Влияние предварительной обработки и аугментации данных на сегментацию опухолевых ядер с помощью сверточных нейронных сетей

Автор: Буравский Н.С., Костюченко Е.Ю.
Журнал: Компьютерная оптика @computer-optics
Рубрика: Численные методы и анализ данных
Статья в выпуске: 4 т.49, 2025 года.
Бесплатный доступ
Актуальность обнаружения и лечения рака молочной железы на ранних этапах остается высокой. За 2020 год зарегистрировано более 65 000 новых случаев онкологии молочной железы, среднегодовой темп прироста – 2%. Число зафиксированных случаев рака молочной железы является лидирующим в статистике по онкологическим заболеваниям. Целью работы является проведение оценки влияния методов предварительной обработки и аугментации наборов данных для сегментации опухолевых ядер на медицинских изображениях в условиях ограниченного объема данных. В экспериментах используется один исходный набор данных и восемь вариантов его предварительной обработки с использованием алгоритмов нарезки изображений для обучения двух моделей сверточных нейронных сетей U-net и U-net с добавлением энкодера ResNet50. Оценка качества обучения нейронных сетей и сегментации ядер выполняется с помощью двух целевых метрик, Dice и IoU, а также в результате сравнения истинного расположения меток ядер и сегментированных ядер с помощью нейронных сетей. В результате обучения моделей на предварительно обработанных наборах данных получены значения целевых метрик по двум моделям для каждого набора, включая исходный. Для архитектуры U-net значения Dice и IoU равны 0,742 и 0,5921, для архитектуры U-net_ResNet50 – 0,7458 и 0,5971.
Предобработка, аугментация, CNN, гистопатологические изображения, BreCAHAD
Короткий адрес: https://sciup.org/140310510
IDR: 140310510 | DOI: 10.18287/2412-6179-CO-1523
Impact of data preprocessing and augmentation on tumor core segmentation using convolutional neural networks
The relevance of detecting and treating breast cancer in the early stages remains high. In 2020, more than 65,000 new cases of breast cancer were registered, with an average annual growth rate being 2%. Every year, the number of recorded cases of breast cancer is leading in statistics of cancer diseases. The goal of the work is to evaluate the impact of preprocessing and augmentation methods on data sets for segmenting tumor nuclei in medical images under conditions of limited data volume. The experiments use one initial data set and eight variants of its pre-processing using image slicing algorithms to train two models of convolutional neural networks, U-net and U-net with the addition of a ResNet50 encoder. Assessing the quality of neural network training and kernel segmentation is performed using two target metrics, Dice and IoU, as well as by comparing the true location of kernel labels and segmented kernels using neural networks. As a result of training the models on pre-processed data sets, values of target metrics are obtained for the two models for each dataset, including the original one. For the U-net architecture, the Dice and IoU values are 0.742 and 0.5921, for the U-net_ResNet50 architecture they are 0.7458 and 0.5971.
Текст научной статьи Влияние предварительной обработки и аугментации данных на сегментацию опухолевых ядер с помощью сверточных нейронных сетей
При использовании современных технологий в медицине, таких как компьютерная визуализация и глубокое обучение, предварительная обработка набора данных является важной задачей. Ключевым фактором успешной ранней диагностики и своевременной помощи человеку является точная сегментация опухолевых ядер.
В большинстве случаев сегментация опухолевых ядер на гистопатологических снимках выполняется не автоматически, а специалистом. Одним из решений может являться внедрение системы, способной в автоматическом режиме выполнять сегментацию ядер на снимках, отмечая их. Данный подход к анализу дает преимущество по времени и не зависит от человеческих факторов, таких как неопытность или невнимательность врача.
Обсуждение методов и перспектив использования глубокого обучения, в частности влияние глубокого обучения на диагностику и лечение заболеваний, описано в обзорной статье исследователей из Китая [1]. Приведены примеры того, как использование сверточных нейронных сетей (CNN), рекуррентных нейронных сетей (RNN) и генеративносостязательных сетей (GAN) может изменить подход к диагностике заболеваний и улучшить результаты лечения.
На фоне последних инноваций и прорывов стоит упомянуть разработку библиотеки MIScnn [2], которая предназначена для упрощения процессов сегментации медицинских изображений с использованием сверточных нейронных сетей. Фреймворк включает в себя функционал для ввода данных, предобработки, аугментации данных и оценки. MIScnn уже показал хорошие результаты в рамках Kidney Tumor Segmentation Challenge 2019, позволив быстро настроить полноценные рабочие процессы сегментации медицинских изображений, а используя модель 3D U-Net, участники смогли достичь высокой точности сегментации.
Сделав выборку публикаций с ресурса «Google Scholar» по запросу «histology segmentation dice», было получено количество публикаций, а также выделены методы, которые использовались для сегментации. Выборка включает в себя общее количество публикаций, а также количество публикаций за 2023 год, что позволят оценить актуальность использованных инструментов.
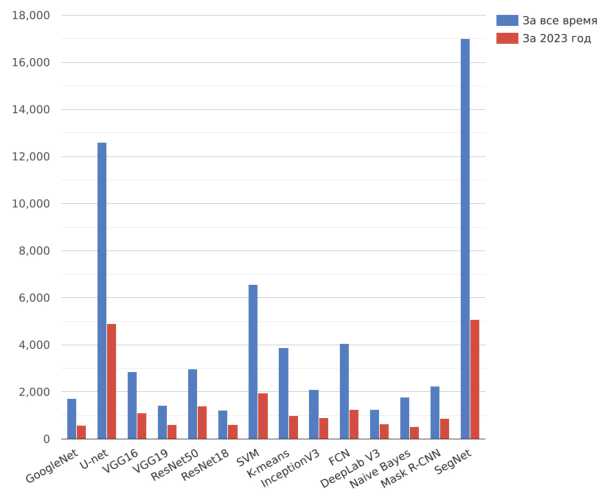
Рис. 1. Количество публикаций по ключевым словам
Анализируя выборку, можно определить инструменты, которые наиболее активно используются и обсуждаются, такими являются U-net, ResNet50, SVM, SegNet. Это указывает на их актуальность и потенциал в задачах сегментации. Согласно количеству цитирований Scopus, работа Роннебергера Олафа, который является автором U-net, цитируется больше (более 80 тысяч прямых цитирований), чем работа Бадринараянана Виджая (около 18 тысяч прямых цитирований), который является автором SegNet.
Выделение и обозначение опухолевых ядер на гистопатологических изображениях в автоматическом режиме на цифровых изображениях ткани молочной железы, полученных в результате гистологического исследования, достигается за счет точечной сегментации .
Результат сегментации позволяет определить и количественно оценить характеристики опухолевых клеток, что представляет значимость для пациента, так как своевременное выявление и лечение рака на ранних стадиях очень важно.
Одной из проблем, которая может возникнуть при создании такой системы, является недостаток медицинских данных при обучении. Очевидным решением является аугментация набора данных, которая не может быть выполнена без предварительной обработки. Создание алгоритма из методов увеличения и предварительной обработки данных представляет собой трудную задачу, так как выбор методов основывается на структуре и разнообразии данных, целях задачи. Не все алгоритмы могут подойти к данным, так как синтетические изображения могут включать в себя аномалии, которые могут быть причинами некорректного обучения модели.
В данной работе была поставлена задача определить, какое влияние оказывают различные методы предварительной обработки и аугментации гистопатологического набора данных на процесс и результаты обучения модели при сегментации опухолевых ядер.
1. Описание задачи и данных
В работе рассматривается построение алгоритма, включающего в себя методы предварительной обра- ботки и аугментации и влияние определенного ало-ритма на результаты обучения модели. На выходе должен быть определен перечень методов, наборов данных и результаты, которые показывает модель при обучении.
В данном случае алгоритм решает проблему маленьких наборов данных при обучении модели сегментации ядер на снимках. Для изучения влияния методов предобработки и аугментации используется набор данных BreCaHAD.
Набор данных BreCaHAD состоит из 162 гистопатологических изображений размером 1360×1024 пикселей [3] и дополнен аннотацией в виде json-файлов с определением центров ядер по координатам x и y , т.е. разметкой ядер. Разметка включает в себя шесть классов: митоз, апоптоз, ядра опухоли, неопухолевые ядра, трубочки и нетрубочки. В работе используется разметка только опухолевых и неопухолевых ядер. Пример изображений приведен ниже (рис. 2).
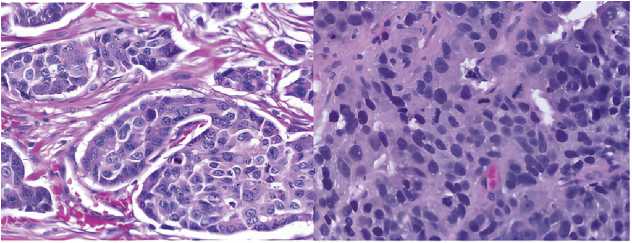
Рис. 2. Гистопатологические изображения
2. Архитектуры
Для проверки влияния выбранных методов предварительной обработки и аугментации данных используются сверточные нейронные сети.
U-Net – это архитектура нейронной сети, которая используется для сегментации изображений, чаще всего в медицинской сфере. Авторы [4] использовали архитектуру U-Net, поскольку она эффективно сочетает в себе контекстную информацию и точную локализацию, необходимую для точной сегментации медицинских изображений. Ее актуальность подтверждается количеством публикаций (рис. 1), в которых она используется для сегментации.
Архитектура включает в себя свёрточные слои сжимающего пути для извлечения признаков и расширяющего пути для восстановления изображения. Отличительной особенностью U-Net является частое использование сверток и pooling-слоев, а также высокие результаты при ограниченном датасете. Типовая архитектура модели изображена ниже (рис. 3).
Архитектура включает в себя слои свертки и развертки. Свертка является стандартом для сверточной нейросети. Слои свертки включают в себя повторение двух сверток 3×3. После этого применяется функция активации «ReLU».
Для снижения разрешения используется операция объединения. Для каждого этапа понижения дискретизации характерно удвоение каналов свойств. Слои развертки включают в себя операции, в процессе ко- торых дискретизация карт свойств изображения увеличивается. Выполняется объединение с данными изображения, которые обработаны другими слоями свертки [5]. Дальше алгоритм включает в себя:
– операцию свертки 2×2, результатом которой является уменьшение числа каналов свойств;
– процесс объединения с обрезанной картой свойств, полученной в процессе свертки;
– процессы двух сверток 3×3, после применяется функция активации «ReLU».
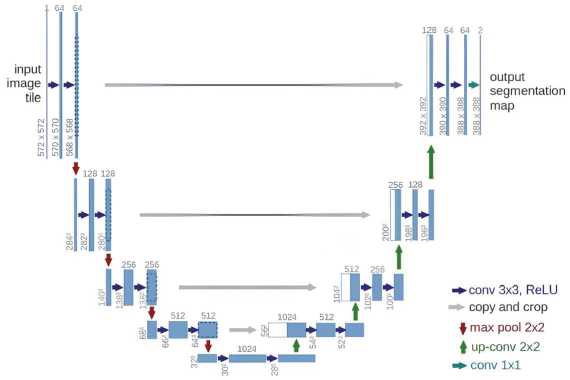
Рис. 3. Типовая архитектура U-net
U-Net обучается с использованием метода обратного распространения ошибки. При обучении U-net для задачи сегментации часто можно встретить использование кросс-энтропии в качестве функции потерь. Она измеряет разницу между вероятностным расположением объектов, предсказанным моделью, и фактическим расположением на масках. Определяется следующей формулой (1):
E = Z x efi w ( x ) log ( P x ( x ) ) , (1) где p – логарифм вероятности, показывающий принадлежность пикселя x к классу l x ; w(x) – весовой коэффициент, который определяется формулой (2):
w ( x ) = v c ( x ) + w0 x exp
( b ( x ) + b 2 ( x ) ) 2
2 o 2
где v c – карта весов для балансировки частот классов; w 0 – базовый коэффициент для корректировки весов; b 1 – расстояние до границы ближайшей ячейки; b 2 – расстояние до границы второй ближайшей ячейки; σ – параметр, контролирующий степень влияния расстояний b 1 ( x ) и b 2 ( x ) на веса.
Архитектура Unet + ResNet50 включает в себя слои свертки и развертки. Только на месте слоя энко-дера присутствует обученный энкодер ResNet50, используя веса «imagenet».
ResNet50 – это архитектура нейронной сети, представляющая собой глубокую свёрточную нейронную сеть (CNN). Основной вклад ResNet заключается в использовании блоков с остаточным соединением (residual connections или skip connections) [6]. Остаточные соединения в блоках позволяют пропускать информацию мимо одного или нескольких слоев нейронной сети. Это не только помогает в решении проблемы затухания градиентов, но и способствует уменьшению числа локальных минимумов функции потерь, нарушая симметрию её рельефа. Таким образом, снижается вероятность сходимости обучения к локальным минимумам, что в среднем повышает точность прогнозов обученной сети.
Присоединение энкодера ResNet50 к U-Net может улучшить производительность модели в задачах сегментации изображений (рис. 4) [7]. U-Net является архитектурой, разработанной специально для задач сегментации, а ResNet50 с его глубокими остаточными соединениями может значительно улучшить способность энкодера извлекать сложные признаки из изображений.

Transpose Convolution Concatenate | | (3x3) Conv2D + BN + ReLU | | (1x1) Conv2D + Sigmoid
Рис. 4. Архитектура U-net_ResNet50
3. Предобработка данных
Выбор и настройка методов предобработки и аугментации данных имеют важное значение для достижения более точных и надежных результатов сегментации опухолевых ядер на медицинских изображениях.
Сначала необходимо подготовить исходные данные для работы. Файлы разметки были преобразованы в маски изображений, где точками обозначены центры опухолевых ядер. Использование преобразования типов данных «float16» позволило уменьшить объем файлов разметки в 1,5 раза.
Исследуя смежные работы по данной теме, были использованы общепринятые и универсальные методы предварительной обработки. Перед созданием наборов данных необходимо провести предварительную обработку гистопатологических изображений набора BreCaHAD. Шум уменьшается с помощью фильтра Гаусса (размер ядра – 5×5, параметр стандартного отклонения в горизонтальном направлении определен как 0); с помощью фильтра повышения резкости (линейное увеличение резкости с ядром свертки 3×3, где центральный элемент равен 5, окружающие его равны – 1) изображения снова становятся более четкими; фильтр medianBlur (размер ядра –3)
для сглаживания изображения [8– 12]. Из обработанных изображений формируется набор данных.
При обучении нейронных сетей также необходимо проводить процедуру нормализации данных, т.е. приводить данные к виду диапазона от 0 до 1. Такой процесс позволяет делать процесс обучения модели возможным.
4. Аугментация данных
Что касаемо методов аугментации, то в функции, генерирующей дополнительные данные, использовались повороты на 90 градусов, вертикальное и горизонтальное отражение [8, 13– 16]. При работе с гистопатологическими изображениями не применялись методы приближения, сдвига и масштабирования, так как эти операции могут привести к удалению важных объектов с изображений, что может сказаться на результатах работы модели.
Помимо использования функции генерации новых данных, подготовлены 8 обработанных наборов, к которым при проведении экспериментов также применялась функция генерации (аугментации) данных. Предварительно обработанные наборы были созданы по следующему принципу: были взяты исходные изображения 1360×1024, преобразованы к квадратному размеру (1024×1024), применена нарезка исходных изображений на меньшие равные части и нарезка мелких частей исходного изображения с шагом. Изображения для первого набора нарезались на 4 равные части, изображения для второго набора нарезались на 9 частей, по 512×512 пикселей с шагом 256 пикселей, изображения для третьего набора нарезались на 49 частей, по 256×256 пикселей с шагом 128 пикселей и для четвертого набора исходные изображения нарезались на 225 частей, по 128×128 пикселей с шагом 64 пикселя.
При использовании таких методов аугментации генерировались экземпляры изображений, которые не имели разметки опухолевых ядер. Исходя из этого, к полученным наборам был применен алгоритм удаления неразмеченных экземпляров. Суть алгоритма заключается в том, что в процессе работы проверяется каждое изображение в наборе: если для изображения имеется разметка опухолевых ядер, оно сохраняется; в ином случае изображение удаляется из набора. Таким образом удалось получить 9 наборов данных (вместе с исходным) для проведения экспериментов.
5. Метрики оценивания
Коэффициент Dice является мерой соответствия или сходства между двумя наборами образцов [17]. G и S являются двумя наборами пикселей изображения. G – набор пикселей, которые принадлежат интересующему объекту (исходная разметка опухолевых ядер), а S – пиксели, которые были отнесены к этому объекту в результате сегментации (предсказанная разметка). Коэффициент Dice определяется следующей формулой (3):
/ 2 G n S
Dice(G , S = ,1 , . (3)
' | G | + | S|
Коэффициент Dice может находиться в интервале от 0 до 1, где чем выше значение, тем более согласуется результат сегментации с достоверностью. Если Dice = 1, это идеальное соответствие.
Метрика IoU (Intersection over Union) является популярной метрикой в задачах сегментации изображений и объектов. Она измеряет схожесть между двумя множествами пикселей: предсказанным (обычно моделью) и истинным (настоящим) сегментированным изображением [18].
IoU вычисляется как отношение площади пересечения между предсказанным и истинным сегментами к площади их объединения [18]. Формула IoU выглядит следующим образом (4):
, „ Predicted n True loU =-----------------. (4)
Predicted и True
6. Результаты экспериментов
Перед тем как проводить обучение на подготовленных наборах данных, проверим, как будет обучаться модель U-net и какой будет сегментация на 2 наборах данных с определенными условиями: первый набор данных (prep), в котором изображения предварительно обработаны; второй набор данных (n_prep), изображения которого предварительно не обрабатывались. Было запущено по два обучения, с использованием аугментации и без. Результаты экспериментов занесены в таблицу (табл. 1).
Табл. 1. Результаты с архитектурой U-net
|
Dataset |
Train |
Test |
Aug |
||
|
Dice |
IoU |
Dice |
IoU |
||
|
prep |
0,902 |
0,8239 |
0,2566 |
0,1471 |
- |
|
prep |
0,3101 |
0,2143 |
0,439 |
0,3767 |
+ |
|
n_prep |
0,0281 |
0,0142 |
0,0484 |
0,0248 |
+ |
|
n_prep |
0,7631 |
0,6312 |
0,2843 |
0,1547 |
- |
Модель U-net, обученная на предварительно обработанных данных (prep), показывает высокие значения целевых метрик на этапе обучения, но испытывает трудности при обобщении на тестовых данных без аугментации, выполняя задачу сегментации. В процессе обучения модели наступает переобучение, тогда как аугментация помогает в улучшении обобщающих способностей модели.
Для получения точечной сегментации на наборах данных с предварительной обработкой и без неё, важно подготовить данные для обучения, используя методы предварительной обработки изображений и аугментацию.
Для обучения набор данных был разделен следующим образом: на тренировочную выборку от- делено 80 %, остальные данные пошли на тестовую выборку. Параметр скорости обучения – learning rate был установлен на 0,1 и уменьшался, когда значение функции потерь на тестовой выборке переставало изменяться.
Результаты экспериментов занесены в таблицы (табл. 2 и табл. 3).
Табл. 2. Результаты с архитектурой U-net
|
Dataset |
Train |
Test |
Size |
||
|
Dice |
IoU |
Dice |
IoU |
||
|
Original |
0,9631 |
0,8312 |
0,3843 |
0,2547 |
162 |
|
1/4 |
0,92 |
0,7632 |
0,431 |
0,377 |
648 |
|
1/4/zero |
0,4029 |
0,3855 |
0,4011 |
0,3641 |
635 |
|
512p/256s |
0,1873 |
0,1013 |
0,3126 |
0,223 |
247 |
|
512p/256s/zero |
0,1789 |
0,0986 |
0,3037 |
0,179 |
286 |
|
256p/128s |
0,8742 |
0,7962 |
0,7271 |
0,5661 |
1349 |
|
256p/128s/zero |
0,8923 |
0,8084 |
0,742 |
0,5921 |
1258 |
|
128p/64s |
0,8134 |
0,6903 |
0,6615 |
0,5008 |
6196 |
|
128p/64s/zero |
0,8553 |
0,7509 |
0,7084 |
0,5547 |
4655 |
Табл. 3. Результаты с архитектурой U-net_ResNet50
|
Dataset |
Train |
Test |
Size |
||
|
Dice |
IoU |
Dice |
IoU |
||
|
Original |
0,3101 |
0,2143 |
0,439 |
0,3767 |
162 |
|
1/4 |
0,8934 |
0,8077 |
0,2562 |
0,1469 |
453 |
|
1/4/zero |
0,6918 |
0,6194 |
0,3538 |
0,2721 |
435 |
|
512p/256s |
0,841 |
0,7268 |
0,6359 |
0,4664 |
247 |
|
512p/256s/zero |
0,1962 |
0,1041 |
0,3218 |
0,278 |
228 |
|
256p/128s |
0,901 |
0,822 |
0,7416 |
0,5934 |
1190 |
|
256p/128s/zero |
0,8845 |
0,7948 |
0,7458 |
0,5971 |
1190 |
|
128p/64s |
0,8293 |
0,712 |
0,676 |
0,5154 |
5103 |
|
128p/64s/zero |
0,8623 |
0,7617 |
0,691 |
0,5333 |
4655 |
Что касается архитектуры U-net_ResNet50, высоких значений целевых метрик удалось достичь, если использовать алгоритм подготовки набора данных с размерами 256×256 и 128×128 пикселей. При использовании в алгоритме удаления неразмеченных экземпляров значения целевых метрик оказались чуть выше. Аналогичную картину по значениям метрик показала и чистая модель U-net. С такими же наборами удалось достичь высоких результатов при обучении моделей. Представлены результаты разметки ядер при обучении (рис. 5 и рис. 6).
По разметке ядер можно сказать, что модель U-net верно выполняет разметку большей части изображения. Но присутствуют те области, где отсутствует разметка соответствующего ядра. На двух изображениях отсутствует разметка одного ядра, на третьем изображении модель не смогла распознать три ядра, не отметив их на маске.
«256p/128s/zero»
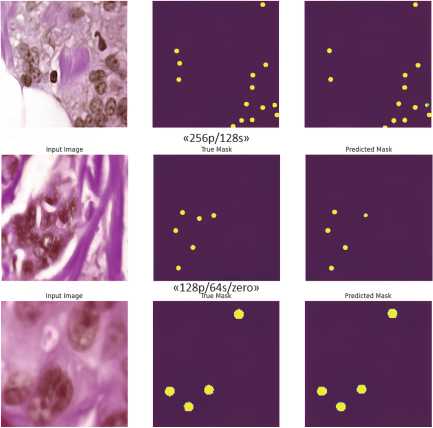
Рис. 5. Сегментация ядер архитектурой U-net
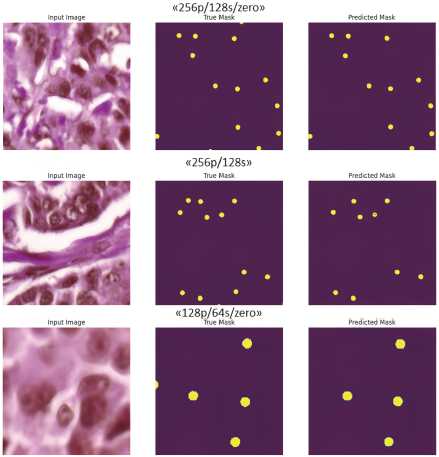
Рис. 6. Сегментация ядер архитектурой U-net_ResNet50
Архитектура U-net_ResNet50 в какой-то момент не смогла распознать большое количество ядер в наборе «256/128_no_zero», возможно, на это повлияло удаление неразмеченных областей. По остальным изображениям видно, что модель не смогла разметить 1–2 ядра в зависимости от набора данных.
7. Сравнение со смежной работой
В большинстве смежных работ, где используется набор данных BreCaHAD, оценивается точность сегментации. При сравнении полученных результатов с результатами смежных работ можно сказать, что значения целевых метрик получились схожими. В работе [19] исследователи использовали синтетический набор данных из 20 тысяч экземпляров; без использования энкодеров и предобученной модели они смогли добиться значений целевых метрик (Dice и IoU) равными 74,22 (наш результат – 74,58) и 59,24 (наш результат – 59,71). Результат является сопоставимым, и имеет значение то, что для обучения исследователи использовали весь набор данных целиком. В нашем же случае в связи с ограниченностью ресурсов, используя предобработанный аугментированный набор, мы смогли добиться такого же результата по целевым метрикам.
Заключение
Как было указано, целью работы является исследование того, как различные методы подготовки и изменения исходного набора данных могут влиять на сегментацию ядер на изображениях в условиях ограниченного объема данных. В процессе исследования и проведения экспериментов были созданы наборы данных, используя методы предобработки и аугментации, которые позволили сделать из небольшого набора, 162 экземпляра, восемь предобработанных, используя нарезку изображений, отступы и удаление неразмеченных экземпляров.
Основываясь на результатах, зафиксированных в табл. 2 и 3, явно видно, что количество данных при обучении влияет на значения целевых метрик. При увеличении количества экземпляров данных, используемых для обучения модели, модель получает больше информации о структуре данных. Это особенно важно в условиях ограниченного исходного объема данных. Результаты показывают, что с увеличением количества данных увеличиваются значения целевых метрик Dice и IoU, вследствие чего модель выявляет дополнительные паттерны, что, в свою очередь, влияет на ее производительность на тестовых данных. Все это говорит о том, что аугментация эффективно способствует обучению модели, позволяя ей лучше адаптироваться.
При создании наборов данных были получены такие наборы, из которых были исключены экземпляры изображений с отсутствующей разметкой ядер. Это, в свою очередь, помогает модели сосредоточиться на более качественных и релевантных данных, что теоретически должно улучшать её способность выявлять значимые паттерны. Однако результаты показывают, что не всегда такая обработка приводит к увеличению значений целевых метрик, что может указывать на потерю важной информации в процессе фильтрации данных.
В процессе экспериментального обучения было получено 22 различных результата. Обучаясь на наборах, размер которых равен 256×256 пикселей с шагом 128 пикселей, архитектура U-net смогла показать наивысшие результаты значений метрик Dice и IoU. Первый из них дал результаты в 0,7271 и 0,5661, в то время как для набора без экземпляров с отсутствующей разметкой результат равен 0,742 и 0,5921.
Наивысшее значение целевых метрик архитектура U-net_ResNet50 достигла, используя такие же наборы данных. Для первого набора были зафиксированы показатели 0,7416 и 0,5934, а для второго – 0,7458 и 0,5971.
Комбинируя предварительную обработку и аугментацию, можно достигать лучших результатов, поскольку обработка улучшает качество данных, а аугментация увеличивает их количество и разнообразие.
Исследование выполнено при финансовой поддержке Министерства образования и науки Российской Федерации в рамках научных проектов, выполняемых коллективами научно-исследовательских лабораторий образовательных учреждений высшего образования, подведомственных Министерству науки и высшего образования Российской Федерации, номер проекта FEWM-2020-0042.
