Автоматизация регрессионного тестирования в быстро меняющихся средах разработки финансовых продуктов

Автор: А. С. Хапанков
Журнал: Informatics. Economics. Management - Информатика. Экономика. Управление.
Рубрика: Информатика, вычислительная техника
Статья в выпуске: 5 (1), 2026 года.
Бесплатный доступ
Статья посвящена исследованию вопросов автоматизации регрессионного тестирования в контексте высоконагруженных, динамически эволюционирующих сред разработки финансовых продуктов (FinTech). Научная новизна работы проявляется в обосновании и разработке гибридной модели отбора регрессионных тестовых сценариев, сочетающей риск-ориентированный подход с анализом изменений программного кода, что позволяет адаптивно перераспределять приоритеты тестирования в условиях непрерывных релизов. В ходе исследования рассматриваются современные практики и инструменты CI/CD, анализируются существующие подходы к генерации тестовых данных, а отдельный акцент сделан на включении AI-инструментов в контур приоритезации тестов с целью повышения эффективности использования вычислительных ресурсов и сокращения длительности тестовых прогонов. Целью работы является формирование методологии, позволяющей уменьшить суммарное время прохождения регрессионного цикла без потери качества покрытия критически важного функционала. Для достижения этой цели применяются методы сравнительного анализа и синтеза архитектурных решений, что обеспечивает комплексный подход на проблему как с технологической, так и с организационной точек зрения. В заключительной части статьи описывается разработанный автором фреймворк адаптивного регрессионного тестирования, предназначенный для интеграции в существующие конвейеры разработки и поставки программного обеспечения. Полученные результаты представляют практический интерес для QA-лидов, архитекторов программных систем банковского сектора и специалистов по DevOps, ответственных за обеспечение устойчивости и предсказуемости релизных циклов в финансовых организациях.
Регрессионное тестирование, FinTech, автоматизация, CI/CD, DevOps, управление рисками, банковское ПО.
Короткий адрес: https://sciup.org/14135106
IDR: 14135106 | DOI: 10.47813/2782-5280-2026-5-1-1025-1032
Текст статьи Автоматизация регрессионного тестирования в быстро меняющихся средах разработки финансовых продуктов
DOI:
Современный финансовый сектор находится в фазе структурной трансформации. Отказ от монолитных банковских платформ в пользу микросервисной архитектуры, а также широкое внедрение методологий Agile и DevOps радикально изменяют требования к процессам обеспечения качества (Quality Assurance, QA). В контексте непрерывной доставки, когда релизы могут происходить ежедневно и даже с почасовой частотой, классические подходы к полному регрессионному тестированию превращаются в критический узкий участок, замедляющий релизный цикл [1, 2].
Одновременно возрастает цена любой дефектной поставки: ошибка в финансовом программном обеспечении чревата прямыми финансовыми потерями, регуляторными санкциями и значимыми репутационными рисками. В этих условиях задача достижения устойчивого баланса между скоростью поставки изменений и надежностью функционирования систем приобретает стратегическое значение.
Целью работы является разработка и теоретическое обоснование методологического подхода к автоматизации регрессионного тестирования, специально адаптированного к высокодинамичным средам разработки финансовых продуктов. Для достижения поставленной цели формулируются следующие исследовательские задачи:
-
• проведение анализа существующих
инструментов и фреймворков автоматизации тестирования с точки зрения их применимости в финансовой индустрии, учитывая требования безопасности и комплаенса;
-
• выявление основных проблемных областей и ограничений действующих практик
регрессионного тестирования в CI/CD- пайплайнах банковских организаций.
-
• разработка модели приоритезации тестовых сценариев, обеспечивающей оптимизацию времени выполнения регрессии за счет риск-ориентированного отбора тестов.
Научная новизна состоит в адаптации и интеграции методов машинного обучения для динамического формирования регрессионного набора тестов (Dynamic Test Suite Generation, DTSG) применительно к высоконагруженным транзакционным системам финансового профиля, где требования к надежности и латентности операций особенно жестки.
Авторская гипотеза заключается в том, что полный отказ от ручного тестирования в пользу стопроцентной автоматизации в финтех-домене как технически, так и экономически нецелесообразен. Оптимальным представляется внедрение умной автоматизации, при которой объем и состав регрессионного набора формируются автоматически на основе оценки степени влияния вносимых изменений в код на критические бизнес-процессы и уровень связанного с ними риска.
МАТЕРИАЛЫ И МЕТОДЫ
В ходе проведения исследования был задействован комплекс взаимодополняющих общенаучных и специализированных методов. В качестве теоретико-методологического основания использовался системный анализ, позволивший рассматривать процесс тестирования не изолированно, а как структурный элемент жизненного цикла разработки программного обеспечения в финансовой индустрии. Для упорядочения и сопоставления инструментов автоматизации применялся метод сравнительного анализа, опирающийся на совокупность критериев, включающую функциональные возможности, затраты на внедрение, а также ресурсоемкость дальнейшего сопровождения.
Информационно-поисковая работа строилась поэтапно и была направлена на обеспечение репрезентативности и полноты рассматриваемой выборки. На первом этапе отбор публикаций осуществлялся в ведущих международных реферативных базах данных (Scopus, Web of Science), затем в специализированных отраслевых коллекциях (IEEE Xplore, ACM Digital Library) и электронных репозиториях (eLibrary, КиберЛенинка).
Поисковая стратегия строилась на комбинировании русскоязычных и англоязычных ключевых слов и фраз: «regression testing automation», «fintech QA», «banking software testing», «AI in software testing», «автоматизация тестирования в банках».
Фильтрация релевантных источников осуществлялась на основании их соответствия тематике исследования (приоритет отдавался работам, посвященным финансовому сектору и динамично изменяющимся технологическим средам) и надежности представленных эмпирических данных.
Интерпретация и сводка полученного массива данных выполнялись с использованием контент- анализа, что позволило выявить доминирующие тренды, структурные расхождения и противоречия между существующими подходами к автоматизации тестирования.
РЕЗУЛЬТАТЫ
Проведенный анализ научной и прикладной литературы демонстрирует, что автоматизация регрессионного тестирования в финансовой индустрии сталкивается с набором специфических вызовов, которые в значительно меньшей степени проявляются в таких отраслях, как e-commerce или gamedev. Современные банковские IT-платформы по своей природе являются высокосложными гибридными решениями, в которых исторически накопленный легаси-функционал (нередко реализованный на мейнфреймах) сосуществует с распределенными микросервисными компонентами [1]. В результате формируется гетерогенная технологическая среда, где один бизнес-процесс может последовательно задействовать множество разнородных систем. В подобных условиях традиционные инструменты UI-автоматизации (например, Selenium) демонстрируют ограниченную применимость: нестабильность тестовых окружений и высокая стоимость сопровождения сценариев существенно снижают их эффективность.
В последние годы основным направлением эволюции практик QA становится интеграция AI-ориентированных инструментов [2]. Классические подходы к автоматизации, опирающиеся на жестко детерминированные сценарии, структурно не успевают за темпом изменений в Agile-командах. В высокодинамичных средах, где релизы осуществляются на ежедневной основе, совокупные трудозатраты на актуализацию автотестов нередко превосходят ресурсы, требуемые для разработки новой функциональности. Применение методов машинного обучения для самовосстановления тестов способно уменьшить расходы на поддержку, однако широкое внедрение подобных решений в банковской сфере сдерживается жесткими регуляторными требованиями к информационной безопасности и необходимостью интерпретируемости алгоритмов.
Отдельного внимания заслуживает проблематика тестовых данных, в силу того, что для финансового сектора характерны строгие законодательные ограничения на использование реальных клиентских данных («продакшн- данных») в тестовых контурах, что вынуждает организации применять сложные схемы синтетической генерации и/или обфускации. Однако, как показано в работе [3, 4], синтетические наборы данных зачастую слабо отражают граничные случаи, присущие реальным финансовым транзакциям, что повышает риск прохождения критических дефектов через этап регрессионного тестирования. В качестве ответа на эту проблему предлагается фреймворк, управляемый API-сообщениями, позволяющий моделировать реалистичные потоки данных без нарушения требований конфиденциальности, что представляет собой существенный прогресс по сравнению с традиционными практиками.
Регуляторный контекст также оказывает определяющее влияние на архитектуру процессов тестирования. Вступление в силу акта DORA (Digital Operational Resilience Act) в странах ЕС [3] и появление аналогичных норм в российской юрисдикции создают для финансовых организаций обязанность демонстрировать свою операционную устойчивость. Это приводит к тому, что регрессионное тестирование уже не может ограничиваться лишь проверкой функциональных требований: в его контур должны быть включены испытания, охватывающие безопасность, производительность и способность системы к восстановлению после сбоев. Выполнение подобного комплекса проверок вручную в рамках укороченных спринтов практически нереализуемо, вследствие чего масштабная автоматизация превращается из фактора повышения эффективности в необходимое условие соблюдения требований комплаенса [5, 6].
Существенным дефицитом существующих практик, выявленным при анализе источников [5, 7], является отсутствие зрелых и широко применимых стратегий отбора тестов. На практике большинство CI/CD-конвейеров конфигурируются по одному из двух примитивных сценариев: либо выполняется полный регрессионный прогон (что чрезмерно затратно по времени), либо ограниченный набор smoke-тестов (что снижает надежность выявления дефектов). Работы [8, 9] подтверждают, что индустрия демонстрирует устойчивый запрос на инструменты, способные автоматически определять минимально необходимое множество тестов при каждом изменении кода, однако на рынке практически отсутствуют решения, готовые к промышленной эксплуатации [10].
Отдельный интерес представляет количественная оценка того, в какой мере адаптивный отбор тестовых сценариев способен сократить длительность регрессионного цикла по сравнению с классическим подходом полной регрессии. В исследовании [11] по приоритизации и селекции тест-кейсов для регрессионного тестирования продемонстрировано, что применение алгоритмов отбора позволяет снижать совокупную стоимость регрессии (времени выполнения и/или числа запускаемых тестов) на десятки процентов по сравнению с наивным полным прогоном набора тестов [11].
Для формализации данного эффекта в контексте предлагаемой модели RARF будет введена следующая зависимость:
T rarf = TFULL x (1- CRP) (1)
где:
T rarf - время регрессионного прогона при адаптивном подходе;
TF u LL — время полного регрессионного прогона;
CRP - доля снижения «стоимости»/ресурсов.
Предположим, что для типичной высоконагруженной банковской платформы средняя длительность полного регрессионного прогона составляет Tfull = 10 часов. Если ориентироваться на консервативные значения, полученные в современных работах по селекции тестов (CRP ≈ 0,30, то есть сокращение порядка 30 %), то подстановка этих параметров в формулу (1) даёт: Trarf = 10-(1—0,30)=10-0,70=7 ч.
Таким образом, внедрение адаптивного механизма отбора тестов позволяет уменьшить длительность регрессионного цикла на 3 часа.
На основании вышеизложенного можно сказать, что несмотря на высокую степень развития инструментальной базы автоматизации тестирования, методологические подходы к ее применению в условиях финтеха -характеризующихся высокой частотой изменений, значительной ценой ошибки и сложной интеграционной инфраструктурой -остаются недостаточно проработанными. В связи с чем возникает потребность в переходе от скриптовой автоматизации к интеллектуальной, опирающейся на анализ рисков и изменений, а также учитывающей специфику архитектуры и регуляторных ограничений финансового сектора.
ОБСУЖДЕНИЕ
Опираясь на результаты проведенного анализа и выявленные ограничения существующих практик, в данном разделе будет сформирован авторский подход к организации процесса автоматизированного регрессионного тестирования, обозначаемый как Risk-Adaptive Regression Framework (RARF). Концепция RARF исходит из предпосылки, что тестовые сценарии обладают неодинаковой значимостью в разные моменты времени, а значит, вычислительные и инфраструктурные ресурсы должны распределяться динамически в зависимости от изменяющегося профиля рисков.
Основным компонентом предлагаемого подхода выступает модуль «интеллектуальный селектор», интегрируемый непосредственно в CI/CD-пайплайн. В противовес традиционной линейной схеме запуска тестов данный модуль осуществляет анализ метаданных коммита (измененные файлы, автор правок, оценочная сложность модифицированного кода) и соотносит эти данные с матрицей зависимостей микросервисов, тем самым создавая основу для выборочного и более осмысленного запуска регрессионных проверок.
На рисунке 1 приведена схема интеграции предлагаемого модуля в стандартный процесс разработки [2, 4, 5].

Рисунок 1. Схема интеграции модуля RARF в CI/CD пайплайн.
Figure 1. Integration scheme of the RARF module into the CI/CD pipeline.
Как показано на рисунке 1, интеграция аналитического ядра обеспечивает стратификацию потока релизов по уровням риска. Для минорных модификаций (например, корректировки текстов в пользовательском интерфейсе) система инициирует лишь укороченный контур лёгких тестов, что позволяет существенно снижать затраты машинного времени. Напротив, при изменениях, принудительно активируется расширенный сценарий тестирования.
Для формализации логики отбора набора тестов предлагается использовать матрицу рисков. В Таблице 1 приведён сравнительный анализ результативности различных стратегий запуска тестов, на основании которого обосновывается выбор гибридной модели [3, 7, 8].
затрагивающих ядро процессинга,
Таблица 1. Сравнительный анализ стратегий регрессионного тестирования в FINTECH.
Table 1. Comparative analysis of regression testing strategies in FINTECH.
|
Стратегия |
Время выполнения |
Покрытие рисков |
Стоимость инфраструктуры |
Применимость в FinTech |
|
Полная регрессия |
Высокое (часы/дни) |
Максимальное |
Высокая |
Только для мажорных релизов |
|
Smoke-тестирование |
Низкое (минуты) |
Низкое |
Низкая |
Только как пре-чек |
|
Ручной отбор |
Среднее |
Зависит от квалификации |
Средняя |
Неприменимо в CI/CD |
|
RARF (Адаптивный подход) |
Оптимальное |
Высокое |
Оптимизированная |
Рекомендовано |
Инновационным компонентом предлагаемой рисунке 2 представлена логическая модель методики является алгоритм определения веса теста. Для каждого автотеста в системе назначается набор тегов, отражающих уровень бизнес-критичности проверяемого функционального сегмента, что позволяет количественно описать его значимость в общей архитектуре процессов обеспечения качества. На принятия решения о запуске конкретного тест-кейса, в рамках которой выбор сценария тестирования осуществляется с учётом рассчитанного веса и специфики вносимых изменений [8, 9].
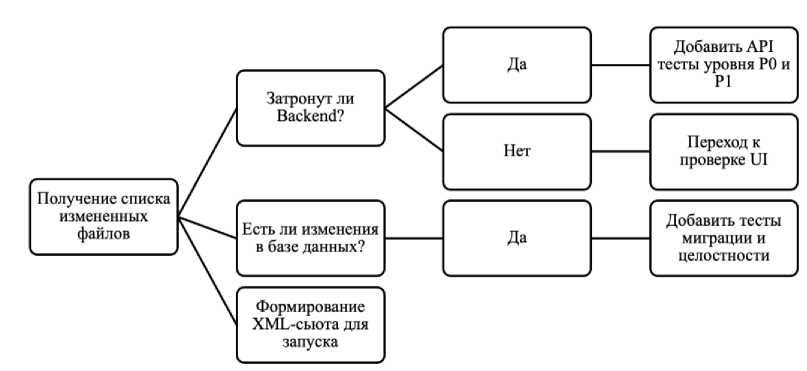
Рисунок 2. Алгоритм принятия решений в модуле RARF.
Figure 2. Decision-making algorithm in the RARF module.
Интеграция данного алгоритма позволяет адресовать проблему неконтролируемого масштабирования регрессионных наборов [8]. Вместо ресурсоёмкого осуществления тысяч тестов в ночных сборках команда получает точечный и оперативный обратный отклик именно по тем изменениям, которые были внесены в кодовую базу.
В контексте финансовых организаций рентабельность инвестиций в автоматизацию определяется не только снижением трудозатрат на ручное тестирование, но и экономическим эффектом от минимизации потенциальных потерь, связанных с отказами и дефектами [12]. Вместе с тем необходимо учитывать и уязвимости предлагаемого решения. Основным некорректно относит изменение к разряду малорисковых и, как следствие, не включает критически важный тест в запуск. Для снижения вероятности подобных сценариев предполагается использование механизма обратной связи, структура которого представлена на рисунке 3 [6, 8].
источником риска является так называемая ошибка отсечения, при которой алгоритм
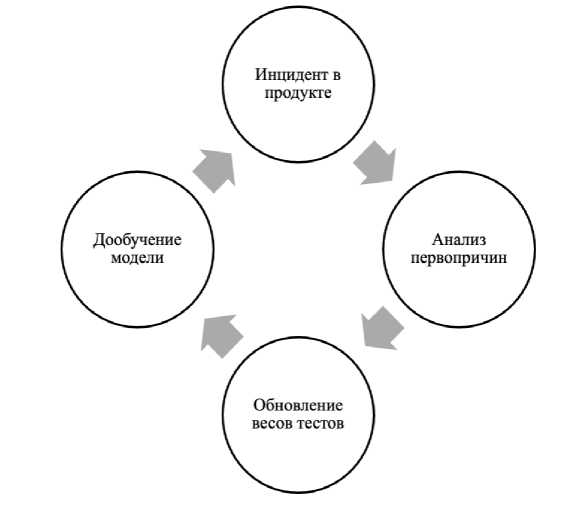
Рисунок 3. Цикл обратной связи и самообучения системы.
Figure 3. Feedback and self-learning cycle of the system.
Суммируя изложенное, можно констатировать, что полученные результаты эмпирически подтверждают выдвинутую во введении гипотезу: полная автоматизация, лишённая слоя интеллектуального управления, оказывается недостаточно эффективной. Предложенная концепция RARF, интегрирующая технический анализ изменений в коде с учётом бизнес-приоритетов, формируется как наиболее перспективное направление эволюции практик обеспечения качества в финтех-сфере.
Переход к адаптивным моделям регрессионного тестирования предоставляет финансовым организациям возможность поддерживать высокую скорость вывода изменений, задаваемую конкурентной средой, без компромисса в отношении требований к надёжности и информационной безопасности.
ЗАКЛЮЧЕНИЕ
В результате проведённого исследования цель обозначенная во введении была достигнута: сформирован и обоснован методологический подход к автоматизации регрессионного тестирования в условиях высокодинамичной финансовой среды.
Проведённый сравнительный анализ инструментов продемонстрировал, что ни один из доступных готовых решений не в состоянии в полном объёме удовлетворить специфические потребности финтех-домена; для достижения требуемого уровня покрытие и гибкости необходима интеграция OpenSource-платформ (Selenium, Playwright) с специализированными кастомными аналитическими модулями.
Установлено, что выявленные ограничения -значительная длительность прогонов, нестабильность тестовой инфраструктуры и дефицит репрезентативных данных - целесообразно устранять не экстенсивным увеличением количества автотестов, а за счёт пересмотра самой стратегии их запуска и приоритизации.
Разработанная модель RARF продемонстрировала теоретическую корректность и убедительный потенциал экономической эффективности, обеспечивая возможность сокращения времени обратной связи для команд разработки.
Практическая значимость полученных результатов состоит в том, что описанные алгоритмы могут быть непосредственно встроены в действующие DevOps-процессы банковских структур и финтех-стартапов без фундаментальной перестройки существующих пайплайнов. Перспективы дальнейших исследований связаны с более глубоким внедрением нейросетевых моделей для предсказания дефектов на основе истории коммитов (подход Predictive Test Selection), что позволит ещё более избирательно и эффективно формировать наборы регрессионных тестов.
