Сравнительный анализ нейронных сетей для подавления шума в аудиосигналах

Автор: Макаров И.С., Разуваев А.В., Цыдилин Д.И., Заботнова Д.А.
Журнал: Инфокоммуникационные технологии @ikt-psuti
Рубрика: Школа молодого ученого
Статья в выпуске: 2 (90) т.23, 2025 года.
Бесплатный доступ
В статье подробно исследуется применение нейронных сетей для решения задачи шумоподавления в аудиосигналах, что является одной из центральных проблем современных технологий обработки звука. Анализируются методы и алгоритмы, направленные на улучшение качества звука за счет устранения фонового шума, который существенно снижает разборчивость аудиосигналов и негативно влияет на их восприятие. В сравнении с традиционными подходами, такими как фильтрация или адаптивные алгоритмы, нейронные сети демонстрируют более высокую эффективность благодаря своим мощным инструментам обработки данных. Особое внимание уделено различным архитектурам нейронных сетей, включая сверточные сети, рекуррентные сети и их комбинации. Эти модели учитывают как временные, так и спектральные характеристики аудиосигналов, что позволяет добиться более точного подавления шума. Для оценки результатов экспериментов использовались объективные метрики, например, отношение сигнал/шум, а также субъективные показатели, такие как качество восприятия звука слушателями. Эксперименты показали, что предложенные подходы значительно превосходят традиционные методы, обеспечивая значительное повышение качества звуковых сигналов. Исследование доказывает перспективность использования нейронных сетей для шумоподавления, открывая новые возможности их применения в коммуникационных системах, мультимедиа, аудиотехнологиях и других областях, где требуется высокое качество обработки звука.
Шумоподавление, нейронные сети, аудиосигналы, качество звука, фоновый шум
Короткий адрес: https://sciup.org/140313575
IDR: 140313575 | УДК: 004.93:534.8 | DOI: 10.18469/ikt.2025.23.2.14
Comparative Analysis of Neural Networks for Noise Suppression in Audio Signals
The article explores in detail the use of neural networks in order of solve the problem of noise reduction in audio signals, representing the one of the critical problems of modern audio processing technologies. The methods and algorithms aimed at improving sound quality by eliminating background noise, which significantly reduce the intelligibility of audio signals and negatively affect their perception, are analyzed. Compared to traditional approaches such as filtering or adaptive algorithms, neural networks demonstrate higher efficiency due to their powerful data processing tools. Special attention is paid to various neural network architectures, including convolutional networks, recurrent networks and their combinations. These models consider both temporal and spectral characteristics of audio signals, which allows to reach more accurate noise reduction. Objective metrics, such as the signal-to-noise ratio, as well as subjective indicators, such as the quality of sound perception by listeners, were used to evaluate the experimental results. Experiments have prooved that the approaches proposed are significantly superior to traditional methods, providing a visible improvement in the quality of audio signals. The study demonstrates perspective of using neural networks for noise reduction, opening up new possibilities for application in communication systems, multimedia, audio technologies and other areas requiring high-quality sound processing.
Текст научной статьи Сравнительный анализ нейронных сетей для подавления шума в аудиосигналах
Результаты научных работ отечественных и зарубежных специалистов и ученых (Дж. Хинтон [1], Ю. ЛеКун, Я. Бенджио [2], А. Григорьев [3] и другие [4–6; 7–9]), подтверждают актуальность задачи устранения шума в аудиосигналах. Современные устройства, такие как смартфоны, голосовые помощники и системы для распознавания речи, нуждаются в высоком качестве звука для эффективной работы. Наличие фонового шума значительно ухудшает качество звука, что, в свою очередь, отрицательно влияет на точность распознавания речи и восприятие ее пользователями. Таким образом, создание действенных методов шумоподавления представляет собой важную задачу для исследователей и инженеров.
Шум значительно влияет на качество передачи данных, вызывая снижение соотношения сигнал-шум (SNR, Signal-to-Noise Ratio), что приводит к искажениям, потере данных и увеличению числа ошибок. В современном мире проблема шума обостряется вследствие роста количества беспроводных сетей, устройств IoT (Internet of Things – Интернет вещей) и повсе- местного использования электроники, создающей электромагнитные помехи. Например, уровень электромагнитного шума в городской среде увеличивается на 0,5–1,0 дБА ежегодно, что связано с ростом числа радиоустройств и загрузкой радиочастотного спектра [10–12].
Эти тенденции подтверждают необходимость поиска эффективных методов подавления шума для обеспечения надежной передачи данных в условиях быстрорастущей технологической нагрузки.
Постановка задачи исследования
Наблюдается активное развитие и применение нейронных сетей в самых разных сферах, в том числе в задачах обработки звуковых сигналов. Такие модели, как сверточные нейронные сети (CNN, Convolutional Neural Network) и рекуррентные нейронные сети (RNN, Recurrent Neural Network), показывают высокую эффективность в устранении шума, благодаря своей способности обучаться на больших объемах данных и выявлять сложные закономерности.
Помимо искусственного интеллекта (ИИ), для подавления шума применяются традиционные методы, такие как фильтрация (низкочастотные или

адаптивные фильтры), спектральный анализ и алгоритмы подавления помех на основе теории сигналов. Однако их эффективность ограничена из-за недостаточной гибкости в обработке сложных или динамически изменяющихся сигналов, в подтверждение чего можно привести следующие статьи [13].
Искусственный интеллект, напротив, позволяет адаптироваться к разнообразным источникам шума, обучаясь непосредственно на реальных данных, что делает его универсальным инструментом. Модели ИИ превосходят традиционные методы, благодаря возможности выявлять скрытые закономерности в данных и использовать их для точного восстановления сигнала, даже в сложных условиях.
Качество обработки аудиосигналов определяется не только эффективностью самого алгоритма шумоподавления, но и методами предварительной обработки данных, а также критериями оценки результатов. Основная цель исследования заключается в сравнительном анализе применения различных алгоритмов шумоподавления для улучшения качества аудиосигналов. В данной работе особое внимание уделяется объективной оценке эффективности шумоподавления, что позволяет провести точный сравнительный анализ различных нейронных моделей.
Нейронные алгоритмы фильтрации шума
Шумоподавление в аудиосигналах является важной задачей в различных приложениях, включая телекоммуникации, системы распознавания речи и обработку музыкальных записей. Использование нейронных сетей для решения этой проблемы открывает новые технические возможности в области повышения качества звука. Обзор научной литературы по вопросу применения методов, основанных на нейронных сетях, с целью выявления их преимуществ, недостатков и областей применения, позволил выявить наиболее популярные и практичные методы:
-
1. Методы на основе CNN. В работе [14] представлен метод, использующий сверточные нейронные сети для анализа спектральных характеристик аудиосигналов. Авторы продемонстрировали, что CNN позволяет выделять локальные особенности, что делает метод особенно эффективным в условиях умеренного шума.
-
2. Методы на основе RNN. Авторы [15] исследовали использование рекуррентных нейронных сетей для подавления шума в реальном времени (LSTM, Long Short-Term Memory). Метод учитывает временные зависимости и показыва-
- ет высокую производительность на мобильных устройствах.
-
3. Гибридные методы (CNN + RNN). В исследовании [1; 16] предложена гибридная архитектура, объединяющая CNN для обработки спектрограмм и RNN для учета временных зависимостей. Такой подход оказался эффективным при работе с динамическими шумами.
-
4. Автоэнкодеры для шумоподавления. Работа [17] посвящена использованию автоэнкодеров для устранения белого шума. Авторы применили метод добавления шумов в обучающие данные, что улучшило результаты восстановления.
-
5. Генеративно-состязательные сети (GAN, Generative Adversarial Network). В статье [18] представлен подход, основанный на GAN, который позволяет эффективно подавлять сложные шумы, обеспечивая естественное звучание.
-
6. Многозадачные сети. Эти сети, представленные в [19], одновременно решают задачи улучшения качества звука и шумоподавления, что наиболее актуально в решении задачи повышения разборчивости речи.
Анализ этих методов, на основе результатов их применения, описанных в указанной литературе, позволили выявить их сильные и слабые стороны. CNN оказались эффективны для обработки локальных особенностей, но плохо учитывают временные зависимости. RNN хорошо справляются с временными зависимостями, но требуют больше вычислительных ресурсов. Гибридные модели объединяют преимущества CNN и RNN, но сложны в реализации.
Для достижения поставленных целей в работе был выбран гибридный подход (CNN + RNN), который позволяет учитывать как спектральные, так и временные аспекты аудиосигнала. Этот метод наиболее подходит для решения задач подавления динамических шумов.
Модели исследования
Исследование проводилось на двух типах шумов: динамическом шуме и белом (гауссовом) шуме.
В случае белого шума временная область имеет хаотические значения с равномерным распределением, а частотная область – равномерное распределение по частотам.
В свою очередь, в динамическом шуме временная область представлена сигналом с изменением формы, характеризующим динамическую природу шума, а частотная область – спектром с ярко выраженным основным компонентом и дополнительными шумовыми пиками.
Для научных исследований важно учитывать как динамический шум, так и белый шум, так как они представляют разные аспекты реальных условий работы систем. Динамический шум моделирует изменения в реальном времени, например, помехи от движущихся объектов или нестабильные сигналы в городской среде, что позволяет тестировать системы на адаптивность и устойчивость. Белый шум, характеризующийся равномерным распределением частотной плотности, используется для проверки работы алгоритмов в условиях стационарных, предсказуемых помех, помогая выявить базовый уровень производительности. Совместное использование этих типов шума обеспечивает более полное и точное моделирование реальной среды, что повышает практическую ценность и надежность результатов.
Были рассмотрены следующие модели шумоподавления, каждая из которых была протестирована на двух типах шумов:
-
1. Demucs (Deep Extractor for Music Source Separation) – модель, основанная на архитектуре U-Net, которая изначально была разработана для решения задач сегментации изображений. В контексте шумоподавления Demucs использует CNN с энкодером-декодером и пропускными соединениями для обработки аудиосигналов.
-
2. NsNet2_Denoiser – модель, специально разработанная для решения задач шумоподавления в речевых сигналах. Она использует RNN для обработки последовательных данных.
-
3. Open-Unmix – модель, разработанная для решения задач разделения источников звука в музыкальных треках. Она также может быть использована для шумоподавления в речевых сигналах.
-
4. Spleeter – это модель, разработанная компанией Deezer для задач разделения источников звука в музыкальных треках. Может быть использована для шумоподавления в речевых сигналах.
U-Net архитектура позволяет модели захватывать как локальные, так и глобальные зависимости в аудиосигнале. Сверточные слои извлекают признаки из входного сигнала, а де-конволюционные слои восстанавливают очищенный сигнал. Это U-образная архитектура, которая преобразует сигнал в спектр через оконное преобразование, например, преобразование Фурье (STFT, Short-Time Fourier Transform) [20], и восстанавливает из него чистый сигнал.
Demucs работает в частотной области, используя короткое преобразование Фурье для преобразования аудиосигнала. Это позволяет модели эффективно удалять шум, сохраняя при этом важные частотные компоненты речи.
Модель применяет слои LSTM, которые позволяют учитывать временные зависимости в аудиосигнале. Это особенно важно для обработки речевых сигналов, где контекст играет важную роль.
NsNet2_Denoiser работает во временной области, что позволяет ей эффективно удалять шум, который имеет временные зависимости. Однако, как показали результаты, эта модель менее эф- фективна по сравнению с другими моделями в условиях белого шума/гауссова шума.
Использует архитектуру, основанную на CNN и полносвязных слоях. Open-Unmix работает в частотной области, используя STFT для преобразования аудиосигнала.
Open-Unmix извлекает маски для каждого источника звука и использует их для разделения сигнала на компоненты. В контексте шумоподавления модель может быть использована для удаления шумовых компонентов, сохраняя при этом речевые компоненты.
Spleeter использует архитектуру, основанную на CNN и RNN. Модель работает в частотной области, используя STFT для преобразования аудиосигнала.
Она извлекает маски для каждого источника звука и использует их для разделения сигнала на компоненты. В контексте шумоподавления модель может быть использована для удаления шумовых компонентов, сохраняя при этом речевые компоненты. Использует механизмы внимания для улучшения качества разделения источников звука.
Метрики сравнительного анализа результатов
Существует множество различных подходов к оценке качества аудиосигналов:
-
1. Субъективные методы. Основаны на восприятии человеком, например, путем оценки качества звука экспертами или пользователями. Хотя субъективная оценка важна для определения удобства использования, она обладает рядом ограничений, включая зависимость от индивидуального восприятия и сложности стандартизации.
-
2. Объективные методы. К ним относятся математические метрики, такие как:
-
– соотношение сигнал-шум (SNR, Signal-to-Noise Ratios), которое показывает, насколько успешно модель устранила шум, сохранив полезный сигнал;
– индекс восприятия речи (PESQ, Perceptual Evaluation of Speech Quality), оценивающий качество звука с точки зрения человеческого слуха;
– коэффициент подобия передаваемой речи (STOI, Short-Time Objective Intelligibility), который измеряет, насколько восстановленный сигнал сохраняет разборчивость речи;
– фокус на качестве шумоподавления.
SNR измеряет отношение мощности полезно- го сигнала к мощности шума:
SNR = 10log 10
P сигнала
P шума
где Pсигнала – мощность полезного сигнала;
P шума – мощность шума.
Этот показатель часто используется для оценки качества аудиосигналов и эффективности алгоритмов шумоподавления:
– низкий SNR – менее 0 дБ, означает высокий уровень шума по сравнению с сигналом;
– средний SNR – от 0 до 30 дБ, хороший баланс между сигналом и шумом;
– высокий SNR – более 30 дБ, все больше до- минирует сигнал по сравнению с шумом.
STOI измеряет разборчивость речи в условиях шума:
J
STOI = -Ydj J ^j=- j , где J – общее количество временных фреймов;
dj – мера корреляции для j -го фрейма.
Этот показатель оценивает, насколько хорошо можно понять речь в зашумленном сигнале:
– низкое STOI – менее 0,3, низкая интеллиги-бельность речи или сигнала;
– среднее STOI – от 0,3 до 0,6, умеренная интеллигибельность, может быть понятной, но с некоторыми трудностями;
– высокое STOI – более 0,6, высокая интелли-гибельность, хорошо понятная речь или сигнал.
PESQ измеряет качество речи, воспринимаемое человеком:
PESQ = j(D,A), где D – различия между оригинальным и обработанным сигналами;
A – агрегация результатов по всем временным фреймам и частотным бинам.
Этот показатель учитывает как объективные, так и субъективные аспекты качества речи:
– низкий PESQ – менее 0,5, низкое качество речевой передачи, заметные искажения;
– средний PESQ – от 0,5 до 2, умеренное качество, некоторые искажения могут быть заметны, но не слишком мешают восприятию;
– высокий PESQ – более 2, отличное качество, минимальные искажения, близко к идеальному восприятию.
В рамках проводимого анализа основное внимание уделено анализу качества шумоподавления как ключевого критерия. Главная задача состоит в сравнении моделей на основе их способностей:
– максимально удалять шумовые компоненты;
– сохранять структуру и характеристики исходного сигнала.
Сравнительный анализ будет проведен на базе наиболее популярных подходов к современным нейронным сетям. Выбор в пользу оценки качества шумоподавления обусловлен его практической значимостью, так как именно этот фактор напрямую влияет на удобство использования моделей в реальных условиях.
Данный подход позволяет стандартизировать процесс оценки и выделить лучшие из современных методов, ориентируясь на реальные условия и задачи, где наличие шума является одной из ключевых проблем.
Результаты исследования
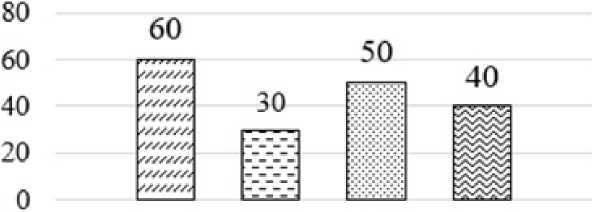
В рамках эксперимента были протестированы уже обученные нейромодели (Demucs, NsNet2_ Denoiser, Open-Unmix, Spleeter) для подавления шума. Исходные данные для тестирования представляли собой аудиофайлы, содержащие смесь сигнала и шума, включая как белый, так и динамический шум. Каждая модель применялась для разделения чистого сигнала и шума, а результаты оценивались по метрикам качества. В качестве устройства проведения исследования использовался персональный компьютер с GPU (NVIDIA GeForce RTX 3050) и CPU (11th Gen Intel(R) Core(TM) i5-11400F @ 2.60GHz). Во время обработки можно наблюдать загрузка CPU (рисунок 1), значение которой имеет большое значение при условии использования определенных вычислительных ресурсов.
Для динамического шума были получены результаты, представленные на рисунке 2. Данные параметра STOI были помножены на 10 для корректного отображения гистограммы.
Из результатов видно, несмотря на улучшение шума, показатель SNR для всех моделей остался в отрицательном диапазоне. Это указывает на трудности, связанные с обработкой динамического шума. Модель Demucs демонстрирует наименьшие отрицательные значения SNR (-3,96 дБ), что свидетельствует о лучшей адаптации к подавлению динамического шума. Spleeter, напротив, имеет наибольшее снижение SNR (-16,77 дБ), что говорит о сложности обработки динамического шума для этой модели.
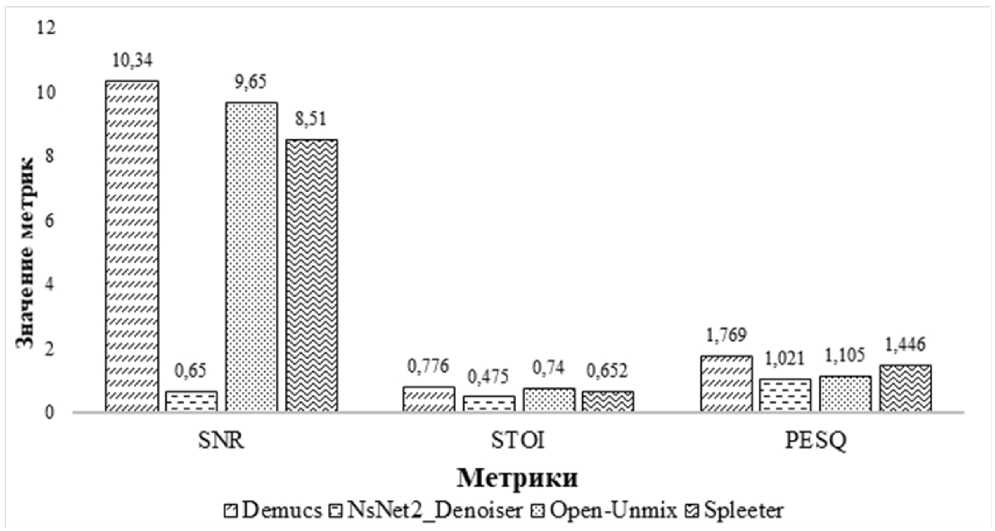
Рисунок 1. Результаты обработки белого (гауссова) шума
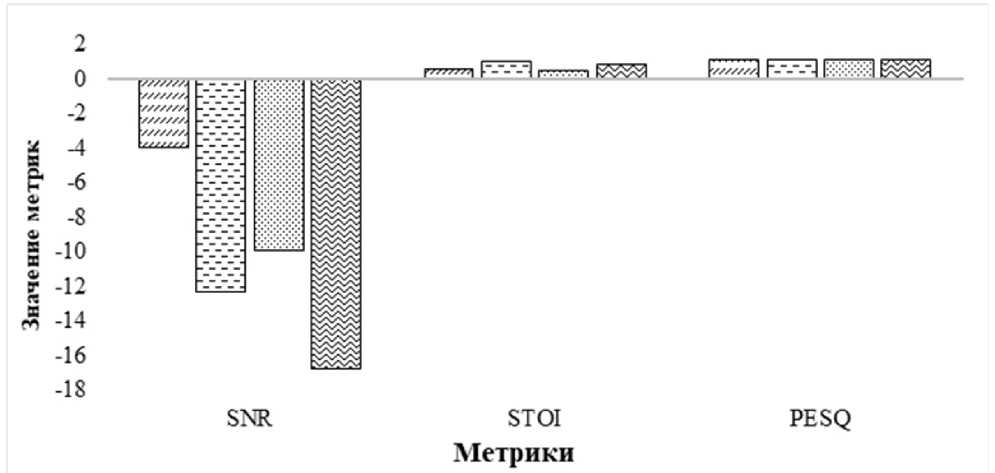
□ Demucs 0NsNet2_Denoiser 0 Open-Unmix 0 Spleeter
Рисунок 2. Результаты обработки динамического шума
Значения STOI и PESQ остаются низкими для всех моделей, что свидетельствует о значительной потери разборчивости и качества речи после обработки. Несмотря на схожие показатели PESQ для моделей, такие как Open-Unmix (1,105) и Spleeter (1,104), их низкие STOI подтверждают, что разборчивость речи остается ключевой проблемой.
Динамический шум создает значительные сложности для всех исследованных моделей. Основной проблемой остается баланс между подавлением шума и сохранением разборчивости речи. Наиболее успешной моделью для подавления динамического шума является Demucs, но даже ее результаты подчеркивают необходимость дальнейшего улучшения алгоритмов.
□ Demucs □ NsNeti Denoiser □ Opeo-Unmix □ Spleeter
Рисунок 3. Загруженность CPU
Результаты обработки аудиозаписи для белого (гауссова) шума представлены на рисунке 3.
Полученные результаты показывают, что модель Demucs демонстрирует наивысшее значение SNR (10,34 дБ), что подтверждает ее превосходство в устранении белого шума. NsNet2_Denoiser, напротив, имеет значительно более низкое значение SNR (0,65 дБ), что указывает на ее менее эффективную работу с этим типом шума.
Demucs показывает лучшие результаты по STOI (0,776) и PESQ (1,769), что указывает на ее способность не только подавлять шум, но и сохранять разборчивость и качество речи. Open-Unmix также демонстрирует хорошие показатели (STOI = 0,740, SNR = 9,65 дБ), однако уступает Demucs в PESQ (1,105). Spleeter с STOI = 0,652 и PESQ = 1,446 показывает результаты средней эффективности.
Белый шум легче подавляется моделями, чем динамический шум. Лидером в данном случае является Demucs, которая обеспечивает наилучшие показатели по всем метрикам, что делает ее подходящей для реального использования.
На основе проведенных экспериментов можно сделать следующие выводы. CNN демонстрируют наилучшие результаты в задачах, требующих высокой скорости обработки, таких как системы реального времени. Это связано с их способностью эффективно работать с локальными признаками в аудиосигнале, что позволяет быстро и качественно удалять шум. RNN показывают высокую эффективность в решении задача, где важна обработка временных зависимостей, например, для улучшения качества речи или в случаях наличия динамичного шума. Однако они требуют больше времени для обработки, что может являться ограничивающим фактором в системах реального времени.
Для систем реального времени затрачиваемое время на обработку имеет критическое значение. Время обработки аудиозаписи длинной 2,5 минуты каждой из исследуемых моделей продемонстрированы в таблице 1.
Таблица 1. Время обработки аудиозаписи
|
Модель |
Время обработки, с |
|
Demucs |
5–10 |
|
NsNet2_Denoiser |
2–5 |
|
Open-Unmix |
5–15 |
|
Spleeter |
5–10 |
CNN благодаря своей архитектуре, обеспечивают высокую скорость обработки с минимальными вычислительными затратами, что делает их оптимальными для таких приложений. RNN и их комбинации с CNN требуют больше времени на вычисления, что делает их менее подходящими для использования в реальных системах с жесткими требованиями к задержке.
Заключение
В отличие от традиционных методов шумоподавления, таких как фильтрация Винера или медианная фильтрация, нейронные сети значительно превосходят их по качеству восстановления аудиосигнала. Традиционные методы часто не способны эффективно справляться с изменяющимися или сложными шумами, теряя при этом важные характеристики сигнала.
Нейронные сети, в отличие от традиционных методов, адаптируются к различным типам шумов и могут поддерживать высокое качество звука, сохраняя все важные аудиопризнаки.
Особое внимание в работе было уделено предварительной обработке данных и методам оценки качества шумоподавления. Правильная пред- варительная обработка, включая нормализацию и фильтрацию, существенно влияет на конечный результат.
Нейронные сети (особенно CNN) являются наиболее эффективными для шумоподавления в аудиосигналах, благодаря своей способности адаптироваться к различным типам шумов и обеспечивать высокое качество звука. В то же время, они обеспечивают лучшую скорость обработки по сравнению с традиционными методами, что делает их особенно подходящими для приложений в реальном времени. Однако для более сложных случаев, когда требуется учет временных зависимостей, можно использовать RNN, несмотря на их большую вычислительную нагрузку.
Результаты данной работы могут быть использованы для целей улучшения качества звука в различных приложениях, таких как системы распознавания речи, голосовые помощники и телекоммуникационные устройства.
Таким образом, исследование подтвердило, что нейронные сети являются мощным инструментом для шумоподавления в аудиосигналах, и их применение открывает новые возможности для улучшения качества звука.
