Способ инфологической обработки рабочих программ дисциплин профессионального цикла направления подготовки специалистов для оценки подобия тематического содержания лекционных курсов

Автор: Михайлов Сергей Николаевич, Чуйкова Виктория Владимировна
Журнал: Образовательные технологии и общество @journal-ifets
Статья в выпуске: 1 т.19, 2016 года.
Бесплатный доступ
Представлен разработанный способ инфологической обработки текста для выявления тематических дублирований информации в различных документах. Рассмотрены основные функции инфологической системы и приведен обобщенный алгоритм её работы для выполнения кластеризации научных тем. Описан состав и функции программных модулей разработанного макета инфологической системы. На основе результатов экспериментальных исследований показана принципиальная возможность реализации автоматизированной оценки содержания дисциплин путем инфологической обработки текстов рабочих программ. Приведены оценочные значения относительного повышения оперативности выполнения процедуры оценки смыслового содержания дисциплин в случае использования предложенного способа инфологической обработки текстовых документов.
Инфологическая система, оценка тематического подобия, информационный ресурс, рабочая программа дисциплины, антология, структурная декомпозиция текста, визуальный интерфейс представления знаний
Короткий адрес: https://sciup.org/14062666
IDR: 14062666
Текст научной статьи Способ инфологической обработки рабочих программ дисциплин профессионального цикла направления подготовки специалистов для оценки подобия тематического содержания лекционных курсов
Оценка смыслового содержания дисциплины является трудоёмким процессом, выполнение которого требуется для оптимизации использования учебного времени. Очевидно, что изучение одной темы в разных дисциплинах, в конечном счете, приводит к сокращению объема знаний, получаемых студентами конкретного направления подготовки, и может поставить под угрозу освоение основной образовательной программы в соответствии с требуемыми компетенциями. Оценку содержания дисциплин целесообразно проводить один раз в год с целью актуализации изучаемого материала и снижения числа тематических дублирований в разных курсах. Реализация подобной оценки на выпускающей кафедре требует привлечения наиболее подготовленных преподавателей и занимает достаточно продолжительное время.
Учитывая, что число дисциплин профессионального цикла обучения может достигать нескольких десятков, то затраты рабочего времени на эти цели могут исчисляться неделями. В этой связи автоматизация процесса оценки смыслового содержания дисциплин, направленная на оперативное выявление тематических дублирований в различных курсах и повышение эффективности использования учебного времени является актуальной и представляет несомненный практический интерес.
Методические основы инфологической обработки текстовых документов
Одним из путей реализации автоматизированной оценки смыслового содержания дисциплин является применение инфологического подхода, ориентированного на использование программных средств, реализующих процедуры автоматического выявления семантики текстовых документов.
В настоящее время инфологические системы находят применение в различных областях структурирования знаний. Отличительной особенностью инфологической системы является функция выявления и наглядного представления пользователю смыслового содержания документа.
Инфологическая обработка текстового документа в общем случае предполагает строго упорядоченную последовательность действий, направленных на выявление семантического содержания выбранных текстов.
Структурная схема основного алгоритма функционирования инфологической системы при обработке текстовых документов представлена на
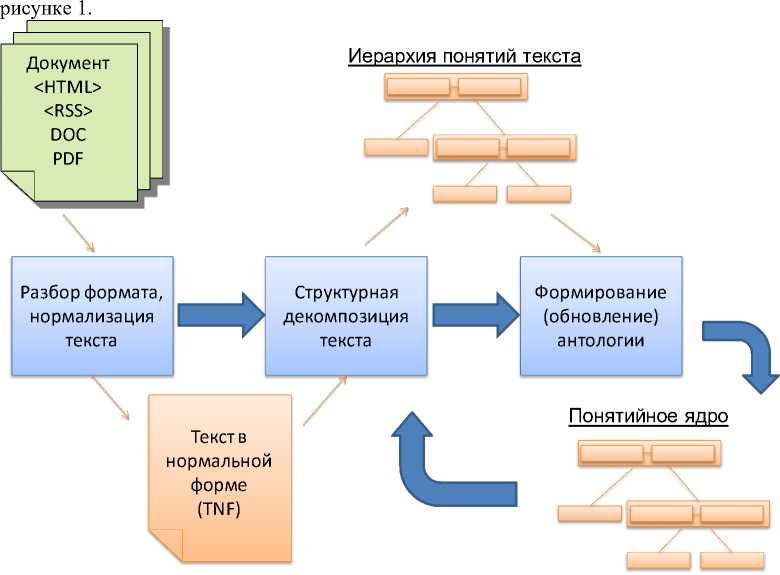
Рис. 1. Структурная схема основного алгоритма функционирования инфологической системы
Предлагаемый алгоритм тематической кластеризации и каталогизации текстов реализован в инфологической системе формирования предметных антологий. На рисунке показаны этапы формирования предметных антологий, где входной поток документов, заданных в виде текстов, проходя этапы нормализации текста и выявления иерархии понятий текста, формирует некоторую заданную антологию. Под формированием антологии понимается отнесение текста к тематике антологии (тематическая кластеризация), выявление и обновление понятийного ядра антологии, на основе вновь поступающих текстов и их понятийных иерархии. Цикличность процесса заключается в том, что сформированная (обновленная) таким образов антология и её понятийное ядро, используются на этапе структурной декомпозиции новых текстов, для выявления заданных терминов текста.
Для эффективной компьютерной обработки новых источников, общим для них является потребность приведения текстов, представленных различными форматами документов, в некоторый нормализованный формат текста (TNF) [1].
В ходе преобразования формата документа производится разбор формата документа, выделяется текст в простом формате (TXT) и содержащаяся в файле документа служебная информация (URI, Дата издания, Имя автора и т.д.). Эта служебная информация используется для регистрации документа в базе данных системы, тем самым текст документа, его внутреннее содержание, представленное в системе, ассоциируется с внешней атрибутикой формата хранения текста (служебной информацией). На рисунке 2 представлена схема преобразования формата документа.
Свердловская область готовится к презентации Уральского федерального университета
9 декабря в Москве состоится заседание межведомственной рабочей группы по реализации приоритетного национального проекта "Образование", на котором пройдет презентация федеральных университетов, в том числе - Уральского федерального университета...
Текст
PDF, …
Разбор формата файла, извлечение простого текста и служебной информации
Простой т екст овый Формат (TXT)
Служебная информация (URL, дата, автор, …)
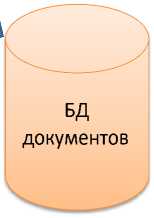
БД документов
Рис. 2. Преобразование формата документа
На первом этапе обработки выполняется нормализация текста, представляющая собой его преобразование к виду, в котором все слова приведены в базовую форму и исключены союзы, местоимения и другие служебные части речи, т. е. текст преобразуется в нормальную форму.
Под текстом в нормальной форме (TNF) понимается специализированный формат представления текст, который получается из текста в простом текстовом формате (TXT), путем приведения всех его слов в нормальную (базовую) форму, с последующим исключением из него малоинформативных слов (т.н. стоп-слова), используемых в качестве союзов, предлогов, местоимений и т.д.
Приведем пример преобразования текста в простом формате в нормализованную форму.
Исходный текст:
«Свердловская область готовится к презентации Уральского федерального университета. 9 декабря в Москве состоится заседание межведомственной рабочей группы по реализации приоритетного национального проекта «Образование», на котором пройдёт презентация федеральных университетов, в том числе – Уральского федерального университета»…
Исходный текст после нормализации:
« Свердловск область готовится презентация Уральский федеральный университет. 9 декабря Москва состояться заседание межведомственный рабочий группа реализация приоритетный национальный проект «Образование»проходить презентация федеральный университет Уральский федеральный университет»…
Алгоритм нормализации текстов состоит в следующем. В тексте выделяются синтаксические конструкции – предложения – последовательности слов естественного языка, разделенные символами. Слова в предложении приводятся в нормальную (базовую) форму с помощью внешнего модуля морфологического анализа, работающего на основе модели прикладного морфологического анализа без словаря. Алгоритмы морфологии построены на самообучении программы на открытых массивах реальных текстов и совмещают два подхода: лингвистический – формализованная грамматика для построения морфологических гипотез и математический – метод корреляции, позволяющий унифицировать морфологическую гипотезу.
После приведения слов в тексте в нормальную форму, из текста исключаются слова из множества стоп-слов. На этом работа алгоритма нормализации текста завершается.
Текст в нормальной форме (TNF) используется в системе на всех дальнейших этапах обработки текстов [1].
На втором этапе выполняется сегментация текста на синтаксические единицы и определяется рейтинг связок слов c последующим формированием иерархической структуры понятийного окружения текста, представляющей упорядоченную форму хранения в вычислительной среде смыслового отражения исходного документа. Под структурной декомпозицией текста понимается преобразование текста из нормальной формы (TNF) в формат компактного компьютерного представления семантики текста, построения понятийного графа текста, выявления тезауруса и глоссария текста.
Понятийным графом текста назовем неориентированный граф, в узлах которого находятся понятия текста, а дугами обозначаются связи между понятиями текста. Вес дуги, соединяющей две вершины графа, характеризует рейтинг соответствующей связи.
Понятийный граф текста формируется методом структурной декомпозиции.
Для отношений строятся рейтинговые распределения связей элементов, т.е. считается, что между каждой парой таких элементов, встречающихся в одном предложении, имеется связь с рейтингом равным единице. Для каждой связи запускается счетчик, учитывающий, сколько раз та или иная связка элементов предложения встречается в тексте. Если связки элементов встречаются повторно в других предложениях, то значение счетчика увеличиваются на единицу. Таким образом, обрабатываются все связи всех предложения текста, и подсчитывается их рейтинги.
После подсчета рейтингов связей элементов из результата исключаются связи с рейтингом меньше двух и отдельные слова, оставшиеся вообще без связей. В результате формируется список слов, двоек слов и троек слов, и производится ранжирование, т.е. упорядочение списков элементов по убыванию рейтинга соответствующих им связей (рис. 3а).
Слова
Слово1

Текст в нормальной форме (TNF)

Подсчет слов, составление тезауруса текста; сегментация на синтаксические единицы, подсчет рейтингов слов, связок 2-х и 3-х слов

Слово3
Связки 2-х слов
-
2.
-
3.
Слово1 Слово2
Слово1 Слово4
Слово3 Слово5
M. СловоN СловоM
Связки 3-х слов
-
1. Слово1 Слово2 Слово7
-
2. Слово1 Слово4 Слово5
-
3. Слово3 Слово5 Слово6
-
2.
-
3.
Слова
Слово1
Предметные словари
Слово2
Слово3
Связки 2-х слов
-
1. Слово1 Слово2
-
2. Слово1 Слово4
-
3. Слово3 Слово5
M. СловоN СловоM
Связки 3-х слов
-
1. Слово1 Слово2 Слово7
-
2. Слово1 Слово4 Слово5
-
3. Слово3 Слово5 Слово6
K. СловоN СловоM СловоK K. СловоN СловоM СловоK

География, субъекты, объекты, шаблоны
Выделение понятий, формирование иерархии понятий
Иерархия понятий
Слово3 Слово5
Слово7 Слово1 Слово 4
СловоN Слово2
а) б)
Рис. 3. Структурная декомпозиция текстов а) подсчет рангов слов и совокупностей слов, б) формирование иерархии понятий текста
Далее на основе списка слов, двоек слов и троек слов текста, полученных на предыдущем этапа, происходит формирование понятий, т.е. выделение из списка слов и связок слов текста понятий, соответствующих заданной предметной области с использованием тезауруса и словарей предметной области (рисунок 3б).
Заключающим этапом обработки выступает построение иерархии понятий текста, как неориентированного взвешенного графа понятий текста, узлы которого являются понятиями, а дуги – связями между понятиями. Вес дуги обозначает рейтинг соответствующей связи между понятиями. На рис. 4 приведены примеры полученных понятийных иерархий текстов.
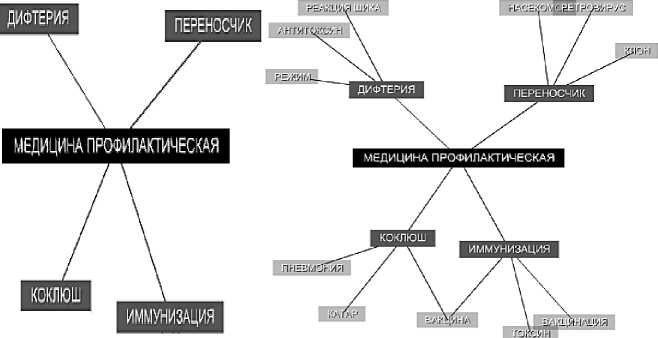
а)
б)
Рис. 4. Примеры результатов выполнения структурной декомпозиции текстов а) минимальный уровень детализации; б) увеличенный уровень детализации
Остановимся более детально на описании процедуры визуального представления семантики текста.
С целью упрощения хранения и компьютерной обработки смыслового отражения текстовых данных разработан формат компактного компьютерного представления семантики текста. Он основан на результатах работы метода структурной декомпозиции и включает в себя:
-
- словарь текста;
-
- словарь нормализованного текста;
-
- списки слов, двоек и троек слов и их связи;
-
- понятийную иерархию текста.
Кроме того, разработана XML схема, описывающая предлагаемый формат представления семантики текстов в формате XML документа [1].
Дальнейшая обработка текста предполагает формирование терминологических ядер предметных антологий.
Итеративный процесс выделения терминологических ядер предметных антологий заключается в начальном выборе интересующего набора антологических текстов (определение топика), а также в мониторинге и итеративном обновлении состава текстов топика, обновления его терминологического ядра.
Тематическим топиком назовем подмножество множества антологических текстов. Для начального формирования топиков, выбирается некоторое количество интересующих пользователя антологических текстов, которые и будут составлять топик. Для выбранных антологических текстов строятся их понятийные иерархии, на основе которых, путем объединения, формируется понятийное ядро топика.
Понятийное ядро топика является обобщением иерархий понятий входящих втопик антологических текстов, и представляет собой неориентированный взвешенный граф понятий, узлы которого являются понятиями, а дуги – связями между понятиями. Вес дуги обозначает рейтинг соответствующей связи между понятиями.
Алгоритм слияния иерархий понятий в понятийное ядро заключается в следующем. Для каждой пары понятий в иерархии понятий текста ищется соответствующая ей пара в понятийном ядре топика, если соответствие найдено, то вес дуги в графе понятий ядра топика увеличивается на соответствующий вес дуги в графе понятий текста. Если такой пары связанных понятий не найдено, они добавляются в ядро топика. Алгоритм продолжается для всех остальных дуг графа понятий текста.
После того как тематический топик сформирован, он участвует в процессе итеративного обновления при обработке новых документов, добавленных на очередном этапе итерационного процесса. Обновление состава тематического топика и обновление его понятийного ядра осуществляется путем слияния идентичных компонент ядра топика и компонент понятийной иерархии добавленного текста.
В результате очередного обновления топика может сложиться ситуация, что тематическое ядро будет иметь несколько сильно связанных компонент в графе понятий. Это свидетельствует о необходимости разделения топика на два независимых топика с ядрами, соответствующими компонентам связанности исходного графа. Наглядно подобная ситуация представлена на рисунке 5.
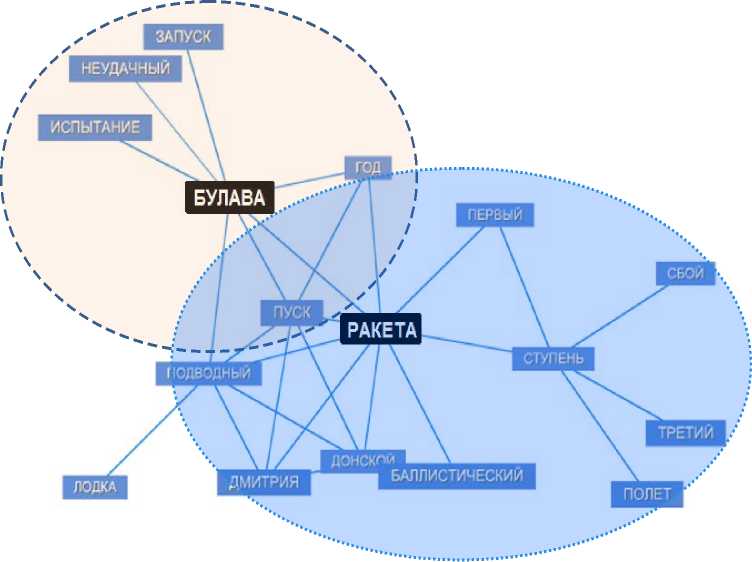
Рис. 5. Примеры понятийного ядра топика с выявленными компонентами сильной связанности графа понятий
Наличие в инфологической системе функций нормализации, структурной декомпозиции и выявления понятийной иерархии текстов обеспечивает возможность её применения для выполнения тематической кластеризациидокументов.
Оценка тематической близости текстов основана на метрике тематической близости текстов. В качестве такой метрики используется метод, основанный на сравнении графов понятий текстов с минимальным уровнем детализации, как обеспечивающий удовлетворительную точность тематической кластеризации.
Далее производится визуализация сформированных понятийных ядер.
Интерфейс визуализации понятийных ядер предметных топиков позволяет получать представление терминологического содержания тематического топика в виде визуального графа («паутины», семантического облака). Дополнение системы интерактивным визуальным интерфейсом, позволяет создать интерактивную среду для быстрого ознакомления с тематикой топика.
Визуальное представление, формируемое системой, являются аналогом иероглифической записи, которая позволяет воспринимать содержимое текстов не последовательно, а одномоментно. Это позволяет воспринимать структуру связей между зависимыми понятиями в комплексе.
С помощью визуального интерфейса представления знаний заданной предметной области возможно реализовать процесс обучения. Пользователь, обладая инструментом визуализации тематического содержания предметного топика, в самом грубом приближении воспринимает смысловое отражение тематики в целом через совокупность основных терминов и их связей. На самом верхнем уровне понятийной иерархии (рис. 4, 5) будут находиться наиболее значимые для данного топика термины и понятия, связанные ассоциативными связями. Детализация выбранного пользователем термина дается в виде понятийного окружения, визуального графа понятий ассоциативно связанных с выбранным термином.
Таким образом, переходя от одного термина к другому и меняя уровень детализации (рис. 4), формируется итерационный процесс терминологического изучения проблемно-ориентированной предметной области (топика) [1].
Кластеризация научных тем является еще одним перспективным направлением применения инфологической системы при обработке новой текстовой информации.
Кластеризация научных тем при использовании технологии инфологической обработки текстов может быть реализована путем структуризации потока новых и ретроспективных научных публикаций по тематическим областям (научным направлениям). Общий подход к решению этой задачи представлен на рисунке 6.
Теория информации, научные основы информационновычислительных систем и сетей, системный анализ
Искусственный интеллект, системы распознавания образов, принятие решений при многих критериях
Основополагающие труды (антология)



Научное

Нейроинформатика и биоинформатика
Архитектура, системные решения и программное обеспечение информационно-вычислительных комплексов новых поколений
Рис. 6. Кластеризация научных тем
Установлено, что существует фиксированный набор научных направлений, каждое из которых представлено основополагающими трудами (антологиями). Например, для кадастров научных исследований встают задачи связанные с классификацией поступающего потока работ (статей) по научным тематикам.
Обобщенный алгоритм функционирования инфологической системы при кластеризации научных тем представляет собой упорядоченную последовательность выполняемых операций по обработке поступающих документов с целью их упорядоченного отбора и адресной сортировки по научным направлениям, а также реферированного и визуального представления содержания пользователям. Последовательность основных операций может быть представлена в следующем виде.
-
1. На вход системы поступают научные статьи, отсчеты, материалы конференций и т.д. в различных текстовых форматах (doc, pdf, html и др.)
-
2. В блоке обработки формата документов система преобразует входные документы в простой текстовый формат (TXT).
-
3. Полученный текст поступает в блок нормализации и преобразуется в формат TNF.
-
4. Нормализованный текст попадает в блок структурной декомпозиции, где формируется тезаурус и понятийная иерархия текста.
-
5. Кластеризация текста осуществляется в блоке классификации и кластеризации по существующим тематическим топикам.
Топики научных направлений (кластеры научных тем) характеризуются следующими атрибутами:
-
- множество документов входящих в данный кластер (антология);
-
- понятийное ядро топика;
-
- краткое содержание топика – краткий реферат одного из документов, входящего в кластер, наиболее точно отражающего тематику топика.
-
6. Семантический поиск документов по текстам реализуется по запросам пользователей, как выборка множества документов по поисковой фразе, удовлетворяющих условию наличия семантических связей в тексте документа между всеми словами поисковой фразы. Поиск документов, отвечающих поисковой фразе, производится путем выбора научных документов и/или топиков, удовлетворяющих условию наличия всех связей между словами, имевшимися в поисковой фразе.
-
7. Визуализация содержания документов реализуется через интерактивный пользовательский интерфейс системы аналитического мониторинга научных тем.
Основными функциями интерфейса визуализации являются:
-
- отображение топиков научных направлений;
-
- представление сформированных понятийных ядер топиков в виде визуальной среды – визуального глоссария;
-
- визуализация тематических топиков: отображение заголовка топика, понятийного ядра и списка входящих в него документов;
-
- ассоциативный поиск по новым публикациям.
Для реализации программного комплекса, ориентированного на выполнение функций инфологической системы выбрана сервисно-ориентированная архитектура, построенная на основе Web-сервисов [2].
Большая часть модулей реализована в среде программирования Java. Отдельные критические по производительности модули выполнены на языке C++.
В состав экспериментального образца программного комплекса входят следующие сервисы и компоненты, представленные в таблице 1.
Таблица 1
Состав программного комплекса
|
Модуль |
Описание |
Язык Программировани я / ОС |
|
Text converter |
Модуль преобразования формата документа – преобразует различные форматы входных документов в простой |
Java / Lin / Win |
|
текстовый форма (TXT) |
||
|
Morphology |
Модуль морфологического анализа – преобразует текст их простом текстового формата к нормализованной форме (TNF) |
C++ / Lin / Win |
|
Document indexer |
Сервис индексации документов – добавление документов поисковую базу. |
Java / Lin / Win |
|
Words dictionary |
Словарь системы – хранение и быстрый поиск базы данных слов. |
С++ / Linux |
|
Document Searcher |
Сервис ассоциативного поиска документов. |
Java / Lin / Win |
|
Document Classifier |
Модуль тематической кластеризации документов. |
Java / Lin / Win |
|
Web portal |
Сервис, предоставляющий пользовательский интерфейс системы – осуществляет возможность поиска документов, визуализацию тематических кластеров и визуальное представление терминологического содержания документов. |
Java / Lin / Win |
|
Crawlers |
Сервис робота-сборщика документов – реализует автоматический поиск и добавление в систему новых документов, обновление уже существующих. |
Java / Lin / Win |
Основные части программных компонентов комплекса являются кросс-платформенными и могут быть развернуты как на серверах под управлением Linux-подобной операционной системы, так и на Windows-серверах. С учетом разработанной обобщенной архитектуры инфокоммуникационной среды информационно – аналитического обеспечения научных исследований технического ВУЗа, а также структурно – функциональной организации системы информационно – аналитического обеспечения научных исследований, управление программным комплексом может осуществляется с использованием следующих АРМ:
-
- диспетчера подсистемы;
-
- управления технологическими операциями подсистемы;
-
- управления базами данных и адресным доведением информации потребителям [1].
Результаты практического применения инфологической обработки текстов при оценке подобия тематического содержания лекционных курсов в различных дисциплинах
Описанная процедура инфологической обработки текстов может быть положена в основу создания нового способа оценки подобия тематического содержания лекционных курсов путем сравнения понятийных иерархий рабочих программ дисциплин выбранного направления подготовки студентов.
В условиях перехода высших учебных заведений на выполнение требований и стандартов третьего поколения указанный способ может быть использован для автоматизации процесса выявления степени отражения компетенций в конкретных дисциплинах направления подготовки. Данная работа описана в [3].
В ходе разработки способа инфологической обработки для оценки тематического подобия содержания лекционных курсов был сформирован методологический подход, содержащий 7 этапов:
Этап 1 - Выбор информативных документов, наиболее интенсивно используемых в деятельности кафедры и хранящихся в информационных ресурсах.
Этап 2 - Нумерация документов и содержащихся в них тем.
Этап 3 - Создание архива документов и приведение их к единому формату.
Этап 4 - Инфологическая обработка документов архива на основе формирования упорядоченной совокупности тематических запросов.
Этап 5 - Последовательный анализ признаков обнаружения подобия тематического содержания запроса в имеющихся архивных данных.
Этап 6 - Принятие решения о тематическом сходстве содержания в различных обработанных документах.
Этап 7 - Идентификация тематик, содержащих семантическое подобие в различных документах [4].
Данная методология легла в основу создания технологии, в которой авторами была определена последовательность операций, необходимых для автоматизированной оценки подобия тематического содержания рабочих программ дисциплин по направлению подготовки 090302.65 «Информационная безопасность телекоммуникационных систем».
Апробация разработанной технологии проводилась в ходе выполнения эксперимента, задачей которого была оценка возможности применения инфологической системы для реализации автоматизированного процесса выявления тематического подобия содержания документов, хранящихся в информационных ресурсах. В качестве информационного ресурса выбрана электронная библиотека сервера кафедры.
В качестве документов отобраны двенадцать рабочих программ дисциплин (РПД) профессионального цикла подготовки специалистов кафедры. При этом каждому из N документов был присвоен идентификационный номер (от 1 до 12) для последующего удобства администрирования данных ресурсов (N i , i=1,2…12).
В каждом N i документе проведена структурная декомпозиция содержащегося в них тематического материала. В результате, каждой теме, конкретной дисциплины, присвоен оригинальный идентификационный номер Ti,j, где i – номер дисциплины, j– номер темы, которая изучается в i-й дисциплине. Таким образом, был создан нумерованный список тем лекционных материалов по каждой дисциплине. Первая дисциплина содержала 20 тем (номера T1.1 – T1.20), вторая – 17 тем (T2.1 – T2.17), третья –10 тем (T3.1 – T3.10), четвёртая – 5 тем (T5.1 – T5.5), пятая – 12 тем (T5.1 – T5.12), шестая – 8 тем (T8.1 – T8.8), седьмая – 4 темы (T7.1 – T7.4), восьмая – 13 тем (T8.1 – T8.13), девятая – 17 тем (T9.1 – T9.17), десятая – 12 тем (T10.1 – T10.12), одиннадцатая – 5 тем (T11.1 – T11.5), двенадцатая – 10 тем (T12.1 – T12.10).
Все 12 полученных документов были сохранены в едином формате с расширением «doc», так как это принципиально при использовании имеющегося экспериментального образца инфологической системы. На рисунке 7 представлен сформированный список.
|
^ 1 Антенны и распространение радиоволн.doc |
315 КБ |
Документ. |
. 27.09.2013 11:50 |
|
^2 Цифровая обработка сигналов.doc |
150 КБ |
Документ. |
. 24.12.2014 15:45 |
|
®^3 Теория электрической связи.doc |
373 КБ |
Документ. |
. 24.12.2014 15:45 |
|
У 4 Геоинформационные системы в TK.doc |
211 КБ |
Документ. |
. 24,12.2014 15:43 |
|
У 5 Квантовая и оптическая электроника.doc |
224 КБ |
Документ. |
. 21.12.201423:07 |
|
®]б Наддисциплинарный учебный курс, doc |
267 КБ |
Документ. |
. 11.12.2014 12:40 |
|
Основы геоинформатики.doc |
236 КБ |
Документ. |
. 24.12.2014 15:43 |
|
®]б Сети и системы передачи информации.doc |
142 КБ |
Документ. |
. 24,12.2014 15:44 |
|
1^9 Системы коммутации.doc |
302 КБ |
Документ. |
. 24.12.2014 15:44 |
|
®] 10 Теория радиотехнических сигналов.doc |
121 КБ |
Документ. |
. 24.12.2014 15:44 |
|
11 Моделирование систем и сетей телекоммуникаций.doc |
109 КБ |
Документ. |
. 05.12.2013 11:21 |
|
12 Электромагнитные поля и волны.doc |
255 КБ |
Документ. |
. 27,09.2013 11:33 |
|
^запросы .doc |
47 КБ |
Документ. |
. 24.12.2014 16:02 |
Рис. 7. Нумерованный список документов, участвующих в эксперименте
На очередном этапе эксперимента сформирован архив документов, который будет использоваться непосредственно инфологической системой для смысловой обработки.
Загрузив архив из 12 документов в программный комплекс инфологической системы пользователь получает возможность отображения понятийного окружения каждого документа визуального графа понятийной иерархии. На рисунке 8 представлен граф понятийной иерархии дисциплины «Теория электрической связи» с минимальным уровнем детализации.
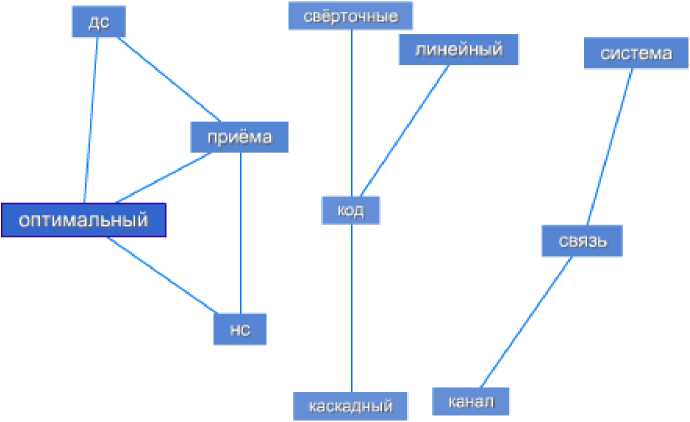
Рис.8. Граф понятийной иерархии дисциплины «Теория электрической связи»
Как видно из графа, инфологической системой выделены в дисциплине 3 основные смысловые ядра. Граф дисциплины позволяет, не читая документ, понять его основной смысл. Так же возможно укрупнение графа, что даёт более детальное тематико-смысловое описание документа. Укрупнённый граф понятийной иерархии рабочей программы дисциплины «Теория электрической связи» приведён на рисунке 9.
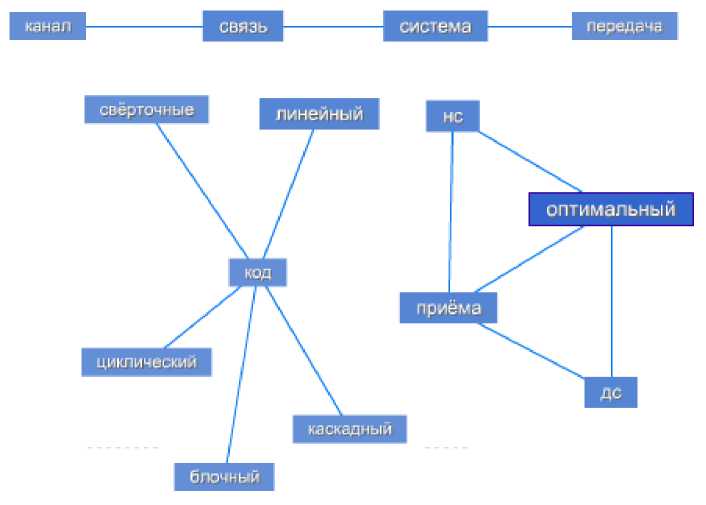
Рис. 9. Укрупнённый граф понятийной иерархии рабочей программы дисциплины «Теория электрической связи»
На следующем этапе эксперимента реализована инфологическая обработка документов архива на основе упорядоченной совокупности тематических запросов. В данном случае в качестве запроса принимается одна тематическая единица документа, т.е. одна нумерованная тема лекционных материалов каждой дисциплины. Для создания запросов использованы 12 архивных документов, представляющих собой рабочие программы дисциплин, представленные на рисунке 7. Ниже приведен их нумерованный список.
-
1. Антенны и распространение радиоволн.
-
2. Цифровая обработка сигналов.
-
3. Теория электрической связи.
-
4. Геоинформационные системы в ТК.
-
5. Квантовая и оптическая электроника.
-
6. Наддисциплинарный учебный курс.
-
7. Основы геоинформатики.
-
8. Сети и системы передачи информации.
-
9. Системы коммутации.
-
10. Теория радиотехнических сигналов.
-
11. Моделирование систем и сетей телекоммуникаций.
-
12. Электромагнитные поля и волны.
Такой подход обеспечил формирование 133 запросов.
Сформированные запросы последовательно вводились в окно поиска инфологической системы, после чего производилась смысловая обработка всех документов архива на предмет оценки тематического подобия запроса в содержании каждого из документов. Документы, в которых обнаружено семантическое сходство с тематикой запроса, представлялись в виде перечня в окне поиска, как это показано на рисунке 10.
Поес i no floeywwrew
■УКВантонныдляссйоисп<шойх)М*<обй!ктаЙ1ГяйпшъНшх!нснкоАлтонна11^^
. \1 Антенны и распространение радиооопн оос
С Ww*g^Mn*W*Mao^t Aeie*e • расфосrpewee радюпоа» Ах
Hwwiz«)7«j»i3 vtsw 3220*4 t^ С.-.woserverniwtdoc»
Аян;т>л
I
EviiVfMuri
I
'^8 -ст и i
-
• 2 цифровая обработо сигналов ooc
И »•«■«• Ю5 N 12 JOU. Мнм 1S3606 6e«' I C'nwtnetver’ihetefXxs'
Awstim'* ! CailAGtilMB! I ГиД I'-Q'tiTw iMR i
-
• tQTeixweoiiwrtoiHWOMcwMiKida
c wwewcf «пемгооосул в teot*» мивтоммеш о«мме бос vtwene-14.44 24.12Л14 01ъе* !22W Uir | C: «two4ervtr«fwe docs twmrI eNiYVRWwrti feiewroiA^j
. 2ШдШЖШШЯ(М4Хй<аШЖ
■ i? t г>»-- v-^: . •• -i;-»» -• -»<»y?caoc
Им#»*1*4011ЛиИ4 lXHMZD40ie»^ C.-viwo'i«rrer4hMfdoci ^'«« l jQxiCEMMBi йДЗЕЩ^ЗЬ;
-
• 12 злегтромзгахтныепопяиеолныок
C YrwotMrvWWWAtoeslt? Vwerprwweene# neat ■ acnw dee
Huw IMS IT OS WSI 04mu N11X W’ | C wwceefwef 'sheedcxs^
Acgn^gi СыудеццЕ»! гма жиг-я» iMu, ।
Рис. 10. Результат тематического запроса к документам архива на предмет семантического подобия по теме 1.9
Выполняя последовательный поиск по каждому запросу, пользователь получает возможность определить полный перечень дисциплин, в которых имеется смысловое подобие выбранной темы по всему направлению подготовки. При этом полученные результаты могут быть представлены в графической форме, удобной для обобщения и дальнейшего анализа.
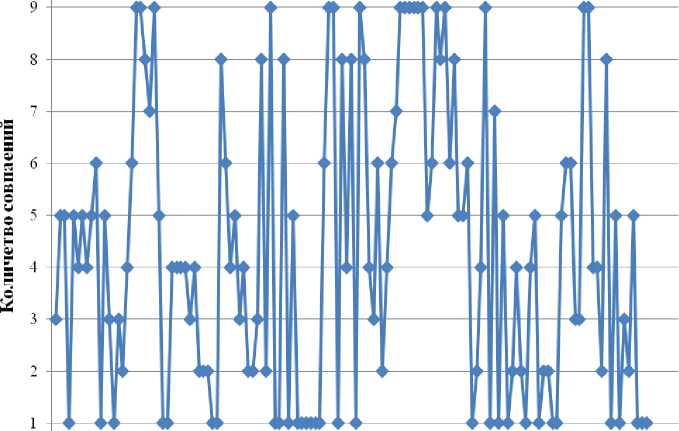
На рисунках 11 и 12 графически представлены обобщенные результаты эксперимента, отражающие количественные и качественные характеристики обнаруженных дублирований.
Анализ представленных результатов показывает, что отдельные темы имеют смысловое подобие в 5 и более дисциплинах. Этот факт подтверждает, что отдельные темы одной дисциплины в ходе учебного процесса могут иметь многократное дублирование в нескольких других дисциплинах.
0 20 40 60 80 100 120 140
Номер темы
Рис. 11. Количество обнаруженных смысловых подобий тем в выбранных дисциплинах
Выявленные по тематическому подобию дисциплины могут быть представлены руководству кафедры для последующего анализа их тематического содержания и уточнения изучаемых вопросов с целью исключения возможности дублирований дидактических единиц.
При этом указанная информация может быть использована для поддержки принятия организационных и управленческих решений, направленных на оптимизацию использования учебного времени.
На рисунке 12 представлены возможные дублирования отдельных тем первой дисциплины в содержании других дисциплин профессионального цикла обучения направления подготовки. Как видно из рисунка некоторые темы неоднократно дублируются. Понимая, что выстроить учебный процесс без повторения изученного материалов в смежных дисциплинах практически невозможно, следует акцентировать внимание профессорско-преподавательского состава кафедры на обоснованном уточнении необходимости повторения отдельных тем в разных дисциплинах.
При этом становится очевидным, что наличие пяти и более кратного повторения содержания темы в разных дисциплинах может потребовать директивных указаний руководства кафедры на устранение подобных ситуаций. В результате может быть принято коллегиальное решение об исключении освещения отдельных вопросов в рамках изложения конкретных дисциплин.
Таким образом, предложенный и реально апробированный способ инфологической обработки рабочих программ дисциплин позволяет автоматизировать процесс оценки содержания учебных дисциплин на выпускающей кафедре и реально оценить степень повторений отдельных тем в содержании всех курсов конкретного направления подготовки. Информация, полученная в результате реализации указанного способа, позволяет своевременно исключать тематические дублирования в различных дисциплинах на этапе согласования рабочих программ дисциплин и, тем самым, оптимизировать процесс использования учебного времени в ходе подготовки студентов.
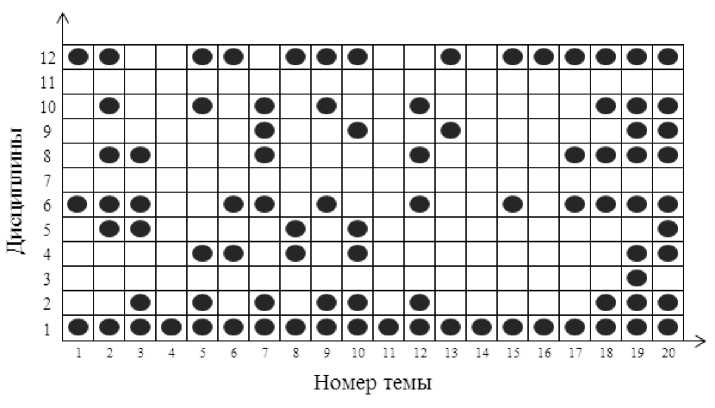
Рис. 12. Отображение возможных дублирований отдельных тем в содержании первой дисциплины
Экспериментальная оценка временных затрат, необходимых для проведения оценки содержания 12 учебных дисциплин и анализа возможных тематических дублирований ручным способом и автоматизировано с применением инфологической обработки показывает, что во втором случае оперативность достижения результата может быть повышена до пяти раз. При этом на первом этапе ввода электронных документов в инфологическую систему и получения оценки тематического подобия достаточно привлечение технического персонала кафедры, что существенно упрощает организацию применения предложенного способа.
Заключение
Экспериментальные исследования по оценке тематического подобия РПД показали принципиальную возможность применения разработанного способа в системе поддержки принятия управленческих решений выпускающей кафедры, направленных на оптимизацию использования учебного времени.
Кроме того, полученные результаты подтверждают, что инфологические системы могут быть положены в основу формирования перспективной подсистемы аналитического обеспечения научных исследований в общей структуре инфокоммуникационной среды технического ВУЗа.
Проведенная оценка показателей временного и стоимостного эффекта при использовании перспективных технологий информационно-аналитического обеспечения позволила установить, что экономический эффект может составить до 50% начальной стоимости информационного обеспечения. При этом возможное повышение оперативности может достигать 80% [1].
Список литературы Способ инфологической обработки рабочих программ дисциплин профессионального цикла направления подготовки специалистов для оценки подобия тематического содержания лекционных курсов
- Архитектура инфокоммуникационной среды информационно-аналитического обеспечения научных исследований технического вуза» аналитической ведомственной целевой программы “Развитие научного потенциала высшей школы (2009 -2010 годы). -Отчет по проекту № 6147, регистрационный № 01200963418, книга 1. -Курск. -2010. -185 с.
- Белоногов Г.Г., и др. Компьютерная лингвистика и перспективные информационные технологии. Теория и практика построения систем автоматической обработки текстовой информации. -М.: Русский мир, 2004. -264 с.
- Михайлов С. Н., Чуйкова В.В. Способ оценки содержания дисциплин отдельного направления подготовки требуемым//Известия Юго-Западного государственного университета. Серия Управление, вычислительная техника, информатика. Медицинское приборостроение. -2014. -№3. -с. 19-24.
- Васильев В.Г., Кривенко М.П. Методы автоматизированной обработки текстов. -М.: ИПИ РАН. 2008. -301 с.
