Сравнительный анализ спектральной языковой модели и других моделей информационного поиска

Автор: Зябрев Илья Николаевич, Василенко Константин Николаевич, Пожарков Олег Витальевич, Пожаркова Ирина Николаевна
Журнал: Сибирский аэрокосмический журнал @vestnik-sibsau
Рубрика: Математика, механика, информатика
Статья в выпуске: 3 (36), 2011 года.
Бесплатный доступ
Проведено сравнение спектральной языковой модели (SLM) с наиболее широко используемыми в информационном поиске моделями, такими как DFR (Difference From Randomness) и BM25 с точки зрения оценки качества решения поисковых задач.
Информационный поиск, вероятностная модель
Короткий адрес: https://sciup.org/148176609
IDR: 148176609 | УДК: 004.738.52
The comparative analysis of spectral language model and other information retrieval models
Comparison of spectral language model (SLM) with models most widely used in information retrieval, such as DFR (Difference From Randomness) and BM25 by quality estimation of the search problems decision.
Текст научной статьи Сравнительный анализ спектральной языковой модели и других моделей информационного поиска
Классическая задача информационного поиска формулируется в следующем виде. Существует множество (коллекция) документов D ( d 1, d 2, … dM ); M – его мощность и формализованный запрос q , выражающий информационные потребности пользователя поисковой системы. Требуется найти документы коллекции D , удовлетворяющие запросу q . Решение задачи обычно представляет собой список документов D rel , в порядке убывания их степени соответствия запросу (релевантности).
В настоящее время большинство алгоритмов оценки релевантности документов построено на основе таких моделей, как BM25 [1] и DFR [2]. К основным достоинствам данных моделей можно отнести довольно высокое качество решения поисковых задач, малую вычислительную сложность и небольшой размер частотной базы, необходимой для вычисления оценок релевантности документов. Среди наиболее существенных недостатков большинства моделей информационного поиска, в частности, BM25 и DFR, стоит выделить унифицированное взвешивание отдельных слов документа, которое приводит к тому, что слова, имеющие одинаковые частоты в оцениваемом документе и во всей коллекции, будут давать одинаковый вклад в оценку релевантности, несмотря на их различную информационную значимость. Спектральная языковая модель (SLM) [3] учитывает распределение слов по всем документам коллекции и этим существенно отличается от указанных моделей, позволяя учитывать статистическую значимость слов при оценке релевантности (взвешивании) документа. Для того чтобы оценить, как такое свойство модели влияет на качество решения поисковых задач, был проведен сравнительный анализ SLM и наиболее широко используемых в данный момент вероятностных моделей: BM25 и DFR.
Описание спектральной языковой модели (SLM). Имеется множество слов W ( w 1, w 2, ..., wN ) и множество документов коллекции D ( d 1, d 2, … dM ), N и M – соответственно их мощности. Для каждой пары «слово–документ» определена нормализованная частота:
nTF(wi, dj) = TF(wi, dj)/len(dj), где TF(wi,dj) – частота слова wi в документе dj; len(dj) – длина документа dj в словах; i = 1...N, j = 1...M.
Тогда спектральная частота ( SF ( w , F )) слова w представляет собой число документов, в которых w имеет нормализованную частоту, равную F :
– SF(w, TF) = {D:nTF(w, dj) = F}, где {*} – оператор мощности множества.
Множество спектральных частот, определенных над областью значений nTF ∈ [0,1], образует частотный спектр слова.
Базовой характеристикой, на основе которой решаются задачи информационного поиска в различных моделях, является вес слова w в документе d . В спектральной модели она определяется по формуле
SLM( w , d ) = log( M / SF ( w , nTF ( w , d ).
Оценка релевантности документа d относительно запроса q определяется по формуле
Re l ( q , d ) = £ SLM( L , d ),
L g q где L – лемма (каноническая форма) слова запроса.
Так как nTF – величина непрерывная, то для построения базы нормализованных частот область значений была разбита на интервалы длиной 0,001. Такая избыточная разрешающая способность была выбрана с целью решения в дальнейшем задачи оптимального разбиения на интервалы.
Последующие исследования показали, что уменьшение интервала разбиения или усреднение значений спектральных частот из окрестности nTF заданной ширины приводит к ухудшению результатов поиска, однако даже при увеличении шага дискретизации до 0,01 качество решения поисковых задач остается достаточно высоким по сравнению с другими моделями.
Сравнение SLM с вероятностными моделями BM25 и DFR. Для независимого оценивания спектральной модели в рамках российского семинара по оценке методов информационного поиска было проведено сравнение двух поисковых алгоритмов: на базе SLM и BM25 [3]. По каждому из них были получены ответы на более чем 40 тысяч предложенных запросов по коллекции из 5 миллионов документов. Оценка ответов проводилась асессорами по методу общего котла. Алгоритм на основе SLM показал практически по всем видам оценок существенно лучшие результаты по сравнению с BM25 (табл. 1).
Однако в сравнении, проведенном на РОМИП-2010, участвовали модели BM25 и SLM не в чистом виде, так как для улучшения качества ранжирования использовался аддитивный алгоритм оценки релевантности документа с использованием весов, вычисленных по различным структурным элементам документов. Поэтому чтобы исключить влияние подобных факторов, было проведено дополнительное исследование моделей на основе таблиц релевантностей РОМИП за 2007–2010 гг.
Для каждой модели (DFR, BM25, SLM) в сравнении было использовано по 2 ранжирующих алгоритма:
– оценка релевантности документа определяется только по исследуемой модели:
Ri( q, d ) = M doc( q, d ), где q – запрос; d – оцениваемый документ;
– оценка релевантности документа определяется по различным структурным элементам документа:
R 2( q, d) = k doc M doc( q, d) +
+ ktitleMtitle (q, d) + kbeginMbegin (q, d), где kdoc, ktitle, kbegin – коэффициенты, полученные на основе машинного обучения; обучение проводилось независимо для каждой модели на основе таблиц релевантностей; Mdoc(q, d) – вклад всего документа в оценку его релевантности; Mtitle(q, d) – вклад заголовка документа; Mbegin(q, d) – вклад начальной части документа; для SLM: M(q, d) = ^SLM(L,d);
L g q для BM25: M (q, d) = ^ BM25( L, d); для
L g q
DFR: M ( q , d ) = ^ DFR( L , d );
L g q
Полученные на запросы ответы по каждому алгоритму оценивались по таблицам релевантостей. Результаты оценок представлены в табл. 2–3.
Как видно, по обоим алгоритмам лучшие результаты по всем оценкам получила спектральная модель. В среднем оценки SLM выше на 10 %, чем у BM25, и на 13 %, чем у DFR, что считается существенной разницей. На рисунке представлен график TREC для ответов по алгоритму R 1 .
Таблица 1
Результаты сравнения ранжирующих алгоритмов на РОМИП-201
|
Evaluation\System |
BM25 |
SLM |
|
Average precision |
0,455 |
0,466 |
|
Bpref |
0,416 |
0,437 |
|
Bpref-10 |
0,514 |
0,522 |
|
Precision(1) |
0,372 |
0,442 |
|
Precision(10) |
0,347 |
0,353 |
|
Precision(5) |
0,372 |
0,395 |
|
Reciprocal Rank |
0,503 |
0,54 |
|
R-precision |
0,439 |
0,456 |
|
NDCG@5 |
0,316 |
0,336 |
|
DCG@5 |
1,091 |
1,186 |
|
NDCG@10 |
0,415 |
0,435 |
|
DCG@10 |
1,608 |
1,689 |
Таблица 2
Результаты сравнения алгоритмов R 1
|
Evaluation\Systems |
DFR |
BM25 |
SLM |
|
Average precision |
0,224 |
0,226 |
0,256 |
|
Bpref |
0,551 |
0,555 |
0,595 |
|
Bpref-10 |
0,64 |
0,643 |
0,685 |
|
Precision(1) |
0,454 |
0,472 |
0,522 |
|
Precision(10) |
0,442 |
0,46 |
0,51 |
|
Precision(5) |
0,444 |
0,464 |
0,514 |
|
Reciprocal Rank |
0,458 |
0,48 |
0,53 |
|
R-precision |
0,28 |
0,296 |
0,32 |
|
NDCG@5 |
0,242 |
0,257 |
0,282 |
|
DCG@5 |
0,835 |
0,863 |
0,961 |
|
NDCG@10 |
0,330 |
0,339 |
0,366 |
|
DCG@10 |
1,306 |
1,315 |
1,451 |
Таблица 3
Результаты сравнения алгоритмов R 2
|
Evaluation\Systems |
DFR |
BM25 |
SLM |
|
Average precision |
0,26 |
0,266 |
0,296 |
|
Bpref |
0,678 |
0,685 |
0,748 |
|
Bpref-10 |
0,782 |
0,788 |
0,858 |
|
Precision(1) |
0,522 |
0,538 |
0,588 |
|
Precision(10) |
0,512 |
0,53 |
0,576 |
|
Precision(5) |
0,514 |
0,53 |
0,58 |
|
Reciprocal Rank |
0,322 |
0,34 |
0,357 |
|
R-precision |
0,526 |
0,542 |
0,597 |
|
NDCG@5 |
0,379 |
0,387 |
0,435 |
|
DCG@5 |
1,203 |
1,231 |
1,406 |
|
NDCG@10 |
0,467 |
0,478 |
0,524 |
|
DCG@10 |
1,772 |
1,802 |
2,026 |
Из графика также видно, что точность результатов поиска при одинаковых значениях полноты у алгоритма на основе SLM выше по сравнению с DFR и BM25.
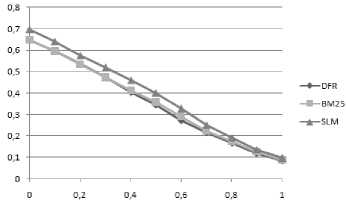
График TREC ответов по алгоритму R 1
В целом, полученные результаты свидетельствуют, что спектральная модель по крайней мере на русскоязычных документах дает более качественное решение поисковых задач.
Проведенные исследования говорят о том, что спектральный подход в оценивании релевантностей документов дает более качественное решение поисковых задач в сравнении с другими методами. Кроме того, SLM является непараметрической моделью, т. е. не требует настройки или машинного обучения, в отличие от многих других моделей, используемых в задачах информационного поиска. Однако спектральная модель обладает существенным недостатком – очень большим размером частотной базы. Если в большинстве вероятностных моделей на каждое слово в частотную базу заносится не более двух параметров, то здесь их число существенно больше. Одним из способов уменьшения базы может быть выбор большего шага дискретизации. Однако проведенные исследования показали, что спектры слов можно аппроксимировать с минимальными потерями качества решения поисковых задач функцией от трех аргументов, в частности, функцией вида aSF(nTF, a,b) = a ■ nTFb, b < 0 , где а и b - параметры, которые определяются для каждого слова на основе метода наименьших квадратов. При этом сохраняется свойство уникальности спектра слов, а размер частотной базы существенно сокращается: на каждое слово необходимо хранить по два параметра.
