Transfer Learning with EfficientNetV2 for Diabetic Retinopathy Detection

Author: Michael Chi Seng Tang, Huong Yong Ting, Abdulwahab Funsho Atanda, Kee Chuong Ting
Journal: International Journal of Engineering and Manufacturing @ijem
Article in issue: 6 vol.14, 2024.
Free access
This paper investigates the application of EfficientNetV2, an advanced variant of EfficientNet, in diabetic retinopathy (DR) detection, a critical area in medical image analysis. Despite the extensive use of deep learning models in this domain, EfficientNetV2’s potential remains largely unexplored. The study conducts comprehensive experiments, comparing EfficientNetV2 with established models like AlexNet, GoogleNet, and various ResNet architectures. A dataset of 3662 images was used to train the models. Results indicate that EfficientNetV2 achieves competitive performance, particularly excelling in sensitivity, a crucial metric in medical image classification. With a high area under the curve (AUC) value of 98.16%, EfficientNetV2 demonstrates robust discriminatory ability. These findings underscore its potential as an effective tool for DR diagnosis, suggesting broader applicability in medical image analysis. Moreover, EfficientNetV2 contains more layers than AlexNet, GoogleNet, and ResNet architecture, which makes EfficientNetV2 the superior deep learning model for DR detection. Future research could focus on optimizing the model for specific clinical contexts and validating its real-world effectiveness through large-scale clinical trials.
Diabetic retinopathy detection, deep learning, convolutional neural network, medical imaging, image classification
Short address: https://sciup.org/15019561
IDR: 15019561 | DOI: 10.5815/ijem.2024.06.05
Text of the scientific article Transfer Learning with EfficientNetV2 for Diabetic Retinopathy Detection
In recent years, the advent of deep learning has revolutionized various fields of medical image analysis, including DR detection [1, 2], blood vessel segmentation [3, 4], and brain tumor detection [5]. Leveraging the power of neural networks, deep learning models have demonstrated remarkable capabilities in automating the detection and diagnosis of diseases from medical images, thereby aiding healthcare professionals in making more accurate and timely decisions.
Among these applications, DR detection holds significant importance due to its prevalence and potential sightthreatening consequences if left undiagnosed or untreated. DR is a common complication of diabetes mellitus and is a leading cause of blindness worldwide. Early detection and intervention are crucial for preventing vision loss in diabetic patients.
While various deep learning architectures have been explored for DR detection, including convolutional neural networks (CNNs) and recurrent neural networks (RNNs), the potential of EfficientNetV2 in this domain remains largely unexplored. EfficientNetV2, an advanced variant of EfficientNet, has shown promising performance across a range of computer vision tasks, yet its efficacy specifically in DR detection has not been extensively investigated.
This paper aims to address this gap by evaluating the performance of EfficientNetV2 in DR detection. We conduct comprehensive experiments to assess its efficacy compared to other established deep learning models that have been previously tested by researchers in this domain. By filling this void in the literature, our study aims to provide insights into the suitability of EfficientNetV2 for DR detection and its potential advantages over existing approaches.
The remaining sections of this paper are divided into several parts. Section 2.0 discusses the related works in this study. Section 3.0 presents the methodology of this study. Section 4.0 shows the results obtained from various deep learning models. Finally, Section 5.0 concludes this paper.
2. Related Works
Various studies have investigated the application of deep learning models for the classification of DR images. For example, Arias-Serrano et al. [6] proposed using a retrained AlexNet in MATLAB for glaucoma and DR detection. They employed transfer learning, dividing the dataset for training and testing, achieving validation accuracy ranging from 89.7% to 94.3%, showcasing the network’s effectiveness.
Shi et al. [7] explored different neural network architectures for DR detection using datasets from the Aravind Eye Hospital. Comparing basic CNNs, VGG16, and GoogLeNet on a dataset of 8929 photos, GoogLeNet outperformed others with a 97% training accuracy and an 85% test accuracy, indicating its potential for efficient patient screening. Junjun et al. [8] introduced a novel approach using deep convolutional neural networks (DCNNs) with ResNet18 architecture. They incorporated a regions scoring map (RSM) attention mechanism to identify severity levels in retinal images. The proposed model achieved comparable performance to existing methods, emphasizing the advantage of highlighting discriminative regions.
Al-Moosawi et al. [9] addressed DR diagnosis challenges using a ResNet34-based deep learning model. Their model, trained on Kaggle datasets, achieved a high F1 score of 93.2% for stage-based DR classification, demonstrating promising computational performance metrics. Lin et al. [10] focused on automating DR diagnosis with a ResNet50-based deep learning model, achieving a high F1 score of 93.2% for stage-based DR classification using Kaggle datasets.
Karthika et al. [11] concentrated on early DR detection using a transformer network based on ResNet101 architecture. The proposed method outperformed state-of-the-art methods, achieving high accuracy, recall, and F1-measures of 99.8%, 99.4%, and 99.3%, respectively, showcasing its efficacy in DR classification. Gulati et al. [12] addressed the increasing prevalence of diabetes and its complications, focusing on early DR detection using DenseNet. They optimized hyperparameters such as batch size, learning rate, and epochs to classify DR into five stages, emphasizing the importance of early detection and treatment to prevent vision loss.
3. Methodology
The dataset used in this study was obtained from Kaggle [13] and comprises 3662 images depicting various severity levels of DR disease. For the purpose of simplification, the dataset was categorized into two classes: Positive and Negative. “Positive” denotes images containing DR, whereas “Negative” denotes images without DR. Using a binary classification of “Positive” (with DR) and “Negative” (without DR) simplifies the model, making it more efficient for screening purposes, addressing class imbalance, and reducing computational complexity, especially when data for intermediate stages is limited. Out of the dataset, 1857 images contain DR, while the remaining 1805 do not. This dataset is considered quite balanced because the difference in the number of images is not significant. Figure 1 displays several images from the dataset.
Hold-out validation method is used in this study to prevent overfitting. 60% of the total images are allocated to the training set, 20% to the validation set, and the remaining 20% to the testing set. Image augmentation is applied to the training set by horizontally and vertically flipping the images. Subsequently, both the training and validation sets are utilized to train the suggested model, referred to as EfficientNetV2 [14]. This model is chosen due to its extensive architecture and proven accuracy in detecting various diseases, alongside its recognized robustness by numerous researchers. Transfer learning was used to train the model because it gets better results compared to training the model from scratch. The model was originally trained from ImageNet, and transfer learning is implemented to re-train the model using the datasets obtained from this study.
EfficientNetV2 represents a significant advancement in convolutional neural network architectures, building upon its predecessor, EfficientNet. It introduces several key architectural elements and optimizations, with compound scaling being one of its fundamental principles. This strategy adjusts the network’s depth, width, and resolution simultaneously, ensuring efficient allocation of resources across different model sizes. Thus, it achieves robust performance across various computational budgets and hardware constraints.
The core of EfficientNetV2 comprises stem convolutional layers, which extract essential features from input data efficiently. Inverted residual blocks, inherited from their predecessor, reduce computational complexity while maintaining expressive power. Depthwise separable convolutions further enhance efficiency by decomposing standard convolutions into separate depthwise and pointwise operations, reducing computational cost and trainable parameters.
During network training, stochastic gradient descent with momentum and backpropagation updates the model weights. A batch size of 32 and a learning rate of 0.001 are utilized, with the binary cross-entropy loss function. A patience of 10 is set, meaning training halts automatically if validation loss doesn’t improve for 10 epochs. Following training, the model is evaluated on the testing set, calculating true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN) to determine accuracy, sensitivity, specificity, and precision.
EfficientNetV2’s performance is then compared to other deep learning models, including AlexNet [15], GoogleNet [16], ResNet18 [17], ResNet34 [17], ResNet50 [17], ResNet101 [17], and DenseNet121 [18]. The models were chosen for comparison because they have been widely used for DR detection. These models are trained and tested under identical conditions for a fair performance comparison. Figure 2 illustrates the flowchart of this study.
(a)
(b)
Fig. 1. Several images obtained from the dataset [13]. (a) Negative. (b) Positive.
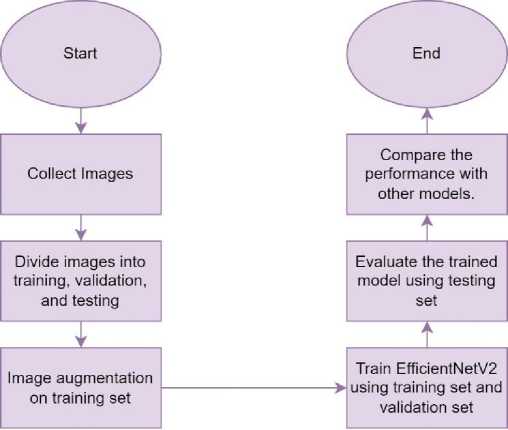
Fig. 2. The flowchart of this study.
4. Results and Discussions
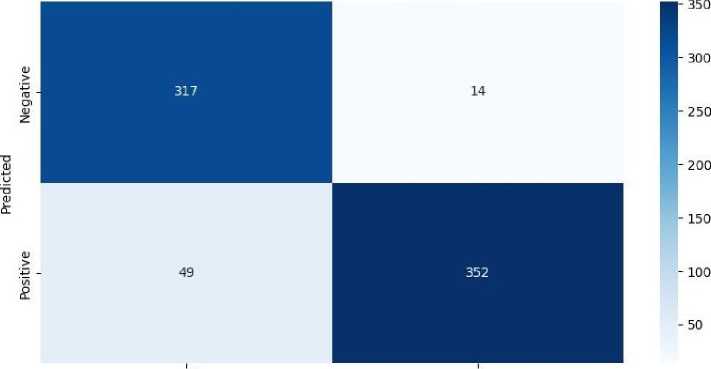
After testing EfficientNetV2 on the testing set, the number of TP, TN, FP, and FN is counted, and a confusion matrix is formed. This confusion matrix is used to calculate accuracy, sensitivity, specificity, and precision. Figure 3 shows the confusion matrix obtained from EfficientNetV2.
Confusion Matrix for EfficientNetV2
Negative Positive
True
Fig. 3. Confusion matrix obtained from EfficientNetV2.
TP means the model classifies the image as positive, and its ground truth is positive. TN means the model classifies the model as negative, and its ground truth is negative. FP means the model classifies the model as positive, but the ground truth is negative. FN means the model classify the image as negative, but the ground truth is positive. The results obtained from EfficientNetV2 are then compared with those obtained by other models. The performance metrics used for this comparison include accuracy, sensitivity, specificity, and precision. Additionally, the Receiver Operating Characteristic (ROC) curve is utilized for performance evaluation. Table 1 presents the performance metrics obtained from various deep learning models, while Figure 4 illustrates the ROC curve of each model.
Table 1. Results obtained from various models tested on the testing set, with the best results highlighted in bold.
|
Model |
Accuracy |
Sensitivity |
Specificity |
Precision |
AUC |
|
Arias-Serrano et al. [6] using AlexNet |
0.7855 |
0.8770 |
0.6940 |
0.7413 |
0.8828 |
|
Shi et al. [7] using GoogleNet |
0.7923 |
0.9098 |
0.6749 |
0.7367 |
0.9168 |
|
Junjun et al. [8] using ResNet18 |
0.8579 |
0.9426 |
0.7732 |
0.8061 |
0.9539 |
|
Al-Moosawi et al. [9] using ResNet34 |
0.8730 |
0.9208 |
0.8251 |
0.8404 |
0.9546 |
|
Lin et al. [10] using ResNet50 |
0.8716 |
0.9563 |
0.7869 |
0.8178 |
0.9706 |
|
Karthika et al. [11] using ResNet101 |
0.9003 |
0.9426 |
0.8579 |
0.8690 |
0.979 |
|
Gulati et al. [12] using DenseNet121 |
0.9221 |
0.9262 |
0.9180 |
0.9187 |
0.9807 |
|
Proposed Method (EfficientNetV2) |
0.9139 |
0.9617 |
0.8661 |
0.8778 |
0.9816 |
Among the models assessed, EfficientNetV2 emerged as a compelling candidate, showcasing competitive performance across multiple evaluation criteria. EfficientNetV2 achieved an accuracy of 91.39%, positioning it favorably against established architectures like AlexNet, GoogleNet, ResNet series, and DenseNet121. Although DenseNet121 exhibited slightly higher accuracy, EfficientNetV2’s performance remained impressive, especially considering its sensitivity.
Sensitivity emerges as the most critical performance metric due to the nature of medical image classification tasks, where missed positive detections carry more significant consequences than missed negative detections. A false negative, representing a missed positive detection, could result in delayed diagnosis or treatment, potentially impacting patient outcomes adversely. Therefore, prioritizing sensitivity ensures a higher likelihood of correctly identifying positive instances, thereby minimizing the risk of false negatives.
In terms of sensitivity, EfficientNetV2 outperformed all other models, achieving a sensitivity of 96.17%. Sensitivity is a crucial metric in medical image classification, as it indicates the model ’s ability to correctly identify positive instances, minimizing false negatives. The high sensitivity of EfficientNetV2 suggests its effectiveness in detecting relevant features indicative of pathological conditions in medical images.
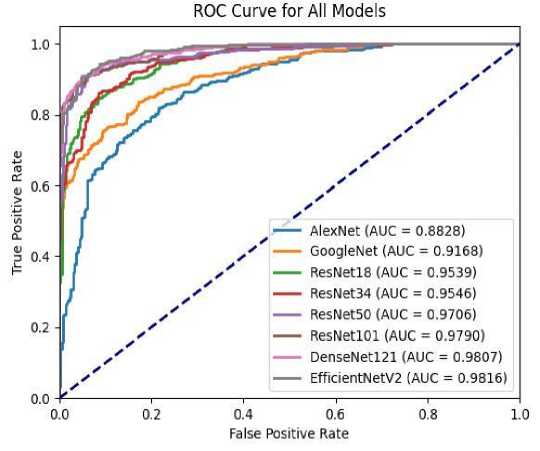
Fig. 4. ROC Curve for all models.
Moreover, EfficientNetV2 demonstrated a specificity of 86.61%, indicating its capacity to accurately identify negative instances, thus reducing false positives. While not the highest among the models evaluated, its specificity remains competitive, showcasing a balanced performance in distinguishing between positive and negative instances.
Precision, another vital metric in medical image classification, measures the proportion of correctly predicted positive cases out of all instances classified as positive by the model. EfficientNetV2 achieved a precision of 87.78%, indicating its ability to minimize false positives while maximizing true positives. This balanced precision is crucial in medical settings, where erroneous diagnoses can have significant consequences.
Furthermore, the AUC, which provides an aggregate measure of a model’s discrimination ability across different classification thresholds, was highest for EfficientNetV2 at 98.16%. A high AUC value indicates superior overall performance in distinguishing between positive and negative instances, further affirming the effectiveness of EfficientNetV2 in medical image classification tasks.
5. Conclusions
In summary, this study explored the effectiveness of EfficientNetV2 in DR detection, highlighting its competitive performance compared to established deep learning models. EfficientNetV2 exhibited superior sensitivity which is essential for accurately identifying DR cases while minimizing false negatives. The high AUC further confirmed its robust discriminatory ability. These findings suggest EfficientNetV2 ’s potential as a valuable tool for healthcare professionals in diagnosing DR, with broader implications for medical image analysis tasks. This study contributes to the field of DR detection by investigating an unexplored model called EfficientNetV2. Future research could focus on fine-tuning the model for specific clinical contexts and validating its real-world effectiveness through large-scale clinical trials.
Conflict of Interest
The authors declare no conflict of interest.
Acknowledgment
This study is supported and funded by the University of Technology Sarawak (UTS) under the UTS Research Grant (URG), research ID (UTS/RESEARCH/4/2023/08).
References Transfer Learning with EfficientNetV2 for Diabetic Retinopathy Detection
- M. C. S. Tang, S. S. Teoh, H. Ibrahim, and Z. Embong, “A deep learning approach for the detection of neovascularization in fundus images using transfer learning,” IEEE Access, vol. 10, pp. 20247–20258, 2022, doi: 10.1109/ACCESS.2022.3151644.
- M. C. S. Tang, S. S. Teoh, H. Ibrahim, and Z. Embong, “Neovascularization detection and localization in fundus images using deep learning,” Sensors, vol. 21, no. 16, p. 5327, Aug. 2021, doi: 10.3390/s21165327.
- M. C. S. Tang, S. S. Teoh, and H. Ibrahim, “Retinal vessel segmentation from fundus images using DeepLabv3+,” in 2022 IEEE 18th International Colloquium on Signal Processing & Applications (CSPA), May 2022, pp. 377–381. doi: 10.1109/CSPA55076.2022.9781891.
- M. C. S. Tang and S. S. Teoh, “Blood vessel segmentation in fundus images using hessian matrix for diabetic retinopathy detection,” in 2020 11th IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Nov. 2020, pp. 0728–0733. doi: 10.1109/IEMCON51383.2020.9284931.
- M. C. S. Tang and S. S. Teoh, “Brain Tumor Detection from MRI Images Based on ResNet18,” in 2023 6th International Conference on Information Systems and Computer Networks (ISCON), Mar. 2023, pp. 1–5. doi: 10.1109/ISCON57294.2023.10112025.
- I. Arias-Serrano et al., “Artificial intelligence based glaucoma and diabetic retinopathy detection using MATLAB — retrained AlexNet convolutional neural network,” F1000Research, vol. 12, p. 14, Jan. 2023, doi: 10.12688/f1000research.122288.1.
- B. Shi et al., “GoogLeNet-based Diabetic-retinopathy-detection,” in 2022 14th International Conference on Advanced Computational Intelligence (ICACI), Jul. 2022, pp. 246–249. doi: 10.1109/ICACI55529.2022.9837677.
- P. Junjun, Y. Zhifan, S. Dong, and Q. Hong, “Diabetic Retinopathy Detection Based on Deep Convolutional Neural Networks for Localization of Discriminative Regions,” in Proceedings - 8th International Conference on Virtual Reality and Visualization, ICVRV 2018, Oct. 2018, pp. 46–52. doi: 10.1109/ICVRV.2018.00016.
- N. M. A.-M. M. Al-Moosawi and R. S. Khudeyer, “ResNet-34/DR: A Residual Convolutional Neural Network for the Diagnosis of Diabetic Retinopathy,” Informatica, vol. 45, no. 7, pp. 115–124, Dec. 2021, doi: 10.31449/inf.v45i7.3774.
- C.-L. Lin and K.-C. Wu, “Development of revised ResNet-50 for diabetic retinopathy detection,” BMC Bioinformatics, vol. 24, no. 1, p. 157, Apr. 2023, doi: 10.1186/s12859-023-05293-1.
- S. Karthika and M. Durgadevi, “Improved ResNet_101 assisted attentional global transformer network for automated detection and classification of diabetic retinopathy disease,” Biomed. Signal Process. Control, vol. 88, p. 105674, Feb. 2024, doi: 10.1016/j.bspc.2023.105674.
- S. Gulati, K. Guleria, and N. Goyal, “Classification of Diabetic Retinopathy using pre-trained Deep Learning Model- DenseNet 121,” in 2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT), Jul. 2023, pp. 1–6. doi: 10.1109/ICCCNT56998.2023.10308181.
- S. R. Rath, “Diabetic Retinopathy 224x224 (2019 Data),” 2020. https://www.kaggle.com/datasets/sovitrath/diabetic-retinopathy-224x224-2019-data (accessed Feb. 02, 2024).
- M. Tan and Q. V. Le, “EfficientNetV2: Smaller Models and Faster Training,” Proc. Mach. Learn. Res., vol. 139, pp. 10096–10106, 2021.
- A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” Commun. ACM, vol. 60, no. 6, pp. 84–90, May 2017, doi: 10.1145/3065386.
- C. Szegedy et al., “Going deeper with convolutions,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2015, vol. 07-12-June, pp. 1–9. doi: 10.1109/CVPR.2015.7298594.
- K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2016, vol. 2016-Decem, pp. 770–778. doi: 10.1109/CVPR.2016.90.
- G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jul. 2017, vol. 2017-Janua, pp. 2261–2269. doi: 10.1109/CVPR.2017.243.
