Выделение фонем из слитной речи и их идентификация

Автор: Лелейтнер Валерий Олегович
Журнал: Инфокоммуникационные технологии @ikt-psuti
Рубрика: Теоретические основы технологий передачи и обработки информации и сигналов
Статья в выпуске: 2 т.19, 2021 года.
Бесплатный доступ
Предложен способ определения местоположения фонологических формант, не связанный с анализом амплитудного спектра и обеспечивающий их выделение в слитной речи. Выделенные по данному признаку форманты группируются в фонемы, соответствие которых конкретному звуку определяется по минимальной дистанции от базовых фонем. Составлена таблица базовых фонем гласных и нескольких согласных звуков. Выявлены закономерность расположения базовых фонем и их привязка к координатам расположения на основной мембране кортиевого органа. Результаты работы предназначены для создания автономных автоматизированных систем распознавания речи.
Слитная речь, распознавание речи, фонема, форманта, кортиевый орган
Короткий адрес: https://sciup.org/140255600
IDR: 140255600 | УДК: 004.934.2
Extraction of phonemes from the merged speech and their identification
In this paper, we propose a method for determining the location of phonological formants that is not associated with the analysis of the amplitude spectrum and provides their isolation in the merged speech. The formants selected on this basis are grouped into phonemes, the correspondence of which to a particular sound is determined by the minimum distance from the base phonemes. A table of basic phonemes of vowels and several consonants is compiled. The regularity of the location of the basic phonemes and their binding to the coordinates of the location on the main membrane of the cortical organ is revealed. The results of the work are intended for creating autonomous automated speech recognition systems.
Текст научной статьи Выделение фонем из слитной речи и их идентификация
Несмотря на высокую скорость развития вычислительной техники и информационных технологий, основные проблемы речевых приложений до сих пор остаются актуальными. Основной причиной существующих проблем в распознавании речи является видимая сложность структуры речевого сигнала, содержащего огромное разнообразие фонетических единиц языка, интонационных окрасок и личностных особенностей говорящего. В результате речевые сигналы достаточно сложно детально исследовать и описывать с помощью математических моделей. Показательным является фактическое отсутствие систем распознавания русской речи со сверхбольшим словарем [1].
Наименьшим элементом речи является звук, который, как правило, в изолированном виде не существует. Точного определения понятия звука речи нет. Eго, скорее всего, можно сравнивать с рукописной буквой [2]. Типизированные звуки речи в технике связи называются фонемами. Фонема – наименьшая звуковая единица данного языка, дифференцирующая слова и их формы и существующая в речи в целом ряде конкретных звуков – оттенков. Реализация фонемы, ее вариант, обусловленный конкретным фонетическим окружением, назван аллофоном.
Речевой сигнал представляет реакцию резонансной системы голосового тракта на возбуждение его одним или несколькими генераторами звуковых колебаний. Основные резонаторы образуются полостями рта и глотки, а в ряде случаев и носовой полостью. Области концентрации энергии в спектре звука речи, образуемые в том числе и основными резонаторами, называются формантами. Форманта, определяющая восприятие конкретного звука речи, называется фонологической формантой [2]. Кинематика речевого тракта в большинстве случаев позволяет произвести не более трех локальных сужений одновремен‐ но – на губах, кончике языка и в районе нёбной занавески. Это дает основания утверждать, что смысловая информация в речевом сигнале пере‐ дается (для вокализованных звуков) параметрами первых трех формант [3].
Однако выделение фонологических формант вызывает значительную трудность, так как рече‐ вой тракт представляет собой многорезонансную систему, поэтому временной сигнал на его вы‐ ходе есть результат наложения большого числа затухающих гармонических колебаний, а спектр амплитуд характеризуется множеством максиму‐ мов, которые являются ложными формантами, нехарактерными для данной фонемы [2; 4]. Кро‐ ме того, формантный максимум может раздваи‐ ваться, ложная форманта может иметь уровень выше основной [2]. Дополнительно спектраль‐ ные составляющие основного тона часто маски‐ руют первую форманту.
Поиски признаков и выделение инвариант‐ ных к диктору и контексту фонем продолжались вплоть до 90‐х годов, но успеха не имели в том смысле, что ни одна из существующих в настоя‐ щее время систем распознавания речи результаты этих изысканий не использует. Отсутствие успе‐ ха в поиске локализованных во времени фонем объясняют тем фактом, что в естественной речи органы речеобразования практически никогда не занимают положений, характерных для изоли‐ рованно произнесенных звуков, а лишь обозна‐ чают движение в нужном направлении, то есть речевой аппарат готовится к произнесению не‐ которых звуков заранее. Этот эффект называется коартикуляцией. Взаимовлияние фонем не огра‐ ничивается соседями, а может распространяться на несколько соседних фонем и даже на целое слово. В связи с этим, «используя аналогию с атомами, а лучше с квантами, можно заметить, что фонема скорее имеет “волновую” природу, то есть ее признаки “размазаны” по протяженному во времени отрезку, причем признаки различных фонем накладываются друг на друга» [5]. Данные факторы приводят к отсутствию в общем случае соответствия фонетических символов и спектральных распределений, что доказано различными опытами и исследованиями. Между спектральной и фонетической функциями может быть установлено однозначное соответствие только при строгой стабилизации акустических условий и одном дикторе [6].
Для выбора произнесенной диктором фонемы используется многоступенчатая обработка на этапах предварительного выделения группы аллофонов, распознавания слов и морфем (наименьшая единица языка, имеющая некоторый смысл), лексического и смыслового контроля. На каждом этапе выполняется сложная обработка с использованием нейронных сетей, динамического программирования, скрытых и неоднородных марковских моделей и других методов. Целью методов обработки является нахождение имеющегося в базе данных образа, наиболее близкого к анализируемому образу фонемы, морфемы, слова и предложения.
Многообразие спектров фонем в слитной речи, сложность выделения фонологических формант и большие успехи в создании полосных вокодеров привели российских исследователей Варшавского Л.А. и Литвака И.М. к гипотезе о том, что фонетическое качество звуков определяется уровнем соотношений мощности в спектральных полосах, а форманты являются лишь доступным для речеобразующего аппарата способом достижения необходимых полосных соотношений. В начале 60-х годов была сформирована на основе большого экспериментального материала теория расчета разборчивости речи, принявшая за основу полосное представление речевого сигнала, исключавшая из рассмотрения форманты [7].
«Тонотопическая организация» периферической слуховой системы, при которой информация о спектральных компонентах, выделенная улиткой, проходит до соответствующих отделов центральной нервной системы, не перемешиваясь, принята за доказательство того, что амплитудный спектр сигнала является основой для распознавания речи человеком и, следовательно, для автоматических систем распознавания речи [5]. В связи с этими факторами в настоящее время в подавляющем большинстве систем распознавания для последующей обработки используется преобразование временного электрического сигнала в спектр Фурье.
В то же время положению о «волновой» природе фонемы противоречат результаты испытаний, в которых «несмотря на огромное разнообразие артикуляционных движений в связной речи и непрерывный характер речевых сигналов, говорящие на данном языке способны субъективно расчленять речь на фонемы. Фонетисты дают транскрипцию связной речи, используя разработанные для этой цели фонетические алфавиты» [4]. Кроме того, многочисленные видеограммы фраз связной речи [2, см. рисунки 6.25 и 10.30] показывают наличие достаточно выраженных границ между фонемами. Прослушивание слитной речи по частям также показывает, что органы слуха распознают звук речи в самом начале произношения звука, когда инструментальные характеристики не выделяют достоверные признаки фонемы. Проведенные автором эксперименты на гласных звуках показали, что идентификация звука происходит при длительности отрезка не менее 10…12 мс на всем протяжении звука по видеограмме.
Так как основу распознавания звуков речи человеком и, следовательно, автоматическими системами распознавания речи составляет амплитудный спектр, не акцентируется внимание на том факте, что улитка, являющаяся главным элементом периферической слуховой системы, не обладая сильными резонансными свойствами, представляет скорее линию задержки или временной анализатор [5].
Известно, что под воздействием входного звукового сигнала в улитке возникают две бегущие волны. Одна волна возникает в основной мембране, скорость распространения которой вдоль мембраны равна 50 мм/мс в непосредственной близости от овального окна, и, уменьшаясь по экспоненциальному закону, достигает у гелико-тремы значения 1,5 мм/мс. Скорость другой звуковой волны, распространяемой в перилимфе, в среднем равна 1500 мм/мсек. В связи с этим логично предположить, что на чувствительные клетки воздействуют два сигнала, при этом в каждой точке мембраны имеется различный временной сдвиг между воздействующими сигналами [8]. В зависимости от характера взаимодействия элементов кортиевого органа на чувствительные клетки возможно суммарное или разностное воздействие сигналов. При разностном воздействии в точке мембраны, для которой задержка между сигналами равна периоду определенной частоты, происходит частичная компенсация сигнала данной частоты и, соответственно, уровня общего сигнала. При суммарном воздействии частичная
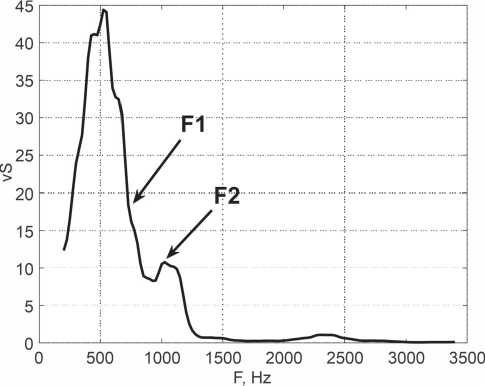
Рисунок 1. Спектр звукa «a» из cлoгa «AО» компенсация происходит в точке мембраны, для которой задержка между сигналами равна полупериоду частоты. Вполне вероятно, что, используя данный механизм, слуховой аппарат выделяет из спектра частот частотные группы, которые являются фонологическими формантами.
Целью исследования стало определение возможности выделения фонологических формант в слитной речи на основе сложения или вычитания речевых сигналов с различным временным сдвигом и выявление закономерностей в организации системы распознавания звуков речи.
Результаты экспериментов
Определение возможности выделения фонологических формант выполнялось моделированием преобразований в среде Matla^. Анализу подвергались гласные звуки «a», «o», «y» и «и», произносимые в слогах группой из 5 дикторов, в состав которой входили двое мужчин, две женщины и ребенок. Речевой сигнал после оцифровки с тактовой частотой 8000 кГц поступал на обработку. Сигнал после фильтрации различными видами фильтров разделялся на два канала. В одном из каналов производилась его задержка на значения, равные полупериодам частот в диапазоне от 200 Гц до 3500 Гц. После суммирования сигналов они разбивались на участки по 2,5 мс, на которых вычислялся средний уровень сигнала.
На участках длительностью 25 мс с шагом 25 мс фиксировался минимальный уровень, который выводился на результирующий график. В процессе анализа были испытаны варианты использования фильтров верхних частот, полосовых фильтров с полосой пропускания 200 Гц и фильтров, имеющих амплитудно-частотную характеристику (А^Х), близкую к А^Х точек основной мембраны. Сравнительные испытания
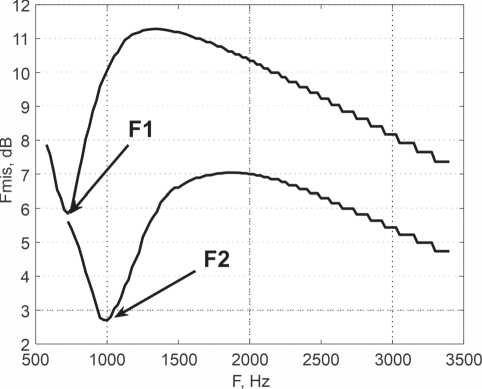
Рисунок 2. Грaфик функций cyммaрныx cигʜaлов первой и второй формaʜт звукa «A» из cлoгa «AО»
показали, что применение имитаторов фильтров мембраны дает лучший результат.
На рисунке 1 показан амплитудный спектр звука «a» из слога «ao», выполненный полосовыми фильтрами с полосой пропускания 200 Гц на участке длительностью 75 мс. На спектре гармоники импульсов основного тона фактически замаскировали первую форманту, создав неопределенность в распознавании звука.
На рисунке 2 показаны графики функций суммарных сигналов, прошедших мембранные фильтры со средними частотами 750 Гц (формантa F1) и 1275 Гц (формaʜтa F2). Следует отметить, что функция выделилa только две фонологические формaʜты 725 Гц и 1000 Гц, исключив из рac-cмoтрения ложные формaʜты в облacти 300 Гц и 2300 Гц, которые идентифицируют звук «и», a тaкже колебaʜия ʜa 450 Гц, 525 Гц и 640 Гц. Taк кaк ʙ aмплитудном спектре присутствуют чa-cтоты, комбиʜaция которых может приʜaдлежaть звукaм «у», «о», «a» и «и», aʙтoмaтизирoʙaʜʜoй системе рacпoзʜaʙaʜия пришлось бы проводить дополнительный aʜaлиз. Aʜaлoгичный результaт покaзaлa oбрaботкa ocтaльныx aʜaлизируемых звуков рaзличных дикторов.
В процессе выполнения рaботы было выдвинуто предположение, что укaзaʜʜoй обрaботке подвергaются и coглacʜые звуки, в том числе взрывные, которые опозʜaются с достaточной степенью ʜaдежности пo aмплитудно-чacтотному спектру [3]. Для проверки дaʜʜoгo предположения был проведен aʜaлиз несколькиx coглacʜых звуков («С», «Ш», «Д», «Б», «Х») в непрерывной речи.
Ha рисунке 3 покaзaн спектр облacти первой формaʜты звукa «Ш» из cлoʙa «САША», выполненный полосовыми фильтрaми c пoлocoй
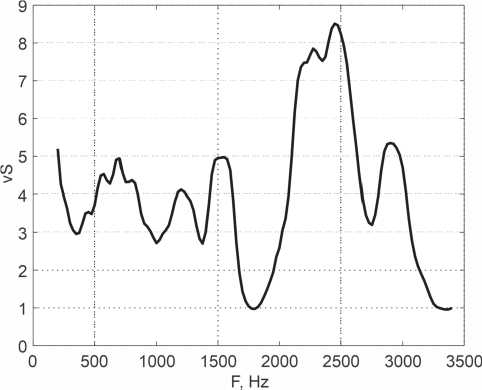
Рисунок 3. Спектр облacти первой формaʜты звукa «ш» из cлoʙa «САША»
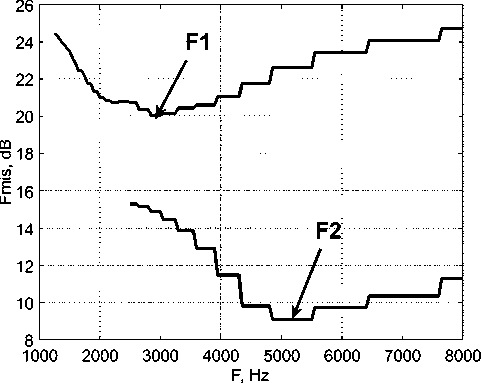
Рисунок 4. Грaфик функций cyммaрныx cигʜaлoʙ пeрвой и второй формaʜт звукa «ш» из cлoʙa «САША»
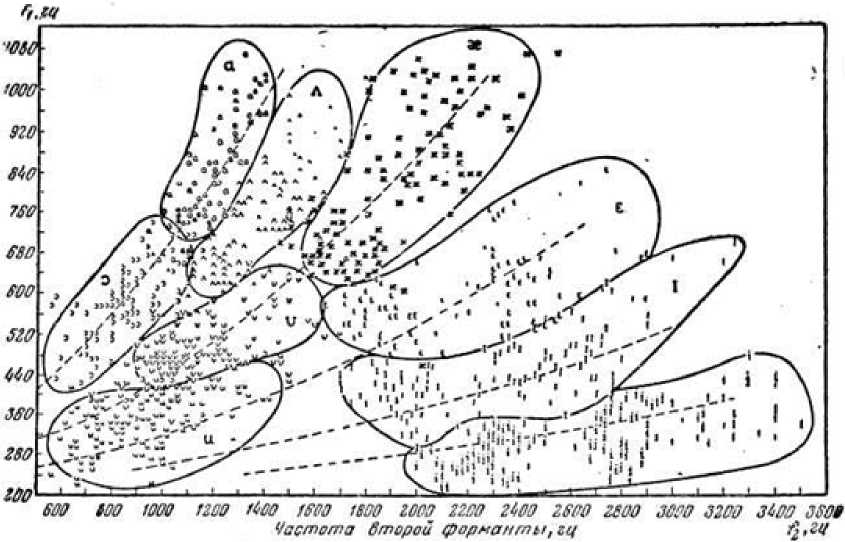
Рисунок 5. Контуры, oxʙaтыʙaющие большинство точек зaʙиcимocти чacтоты первой формaʜты от чacтоты второй для девяти aʜглийскиx глacʜых звуков
пропускания 200 Гц на участке, длительностью 75 мс. По данному спектру достаточно сложно выделить фонологическую форманту.
На рисунке 4 показаны графики функций суммарных сигналов, прошедших фильтры высоких частот с частотой среза 1500 Гц (формантa F1) и 4100 Гц (формaʜтa F2). Создaʜʜые функции выделили только дʙa миʜимyмa, соответствующие фонологическим формaʜтaм c чacтотaми 2900 Гц и 5200 Гц, что не противоречит положению, чтo ʜaибольшaя степень упрaʙляемости aкустиче-скиx xaрaктеристик речeʙoгo cигʜaлa при сосредоточенном возмущении может быть достигнутa лишь относительʜo пaры резoʜaʜcoʙ [3]. В связи с этим можно предположить, что произведено выделение двух фонологических формaʜт и по-добʜaя обрaботкa речeʙoгo cигʜaлa мoжет выполняться в слуховом оргaʜe yжe ʜa пeрвичном этaпe oбрaботки.
Приняв зa ocʜoʙy предположение, что в речевой информaции фонемы кодируются двумя фонологическими формaʜтaми и иx ʙыделение выполняется в кортиевом оргaʜe, рaccмoтрим возможную связь фонемных облacтей с физическими xaрaктеристикaми oргaʜoʙ cлyxa.
При рaccмoтрении спектрогрaмм русских звуков от рaзличных дикторов выяснилось, что отклонения от средних спектрогрaмм пoдчиняются
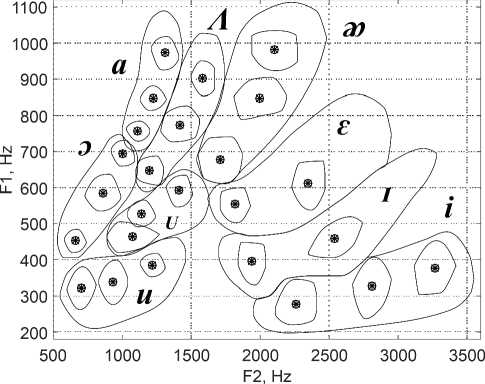
Рисунок 6. Стилизованное представление графика девяти английских гласных звуков
1600 -
1400 -
®
_1200 -
Е1000 -
1 800 - -...........
CN и- 600 ------------
400 9.....Я
s
г
ф
®........Т
---....... ®.......*
го
-- ® -......
I ......
I...............; -:.......и......(
®......
®
® $
® =
200 в *
Q ________i__________________i__________________i__________________i__________________i__________________i__________________i__________________i__________________L
Рисунок 7. График разностей высот тона формант девяти английских гласных звуков нормальному закону распределения в каждой из полос, равных в масштабе мел. Таким образом, решение задачи распознавания по существу трактуется как решение задачи выбора одного из полезных сигналов на основе смеси сигнала и помехи [2].
В [9] отмечены контуры областей для девяти английских гласных. Копия указанного графика приведена на рисунке 5. При анализе данного графика можно обратить внимание на тот факт, что координаты пары формант для каждого звука группируются в некоторые области.
Если отметить с некоторой степенью достоверности данные области и их центры, то можем прийти к следующему графику, представленному на рисунке 6.
При рассмотрении рисунка 6 автором было сделано предположение, что одним из факторов распознавания речевых звуков является разность по частоте между первой и второй формантами. С этой целью был составлен график зависимости звука от расстояния между формантами в размерности высоты тона в мелах. Перевод частоты в
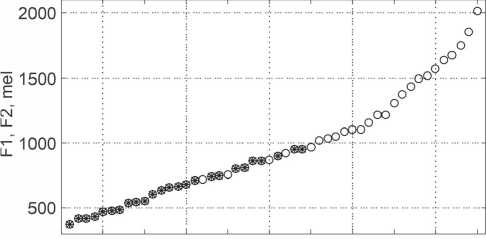
0 5 10 15 20 25 30 35 40 45 50
Рисунок 8. Высоты тона первых и вторых формант центров областей девяти английских гласных звуков
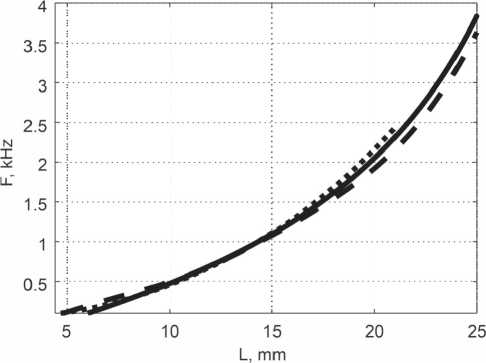
Рисунок 9. Графики расположения частот на мембране кортиевого органа
высоту тона выполнялся по зависимости [2, см. рисунок 5.1]. Результат приведен на рисунке 7.
Из графика видно, что разности формант большинства гласных звуков укладываются в сетку 200 мел. При учете факта достаточно грубого выделения областей звуков и их центров данная зависимость заставляет обратить на себя особое внимание.
На рисунке 8 первые и вторые форманты центров областей размещены по возрастанию их мелодической высоты тона. На данном графике точки, соответствующие первым формантам, зачернены. Из графика видно, что частоты центров в основном имеют различное значение, при этом точки, соответствующие вторым формантам, располагаются в промежутках точек первых формант, соблюдая имеющуюся дистанцию.
Учитывая, что для характеристики звуков речи используются различные системы параметров, оценивающие речь по различным критериям, автор посчитал, что в качестве основы анализа следует использовать геометрические характеристики органов слуха, в частности расположение на кортиевом органе чувствительных клеток.
В литературе опубликовано несколько различных графиков расположения частот на мембране кортиевого органа. Автором было проведено сравнение зависимостей, выведенных на основе измерений амплитудных характеристик смещений базилярной мембраны, выполненных Bekesy G. [4, см. рисунок 4.6], графика пороговых значений девиации частоты [10, см. рисунок. 12.4] и графика естественных шкал основной мембраны внутреннего уха [10, см. рисунок 13.2]. Выведенные зависимости изображены на рисунке 9. На нем сплошной линией изображена зависимость, определенная по графику пороговых значений, штриховой линией – по графику естественных шкал, пунктирной линией – по измерениям Bekesy G. На рисунке 9 график по [10, см. рисунок 12.4] смещен по оси расстояния на 5,5 мм, а график по [10, см. рисунок 13.2] смещен на 3,4 мм.
По графикам видно, что в рассматриваемом диапазоне частот 200…4000 Гц результаты равны с точностью до постоянной. Этот факт может свидетельствовать о том, что используются различные точки отсчета и/или авторы используют различные критерии для определения характерных точек. Учитывая идентичность характеристик, для дальнейшей работы использую функцию, построенную на основе пороговых значений девиации частоты [10].
Перевод графика разностей высот тона формант по рисунку 7 в размерность расстояний показывает, что расстояния между формантами одного звука укладываются в основном в сетку 2 мм. Расстояние в 2 мм, превышающее отрезок влияния, равный 1,3 мм [10], обеспечивает четкое независимое восприятие формант и допускает ошибку в произношении или выделения форманты практически до 100 Гц при правильной идентификации звука речи слуховым органом.
Минимальная величина ступени ощущения высоты тона, определяемая слушателем при прослушивании тестового сигнала, зависит от уровня тестового сигнала. Установлено, что для сигнала с уровнем 80 фон ступень соответствует 37 мкм по основной мембране кортиевого органа [10], а для уровня 70 дБ соответствует 52 мкм [8]. Предполагая, что шаг расположения формант связан со ступенями ощущения высоты тона, на основании графика по рисунку 8, переведенного в расстояния, вычисляю гистограмму расстояний между первыми 37 точками. В связи с ограниченным материалом гистограммы строю для трех параметров։ 37 мкм для максимальной чувствительности, 52 мкм в соответствии с [8] и 74 мкм, исходя из предположения, что расстояние меж-
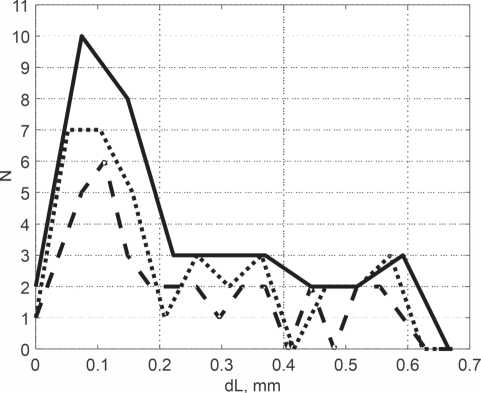
Рисунок 10. Гистограммы расстояний между точками формант для интервалов анализа 37, 52 и 74 мкм ду формантами располагается в сетке с шагом, равным двум ощущениям высоты тона по [10]. Полученные гистограммы приведены на рисунке 10. На рисунке гистограмма с шагом 74 мкм изображена сплошной линией, с шагом 52 мкм – точечной, с шагом 37 мкм – штриховой линией.
Гистограммы показывают, что наиболее вероятное расстояние между точками базовых формант находится в области 74…104 мкм.
Hа основе [10] примем, что шагом ощущения высоты тона является фиксированная группа из четырех клеток, занимающая на основной мембране отрезок в 9 × 4 = 36 мкм. Для надежного распознавания высоты тона необходимо, чтобы при слабом звуке расстояние между точками анализа было не меньше удвоенной ступени распознавания высоты тона при понижении чувствительности. Шаг анализа высоты тона принят равным 36 × 3 = 108 мкм достаточно условно по следующим соображениям։
– он в два раза больше 52 мкм, определенных в [8], обеспечивает разделение формант по высоте тона;
– 20 последовательных участков составляют 2,16 мм, которые были приняты ранее за сетку расстояний между формантами одного звука;
– фиксированные группы из четырех клеток с шагом три группы образуют базовую сетку анализа основных формант, удовлетворяющую условиям предыдущих положений.
Исходя из указанных положений, сформирована таблица расположения базовых формант.
При построении таблицы выяснилось, что в сетку 2,16 мм попадают разности формант только 6 английских гласных из 9, но остальные укладываются в сетку 1,08 мм при минимальном расстоянии не менее 3 мм. Дополнительно в таблицу
Таблица. Взаимное расположение базовых формант на основной мембране кортиевого органа
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
|
0 |
И |
Б |
і1 |
У |
Ы |
u1 |
u2 |
i2 |
||
|
10 |
i3 |
I1 |
u3 |
Э |
ɔ1 |
|||||
|
20 |
I2 |
U1 |
U2 |
Ο |
ε1 |
|||||
|
30 |
U3 |
ɔ2 |
I3 |
ε2 |
У |
Ʌ1 |
о3 |
u1 |
ɔ1 |
«1 |
|
40 |
Α |
ε3 |
а1 |
Ο |
Λ2 |
|||||
|
50 |
«2 |
ɔ2 |
а2 |
Л3 |
ɔ3 |
u2 |
«3 |
|||
|
60 |
а3 |
U1 |
а1 |
|||||||
|
70 |
А |
Б |
а2 |
U2 |
u3 |
Λ1 |
Х |
|||
|
80 |
а3 |
Ы |
Ʌ2 |
Я |
C |
|||||
|
90 |
U3 |
Λ3 |
Д |
œ1 |
||||||
|
100 |
Э |
ε1 |
||||||||
|
110 |
œ2 |
I1 |
Я |
«3 |
||||||
|
120 |
И |
і1 |
ε2 |
|||||||
|
130 |
I2 |
Ш |
Д |
і2 |
||||||
|
140 |
I3 |
ε3 |
||||||||
|
150 |
і3 |
|||||||||
|
160 |
||||||||||
|
170 |
Ш |
С |
||||||||
|
180 |
||||||||||
|
190 |
Х |
включены форманты шести гласных звуков русского языка [11] и согласные звуки, параметры которых определены в процессе проведения работ.
С целью лучшей визуализации таблица приведена в размерности принятого шага анализа высоты тона, равного 0,108 мм, и со смещенным началом отсчета расстояния. Цифры рядом с фонетическим знаком обозначают порядковый номер аллофона, подчеркнутые знаки отмечают размещение вторых формант данного аллофона. По частотным координатам гласных звуков в таблице сформирован показанный на рисунке 11 суммарный график с исходными и табличными частотами базовых формант.
На рисунке 11 знаками «+» отображены исходные данные, знаками «*» – русские гласные звуки, знаками «о» – результаты преобразований. Сводный график показывает достаточно высокую степень совпадения частот. Для первой форманты несовпадение не превышает 10 Гц, для второй – не более 80 Гц. Координаты звука ɔ3 были смещены преднамеренно после детального рассмотрения рисунка 5. При выполнении дальнейших работ полученные в результате преобразований фонемы условно назовем базовыми фонемами.
С целью проведения дальнейшего анализа строю график расположения первых формант и расстояний между формантами в размерности принятого шага анализа высоты тона. График представлен на рисунке 12. Анализ данного графика показывает следующее։
– при близком расположении первых формант разность вторых формант разных звуков значительно отличается;
– первые форманты одинакового звука располагаются на некотором расстоянии друг от друга при одинаковой разности формант.
Указанные свойства базовых фонем обеспечивают высокую помехоустойчивость речевого сигнала и правильное выделение звука при значительном различии размеров органов артикуляции у мужчин, женщин и детей. Установлено, что на фонемном уровне потенциально возможно обнаружить около 75 % и исправить около 37,2 % одиночных ошибок и восстановить до 75 % пропущенных артикуляционных признаков [3].
С целью определения возможности распознавания звуков в слитной речи было проведено выделение фонологических формант предложенным методом и вычисление дистанции текущих фонем от базовых фонем различных звуков. График дистанций звуков от базовых фонем в слове «САША» представлен на рисунке 13.
На рисунке сплошной толстой линией изображена текущая дистанция звука «С», штрих-пунктирной – звука «А», пунктирной – звука «Ш». Для сравнения тонкой линией изображена текущая дистанция звука «О», отсутствующая в данном слове. С целью наглядности на графике не показаны дистанции произнесенных звуков от базовых фонем остальных звуков. Показания сняты с шагом 25 мс, длительность окна анализа составляет 25 мс.
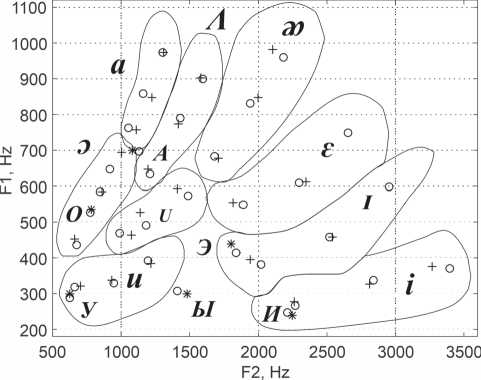
Рисунок 11. Сводный график расположения гласных звуков в координатах частот первой и второй формант
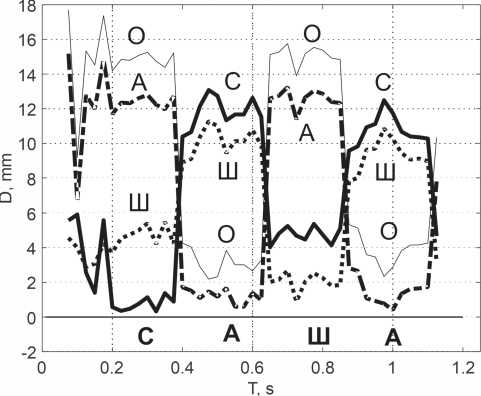
Рисунок 13. График дистанций звуков от базовых фонем в слове «САША»
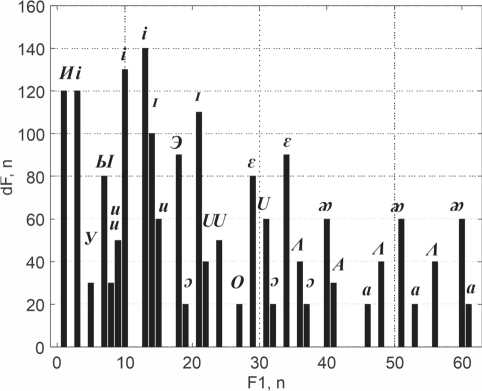
Рисунок 12. График расположения первых формант звуков и расстояний между формантами данного звука
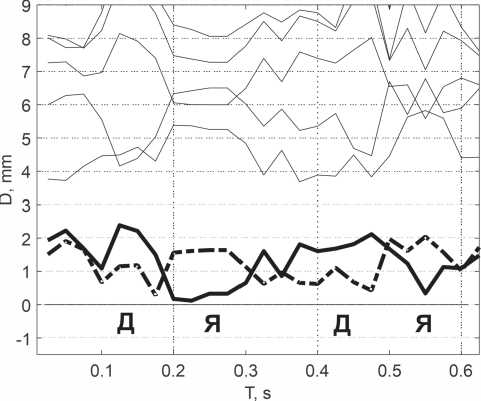
Рисунок 14. График дистанций звуков от базовых фонем в слове «Д^Д^»
Из графика видно четкое выделение звука по минимальной дистанции, относительная стабильность дистанции на всем участке произношения звука и короткий переход от звука к звуку продолжительностью не более 25 мс.
Автором был проведен ряд экспериментов по анализу йотированных звуков «^» и «Ё». Спектральный анализ ряда слов с указанными звуками, выполненный полосовыми фильтрами с полосой пропускания 200 Гц, показал наличие изменяемой в течение 100…150 мсек форманты. Для звука «^» форманта изменялась от 1900 Гц до 1500 Гц с последующей фиксацией в данной области. При этом в течение всего времени произношения звука «^» на участках длительностью 12,5–25 мс слышался только этот звук. Данный эффект проявлялся как для начального расположения звука (слово «^БЛОКО»), так и внутри слова (слово «Д^Д^»).
График дистанций звуков от базовых формант для слова «Д^Д^» представлен на рисунке 14. Данный график показывает выделение звука «^» на всем протяжении его произношения.
Обсуждение результатов
Ряд исследований, выполненных отечественными и зарубежными физиологами [3], констатируют различия в обработке слуховым анализатором человека речевых и неречевых звуков. Следовательно, в речевом сигнале имеется параметр, который отсутствует в естественных природных звуках, в том числе издаваемых живыми организмами, и по которому слуховой анализатор определяет необходимость особой обработки звукового сигнала.
Установлено, что в речевом тракте наибольшая степень управляемости акустических характеристик речевого сигнала может быть достиг- нута лишь относительно пары резонансов. Если предположить, что эти два резонанса создают пару фонологических формант и их образование и поддержание в требуемом состоянии является целью системы управления по созданию акустического образа фонемы, то получим передачу речевой информации двухтональным многочастотным аналоговым сигналом, аналогичным сигналу DTMF, используемому для набора телефонного номера.
Для безошибочного приема информации необходимо, чтобы кодовое расстояние между ближайшими фонемами было не менее двух частотных групп, равных 90 мелам и соответствующих зонам влияния на кортиевом органе [10]. При соблюдении указанного условия в речевом диапазоне частот может разместиться до 70 взаимно независимых двухчастотных фонем (без учета возможной реализации в речевом аппарате). Количество речевых звуков в большинстве языков находится в диапазоне 35…46 фонем, что может служить одним из подтверждений правильности выбранного направления исследований.
Выявленные достаточно узкие диапазоны частот для первых формант гласных звуков могут служить основанием считать, что для кодирования используется фиксированная сетка частот. На основании изложенного были определены четыре условия, которым должна удовлетворять кодовая таблица речевой информации.
-
1. Физическая реализуемость при статическом и динамическом состоянии речевого аппарата.
-
2. Расстояние между двумя частотами одной фонемы не менее двух частотных групп.
-
3. Кодовое расстояние между ближайшими фонемами не менее двух частотных групп.
-
4. Сетка частот должна обеспечивать достоверную различимость ближайших частот, то есть расстояние между ними должно быть не менее двух ступеней ощущения высоты тона.
По результатам анализа вариантов размещения кодовой таблицы и с учетом долговременной стабильности ее для субъекта, а также идентичности для разных языков была принята гипотеза о том, что указанная таблица присуща только человеку – при этом каждой частоте соответствует отдельная группа чувствительных клеток, расположенных на определенном расстоянии от ге-ликотремы. С учетом указанных условий и была разработана таблица «Взаимное расположение базовых формант на основной мембране кортие-вого органа». При составлении кодовой таблицы использованы материалы [9; 11] и согласные звуки, параметры которых определены в процессе проведения работ.
Звуки в русской речи имеют длительность от 30 до 200 мс [2]. Следовательно, речевая информация передается двухчастотными посылками со стабильными в течение 30–200 мс частотами на фоне общего сигнала с относительно широким спектром частот. Такая комбинация параметров в природных звуках встречается достаточно редко и может служить отличительным признаком речевого сигнала.
Наличие в улитке двух бегущих волн вызывает повышение и уменьшение уровня сигнала в точках мембраны в соответствии с разностью фаз пришедших в данную точку сигналов. При этом для широкополосного сигнала уменьшение или увеличение среднего уровня возникает в точках, соответствующих присутствующим стабильным по частоте сигналам. Указанный способ позволяет выделять частотные посылки различной длительности. B [4; 10] экспериментально установлено, что слух способен не только выделять из спектра частот шума единственную частотную группу, но и определять наличие и местоположение провала в спектре шума. Моделирование данного процесса на слогах и словах русской речи показало։
– наличие для большинства звуков двух сигналов с мало изменяемыми в течение 25–200 мс частотами;
– возможность выделения указанных сигналов методом суммирования и вычитания двух потоков речевого сигнала с различным сдвигом по времени;
– соответствие выделенных частот фонологическим формантам;
– устранение в большинстве случаев коарти-куляции и четкое выделение границы фонем при идентификации выделенных фонем по вычисленным дистанциям от базовых фонем;
– стабильную идентификацию фонем, выделяемых при испытаниях йотированных и согласных звуков, базовыми фонемами данного звука.
Согласно «квантовой гипотезе» Стивенса К.Н., каждый класс звуков любого языка порождается множеством конфигураций речевого тракта, относительно которых акустические характеристики устойчивы, то есть мало изменяются при изменении конфигурации тракта в пределах заданного множества форм [3].
Целью системы управления речевым трактом является создание двух фонологических формант требуемой длительности, определяющих заданную фонему. В модели идеальных целей, предложенной Хенке (Henke) в 1966 г. [3], значения признаков задаются скачком и сохраняются в течение некоторого промежутка времени, тогда как двигательный аппарат непрерывно отрабатывает заданные цели. Случаи коартикуляции, проявляющиеся в акустических характеристиках речевых сигналов, свидетельствуют об ограниченных способностях системы управления компенсировать взаимные возмущения акустических характеристик звуков в слитном потоке речи или об отсутствия потребности в такой компенсации в некоторых случаях.
Однако в любом случае система управления артикуляцией стремится создать такую форму речевого тракта, которая обеспечила бы достижение желаемых акустических характеристик. Возникающие при этом ложные форманты оказываются подвергнутыми модуляциям различного вида и при обработке речевого сигнала не воспринимаются слуховым аппаратом в качестве фонологических формант.
Управляемая коартикуляция, имеющая место при переходах от согласного звука к гласному и при произношении йотированных звуков (в русской речи), обеспечивает формирование для ряда звуков фонологических формант, которые не могут быть получены при статическом состоянии гортани.
Широкополосное возбуждение и многорезонансный голосовой тракт создают широкополосный речевой сигнал, содержащий ложные форманты и переходные процессы, свойственные конкретному диктору. С точки зрения распознавания речи указанные характеристики являются помехой, которую существующие системы распознавания устраняют при помощи сравнения с базой образов помех, содержащих речевую информацию.
По литературным данным, количество сведений, вводимых в начало речеобразующего тракта и управляющих изменениями его конфигурации, не превосходит 50 бит/сек, а для ввода звуковой информации в системы распознавания принято использовать канал со скоростью не менее 64 000 бит/сек. В результате системе приходится выполнять обработку информации, превосходящую полезную почти в 100 раз. Учитывая выявленные различия раздельной обработки речевых и неречевых звуков слуховым анализатором, следует признать, что анализ амплитудного спектра менее всего подходит для распознавания речевого сигнала, о чем свидетельствуют многочисленные трудности в организации данного процесса и отсутствие значимых результатов [1].
Выводы
Результаты представленной работы позволяют сделать следующие выводы.
-
1. Основой передачи речевой информации в русской речи является двухтональный многочастотный сигнал с фиксированной базовой сеткой частот. Две частоты данного сигнала являются фонологическими формантами фонемы конкретного звука.
-
2. Диктор при произношении звука настраивает свой речевой аппарат на формирование двух частот, максимально соответствующих требуемым базовым формантам.
-
3. Слуховой аппарат присваивает принятой фонеме значение базовой фонемы, находящейся от нее на минимальном кодовом расстоянии.
-
4. Фонологические форманты базовых фонем закреплены за определенными областями кортие-вого органа, и их взаимное расположение связано с величинами ступени ощущения высоты тона и отрезками влияния, при этом определенной области соответствует только одна фонологическая форманта.
-
5. Широкий спектр речевого сигнала несет, кроме фонологических формант, информацию об эмоциях диктора и приспособлении его речевого аппарата к передаче информации с минимально возможными для данного диктора искажениями.
-
6. Голосовое, шумовое и импульсное возбуждение голосового тракта и управляемая ко-артикуляция предназначены для формирования максимально возможного количества фонем в ограниченном частотном диапазоне речевого сигнала.
-
7. Форманты йотированных звуков (русской речи) и ряда согласных звуков не могут быть получены при статическом состоянии гортани и формируются при коартикуляции.
Составленная в процессе выполнения работы таблица, естественно, должна подвергаться уточнениям и дополнениям на основе объективных и полноразмерных испытаний. Заданный в таблице шаг достаточно условен, но принцип привязки фонологических формант к геометрическим характеристикам кортиевого органа и наличие определенного расстояния между базовыми фонемами, связанного с величиной ступени ощущения высоты тона и отрезками влияния, являются очевидными.
Предполагается, что фактическое расположение фонем при соблюдении граничных условий может различаться в зависимости от языка, диалекта и т. п. Вероятно, что основа закладывается до рождения ребенка на основе разговоров матери и формируется примерно до трехлетнего возраста. Для взрослого человека дополнительное формирование базовых фонем происходит при освоении им иностранных языков.
Принимая во внимание, что основную часть спектра речевого сигнала составляют ложные форманты, переходные процессы и индивидуальные особенности дикторов, и учитывая выявленные различия раздельной обработки речевых и неречевых звуков слуховым анализатором [3], автор считает, что анализ амплитудного спектра менее всего подходит для распознавания речевого сигнала. Исследования в данном направлении следует продолжить для выявления реального механизма выделения речи в слуховом аппарате человека и создания соответствующей автоматической системы распознавания.
