Super-resolution Image Created from a Sequence of Images with Application of Character Recognition

Author: Leandro Luiz de Almeida, Maria Stela V. de Paiva, Francisco Assis da Silva, Almir Olivette Artero
Journal: International Journal of Intelligent Systems and Applications(IJISA) @ijisa
Article in issue: 1 vol.6, 2013.
Free access
Super-resolution techniques allow combine multiple images of the same scene to obtain an image with increased geometric and radiometric resolution, called super-resolution image. In this image are enhanced features allowing to recover important details and information. The objective of this work is to develop efficient algorithm, robust and automated fusion image frames to obtain a super-resolution image. Image registration is a fundamental step in combining several images that make up the scene. Our research is based on the determination and extraction of characteristics defined by the SIFT and RANSAC algorithms for automatic image registration. We use images containing characters and perform recognition of these characters to validate and show the effectiveness of our proposed method. The distinction of this work is the way to get the matching and merging of images because it occurs dynamically between elements common images that are stored in a dynamic matrix.
Super-resolution Images, Image Registration, SIFT, RANSAC
Short address: https://sciup.org/15010510
IDR: 15010510
Text of the scientific article Super-resolution Image Created from a Sequence of Images with Application of Character Recognition
Published Online December 2013 in MECS
The development of techniques that make possible the generation of super-resolution images from a image sequence has been useful in several applications, such as for vehicle license plate identification [5], facial identification of possible suspects (criminals, for example) in images from security systems [3], generation of super-resolution aerial images from video pictures or digital camera, accomplish the determination of diagnoses through medical images [4] or even the detection of diseases in their early stages. In astronomy, it can reveal new stars or better identify them by algorithms applied to these images [5][6], and also reconstruct old films [7], minimizing the amount of noise and blurring that appear in each frame designed. In all applications mentioned, it is essential to have visualization with a higher level of detail from one or more specific areas of interest in an image; this is essential to obtain high resolution. However, superresolution images are not always available; this motivates the investigation of super-resolution techniques. Super-resolution is the process of obtaining a high resolution image from one or more low resolution images [27].
Digital images can not present a radiometric resolution (sharpness) and or geometric (size) satisfactory for analysis, whether due to natural factors such as excessive light, or even by the characteristics of the mechanism being used to obtain these images. It is possible that these images of poor quality are reused, i.e. from a sequence of images of poor quality it is possible to obtain a quality superior to those that are being analyzed. The brightness level of each image point of highest resolution is determined by the fusion of the corresponding points in other images, all transformed (rectified).
In this paper, we present an algorithm for construction super-resolution digital images. This is an area of current research in the fields of photogrammetry, computer vision, digital image processing and computer graphics. For the generation of a high resolution image from sequence of images, the correlation between the several images was used in this study, which one of the images was defined as the reference image for each process generation.
The generation of super-resolution images based on a sequence requires first that the images belonging to the scene be rectified, i.e., the image registration must have been executed. The image registration is the process of overlapping two or more images of the same scene taken at different times, from different viewpoints, and or by different sensors. The process geometrically aligns two images. From this, you can create a new image with greater precision that may be used for more detailed analyses, as evidenced in several studies related to this line of research [12].
We use character recognition applied in high resolution, low resolution and super-resolution (generated with the proposed method of this paper) images as a way of qualitative analysis and thus validate and demonstrate the efficiency of our method. We also calculated the mean square error (MSE) between the high resolution image with low resolution image and with a high resolution image with the super-resolution image, generated with our method.
The remaining sections of this paper are organized in the following way: In Section II, we presented the related work and the techniques used for automatic image registration used in this work. In Section III, we present the methodology used in the work for the generation of super-resolution images. In Section IV, we present the experiments, results and discussion. Finally, in Section V we present the conclusions of our work.
-
II. Related Work
-
2.1 Techniques Used for Automated Image Registration
-
2.2 SIFT Algorithm
Tsai and Huang [13] were pioneers in the reconstruction of high resolution image from a sequence of frames from low-resolution images, and based on translation of movements to solve the registry and restore problem. Some years later, Stark and Oskui [14] proposed the reconstruction of high resolution images using the formulation of Projection Onto Convex Sets (POCS), from a set of images. In Peleg et al. [28][1][2] the process for generation of high resolution image started with a super-sampled image, determined as a first approximation, and thereby producing an image with enhanced resolution using the known offsets between images. Hathaway and Meyer [15], scientists of NASA’s Marshall Space Flight (Hunstsville, AL), developed a software used to improve the resolution of images for the purpose to accomplish image analysis involving a sequence of images. A solution is presented in Baker and Kanade [16] to generate high resolution images of the facial images to assist in the construction of a 3-D model of the face human. The approach used by Joyeux et al. [7] addressed the process in the frequency domain for the reconstruction of degraded image sequences, focusing on restoring old movies in black and white, removing noise and blurring found the images through low-pass and high-pass filters, beyond the Fourier series. Freeman et al. [17][8] used Bayesian methods and Markov networks. Sezer [3] used the method of POCS and PCA (Principal Component Analysis) to address the problem of face recognition in video images. Willett et al. [5] implemented a hybrid method that uses wavelet-based methods and FFT (Fast Fourier Transform) to restore images of space telescopes. Kennedy et al. [4] developed a superresolution method for improving the resolution of medical images obtained from the use of scanners clinical PET (Positron Emission Tomography). Papa et al. [6] presented an implementation of POCS in the restoration of images from CCD sensor of CBERS-2 satellite.
Unlike the process that was adopted several years ago to conduct the registration of images manually or a controlled way, several techniques are currently adopted to perform this process automatically. The search for better quality in image registration processes, thus achieving better results in image reconstruction, has led to several studies in this direction. Some of these studies use the SIFT algorithm [19] as a step in the location of the keypoints that are matched between images. The study by Tang et al. [9] is intended for automatic registration in medical images of microscopic sequences. The authors proposed an algorithm that reduces the complexity and size of SIFT descriptors [26], and used a bidirectional matching algorithm to eliminate points corresponding duplicates and
RANSAC algorithm [5][29] to remove false matches. Nasir et al. [21] deal with the problem of generating high resolution images from low-resolution images in three steps: image registration, image fusion based on SVD (Singular Value Decomposition) and interpolation. The authors customized a technique for image registration algorithms using SIFT [19], Belief
Propagation and RANSAC [5][29].
An initial phase for generation of images, used in this study, enables correspondence between multiple images. One of these images is defined as the reference image to the whole process. The match is the process adopted to accomplish the registration of two images, and for this, it is necessary to identify the region of overlap between them. This is done by finding common points. The initial difficulty is to find the keypoints in the first image, which can be located in the second image. One possible approach [24], also used in this study, applies the algorithm SIFT [19] to find points of interest in the two images, and then uses the RANSAC algorithm [29][5] to remove incompatible points.
This algorithm consists in a very efficient method to identify and to describe image keypoints, which is done by performing a mapping with different views of an object or scene, resulting in a vector with 128 values that describes each image keypoint. The algorithm consists of the following steps:
Scale-space extrema detection: The keypoints are detected applying a cascade filtering that identifies candidates that are invariant to scale. The scale-space is defined as a function L ( x , y , σ ) in Equation 1, with an input image I ( x , y ) [25].
L(x,y,σ) = G(x,y,σ) * I(x,y) (1)
where * is a convolution in x and y with the Gaussian G ( x , y , σ ) in Equation 2.
G ( x , y , σ ) = 1 e - ( x 2 + y 2 )/2 σ 2 (2) 2 πσ 2
In order to detect stable keypoint locations in spacescale, Lowe [26] proposed the use of space-scale extrema in the difference-of-Gaussian (DoG) function convolved with the image I ( x , y ), resulting in D ( x , y , σ ), which can be computed from the difference of two nearby scales separated by a constant multiplicative factor k , as in Equation 3.
D(x,y,σ) = (G(x,y,kσ) – G(x,y,σ)) * I(x,y) (3)
The DoG is an approximation of the scale-normalized Laplacian of Gaussian σ 2 ∇ 2 G [26]. The maxima and minima of σ 2 ∇ 2 G produce the most stable image features.
Local extrema detection: from D ( x , y , σ ), in [19], it is suggested that the local maxima and minima must be detected by comparing each pixel with its eight neighbors in the current image and nine neighbors in the scale above and below (26 neighbors). SIFT guarantees that the keypoints are located at regions and scales of high variations, which make these locations stable for characterizing the image.
Orientation assignment: The scale of the keypoint is used to select the Gaussian smoothed image L, with the closest scale, so that all computations are performed in a scale-invariant manner. The gradient magnitude m(x,y) is computed with Equation 4.
m ( x , y ) = Δ x 2 + Δ y 2 (4)
where Δ x = L ( x + 1, y ) - L ( x - 1, y ) and Δ y = L ( x , y + 1) - L ( x , y - 1). The orientation θ ( x , y ) is calculated by Equation 5.
θ ( x , y ) = arctan( Δ y / Δ x ) (5)
Keypoint description: The next step is to compute a descriptor for the local image region that is distinctive and invariant to additional variations, such as change in illumination or 3D viewpoint. In [19][18][22] is suggested that the best approach is to determine the magnitudes and directions of the gradients around the keypoint location. In this approach the Gaussian image on the keypoint scale is used.
-
2.3 Matching between Two Images
-
2.4 RANSAC
In order to find the match between two images it is possible to use the keypoints detected with the SIFT algorithm. In [19][10] is proved that the best match for each keypoint is found by identifying its nearest neighbor, which is defined by minimizing the Euclidean distance to the features vectors. To avoid an exhaustive search in [19] the use of a data structure k-d tree [30] that supports a balanced binary search is suggested to find the closest neighbor of the features and the heuristic algorithm Best-Bin-First (BBF) is used for the search.
RANSAC (RANdom SAmple Consensus) algorithm proposed by Fischler and Bolles [20] is a robust estimation method designed to identify the inliers1 and outliers2 from the set of keypoints detected by the SIFT algorithm. RANSAC is widely used for object recognition [29][22][23]. In addition, it makes it possible to find the geometrically consistent correspondences to solve the problem of joining pairs of images. RANSAC is a robust estimator, so much so that it shows fine results, even in extreme conditions, or with some kind of outlier.
As mentioned by Fischler and Bolles [20], unlike the conventional techniques that use a lot of data to obtain an initial solution, and then eliminate the outliers, RANSAC uses only a set with a minimum number of required and sufficient points for a first estimate, and it continues the process by increasing the set of data points consistent.
-
III. Methodology
This section describes the methodology used in the study to accomplish the generation of super-resolution images from sequences of images (Fig. 1). The implementation of this methodology favored the validation process of the elements used to obtain the image in question.
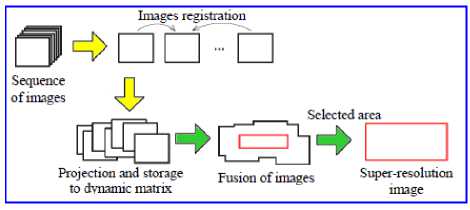
Fig. 1: Methodology for generating image super-resolution from several images
We describe four important steps for the process application:
-
a. Collection of Images: The images were taken by digital cameras.
-
b. Registration and Rectification: SIFT was used to determine the matching points between the images. After the parameters were determined, there was simultaneous rectification and resampling of the images that belong to a sequence relative to reference image. Based on the parameters that allowed the recording of images (detected and extracted by the SIFT and selected by RANSAC), we determined the matching between the images of interest. As the coordinates of the images are projected on the pixel fractions, it was necessary to perform an interpolation between the neighbors in order to determine the brightness level relative to what is desired to determine the super-resolution image on the basis of a real and not just calculated increase in resolution.
-
c. Fusion: an image mosaic is generated by merging the corresponding pixels from the rectified images, with respect to the reference image. In parallel with this process, it was necessary to build data structures based on dynamic lists that merge to form a similar model for a dynamic matrix. This process resulted in the labeling of each point of the original image mosaic to which it belongs, in order to generate a higher resolution image based on the original sequence. The implementation done allows these data structures can be expanded in any direction, displacing the original data and its indexes according to the insertion request.
-
d. Super-resolution: the last step is obtained by selecting the area of interest from the image generated. From this, a super-resolution image is generated based on the data linked to the images that belong to the desired area.
-
3. 1 Steps to Generate the Images from Mosaics
In this step it is necessary to label each point of the original image to which it belongs, making it possible to generate a higher resolution image based on the original sequence, leading to formation of the tiles.
The structures used are described in the following, starting with the data structures to accomplish the rectification in memory of each pixel. The implementation provided allows that the dynamic matrix to be expanded in any direction, displacing the old data and inserting its contents as needed. For example: entering 10 columns on the left side of the matrix implies that the old index (0, 0) exists; it is moved to the index (0, 10). The elements of the dynamic matrix can be checked in Fig. 2.
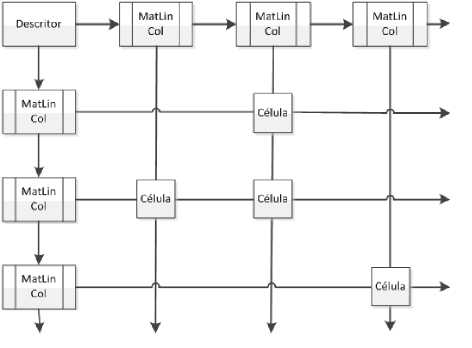
Fig. 2: Dynamic matrix to store the image pixels that belong to the mosaic
Different methods were used and the following records that define the data structures (dynamic matrix) to store the pixels of the images belong to the mosaic:
MatLinCol *next_line,*next_column;
Celula *next_celula;
};
struct Descritor
{
MatLinCol *first_line,*first_column;
};
Next_Celula
This field stores the pointer to the next cell in the linked list.
Descritor
It has the following fields: *first_line, *first_column. Important fields that store elements able to access any element that is part of this structure.
The construction of the linked lists is made during the process of generating the panoramic image. The lists grow with each iteration of the process, and it may occur in any direction, maintaining the old data. This process is done by inserting columns or rows negative (insert to left or up) or positive (insert to right or down). If negative columns are inserted, the whole structure is then corrected by adding the index of each cell and of the structure that forms the grid (Matlincol) with the lines inserted value for line or column.
Only the corresponding positions in the mosaic are stored that have at least one pixel that was obtained some images considered for the construction of the mosaic.
-
IV. Experiments, Results and Discussions
This section presents the experiments performed and validated using the methodology proposed in this work. Two experiments were performed to evaluate the superresolution image quality obtained with the proposal of this work. In the first experiment, we used a character recognition algorithm [11] applied to the images. In the second experiment we calculated the mean square error between the captured images and super-resolution image.
The images used in the experiments are presented in Fig. 3. In (a) it has a high resolution image (a piece of 413 x 360 pixels) obtained using a camera with a resolution of 12 Megapixels, in (b) one of the 15 low resolution images (a piece of 207 x 181 pixels ) obtained with the same camera, but with a resolution of 3 Megapixels. In (c) it has the image super-resolution (427 x 372 pixels) obtained with the proposal presented in this paper.

Fig. 3: a) high resolution image (413 x 360)

Fig. 3: b) one of 15 low-resolution images (207 x 181)

Fig. 3: c) super-resolution image (427 x 372) obtained with the proposal presented in this work

Fig. 4: (c)
Fig. 4: Regions of images containing the characters evaluated in the first part of the experiment: a) high resolution (HR); b) one of 15 low resolution images, used to obtain super-resolution image; c) superresolution image (SR) obtained with the proposed method.
In the 15 low-resolution images, the character recognition algorithm presented an average hit rate of 77.27%, failing on average 5 of 22 characters, while for super-resolution images the hit rate was 95.45%, not recognizing only a character ('R').
Table 1 shows the errors obtained in each of the 15 low-resolution images and also the super-resolution (SR) and high resolution (HR) images.
Table 1: Number of characters incorrectly identified in 15 low resolution, super-resolution and high resolution images
|
#image |
errors |
#image |
errors |
#image |
errors |
||
|
1 |
4 |
7 |
7 |
13 |
5 |
||
|
2 |
6 |
8 |
4 |
14 |
6 |
||
|
3 |
3 |
9 |
5 |
15 |
9 |
||
|
4 |
4 |
10 |
5 |
SR |
1 |
||
|
5 |
5 |
11 |
5 |
HR |
0 |
||
|
6 |
4 |
12 |
3 |
-
4.1 Experiment I – Characters Recognition
In this experiment a character recognition algorithm [11] is applied on the images as a way of quality analysis. The experiment was divided into two parts, where each part contains the image region containing the title of one of two books photographed in the images. In the first part of the experiment, were used images containing the title of one of the books (“INTELIGÊNCIA ARTIFICIAL”). The character recognition algorithm could correctly identify all characters in high resolution image. The regions containing the characters evaluated by the algorithm are shown in Fig. 4.
inteugEncia
ARTIFICIAL
Fig. 4: (a)

Fig. 4: (b)
In the second part of this experiment, images were used containing the title of the second book ("Image Processing, Analysis, and Machine Vision"). Fig. 5 shows in (a) an image containing a piece of the title of the book, obtained at high resolution, and (b) an image obtained at low resolution. In (c) it has the superresolution image obtained with the proposed method.
Image Processing, Analysis, and Machine Vision
Image Processing, Analysis, and Machine Villon

(a) (b) (c)
Fig. 5: Regions of images containing the characters evaluated in the second part of the experiment:
-
a) high resolution (HR);
-
b) one of 15 low resolution images, used to obtain super-resolution image;
-
c) super-resolution image (SR) obtained with the proposed method
In the experiment we use the character recognition algorithm of Silva et al. (2011) applied in the images as a form of quality analysis, the algorithm had a hit rate
-
4.2 Experiment II – Mean Square Error between Images
of 87.18%, failing to hit only 5 of the 39 characters. In 15 low-resolution images, the algorithm presented an average hit rate of 62.89%, failing to hit an average of 14.47 of the 39 characters. In the super-resolution image, the algorithm presented an average hit rate of 82.05%, failing to hit 7 of 39 characters, a rate much higher than that obtained with the low resolution images and very close to that obtained with the high resolution image. Table 2 shows the errors obtained in each of the 15 low-resolution images.
Table 2: Number of characters incorrectly identified in 15 low resolution, super-resolution and high resolution images
|
#image |
errors |
#image |
errors |
#image |
errors |
||
|
1 |
11 |
7 |
11 |
13 |
21 |
||
|
2 |
18 |
8 |
12 |
14 |
11 |
||
|
3 |
15 |
9 |
10 |
15 |
12 |
||
|
4 |
17 |
10 |
12 |
SR |
7 |
||
|
5 |
16 |
11 |
19 |
HR |
5 |
||
|
6 |
14 |
12 |
18 |
The mean square error (MSE) pixel-to-pixel between the high resolution image and the image superresolution it is observed in this experiment, as well as the mean squared errors between the high image resolution and 15 low resolution images. Firstly, the keypoints are extracted from images by performing the matching between high resolution image with the super- resolution image, obtained with the proposed method, as well as the correspondence being the high resolution image with 15 low resolution images. From the correspondence inliers are obtained and are calculated the homographic matrices, using the RANSAC algorithm [20]. The low resolution images and superresolution image, obtained with the proposed method, are transformed so that the region of interest is homogeneous to super-resolution image. This transformation (scale, rotation, translation and perspective) is performed using the function “warpPerspective” from OpenCV computer vision library [31] that transforms the source image using the equation:
dst ( x , y ) = src
Mx+M у + Мз M31x + M32y + M33
,
M^x + M22y + M23 M31x + M32y + M33
where M is the homographic matrix. We use the bicubic interpolation method on the transformation of the images.
Are also evaluated these same errors (mean square error), however, considering a small neighborhood (3x3) between corresponding pixels in the images. Table 3 shows the errors obtained from the high resolution image and the 15 low resolution images, and the error obtained from the high resolution image and the with super-resolution image (SR), obtained with the method proposed in this paper.
Table 3: Mean square error (MSE) pixel-to-pixel and neighborhood (3x3)
|
#image |
MSE pixel-to-pixel |
MSE 3x3 |
#image |
MSE pixel-to-pixel |
MSE 3x3 |
|
|
1 |
188,25 |
68,45 |
9 |
137,38 |
42,61 |
|
|
2 |
142,34 |
49,72 |
10 |
141,07 |
45,13 |
|
|
3 |
141,56 |
45,67 |
11 |
153,89 |
58,79 |
|
|
4 |
150,29 |
48,63 |
12 |
362,82 |
147,24 |
|
|
5 |
147,00 |
45,57 |
13 |
189,72 |
67,02 |
|
|
6 |
128,31 |
39,96 |
14 |
151,92 |
50,13 |
|
|
7 |
154,33 |
50,07 |
15 |
221,97 |
81,01 |
|
|
8 |
138,98 |
44,35 |
SR |
117,79 |
29,89 |
-
V. Conclusions
This paper presented the proposal for a methodology to automatically build super-resolution images from sequences of images with overlapping. The results were significant, and show the relevance of the work in super-resolution image generation. For the generation of super resolution images, the proposed methodology was based on SIFT algorithm for extracting descriptors of keypoints, and also the RANSAC algorithm to eliminate false matches and estimate the homographic matrix. The parameters provided by the matrix homographic allowed recording the images that belong to the same scene for subsequent fusion of the points using the median correlation between these points, thus minimizing the aliasing effect contained in images. It is necessary to know which images contain data that are linked to the area of the mosaic that is being analyzed to have ideal descriptors and good matching, especially because the images generated show great improvement as regards their restoration for future analysis of targets of interest without reworking to acquire new images with higher resolution.
References Super-resolution Image Created from a Sequence of Images with Application of Character Recognition
- J. Yuan, S. Du, X. Zhu, “Fast super-resolution for license plate image reconstruction”, 19th Int Conf on Pattern Recog (ICPR), 2008, pp. 1-4.
- Y. Tian, K.-H. Yap, and Y. He, “Vehicle license plate super-resolution using soft learning prior”, Multimedia Tools and Applic, pp. 1-17, 2011.
- O.G. Sezer, “Super-resolution techniques for face recognition from video”, Thesis, Sabanci University, Istanbul, Turkiye, 62p. 2003.
- J.A. Kennedy, O. Israel, A. Frenkel, R. Bar-Shalom, H. Az-hari, “Super-resolution in PET imaging”, IEEE Trans Medical Img, pp.137-147, 2006.
- R. Willett, I. Jermyn, R. Nowak, J. Zerubia, “Wavelet-based super-resolution in astronomy”. In: XIII Astronomical Data Analysis Software and Systems, vol. 314, 2004.
- J.P. Papa, N.D.A. Mascarenhas, L.M.G. Fonseca, K. Bensebaa, “Convex restriction sets for CBERS-2 satellite image restoration”. Int. J. Remote Sensing, pp.443-458, 2008.
- L. Joyeux, et al., “Reconstruction of degraded image sequences. Application to film restoration”, Image and Vision Computing. n. 19, France, 2001, pp. 503-516.
- M. Irani, P. Anandan, S. Hsu, “Mosaic based representations of video sequences and their applications”, Proc. of Fifth Int Conf on Computer Vision (ICCV'95), 1995.
- C. Tang, Y. Dong, X”. Su, “Automatic registration based on improved SIFT for medical microscopic sequence images. In: 2nd Int Symp on Intell Inf Technology Application. IITA '08. vol. 1. 2008, pp. 580-583.
- C. Xing, J. Huang, “An improved mosaic method based on SIFT algorithm for UAV sequence images”, IEEE Int Conf on Computer Design and Applications (ICCDA), p. 414-417, 2010.
- F.A. Silva, A.O. Artero, M.S.V. Paiva, R.L. Barbosa, “Reconhecimento de Caracteres Baseado em Regras de Transições entre Pixels Vizinhos”, Avanços em Visão Computacional. Omnipax Editora Ltda, Curitiba, PR, 2011.
- L. Li, N. Geng, “Algorithm for Sequence Image Automatic Mosaic based on SIFT Feature” IEEE – International Confer-ence on Information Engineering. pp. 203 -206, 2010.
- R.Y. Tsai, T.S Huang, “Multiframe image restoration and registration”, Advances in Computer Vision and Image Processing. pp. 317–339 1984.
- H. Stark, P. Oksui, “High-resolution imge recovery from image-plane arrays using convex projections” J. Optical Society of America, vol.6, n. 11, pp. 1715–1726, 1989.
- D. Hathaway, P. Meyer, “NASA: Video Enhancer For Law Enforcement & More” Adv Imaging: Sol for the Electronic Imaging Prof, 1999.
- S. Baker, T. Kanade, “Super-resolution optical flow”, CMU-RI-TR-99-36, 1999.
- W.T. Freeman, T.R. Jones, E.C. Paztor, “Example-based super-resolution”, MERL (2001).
- M.S. Shrestha, I. Arai, “Signal Processing of Ground Penetrating Radas Using Spectral Estimation Techniques to Estimate the Position of Buried Target”, EURASIP Journal Applied Signal Proc. pp. 1198-1209, 2003.
- D.G. Lowe, “Distinctive image features from scale-invariant keypoints”. Int Journal of Computer Vision, Vol. 60, No. 2, pp. 91–110, 2004.
- M.A. Fischler, R.C. Bolles, “Random Sample Con-sensus: A Paradigm for Model Fitting with Applications to Im-age Analysis and Automated Cartography”, Comm. of the ACM, Vol 24, pp. 381–395, 1981.
- H. Nasir, V. Stankovic, S. Marshall, “Singular value decomposi-tion based fusion for super-resolution image reconstruction”, Int Conf on Signal and Image Proc Applic (ICSIPA), 2011 IEEE, pp. 393-398.
- Z. Dakun, L. Zhaoxin, J. Guiyuan, “A feature-based al-gorithm for image mosaics with moving objects, IEEE Int Conf on Intelligent Computing and Int Systems (ICIS), p. 26-29, 2010.
- P.V. Lukashevich, B.A. Zalesky, S.V. Ablameyko, “Medical Image Registration Based on SURF Detector” Pattern Recognition and Image Analysis, v. 21, n. 3, p. 519–521, 2011.
- X. Fang, B. Luo, H. Zhao, J. Tang, S. Zhai, “New multi-resolution image stitching with local and global alignment”, IET Computer Vision, vol. 4, n. 4, p. 231-246, 2010.
- T. Lindeberg, “Scale-space theory: A basic tool for ana-lyzing structures at different scales”, Journal of Applied Statistics, 1994.
- D.G. Lowe, “Object recognition from local scale-invariant features”. In: Int Conf on Computer Vision, Corfu, Greece, pp. 1150–1157, 1999.
- A. Collet, D. Berenson, S.S. Srinivasa, D. Ferguson, “Object recognition and full pose registration from a single image for robotic manipulation”, In: IEEE Int Conf Robotics and Automation, ICRA'09, pp. 48–55, 2009.
- S. Peleg, D. Keren, L. Schweitzer: Improving Image Resolution Using Subpixel Offsets (Motion). Pattern Recog Letters, pp. 223–226. 1987.
- T. Okabe, Y. Sato: Object recognition based on photometric alignment using RANSAC. In Proc of Comp Vision and Pattern Recognition. pp. 221-228, 2003.
- M. Brown, D.G. Lowe: Automatic Panoramic Image Stitching using Invariant Features. International Journal of Computer Vision, vol. 74, n. 1, pp. 59–73, 2007.
- G. Bradski, A. Kaehler, “Learning OpenCV: Computer Vision with the OpenCV Library”, O’Reilly, 2008.
