Технологии хранения и обработки больших данных для обучения скоринговых моделей

Автор: Брюхова Е.М., Данилов А.С.
Журнал: Международный журнал гуманитарных и естественных наук @intjournal
Рубрика: Технические науки
Статья в выпуске: 12-3 (99), 2024 года.
Бесплатный доступ
В статье рассматриваются современные подходы к хранению и обработке больших данных для обучения скоринговых моделей для оценки кредитных рисков. Спроектирована модель данных, используемых для обучения скоринговых моделей, рассчитаны объемы данных в схеме. Исследование показывает эффективность использования технологий экосистемы Apache Hadoop и Nifi для распределенного хранения, записи и чтения данных, и фреймворка Apache Spark для их обработки. Разработано архитектурное решение, позволяющее управлять потоками данных, получаемых из продуктовых систем-источников. Решение позволяет хранить большие объемы данных, а используемый фреймворк - их обрабатывать и решать задачу обучения скоринговой модели для оценки кредитных рисков.
Скоринг, большие данные, база данных, машинное обучение
Короткий адрес: https://sciup.org/170208586
IDR: 170208586 | DOI: 10.24412/2500-1000-2024-12-3-55-59
Big data storage and processing technologies for purposes of training scoring models
The article contains actual approaches to storing and processing big data for training scoring models for assessing credit risks. A model of the data used for training scoring models was designed, and the volumes of data in the scheme were calculated. The research shows the effectiveness of using the Apache Hadoop and Nifi ecosystem technologies for distributed storage, writing and reading data, and the Apache Spark framework for processing them. An architectural solution has been developed to manage data flows received from source product systems. The solution allows you to store large volumes of data, and the framework used allows you to process it and solve the problem of training a scoring model for assessing credit risks.
Текст научной статьи Технологии хранения и обработки больших данных для обучения скоринговых моделей
На сегодняшний день, в сфере финансовых технологий, для оценки рисков, все чаще разрабатываются и внедряются скоринговые системы с применением обучаемых ml-моделей. Это позволяет повысить точность прогноза, снизить возможные риски, тем самым увеличив прибыльность кредитных продуктов. Для решения задач разработки и обучения скоринговых моделей, необходима соответствующая инфраструктура хранения, записи, чтения и обработки больших объемов данных. Выбор подходящих технологий хранения и обработки данных становится ключевой задачей при разработке подобных систем. Ошибки в проектировании архитектуры и работе с данными могут повлиять на точность прогнозов моделей, увеличить продолжительность обучения, повлиять на производительность системы [1, с. 178].
В качестве технологий хранения статич-ных/регулярно обновляемых данных реляционные базы данных, например, PostgreSQL, реже - нереляционные базы данных. Реляционные базы данных характеризуются высокой надежностью и структурой хранения данных, соблюдением связей, и принципов ACID. При этом, реляционные базы данных неэффективны при работе с неструктурированными или высоконагруженными потоками данных. Нереляционные базы данных адаптированы под задачу хранения и обновления больших объе- мов данных. К примеру, это может быть колоночная база данных - MongoDB или Clickhouse [1, с. 316]. Такие базы данных обладают большей гибкостью, однако требуют дополнительных усилий для интеграции с традиционными аналитическими инструментами. Для задач скоринговых сервисов и моделей необходимы инфраструктурные решения и хранилища, подходящие под 2 условия: объемы и нагрузка.
Чтобы правильно определить выбрать и спроектировать подходящее решение, необходимо определить минимальный (исходный) набор, структуру и типы данных, примерный и прогнозный объем с учетом роста числа заявок и объемов портфеля. Набор данных может быть следующим: доход, возраст, семейное положение, количество иждивенцев, тип занятости, стаж работы, уровень образования, кредитная история, размер задолженности, ежемесячные платежи, доля дохода на кредиты, регион, тип недвижимости, срок проживания по адресу, наличие автомобиля, количество запросов в бки, тип кредита, сумма кредита, срок кредита, цель кредита. Также добавим версионная (событийную) таблицу, в которой будет храниться история оплат клиента по ранее оформленным кредитам. Тем самым получается таблица статичных данных по заемщику на момент запроса, и таблица истории оплат.
|
Переменная |
Название переменной |
Example Value |
Data Type |
|
Payment_ID |
Идентификатор платежа |
1 |
integer |
|
Borrower_ID |
Идентификатор заемщика |
101 |
integer |
|
Payment_Date |
Дата платежа |
10.01.2024 |
date |
|
Payment_Amount |
Сумма платежа |
10000 |
integer |
|
Payment_Status |
Статус платежа |
on_time |
varchar |
Рис. 1. Версионная таблица истории платежей клиента
Также следует учитывать несколько таблиц, которые будут хранить перефирийные данные. Например, классификаторы статусов, балансы, проводки по депозитным счетам, транзакции по картам, данные об имуществе, таблица данных о пользователе, обезличенные экономические данные для поправки на ситуацию на рынке и в экономике. Приблизим задачу к максимально реальной, и будем использовать логи транзакций пользователя, которые могут использоваться для обучения модели. Минимальная информация из логов, которую можно сохранять для каждой транзакции - это идентификатор, timestamp, сумма, валюта, тип, местоположение сведения об устройстве и так далее. Исходники логов передаются в формате JSON и могут быть преобразованы в тип данных Apache Parquet. Итого получается одна статичная таблица -назовем ее scoring.static_data, версионная таблица с историей платежей – scoring.payments_history и логовые файлы, назовем их log_service.transactions
На следующем этапе необходимо оценить объемы хранимых данных и ожидаемую нагрузку на сервис. Предположим, что количество пользователей, по которым мы можем записать данные и использовать их для скоринга - около 10 млн. Сначала рассчитаем вес статичной таблицы static_data: 11 переменных int (4 байта), 1 булевая переменная (1 байт), остальные - переменные varchar с разным предельным количеством байтов. Итого: (11*4+220+1)*10Л7=2,65 гигабайт. В этой связи, для хранения статичных данных вполне подойдет Postgres [1, с. 482]. Даже с учетом создания read-only реплики, вес таблицы займет не больше 5 гб, с поправкой на масштабирование (новые записи) может понадобиться до 7 гб емкости в ближайшие 1-2 года. Рассчитаем объемы для истории платежей payments_history. Установим условие, что в среднем пользователь совершает около 1.5 платежа в месяц. Тогда получим 10^7*1.5*120=1,8*10^9 записей. При среднем весе в 150 байт/запись (строка), получим 1,8*10Л9*150=270 ГБ. Объем уже значительно больше, но, тем не менее, с этими данными сможет также справиться Postgres. Даже с поправкой на масштабирование предельного объема хранение в ближайшие 2 года на 6080%, этот объем не превысит 500 ГБ.
Логовые файлы, как правило, хранятся в формате JSON и содержат в себе больший объем данных. Для примера возьмем: идентификатор транзакции, идентификатор пользователя, сумма транзакции, валюта, идентификатор мерчанта, название мерчанта, город местоположения мерчанта, страна местоположения мерчанта, категория мерчанта, статус, тип платежного метода, последние 4 цифры карты платежного метода, эмитент карты платежного метода, идентификатор устройства, ip адрес устройства, операционная система устройства, версия программы устройства, оценка рисков, идентификатор кампании метаданных, примечание метаданных. Тогда, одна запись в формате JSON будет весить около 500 байт. Количество транзакций на пользователя за 10 лет = 21,9 тыс. Тогда 21900*10^7=2.19*10^11 логовых записей транзакций. Итоговый вес будет равняться 2.19*10Л11*500=109.5 ТБ. Для таких объемов данных Postgres не подойдет, к тому же эта СУБД не предназначена для хранения логовых файлов. С учетом того, что данные о транзакциях будут использоваться для аналитических задач, необходимо обеспечить гибкое и стабильное хранение логовых записей, а также внедрить ETL процесс, реплицирующий данные из логовых записей в различные аналитические хранилища (например, Clickhouse или аналитические СУБД на базе
PostgresSQL). Одним из таких решений может быть Apache Hadoop [4, с. 509].
Построим схему хранения данных, с поправкой на то, что в рамках статьи придерживаемся заранее установленного ограничения в
2 исходные таблицы, логовые файлы и 1 таблицу для репликации данных из логов в аналитическое хранилище. Рассмотрим получившийся верхнеуровневый дизайн хранения и репликации больших данных на рисунке 2.
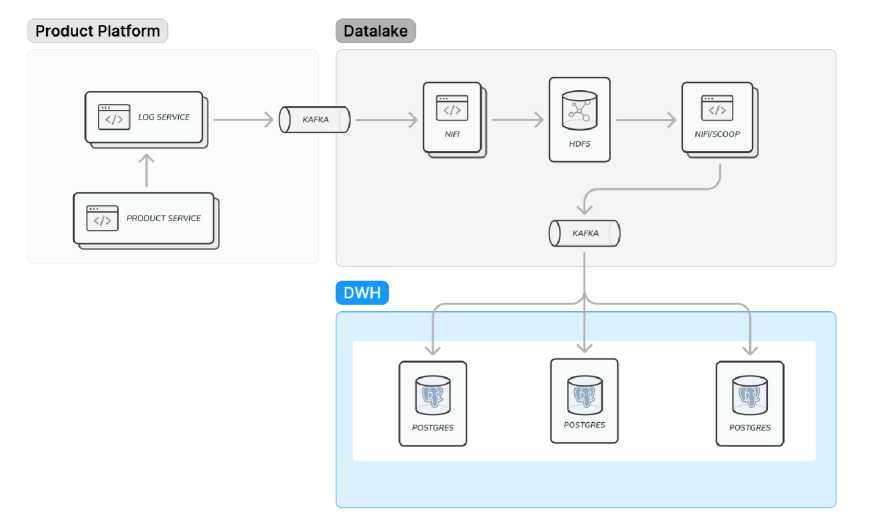
Рис. 2. Схема архитектуры хранения и репликации больших данных для задач скоринга
Схема состоит из 3 основных кластера инфраструктуры: продуктовая платформа, дата-лейк и храналище данных (DWH). Продуктовая платформа – это источник данных (мастер-система). По каждой совершенной пользователем операции данные передаются в ло-говые сервисы. Это может быть Logstash или Slunk. Логовый сервис (в некоторых случаях это может быть напрямую продуктовая система) отправляет топиками брокера сообщений Kafka. Топики вычитывает Apache Nifi – сервис управления потоками данных (входящих и выходящих из даталейка). На следующем этапе необходимо преобразовать получившиеся данные в подходящий тип: Apache parquet. Это необходимо для решения оптимизационной задачи за счет сжатия конечного файла. Для оценки эффекта рассчитаем сжатие на синтетической модели логов в формате JSON, которую можно преобразовать в parquest с помощью фреймворка Apache Spark [8]. Он позволяет выполнять распределенную обработку и вычисление данных. Выполним тест в среде Google Colab. С помощью библиотеки random и функций randomint() + random.randomchoice() из заданных массивов с категориями транзакций, статусами и валютой, зададим 500 тысяч случайно сгенерированных записей (объектов) в логах транзакций вида:
def gene rate„random_t ransaetion_data(п=100): data = [] for i in range(n):
transaction = {
"transaction_id": f"txn_{str(i+1).zfill(3)}", "user_id": random.randintl100000, 999999), "timestamp": f"2024-12-02T{random.randint(10, 23)}:{random.randint(0, 59)}:{random.randint(0, 59)}" "amount": round(random.uniform!10, 500), 2), "currency": "USD", "status": random.choice!["completed", "pending"]), "transaction_type": "payment", “product_type": "debit_card", "processing_type": random.choice!["online", "offline"])
Рис. 3. Функция, генерирующая записи о совершенной транзакции в формате JSON
Преобразуем полученный JSON в паркет-ник с помощью функции pq.write_table(), предварительно загрузив данные в таблицу pa.Table.from_pandas(). Используя функцию getsize(json_data), измерим вес полученных объектов и сравним. Размер JSON файла: 152.43 MB. Размер Parquet файла: 9.30 MB. Разница (эффект оптимизации ранения) – почти в 16 раз. В nifi это может быть реализовано с помощью процессора convertRecord.
После обработки данных и преобразования их в тип данных parquet, nifi загружает данные в HDFS (Hadoop Distributed File System). Его можно поднять локально, для теста и учебных задач. Для решения подобных задач, в IT-инфраструктуре бизнеса, кластеры hadoop обычно разворачивают с использованиям k8s (kubernetus). Для этого необходима установка, настройка переменных и конфигов, развертывание файловой системы. Глобальное отличие использования в бизнесе – в объемах данных и нагрузки, именно поэтому используют кластеры (чтобы распределить больше машинного ресурса, в зависимости от задач) [5, с. 14].
Как показано на схеме, также с помощью встроенных процессоров nifi ParquetReader, ConvertRecord и PutDatabaseRecord можно настроить ETL-процесс отправки данных в PostgresSQL. Однако для задачи обучения ml-модели в скоринге это не обязательно, по- скольку можно использовать любые данные напрямую из даталейка.
Для выполнения аналитических вычислений на данных в HDFS удобнее всего использовать также Apache Spark. Это позволит не использовать аналитические хранилища (а значит, работать напрямую с паркетниками и с минимальным временным лагом). В фреймворк встроены ml-библиотеки MLib и SparkML, с помощью которой модель можно обучить. Оптимальные языки – Python или Scala.
Подводя итог, хранение больших данных с применением технологий экосистемы Apache, таких как HDFS, Apache Spark, nifi и других позволяет оптимизировать объемы файлов, а также производить обучение модели напрямую из даталейка, что существенно сокращает время на загрузку данных. Использование HDFS и Apache Spark в задачах машинного обучения для скоринга является эффективным и масштабируемым решением. Эти технологии обеспечивают необходимую гибкость и производительность для обработки данных, что позволяет строить точные и надежные модели, на актуальных данных с минимально возможной загрузкой машинного ресурса. Встроенные в фреймворк Apache Spark библиотеки позволяют решать большинство аналитических задач, а также строить сложные прогнозные и обучаемые ml-модели на больших объемах данных.
Список литературы Технологии хранения и обработки больших данных для обучения скоринговых моделей
- Алджанов В. ИТ-архитектура от А до Я: Комплексное решение. Первое издание. - М.: Изд-во БХВ, 2018. - 503 с.
- Уиллс Д., Тандон А. Расширенная аналитика с PySpark. Практические примеры анализа больших наборов данных с использованием Python и Spark. - М.: Манн, Иванов и Фербер, 2022. - 223 с.
- Шапира Г., Палино Т. Apache Kafka. Потоковая обработка и анализ данных. - М.: ДМК Пресс, 2022. - 512 с.
- White T. Hadoop: Подробное руководство. - М.: О'Рейли, 2013. - 672 с.
- Shtoltc E. Machine Learning in Practice - From PyTorch Model to Kubeflow in the Cloud for Big Data. 2020. - 93 p.
- Zhang X., Lin W. Big Data Analytics: From Data to Knowledge. - New York: Wiley, 2020. - 350 p.
- HDFS Architecture Guide. - [Электронный ресурс]. - Режим доступа: https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html (дата обращения: 13.12.2024).
- Apache Spark 3.5.1 Documentation. - [Электронный ресурс]. - Режим доступа: https://spark.apache.org/docs/3.5.1/index.html (дата обращения: 13.12.2024).
