Моделирование валового регионального продукта при помощи методов машинного обучения

Автор: Майкова А.А., Старченкова О.Д., Схведиани А.Е.
Журнал: Вестник Пермского университета. Серия: Экономика @economics-psu
Рубрика: Математические, статистические и инструментальные методы в экономике
Статья в выпуске: 4 т.20, 2025 года.
Бесплатный доступ
Введение. Валовой региональный продукт является одним из ключевых индикаторов регионального развития, поэтому построение моделей его прогнозирования – актуальный вопрос современных исследований. Цель. Прогнозирование валового регионального продукта с высокой точностью при помощи методов машинного обучения. Материалы и методы. В качестве статистической базы использовались данные, приведенные в периодической печати и интернете, справочные материалы и ежегодные статистические сборники органов государственной статистики РФ. Экзогенными переменными являются 12 факторов, которые отражают экономическое развитие региона, а также уровень его цифровизации. Для моделирования прогноза валового регионального продукта применяются методы машинного обучения, для написания кодов с помощью языка программирования Python выбрана среда Google Colaboratory. Результаты. Построено четыре модели машинного обучения: Linear Regression, Gradient Boosting Regressor, LGBM Regressor, Decision Tree Regressor. В итоге на тестовой выборке модель Linear Regression показала R2, равный 87 %, Gradient Boosting Regressor – 89 %, LGBM Regressor – 88 %, Decision Tree Regressor – 81 %, что является хорошим результатом. Выводы. Представленные в работе модели могут быть применены для краткосрочного прогноза валового регионального продукта. Результаты могут быть использованы в практике социально-экономического планирования, оценки инвестиционной привлекательности регионов, а также в управлении региональной политикой и разработке стратегий развития регионов. Основу будущего исследования может составить построение иных моделей машинного обучения, определение которых будет реализовано через применение Lazy Regressor, а также благодаря улучшению прогностической способности моделей настоящего исследования.
Валовой региональный продукт, регион, развитие региона, прогнозирование, машинное обучение, цифровизация, цифровое развитие, цифровая трансформация
Короткий адрес: https://sciup.org/147252616
IDR: 147252616 | УДК: 332, 332.1, 330.4 | DOI: 10.17072/1994-9960-2025-4-449-467
Gross regional product modeling with machine learning methods
Introduction. Gross regional product is one of the key indicators of regional development; therefore its forecasting modeling is a relevant issue for modern studies. Purpose. The article aims at applying machine learning methods to forecast gross regional product with high accuracy. Materials and Methods. The statistical base included data from periodicals and the Internet, reference materials and annual statistical collections prepared by the public statistics bodies of the Russian Federation. Exogenous variables are 12 factors which reflect the economic development of the region, as well as the level of its digitalization. Machine learning methods are used to model the gross regional product forecast; the Google Colaboratory environment was chosen to write Python codes. Results. This study developed four machine learning models: Linear Regression, Gradient Boosting Regressor, LGBM Regressor, Decision Tree Regressor. Linear Regression has an R2 of 87 % on the test sample, Gradient Boosting Regressor has an R2 of 89 % on the test sample, LGBM Regressor and Decision Tree Regressor have an R2 of 88 % and 81 % on the test sample, respectively, which is a good result. Conclusions. The models described in the paper could be applied to short-term forecasting of gross regional product. The results of the study can be used in socio-economic planning practices, assessing the investment attractiveness of regions, as well as in managing regional policy and developing regional growth policies. Further research may be connected with constructing other machine learning models which could be derived from Lazy Regressor, as well as improving the predictive capacity of the models in this study.
Текст научной статьи Моделирование валового регионального продукта при помощи методов машинного обучения
Валовой региональный продукт (ВРП) – один из ключевых индикаторов регионального развития. Построение моделей прогнозирования данного макроэкономического показателя является важным исследовательским вопросом. Это подтверждается тем, что результаты прогнозирования ВРП позволяют компаниям планировать свою деятельность, принимать обоснованные управленческие и стратегические решения, оценивать потенциальные риски, разрабатывать или модернизировать экономические программы, стратегии, политику, оценивать перспективы. Определение факторов, которые в большей мере описывают экономическое развитие региона, а значит, влияют на ВРП, помогает лучше понимать текущее состояние экономики. Прогнозирование ВРП методами машинного обучения с применением языка программирования Python отличает данную работу от ряда других научных трудов, авторы которых, как правило, применяют традиционные эконометрические методы прогнозирования.
В рамках исследования выдвигается следующая гипотеза: «Применение методов машинного обучения позволяет повысить точность прогноза относительно эконометрических моделей». Целью исследования является прогнозирование ВРП с высокой точностью при помощи методов машинного обучения и проверка выдвинутой гипотезы.
ОБЗОР НАУЧНОЙ ЛИТЕРАТУРЫ
Вопрос прогнозирования ВРП освещается многими отечественными авторами. Рассмотрим ряд трудов и на основе детального обзора определим набор объясняющих переменных настоящего исследования.
Л. П. Бакуменко и Е. В. Костромина разработали и апробировали методику оценки социально-экономического развития Республики Марий Эл через построение эконометрических моделей основных показателей экономического и социального развития региона. Авторы отобрали следующие факторы, которые потенциально могут оказывать влияние на уровень развития экономики Республики Марий Эл: среднегодовая численность занятых в экономическом секторе (тыс. чел.), стоимость основных фондов в экономике (млн руб.), динамика объема промышленного производства (%), объем производства сельхозпродукции (млн руб.), ввод в эксплуатацию общей площади жилых домов в расчете на 1000 человек населения (м2), оборот розничной торговли (млн руб.), инвестиции в основной капитал (млн руб.). В качестве эндогенной переменной выступил показатель ВРП. По результатам регрессионного анализа значимыми переменными оказались оборот розничной торговли, объем производства сельхозпродукции и динамика объема промышленного производства: увеличение данных факторов будет способствовать реальному росту экономики Республики Марий Эл [1].
Вопросом моделирования влияния социально-экономических факторов на ВРП занимались С. В. Панкова и А. П. Цыпин. Авторы применяли различные методы, в том числе методы эконометрики и многомерной статистики. Проведя детальный обзор аналогичных исследований, С. В. Панкова и А. П. Цыпин отобрали следующие экзогенные показатели: динамика объема промышленного производства (%), инвестиции в основной капитал на душу населения (руб.), доля занятого населения (%), среднемесячная номинальная начисленная заработная плата работников организаций (руб.), оборот розничной торговли на душу населения (руб.). Авторы отмечают, что на ВРП оказывают влияние различные наборы факторов в зависимости от исследуемой группы субъектов РФ, и приходят к выводу, что для получения наибольших значений ВРП региону важно направить силы на повышение уровня жизни граждан [2].
Т. В. Миролюбова и Е. Н. Ворончихина разработали модель среднесрочного прогноза ВРП Пермского края. ВРП в наибольшей степени объясняется такими факторами, как инвестиции в основной капитал и среднемесячная номинальная начисленная заработная плата. Следует отметить, что для достижения поставленной цели авторы включили в анализ следующие экзогенные переменные: инвестиции в основной капитал (%), расходы свода бюджетов всех уровней на соответствующей территории, т. е. консолидированного бюджета (%), объем вывоза за границу (%), среднемесячная номинальная начисленная заработная плата (%) [3].
П. С. Бравок и Л. Е. Пынько сделали акцент на эконометрическом анализе ВРП Дальневосточного федерального округа. По результатам моделирования наибольшее влияние на ВРП ДФО оказывают такие факторы, как поступление налогов, сборов и иных обязательных платежей в консолидированный бюджет РФ, инвестиции в основной капитал и оборот розничной торговли. Авторы пришли к выводу, что для прогнозирования необходимо использовать модель с фиксированными эффектами [4].
Разработкой модели оценки ВРП также занимался С. Д. Русских. Он проанализировал, какие факторы оказывают наибольшее влияние на зависимую переменную, после чего разработал двухфакторную модель, обладающую хорошей прогностической способностью. Выборка исследования состояла из 30 субъектов РФ за 2018 г. В финальной версии модели фигурируют следующие экзогенные факторы: инвестиции в основной капитал и численность рабочей силы от 15 лет [5].
Ю. С. Положенцева с соавторами прогнозировали динамику ВРП с помощью нейронных сетей. Исследователи сосредоточили внимание на Курской области, спрогнозировав для данного региона ВРП на три года (2019–2021). Они сравнили полученные результаты с данными, представленными на официальном сайте Росстата. Так как на показатель ВРП оказывает влияние большое количество различных факторов, по результатам процедуры сравнения было отобрано семь определяющих показателей. Для моделирования использовалась программа SPSS Statistics. Построив три нейросети, авторы пришли к выводу, что наиболее приближенными к реальным значениям являются значения нейросети с пакетным типом обучения. Наиболее значимыми факторами по результатам моделирования выступили обрабатывающие производства, затраты на внедрение, использование цифровых технологий [6].
В. В. Носов, А. П. Цыпин провели моделирование влияния факторов на ВРП на основе искусственных нейронных сетей. Авторы отобрали для анализа такие экзогенные переменные, как индекс промышленного производства (%), инвестиции в основной капитал на душу населения (руб.), доля занятого населения (%), среднемесячная номинальная начисленная заработная плата работников организаций (руб.), оборот розничной торговли на душу населения (руб.). Все необходимые расчеты авторы выполнили с использованием программного пакета Statistica . Ученые акцентируют внимание на том, что все проанализированные ими переменные оказывают положительное влияние на результативную переменную [7].
Л. С. Невьянцева, Е. В. Радковская применили в своей работе методы экономико-математического моделирования. Авторы исследовали величину и динамику ВРП. Набор проанализированных независимых переменных достаточно обширен. При этом стоит отметить, что значимыми оказались следующие: конечный финансовый результат до налогообложения, расходы консолидированных бюджетов, поступившие иностранные инвестиции, стоимость основных фондов и расходы в рамках реализации различных видов инновационной деятельности. В заключение авторы отметили, что прогнозирование с помощью предложенной ими модели способно оказать влияние на формирование управленческих решений, которые направлены на создание устойчивого регионального роста экономики, а также задать вектор для их принятия [8].
-
А. В. Баенхаева с соавторами для моделирования ВРП Иркутской области использовали статистические данные за 10 лет по следующим
независимым переменным: потребление электроэнергии (млрд кВт·ч), численность безработных (тыс. чел.), строительство жилых домов (тыс. м2), оборот розничной торговли (млрд руб.) [9].
Ю. С. Ивченко в качестве цели исследования указал установление факторов, которые в большей мере объясняют уровень ВРП. На начальном этапе исследования автор выявил 15 факторов. В результате наиболее значимыми оказались такие: суммарные денежные доходы населения региона (млн руб.), среднегодовая остаточная стоимость основных фондов (млн руб.), конечный финансовый результат организаций до налогообложения (млн руб.), среднегодовые остатки средств на счетах юридических лиц (млн руб.), доля занятых в общей численности рабочей силы [10].
Н. Т. Рафикова, З. А. Залилова построили семь моделей множественной регрессии. Авторы пришли к выводу, что наибольшее влияние на показатель ВРП оказали такие переменные, как обеспеченность основными фондами, уровень занятости, инвестиционная и инновационная активность [11].
-
А. Н. Соколова с соавторами оценили влияние ряда социальных факторов на ВРП субъектов РФ. Выборка исследования составила 85 субъектов, а период, рассмотренный учеными, охватывает 2017–2019 гг. Эндогенной переменной выступил натуральный логарифм ВРП. Положительное влияние на ВРП оказали доля удаленных веществ, которые загрязняют атмосферу, численность зрителей театральных постановок и число посещений музеев гражданами [12].
-
О. Е. Куницын позиционирует ключевой индикатор регионального развития как фактор социально-экономического развития и на примере Вологодской области показывает, что реализованный им прогноз поможет в планировании объемов и распределении соответствующих финансовых потоков для увеличения уровня социально-экономического развития региона. Объясняющие переменные, которые автор включил в анализ: среднегодовая численность занятых, оборот розничной торговли,
объем работ, выполненных по виду деятельности «Строительство». В результате установлено, что влияние фактора «объем строительных работ» на ВРП несущественно [13].
Е. В. Королева с соавторами провели оценку влияния уровня цифровизации предпринимательской деятельности на ВРП. Выборка исследования включала все регионы РФ, а наблюдения были собраны за 2017–2019 гг. Авторы пришли к главному выводу: рост уровня цифровизации предпринимательской деятельности положительно влияет на ВРП. К факторам цифровизации авторы отнесли использование персональных компьютеров, интернета, осуществление организациями технологических инноваций, использование организациями средств защиты информации. Все экзогенные переменные измерялись в процентах и преимущественно отражали удельный вес. Результаты данного исследования и сделанные авторами наблюдения позволили нам включить в перечень экзогенных переменных факторы, которые потенциально могут отразить уровень цифровизации регионов РФ [14]. Данное решение также подтверждается выводами Ю. С. Положенцевой с соавторами [6].
На основании анализа научной литературы построена сводная таблица, включающая информацию об экзогенных переменных, которые были использованы отечественными авторами для моделирования ВРП (табл. 1).
Рассмотрим еще несколько работ, в которых для прогнозирования ВРП, ВВП используются методы моделирования.
Т. В. Азарнова с соавторами строили прогноз факторов, отражающих социально-экономическое развитие региона, с использованием нейронных сетей и пришли к выводу, что полученные прогнозные значения можно считать адекватными реальным в регионе [15].
-
Р. Р. Латыпова с коллегами предлагают задействовать искусственную нейронную сеть с архитектурой многослойного персептрона с целью моделирования и прогнозирования. Для осуществления поставленной цели авторы использовали среду Matlab 2013a [16].
Табл. 1. Сводная информация о часто исследуемых экзогенных переменных
Table 1. Summary of commonly studied exogenous variables
|
Автор |
Пересекающаяся экзогенная переменная |
|
Л. П. Бакуменко, Е. В. Костромина [1] |
Стоимость основных фондов в экономике (млн руб.); индекс промышленного производства (%); оборот розничной торговли (млн руб.); инвестиции в основной капитал (млн руб.) |
|
С. В. Панкова, А. П. Цыпин [2] |
Индекс промышленного производства (%); инвестиции в основной капитал на душу населения (руб.); уровень занятости (%); оборот розничной торговли на душу населения (руб.) |
|
Т. В. Миролюбова, Е. Н. Ворончихина [3] |
Инвестиции в основной капитал (%); расходы консолидированного бюджета (%); экспорт (%); среднемесячная номинальная начисленная заработная плата (%) |
|
П. С. Бравок, Л. Е. Пынько [4] |
Инвестиции в основной капитал (млн руб.); оборот розничной торговли (млн руб.), сальдированный финансовый результат деятельности организаций (млн руб.); экспорт (млн дол. США) |
|
С. Д. Русских [5] |
Инвестиции в основной капитал (млн руб.); численность рабочей силы в возрасте 15 лет и старше (чел.); среднемесячная номинальная начисленная заработная плата работников по полному кругу организаций (руб.) |
|
Ю. С. Положенцева, О. В. Согачева, А. А. Ярошенко [6] |
Инвестиции в основной капитал; стоимость основных фондов; сальдированный финансовый результат деятельности организаций; прямые иностранные инвестиции |
|
В. В. Носов, А. П. Цыпин [7] |
Индекс промышленного производства (%); инвестиции в основной капитал на душу населения (руб.); уровень занятости (%); среднемесячная номинальная начисленная заработная плата работников организаций (руб.); оборот розничной торговли на душу населения (руб.) |
|
Л. С. Невьянцева, Е. В. Радковская [8] |
Инвестиции в основной капитал; сальдированный финансовый результат организаций; расходы консолидированных бюджетов; поступившие иностранные инвестиции; стоимость основных фондов; среднегодовая численность занятых |
|
А. В. Баенхаева, М. П. Базилевский, С. И. Носков [9] |
Оборот розничной торговли (млрд руб.) |
|
Ю. С. Ивченко [10] |
Суммарные денежные доходы населения региона (млн руб.); сальдированный финансовый результат деятельности предприятий и организаций (млн руб.); доля занятых в общей численности рабочей силы (%); расходы консолидированного бюджета субъекта на национальную экономику (млн руб.); экспорт (млн дол. США) |
|
Н. Т. Рафикова, З. А. Залилова [11] |
Обеспеченность основными фондами; уровень занятости |
|
О. Е. Куницын [13] |
Среднегодовая численность занятых; оборот розничной торговли |
О. В. Криони, Д. А. Федосов рассмотрели разные подходы к прогнозированию валового регионального продукта, а именно три метода прогнозирования, основанные на ARIMA -моделях, сбалансированной системе показателей, нейронных сетях. В итоге авторы выявили, что для прогнозирования чаще всего используются многослойные нейронные сети [17].
Методы машинного обучения для моделирования ВВП применяли в своих исследованиях M. D. Adewale с соавторами. Ученые использовали такие методы, как Random Forest Regressor, XGBoost Regressor и Linear Regression. Модель Random Forest Regressor оказалась наи- более надежной, поскольку коэффициент детерминации равен 0,96, а средняя абсолютная ошибка (MAE) равна 24,29. Авторы отмечают, что моделирование ВВП позволяет идентифицировать факторы, которые необходимо оптимизировать в первую очередь, так как это может стать решающим рычагом для ускорения экономического роста страны, а при моделировании ВРП – региона [18].
-
I. Putra с группой исследователей провели оценку ВРП на душу населения на уровне субрайона в провинциях Бали, применяя методы машинного обучения и линейной регрессии, включая нейронные сети, регрессию случайного
леса ( Random Forest Regression ) и регрессию опорных векторов. Наиболее эффективной моделью оказалась регрессия опорных векторов [19].
R. Flannery для моделирования использовал язык программирования Python , а в качестве рабочей среды – Google Colab . Как отмечает автор, Google Colab имеет множество преимуществ для создания моделей нейронных сетей и машинного обучения, например позволяет работать онлайн без необходимости установки каких-либо пакетов на локальной машине [20]. В качестве языка программирования использовали Python и такие авторы, как E. Bekele и T. Zekarias [21].
На основе проведенного анализа можно сделать вывод, что для прогнозирования ВРП все шире применяются современные методы моделирования, в частности искусственные нейронные сети и алгоритмы машинного обучения. Ученые отмечают высокую точность и адаптивность нейросетей, особенно моделей с многослойной архитектурой и пакетным типом обучения. Активно используются также методы Random Forest , XGBoost и регрессия опорных векторов, демонстрирующие высокую надежность и точность прогнозов. Важно подчеркнуть, что выбор метода зависит от специфики задачи и доступных данных, но на практике наибольшую эффективность показывают гибридные и нейросетевые подходы.
Основы экономико-математического моделирования заложил Л. В. Канторович. Из- вестному экономисту и математику удалось создать алгоритм для широкого круга задач, формализуемых с помощью математического аппарата («линейное программирование»)1. Актуальными в настоящее время являются работы, объединяющие в себе математическое моделирование и системный анализ экономики регионов с целью получения количественной оценки деятельности государства. Данный факт отмечается во многих работах, в том числе в монографии В. Л. Макарова с соавторами [22].
МАТЕРИАЛЫ И МЕТОДЫ
Выборка настоящего исследования включает 82 региона РФ. Анализируемый период – 2014–2022 гг. Эндогенной переменной выступает ВРП на душу населения. Экзогенными переменными являются 12 факторов, которые отражают экономическое развитие региона, а также уровень его цифровизации. Для моделирования прогноза ВРП применяются методы машинного обучения. Для написания кодов с помощью языка программирования Python выбрана среда Google Colaboratory , так как она наиболее подходит для работы с такими составляющими, как машинное обучение и искусственный интеллект.
Набор экзогенных переменных, которые использованы в настоящем исследовании, отражен в табл. 2.
Табл. 2. Набор экзогенных переменных и их характеристика
Table 2. A set of exogenous variables and their description
|
Переменная |
Признак |
Ед. изм. |
|
Х1 |
Внутренние текущие затраты на научные исследования и разработки |
Тыс. руб. |
|
Х2 |
Автомобильные дороги общего пользования |
Км |
|
Х3 |
Оборот розничной торговли на душу населения |
Руб. |
|
Х4 |
Инвестиции в основной капитал |
Тыс. руб. |
|
Х5 |
Объем инвестиций в основной капитал, направленных на приобретение информационного, компьютерного и телекоммуникационного (ИКТ) оборудования |
Тыс. руб. |
|
Х6 |
Доля продаж через интернет в общем объеме оборота розничной торговли |
Процент |
|
Х7 |
Удельный вес занятых в секторе ИКТ в общей численности занятого населения |
Процент |
1 Канторович Л. В. Математические методы организации и планирования производства: учеб. пособие. Л.: Изд-во ЛГУ, 1939. 68 с.
Продолжение табл. 2
|
Переменная |
Признак |
Ед. изм. |
|
Х8 |
Удельный вес организаций, использовавших персональные компьютеры |
Процент |
|
Х9 |
Численность занятых в возрасте 15–72 лет |
Чел. |
|
Х10 |
Количество введенных жилых помещений (квартир) в расчете на 1000 человек населения |
Ед. |
|
Х11 |
Наличие основных фондов на конец года по полной учетной стоимости по полному кругу организаций |
Тыс. руб. |
|
Х12 |
Потребление электроэнергии |
Млн кВт·ч |
|
Источник : составлено авторами. Source : compiled by the authors. |
||
Переменная, отражающая использование цифровых технологий, значима в исследовании [6], поэтому в перечень экзогенных переменных были включены показатели, отражающие цифровизацию региона. Так, авторы работы [14] включили в построение переменную «удельный вес организаций, использовавших персональные компьютеры». Аналогичный показатель вошел в наш перечень экзогенных переменных для анализа и последующего моделирования. В настоящий анализ была также включена переменная «потребление электроэнергии», которая учитывалась, например, в работе [9]. В рассмотренных ранее исследованиях использовались факторы, связанные со строительной отраслью, по аналогии с которыми включена авторская переменная «автомобильные дороги общего пользования». Таким образом, сформированный набор экзогенных переменных содержит в себе факторы экономического развития региона, включая ряд факторов, отражающих уровень его цифрового развития.
Кратко поясним выбор признаков.
X 1 – внутренние текущие затраты на научные исследования и разработки. Признак отражает объем финансовых ресурсов, направленных на создание и внедрение новых технологий, продуктов и процессов. Инвестиции в НИОКР способствуют развитию научного и технического потенциала региона, повышают инновационную активность компаний. Результатом такого рода вложений становится рост производительности и увеличение добавленной стоимости, что, в свою очередь, напрямую влияет на уровень ВРП.
X 2 – автомобильные дороги общего пользования (в километрах). Протяженность дорожной сети является ключевым инфраструктурным фактором, который определяет логистику, транспортные издержки, региональные рынки. Развитая дорожная сеть способствует снижению затрат на доставку, повышению мобильности рабочей силы и расширению экономических связей между субъектами. Все это создает условия для интенсификации экономической деятельности и увеличения ВРП.
X 3 – оборот розничной торговли на душу населения. Признак может служить показателем уровня потребительского спроса и активности домашних хозяйств. Высокий оборот розничной торговли указывает на более высокий уровень доходов и потребления, что стимулирует производство товаров и услуг. Растущий внутренний спрос в значительной степени определяет объемы создаваемой добавленной стоимости и соответственно рост ВРП.
X 4 – инвестиции в основной капитал. Объем инвестиций в основной капитал представляет собой вложения в долгосрочные активы. Эти инвестиции напрямую влияют на расширение производственных мощностей и модернизацию производства, создают определенные условия для устойчивого роста выпуска товаров и услуг, тем самым способствуя увеличению ВРП.
X5 – объем инвестиций в основной капитал, направленных на приобретение ИКТ-обо-рудования. Показатель уточняет структуру общего инвестиционного потока и показывает, насколько регион ориентирован на цифровизацию и технологическое обновление. Вложения в ИКТ повышают эффективность всех сфер деятельности – от управления до производства. Они играют критическую роль в формировании современной высокотехнологичной экономики, обеспечивая долгосрочный рост ВРП.
X 6 – доля продаж через интернет в общем объеме оборота розничной торговли. Показатель служит индикатором степени развития цифровой экономики в регионе. Рост онлайн-продаж свидетельствует о внедрении современных информационных технологий в сферу торговли в регионе, что повышает ее эффективность, расширяет рынок сбыта продукции. Таким образом, цифровизация торговли оказывает прямое влияние на объем создаваемой добавленной стоимости, а следовательно, на уровень ВРП.
X 7 – удельный вес занятых в секторе информационно-коммуникационных технологий. Отражает уровень инновационного и технологического развития региона: увеличение доли занятых в ИКТ-сфере указывает на структурные изменения в экономике в сторону более наукоемких и высокотехнологичных отраслей региона, которые, как правило, характеризуются высокой производительностью труда. Это напрямую способствует увеличению ВРП.
X 8 – доля организаций, использующих персональные компьютеры. Является индикатором цифровой трансформации бизнеса: расширение применения компьютерных технологий в управлении, производстве, бухгалтерии и логистике ведет к оптимизации внутренних процессов компании, росту эффективности и конкурентоспособности. В совокупности это способствует интенсификации экономической деятельности и, как следствие, росту ВРП.
X9 – численность занятых в возрасте 15– 72 лет. Показатель отражает масштаб трудовых ресурсов, вовлеченных в экономическую деятельность региона. Труд является одним из ключевых факторов производства, влияющих как на объем выпуска, так и на структуру создаваемой добавленной стоимости. Высокий уровень занятости представляет собой необ- ходимое условие устойчивого регионального экономического роста.
X 10 – количество введенных в эксплуатацию жилых помещений (квартир) на 1000 человек населения. Показатель используется как индикатор строительной активности, так как строительство жилья – это не только важный компонент ВРП, относящийся к разделу «Строительство», но и опосредованный индикатор общего инвестиционного климата в регионе. Более активное жилищное строительство указывает на развитие инфраструктуры и потребительского спроса, создает общественные блага, что положительно отражается на экономике региона в целом и его развитии.
X 11 – стоимость основных фондов на конец года по полной учетной стоимости. Характеризует накопленный производственный капитал: основные фонды, включающие здания, сооружения, машины и оборудование, формируют базу для осуществления производственной деятельности; наличие развитой материально-технической базы способствует расширению производства, его развитию и реализации долгосрочных экономических проектов, что в конечном счете отражается в росте ВРП.
X 12 – потребление электроэнергии. Является индикатором, который может быть использован для оценки общего уровня экономической активности: в большинстве случаев увеличение объемов энергопотребления связано с ростом производства, расширением бизнеса, увеличением занятости и другими формами экономической активности. Данный признак тоже может быть надежным индикатором динамики ВРП.
Методика исследования включает определенные шаги: предварительный анализ данных, логарифмирование, разбиение выборки на тренировочную и тестовую в соотношении 80 и 20 % соответственно, построение моделей на тренировочной выборке ( Linear Regression , Gradient Boosting Regressor , LGBM Regressor , Decision Tree Regressor ), получение прогнозов на тестовой выборке, оценивание точности прогнозов по таким метрикам качества, как MSE , MAE , R 2.
Табл. 3. Библиотеки (модели) и их задачи
Table 3. Libraries (models) and their tasks
Библиотека (модель) Назначение (задача)
|
numpy |
Работа с многомерными массивами и матрицами, численные вычисления |
|
pandas |
Обработка и анализ табличных данных ( DataFrame ) |
|
matplotlib.pyplot |
Построение графиков и визуализация результатов моделей |
|
seaborn |
Корреляционные матрицы, визуализация распределений |
|
warnings |
Подавление предупреждений |
|
subprocess |
Вызов внешних процессов, например для взаимодействия с системой |
|
sklearn.ensemble.DecisionTreeRegressor |
Реализация построения модели |
|
sklearn.ensemble.GradientBoostingRegressor |
Реализация построения модели |
|
sklearn.linear_model.LinearRegression |
Реализация построения модели |
|
lightgbm.LGBMRegressor |
Реализация построения модели |
|
sklearn.metrics |
Оценка моделей |
|
sklearn.model_selection.train_test_split |
Разделение данных на обучающую и тестовую выборки |
|
sklearn.model_selection.GridSearchCV |
Перебор гиперпараметров моделей |
|
sklearn.preprocessing.StandardScaler |
Нормализация данных |
|
sklearn.preprocessing.LabelEncoder |
Преобразование категориальных признаков в числовые |
|
lazypredict.Supervised.LazyRegressor |
Автоматическое сравнение моделей регрессии |
|
optuna |
Оптимизация гиперпараметров моделей |
|
scipy.stats |
Анализ распределений, нормализация данных, проверка на выбросы |
|
statsmodels.api |
Статистическое моделирование, оценка значимости признаков |
Источник : составлено авторами. Source : compiled by the authors.
В процессе построения моделей определены гиперпараметры – характеристики модели, устанавливаемые до начала обучения. Гиперпараметры регулируют структуру модели и процесс обучения. Их корректный выбор позволяет избегать как переобучения, так и недо-обучения модели. Для настройки использовались методы перебора по сетке ( GridSearchCV ) с кросс-валидацией, обеспечивающие нахождение наилучшей конфигурации на основе заданных критериев качества.
В ходе построения задействованы различные библиотеки Python , каждая из которых выполняла специфическую роль в процессе анализа данных, построения моделей и оценки их качества (табл. 3).
РЕЗУЛЬТАТЫ
На первом этапе исследования описаны исходные данные, так как важно понимать характеристики выборки и ее особенности с точки зрения статистики.
В табл. 4 отражены полученные результаты реализации описательной статистики посред- ством написания соответствующего кода: приведено описание данных по 13 переменным, включая количество наблюдений (738), среднее значение, стандартное отклонение, минимальные и максимальные значения, а также квартильные показатели (25, 50 и 75 %).
На основе описательной статистики можно сделать вывод, что данные являются полными, каждая переменная содержит 738 наблюдений, обеспечивая надежную основу для анализа и построения моделей.
Показатель Y – зависимая (целевая) переменная. Ее среднее значение составляет 526,2 при стандартном отклонении 443,25, а максимальное значение достигает 3637,1, что говорит о высоком разбросе данных и наличии выбросов, поскольку медиана (402,76) значительно ниже среднего. Это можно объяснить высокой дифференциацией регионов РФ.
Среди некоторых признаков наблюдается большая дисперсия, например у переменных Х 5, Х 11 и Х 12, что указывает на сильную вариативность. Аналогично переменные Х 11 и Х 12 имеют высокие значения максимума по сравнению с медианой и 75-м процентилем,
Табл. 4. Описательная статистика
Table 4. Descriptive statistics
|
Y |
X1 |
X2 |
X3 |
X4 |
X5 |
X6 |
X7 |
X8 |
X9 |
X10 |
X11 |
X12 |
|
|
count |
738 |
738 |
738 |
738 |
738 |
738 |
738 |
738 |
738 |
738 |
738 |
738 |
738 |
|
mean |
526,2 |
12 333 914 |
13 106,7 |
189,6 |
27 000 000 |
6 342 652 |
1,5 |
1,4 |
89,5 |
882,3 |
1 497,7 |
3 301 783 |
17 646,3 |
|
std |
443,3 |
44 186 539 |
8 739,0 |
62,4 |
460 000 000 |
25 447 337 |
1,9 |
0,6 |
7,8 |
988,3 |
1 884,8 |
7 311 101 |
31 650,9 |
|
min |
78,0 |
38 887,1 |
643,2 |
42,2 |
3 384 616 |
78 738 |
0 |
0,2 |
48,7 |
28,7 |
0 |
9 193 |
489,9 |
|
25 % |
288,5 |
630 088,3 |
7 149,3 |
149,1 |
51 853 111 |
1 172 819 |
0,3 |
1,0 |
84,2 |
356,2 |
300 |
734 622,3 |
3 729,2 |
|
50 % |
402,7 |
1 797 462 |
10 785,4 |
182,9 |
106 000 000 |
2 169 371 |
0,8 |
1,3 |
91,5 |
565,0 |
1 100 |
1 534 132 |
8 431,6 |
|
75 % |
573,6 |
6 457 581 |
17 738,0 |
223,0 |
231 000 000 |
4 599 218 |
1,9 |
1,8 |
95,8 |
1 132,1 |
1 900 |
2 956 645 |
16 901 |
|
max |
3 637,1 |
483 000 000 |
46 181,3 |
464,6 |
6 050 000 000 |
387 000 000 |
13,5 |
4,4 |
100 |
7 143,9 |
13 500 |
82 397 381 |
221 761,6 |
Источник : составлено авторами. Source : compiled by the authors.
что тоже говорит о наличии значительных выбросов. Переменные Х 6– Х 9 показывают более стабильное поведение: их значения варьируются в узком диапазоне, а стандартные отклонения относительно малы. Такую стабильность можно объяснить относительно равномерным распределением переменных по регионам РФ. Переменные Х 6– Х 8 отражают уровень цифровизации и ИКТ-инфраструктуры, повышение которого в последние годы активно продвигается на уровне федерации. Это привело к сокращению разрыва между регионами за счет программ цифровой трансформации, нацпроектов и субсидирования. Переменная Х 9 – численность населения трудоспособного возраста – изменяется относительно слабо, так как определяется демографической структурой, эволюционирующей постепенно и не подверженной резким колебаниям на уровне региона.
Стоит отметить, что для некоторых переменных значения максимума значительно превышают 75-й квартиль, что может потребовать дополнительной обработки данных, а именно логарифмирования. Таким образом, данные табл. 4 указывают на наличие как симметрично распределенных переменных, так и переменных с высокой степенью асимметрии, что будет учтено при построении моделей машинного обучения.
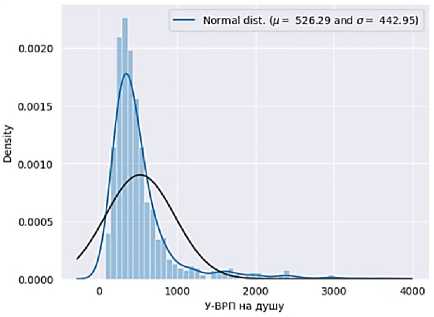
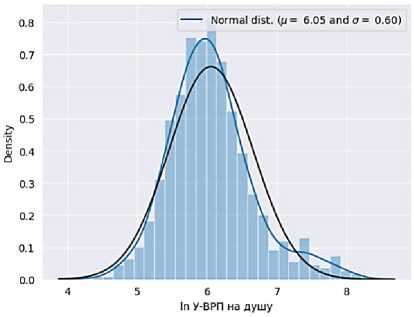
Авторами была идентифицирована правосторонняя асимметрия. Об этом свидетельствует рис. 1. Было принято решение логарифмировать ряд переменных. Построенная гистограмма плотности распределения после процедуры логарифмирования демонстрирует, что распределение стало ближе к нормальному, правый хвост сжался, аномальные значения сократились (рис. 2).
Источник : составлено авторами.
Source : compiled by the authors.
Рис. 1. Гистограмма плотности распределения до логарифмирования
Fig. 1. Histogram of the distribution density before logarithmization
Источник : составлено авторами.
Source : compiled by the authors.
Рис. 2. Гистограмма плотности распределения после логарифмирования
Fig. 2. Histogram of the distribution density after logarithmization
Для реализации построения моделей предсказания значений ВРП в краткосрочной перспективе авторами импортированы необходимые библиотеки и написан соответствующий код в средe Google Colaboratory . Код реализует построение каждой отдельной модели. Так, в начале авторы смоделировали ВРП с применением Linear Regression .
Метрики качества модели Linear Regression представлены в табл. 5.
Табл. 5. Метрики качества Linear Regression
Table 5. Linear Regression quality metrics
Метрика Тренировочная Тестовая
MSE 0,0550,050
MAE 0,1760,181
R2 0,8450,872
Источник : составлено авторами.
Source : compiled by the authors.
Результаты, полученные на тренировочной выборке, позволяют сказать, что модель значима, удовлетворяет требованиям адекватности по различным критериям, в том числе высокому R 2, а значит, может быть использована для прогнозирования и интерпретации.
Модель Linear Regression показывает достаточно хорошее качество как на тренировочной, так и на тестовой выборках. Разница между метриками на этих выборках относительно невелика, что указывает на отсутствие существенного переобучения.
Значения R 2 близки к 1, что говорит о высокой корреляции между предсказанными и фактическими значениями.
Следует указать на ряд незначимых переменных, значение p-value которых больше 0,05. К их числу относятся следующие: ln Х 5 – инвестиции в ОК ИКТ; Х 6 – продажи через интернет; Х 7 – занятые в ИКТ, что указывает на статистическую незначимость их влияния на целевую переменную. Присутствие этих переменных в качестве экзогенных может ухудшать интерпретируемость и качество модели в целом.
Статистика Durbin–Watson была использована для проверки автокорреляции остатков модели. Коэффициент Durbin–Watson, равный 1,88, что близко к 2, говорит об отсутствии автокорреляции остатков. Данный признак указывает на корректность модели.
С нашей точки зрения, значение MSE само по себе не является напрямую интерпретируемым в прикладном смысле, поскольку выражается в квадратичных единицах измерения зависимой переменной. Значение MSE на тренировочной выборке составляет 0,055, следовательно, можно говорить об относительно низкой средней ошибке предсказания модели на данных, по которым она обучалась. Это говорит о том, что модель хорошо подстроилась под имеющиеся данные и не содержит признаков переобучения. На тестовой выборке MSE = 0,050, что близко к значению на тренировочной выборке. Это говорит о хорошей обобщающей способности модели: она не просто запомнила обучающие данные, а показала устойчивую точность на новых наблюдениях.
Значение показателя MAE (средняя абсолютная ошибка), равное 0,18, показывает, на сколько в среднем модель ошибается в единицах целевой переменной.
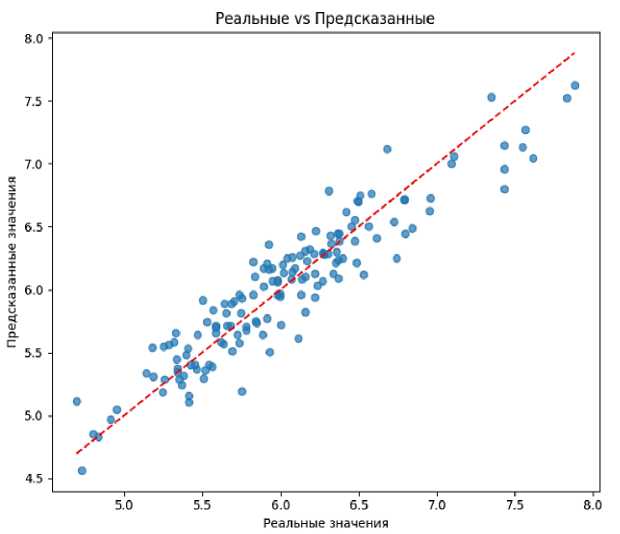
На рис. 3 представлен график реальных и предсказанных значений, построенный на данных тестовой выборки. Значения находятся вблизи линии тренда, но есть те, которые отдалены от нее. Большинство значений находятся вблизи линии тренда, что говорит об умеренной точности предсказания модели.
Далее построена модель LGBM Regressor . Метрики качества по результатам моделирования представлены в табл. 6.
Результаты, полученные на тренировочной выборке, позволяют сказать, что модель значима, удовлетворяет требованиям адекватности по различным критериям, в том числе высокому R 2, а значит, может быть использована для прогнозирования и интерпретации. Данный вывод имеет характер диагностики: модель хорошо подстроилась под данные.
Наблюдается небольшое расхождение между значениями метрик на тренировочной и тестовой выборках исследования.
Источник : составлено авторами. Source : compiled by the authors.
Рис. 3. График «Реальные значения vs Предсказанные» Linear Regression
Fig. 3. Actual vs Predicted Values schedule of Linear Regression
Отметим, что значение R 2 на тестовой выборке показывает высокую объяснительную способность модели. Модель объясняет 88 % дисперсии зависимой переменной, что является хорошим результатом, а значит, она обладает достаточно высокой прогнозной способностью, способна давать точные прогнозы. Предыдущие выводы, сделанные по итогам анализа модели, подтвердились.
Табл. 6. Метрики качества LGBM Regressor
Table 6. LGBM Regressor quality metrics
|
Метрика |
Тренировочная |
Тестовая |
|
MSE |
0,0039 |
0,0484 |
|
MAE |
0,0474 |
0,1499 |
|
R 2 |
0,9890 |
0,8776 |
Источник : составлено авторами.
Source : compiled by the authors.
MSE и MAE на тестовой выборке немного выше, чем на тренировочной, однако разница в значениях данных метрик качества некритическая, что указывает на приемлемую обобщающую способность.
В итоге можно сделать следующие выводы по настройке гиперпараметров модели:
– subsample = 0,8 показывает, что модель будет использовать 80 % случайно выбранных объектов из тренировочной выборки при построении каждого дерева; помогает бороться с переобучением;
– num_leaves = 20 отражает максимальное количество листьев (ветвей) в каждом дереве (чем больше листьев, тем выше модельная сложность и потенциальная точность, однако тем выше риск переобучения);
– n_estimators = 70 означает количество деревьев в ансамбле, создает баланс между качеством и скоростью обучения (чем больше деревьев в ансамбле, тем дольше обрабатывается код и выше риск переобучения);
– min_child_samples = 5 демонстрирует минимальное количество объектов в листе дерева и предотвращает слишком глубокое деление, если в подвыборке слишком мало объектов;
– max_depth = 7 означает максимальную глубину дерева, ограничивает рост дерева, помогает бороться с переобучением;
– learning_rate = 0,1 говорит о скорости обучения (насколько сильно каждый следующий шаг влияет на итоговую модель); 0,1 – стандартное начальное значение;
– colsample_bytree = 0,6 означает долю признаков, случайно выбираемых для каждого дерева, снижает корреляцию между деревьями, помогает предотвратить переобучение.
На рис. 4 представлен график реальных и предсказанных значений на данных тестовой выборки.
Источник : составлено авторами.
Source : compiled by the authors.
Рис. 4. График «Реальные значения vs Предсказанные» LGBM Regressor
Fig. 4. Actual vs Predicted Values schedule of LGBM Regressor
Из данных графика на рис. 4 видно, что значения расположены достаточно близко к линии тренда. Однако есть отклонения, указывающие на погрешность в предсказании.
Далее авторы построили модель класса Gradient Boosting Regressor , которая является довольно распространенной моделью машинного обучения. После настройки гиперпараметров определены метрики качества (табл. 7).
Опираясь на результаты тренировочной выборки, можно сказать, что модель значима, удовлетворяет требованиям адекватности по различным критериям, в том числе высокому R 2, а значит, может быть использована для прогнозирования и интерпретации.
Табл. 7. Метрики качества модели Gradient Boosting Regressor
Table 7. Gradient Boosting Regressor quality metrics
|
Метрика |
Тренировочная |
Тестовая |
|
MSE |
0,0025 |
0,0423 |
|
MAE |
0,0397 |
0,1445 |
|
R2 |
0,9930 |
0,8931 |
Источник : составлено авторами.
Source : compiled by the authors.
Разница между результатами на тренировочной и тестовой выборках незначительна, а значит, Gradient Boosting Regressor не является переобученной. Показатели качества на тестовой выборке незначительно уступают показателям на тренировочной, что является признаком стабильности модели. Коэффициент детерминации показывает высокое значение и указывает на то, что модель объясняет почти 90 % вариации целевого показателя, демонстрируя тем самым отличный результат. Модель действительно способна давать точные прогнозы. Предыдущие выводы, сделанные по итогам анализа модели, подтвердились.
Выводы по настройке гиперпараметров модели таковы:
– learning_rate = 0,01 – малая скорость обучения (делает модель более устойчивой к переобучению, но может потребовать большего числа деревьев);
– max_depth = 5 – максимальная глубина каждого дерева решений (небольшая глубина помогает контролировать сложность модели и предотвращает переобучение);
– min_samples_leaf = 1 – минимальное количество наблюдений в листе дерева (допускает самые маленькие разбиения, что может повысить детализацию модели);
– n_estimators = 70 – количество деревьев в ансамбле;
– subsample = 0,8 – типичное и часто эффективное значение, обеспечивающее баланс между точностью и скоростью обучения.
На рис. 5 представлен график реальных и предсказанных значений на данных тестовой выборки.
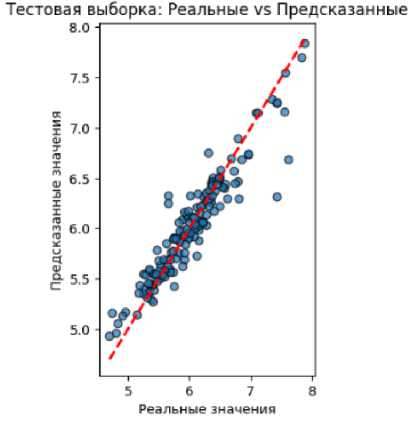
Источник : составлено авторами.
Source : compiled by the authors.
Рис. 5. График «Реальные значения vs Предсказанные» Gradient Boosting Regressor
Fig. 5. Actual vs Predicted Values schedule of Gradient Boosting Regressor
График на рис. 5 показывает распределение реальных значений в зависимости от предсказанных. Заметно, что значения распределены вдоль красной линии и явный разброс отсутствует.
Далее построена модель класса Decision Tree Regressor . Метрики качества по результатам моделирования представлены в табл. 8.
Табл. 8. Метрики качества модели Decision Tree Regressor
Table. 8. Decision Tree Regressor quality metrics
|
Метрика |
Тренировочная |
Тестовая |
|
MSE |
0,0265 |
0,0733 |
|
MAE |
0,1162 |
0,1987 |
|
R 2 |
0,9254 |
0,8148 |
Источник : составлено авторами.
Source : compiled by the authors.
Опираясь на результаты тренировочной выборки, можно сказать, что модель значима, удовлетворяет требованиям адекватности по высокому R 2, а значит, может быть использована для прогнозирования.
Модель демонстрирует хорошие показатели качества как на тренировочном, так и на тесто- вом наборе данных. Она не страдает от значительного переобучения, а ее прогнозы имеют приемлемую точность. Модель действительно способна давать точные прогнозы. Предыдущие выводы, сделанные по итогам анализа модели, подтвердились.
В результате можно сделать такие выводы по настройке гиперпараметров модели:
– max_depth = 12 – максимальная глубина дерева (ограничивает рост дерева, помогает бороться с переобучением);
– max_features = sqrt – при построении каждого дерева выбирается корень из общего числа признаков для поиска наилучшего разделения (сплита);
-
– min_samples_leaf = 4 – минимальное количество объектов в конечном листе дерева;
-
– min_samples_split = 2 – минимальное количество объектов, необходимое для разделения узла (узел может быть разделен при наличии хотя бы двух объектов);
-
– n_estimators = 140 – количество деревьев в ансамбле.
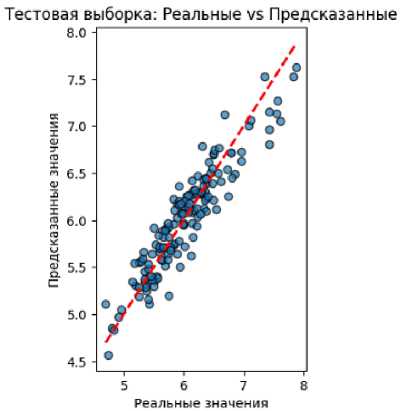
На рис. 6 представлен график реальных и предсказанных значений на данных тестовой выборки.
Тестовая выборка: Реальные vs Предсказанные
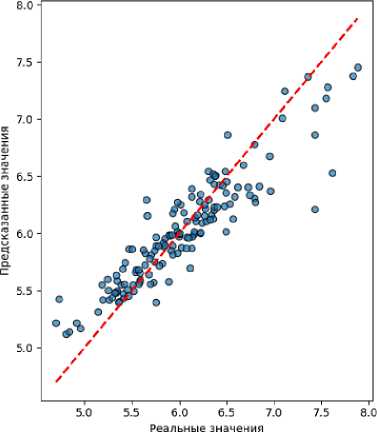
Источник : составлено авторами.
Source : compiled by the authors.
Рис. 6. График «Реальные значения vs Предсказанные» Decision Tree Regressor
Fig. 6. Actual vs Predicted Values schedule of Decision Tree Regressor
Табл. 9. Сводные результаты метрик качества всех реализованных моделей машинного обучения
Table 9. Summary of quality metrics results for all implemented machine learning models
|
Модель |
MSE |
MAE |
R2 |
|||
|
train |
test |
train |
test |
train |
test |
|
|
Linear Regression |
0,055 |
0,050 |
0,176 |
0,181 |
0,845 |
0,872 |
|
Gradient Boosting Regressor |
0,0025 |
0,0423 |
0,0397 |
0,1445 |
0,9930 |
0,8931 |
|
LGBM Regressor |
0,0039 |
0,0484 |
0,0474 |
0,1499 |
0,9890 |
0,8776 |
|
Decision Tree Regressor |
0,0265 |
0,0733 |
0,1162 |
0,1987 |
0,9254 |
0,8148 |
|
Источник : составлено авторами. Source : compiled by the authors. |
||||||
График на рис. 6 показывает распределение реальных значений в зависимости от предсказанных. В целом видно, что значения сконцентрированы вдоль красной линии, однако наблюдается небольшая группировка значений и небольшой разброс.
В табл. 9 представлена сводная информация, в которой отражены метрики качества всех реализованных в данной работе моделей машинного обучения.
Сравнительный анализ четырех построенных моделей машинного обучения показал, что на тестовой выборке Linear Regression имеет R 2, равный 87 %, Gradient Boosting Regressor – 89 %, LGBM Regressor – 88 %, Decision Tree Regressor – 81 %. Наилучшие результаты по точности прогноза демонстрируют Gradient Boosting Regressor и LGBM Regressor , которые обеспечили минимальные значения ошибок ( MSE и MAE ) и высокие коэффициенты детерминации ( R ²) как на тренировочной, так и на тестовой выборке, что указывает на хорошую обобщающую способность и устойчивость моделей. Linear Regression , несмотря на простоту, показала достойное качество предсказаний, подтверждая наличие линейной зависимости в данных и выступая как сильная интерпретируемая базовая модель. Наименьшая точность оказалась у Decision Tree Regressor , которая продемонстрировала наибольшие ошибки и наименьшее значение R ² на тесте, что может говорить о слабой устойчивости к разнообразию данных или переподгонке.
ЗАКЛЮЧЕНИЕ
Таким образом, в рамках данного исследования построены четыре модели машинного обучения, которые позволяют давать кратко- срочный прогноз ВРП. Построенные модели показали высокие значения коэффициента детерминации, при этом лучшими по качеству прогноза оказались ансамблевые методы. Полученные модели обладают практической значимостью и могут быть использованы для поддержки управленческих решений и оценки экономических перспектив территорий. Следовательно, можно утверждать, что выдвинутая авторами гипотеза подтвердилась.
Для прогнозирования ВРП предпочтительнее использовать методы машинного обучения вместо традиционных эконометрических моделей, поскольку они дают возможность получать более точные прогнозы. Применение методов машинного обучения позволяет эффективно обрабатывать большие объемы данных, а значит, работать с большой выборкой. Более того, методы машинного обучения имеют высокую скорость обработки данных, являются адаптивными, обладают способностью давать прогнозы с недоступной для других методов точностью. При этом нельзя не отметить их ключевой недостаток, связанный с интерпретируемостью результатов. Как правило, интерпретируемость игнорируется при работе с моделями машинного обучения, так как их цель – прогноз. Иными словами, проблему интерпретируемости результатов можно отнести к одному из основных ограничений методики исследования. К подобным ограничениям относятся также отсутствие официальных статистических данных по ряду показателей, отражающих как социально-экономическое развитие регионов, так и уровень их цифровизации, ограниченный период и набор экзогенных переменных. В дальнейшем можно включить в перечень экзогенных переменных показатели из других групп и категорий.
В данной работе выбор экзогенных переменных, сочетающих традиционные экономические показатели и факторы цифровизации, позволил учесть современные тенденции цифровой трансформации регионов.
