Тонкая настройка больших языковых моделей в качестве исторических экстракторов текста: улучшение последовательных рекомендаций с помощью латентных сигналов

Автор: Ли Ч.
Журнал: Труды Московского физико-технического института @trudy-mipt
Рубрика: Информатика и управление
Статья в выпуске: 2 (66) т.17, 2025 года.
Бесплатный доступ
Системы последовательных рекомендаций предназначены для прогнозирования следующего взаимодействия пользователя с элементом на основе его предыдущих действий. Традиционные методы часто опираются на структурированные идентификаторы, что может упускать богатую контекстуальную информацию, содержащуюся в текстовых метаданных. В данной работе предложена тонкая настройка больших языковых моделей (LLM) в качестве экстракторов исторического текста для генерации скрытых сигналов из последовательностей взаимодействий пользователей. Эти сигналы улучшают традиционные подходы к моделированию последовательностей, повышая точность и надежность рекомендаций.
Рекомендательная система, большая языковая модель, интел- лектуальный анализ данных, извлечение признаков
Короткий адрес: https://sciup.org/142245006
IDR: 142245006 | УДК: 004.9
Fine-tuning large language models as historical text extractors: enhancing sequential recommendation with latent signals
Sequential recommendation systems aim to predict the next item a user will interact with based on their historical behaviors. Traditional methods often rely on structured IDs or embeddings, which may overlook rich contextual information presented in textual metadata. In this work, we propose fine-tuning large language models (LLMs) as historical text extractors to generate latent signals from user interaction sequences. These signals enhance conventional sequence modeling approaches, improving recommendation accuracy and robustness.
Текст научной статьи Тонкая настройка больших языковых моделей в качестве исторических экстракторов текста: улучшение последовательных рекомендаций с помощью латентных сигналов
«Московский физико-технический институт (пациопальпый исследовательский университет)», 2025
в неструктурированных текстовых данных, сопровождающих пользовательские действия. Последние исследования показывают, что вспомогательные сигналы, такие как отзывы о продуктах [4], контекст просмотров [5] и описания сессий [6], содержат ключевые подсказки о предпочтениях пользователей, однако их потенциал остается недоиспользованным из-за сложностей семантического извлечения и временного согласования.
Появление больших языковых моделей, таких как BERT [7] и GPT [8], открывает беспрецедентные возможности для преодоления этого разрыва. Хотя существующие работы (например, [9,10]) исследовали применение больших языковых моделей для задач рекомендаций, большинство из них используют либо прямое промптирование, либо поверхностное объединение признаков, не решая две ключевые проблемы: 1) семантическую дизъюнкцию в предметной области: большые языковые модели, предобученные на общих корпусах, плохо распознают узкоспециализированную терминологию и временные зависимости в исторических текстах (например, «матрица» в математике против названий фильмов); 2) согласование сигналов с последовательностью: скрытые предпочтения, извлеченные из текстов, часто конфликтуют с явными поведенческими паттернами при наивном объединении [11].
В данной статье представлен FTE4REC (Fine-tuning Text Extractors for RECommendation) — новаторский фреймворк, объединяющий тонкую настройку больших языковых моделей с традиционной системой последовательных рекомендаций . Тонкая настройка (fine-tuning) — это процесс дополнительного обучения предобученной большой языковой модели на наборе данных, специфичном для конкретной области. Она направлена на оптимизацию производительности модели при выполнении специализированных задач, что позволяет ей лучше адаптироваться к требованиям целевой предметной области.
-
2. Постановка задачи
-
3. FTE4REC
В задаче последовательных рекомендаций целью является предсказание следующего элемента, с которым может взаимодействовать пользователь, на основе истории его взаимодействий. Для заданного множества пользователей U = {ui,u2, ... ,u n }, г де N — общее количество пользователей, и множества элементов У = {vi,v2,... ,v m }, г де М — общее количество элементов, задача заключается в моделировании последовательности взаимодействий между пользователями и элементами во времени.
Для каждого пользователя u Е U, его история взаимодействий с элементами v Е V представляется в виде временной последовательности событий:
Н (u,v,t) = '■ ,h^^2 . ■, где Т обозначает длину истории взаимодействий, а Н(u,v,t) означает взаимодействие (например, клик, оценку или покупку) между пользователем u и элементом v в момент времени t.
Цель состоит в предсказании следующего элемента vp+1, с которым пользователь вероятнее всего взаимодействует, учитывая его историю до момента Т. Формально это можно выразить как vT+1 = arg max Р (v \ u, W1^, h't,..., h'h) vEV где Vp+1 — предсказанный следующий элемент, а Р(v | u,h^t1 ,h't2,...,h'tT) ~ вероятность того, что пользователь u взаимодействует с элементом v при условии его прошлых взаимодействий h^t1, h^t2,..., h'^T-
FTE4REC (Fine-tuning Text Extractors for RECommendation) — это фреймворк рекомендательной системы, предназначенный для предсказания следующего элемента, представля- ющего интерес для пользователя, использует временную и контекстную информацию для повышения предсказательной силы традиционных последовательныхмоделей рекомендаций.
Ро (vt+1 | U,V,H), где в представляет веса большой языковой модели.
Используя встраиваемый слой, можно генерировать персонализированные векторные представления на основе информации о пользователе и его исторического поведения.
LLM (u),LLM(V).
Цель данного фреймворка максимизировать вероятность генерации элементов, схожих с целевым элементом.
Ро(vT +1 | LLM(n),LLM(V),H).
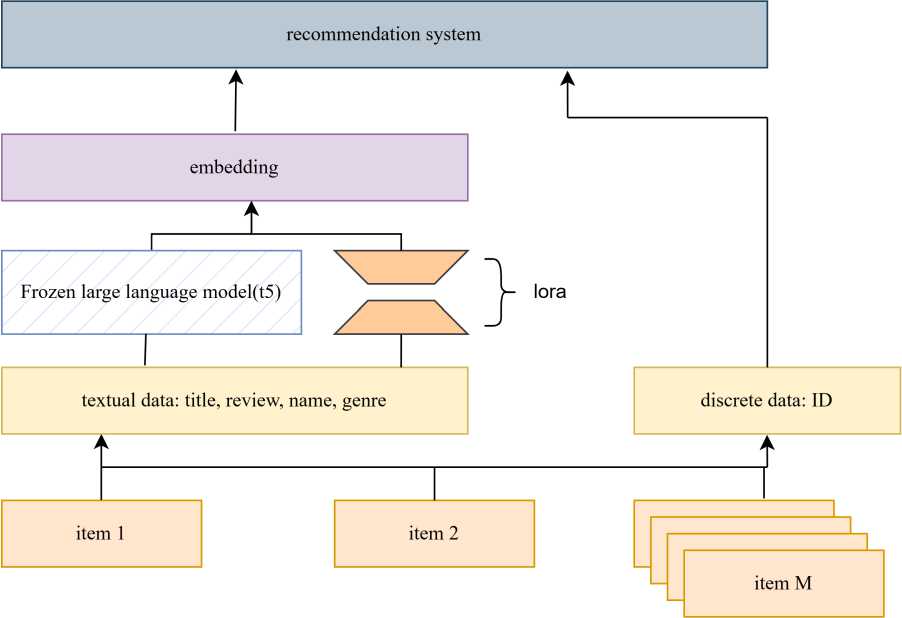
Рис. 1. Структура FTE4REC
Основная идея фреймворка заключается в использовании большой языковой модели для формирования рекомендаций на основе текстовой информации. Два ключевых модуля FTE4REC описаны в следующих разделах.
-
3.1. Описание экстрактора текста
Пользователи и элементы являются базовыми единицами рекомендательной системы. Традиционный подход к представлению элементов и пользователей заключается в назначении каждому из них уникального индекса (т.е. дискретного ID). Для учета предпочтений пользователей предлагаются ID-ориентированные рекомендательные системы, которые обучают представления пользователей и элементов на основе их взаимодействий.
Однако, поскольку текстовая информация о пользователях и элементах содержит важные данные для понимания их интересов, разработан Улучшенный метод рекомендаций, использующий текстовую информацию через большую языковую модели, что позволяет улучшить обучение представлений пользователей и элементов в рамках end-to-end обуче ния.
В рамках предложенного подхода большая языковая модель выступает в качестве универсального семантического экстрактора, преобразующего неструктурированные текстовые описания элементов (названия товаров, отзывы пользователей, технические характеристики) в компактные векторные представления. Ключевой идеей является синтез глубокого контекстуального понимания, присущего большой языковой модели, с адаптивностью к специфике рекомендательных задач.
Архитектурные основания выбора большой языковой модели обусловлены принципиальными ограничениями классических методов [14]. Статистические подходы (TF-IDF, ВМ25 [15]) фиксируют поверхностные лексические паттерны, игнорируя смысловые нюансы. Нейросетевые модели типа Word2Vec, хотя и улучшают ситуацию, остаются слепы к контекстуальной полисемии. Например, термин «яблоко» в описании фрукта и логотипа технологической компании кодируется идентично. Трансформерные большые языковые модели, благодаря механизмам самовнимания, разрешают эту проблему через динамическое взвешивание контекстных зависимостей.
Предобученные языковые модели, несмотря на их универсальность, сталкиваются с фундаментальными проблемами при применении в рекомендательных системах. Эти ограничения обусловлены диссонансом между общими лингвистическими паттернами и спецификой предметной области, что требует целенаправленной адаптации модели. В этом исследовании большая языковая модель тонко настраивается с помощью низкоранговой адаптации (LoRA) [16], что позволяет эффективно обновлять параметры модели, не изменяя основную предварительно обученную модель.
В отличие от традиционного полного дообучения метод LoRA вносит модификации только в небольшое подмножество параметров модели, добавляя низкоранговые адаптивные матрицы к слоям самовнимания. Это значительно снижает вычислительные затраты и уменьшает объем необходимой разметки данных, что делает метод особенно привлекательным для использования в рекомендационных системах с ограниченными ресурсами.
LoRA обновляет параметры, связанные с конкретной задачей последовательной рекомендации, адаптируя их для прогнозирования следующего элемента на основе изученных текстовых представлений.
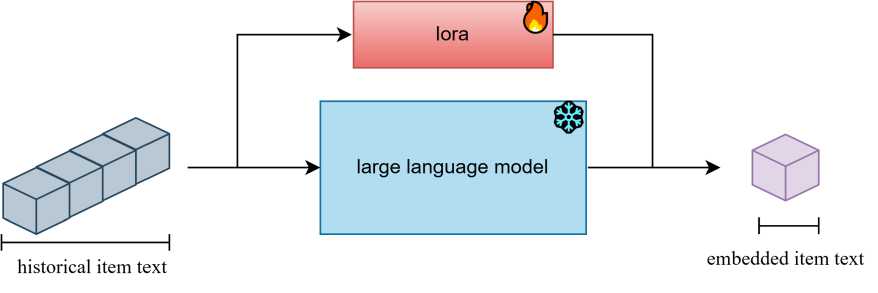
Рис. 2. Тонкая настройка большой языковой модели
На рисунке 2 показан модуль экстрактора текста, используемый в нашем подходе. Сначала текстовое описание каждого элемента подается на вход предобученной модели t5 (t5-small) для получения персонализированные векторные векторы. Поскольку веса модели t5 фиксированы, поэтому требуют тонкой настройки, каждый элемент представляется 512-мерным вектором.
В этом подходе использованы последние слои большой языковой модели для получения векторов в задачах рекомендаций. Этот выбор основан на исследованиях распределения лингвистической информации в слоях большой языковой модели. В частности, работа М. Цзинь и др. [17] показала, что разные слои большой языковой модели кодируют различную информацию: нижние слои захватывают синтаксические особенности, а верхние — семантические.
В итоге получен обработанный набор данных, включающий как семантические признаки каждого элемента.
-
3.2. Гибридная архитектура LLM+ID
Современные системы последовательных рекомендаций всё чаще используют архитектуры на основе трансформеров, первоначально предложенных для задач обработки естественного языка. Ключевое преимущество механизма самовнимания (self-attention) заключается в способности моделировать долгосрочные зависимости в последовательностях взаимодействий. Для пользовательской последовательности длиной Г, матрица внимания вычисляется как:
Attention (Q, К, V ) = softmax
(QKF)
V
-
• Q = ЕUiWQ векторы запроса,
-
• К = ЕUiWx векторы ключа,
-
• V = ЕUiWy векторы значения,
-
• Vd размерность ключевого вектора.
Здесь W q ,W k ,Wy Е Rdxd — обучаемые проекционные матрицы, ad — размерность вложения. Коэффициент масштабирования dd обеспечивает численную стабильность во время обучения, предотвращая слишком большие скалярные произведения.
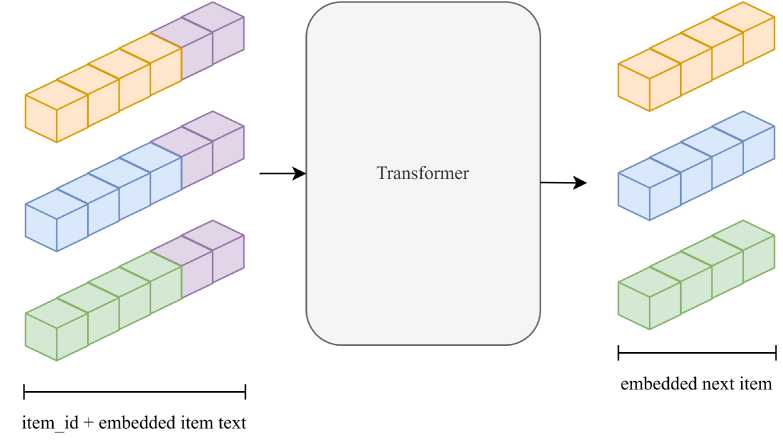
Рис. 3. Embeddings
Традиционные реализации (наир., SASRec [18]) используют исключительно ID-встраивания элементов, что приводит к двум фундаментальным ограничениям:
семантическая бедность: дискретные ID не отражают содержательные атрибуты элементов;
холодный старт: новые элементы без истории взаимодействий получают случайные встраивания.
Для преодоления этих ограничений мы предлагаем инновационный метод комбинирования текстовых встраиваний большой языковой модели с традиционными ID-представлениями .
embeddings (id, text) = Concat (linear (id1 ), lin ea^di ),..., linear(id^ ), LLM (text)) (2)
-
3.3. Функция потерь Listwise
-
4. Эксперименты
В рекомендательных системах для оптимизации качества рекомендаций использована функция потерь на основе метода Listwise, которая помогает моделировать предпочтения пользователей. В отличие от методов Pointwise и Pairwise метод Listwise оптимизирует сразу весь список рекомендаций, что позволяет лучше учитывать глобальные закономерности ранжирования.
Применяемая функция потерь Listwise определяется следующим образом:
£ = - ^ (log a(yi) + ^ j / Su log(l - a(yj ))) , (3)
ie,su где Su обозначает множество положительных примеров для пользователя u, yi — прогнозируемая оценка релевантности для положительного элемента i, а ст0 — сигмоидная функция активации.
Цель данной функции потерь заключается в максимизации предсказанных оценок для объектов, с которыми пользователь взаимодействовал (положительных примеров), и минимизации оценок для невзаимодействованных объектов (отрицательных примеров). Она состоит из двух частей:
стимулирует приближение предсказанного рейтинга положительных примеров к 1, повышая их позиции в списке рекомендаций, способствует приближению предсказанных оценок отрицательных примеров к 0, понижая их ранги.
Эксперименты проведены на трех версиях кинематографического датасета MovieLens: ml-100k (100,000 оценок), ml-lm (1 миллион оценок) и ml-20m (20 миллионов оценок). Для обеспечения репрезентативности данных выполнена предобработка: удаление пользователей с менее чем пятью взаимодействиями, временная сортировка событий по меткам времени. Для каждого пользователя с историей взаимодействий длиной не менее 25 элементов сконструированы перекрывающиеся последовательности. Входные данные разбиты на три части:
Тренировочные выборки: первые 20 элементов последовательности, цель — векторное представление 21-го элемента.
Валидационные выборки: элементы с 1-го по 21-й, цель — векторное представление 22-го элемента.
Положительные примеры: Для каждого пользователя в качестве положительных примеров выбираются фильмы, с которыми он имел взаимодействия (например, просмотр, оценка).
Отрицательные примеры: Отрицательные примеры формируются случайным образом из фильмов, с которыми пользователь не взаимодействовал. Такой баланс позволяет модели учиться различать релевантные и нерелевантные объекты.
Для объективной оценки эффективности предлагается сравнение с тремя популярными моделями:
SASRec (Self-Attentive Sequential Recommendation)
BSARec (Beyond Self-Attention for Sequential Recommendation) [19]
Основные метрики — Hit RateAK (HR(Q>K) и Normalized Discounted Cumulative GaiirAK (NDCG@K) — вычисляются для К = 5, К = 10 и К = 20.
Таблица!
Сравнение эффективности методов адаптации T5-small на датасете MovieLens
|
NDCG@5 |
NDCG |
NDCG(&20 |
HR(&5 |
HRalO |
HR(&20 |
||
|
ml-lOOk |
SASRec |
0.169 |
0.221 |
0.293 |
0.374 |
0.516 |
0.755 |
|
BSARec |
0.190 |
0.247 |
0.291 |
0.385 |
0.570 |
0.752 |
|
|
FTE4REC |
0.181 |
0.232 |
0.277 |
0.377 |
0.542 |
0.725 |
|
|
ml-Im |
SASRec |
0.419 |
0.451 |
0.470 |
0.768 |
0.871 |
0.947 |
|
BSARec |
0.410 |
0.444 |
0.462 |
0.765 |
0.877 |
0.952 |
|
|
FTE4REC |
0.426 |
0.454 |
0.474 |
0.784 |
0.873 |
0.953 |
|
|
ml-20m |
SASRec |
0.390 |
0.429 |
0.444 |
0.722 |
0.850 |
0.942 |
|
BSARec |
0.391 |
0.430 |
0.458 |
0.718 |
0.855 |
0.949 |
|
|
FTE4REC |
0.391 |
0.432 |
0.454 |
0.726 |
0.857 |
0.945 |
-
5. Заключение
В данной работе была предложена и исследована модель FTE4REC для задач последовательных рекомендаций. Проведенные эксперименты на датасетах ML-100K, ML-1M и ML-20M позволили оценить её эффективность по сравнению с базовыми моделями SASRec и BSARec.
Результаты показывают, что FTE4REC демонстрирует наилучшие показатели NDCGK
и
НВ'ЦК на более крупных датасетах (ML-1M и ML-20M), что подтверждает её способность учитывать сложные паттерны пользовательского поведения и эффективно обучаться на больших объемах данных. Однако на небольшом датасете ML-100K наша модель уступает BSARec, особенно по метрике NDCG<0>5 и HR(Q>10.
Причины более слабых результатов на малых данных:
Проблема недообучения - FTE4REC использует сложные механизмы обучения, требующие большого количества данных для полной настройки параметров модели. В случае ML-100K данных может быть недостаточно для эффективного обучения.
Чувствительность к размеру выборки - Методы на основе самовнимания, такие как BSARec, могут лучше справляться с небольшими датасетами за счет меньшего количества параметров и более агрессивного механизма обобщения.
Зависимость от глубины истории - В малых выборках пользовательские истории короче, что может снижать эффективность представления последовательностей в нашей модели, тогда как BSARec адаптируется лучше за счет двунаправленного самовнимания.
В целом результаты подтверждают, что FTE4REC является перспективным методом для крупных рекомендательных систем, однако на небольших выборках ее преимущества могут нивелироваться. В будущих исследованиях можно рассмотреть методы предварительного обучения или доработать модель для более эффективного обучения на ограниченных данных.
