Telegram-бот и парсинг системы

Автор: Нестерова Н. С., Демченков М. В.
Журнал: Международный журнал гуманитарных и естественных наук @intjournal
Рубрика: Технические науки
Статья в выпуске: 7-2 (106), 2025 года.
Бесплатный доступ
Статья посвящена созданию интеллектуального агента, способного автоматически парсить и анализировать данные, поступающие из социальных сетей. Агент обладает возможностью не только извлекать и обрабатывать большие объёмы информации, но и интерпретировать её, превращая разрозненные данные в полезные аналитические выводы для маркетологов, социологов, политологов, выполнения прогнозов различного типа.
Чат-бот, парсинг, структура, диаграмма
Короткий адрес: https://sciup.org/170210808
IDR: 170210808 | DOI: 10.24412/2500-1000-2025-7-2-252-256
Telegram bot and parsing systems
The aim of the study was to create an intelligent agent capable of automatically parsing and analyzing data coming from social networks. The agent has the ability not only to extract and process large amounts of information, but also to interpret it, turning disparate data into useful analytical conclusions for marketers, sociologists, political scientists, and making forecasts of various types.
Текст научной статьи Telegram-бот и парсинг системы
Эпоха Big Data нуждается в наличии интеллектуальных агентов с возможностью самостоятельного парсинга и анализа данных из социальных сетей.
Таким образом необходимо наличие Telegram-бота, способного в автоматическом режиме:
-
- собирать новостной контент из заданных источников,
-
- производить интеллектуальную фильтрацию на основе тематических, тональных и контекстных признаков,
-
- оперативно предоставлять пользователю только релевантную и значимую информацию.
Реализация этой цели обеспечивает создание эффективного инструмента, способного решать задачи информационного мониторинга, персонализированной ленты новостей и интеллектуальной поддержки принятия решений.
Проведённый сравнительный анализ платформ разработки Telegram-ботов показал, что выбор метода реализации должен опираться на специфику задачи, а также учитывать баланс между гибкостью инструментария, сложностью настройки и доступностью экосистемы [1]. В условиях, когда проект ориентирован на автоматический сбор информации из внешних источников (социальных сетей, новостных каналов) и интеллектуальную фильтрацию по заданным критериям, особенно важными становятся такие параметры, как возможность обработки данных в реальном времени, расширяемость архитектуры и инте- грация с системами машинного анализа текста.
По результатам анализа были рассмотрены как визуальные конструкторы (Manybot, Chatfuel), так и полнофункциональные программные библиотеки на Python, Node.js и других языках [2-4]. Конструкторы оказались недостаточными в контексте требований к интеллектуальной обработке и парсингу – они ограничены в возможностях настройки логики, не позволяют взаимодействовать с внешними API и библиотеками анализа текста, а также не масштабируются под задачи машинного обучения.
Оптимальным путём реализации проекта стала разработка на языке Python с использованием среды разработки PyCharm и асинхронного фреймворка Aiogram, предоставляющего высокую производительность и гибкость при работе с Telegram Bot API. Такой подход обеспечивает полный контроль над логикой взаимодействия, позволяет подключать библиотеки для парсинга (например, requests, BeautifulSoup4, aiohttp) и модули для интеллектуальной фильтрации (в том числе с использованием библиотек NLTK, spaCy, transformers и др.).
Принятый подход позволяет выстроить модульную архитектуру бота, в которой компоненты отвечают за независимые задачи: получение и предварительную очистку данных, анализ содержимого, фильтрацию на основе ключевых признаков и выдачу релевантной информации пользователю. Такая структура легко масштабируется – можно подключать новые источники, адаптировать фильтры под тематические направления или интегрировать модели искусственного интеллекта для более глубокой семантической обработки.
Ключевым этапом разработки чат-бота явилось создание схемы компоновки системы, которая описывает ключевые модули с функциональными взаимосвязями и порядком взаимодействия в рамках общей архитектуры.
Схема определяет, порядок объединения компонентов системы для обеспечения стабильной работы парсинга, гибкой фильтрации и интерактивного взаимодействия с пользова- телем через интерфейс Telegram. Схема компоновки представлена на рисунке 1.
User (Пользователь) – инициирует запросы в Telegram-бот, отправляя команды или ключевые слова для получения информации. Ввод пользователя запускает цепочку логики, включая парсинг и фильтрацию.
Telegram Bot API – промежуточный уровень, через который происходит обработка входящих и исходящих сообщений. Он принимает запросы от пользователей, передаёт их в логический модуль, а также возвращает отфильтрованный контент обратно.
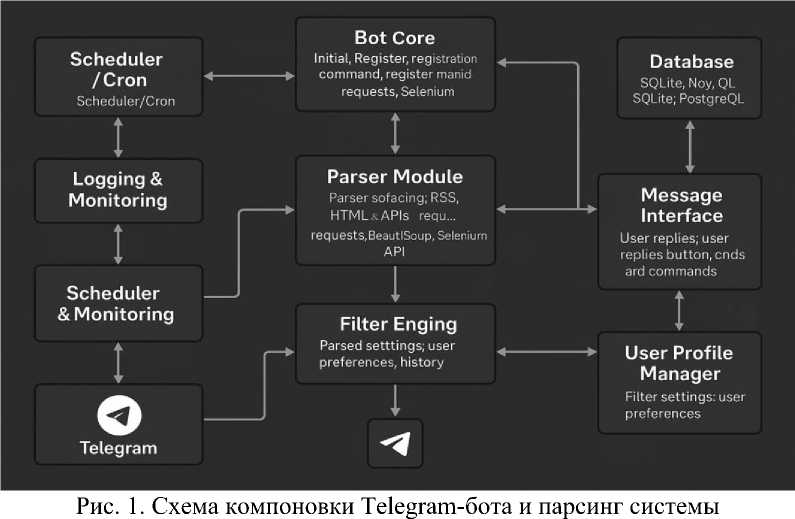
Core Logic Module (Основной логический модуль) – отвечает за координацию работы всей системы. Он анализирует команды пользователя, формирует задачи для парсинга, направляет их в соответствующий парсер и запускает фильтрацию полученных данных.
Parser Subsystem (Подсистема парсинга) – реализована на основе библиотек парсинга (например, requests, BeautifulSoup, lxml). Подсистема выполняет сбор данных с указанных источников (VK, Telegram-каналы, новостные сайты) и структурирует их в удобный для фильтрации формат.
Filtering Enging (Модуль интеллектуальной фильтрации) – применяет заданные критерии (по ключевым словам, по авторам, по дате, тематике и т.д.) для отбора релевантного контента. Этот модуль может использовать базовые алгоритмы на основе логических выраже- ний или даже ML-модели для оценки значимости новостей.
Database (База данных) – служит для хранения истории запросов, кэшированных новостных блоков и параметров фильтрации,что обеспечивает быстрый доступ к данным и возможность анализа предпочтений пользователя.
Admin Panel / Config Interface (Админ-панель) – используется разработчиком или администратором системы для настройки источников, фильтров и параметров работы парсинга и может использоваться для отслеживания логики и статистики.
Scheduler / Cron Task Manager (Планировщик задач) – отвечает за автоматический запуск парсинга по расписанию, поддерживая регулярность обновления новостного контента без участия пользователя.
Message Formatter (Формирователь сообщений) – адаптирует отфильтрованные данные в формат, удобный для отображения в Telegram (текст, ссылки, кнопки и т.д.). Также подготавливает шаблоны ответов и может генерировать карусели или инлайн-меню.
Telegram UI Layer (Интерфейс Telegram) – обеспечивает конечную визуализацию информации в Telegram: текстовые сообщения, кнопки, команды. Этот уровень отвечает за удобство и понятность взаимодействия.
Диаграмма вариантов использования Telegram-бота представлена на рисунке 2.
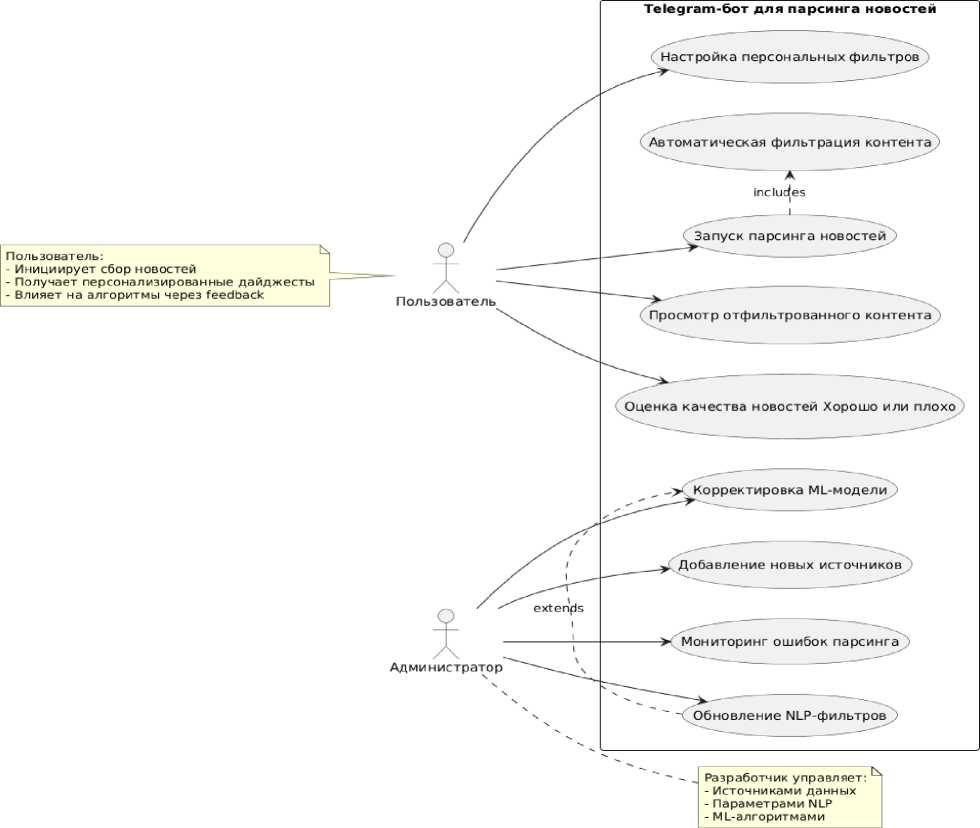
Рис. 2. Диаграмма вариантов использования Telegram-бота
На диаграмме представлены два ключевых актора – пользователь и администратор. Пользователь взаимодействует с готовой системой парсинга новостей, а именно: инициирует сбор контента по заданным параметрам (ключевые слова, темы), и получает персонализированные новостные дайджесты, автоматически отфильтрованные системой. Он также влияет на качество подборки через механизм обратной связи (оценки хорошо/Плохо) для корректировки работы алгоритмов. С другой стороны, администратор (разработчик)
управляет технической частью системы: настраивает и обновляет источники данных (Telegram-каналы, RSS-ленты, социальные сети), конфигуририрует NLP-фильтры (стоп-слова, тематические категории, параметры релевантности) и корректирует ML-модель в целях улучшения классификации контента, мониторит ошибки парсинга и выполняет техническое обслуживание системы.
Диаграмма активности и парсинг системы представлены на рисунке 3.
| Корректировка ML-модели
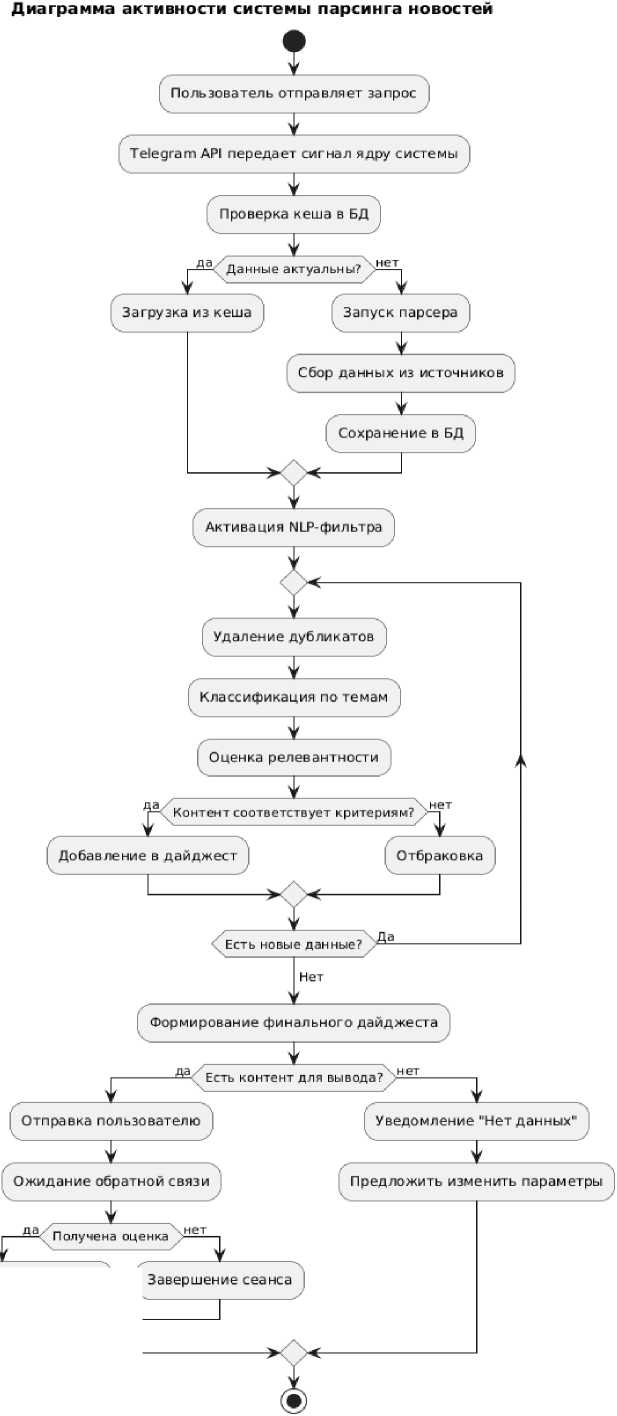
Рис. 3. Диаграмма активности Telegram-бота и парсинг системы
Процесс начинается с запроса пользователя, который через Telegram API передается ядру системы. Прежде всего проверяется наличие актуальных данных в БД. При их отсутствии - активируется парсер для сбора информации из внешних источников. Затем NLP-модуль последовательно удаляет дубликаты, классифицирует контент и оценивает релевантность. Материалы, не соответствую- щие критериям, отбраковываются. Система отправляет сформированный дайджест пользователю и ожидает обратной связи. Полученные оценки корректируют ML-модель для улучшения будущих подборок. При отсутствии запрошенного контента пользователю предлагается изменить параметры поиска.
Классы, их переменные и функции Telegram-бота представлены в таблице 1.
Таблица 1. Компоненты Telegram-бота и парсинг системы
|
Класс |
Атрибуты/Методы |
Описание |
|
DataTable |
source_links, parsed_content, getContent() |
Хранит кешированные новости и параметры фильтрации |
|
Parser |
target_sources, startParsing() |
Занимается сбором данных из Telegram, RSS и других источников |
|
NLPFilter |
stop_words, filterContent() |
Удаляет дубликаты, классифицирует контент по темам |
|
NewsItem |
title, source, relevance_score |
Структура единицы новостного контента |
|
TelegramAPI |
sendDigest(), getUserFeedback() |
Отправляет результаты пользователю и получает оценки |
|
User |
preferences, rateContent() |
Управляет запросами и фидбеком |
|
MLModel |
updateWeights(), predictRelevance() |
Адаптирует фильтрацию на основе оценок пользователей |
Основными результатами работы является создание Telegram-бота, реализующего интеллектуальный анализ пользовательского запроса, автоматизированный сбор новостного контента из Telegram-каналов, его семантическую фильтрацию на основе лемматизации и понятийной близости, сохранение пользовательского фидбека и уточнения исходного запроса. Также поддерживается расширение базы знаний и интерактивное дообучение системы.
Областью применения являются системы мониторинга, редакционные и аналитические службы, интеллектуальные ассистенты, образовательные и исследовательские проекты, коммерческий продукт.
