Извлечение именных групп из корпуса текстов на испанском языке

Автор: Бабина Ольга Ивановна, Мыларщикова Татьяна Юрьевна
Журнал: Вестник Южно-Уральского государственного университета. Серия: Лингвистика @vestnik-susu-linguistics
Рубрика: Лингвистическая философия и прикладная лингвистика
Статья в выпуске: 22 (239), 2011 года.
Бесплатный доступ
Рассматривается применение лексикалистского подхода к извлечению именных групп из корпуса патентных текстов на испанском языке. Проведено корпусное исследование именных групп в текстах патентов на аппараты, в результате которого определены синтаксические шаблоны именной группы, типичные для флективного языка, такого как испанский. Рассмотрены трудности, препятствующие повторному использованию базы знаний, разработанной для распознавания именной группы на английском языке. Расширен алгоритм распознавания именной группы, состоящий в фильтровании списка кандидатов в именные группы на основе анализа их лексических контекстов, посредством включения в него морфологического анализа флективных форм на испанском языке. Эффективность алгоритма оценивается через анализ причин ложного принятия и ложного отклонения кандидатов в ходе исполнения алгоритма.
Именная группа, извлечение информации, база знаний, лексика-листский подход, флективные языки, испанский язык, синтаксические шаблоны, контекст, предметная область, корпусное исследование
Короткий адрес: https://sciup.org/147153760
IDR: 147153760 | УДК: 811.135.2'33
Noun phrase extraction from a Spanish corpus
The article investigates the application of a lexicalist approach to the extraction of noun phrases from the corpus of Spanish patent texts. A corpus-based research into noun phrases in texts of patents for apparatuses is undertaken which results in formulation of syntactic patterns of a noun phrase typical of an inflectional language, such as Spanish. Difficulties hampering the complete reuse of the knowledge base, compiled for English noun phrase recognition, are investigated. The algorithm of noun phrase recognition consisting in filtering a list of candidates for noun phrases on the basis of the analysis of their lexical contexts has been enhanced by integrating morphological analysis of inflectional forms in Spanish. The performance of the algorithm is evaluated by analyzing the causes of false acceptance and false rejection of candidates.
Текст научной статьи Извлечение именных групп из корпуса текстов на испанском языке
Автоматическое понимание текстов является необходимой частью разнообразных прикладных задач. Локальное понимание, включающее интерпретацию отдельного предложения с сохране- нием синтаксических связей1, является необходимой базой для системы автоматической обработки текста.
Для конструирования информационной системы, в которой реализован компонент локального
Tatiana Yu. Mylarshchikova. Post-graduate student of the Department of Linguistics and Cross-Cultural Communication, South Ural State University (Chelyabinsk). E-mail: tatiana. mylarshchikova@ gmail.com понимания, необходимо моделирование семантического компонента. Придерживаясь теории семантических ролей (падежей)2, локальное понимание в нашем исследовании трактуется как идентификация предикатно-актантной структуры предложения.
На поверхностно-синтаксическом уровне актанты, заполняющие семантические роли предикатов, в большинстве случаев выражены именными группами (группами существительного), поэтому распознавание именной группы (ИГ) и разграничение в тексте ИГ, выполняющих различные роли, является важнейшей задачей для обеспечения локального понимания входного текста компьютером.
Очевидно, в языке именная группа является достаточно сложным объектом. В различных языках, чаще всего, можно определить набор типичных структур именных групп в терминах частей речи (грамматически) и лексических единиц (лек-сикалистский подход), чаще всего представляющих закрытые классы слов3. Так, некоторые типичные шаблоны именных групп в различных языках представлены в табл. 1 (в нижних индексах указаны релевантные для согласования элементов ИГ грамматические признаки).
В различных языках структура именных групп имеет существенные отличия. Так, например, в романских языках определение, выраженное прилагательным, ставится после определяемого слова, а в германских и славянских языках перед ним; аналитический английский язык имеет менее выраженную систему морфологических категорий в отличие от флективных языков; во флективных языках происходит согласование по грамматическим признакам, однако в силу различий в грамматической системе языков набор признаков, по которым согласуются члены именной группы, также отличается.
Лингвистические особенности именной группы, а также статистические данные о функционировании именных групп в тексте являются основой для моделирования методов автоматического извлечения словосочетаний из текста.
Подходы к автоматическому извлечению словосочетаний из текста
В целом, выделяется два основных подхода для решения задачи извлечения ИГ из текста. Рационалистический подход, заключающийся в составлении шаблонов для идентификации именных групп в определенном языке в тексте, дает возможность выявить актанты. Однако, как правило, разработка базы знаний для такой системы является трудоемкой задачей. Во-первых, необходимо составить спектр возможных шаблонов ИГ, который тем не менее может оказаться неполным. Составление шаблонов требует тщательного анализа корпуса текстов вручную или морфологосинтаксическую разметку корпуса (с последующей автоматизацией извлечения шаблонов) - и то, и другое требует значительных трудозатрат.
Во-вторых, для применения шаблонов к корпусу необходимо составление лексикона, включающего все лексические единицы с соответствующими им морфологическими метками. В случае если в процессе идентификации именной группы по шаблону система встретит незнакомое слово (которое не будет иметь морфологической метки), алгоритм извлечения именной группы по шаблону окажется ненадежным, так как не сможет обработать этот случай.
В-третьих, в некоторых случаях набор лексико-грамматических категорий шаблона, репрезентирующий одну именную группу, неотличим от нескольких именных групп, расположенных контактно друг с другом. В аналитических языках, очевидно, для разрешения подобной однозначности не обойтись без учета семантических характеристик предиката, от которого зависят актанты. Во флективных языках в силу достаточно разветвленной системы морфологических категорий и формальных показателей (флексий) значительную помощь в разграничении групп могут оказать грамматические признаки, имеющие формальное выражение в лексических единицах соответствующих лексико-грамматических категорий.
Попытка преодоления некоторых из этих недостатков состоит в использовании статистических методов, основой которых является оценка типичного для лексической единицы контекста ее употребления4. Эмпирический подход дает возможность основываться на данных текста и не требует, как правило, больших затрат для разработки базы знаний. Однако способ принятия решений в таких алгоритмах не всегда прозрачен в том смысле, что результат работы иногда сложно интерпретировать лингвистически. Кроме того, статистические алгоритмы редко учитывают особенности лингвистической структуры ИГ и «особые» языковые случаи, которые нередко встречаются в естественном языке.
В целом, проблема извлечения ключевых слов остается нетривиальной задачей, поэтому для ее решения чаще всего привлекаются гибридные
Таблица 1
|
Язык |
Синтаксическая формула |
Пример |
|
Рус. |
Adjxvz* NxYZ Ngen Ngen |
«промежуточный преобразователь уровня напряжения» |
|
Англ. |
DetNNN |
«the joint ventures domain» |
|
Исп. |
Det yizi* Partyizi Adjyizi ‘ряга’ DetY2Z2 N Y2z2 |
«ип recorrido largo para la cuerda» |
* X - категория падежа; ¥ - категория рода; Z - категория числа.
методы, использующие преимущества рационалистического и эмпирического подходов для улучшения показателей эффективности алгоритма.
Гибридный метод извлечения именных групп
Эффективным способом выделения ИГ представляется гибридный подход, разрабатываемый С.О. Шереметьевой и основанный на применении базы знаний стоп-слов, которые не могут использоваться в начале, середине или конце ИГ5. Предварительная обработка текста для работы алгоритма заключается в построении списков п-грам для множества {ле^|/?<5}. Работа алгоритма извлечения ИГ включает фильтрование построенных словосочетаний с применением лингвистической базы знаний. При построении базы знаний эмпирически составленный лексикон разбивается на части, включающие списки стоп-слов а) которые не могут располагаться в начале именной группы; б) которые не могут располагаться в середине именной группы; в) которые не могут располагаться в середине именной группы. Например, ИГ в английском языке не может заканчиваться на предлог, поэтому, исчислив в списке финальных стоп-слов относительно немногочисленный лексический класс предлогов и применив этот фильтр, можно исключить все n-грамы, заканчивающиеся на один из предлогов. Таким образом, особенностью алгоритма является локальное применение ограничений на структуру ИГ - исключение неверных именных групп осуществляется на основе применения фильтра к соответствующей части л-грама, а не к ИГ целиком.
Другой особенностью подхода представляется использование лексикалистской грамматики ИГ -в качестве ограничений на структуру именной группы используется не принадлежность ее составляющих определенному лексико-грамматическому классу, а набор словоформ. Поскольку основу лексической базы знаний составляют закрытые части речи, они могут быть легко исчислены. Бесспорным преимуществом такого подхода является то, что он позволяет обрабатывать «сырой» текст, не снабженный морфологической и синтаксической разметкой.
Данная методика была успешно апробирована ее автором на материале англоязычных патентных текстов, а в силу простоты и относительно небольшого объема необходимой для работы алгоритма базы знаний представляется перспективным повторное использование для других языков.
Анализ лингвистических трудностей при извлечении испанских ИГ
В нашем исследовании данная методика была применена к извлечению ИГ из текстов патентов на испанском языке. Для испанского языка были составлены списки инициальных, медиальных и финальных стоп-слов, по частеречному составу соответствующих англоязычным спискам (с учетом особенностей синтаксической структуры испанской ИГ), и правила фильтрации применены к корпусу испано-язычных патентных текстов.
Эксперимент по применению метода фильтрации выявил ряд проблем в понимании текстов на уровне распознавания ИГ, что обусловлено структурными особенностями испанского языка. Приведем наиболее типичные случаи неоднозначности в распознавании.
-
1) Синтаксическая омонимия причастий, функционирующих как определение или ядро причастного оборота: в испанской ИГ определения ставятся после существительного, поэтому включение в список инициальных стоп-слов причастий приводит к исключению таких n-грам из списка потенциальных ИГ. Однако при лексикалистском подходе в этом случае возникают две проблемы: во-первых, при таком подходе в полученном в результате списке ИГ, построенных по схеме сугц. + прич., не разрешается неоднозначность на уровне синтаксической функции причастия. Так, motor conectado может быть ИГ (сущ. + определение) или частью причастного оборота, где conectado - предикат в форме причастия, a motor - один из актантов. Во-вторых, причастия являются отглагольными производными и представляют собой открытый класс слов. В связи с этим список причастий даже в пределах подъязыка имеет значительный объем, и его построение представляется неоправданно трудоемкой задачей. Кроме того, в силу флективности испанского языка включение различных морфологических парадигматических форм испанских причастий приводит к еще большему росту списка стоп-слов.
-
2) Омонимия субстантивных и атрибутивных причастий: ИГ может состоять из причастия в качестве ее ядра - лексикалистский подход не рассматривает целый класс ИГ, главным словом в которых является форма существительного, омонимичная причастию (например, un recorrido para la cuerddy
-
3) Включение артиклей в список медиальных стоп-слов сводит работу системы к идентификации простых ИГ, в то время как актант может быть выражен также и сложной ИГ, например, cubo de una polea.
-
4) Включение предлогов (кроме предлога de и его вариантов, сочлененных с артиклем) в список медиальных стоп-слов также приводит к исключению сложных ИГ. Например, при включении предлога para не будут найдены такие ИГ как calzones saludables para hombre, recorrido para la cuerda. С другой стороны, исключение предлога из списка позволит вычленить из текста un conjunto de rueda de ruleta para un arreglo de mesa de ruleta именную группу ruleta para un arreglo, в которой неверно представлены подразумеваемые в тексте синтаксические связи.
Модификация гибридного метода извлечения именных групп для флективных языков
Решение указанных проблем видится, с одной стороны, в изучении более широкого контекста (как лексического, так и лексико-грамматического), в котором функционируют n-грамы; с другой стороны, в использовании наряду с лексикали-стским также рационалистического подхода (использование информации о частеречной принадлежности лексических единиц) для автоматического анализа структуры n-грама и его контекста.
Узким местом рационалистического подхода к идентификации ИГ (применение синтаксических формул-шаблонов) всегда являлась необходимость предварительной парадигматической идентификации словоформ в тексте. Обычно эта задача требует предварительной обработки корпуса текстов с помощью лингвистического процессора, моделирование которого связано с необходимостью составления объемных словарей лексических единиц с лингвистической разметкой. Составление такой лингвистической базы знаний, с одной стороны, трудоемко, а с другой стороны, даже в ограниченных подъязыках существует вероятность, что составленный словарь при его применении за пределами тренировочного корпуса не будет покрывать всех единиц (обычно относящихся к категории открытых лексико-грамматических классов).
Поэтому при необходимости привлечения лексико-грамматической категоризации лексических единиц для работы алгоритма извлечения ИГ первоочередной задачей является решение проблемы автоматизации парадигматической идентификации словоформ с минимальным привлечением «ручной» обработки и максимальной «зоной покрытия» лексических единиц. Решением этой задачи представляется использование характера грамматического строя исследуемого языка.
Флективные языки, такие как испанский, обладают достаточно развитой системой морфологических признаков, эксплицитно выраженных в форме лексических единиц текста. Изменяемые части речи в испанском языке (за исключением нерегулярных форм, которые в грамматиках зада ются прямым перечислением) формируют достаточно легко формализуемые флективные классы. Так, отклоняющиеся глаголы sentir, convertir, preferir, advertir и т.д. спрягаются единообразно и могут быть объединены в один флективный класс. Флективные классы в испанском языке могут быть описаны через изменение флексий, которые иногда сопровождаются чередованиями в гласных корня. Пример спряжения глагола preferir в некоторых формах представлен в табл. 2.
Свойство формальной выраженности флективных классов в словоформах языка является основой корпусного метода автоматического морфологического анализа флективных языков6, использующего лингвистическую базу знаний, сбор которой ограничивается перечислением флективных классов данного языка. Поскольку метод не подразумевает использование словаря основ, его использование преодолевает барьер трудоемкости разработки лингвистической базы знаний, и он применим для парадигматической идентификации неизвестных словоформ (строго говоря, все словоформы открытых классов частей речи, подаваемые на вход алгоритма, неизвестны системе). На основе автоматически вычисляемой принадлежности словоформы флективному классу каждой словоформе текста из открытого класса лексем может быть приписана лексико-грамматическая информация, использующаяся при проецировании п-грама и его грамматического контекста на синтаксические шаблоны ИГ и правила фильтрации.
Применение эвристической морфологической разметки к корпусу текстов дает выгоду в нескольких планах. Во-первых, использование грамматической разметки дает возможность отказаться от перечисления в списках стоп-слов лексических единиц, принадлежащих открытым частям речи. Списки стоп-слов пополняются автоматически на основе данных анализируемого в данный момент (а не только тренировочного) корпуса.
Во-вторых, точность алгоритма фильтрации именных групп увеличивается за счет учета принадлежности элементов n-грама грамматическим подкатегориям (n-грамы могут быть отсортированы по свойству грамматической согласованности
Таблица 2
|
Форма |
Пример |
Флективный класс |
|
Инфинитив |
«preferir» |
-ir |
|
Наст.вр., Зл., ед.ч. |
«prefiere» |
-e: e -> ie; 1* |
|
Наст.вр., Зл., мн.ч. |
«prefieren» |
-en: e -> ie; 1 |
|
Прост.прош.вр., Зл., ед.ч. |
«prefirid» |
-id: e -> i; 1 |
|
Прост.прош.вр., Зл., мн.ч. |
«prefirieron» |
-ieron: e -> i; 1 |
|
Буд.вр., Зл., ед.ч. |
«preferira» |
-ira |
|
Буд.вр., Зл., мн.ч. |
«preferiran» |
-iran |
|
Причастие |
«preferido» |
-ido |
|
Герундий |
«preferiendo» |
-iendo |
* Данное правило может быть интерпретировано так: добавить к основе окончание -е и изменить ближайшую к концу основы последовательность подряд идущих гласных (тип изменений 1) с -е- на -ie-. Аналогично трактуются и последующие правила.
их составляющих). В синтаксисе словосочетаний выделяют 3 приема осуществления связей между его элементами: примыкание, управление и согласование. Из перечисленных приемов наиболее полезным с точки зрения возможности применения фильтров к именным группам оказывается согласование. Так как морфологический анализ слов флективных языков позволяет выявить по формальному признаку принадлежность словоформы лексико-грамматическому классу и ее грамматические признаки, это дает возможность осуществить фильтрацию при условии несовпадения грамматических признаков у элементов ИГ.
Учитывая эту особенности, алгоритм проверки согласованности элементов ИГ имеет вид:
/♦Извлечение простых ИГ из рассматриваемого п-грама*/
ЕСЛИ ИГ содержит разделитель
Извлечь в СПИСОК последовательность словоформ до разделителей
Извлечь в СПИСОК последовательность словоформ после разделителей
ИНАЧЕ извлечь в СПИСОК именную группу целиком
КОНЕЦ
Исключить из простых ИГ неизменяемые ЧР /♦Проверка согласованности простых ИГ в п-граме*/
ДЛЯ каждой ИГ в СПИСКЕ, где кол-во словоформ больше 1 ДЕЛАИ
ЕСЛИ (ГП^слово’) + ГП,(слово2) + „.+
ГП^слово"))
ИЛИ (Пислово1) + ГП2(стово2) + Нислово^) ИЛИ <...>
ИЛИ (ГП^слово2) # ГПт(слово2) / .../ ГПщСслово^))
ТОГДА исключить n-грам из списка кандидатов в ИГ
КОНЕЦ
Здесь ГП обозначает грамматический признак, по которому в данном языке осуществляется согласование словоформ в именной группе. Под разделителями подразумеваются слова, принадлежащие закрытым частям речи и не согласующиеся формально с элементами ИГ.
Структуру наиболее типичной именной группы в испанском языке можно представить следующей синтаксической формулой:
(Det)" + N ((+ Adv^+Adj/Part$ (+ «de» + (£>е0?
+ N ((+ AdvY + Adj/ParfYY-
Согласно правилам испанской грамматики, прилагательное или причастие (в атрибутивной функции) согласуются с существительным по роду (ГПО и числу (ГП2). В качестве разделителей следует рассматривает предлог «de» и определители (артикли). К неизменяемым частям речи, которые не согласуются по числу и роду, следует отнести наречия (определяемые в процессе морфологического анализа по словообра зовательным аффиксам), а также сочинительные союзы «у»/«о».
Рассмотрение n-грам не изолированно, а в их грамматическом и/или лексическом контексте, дает дополнительные преимущества для улучшения точности извлечения ИГ. Так, например, в системе в список слов, с которых не может начинаться именная группа, занесены определители (артикли), так как - несмотря на то, что в классической грамматике определитель является частью ИГ - этот элемент не обладает лексическим значением (в противном случае, например, такие именные группы как w^aDet modalidad alternativa и foDet modalidad alternativa следовало бы признать различными ИГ). Однако наличие артикля слева от ИГ явно указывает на начало ИГ. С другой стороны, если слева от ИГ расположен предлог «de» - это признак того что элемент является частью более крупной ИГ, и данный n-грам не следует рассматривать как отдельную смысловую единицу текста. Например, jreno de mano, имеющая в левом контексте (rodante) de, очевидно, не представляет собой независимую ИГ, а исполь-зуютеся как часть составной ИГ rodante de freno de mano. Аналогично, пользу для идентификации границ именной группы может принести и правый контекст. Например, n-грам ^сугц. + прич.\ в правом контексте которого располагается последовательность «рага» + инфинитив, согласно эмпирическим данным, не является ИГ.
Для проверки контекста нами используется алгоритм, фрагмент которого представлен на рисунке. Алгоритм демонстрирует последовательность действий по проверке содержания контекстов потенциальных ИГ и условия, при которых п-грам исключается из списка именных групп. В узлах указаны лексико-грамматические категории слов. Следуя лексикалистской модели, для фильтрации именных групп используются списки стоп-слов. Списки закрытых частей речи (определители, союзы, предлоги и т.д.) составляются вручную. Категории открытых частей речи выполняются в форме списка лексических единиц, наполняемого в процессе автоматического морфологического анализа на данном корпусе.
Применение расширенного гибридного метода для извлечения именных групп на испанском языке
Расширенный гибридный алгоритм извлечения именных групп был применен для выявления именных групп в корпусе текстов патентов на испанском языке объемом около 55 тыс. словоупотреблений. Предварительно были составлены списки стоп-слов, включающие союзы, предлоги, артикли и другие закрытые части речи, позволяющие исключить заведомо неверные именные группы из списка собранных по корпусу текстов п-грам.
Списки, составленные вручную, были далее автоматически дополнены глагольными формами
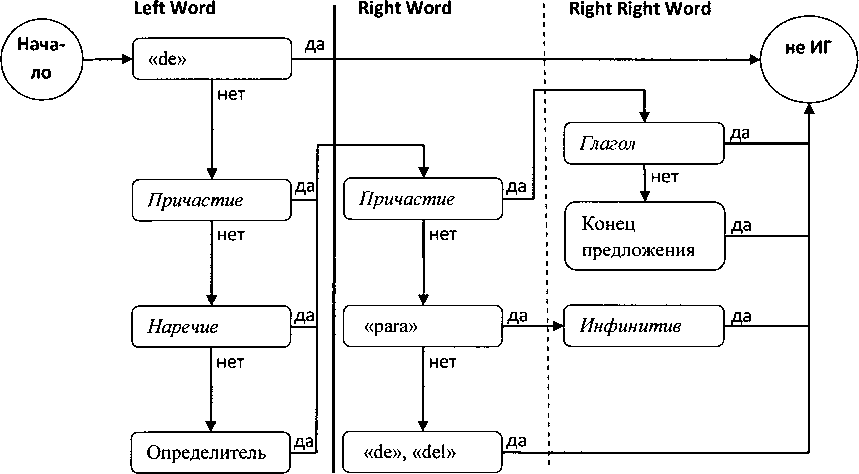
Фрагмент алгоритма анализа контекстов п-грам
(инициальный и финальный список), которые были выявлены автоматически с помощью алгоритма морфологического анализа. Эти фильтры были применены к спискам п-грам.
Далее результат работы этой стадии алгоритма был пропущен через контекстный фильтр и правила согласования. Благодаря контекстному фильтру из списка кандадитов в ИГ были удалены такие n-грамы, как:
(montaje de) embrague construido, envases conocidos (para aplicar Vwl extremos longitudinales (del campo)
(un soporte de) bola adaptado (para recibir Vinf la bob) и т.д.
Так, для 2-грам в общей сложности из списка кандидатов в ИГ, насчитывающего к данному этапу 186 единиц, было удалено 67 п-грам. Анализ удаленных п-грам показывает, что большинство удаленных групп представляют собой части более крупных ИГ. Например,
(lo largo de los ) bordes longitudinales ( del campo para desplazar),
(comprende una rueda de ) ruleta giratoria ( que tiene una pluralidad).
Однако среди удаленных п-грам оказалась также немногочисленная группа таких ИГ, как:
(en el control de ) brazos roboticos ( la invention proporciona un),
(resultado del mantenimiento de) ciertas properclones (entre el angulo de).
Формально данные ИГ также представляют собой части более крупной ИГ. Семантически управляющее существительное (control, montenimiento) полной ИГ представляет собой действие, то есть обладает предикатной функцией. Удаленные ИГ, фактически, являются актантами предиката, выраженного этим существительным, и их можно рассматривать как самостоятельные ИГ. Вместе с тем, с точки зрения семантико-синтаксического подхода, полный актант глагольной единицы текста представлен всей именной группой, включая отглагольное существительное. Поэтому при отборе ИГ, заполняющих валентности предикатов, мы полагаем удаление таких ИГ из списка кандидатов, соответствующих решаемой задаче.
Применение правил согласования в испанском языке позволило отбросить такие именные группы, как cwerpo_NmasCjSg qpw^ra_PartfemjP1, /racc/d^Nfen^sg independientes_M^ accionamiento de energiaff^em^ descritosj^mas<^ и др., которые не согласуются по роду и/или числу. Однако применение правил согласования не во всех случаях дает возможность выявить согласующиеся элементы, так как в испанском языке существуют несклоняемые (или изменяемые не по всем грамматическим признакам) прилагательные, например, в таких ИГ как ejes principal, forma variable, superficie inferior и т.д.
В целом, расширение гибридного метода позволило, с одной стороны, минимизировать затраты на составление списков стоп-слов. С другой стороны, выделение ИГ из списков п-грам на основе расширенных правил оказалось более точным.
Заключение
Таким образом, флективность языка, такого как испанский, обусловливает целесообразность усиления лексикалистской модели распознавания именных групп использованием рационалистиче- ского подхода, применяемого для анализа морфологической структуры слов потенциальной ИГ и учета ее лексико-грамматического контекста. Довольно развитая морфологическая структура слов флективного языка дает возможность с достаточно большой точностью определить лексико-грамматическую принадлежность слова. Это, в свою очередь, позволяет составлять правила обработки текстов на естественном языке, оперируя категориями частей речи и их парадигматических форм.
Для идентификации именной группы нами применяется не только анализ структуры п-грама, но также и его контекста. Для аноиза структуры ИГ и ее контекста мы следуем лексикалистской модели, применяя в качестве фильтров списки слов, которые не могут располагаться в определенной части ИГ или в ее левом или правом контексте. Преимуществом использования морфологического анализатора является возможность автоматизации формирования списков слов, принадлежащих открытым частям речи. Это минимизирует усилия разработчика, при этом, несмотря на то, что в основе фильтров лежит словоформа (это обычно ограничивает покрываемость модели тренировочным корпусом текстов), алгоритм отличается универсальностью в том смысле, что в ходе применения система способна обучаться и пополнять списки-фильтры словами, ранее неизвестными системе.
Результат работы данного метода во многом определяется корректностью работы морфологического анализатора. Для испанского языка точность работы анализатора достаточно высока.
При применении анализа к большим корпусам текстов и языкам с большей выраженностью флективных свойств возможно также достижение достаточно высоких показателей полноты.
Применение контекстных правил для выявления границ именной группы дает возможность увеличить точность извлечения именных групп посредством изъятия из списков кандидатов неполных именных групп, имеющих более широкие границы, чем рассматриваемый п-грам.
Мы полагаем, что использование представленного метода обещает достижение хороших результатов при применении также к другим флективным языкам.
-
1 Леонтьева Н.Н. Автоматическое понимание текстов: системы, модели, ресурсы: уч.пособ. для студентов лингв, фак. вузов. М.: Издательский центр «Академия», 2006. С. 22.
-
2 Филлмор Ч. Дело о падеже // Зарубежная лингвистика III / общ. ред. В.Ю. Розенцвейга, В.А. Звегинцева, Б.Ю. Городецкого. - М.: Изд. группа «Прогресс», 2002. С. 127-258; Апресян Ю.Д. Избранные труды. 2-е изд., испр. и доп. - М.: Школа «Языки русской культуры»: Изд-во «Восточная литература» РАН, 1995. Т. 1. Лексическая семантика. - VIII, 472 с.; Мельчук И.А. Опыт теории лингвистических моделей «Смысл <=> Текст». М.: Школа «Языки русской культуры», 1999.
-
3 Huddleston, R. Introduction to the Grammar of English, Cambridge, Cambridge University Press, 1997 (reprinted). P. 120.
-
4 См. подробнее о статистической модели совместной встречаемости слов в Evert, Stefan. 2004. The Statistics of Word Cooccurrences: Word Pairs and Collocations. Ph.D. thesis, University of Stuttgart, 353 p.; различные коэффициенты, используемые для оценки контекстуальной зависимости слов, приведены в Pecina, Pavel. 2005. An extensive empirical study of collocation extraction methods. In Proceedings of the ACL Student Research Workshop, June 2005, Ann Arbor, Michigan; P. 13-18.
-
5 Sheremetyeva S. 2009. On extracting multiword NP terminology for MT. In EAMT-2009: Proceedings of the 13th Annual Conference of the European Association for Machine Translation, ed. Lluis Marquez and Harold Somers, 14-15 May 2009. Universitat Polit^cnica de Catalunya, Barcelona, Spain; P. 205-212; Sheremetyeva S. 2009b. An efficient patent keyword extractor as translation resource. In MT Summit XII: Third Workshop on Patent Translation, August 30, 2009. Ottawa, Ontario, Canada; P. 25-32.
-
6 Бабина О.И. Автоматический морфологический анализ флективных языков // Наука ЮУрГУ: материалы 62-й научной конференции. Секции естественно-научных и гуманитарных наук (Челябинск, 28 апреля 2010 г.). Челябинск: Издательский центр ЮУрГУ, 2010; Бабина О.И. Нестрого аддитивный подход к автоматическому морфологическому анализу флективных языков // Материалы 5-й международной научно-практической конференции «Наука и современность-2010». Секция филологические науки. Новосибирск: Центр Развития Научного Сотрудничества, 2010.
Список литературы Извлечение именных групп из корпуса текстов на испанском языке
- Леонтьева Н.Н. Автоматическое понимание текстов: системы, модели, ресурсы: уч.пособ. для студентов лингв, фак. вузов. М.: Издательский центр «Академия», 2006. С. 22.
- Филлмор Ч. Дело о падеже//Зарубежная лингвистика III/общ. ред. В.Ю. Розенцвейга, В.А. Звегинцева, Б.Ю. Городецкого. -М.: Изд. группа «Прогресс», 2002. С. 127-258
- Апресян Ю.Д. Избранные труды. 2-е изд., испр. и доп. -М.: Школа «Языки русской культуры»: Изд-во «Восточная литература» РАН, 1995. Т. 1. Лексическая семантика. -VIII, 472 с
- Мельчук И.А. Опыт теории лингвистических моделей «Смысл Текст». М.: Школа «Языки русской культуры», 1999.
- Huddleston, R. Introduction to the Grammar of English, Cambridge, Cambridge University Press, 1997 (reprinted). P. 120.
- The Statistics of Word Cooccurrences: Word Pairs and Collocations. Ph.D. thesis, University of Stuttgart, 353 p.
- Sheremetyeva S. 2009. On extracting multiword NP terminology for MT. In EAMT-2009: Proceedings of the 13th Annual Conference of the European Association for Machine Translation, ed. Lluis Marquez and Harold Somers, 14-15 May 2009. Universitat Politecnica de Catalunya, Barcelona, Spain; P. 205-212
- Sheremetyeva S. 2009b. An efficient patent keyword extractor as translation resource. In MT Summit XII: Third Workshop on Patent Translation, August 30, 2009. Ottawa, Ontario, Canada; P. 25-32.
- Бабина О.И. Автоматический морфологический анализ флективных языков//Наука ЮУрГУ: материалы 62-й научной конференции. Секции естественно-научных и гуманитарных наук (Челябинск, 28 апреля 2010 г.). Челябинск: Издательский центр ЮУрГУ, 2010
- Бабина О.И. Нестрого аддитивный подход к автоматическому морфологическому анализу флективных языков//Материалы 5-й международной научно-практической конференции «Наука и современность-2010». Секция филологические науки. Новосибирск: Центр Развития Научного Сотрудничества, 2010.
