Создание модели для генерации изображений по текстовым описаниям методом авторегрессии по разрешению

Автор: Воронов А.Д.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Информатика и управление
Статья в выпуске: 4 (68) т.17, 2025 года.
Бесплатный доступ
В данной работе мы адаптируем VAR, недавно предложенную архитектуру для генерации изображений определённого класса, к задаче генерации изображений по текстовым описаниям (text-to-image). Для этого мы предлагаем несколько модификаций к оригинальной архитектуре, позволяющих обуславливаться на любой текст, а также улучшающих стабильность и сходимость обучения. Одна из таких модификаций — это замена маски внимания на блочно-диагональную, позволяющую быстрее сэмплировать изображения на инференсе и потреблять меньше памяти во время обучения. Итоговая модель, Scale-Wise Autoregressive Transformer (SWAT) — способна генерировать изображения в разрешении 512×512, сравнимые по визуальному качеству с генерациями лучших диффузионных моделей, превосходя их по скорости в семь раз. Наша работа показывает, что недиффузионные архитектуры могут стать новой парадигмой в texttoimage генерации, балансируя между качеством и эффективностью.
Генерация изображений, авторегрессия, трансформер
Короткий адрес: https://sciup.org/142247114
IDR: 142247114 | УДК: 004.932
Scale-wise autoregressive transformer for text-to-image generation
In this work we adapt VAR, a recently proposed architecture for class-conditional image generation, to the text-to-image synthesis. To support this transition, we first introduce several architectural modifications aimed at improving training stability and final performance. One of such modifications is transforming attention mask in VAR to a block-wise non-causal one, allowing faster sampling and reducing memory consumption. The resulting model, a Scale-Wise Autoregressive Transformer (SWAT) is capable of generating high-quality 512×512 images, achieving competitive visual fidelity compared to strong diffusion-based baselines, while being up to 7× faster at inference. Our work demonstrates that non-diffusion architectures can offer a compelling alternative for text-toimage generation, balancing quality and efficiency.
Текст научной статьи Создание модели для генерации изображений по текстовым описаниям методом авторегрессии по разрешению
Диффузионные модели (ДМ) сегодня доминируют в области генерации визуального контента. Они показывают отличные результаты в создании изображений по текстовому описанию, а также в генерации видео и ЗВ-моделей. В то же время в области генерации текста наибольших успехов добились авторегрессионные (АР) модели, что подталкивает исследователей пытаться адаптировать этот подход и для визуального домена.
АР-модели работают по принципу «предсказания следующего токена»: генерируемый объект представляется как последовательность токенов, и модель поочерёдно предсказывает каждый из них. В текстовом домене токенами могут являться слова или части слов, в визуальном — пиксели или части (патчи) изображения. Однако такие подходы к генерации изображений уступают диффузионным моделям как по качеству, так и по скорости.
Одно из объяснений, почему АР-модели работают хуже в визуальной сфере, чем в текстовой, заключается в том что представление изображения в виде последовательности токенов в растровом порядке (слева направо, сверху вниз) вносит необоснованный индуктивный сдвиг и ведёт к потери части информации, усложняя процесс обучения нейронной сети. Диффузионные модели, напротив, на каждой итерации работают со всем изображением и генерируют его поэтапно — от общего к частному, от грубой структуры к мелким деталям. Такая предпосылка к представлению изображений кажется более оправданной.
В недавней работе VAR [1] был предложен альтернативный метод токенизации изображений: в виде прогрессивно увеличивающихся разрешений (скейлов). Этот подход породил новый класс АР-моделей, авторегрессивных по разрешениям (scale-wise AR). Модели такого вида начинают генерацию с изображения низкого разрешения и на каждом шаге прибавляют результат генерации в более высоком разрешении. Такой подход тоже реализует стратегию от грубого к детальному, напоминая диффузионные методы, но требует меньше вычислений, так как большая часть работы делается на низких разрешениях. Это делает такие модели гораздо быстрее при сравнимом качестве.
В данной работе мы развиваем подход scale-wise авторегрессии, адаптируя метод VAR для генерации изображений по тексту (text-to-image). Сначала мы модифицируем существующую архитектуру для возможности обуславливаться на любой текст и вносим несколько изменений для повышения стабильности обучения.
Далее, мы изучаем более пристально процесс генерации изображения и приходим к выводу, что в оригинальной архитектуре обсулавливание на токены, сгенерированные на предыдущем этапе, происходит дважды: явно в операции self-attention и неявно при формировании входа для следующего шага генерации. Переход к блочно-диагональной маске внимания в операции self-attention позволяет сделать модель ещё эффективнее, что открывает возможности для более масштабируемого обучения. Вследствие этого качество итоговой модели также увеличивается.
2. Описание метода2.1. Токенизация изображения
Один из способов для представления изображения в виде последовательности токенов ---использование модели автокодировщика. Одна из архитектур автокодировщика, VQ-VAE [2], переводит изображение в последовательность дискретных значений ключей словаря (кодовой книги), каждому из которых сопоставлен вектор — латентная переменная.
Для представления изображения в виде прогрессивно увеличивающихся разрешений используется вариация этого метода — RQ-VAE [3], которая отображает изображение в пирамиду латентных представлений с разным разрешением, последовательно формируемую с использованием остаточной квантизации (Residual Quantization).
Таким образом, изображение ж G R3^ xW сначала переводится в латентное пространство энкодером 8: 8 (ж) = / G RCxhxwt а затем с помощью RQ-VAE HQ со словарём Z G Ry хС раскладывается на N скейлов следующим образом:
HQ(f, Z, N) = (qi,...,qN ) G [Е^hx-,
N а реконструкция изображения представляется как / = ^2 %. г=1
Тогда сэмплинг изображений с помощью scale-wise АР модели в выражается как:
N рв (qi,...,qN |с) = Цр0 (qi|qi,...,qi-i1c), (1)
i=1
где qi обозначает последовательность токенов на г-ом скейле, а с — обуславливающая информация (в нашем случае представление текстового описания).
В данной работе мы использовали предобученную модель RQ-VAE из оригинальной работы VAR для токенизации изображений, раскладывающую изображения 512x512 на N = 10 скейлов. В качестве генератора, модели в предсказывающей qi, обучалась архитектура трансформера.
2.2. Архитектура генератора
Для адаптации архитектуры VAR к задаче text-to-image необходимо было добавить способ обуславливания на текстовую информацию в блоках трансформера. В нашей архитектуре тексты кодируются двумя замороженными предобученными энкодерами: СЫР ViT-L [4] и OpenCLIP ViT-bigG, текстовые эмбеддинги которых конкатенируются по размерности каналов. Далее, текстовая информация передаётся в модель двумя способами: через операцию cross-attention между визуальными токенами текущего скейла и текстовыми эмбеддингами, а также усреднённый эмбеддинг из текстового энкодера OpenCLIP ViT-bigG используется в качестве стартового токена для генерации. Архитектура транс-формерных блоков, используемых в SWAT, изображена на рис. 1
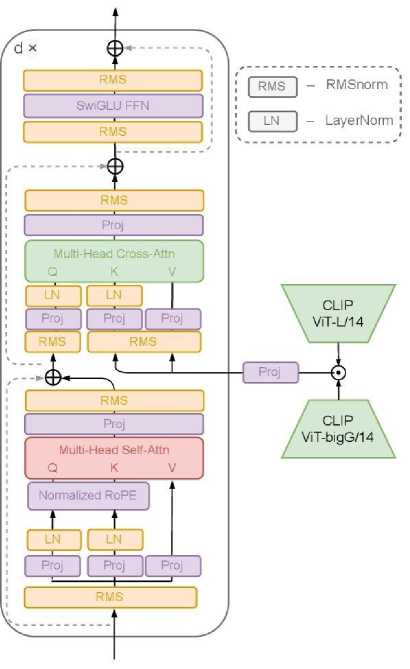
Рис. 1. Архитектура траисформериых блоков, используемых в SWAT
Во время первых экспериментов мы обнаружили проблемы со стабильностью обучения, которые приводили к субоптимальным результатам модели или даже к расхождению функции потерь. Наш анализ показал, что причиной такого нестабильного поведения является неконтролируемый рост активации в самых глубоких траисформериых блоках: нормы активаций во время обучения могли достигатв значений 1016. Мы обнаружили, что использование RMSNorm слоёв для нормализации вместо обычных LayerNorm, а также применение нормализационных слоёв и ко входам, и к выходам процеиругощих матриц в слоях внимания трансформера существенно снижает рост активаций.
Далее, мы тщательно проанализировали авторегрессионную процедуру сэмплирования по скейлам оригинальной работы VAR. По формуле 1, на каждом шаге генератора предсказывается последовательность токенов qt, обуславливаясь на предыдущие сгенерированные токены qi,..., qt-i- Патенты, соответствующие этим токенам, образуют Д G RhiXWi. На следующем шаге ft интерполируется в следующую предсказываемую размерность ht+1 х wt+1 и суммируется со всеми предыдущими предсказаниями, образуя вход для следующего шага генерации.
Таким образом, можно заметить, что обуславливание на информацию с предыдущих скейлов происходит дважды: один раз неявно, при формировании входа на текущем шаге генерации, и второй раз явно, так как в операции self-attention в каждом трансформерном блоке используется диагональная матрица внимания, при которой токены, предсказываемые на текущем шаге, взаимодействуют со всеми ранее сгенерированными токенами. Это наблюдение позволяет нам перейти к блочно-диагональной матрице внимания, что делает процедуру сэмплирования более эффективной, так как операции внимания будут потреблять меньше памяти, а также отпадает необходимость хранить в кэше ключи и значения внимания для токенов с прошлых шагов. Сравнение масок внимания в оригинальном VAR и предложенном SWAT приведено на рис. 2.
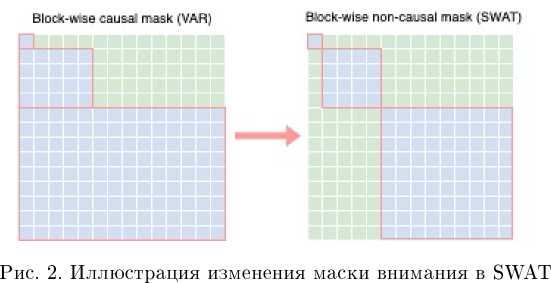
3. Обучение3.1. Данные
Для обучения был собран предварительный датасет из 6 млрд пар изображение-текст путём автоматизированного обхода и выгрузки данных из открытых интернет-источников, который затем проходил несколько стадий фильтрации. В первой стадии фильтрации были отсеяны пары с недостаточным соответствием текстовых описаний изображениям. Затем были отфильтрованы изображения, получившие низкую оценку моделями, обученными предсказывать эстетичность изображений. Также в итоговый датасет вошли только изображения достаточно высокого разрешения, где размер каждой стороны содержит минимум 512 пикселей. В итоговый датасет вошло 100 миллионов пар изображение-текст. Итоговые изображения были переаннотированы визуальными языковыми моделями (VLM) LLaVA-V1.4-13B, LLaVA-vl.6-34B [5] и ShareGPT4V [6].
SWAT обучался на случайных фрагментах из исходных изображений размером 512x512 пикселей. Для передачи модели информации об исходном расположении фрагмента, его координаты cieft, ctop были преобразованы в фурье-эмбеддинги, после чего проходили через линейный слой для совпадения размерности с эмбеддингом из OpenCLIP ViT-bigG.
3.2. Технические параметры обучения
В финальной модели SWAT использовалось 30 блоков трансформера, что в совокупности даёт 2.5В параметров. Модель училась в три этапа, в смешанной точности BF16/FP32. Для эффективного обучения на нескольких серверах мы использовали фреймворк FSDP из библиотеки PyTorch. Чтобы снизить потребление памяти во время обучения и ускорить шаги обучения, мы использовали предпосчитанные текстовые эмбеддинги от замороженных текстовых энкодеров.
На первой стадии обучения на разрешении 256x256 было сделано 400 тысяч итераций с размером батча 2560, что заняло примерно 25, 000 ГПУ-часов для графического ускорителя NVIDIA А100. learning rate линейно затухал от значения 1е—4 до 1е—5.
Затем мы обучались на изображениях разрешения 512x512 в течение 200 тысяч итераций с размером батча 768, с learning rate линейно затухающим от 1е—5 до 5е—7. Эта стадия заняла ещё ~12 тысяч NVIDIA А100 ГПУ-часов.
В последней стадии обучения мы дополнительно файн-тюнили модель на датасете из ~40, 000 пар изображение-текст, отдельно отобранных по критериям исключительной эстетичности изображений, с максимально детализированными и релевантными текстовыми описаниями. Эта стадия длилась 40 тысяч итераций с размером батча 80 и константным learning rate 5е—7. Использовались центральные фрагменты изображений 512x512.
4. Результаты4.1. Постановка сравнения
Бейзлайны Мы сравниваем нашу финальную модель с лучшими моделями аналогичного размера, находящимися в открытом доступе, представляющими различные подходы к text-to-image генерации:
• Диффузионные модели: Stable Diffusion XL, Stable Diffusion 3 Medium [7], Lumina-Next [8].
• Дистилляция диффузии: SDXL-Turbo [9], DMD2 [10]
• Авторегрессивные модели: LlamaGen-XL, HART [11].
4.2. Результаты сравнения
Метрики Мы оцениваем модели с помощью следующих стандартных метрик для text-to-image: CLIP Score [12] для оценки соответствия сгенерированного изображения текстовому описанию; FID [13] используется для оценки реалистичности сгенерированных изображений; ImageReward [14] и PickScore [15] — для моделей, обученных предсказывать пользовательские предпочтения; GenEval [16] — для комплексной оценки соответствия сложным текстовым запросам (учёт взаимного расположения, точное число объектов, и т.д.)
Для всех сравниваемых моделей мы генерировали изображения в их нативном разрешение, после чего переводили их в 512x512. Для подсчёта CLIP Score признаки извлекались с помощью предобученного CLIP-ViT-H-14-laion2B-s32B-b79K [17].
Датасеты Для подсчёта метрик мы используем распространённые для оценки text-to-image моделей датасеты MS-COCO [18] и MJHQ. Для обоих датасетов мы генерируем каждой моделью 1 изображение для 30, 000 текстовых промптов. Для подсчёта метрики GenEval [16] мы используем все предоставленные 533 промпта и генерируем по 4 изображения для каждого из них.
Значения валидационных метрик приведены в табл. 1.
SWAT достигает качества сопоставимого с лучшими бейзланайми, входя в топ-3 в 8 из 9 исследуемых метрик, будучи гораздо более эффективным чем конкуренты.
Таблица!
Валидационные метрики
|
MS-COCO 30K |
MJHQ 30K |
||||||||||
|
Model |
Latency, s/image |
Parameters count, В |
PickScore f |
CLIP f |
IR f |
FID 1 |
PickScore |
f CLIP f |
IR f |
FID 1 |
GenEval f |
|
Дистиллированные диффузионные модели |
|||||||||||
|
SDXL-Turbo [9] |
0.251 |
2.6 |
0.229 |
0.355 |
0.83 |
17.6 |
0.216 |
0.365 |
0.84 |
15.7 |
0.55 |
|
DMD2 [10] |
0.251 |
2.6 |
0.231 |
0.356 |
0.87 |
14.3 |
0.219 |
0.374 |
0.87 |
7.2 |
0.58 |
|
Диффузионные модели |
|||||||||||
|
SDXL |
0.867 |
2.6 |
0.226 |
0.360 |
0.77 |
14.4 |
0.217 |
0.384 |
0.78 |
7.6 |
0.55 |
|
SD3-medium [7] |
0.934 |
2.0 |
0.227 |
0.354 |
1.01 |
19.5 |
0.215 |
0.363 |
0.91 |
13.1 |
0.65 |
|
Lumina-Next [8] |
5.812 |
2.0 |
0.224 |
0.329 |
0.55 |
18.4 |
0.216 |
0.353 |
0.75 |
5.9 |
0.47 |
|
Авторегрессивные модели |
|||||||||||
|
LlamaGen |
3.821 |
0.8 |
0.208 |
0.274 |
-0.25 |
44.8 |
0.194 |
0.288 |
-0.45 |
26.9 |
0.32 |
|
HART [11] |
0.063 |
0.7 |
0.223 |
0.341 |
0.75 |
20.9 |
0.216 |
0.366 |
0.84 |
5.8 |
0.55 |
|
SWAT (ours) |
0.127 |
2.5 |
0.227 |
0.356 |
0.95 |
17.6 |
0.217 |
0.381 |
0.91 |
9.5 |
0.63 |
Количественное сравнение SWAT с другими доступными моделями. Лучшее значение каждой метрики выделено красным, второе — синим, третье — жёлтым.
4.3. Оценка эффективности
Далее, мы анализируем эффективность инференса нашего метода и сравниваем его с бейзлайнами. Мы рассматриваем два подхода к оценке: замер одного шага генератора (без учёта времени необходимого на кодирование текста и кодирование-декодирование автокодировщиком) и полное время инференса всего text-to-image алгоритма. Все модели оценивались в точности FP16/BF16 с размером батча равным 8. Так как SWAT генерирует изображения только в 512x512, мы оцениваем скорость генерации всех моделей в этом разрешении для честного сравнения.
Т а б л и ц а 2
Оценка эффективности
|
Model |
Generator size, В |
N steps |
1 step, ms/image s |
Full, /image |
|
Дистиллированные диффузионные модели |
||||
|
SDXL-Turbo |
2.6 |
4 |
12.4 |
0.251 |
|
DMD2 |
2.6 |
4 |
12.4 |
0.251 |
|
Диффузионные модели |
||||
|
SDXL |
2.6 |
25 |
12.4 |
0.867 |
|
SD3-medium |
2.0 |
28 |
16.8 |
0.934 |
|
Авторегрессивные модели |
||||
|
LlamaGen |
0.8 |
1024 |
— |
3.821 |
|
HART |
0.7 |
10 |
4.7* |
0.063 |
|
SWAT (ours) |
2.5 |
10 |
9.5* |
0.127 |
|
’Среднее время за 10 шагов. |
||||
Сравнение времени генерации изображений 512x512.
Как следует из табл. 2, наш метод гораздо более эффективный, чем другие генеративные модели того же размера, обгоняя популярный метод SDXL примерно в 7 раз. Стоит также отметить, что генерация изображения с помощью SWAT занимает всего на 0.06 с больше чем методом HART, хотя наша модель более чем в 3 раза больше, что позволяет генерировать более качественные изображения за примерно то же время.
4.4. Качественное сравнение
Мы приводим качественное сравнение с другими методами на рис. 3. SWAT не уступает бейзлайнам в визуальном качестве и соответствии сложным текстовым описаниям, будучи гораздо более эффективной моделью.
A small cactus with a happy face itt the Sahara desert.

SWAT HART DMD2 SDXL SD3
Рис. 3. Качественное сравнение с бейзлайпами
5. Заключение
В данной работе мы представляем SWAT — новую архитектуру трансформера для авторегрессивной поскейловой генерации изображений по текстовым описаниям. Мы адаптировали оригинальную архитектуру для обработки текстовых описаний в свободной форме, а также сделали несколько модификаций, улучшающих стабильность и эффективность обучения и инференса. Эти модификации позволили эффективно обучить SWAT на крупном тщательно отобранном датасете. В результате SWAT превосходит предшедствутощие авторегрессивные text-to-image модели и достигает более чем семикратного ускорения по сравнению с передовыми диффузионными text-to-image моделями, при этом не уступая им по визуальному качеству и соответствию текстовым описаниям.
