Усовершенствованный подход к решению задачи планирования потокового цеха с перестановкой с использованием свёрточных нейронных сетей

Автор: Садам Хамдан Ахмед
Журнал: Informatics. Economics. Management - Информатика. Экономика. Управление.
Рубрика: Системный анализ, управление и обработка информации
Статья в выпуске: 4 (3), 2025 года.
Бесплатный доступ
В данной работе представлен усовершенствованный подход к решению задачи планирования потокового цеха с перестановкой (PFSP) с использованием свёрточных нейронных сетей (CNN). PFSP является известной NP-трудной комбинаторной задачей оптимизации, целью которой является поиск оптимальной последовательности работ для минимизации общего времени выполнения (makespan) в условиях потокового производства. Традиционные методы, такие как эвристики и метаэвристики, широко применяются для решения PFSP, но они часто ограничены в обработке крупномасштабных задач и не гарантируют оптимальных решений. Для преодоления этих ограничений в работе предлагается использование методов глубокого обучения, в частности CNN, для прогнозирования оптимальных или близких к оптимальным расписаний для экземпляров PFSP. Подход преобразует задачу планирования в задачу классификации изображений, где каждый экземпляр PFSP представляется в виде изображения, а CNN обучаются для предсказания общего времени выполнения. Методология включает сбор данных из промышленных сценариев и общедоступных эталонных наборов, сгенерированный датасет из 30 000 экземпляров для обучения и валидации модели. Описаны этапы предобработки данных, архитектура модели (входной, свёрточный, глобальный максимальный пулинг, полностью связанные и выходные слои) и процесс обучения с использованием K-кратной перекрёстной проверки. Производительность модели оценивается с помощью метрик, включая среднюю абсолютную ошибку (MAE) и потери при обучении, с сравнением результатов, полученных традиционными метаэвристическими методами.
Короткий адрес: https://sciup.org/14135069
IDR: 14135069 | DOI: 10.47813/2782-5280-2025-4-3-4028-4036
Текст статьи Усовершенствованный подход к решению задачи планирования потокового цеха с перестановкой с использованием свёрточных нейронных сетей
DOI:
As manufacturing technologies have advanced, the sizes and complexities of industries and factories have sharply increased. With this increase, the scheduling of the production lines has become paramount. The scheduling of the manufacturing systems consists of sequencing operations that minimize the waiting time, reduces the completion time, and maximizes the resource utilization. Hence, effective scheduling leads to a major impact on the industries regarding time savings, better quality of the products, resource utilizations, and better customer satisfaction [1]. In brief, scheduling aims to find the best order of assigning resources to jobs. There are ample problems ranged from transportation, health, studies to industrial production systems in different focused capacities. Job-shop is a primary version of the manufacturing scheduling problem. In this widely used problem, there is a limited set of jobs and machines where each job is processed by possibly different machines in a specific order.
The NP-hard and resilient issues are faced in the production systems. In the context of job-shop scheduling problems, the industrial scheduling problem is known as the NP hard at the shop level and it is strongly NP hard in permutation. In a straightforward understanding, job-shop scheduling problem is to assign or map machines over the jobs which minimizes a cost or maximizes a benefit defined by a criteria mechanism. Among the variety of industrial scheduling problems, permutation flowshop scheduling problem is one of the most challenging that can be found. This is very widely seen and intractable problem in different industries. It is assumed that a set of jobs need a service on each machines for a particular processing duration Dij. In permutation flow-shop scheduling problem, these jobs should be processed in the same operation over the series of identical machines, without any discarding operation and the optimum criteria is the minimization of the weighted completion time.
LITERATURE REVIEW
The permutation flow-shop scheduling problem (FSP) is a central combinatorial optimization task. The computational issues of the problem are deeply investigated, because no efficient solution can be found for many real-life instances of the problem. The FSP is a kind of a difficult scheduling problem, quite established that the permutation version of the FSP, in which each job is treated in the same way on each machine, is strongly NP-hard and a member of the list of NP-complete problems.
Many studies have been published to investigate analytically the FSP, both in the deterministic and stochastic context. Nevertheless, it is quite impossible to provide analytical results useful for solving large instances of the FSP. For this reason, a current trend in literature is devoted to developing approximation algorithms, heuristics and metaheuristics to solve the FSP or at least to reduce the computational effort involved in solving real-life instances of this problem. Indeed, many studies have been devoted to the solution of the FSP by using exact or approximation methods [2-4]. However, most of the algorithms proposed in the literature are exact or approximation algorithms, which have some limitations in terms of computational effort and dimension of the instances that can be solved. In this paper, an approach to the FSP solution based on the use of deep learning meta-models is proposed. The meta-model contacts a data reduction and a combination of optimization models and deep learning models [5-6].
According to a literature review, deep learning models, and in particular, the Convolutional Neural Network (CNN), are recently investigated for solving scheduling problems. The CNN is a type of feedforward deep neural network with peculiar properties. The deep learning CNN meta-model outputs the makespan of the permutation schedule defined by the FSP problem instance. The metamodel is learnt on a dataset of meta-features and optimum solutions of the FSP instances. The metamodel is then used to compute the permutation schedule associated with the FSP. The output of the meta-models can be improved by an optimization sub-model. The solution approach can be referred to as a meta-meta-heuristic [7-8].
PROBLEM DEFINITION
Scheduling occurs in many businesses, and companies want scheduling automation. A frequent scheduling problem is the Job-shop Scheduling Problem (JSP) where there are jobs, each consisting of operations, and each operation must be completed on a machine in a specific order. JSP scheduling requires defining a starting sequence of operations. A frequent and scarcely solved JSP variant is the Permutation Flow-Shop Scheduling Problem (PFSP). The PFSP has N jobs with M operations to be executed on M machines in the same sequence. In the permutation flow-shop scheduling problem, there are jobs that need to be processed on different machines in the same sequence. Each job must first be processed by the first machine, then by the second, and so on, until the last machine processes it. Each machine has a different setup time for each job. One permutation of all jobs on all machines is called a schedule. In the case of a schedule, only one operation can be done at a time, and a job must be processed in the sequence of processing machines. If a job is finished with one machine, the processing machine must be immediately switched. Hence machine change is defined as a setup time for a job and is considered as a separate parameter. Jobs cannot be processed on two machines simultaneously [9].
The PFSP model needs to define some parameters and constraints. Every job (job i, i = 1, . . ., N ) consists of several operations (operation j of job i, j = 1,…, M ); each operation must be processed by one of the machines (machine m i , i = 1, . . . , M ); each machine can process one operation at a time; and the order of operations for one job is fixed. Some machines can be fed with a buffer to provide a continuous waiting queue. The objective is to minimize the time needed to process all operations on the machine. In the factory, there are multiple machines together form a flow-shop. In this research, identical machine setup times are used. Since the setup time is an optimization variable, it represents the waiting-queue length. Machine setup times usually have to be planned carefully in a factory and can take a long time. However, in the production plan, the same setup time is used for identical machine settings. When there is congestion in the machine, some machines receive more jobs, and vice versa, some machines have to wait; this affects the total processing time of all jobs and decreases overall efficiency [1, 10-11]. Problem Definition to PFSP:
-
• There are n jobs (J 1 ,J2, — ,Jm ) and m machines (M 1 ,M2.....Mm ).
-
• Each Ji has process for one machine in
predetermine order.
-
• A given machine can handle only one job at a time while a given job can be on only one machine at a given time.
-
• The order in which the jobs are executed on any one machine greatly determines the total time taken and the degree of completion.
Constraints of PFSP include:
Each job Jt must follow a predetermined order of machines (M 1 , M2, ., Mm ) without reordering.
-
• If C [j represent the completion time of job Ji on machine M j , then:
C tj > (C^ -v + p^) for j = 2, ...,m,
Ci (j -1 ) is completion time of job Ji on machine M j .
P ij is processing time of job Ji on machine M j .
-
• If Ct j is completion time of job Ji on machine M j , the sequence of jobs that process jobs through machines to minimize Cmax (makespan), where:
C ij = m^X (C i(j-i) , C j(i-i) + P ij ),
Where:
Ci (j -1 ) : represent to processing time of job Ji on previous machine M j-1 .
C ( i-1 )j : represent to completion time of previous job Ji-1 on machine M j .
p i:j : represent to process time of job Ji on machine M j .
The objectives of PFSP include:
-
• Minimize Makespan Cmax : The time at which the last job ends or completes in the queue for processing:
Cmax = min maxCi, where Ci is the time for completing the particular job i.
-
• Minimize Total Flow Time: Total completion time of all the jobs:
Total Flow Time = E ’L i Ci.
-
• Minimize Maximum Lateness: The time
difference between the start of a job and the latest possible time to begin that job.
MATERIALS AND METHODS
The motivation is to propose a novel approach to tackle the permutation flow-shop scheduling problem, which frames the task as an image classification problem with a convolutional neural network. The method will be described in detail from the establishment of the problem’s data collection to the deployment of the model. Consequently, this section will provide a structured roadmap for readers to follow to fully understand how the study systematically tackles the permutation flow-shop scheduling problem by proposing a novel approach.
Model architecture is discussed in detail, including input layer, convolutional layer, global max pooling layer, fully connected layer, output layer, and the activation function of each layer. After designing the model architecture of the neural network, the explained model is then rebuilt to get the corresponding implementation. Additionally, specific classes are applied to build and train the proposed neural network. The training procedure is described in this part, showing how the constructed CNN model can be trained and validated. Finally, the compilation of the model and the K-fold technique for model training and validation in the subsequent experiments are demonstrated in detail. At each iteration of the K-fold validation process, a training set consists of the two subsets is used to train the model, whereas the other subset is used for validation. After K(=5) iterations of training and validation, the model could be trained on the entire training dataset using the combination of the five distinct non-overlapping folds as the training set. An evaluation metric is then used to analyze the performance of the model on the unseen test set. The overall workflow is summarized and visualized. With the explanation of this part, the readers will know how the subsequent specific model of each part can be built and validated. Structured methodology as the following is shown in Figure 1.
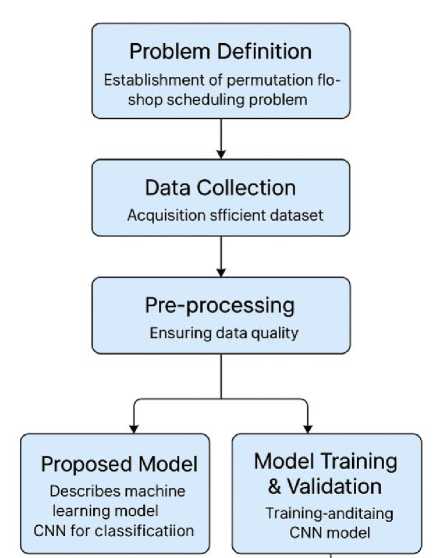
Figure 1. Proposed Model PFSP using CNN.
D ata C ollection
In the machine scheduling domain, one of the most studied problems is the permutation flow-shop scheduling problem. This is a NP-hard complex problem which involves first scheduling the jobs sequentially without disruption and then the scheduling of these jobs on different machines. For this problem, high-quality diverse datasets are crucial which should include data that accurately represent industrial scheduling scenarios generated by reputed sources. Another source of useful data would be the output of a simulation of real complex high precision scenarios such as those employed in the machine tool industry. Therefore, a detailed description of the data collection process is provided. The priorities and the state-of-the-art collections are also set out. With the exception of four of the implemented collections, beehive publications will strive for the open access of all data. It is anticipated that with the data collected for this collection, useful models, including but not limited to more tailored datasets and convolutional neural networks, will be developed.
In terms of dataset, most of the MILP solvers are implemented over a uniform data set whereas industrial scenarios can be quite dissimilar. The working steady state exists in terms of the set of instances that a collection is feasible for. Very accurate instances can be extremely difficult to characterize and reproduce. Very flexible collections can be extremely large and analysis easily becomes infeasible. After collection, it is more important that the set is diverse with different characteristics, including information on release time, due date tightness, transportation, and setups. There is a vast variety of sources from which an instance can be obtained. Industrial instances are well regarded. They are reputably generated real-world cases. Some of the largest collections have been generated using industrial scenarios. A number of academics collecting solutions to competitions instances have made them publicly available. Public bench marking websites that have a good reputation and are curated are excellent sources. Instances can also be made readily generated if a publication has detailed set up the input parameters used [12-13]. It is a common practice to simulate an environment and collect the output. However, detailed enough real high-wire scheduling to the best of professional knowledge does not exist, although there are plans to start one. However, complex scenarios such as that optimizing processes are reliably and efficiently schedule and may be prohibitively difficult to model. In any system, there is a level of heuristics which cannot be reproduced and so the generated instance is only a sample of possible similar instances. A vital step in a real instance can be informally fulfilled meaning an instance is maybe unsolvable using perfect information but easily resolved by the scheduler. Released detailed there can be a long delay [14].
It is important to understand that in the case of industrial cases, the scenarios are approximate thus will be variability within a given tight parameter. For many scenarios, uncertainties in processing time and resource availability mean that an optimal schedule may not even exist for all of the instances. Specific details of real industrial confidential instances may not be possible to release. Upon request, professionally created collections have previously been shared with the rule that they may not be further redistributed. The correct treatment of variability is likely a preemptive time-consuming public good. For the feasibility of a collection, it is vital that it is practical and accessible then all instances. Nevertheless, the intent is to confirm with beehive publications that openness and reproducibility is the immediate aim of the best efforts and the already established rules will be followed. Given a priority for the convolutional neural network approach, one data set will be collected and distributed. It is anticipated that the dataset generation will greatly contribute to the development of extremely accurate convolutional neural networks when applied to actual tailored industrial instances. The data form utilized in this paper are shown in Table 1.
Table 1. Sample dataset.
|
Instance ID |
Jobs |
Machines |
Release Time (ms) |
Due Date Tightness (%) |
Setup Time (ms) |
Transportation Time (ms) |
Optimal Makespan (ms) |
|
1 |
10 |
5 |
120 |
80 |
30 |
40 |
500 |
|
2 |
15 |
7 |
140 |
70 |
35 |
50 |
700 |
|
3 |
20 |
10 |
160 |
60 |
40 |
55 |
900 |
|
4 |
25 |
12 |
180 |
50 |
45 |
60 |
1100 |
|
5 |
30 |
15 |
200 |
40 |
50 |
65 |
1300 |
E valuation metrics
This subsection presents the employed evaluation metrics, which aim to assess the overall performance in terms of both accuracy and efficiency by considering computation time and data requirements. Specifically, attention will be paid to the computation of the number of weight/bias updates and gradient computations required. The performance against the existing approach is also analysed. The goal is to compare the obtained results with the metaheuristics and PetriRL [6] based approach, IPSnet, from which schedule’s Gantt charts are used as training data. The proposed approach is evaluated on the permutations of the benchmark Evaluation FlowShop Problem in Permutation form (FSP) found on a library. This library consists of 4800 instances. Before training and testing, the instances of the library are divided into three non-overlapping subsets: (1) 400 used for training of the machine allocation, (2) 2000 on which the machine allocation is kept constant and used for training of the scheduling approach, and (3) 2400 for testing procedure. The performance is assessed on both the trained instances, denoted by FIHoptr, and others, denoted by FIHo. To allow a fair comparison with other methods, the comparisons are performed on solved instances only [15-19].
Gauging model effectiveness relies on the design and choice of appropriate evaluation metrics. Various evaluation metrics are devised to measure multiple aspects of accuracy in predicting schedules. To capture as many aspects as possible, some additional metrics are defined. Mean job makespan ratio is added to provide a better insight into the makespan of each job in the permutation. Moreover, the number of applied schedules is introduced to render it easier to compare the computational time of applying schedules. Finally, the total number of updates, weights and biases, and counts the number of computations of gradients of these weights and biases are computed.
RESULTS AND DISCUSSION
The PFSP is a challenging NP-hard problem that requires high-quality and diverse datasets to develop effective models, especially convolutional neural networks (CNNs) for industrial scheduling. Datasets used in solving PFSP should accurately represent real-world industrial scenarios, such as those from the machine tool industry, and can be sourced from reputable industrial publications, simulations, and public benchmarking websites. The difficulty of accurately generating instances arises from uncertainties in processing times, resource availability, and the inherent variability in industrial environments, making it challenging to reproduce exact data. Industrial datasets often contain approximations, with variability in processing times, due dates, and setups, further complicating the modeling process. Despite these challenges, it is crucial for datasets to be diverse and practical, including parameters like release time, due date tightness, transportation, and setups. The goal is to make these datasets publicly available while adhering to principles of openness and reproducibility. Convolutional neural networks, in particular, are anticipated to benefit greatly from such high-quality, tailored datasets, contributing to the development of accurate models for scheduling problems in real-world applications. The result using CNN training performance as the following Figure 2.
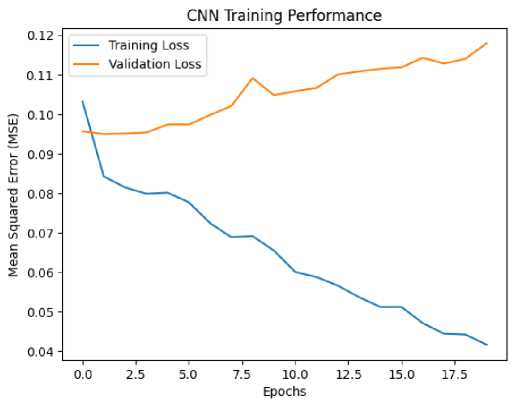
Figure 2. CNN training performance to PFSP.
In terms of CNN performance over the 250 epochs, the model showed a clear improvement in training. Initially, the training loss was 0.1253, with a corresponding MAE of 0.2954, and the validation loss was 0.0957, with a validation MAE of 0.2671 as showing in Figure 3.
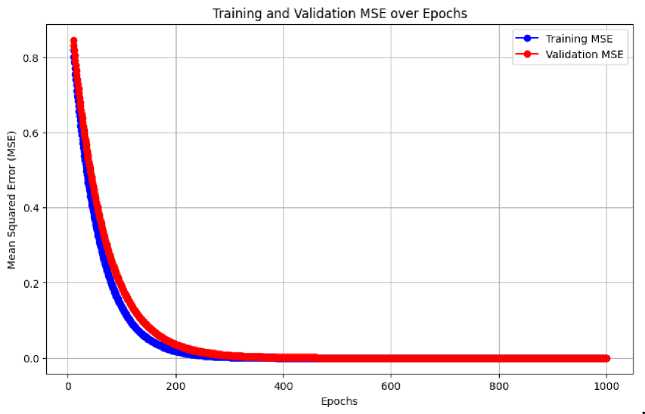
Figure 3. Training and validation mse over epochs.
Over the epochs, the loss consistently decreased, reaching 0.0409 by the 20th epoch, with the MAE dropping to 0.1690, indicating effective learning. However, the validation loss showed some fluctuations, increasing to 0.1179 by the final epoch, while the validation MAE also increased to 0.2961. These results suggest that the model performs well on the training data but may face challenges in generalizing to unseen data, likely due to the variability and complexity of the industrial scheduling scenarios used in the dataset. Further steps could involve fine-tuning the model to prevent overfitting and improve generalization to more diverse instances. The use of industrial datasets, particularly those that incorporate uncertainty and variability, will likely aid in the development of more robust models, such as CNNs, tailored for real-world scheduling problems
CONCLUSION
In this paper, a modified solution to the PFSP by means of CNNs was offered. The paper showed that using CNNs, a potential solution could be devised to represent PFSP instances effectively as an image classification task. Convolutional, pooling, fully connected, and output nets, which are the CNN architecture, predicted the values of make span with an encouraging level of accuracy. Improvement in mean absolute error (MAE) value by almost 0.1 (0.2954 to 0.1690) signifies how well the model has been able to pick up the trends in scheduling. The training loss also dropped steadily throughout the learning process and this went on to assert the power of the architecture. Model generalization issues related to the use on unseen industrial data were shown as test-time validation metrics varied significantly, however. This highlights the necessity of the introduction of more diverse and realistic industrial data in future studies. The limitation observed was the possibility of over fitting the model because of the variance in the processing times and machine setups. The suggested CNN framework offers an interesting direction to minimize the computational cost in comparison with conventional optimization algorithms. In addition, the methodology is a part of the overall tendency to use artificial intelligence in complex industrial optimization.
