Utilizing RoBERTa Model for Churn Prediction through Clustered Contextual Conversation Opinion Mining

Author: Ayodeji O. J. Ibitoye, Olufade F.W. Onifade
Journal: International Journal of Intelligent Systems and Applications @ijisa
Article in issue: 6 vol.15, 2023.
Free access
In computational study and automatic recognition of opinions in free texts, certain words in sentences are used to decide its sentiments. While analysing each customer’s opinion per time in churn management will be effective for personalised recommendations. Oftentimes, the opinion is not sufficient for contextualised content mining. While personalised recommendations are time consuming, it also does not provide complete picture of an overall sentiment in the business community of customers. To help businesses identify widespread issues affecting a large segment of their customers towards engendering patterns and trends of different customer churn behaviour, here, we developed a clustered contextualised conversation as opinions set for integration with Roberta Model. The developed churn behavioural opinion clusters disambiguated short messages while charactering contents collectively based on context beyond keyword-based sentiment matching for effective mining. Based on the predicted opinion threshold, customer churn category for group-based personalised decision support was generated, with matching concepts. The baseline RoBERTa model on the contextually clustered opinions, trained with a batch size of 16, a learning rate of 2e-5, over 8 epochs, using a maximum sequence length of 128 and standard hyperparameters, achieved an accuracy of 92%, Precision of 88%, Recall of 86% and F1 score of 84% over a test set of 30%.
Churn Prediction, Opinion Mining, Roberta Model, Customer Relationship Management, Decision Support
Short address: https://sciup.org/15019016
IDR: 15019016 | DOI: 10.5815/ijisa.2023.06.01
Text of the scientific article Utilizing RoBERTa Model for Churn Prediction through Clustered Contextual Conversation Opinion Mining
Published Online on December 8, 2023 by MECS Press
In the social media era, businesses face unique challenges and opportunities in staying competitive. Twitter as a microblogging site among others like Facebook; allow users to express their opinion(s) about their personal life, products and services [1]. Although transactions themselves are not solely determined through social media. The digital media assumes a vital role in the marketing and promotion of products or services has a prominent marketplace [2]. These platforms have transformed the way companies interact with customers and the public, providing unprecedented avenues for marketing, customer engagement, and brand building. Churn prediction as a process of identifying customers with increasing chances of leaving or "churning" from a company's products or services has taking on added complexity due to the dynamic nature of customer behaviour on these platforms [3]. Since customers represent a vital cornerstone within an enterprise, they also bear significant influence over the market competitiveness and overall performance of the company. As one of the most valuable assets, customers play a pivotal role in driving success and growth for the business [4] especially by what they say in responding to company’s brand activities on the social media. In predictive customer service, especially when finding important social media conversations in churn management, certain expression to look out for may include but not limited to a customer reporting a possible service issue, making a feature request, angry or happy about a product or service, or asking specific question. These opinions travel as fast as possible, are seen from different customer perspectives, and can contribute aggressively to customer churn or retention in the business community. Opinion mining now adds a layer of customer perception and understanding to churn prediction. This enables businesses to proactively address customer concerns towards enhancing customer retention efforts. In more recent times, goal driven organisations have become active users of the social media for the purpose of providing consistent engagement and proactive response to client while defending their brand [5]. However, the process of mining these opinions goes a long well in determining an effective result in customer relationship management. Should customers opinion be mined independently? How important is collective opinion mining in customers behavioural recognition for targeted decision support? Sample existing works in customer management [6-9] used keyword approach to analyses individual sentences in isolation. Basic keyword driven sentiment analysis approach may lead to a lack of context, oversimplification of sentiment, misclassification of polarity, and amplification of extreme opinions. First, the research exploration of opinion mining, went beyond mere use of keywords in isolated sentences into clustering conversations collectively based on context and semantics to effectively categorise customer behaviour. Then the contextually clustered opinions were integrated with RoBERTa model to provide a group-based decision support model for customer churn management based on obtained opinion polarity from five (5) output labels, the goal is to boost the model's accuracy while also increasing the churn prediction class of customers from binary to quadruple if every single client has the chance to leave one service provider for the other. In section two, research motivation with related works is presented. A description of the research methodology is discussed in section three before sample results from model experiments and evaluation are showcased in section four. The research is concluded in five with an insight into future work.
2. Literature Review
In fiercely competitive markets, customer churn can have a profound effect on a company's income and market share. For instance, in telecommunication and banks, customer retention is crucial for sustainable growth [10]. Churn prediction plays a pivotal role in identifying such customers with the likelihood of leaving, while allowing businesses to apply targeted retention tactics [11]. By intervening before customers switch to competitors, businesses can foster brand loyalty and maintain a competitive edge. Over the years, traditional churn prediction methods often fall short in capturing the complexity of customer behaviour. Machine learning [12-13], on the other hand, offers a data-driven and sophisticated approach to churn prediction. Leveraging enormous amounts of customer data, machine learning algorithms can easily detect patterns and trends that human analysts may overlook. Although, churn prediction has traditionally relied on quantitative metrics such as customer transaction history and engagement patterns. While these data points are crucial, they may not fully capture the emotional aspects of customer behaviour. Hence, opinion mining offers a complementary approach by unlocking the sentiment behind customer interactions. To this end, [14] explored the application of opinion mining techniques for churn prediction in various industries by extracting customer opinions from textual data, such as reviews and social media posts before analysing with different machine learning algorithms for churn prediction based on sentiment features, including logistic regression, support vector machines, and neural networks. Similarly, [15] review examines the use of natural language processing algorithms, topic modelling, and emotion analysis to extract valuable insights from customer feedback and textual data. A further analysis in the research showed how sentiment features are incorporated into machine learning models, such as random forests, gradient boosting, and deep learning. [16] demonstrated how the interdependent relationship between headwords and their corresponding tail equivalents in a sentence can be harnessed to maintain the contextual essence of an expression in the realm of opinion mining and these classifications were used for customer’s churn categorization. While, [17] examined how these extracted sentiments are integrated into churn prediction models, such as decision trees, ensemble methods, and neural networks and highlighting the potential of social media data in capturing real-time customer sentiments, [18] attention on churn prediction through opinion mining focuses on using a combination of opinion mining and topic modelling techniques such as Latent Dirichlet Allocation (LDA) and Non-negative Matrix Factorization (NMF), to identify relevant topics from customer feedback. [19] compared the performances of traditional sentiment analysis methods, lexicon-based approaches, and machine learning-based sentiment classification algorithms for customer churn prediction. Just as Support Vector Machine was employed by [20] to perform contextual opinion mining in Online Odia Text, [21] investigated contextual variables and their impact on box-office revenue by using a framework, which combined sentiment analysis and machine learning methodologies on consumer reviews.[22] examined the mechanism behind contextual advertising, which leverages on opinions regarding a particular topic that is embedded within webpage content. By taking advantages of both sequence and transformer model, [23] built a model for sentiment analysis. To increase the accuracy of aspect sentiment classifier, [24] integrated part-of speech embedding, dependency for enhanced aspect extractor performance while the concept of syntactic relative distance was used to mitigate the impact of unrelated words in sentiment analysis. Similarly, to mitigate the challenges associated with domain-dependency in text mining, [25] tackled the problem by employing a resourceintensive process of manual data labeling to constructing a context-driven unsupervised ensemble learning approach tailored for sentiment analysis. In the bid to model customer’s contextual expectations, [26] integrated the Benefits Language theory with a fusion of two powerful methods: probabilistic Latent Dirichlet Allocation (LDA) and Linear Algebra-based Latent Semantic Analysis (LSA). This innovative approach created a Contextual Expectations Dictionary, which plays a crucial role in shaping customers' contextual expectations. Once a customer’s expectations are known, the potential to churn can easily be tracked. However, with customers talking in seconds, varieties of data now exist about different brands from different sources at different time intervals for different purposes. Analysing a single tweet per time may not produce a bird view report required in business intelligence. Hence, a collective analysis of opinions in differently defined context is required for targeted decision support. This improved approach is presented in section three alongside its integration with RoBERTa Model for opinion mining towards customer churn classification.
3. Research Methodology
Traditional sentiment analysis models often classify the overall sentiment of a document or sentence as positive, negative, or neutral without considering the context or specific entities mentioned. However, real-world texts frequently contain multiple aspects or entities, each with its associated sentiment. In the first phase of our methodology, we employ advanced techniques for contextual opinion clustering. This step involves identifying and grouping opinions that share the same context or refer to the same aspect or entity. These clusters provide a more granular understanding of sentiment within a text, enabling us to analyze sentiments toward specific aspects or entities independently. Thus, the core of our methodology lies in the integration of these contextually clustered opinions with RoBERTa, a powerful contextual language model. First, the Contextually Clustered Opinion Mining (CCOM) as a semi-supervised fuzzy contextual semantic model was built to determine customer tweets churn score while extracting knowledgeable facts that informed the churn score. It handles uncertainty and learn from the training data wherein each tweet or post is a vector space that is linked to the lexical database for essential analysis, since tweets are fine-grained and relatively precise. The logic of the development is guided by the definitions below:
Definition 1: An expression E, a clustered conversation Cet is an associative group of expressions that are contextually and sequentially related over a time space tf
Definition 2:
Given an expression E, the social context
Set
of a clustered conversation is defined as
Definition 3: Given an expression E, the semantic relationship SMrt between clustered conversations is the cosine relationship amid a set of tweets after extracting the features using the term frequency-inverse document frequency (tf-idf) of each tweet as a vector space over a period of time tf.
Definition 4: Given an expression E, the behaviour №t is the Sentiment and Word Order Contextual Semantics (WOCS) of the tweets in extracting churn concepts and determining tweet churn score.
From definitions 1 to 4, the technique employed changed from the ordinary usage of keywords and the co-occurrence count of word. It relatively relies on the inherent structures that is associated with the concepts of natural language, and relationship among social users. It mine concepts that carries the meaning articulated through text while using inference rules to find the most probable meanings of the concepts given some evidence., CCOM can spot sentiments, which are subtly conveyed although not obviously but are interrelated to other concepts implicitly. The essence of this technique as presented in Fig 1 is to develop an approach that can discover collective customer behaviour through expression mining by generating scores and extracting knowledgeable insights towards a better customer relationship management.
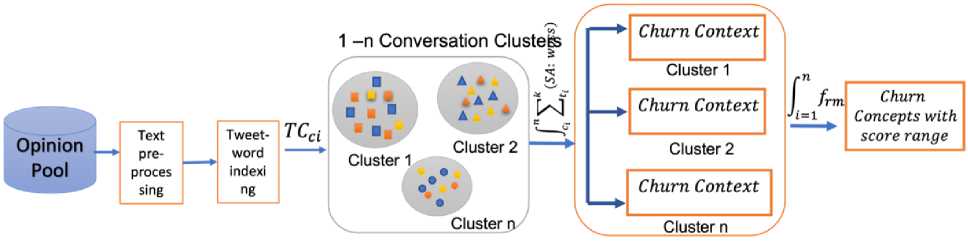
Fig.1. Cluster context conversation opinion mining architecture
From the opinion pool at time t, TCct is the tweet conversation class identifier, ^^(SA: woes) is the sentiment C t 1
analysis and word order contextual semantic function, which defines the churn behaviour of each clustered conversation in context with intelligent concepts. ^ ^1 f rm is the fuzzy network analysis function, which clusters the results of all contextually clustered opinion into a single range of churn class as final output upon training.
From Fig 1, the process of analyzing the contextual conversion towards engendering churn class and knowledge discovering is partitioned into five distinct sub categories. This is inadvertently presented in Algorithm Listing 1 below:
Table 1. Cluster context conversation opinion mining algorithm
Input: Let sr ^ be the stream of data
Output: a model for opinion score detection and information extraction.
|
1. |
Pre-Process sr ^ |
|
2. |
Index Tweet-Word prtw |
|
3. |
Identify or Generate the Conservation Cluster for sr ^ in time tt |
|
4. |
Determine the behaviour class of each tweet in each cluster |
|
5. |
Apply fuzzy network analysis function to the clusters in 4 |
Thus, from Table 1, the sequence of actions outlines a data processing pipeline for analysing tweets. It starts with data preprocessing, moves on to clustering tweets, categorizing them into behaviour classes, and finally applying fuzzy network analysis to the clusters. Hence, by giving a set of raw input tweets as expression, the tweet was pre-processed first to remove noisy tokens and characters. Thereafter, the tweet words were indexed to keep track of the tweet for onward processing. The initial stage of tweet processing requires the clustering of tweet words into clustered conversation as defined in def 3 before the behaviour (content and context with respect to time) of each indexed tweet is obtained. Here, the behaviour of an indexed tweet is guided through the definition 4. Thereafter, the newly discovered class and tweet churn score for each conversation cluster is integrated with Roberta model to obtaining a wide range of churn opinion concepts and scores that defines the template/model where incoming tweet interferes for churn behaviour classification during the testing phase.
4. Experiments and Evaluation
Utilizing a dataset comprising 85,948 expressed opinions with 72,805 containing at least one adjective. The clustered information was on telecom organization's keyword brand, promotions, and other service-related data. Subsequently, preprocessing was executed on the tweets to remove unwanted data such as emotion icons, RT tweets, and other replicated characters. With an undefined 676 tweets, first the behavioural class which informed churn category as Strong Positive, Positive, Neutral, Negative and Strong Negative is presented in Fig 2. Then, eight distinct contextual clustered groups, are presented in Fig 3 from CCOM.
CLASSIFICATION
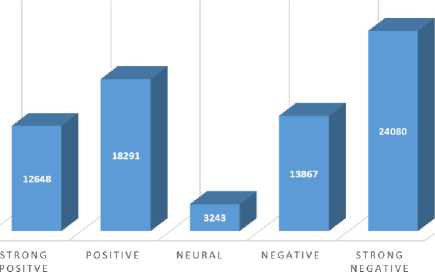
Fig.2. CCOM clustered opinion
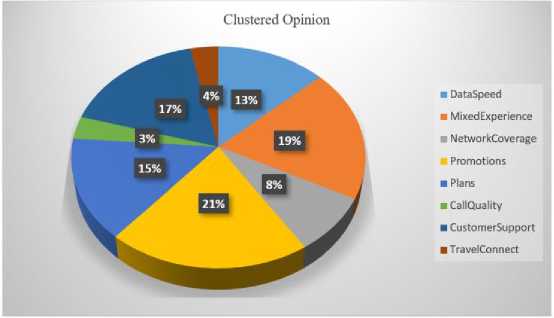
Fig.3. Context driven opinion cluster
The obtained context driven clustered dataset was then integrated with RoBERTa model for the purpose of opinion classification. By mapping Strong Positive opinion to a Premium Customer, Positive – Inertia Customer, Negative – Potential Churner, Strong Positive – Churner, RoBERTa model was fine-tune for fine-grained sentiment analysis of opinion as Strong Positive, Positive, Neutral, Negative and Strong Negative. Initially, the text data was tokenized using RoBERTa's tokenizer, and a maximum sequence length of 128 was set to ensure compatibility with the model's architecture. The following hyperparameters were defined for the baseline experiment: Batch Size: 32, Learning Rate: 2e-5, Number of Epochs: 8, Warmup Steps: 500, Optimizer: AdamW, Dropout Rate: 0.1, Number of Attention Heads: 12 (default for RoBERTa base), Hidden Layer Size: 768 (default for RoBERTa base), and Weight Decay. Early stopping based on the validation loss was implemented to prevent overfitting, and learning rate while scheduling was optionally used to adjust the learning rate through training. Consistently the model learns to distinguish between the different sentiment classes while an output layer was added on top of each model to map the contextualized representations to the five sentimental classes, which defined a customer’s churn category. After passing the input through the RoBERTa model, we got the logits (raw scores) from the model's output, and then we apply a SoftMax function to obtain the likelihood distribution on the five-sentiment category. The class with the topmost likelihood is the predicted sentiment during testing.
Table 2. Opinion classification per cluster context with roberta
|
Context |
Strong Positive |
Positive |
Neutral |
Negative |
Strong Negative |
|
DataSpeed |
1441 |
2268 |
107 |
1979 |
3731 |
|
MixedExperience |
997 |
1774 |
1342 |
2573 |
7231 |
|
NetworkCoverage |
1029 |
785 |
1130 |
1873 |
1222 |
|
Promotions |
4523 |
6673 |
207 |
1176 |
2126 |
|
Plans |
1216 |
4527 |
164 |
3285 |
1581 |
|
CallQuality |
652 |
345 |
34 |
504 |
832 |
|
CustomerSupport |
2359 |
1682 |
201 |
1652 |
6452 |
|
TravelConnect |
431 |
237 |
58 |
825 |
905 |
After training, the model's performance through the developed CCOM alongside are evaluated using the test set (30%) and evaluation metrics, including accuracy, precision, recall, and F1-score are calculated. Although the fifth epoch had a better validation accuracy with consistent training accuracy and decreasing loss as show in Fig 4. However, when the model performance was monitored on a separate test dataset to confirm that the improvement in validation accuracy translates to better performance on unseen data, the Table 3 showcased the model comparative outputs before sample extracted positive and negative concepts from the dataset are showcased in Table 4.
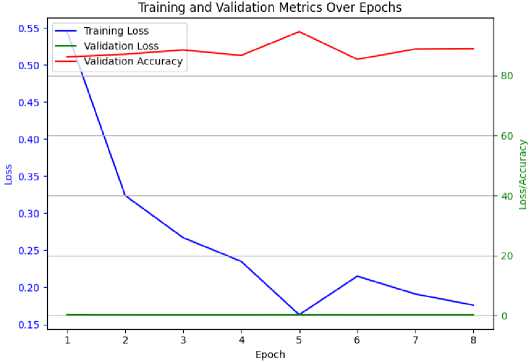
Fig.4. CCOM training and validation metrics over epoch
Table 3. Model Comparative Analysis
|
Approach |
Accuracy |
Precision |
Recall |
F1 Score |
|
CCOM with RoBERTa |
0.92 |
0.88 |
0.87 |
0.84 |
|
Traditional Cluster + RoBERTA |
0.67 |
0.58 |
0.67 |
0.64 |
Table 4. Sample reoccurring positive and negative terms from the clustered opinion
|
Positive Terms |
Negative Terms |
|
Accurate, glad, love, satisfied, advantage, bonus, heroic, keen, affirm, recommend, happier, stable, cheapest, portable, useful, agreeable, extraordinary, abundant, laugh, accountable, strength, reliable, splendid, accomplishment speedy, wow, yes, adaptable, supreme, best, adventure, won, suitable, astounding, favour, optimism, attractive, luck, alive, responsive, marvel, fearless, anticipation, overtake, benefit, feasible, top-notch, nice, flawless, flexible, superior, appreciate, fine, gain, endorse, rich, achievement, gallant, agree, robust, generous, accomplish, good, smart, honest, enjoy, joyous, improve, reward, amaze, delight, graceful, zeal, great, agility, innovative, kudus, like, outshine, perfect, popular, ambition, quicker, ready, acknowledgement, true, upgrade, valuable, renewed, sincere, thank, unbeatable, champion, excellent |
Abnormal, bad, unsatisfactory, hate, embarrassing, grind, ridiculous, terrible, irresponsible, danger, bitter, hurt, crap, fraudulent, enslave, condemnable, headache, detrimental, issue, nuisance, brainless, ambiguous, complaint, mislead, dilemma, frustrated, unacceptable, worst, inefficient, mistake, kills, disappoint, loser, eschew, annoy, havoc, weak, monster, useless, disdain, problem, treachery, lag, aimless, gullible, invalid, painful, awful, condemned, bomb, unkind, nemesis, distraction, backward, bias, debt, controversial, oppressive, crazy, deadly, redundant, exhaust, undecided, evil, false, odd, guilty, hype, ill-formed, jeopardize, liars, mischievous, needless, no, over-priced, poorer, reject, stupid, unhappy, vague, refuse, angry, damn, expensive |
5. Conclusions
Toward mitigating wide spread issues from online community in customer relationship management, collective mining through cluster conversational Network model was developed to identify emerging patterns and trends that might not be apparent when analysing individual opinions. This approach does not only provide a macro-level understanding of customer perceptions but also useful in aiding decision support to a wider variety of individual with close similar behavioural patterns. The adoption of a context-driven approach in opinion mining for churn prediction in this research has redefined existing keyword driven abilities for better understanding, and analysing of sentiments expressed in textual data. The transformation has been achieved through the incorporation of advanced natural language processing techniques in CCOM development and machine learning algorithms that take into account the surrounding context of words and phrases in text data. This contextual analysis enables a more nuanced understanding of the sentiments expressed by considering factors like tone, sarcasm, and ambiguity, which may not be adequately captured by keyword-based approaches. Additionally, context-driven opinion mining leverages semantic analysis to recognize the relationships between words and their meanings, allowing for a deeper interpretation of sentiment. Through integrated with RoBERTa learning algorithms, customers were classified as Churner, Potential Churner, Inertia Customer and Premium customer respectively based on the derived opinion polarity. This was achieved through the combined strengths of RoBERTa's contextual embeddings with an innovative opinion clustering technique presented as CCOM in this research. By considering the context in which words and phrases are used, the accuracy and reliability of sentiment analysis for churn prediction have significantly improved. Subsequently, this model can also be applied in other customer relationship management domains like Bank, Education and Public Opining Sampling. Also, it can also be effective as a campaign tool in politics. Hence, As NLP continues to evolve, this methodology represents a noteworthy contribution to the field, offering a pathway toward more advanced sentiment analysis applications.
References Utilizing RoBERTa Model for Churn Prediction through Clustered Contextual Conversation Opinion Mining
- Evans, Dave. Social media marketing: the next generation of business engagement. John Wiley & Sons, 2010.
- Bashar, Abu, Irshad Ahmad, and Mohammad Wasiq. "Effectiveness of social media as a marketing tool: An empirical study." International Journal of Marketing, Financial Services & Management Research 1, no. 11 88-99: (2012)
- Mishra, Abinash, and U. Srinivasulu Reddy. "A comparative study of customer churn prediction in telecom industry using ensemble-based classifiers." In 2017 International conference on inventive computing and informatics (ICICI), pp. 721-725. IEEE, 2017.
- Bi, Qingqing. "Cultivating loyal customers through online customer communities: A psychological contract perspective." Journal of Business Research 103 (2019): 34-44.
- Mewari, Ritu, Ajit Singh, and Akash Srivastava. "Opinion mining techniques on social media data." International Journal of Computer Applications 118, no. 6 (2015).
- Tayal, Devendra Kumar, Sumit Kumar Yadav, and Divya Arora. "Personalized ranking of products using aspect-based sentiment analysis and Plithogenic sets." Multimedia Tools and Applications 82, no. 1 (2023): 1261-1287.
- Madhuri, D. and Prasad, R., 2020. A ML and NLP based Framework for Sentiment Analysis on Bigdata. International Journal of Recent Technology and Engineering, 8(5), pp.189-200.
- Ayub, Nafees, Muhammad Ramzan Talib, Muhammad Kashif Hanif, and Muhammad Awais. "Aspect Extraction Approach for Sentiment Analysis Using Keywords." Computers, Materials & Continua 74, no. 3 (2023).
- Al-Otaibi, Shaha, Allulo Alnassar, Asma Alshahrani, Amany Al-Mubarak, Sara Albugami, Nada Almutiri, and Aisha Albugami. "Customer satisfaction measurement using sentiment analysis." International Journal of Advanced Computer Science and Applications 9, no. 2 (2018).
- A. Amin, F. Al-Obeidat, B. Shah, A. Adnan, J. Loo and S. Anwar, "Customer churn prediction in telecommunication industry using data certainty," Journal of Business Research, vol. 94, pp. 290-301, 2019.
- Umayaparvathi, V., and K. Iyakutti. "A survey on customer churn prediction in telecom industry: Datasets, methods and metrics." International Research Journal of Engineering and Technology (IRJET) 3, no. 04 (2016).
- Ullah, Irfan, Basit Raza, Ahmad Kamran Malik, Muhammad Imran, Saif Ul Islam, and Sung Won Kim. "A churn prediction model using random forest: analysis of machine learning techniques for churn prediction and factor identification in telecom sector." IEEE access 7 (2019): 60134-60149.
- Lalwani, Praveen, Manas Kumar Mishra, Jasroop Singh Chadha, and Pratyush Sethi. "Customer churn prediction system: a machine learning approach." Computing 1-24, 2022
- Lee, S., Kim, J., Park, H. “Opinion Mining for Churn Prediction: A Review of Techniques and Applications”. International Journal of Data Science and Knowledge Engineering, 9(3), 215-230, 2021
- Nassirtoussi, Arman Khadjeh, Saeed Aghabozorgi, Teh Ying Wah, and David Chek Ling Ngo. "Text mining for market prediction: A systematic review." Expert Systems with Applications 41, no. 16 (2014): 7653-7670.
- Ibitoye, Ayodeji OJ, and Olufade FW Onifade. "Improved customer churn prediction model using word order contextualized semantics on customers’ social opinion." Int J Adv Appl Sci 11, no. 2 (2022): 107-112.
- Wang, L., Zhang, Q., Li, X. “Leveraging Social Media Data for Customer Churn Prediction: A Review of Opinion Mining Approaches”. International Journal of Information Management, 42, 131-147. 2018
- Gupta, R., Sharma, A., Kumar, V.” Customer Churn Prediction using Opinion Mining and Topic Modeling: A Literature Review”. International Journal of Computational Intelligence and Applications, 18(4), 1950021. 2019
- Chen, S., Wang, Y., Liu, H. “A Comparative Review of Opinion Mining Techniques for Customer Churn Prediction.” Journal of Marketing Analytics, 4(2), 89-105, 2017
- Jena, M., and Sanghamitra Mohanty. "Contextual opinion mining in online Odia text using support vector machine." Compliance Eng. J 10, no. 7 (2019): 166-169.
- Cheng, Li-Chen, and Chi-Lun Huang. "Exploring contextual factors from consumer reviews affecting movie sales: an opinion mining approach." Electronic commerce research 20 (2020): 807-832.
- Sundermann, Camila Vaccari, Marcos Aurélio Domingues, Roberta Akemi Sinoara, Ricardo Marcondes Marcacini, and Solange Oliveira Rezende. "Using opinion mining in context-aware recommender systems: A systematic review." Information 10, no. 2 (2019): 42.
- Tan, Kian Long, Chin Poo Lee, Kalaiarasi Sonai Muthu Anbananthen, and Kian Ming Lim. "RoBERTa-LSTM: a hybrid model for sentiment analysis with transformer and recurrent neural network." IEEE Access 10 (2022): 21517-21525.
- Phan, Minh Hieu, and Philip O. Ogunbona. "Modelling context and syntactical features for aspect-based sentiment analysis." In Proceedings of the 58th annual meeting of the association for computational linguistics, pp. 3211-3220. 2020.
- AL-Sharuee, Murtadha Talib, Fei Liu, and Mahardhika Pratama. "Sentiment analysis: an automatic contextual analysis and ensemble clustering approach and comparison." Data & Knowledge Engineering 115 (2018): 194-213.
- Rizun, Nina, Katarzyna Ossowska, and Yurii Taranenko. "Modeling the customer’s contextual expectations based on latent semantic analysis algorithms." In Information Systems Architecture and Technology: Proceedings of 38th International Conference on Information Systems Architecture and Technology–ISAT 2017: Part II, pp. 364-373. Springer International Publishing, 2018.
