достоверности классификации изображений для 10 000 эпох обучения
Для такого числа эпох достоверность классификации (1) составила 0,692, LRAP (3) – 0,795, что является неплохим результатам для классификации на 15 классов.
Классификатор текстов обучался на 978 медицинских отчетах, которые были разбиты на те же 15 классов, что и соответствующие им изображения. Классификатор обучался в течение 50 эпох. На рис. 8 видно, как функция потерь (4) убывает с каждой эпохой, а на рис. 9 – как с каждой эпохой растёт достоверность классификации (2). Значение достоверности классификации на тестовой выборке составило 0,996, что говорит о том, что классификация текстов радиологических отчётов представляет собой объективно несложную задачу.
Таким образом, мы практически безошибочно определяем класс, к которому относится текстовое описание медицинских изображений, и около 70 % изображений также классифицируем правильно.
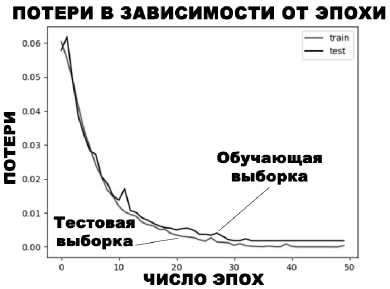
Рис. 8. Изменение функции потерь при обучении классификатора радиологических отчётов
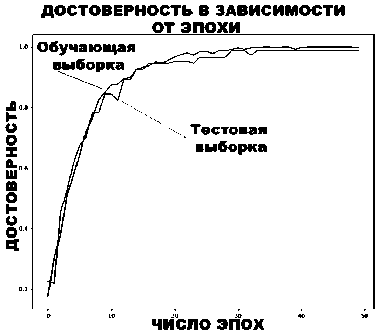
Рис. 9. Изменение достоверности при обучении классификатора радиологических отчётов
Перейдем ко второму подходу, основанному на ruCLIP. Изначально была взята базовая, предобучен-ная мультимодальная модель, которая была обучена на большом количестве изображений, но при этом не была обучена на медицинских данных.
В отличие от первого метода, ruCLIP выдаёт результат схожести, не оценивая отдельно, насколько текст похож на тот или иной класс и насколько изображение похоже на тот или иной класс. Для демонстрации работы ruCLIP была построена матрица Y CLIP ( i , j ), представленная на рис. 10. В табл. 2 можно найти расшифровку текстов, которые обозначены буквами «а», «б», «в», «г» и «д». Как можно заметить по диагонали матрицы, модель с большим трудом может установить соответствия между изображениями компьютерной томографии головного мозга и их радиологическими отчётами. Среднее значение параметра схожести (5) для исходной версии ruCLIP составило 0,294, при максимальном значении 1,0 и минимальном значении 0,0.
Для обучения модели ruCLIP выборка была разбита на обучающую и контрольную. В обучающую выборку вошло 75 % от общей выборки и оставшиеся
25 % попали в контрольную выборку. Все изображения были приведены к единому размеру 224 х 224 отсчёта. Максимальная длина текста составила 76 слов. Обучение длилось 71 эпоху и продолжалось в течение около 12 часов.
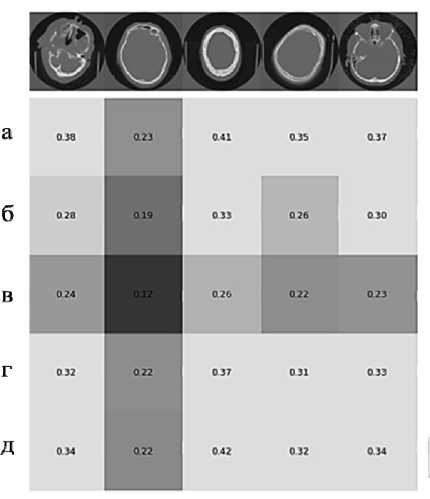
Рис. 10. Пример матрицы схожести для некоторых изображений КТ головного мозга и радиологических отчётов
Табл. 2. Примеры радиологических отчётов
|
Обозначение |
Текст |
|
а |
ОНМК по геморрагическому типу левой гемисферы головного мозга с прорывом в желудочки |
|
б |
Патологии не выявлено |
|
в |
Патологии не выявлено |
|
г |
ОНМК по ишемическому типу в бассейне ПВСА, отек правой гемисферы головного мозга |
|
д |
Умеренный отек правой гемисферы головного мозга |
После обучения было также подсчитано среднее значение схожести (5) для контрольной выборки, и оно составило 0,95.
Заключение
В ходе работы были предложены и исследованы два возможных подхода к совместному анализу томограмм и рентгенологических протоколов с целью автоматического уточнения патологических состояний головного мозга. Использование свёрточной нейронной сети для классификации изображений позволяет правильно классифицировать 69% изображений из контрольной выборки, а использование рекуррентной нейронной сети для классификации текстов позволяет правильно классифицировать 99,6 % радиологических отчётов. Совместное использование этих нейронных сетей может позволить автоматически проверять соответствие диагноза на изображении и в радиологическом отчёте. Также с этой целью можно использовать мультимодальную модель ruCLIP, которая после дополнительного обучения также способна предсказывать меру соответствия между заданным изображением и текстом. Пороговое значение подбирается экспериментально в зависимости от набора и типа данных.
Комплексное исследование эффективности на клинических данных показало, что использование двух простейших нейронных сетей позволяет добиться сопоставимых результатов по сравнению с моделью ruCLIP при том, что не требует больших объёмов памяти для хранения предсказательных моделей, больших объёмов выборки и времени на обучение. Модель ruCLIP же требует значительных вычислительных ресурсов, но при этом не показывает значительного прогресса при обучении на выборке из порядка тысячи медицинских изображений, что объясняется размерами самой модели и объёмами данных, которые были использованы для её обучения изначально. Эксперименты показывают, что для решения прикладной задачи сопоставления радиологических отчётов и изображений компьютерной томографии головного мозга достаточно использовать более простые нейронные сети, нежели ruCLIP.
Полученные в данной работе результаты могут быть в дальнейшем использованы при разработке автоматизированной системы уточнения поставленных диагнозов по данным, хранящимся в базах лечебных учереждений. Это может существенно повысить эффективность работы подобных медицинских учреждений, поскольку позволит в автоматическом режиме обнаруживать спорные случаи, требующие дополнительного внимания большего количества врачей-радиологов. Конечно, разработка подобной системы – это отдельная задача, которой авторы планируют заняться в будущем, а оценивание эффективности подобной системы потребует масштабного клинического исследования на большом количестве пациентов. В дальнейшем планируется провести совместный анализ для исследований других анатомических областей и модальностей, например, МРТ.
Работа выполнена при поддержке РФФИ (грант 19-29-01235МК).
Список литературы Совместный анализ рентгенологических протоколов и компьютерных томограмм для автоматического уточнения патологических состояний головного мозга
- Yanase J, Triantaphyllou E. A systematic survey of computer-aided diagnosis in medicine: Past and present developments. Expert Syst Appl 2019; 138: 112821. DOI: 10.1016/j.eswa.2019.112821.
- Choplin RH, Boehme JM, Maynard CD, Picture archiving and communication systems: an overview. Radiographics 1992; 12(1): 127-129. DOI: 10.1148/radiographics.12.1.1734458.
- Zingmond D, Lenert L. Monitoring free-text data using medical language processing. Comput Biomed Res 1993; 26(5): 467-481. DOI: 10.1006/cbmr.1993.1033.
- Wahlang I, Maji AK, Saha G, Chakrabarti P, Jasinski M, Leonowicz Z, Jasinska E. Brain magnetic resonance imaging classification using deep learning architectures with gender and age. Sensors 2022; 22: 1766.
- Yagis E, Atnafu SW, de Herrera AG, et al. Effect of data leakage in brain MRI classification using 2D convolutional neural networks. Sci Rep 2021; 11: 22544. DOI: 10.1038/s41598-021-01681-w.
- Bala W, Steinkamp J, Feeney T, Gupta A, Sharma A, Kantrowitz J, Cordella N, Moses J, Draken FT. A web application for adrenal incidentaloma identification, tracking, and management using machine learning. Appl Clin Inform 2020; 11(4): 606-616. DOI: 10.1055/s-0040-1715892.
- Dantas R, Bertoldi M, Wangenheim F. An approach for retrieval and knowledge communication using medical documents. Proc 23rd Int Conf on Software Engineering and Knowledge Engineering (SEKE) 2011: 169-174.
- Sludnova A, Shutko V, Gaidel A, Zelter P, Kapishnikov A, Nikonorov A. Identification of pathological changes in the lungs using an analysis of radiological reports and tomo-graphic images. Computer Optics 2021; 45(2): 261-266. DOI: 10.18287/2412-6179-CO-793.
- Wu Y, Mukunoki M, Funatomi T, Minoh M, Lao S. Optimizing mean reciprocal rank for person re-identification. 8th IEEE Int Conf on Advanced Video and Signal Based Surveillance (AVSS) 2011: 408-413. DOI: 10.1109/AVSS.2011.6027363.
- Chen CH, Lin PH, Hsieh JG, Cheng SL, Jeng JH. Robust multi-class classification using linearly scored categorical cross-entropy. 3rd IEEE Int Conf on Knowledge Innovation and Invention (ICKII) 2020: 200-203. DOI: 10.1109/ICKII50300.2020.9318835.
- Krizhevsky A, Sutskever I, Hinton GE. ImageNet classification with deep convolutional neural networks. Commun ACM 2017; 60(6): 84-90. DOI: 10.1145/3065386.
- Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput 1997; 9(8): 1735-1780. DOI: 10.1162/neco.1997.9.8.1735.
- Shonenkov A, Kuznetsov A, Dimitrov D, Shavrina T, Chesakov D, Maltseva A, Fenogenova A, Pavlov I, Emel-yanov A, Markov S, Bakshandaeva D, Shybaeva V, Chertok A. RuCLIP - new models and experiments: a technical report. arXiv Preprint. 2022. Source:
- Radford A, Kim JW, Hallacy C, Ramesh A, Goh G, Agarwal S, Sastry G, Askell A, Mishkin P, Clark J, Krue-ger G. Learning transferable visual models from natural language supervision. Int Conf on Machine Learning 2021; 139: 8748-8763.
