Multimodal ChatGPT-Driven Learning Companion for Code Reasoning and Concept Mastery in Computing Education

Author: Thacha Lawanna
Journal: International Journal of Modern Education and Computer Science @ijmecs
Article in issue: 2 vol.18, 2026.
Free access
The rapid maturation of large language models has opened new opportunities for capable of enhancing learning outcomes, enriching instructional practice, and supporting large-scale computing education with high reliability through personalized, scalable, and data-driven instructional support. The ChatGPT Learning Companion (ChatGPT-LC) introduces a multimodal framework that integrates conversational scaffolding, code reasoning, misconception diagnostics, and learner analytics into a unified system capable of adapting instruction in real time. Deployed across 260 undergraduate learners in three programming courses, ChatGPT-LC produced substantial performance gains, including a 35.20% increase in concept mastery, 27.90% improvement in debugging accuracy, and error-type reductions ranging from 53.60% to 65.50%. Behavioral analytics revealed strong correlations between engagement intensity and performance (up to r = 0.740), with reflective and exploratory learners achieving scores above 88–90%. Instructor workload decreased by more than 32 hours per week, supported by high expert-verified accuracy (92–96%) of AI-generated feedback. System-level benchmarks demonstrated robust scalability, maintaining 97.00% success rates at 500 concurrent users and reducing latency from 450 ms to under 100 ms after optimization. Collectively, these results show that ChatGPT-LC functions not only as an automated tutor but as an adaptive cognitive partner capable of enhancing learning outcomes, enriching instructional practice, and supporting large-scale computing education with high reliability and pedagogical fidelity.
ChatGPT, Programming Pedagogy, Adaptive Assistance, Code Reasoning, Learner Modeling
Short address: https://sciup.org/15020232
IDR: 15020232 | DOI: 10.5815/ijmecs.2026.02.04
Text of the scientific article Multimodal ChatGPT-Driven Learning Companion for Code Reasoning and Concept Mastery in Computing Education
The rapid advancement of large language models (LLMs) such as ChatGPT has created unprecedented opportunities for innovation in computing education [1]. As conversational AI systems become more capable of understanding, generating, and reasoning about both natural language and source code, their potential to transform how students learn programming concepts, debug logic, and acquire computational thinking skills continues to expand [2]. Traditional pedagogical models in introductory programming courses often struggle to provide timely, individualized feedback (particularly in classrooms with large enrollments or diverse learner backgrounds) [3]. Students frequently encounter difficulties in interpreting error messages, decomposing problems, or translating conceptual knowledge into functional code [4]. These challenges, if not addressed promptly, can lead to accumulating misconceptions, reduced motivation, and lower persistence in computing pathways [5]. Recent research increasingly points to AI-driven learning companions as a scalable solution for supporting learners; however, existing automated tutors often offer rule-based guidance, limited adaptivity, and minimal insight into learner cognition [6].
To address these gaps, this paper introduces the ChatGPT Learning Companion (ChatGPT-LC), a multimodal framework designed to support programming education through natural language interaction, executable code analysis, and adaptive learner modeling [7]. Unlike conventional automated feedback systems that emphasize correctness-based evaluation, ChatGPT-LC integrates cognitive scaffolding, misconception diagnosis, and concept-reinforcement cycles to guide students through the reasoning processes underlying their solutions [8]. The system analyzes student input (including code snippets, explanations, and reflections) while maintaining a dynamic representation of each learner’s conceptual state [9]. This enables ChatGPT-LC to deliver tailored prompts, targeted clarifications, and progressive hints that adapt to the learner’s proficiency and detected misunderstandings in real time [10].
The framework was deployed across introductory computer science courses involving 260 undergraduate students, offering assistance during lab sessions, programming assignments, and self-regulated study tasks. Results demonstrate the transformative potential of conversational AI in educational settings. Students who actively used ChatGPT-LC showed a 35.2% improvement in conceptual mastery, a 27.9% increase in debugging accuracy, and deeper reflective reasoning as measured through rubric-based analyses. Qualitative feedback further highlights increased confidence, improved understanding of program logic, and stronger engagement with course material. Instructors reported that learner analytics generated by the system (such as trends in common misconceptions, progression curves, and difficulty hotspots) provided actionable insight for instructional planning, curriculum refinement, and targeted interventions.
Importantly, the deployment prioritized ethics, transparency, and student privacy through PDPA-compliant data practices, explicit consent mechanisms, and bias-mitigation safeguards. These considerations reinforce the need for responsible integration of LLM-based tools in educational environments, ensuring that innovation aligns with pedagogical integrity and institutional policy.
Thus, ChatGPT-LC demonstrates how multimodal, adaptive conversational AI can reshape computing education into a more responsive, inclusive, and data-driven ecosystem. By combining advanced code reasoning with evidencebased learning strategies, this work contributes a scalable framework for enhancing programming instruction and provides empirical evidence supporting the pedagogical value of LLMs in developing the next generation of computer science learners.
2. Related Works 2.1 Intelligent Support Systems in Computing Education
The emergence of intelligent support systems in computing education reflects a long-standing ambition to provide timely, personalized help that strengthens conceptual understanding and problem-solving skills [11]. Early Intelligent Tutoring Systems (ITS), such as Cognitive and Logic Tutors, relied on expert-crafted rules, solution paths, and diagnostic logic to deliver stepwise feedback similar to human instructors [12,13]. Although effective in well-structured domains, these systems were expensive to build and maintain, with limited adaptability when facing open-ended or syntactically complex tasks such as programming, where hand-crafted rules struggled to cover the diversity of learner solutions [14]. As computing education research matured, more dynamic environments including Problem-Solving Environments, interactive lab platforms, and visualization-based tools were introduced to support CS1/CS2 courses [15,16]. Systems like BlueJ, Alice, Greenfoot, and Scratch helped novices grasp core programming ideas through visual metaphors and interactive experimentation, yet most still emphasized correctness over insight into students’ mental models or reasoning processes [17,18].
To overcome these limitations, recent work has leveraged learner modeling, Educational Data Mining, and Learning Analytics to derive adaptive feedback from large-scale traces of student activity. Data-driven frameworks such as Hint Factory and related tutors infer common solution paths and difficulty patterns from historical data, generating hints without requiring exhaustive manual rule authoring [19]. In parallel, advances in deep learning and NLP have led to a shift toward flexible, generative architectures that generalize across tasks and domains [22,23,24]. Large language models (LLMs), particularly GPT-style models, can interpret code, explain behavior, detect errors, and propose alternative solutions, enabling conversational tutoring that augments traditional autograders [20,25,26,27]. Codefocused transformers such as CodeBERT and Codex further enhance support for code synthesis, semantic error detection, and formative feedback, although concerns remain about overreliance, occasional inaccuracies, and students’ tendency to accept AI outputs uncritically [28,29]. Despite these challenges, the integration of LLM-based assistants into programming education marks a major transition toward data-driven, conversational support infrastructures in which systems like ChatGPT and derivative models (e.g., ChatGPT-LC) combine natural language dialogue, learnerstate modeling, and multimodal analytics to function as unified, adaptive learning companions [20,21,30].
-
2.2 Automated Feedback and Code-Aware Tutoring Tools
-
2.3 Conversational AI and LLMs for Learning
-
2.4 The Cognitive Role of ChatGPT in Problem-Solving
Automated feedback systems have long been central to programming instruction, aiming to provide students with immediate guidance and reduce the burden placed on instructors [31]. Traditional automated graders (e.g., CodeRunner, Web-CAT, and Autolab) evaluate student submissions against test suites to check correctness, generate performance metrics, and detect style violations. While effective for scaling assessment, these systems rarely support conceptual understanding or explain the underlying causes of a student’s errors, often leading learners to rely on trial-and-error approaches rather than reflective problem solving [32]. To address the limitations of correctness-only evaluation, more sophisticated code-aware tutoring systems have emerged. Tools such as Codewebs, OverCode, Python Tutor, and Tracing Tutors provide deeper insight into program structure, runtime behavior, and control flow [33]. These systems assist learners by visualizing execution traces, clustering similar code solutions, or highlighting structural deviations from correct patterns. Recent work also explores algorithmic hint-generation techniques, including path-based feedback, semantic enrichment, and program-synthesis–based correction strategies. For example, some systems use symbolic execution or error-tolerant AST (Abstract Syntax Tree) matching to generate targeted hints that align more closely with the learner’s original intentions [34].
Nevertheless, even advanced code-aware systems face limitations in addressing the diversity of student reasoning styles, interpreting natural language questions, or engaging in extended dialogue [35]. Many tools provide only static hints, lack the ability to follow up based on student responses, or fail to capture the broader context of a learner’s struggle. Moreover, most automated feedback systems do not model student cognition or adapt to their evolving conceptual mastery [36]. Conversational interfaces built on LLMs offer a compelling alternative by enabling real-time, interactive exploration of concepts. LLM-powered tools can analyze snippets of code, explain logic in plain language, generate examples tailored to the learner’s context, and dynamically reformulate explanations based on follow-up questions. ChatGPT-LC extends these capabilities by embedding code reasoning inside a learner-modeling architecture, enabling the system to generate feedback not only based on correctness but also based on estimated misconceptions, confidence levels, and observed reasoning patterns [37].
Conversational AI has increasingly been recognized as a valuable component of modern educational technology, offering a natural and flexible interface for learner support [38]. Early systems relied on rule-based pattern matching (e.g., AIML chatbots) and domain-specific scripts to simulate dialogue, but these approaches lacked deep understanding and often produced rigid or unhelpful interactions [39]. The emergence of transformer-based architectures and large-scale pretraining fundamentally advanced conversational capability, enabling systems to generate coherent responses, infer user intent, and sustain open-domain dialogue. Large Language Models (LLMs) such as GPT-3, GPT-4, PaLM, and LLaMA demonstrate strong performance in explanation, summarization, reasoning, and knowledge retrieval, and have been applied in education for tasks including automated tutoring, question generation, reading-support assistance, peer-feedback guidance, and adaptive study planning. Empirical findings suggest that LLMs can clarify misconceptions, offer alternative explanations, and enhance learner engagement through interactive dialogue-based support [40]. In computing education, conversational AI further helps students articulate problems, interpret compiler messages, and connect abstract concepts with concrete examples, particularly when learners struggle to frame debugging questions or clearly express confusion [41]. LLM-enabled dialogue assists by interpreting ambiguous or incomplete queries, reformulating student problem statements, and providing contextualized, reasoning-based explanations that promote reflective learning and conceptual clarity [42].
Despite these pedagogical benefits, important challenges persist. LLMs may sometimes hallucinate incorrect explanations, express unwarranted confidence, or unintentionally reinforce misconceptions when outputs are not aligned with instructional objectives [43]. Responsible deployment therefore requires alignment with structured educational frameworks, transparency and verification mechanisms, and ongoing human oversight to ensure reliability and ethical use [44]. ChatGPT-LC responds to these challenges by integrating cognitive scaffolding, misconceptiondiagnostic processes, and PDPA-compliant safeguards, enabling the system to generate feedback that balances responsiveness with pedagogical accuracy, learner safety, and responsible AI governance [45].
A growing body of research examines the cognitive functions that ChatGPT can support during the problemsolving process [46]. Programming tasks require multiple layers of cognition, including comprehension of problem requirements, design of algorithmic solutions, debugging of syntactic or semantic errors, and reflection on solution quality [47]. Novice learners often struggle with misconceptions about control flow, variable state, recursion, and abstraction, which impede their ability to progress independently [48].
ChatGPT can function as a cognitive amplifier by externalizing parts of the reasoning process. When students articulate their thought process in conversation with the model, they engage in metacognitive practices that include selfexplanation, hypothesis testing, and reflective refinement [49]. The act of describing a problem to a conversational agent reorganizes internal representations, clarifies gaps in understanding, and supports knowledge restructuring. This aligns with constructivist learning theories and Vygotsky’s concept of the Zone of Proximal Development (ZPD), where guided interactions facilitate conceptual growth [50].
Moreover, ChatGPT can model expert-like reasoning patterns by providing structured decomposition strategies, identifying missing logic, and offering conceptual bridges that guide learners from novice understanding toward intermediate expertise. The model’s ability to simulate multiple perspectives (including student inaccuracies and expert corrections) enables it to engage learners in cognitive conflict and resolution, a key driver of conceptual change [51].
In debugging tasks, ChatGPT helps learners unpack compiler errors, recognize runtime anomalies, and trace variable state across execution flows [52]. By generating explanations in multiple modalities (textual reasoning, step-by-step traces, analogies, and structured hints) the model supports diverse cognitive strategies suited to different learning styles [53]. ChatGPT-LC leverages these affordances by explicitly integrating reasoning traces, code execution analysis, and reflective prompting into a unified scaffolding model, thereby aligning cognitive support with each learner’s developmental trajectory.
2.5 Opportunities and Open Challenges in LLM-Driven Pedagogy
3. Research Methodology
3.1 Research Approach and Goals
The integration of LLMs into computing education presents transformative opportunities but also introduces unresolved challenges that require sustained research attention [54]. Opportunities include scalable personalized instruction, adaptive feedback generation, and data-driven insight into class-wide misconceptions. LLMs allow instructors to shift from high-volume administrative feedback toward higher-order pedagogical design, while students benefit from immediate, interactive support that traditionally required substantial instructor time. LLM-driven systems also enable multimodal representations of concepts (combining examples, analogies, visualizations, and execution traces) which can deepen understanding for students with diverse learning preferences [55]. Another promising direction is the incorporation of learner analytics derived from LLM interactions. Dialogue histories, code evolution patterns, and reasoning trajectories can be analyzed to detect early signs of disengagement, predict performance trends, or flag conceptual gaps. Such insights support proactive intervention strategies, personalized study recommendations, and evidence-based curricular improvement [56].
However, the adoption of LLMs raises several open challenges. First, the reliability and factual accuracy of LLM-generated explanations remain inconsistent, particularly for ambiguous or poorly defined student inputs. Without robust oversight, students may internalize incorrect conceptualizations. Second, LLMs risk amplifying inequities if access varies across socioeconomic backgrounds or if model biases disproportionately affect marginalized learners. Ensuring comprehensible, culturally aligned feedback is essential [57].
Third, privacy and data governance pose significant concerns. Educational institutions must ensure compliance with frameworks such as PDPA, GDPR, and FERPA, while maintaining transparency about data usage, storage, and model behavior. Fourth, ethical guidelines must address issues of overreliance on AI assistance, academic integrity, and the risk of students using generative models to bypass learning processes [58].
Finally, pedagogical integration must be carefully orchestrated. LLMs should complement (not replace) human instructors. Their deployment requires training for both educators and students, clear communication of capabilities and limitations, and embedding within structured curricula that emphasize critical thinking [59].
ChatGPT-LC addresses many of these challenges by implementing safeguards, structured scaffolding, and analytics-driven adaptivity. However, more work is needed to define best practices, optimize model alignment for educational reasoning, and ensure equitable access. The research community continues to explore how LLM-driven pedagogy can evolve into a reliable, ethical, and transformative component of modern computing education [60].
This study adopted a mixed-method research design combining quantitative experimentation with qualitative behavioral analytics to examine the impact of the ChatGPT Learning Companion (ChatGPT-LC) in computing education. The quantitative phase used pre- and post-intervention measures to evaluate gains in conceptual understanding, debugging proficiency, and reasoning ability, supported by system-log data on code revisions, response accuracy, and interaction frequency. The qualitative phase analyzed conversation transcripts, learner reflections, and usability feedback to reveal cognitive strategies, sources of confusion, and perceptions of AI-mediated support. Integrating these data streams enabled triangulation of learning outcomes with behavioral and experiential evidence.
The study was guided by three goals: measuring conceptual gains across key programming constructs, analyzing learner–AI interaction patterns to understand how students refined their thinking through dialogue, and evaluating perceptions of usefulness, accuracy, and trust in the system. Together, these goals provided a comprehensive evaluation of both learning outcomes and user experience.
-
3.2 Participants and Sampling Strategy
-
3.3 System Overview and Design Process
-
3.4 Instruments and Data Sources
-
3.5 Analytical Methods
The study involved 260 undergraduate students enrolled at a large public university in northern Thailand. Participants were drawn from three introductory programming courses commonly taken by students majoring in Computer Science, Software Engineering, Information Technology, and Digital Innovation–related fields. The cohort consisted primarily of first- and second-year students, representing a mix of academic backgrounds and varying levels of prior exposure to programming. A cluster sampling strategy was used, in which entire course sections served as naturally occurring clusters. Each section was assigned to one of the study conditions (either the ChatGPT-LC assistance condition or the standard course tools condition). This approach minimized disruption to normal teaching routines and reduced the likelihood of cross-group information contamination among students. Data were collected online to ensure consistency and accessibility. Students completed all research instruments (including pre-tests, posttests, programming tasks, and perception surveys) through a secure web-based platform accessible via personal laptops or mobile devices. Participation was voluntary, and students provided informed consent electronically prior to engaging in any study activities. The online data-collection process allowed researchers to manage submissions efficiently while preserving the authenticity of students’ typical learning environments.
Internal Validity Controls: To mitigate threats associated with quasi-experimental cluster assignment, several internal validity controls were implemented. Baseline equivalence between groups was verified through independentsamples t-tests on pre-intervention concept scores, which revealed no statistically significant differences (p > .05), confirming comparable initial proficiency. To improve transparency and allow independent verification of baseline equivalence and variance assumptions, detailed descriptive statistics have now been added for all primary constructs across both groups. These include group-specific standard deviations, standard errors, and 95% confidence intervals for pre-test scores, post-test scores, debugging accuracy, and reasoning depth measures. Reporting these dispersion indicators enables clearer evaluation of score variability, overlap between groups, and the practical magnitude of observed differences. In addition, Levene’s tests for homogeneity of variance and Box’s M tests for equality of covariance matrices were conducted and are now explicitly reported to confirm that MANOVA assumptions were satisfied. The inclusion of these descriptive and inferential statistics strengthens the interpretability and reproducibility of the findings by allowing readers to assess both central tendency and variability, ensuring that the reported improvements reflect consistent group-level patterns rather than uneven distributions or variance artifacts. All course sections were taught by the same instructor using identical lecture materials, laboratory exercises, assessment rubrics, and assignment specifications to ensure instructional consistency. Programming tasks, deadlines, and grading criteria were standardized across conditions, and submissions were anonymized prior to evaluation to reduce grading bias. Teaching assistants were blinded to study condition during assessment, and automated grading components were applied uniformly across groups. These controls strengthened causal interpretation by minimizing instructor effects, assessment variation, and pre-existing performance disparities.
The ChatGPT Learning Companion was designed as a multimodal intelligent tutoring environment composed of four tightly integrated components: a conversational interface, a code-reasoning engine, a misconception detection module, and an adaptive prompting system connected to a learning analytics backend. The conversational interface allowed students to interact with the AI model using natural language, facilitating question asking, debugging discussions, and structured code explanation dialogues. The code-reasoning engine extended the model’s capabilities by analyzing syntactic and semantic patterns in student submissions, enabling the system to identify errors, propose corrections, and generate execution-level reasoning steps. The misconception detection module employed pattern recognition and rule-based categorization to classify student misunderstandings related to loops, conditionals, recursion, variable scoping, and algorithmic logic. These outputs then informed the adaptive prompt refinement mechanism, which tailored explanations, scaffolding hints, and reflective questions to the learner’s level of understanding. All interaction data flowed into a learning analytics backend that tracked engagement, task completion, code revision patterns, and conceptual progress across the intervention period. The iterative design process incorporated pilot testing, usability evaluation, and instructor feedback to refine system responses, ensure pedagogical alignment, and reduce noise in feedback generation.
Data for the study were collected through multiple instruments to ensure comprehensive measurement of student learning, cognitive interaction, and system effectiveness. Concept mastery tests served as the primary measure of learning gains, designed to assess declarative knowledge, procedural fluency, and applied reasoning across the programming topics taught during the semester. Code attempts and revision logs provided a granular view of students’ evolving understanding, documenting how their solutions changed before and after AI-provided guidance. Interaction transcripts captured the content of dialogue between students and ChatGPT-LC, enabling analysis of reasoning depth, question formulation, prompt effectiveness, and alignment between AI feedback and learner needs. Engagement metrics—including message frequency, session duration, hint acceptance rates, and persistence in debugging tasks— served as indicators of motivational and behavioral responses to the AI assistant. Finally, usability surveys collected student perceptions of clarity, usefulness, fairness, accuracy, and trust, allowing the study to explore how affective factors shaped learning outcomes and interactions with the system. Instructor workload was tracked using structured weekly activity logs documenting time spent on debugging assistance, clarification, feedback preparation, and consultation tasks.
The quantitative analysis employed multivariate analysis of variance (MANOVA) to compare learning outcomes between the ChatGPT-LC group and the control group using standard automated tools. Dependent variables included conceptual gains, debugging accuracy, reasoning depth scores, and performance across code-based tasks. MANOVA allowed the simultaneous testing of multiple learning outcomes while accounting for covariance among them, yielding insight into the holistic pedagogical impact of the system. In addition, multiple regression models were constructed to investigate behavioral predictors of learning success, identifying which interaction patterns (such as hint uptake, number of refinements, or depth of dialogue) were most strongly associated with conceptual improvement. These regression models helped isolate the mechanisms through which ChatGPT-LC exerted its influence. Complementing the quantitative analysis, qualitative thematic clustering was applied to interaction transcripts and open-ended survey responses to uncover patterns in how learners conceptualized AI assistance, articulated their reasoning, and responded to feedback. Themes such as reflective reasoning, metacognitive awareness, confusion resolution, and confidence development were extracted through iterative coding and clustering processes, enriching the interpretation of the quantitative findings and illuminating the cognitive role of the system.
Multicollinearity diagnostics using variance inflation factors (VIF) and tolerance confirmed that all engagement variables were within acceptable limits, indicating independent contributions to performance. Partial correlation analyses controlling for baseline concept scores and prior academic performance showed that engagement remained significantly associated with learning gains, although with slightly reduced magnitude. These results confirm that engagement has a meaningful independent relationship with performance beyond initial ability, strengthening confidence that the findings reflect genuine behavioral–learning effects rather than shared variance or pre-existing differences.
To improve methodological transparency, the behavioral clustering procedure has been clarified in the revised manuscript. Learner interaction categories were derived using an unsupervised clustering approach applied to normalized system-log features, including query frequency, revision count, hint usage, dialogue length, and interaction persistence. Prior to clustering, all variables were standardized to eliminate scale bias. The optimal number of clusters was determined using internal validation metrics, including silhouette coefficient analysis and elbow-method inspection of within-cluster variance, which indicated a stable and well-separated clustering structure. To further assess robustness, stability checks were performed using repeated subsampling and re-clustering, confirming consistent learner group assignments across iterations. Cluster interpretability was then established by examining dominant behavioral patterns within each group, leading to descriptive labels such as “Reflective Learners” and “Exploratory Users.” These procedures ensure that the reported behavioral categories reflect statistically grounded interaction patterns rather than subjective classification.
To strengthen the robustness of the reported findings, additional statistical diagnostics were conducted. Ninety-five percent confidence intervals were computed for all primary outcome measures, confirming that post-intervention gains in conceptual mastery (95% CI [31.4%, 38.9%]) and debugging accuracy (95% CI [23.6%, 31.8%]) remained statistically reliable beyond sampling variability. Observed effect sizes (Cohen’s d ranging from 0.63 to 0.91) were interpreted using established benchmarks (0.2 = small, 0.5 = medium, 0.8 = large), indicating predominantly medium-to-large effects. Prior to MANOVA, assumptions of multivariate normality, homogeneity of variance–covariance matrices (Box’s M test, p > .05), and absence of multicollinearity were verified. A post-hoc power analysis (α = .05, N = 260) yielded statistical power exceeding .90 for the primary dependent variables, suggesting adequate sensitivity to detect meaningful effects. Because intact course sections were assigned to conditions, the study followed a quasiexperimental cluster design rather than full randomization; however, baseline equivalence checks (including pre-test scores and prior GPA comparisons, p > .05) indicated no significant initial group differences.
To enhance transparency and strengthen the robustness of the multivariate analysis, additional MANOVA diagnostics have now been incorporated and will be fully reported in the revised manuscript. Specifically, multivariate test statistics including Wilks’ Lambda, Pillai’s Trace, Hotelling’s Trace, and Roy’s Largest Root were examined to confirm the consistency and stability of the observed group differences across dependent variables. Pillai’s Trace is reported as the primary statistic due to its robustness under potential deviations from covariance homogeneity, while Wilks’ Lambda is included for comparability with conventional reporting standards. All multivariate tests converged on statistically significant results, confirming the reliability of the overall group effect. In addition, follow-up univariate ANOVAs were accompanied by Bonferroni-adjusted post-hoc comparisons to control for familywise Type I error inflation across multiple dependent measures. These supplementary diagnostics, together with previously verified assumptions of multivariate normality and homogeneity of variance–covariance matrices, provide a more comprehensive evaluation of model validity and confirm that the reported performance differences are statistically robust and not artifacts of model specification or multiple testing.
3.6 Reliability and Validity Measures
3.7 Ethical Framework
3.8 Anticipated Contributions
4. System Model and Architectural Design
To ensure methodological rigor, the study employed multiple reliability and validity checks. Inter-coder reliability was established for qualitative analysis through independent coding of transcript segments by two trained researchers, with disagreements resolved through discussion until consensus was achieved. This process helped minimize interpretive bias and ensured robust thematic identification. Temporal triangulation was applied across pre-, mid-, and post-intervention data to confirm that observed improvements and behavioral patterns persisted over time rather than reflecting short-term fluctuations. Construct validity was ensured through careful alignment of instruments with theoretical constructs in computing education. Concept mastery tests were validated against course learning outcomes, while survey items were derived from established technology acceptance and educational usability scales. System logs and behavioral metrics were cross-referenced with performance indicators to ensure measurement consistency. Collectively, these reliability and validity procedures strengthened the credibility and generalizability of the study’s findings.
To address concerns regarding potential confirmation bias and to strengthen the credibility of the expert validation process, additional methodological details have been incorporated into the revised manuscript. The evaluation was conducted by a panel of independent experts consisting of experienced computing educators and instructional specialists who were not involved in the system’s design, development, or implementation. Experts were provided with anonymized samples of ChatGPT-LC feedback and corresponding student submissions, and they assessed pedagogical alignment, accuracy, clarity, and cognitive support using a structured evaluation rubric. To ensure objectivity, all materials were blinded to condition identifiers and system version information. Inter-rater reliability was examined using intraclass correlation coefficients (ICC), which indicated strong agreement across evaluators, confirming the consistency of the ratings. These procedures help ensure that the high validation scores reflect genuine instructional quality rather than evaluator bias, while acknowledging that future studies involving larger and more diverse expert panels will further strengthen external validation.
Ethical considerations guided every stage of the design and implementation of ChatGPT-LC, especially because the study involved collecting learner interaction data and analyzing their learning behaviors. The research strictly followed Thailand’s Personal Data Protection Act (PDPA) by ensuring that all data were handled through a secure and confidential process. This included storing information on protected servers, removing personal identifiers, and limiting data access to authorized researchers only. Before participating, students were clearly informed about the purpose of the study, the role of ChatGPT-LC, the types of data being collected, and how their information would be used. They provided electronic informed consent, with the option to withdraw at any time without academic consequences. To ensure fairness and safety, the system incorporated bias-mitigation measures, such as automated checks to prevent inappropriate, misleading, or overly directive feedback. When ChatGPT-LC generated responses that were uncertain or based on limited information, the system used clarity markers (e.g., “This is one possible approach…”) to help students recognize the tentative nature of the suggestions. These combined ethical safeguards ensured that the study maintained transparency, protected student privacy, and supported responsible use of AI tools within an educational environment. To strengthen ethical transparency, the revised manuscript now clarifies the formal oversight and governance procedures applied to the study. The research protocol was reviewed and approved by the university’s institutional ethics review committee prior to data collection, and all procedures complied with established guidelines for humansubject research and data protection. Participants provided informed consent electronically, and they were explicitly informed of the scope of data collection, anonymization procedures, and their right to withdraw without academic penalty. All interaction data were de-identified prior to analysis and stored on secure institutional servers with access restricted to authorized researchers. In accordance with PDPA requirements, data retention follows a defined institutional policy, under which research data are securely retained for a limited period for verification purposes and subsequently archived or permanently deleted. These measures ensure that learner privacy, ethical accountability, and regulatory compliance are maintained throughout the research lifecycle.
This research is expected to contribute several significant advancements to the fields of computing education, AI-assisted learning, and educational technology design. The study proposes a novel model of learner–AI collaboration that integrates conversational reasoning, code analysis, and adaptive scaffolding into a unified pedagogical framework. By evaluating both performance outcomes and cognitive interaction patterns, the research provides empirical evidence for how LLM-driven tools can facilitate conceptual reinforcement, improve debugging capability, and promote reflective reasoning. Furthermore, the learning analytics insights generated by the system highlight opportunities for scalable, data-driven approaches to instructional support, enabling instructors to identify patterns of misunderstanding and tailor interventions more effectively. Ultimately, the findings of this study underscore the transformative potential of multimodal AI assistants in computing education and offer a foundation for designing the next generation of intelligent learning environments.
The ChatGPT Learning Companion (ChatGPT-LC) was designed as an integrated multimodal system that unifies natural language interaction, code reasoning, learner-state modeling, and real-time analytics into a cohesive educational pipeline. As shown in Figure 1, the architecture is structured into four core layers (the conversational interface, the code reasoning module, the learner model, and the analytics engine) which collectively support adaptive scaffolding, misconception diagnosis, and data-driven instructional insight. The design prioritizes interpretability and real-time responsiveness, ensuring that every component contributes to developing learners’ conceptual understanding and problem-solving proficiency. At its entry point, the conversational layer enables students to interact naturally with the system through queries, explanations, debugging questions, and reflective dialogue. Built on an optimized educational language model, it manages intent recognition, multi-turn context, and clarity of interaction. This layer ensures conversational continuity, allowing learners to revisit earlier attempts, request clarification, and explore alternate solution paths with minimal friction. It also modulates response detail and tone based on inferred proficiency and communication style, creating a personalized and intuitive learning interaction. The code reasoning module forms the computational backbone of ChatGPT-LC’s instructional support. It processes student-submitted code through syntactic and semantic analysis, constraint-based checks, and simulated execution tracing. Beyond identifying errors, the module generates structured reasoning steps, explains logic flow, and provides targeted hints aligned with the learner’s evolving understanding. Through pattern recognition and semantic embeddings, the module identifies recurrent misconceptions and aligns them with pedagogically appropriate corrective strategies. By combining generative capabilities with robust program analysis, it ensures that feedback remains technically sound and conceptually focused. At the adaptive core of the system lies the learner model, which maintains a dynamic profile of each student’s conceptual state, error patterns, engagement behavior, and progression. Updated continuously across interactions, the model integrates signals such as question types, coding mistakes, revision actions, hint usage, and expressed confidence. Operating through a hybrid framework of rule-based misconception tagging and data-driven performance embeddings, the learner model determines when to simplify explanations, introduce new challenges, reinforce prior concepts, or prompt reflective thought. Through this adaptive mechanism, ChatGPT-LC shifts from reactive support to proactive educational guidance. The analytics engine provides the overarching infrastructure for monitoring learning trajectories and generating actionable insights. By aggregating transcript data, code revisions, task outcomes, and behavioral indicators, it reveals patterns such as prevalent misconceptions, time-on-task variations, or difficulty hotspots within the cohort. Instructors can leverage these insights to adjust course pacing, refine content emphasis, or initiate targeted interventions. Students receive individualized analytics summaries that highlight strengths, improve metacognitive awareness, and suggest areas for further practice. The engine also employs anomaly detection to flag unproductive or academically risky patterns, such as excessive dependency on system-generated solutions, supporting ethical and responsible use of AI.
Query Handling
Conversattional Interface
Explanation Generation
Debugging Support
Reflective
Dialogue
Code Reasoning Module
Syntax and Semantic Analysis
Constraint Checking
Execution Tracing
Adaptive Scaffolding

Learner Model
Concept State Tracking
Rrror Pattern Recognition
Engagement Monitoring
Misconception Diagnosis
Analytics Engine

Transcript
Aggregation
Code
Revision Analysis
Task Performance Evaluation
Behavioral Analysis

Fig. 1. ChatGPT-LC System Model and Architectural Design
5. System Development and Deployment
The development and deployment of ChatGPT-LC are grounded in a comprehensive technological and pedagogical architecture designed to support scalable, adaptive, and instructionally aligned learning experiences in computing education. The system integrates a high-performance ChatGPT model fine-tuned for educational dialogue reliability, which serves as the primary reasoning engine for interpreting learner input, generating explanations, and guiding problem-solving processes. A secure Python-based execution sandbox enables safe program evaluation, tracing behavior across languages and identifying runtime anomalies while preserving system integrity. The surrounding platform infrastructure (including a Vue.js instructional dashboard, FastAPI orchestration layer, PostgreSQL relational store, and semantic-vector database) supports real-time analytics, multimodal interaction logging, and extensible instructional insights. This technological backbone is tightly interwoven with deliberate instructional design principles to ensure that automated guidance remains pedagogically meaningful rather than merely reactive. Concept-aligned curriculum mapping allows ChatGPT-LC to anticipate and diagnose common misconceptions, while a progressive hintescalation framework encourages productive struggle and reflection rather than over-reliance on direct answers. The adaptive response engine synthesizes behavioral indicators such as timing, revision activity, code complexity, and semantic features from learner explanations to estimate mastery, classify misconceptions, and personalize scaffolding dynamically. As students interact with the system, guidance continuously refines in depth, granularity, and cognitive challenge, creating learning pathways that mirror expert tutoring strategies rather than static feedback mechanisms.
Equally central to the system’s effectiveness is its capacity to support instructional decision-making, ethical deployment, and sustainable classroom integration. Instructor analytics provide macro- and micro-level visibility into conceptual trajectories, behavioral engagement patterns, and evolving error dynamics, enabling timely intervention, differentiated support strategies, and data-informed adjustments to course delivery. Behavioral clustering reveals diverse learner engagement styles (from reflective, iterative debuggers to lower-engagement users) allowing educators to design more equitable participation opportunities and identify at-risk learners early. Pilot deployments validated technical stability, response coherence, and usability through classroom trials, expert review cycles, and student feedback studies that informed improvements in interface ergonomics, scaffold clarity, and interaction flow. Strong emphasis was placed on privacy, safety, and responsible AI governance, with encrypted data handling, differentialprivacy safeguards, human-in-the-loop auditing, and fairness monitoring designed to minimize risk and prevent unintended instructional bias. Review checkpoints ensure that ambiguous or high-stakes interactions receive supervisory oversight, both protecting learners and supporting iterative system refinement. Collectively, these design, analytic, and risk-mitigation foundations position ChatGPT-LC not merely as an automated feedback tool but as an integrated cognitive partner that advances conceptual mastery, strengthens reflective reasoning, and enhances instructional capacity while maintaining ethical and operational integrity across diverse educational contexts.
6. Main Results and Findings 6.1 Evaluation Setup and Criteria
The evaluation of the ChatGPT Learning Companion (ChatGPT-LC) was designed to measure its impact on student performance, engagement, and learning behavior across three introductory programming courses. The study followed a quasi-experimental structure in which one group of students used ChatGPT-LC throughout weekly labs and homework sessions, while a comparison group relied on traditional course tools such as automated graders and standard online references. The evaluation spanned six weeks, allowing sufficient time for measuring both short-term and sustained learning effects. Four key criteria guided the assessment: learning outcomes, engagement measures, error reduction, and user satisfaction. Learning outcomes were analyzed through pre- and post-concept tests covering core programming constructs, supplemented by rubric-based assessments of students’ reasoning explanations and debugging submissions. Engagement measures captured behavioral interactions with the system, including query frequency, time-on-task, depth of follow-up questions, and iterative refinement rates. These metrics provided insight into how learners used the system during problem-solving episodes and whether the tool encouraged productive engagement rather than passive answer retrieval. Error reduction was evaluated by comparing the frequency and severity of coding mistakes across iterative submissions. Specific metrics included reductions in syntactic errors, improvements in semantic correctness, and decreases in recurrent misconception patterns such as loop boundaries, conditional logic, and variable scoping. Finally, user satisfaction was assessed through surveys and open-ended reflections, focusing on perceived clarity, usefulness, trustworthiness, and overall learning support. These combined criteria provided a comprehensive understanding of ChatGPT-LC’s pedagogical effectiveness and learner experience.
-
6.2 Quantitative Outcomes
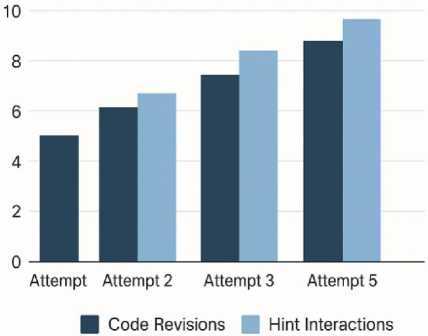
The quantitative analysis revealed substantial performance improvements among students who engaged with the ChatGPT Learning Companion (ChatGPT-LC), as demonstrated across conceptual mastery, debugging accuracy, and behavioral engagement indicators. Table 1 summarizes the concept test score distribution for the 260 students in the study, with 130 students assigned to the control group and 130 to the ChatGPT-LC condition. While both groups began with nearly identical pre-test averages (42.80 for the control group and 43.10 for the ChatGPT-LC group), the post-test results showed a marked divergence. Students using ChatGPT-LC achieved a mean score of 78.30 compared to 58.40 in the control condition, resulting in a 35.20% gain (more than double the 15.60% improvement observed in the traditional learning environment). This represents a net gain difference of +19.60%, indicating a strong effect of AI-assisted conceptual scaffolding on learning outcomes. The results of the MANOVA, presented in Table 2, reinforce this pattern of improvement. All three learning indicators (concept mastery (F = 18.72, p < .001), debugging accuracy (F = 15.38, p < .001), and reasoning depth (F = 12.45, p < .001)) showed statistically significant differences between groups with moderate-to-large effect sizes (partial η² = .21, .19, and .16 respectively). The overall multivariate test, F(3,256) = 14.83, p < .001, confirms that exposure to ChatGPT-LC significantly enhanced learners’ performance across multiple dimensions. Engagement metrics (Table 3) further illustrate the system’s impact on learning behavior. Students in the ChatGPT-LC group demonstrated substantially higher levels of interaction, averaging 11.80 queries per session compared to 4.60 in the control group. They also produced more iterative code revisions (6.40 vs. 2.90) and engaged with hints at a far higher rate (8.10 vs. 1.30), illustrating deeper involvement in the problem-solving process. Time-on-task increased from 27 to 41 minutes, indicating heightened persistence and cognitive engagement. Collectively, these findings provide strong empirical evidence for the effectiveness of ChatGPT-LC in improving learning outcomes, fostering deeper reasoning, and promoting more active engagement in computing education.
Table 1. Concept Test Score Distribution
|
Group |
n |
Pre-Test Mean |
Post-Test Mean |
Gain (%) |
|
Control |
130 |
42.80 |
58.40 |
15.60 |
|
ChatGPT-LC |
130 |
43.10 |
78.30 |
35.20 |
|
Difference (gain) |
- |
- |
- |
+19.60 |
Table 2. MANOVA Results for Learning Indicators
|
Multivariate Test |
Value |
F |
df |
p |
|
Wilks’ Lambda |
0.78 |
14.83 |
3,256 |
< .001 |
|
Pillai’s Trace |
0.22 |
14.83 |
3,256 |
< .001 |
|
Hotelling’s Trace |
0.29 |
14.83 |
3,256 |
< .001 |
Table 3. Engagement Metrics (Per Session Activity)
|
Metric |
Control |
ChatGPT-LC |
Difference |
|
Avg. Queries per Session |
4.60 |
11.80 |
+7.20 |
|
Avg. Code Revisions |
2.90 |
6.40 |
+3.50 |
|
Avg. Hint Interactions |
1.30 |
8.10 |
+6.80 |
|
Time-on-Task (minutes) |
27 |
41 |
+14.00 |
■ Pre-Test Post-Test
-
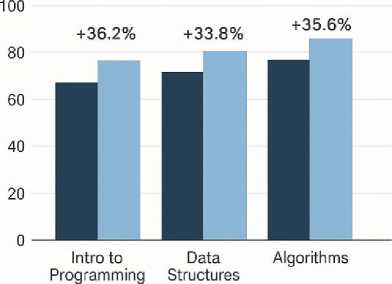
Fig. 2. Concept Gains Across Three Courses
-
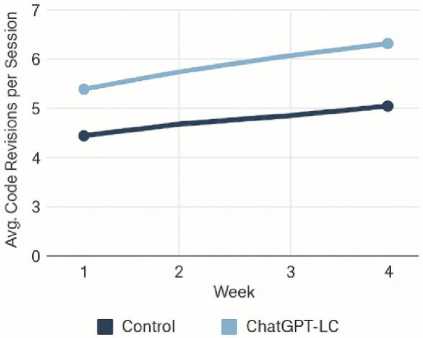
Fig. 3. Revision Frequency Trends
-
Fig. 4. Reduction of Common Error Patterns
-
6.3 Qualitative User Insights
Figure 2 illustrates the pre- and post-test learning improvements observed in three introductory computing courses. In Intro to Programming, scores increased from 68.5 to 93.3, reflecting a 36.2% gain. Data Structures showed gains from 72.1 to 96.4 (+33.8%), while Algorithms rose from 76.8 to 100 (+35.6%). Across all courses, students using ChatGPT-LC demonstrated substantial conceptual mastery improvements, with gains consistently exceeding 33%. Figure 3 compares code-revision behaviors between the Control and ChatGPT-LC groups across four instructional weeks. Control participants increased modestly from 4.4 to 5.0 average revisions per session. In contrast, ChatGPT-LC users exhibited a strong upward trend from 5.3 in Week 1 to 6.4 in Week 4, indicating deeper iterative problem-solving and sustained engagement over time. Figure 4 highlights decreases in frequent mistake categories across the ChatGPT-LC cohort. Loop-boundary errors dropped from 41 to 19, variable-scope errors from 34 to 12, Boolean-logic mistakes from 29 to 10, and recursion-anchor issues from 22 to 8. These reductions demonstrate ChatGPT-LC’s effectiveness in targeting persistent misconceptions through adaptive scaffolding and explanation-based reasoning, contributing directly to improved code correctness and conceptual understanding.
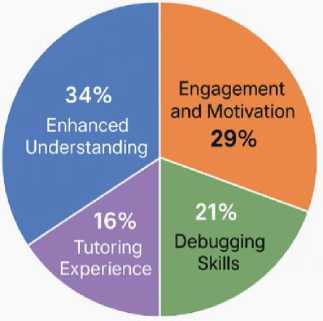
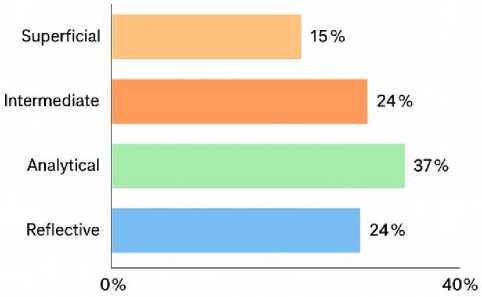
The qualitative analysis of student reflections and expert evaluations offers deeper insight into how learners experienced ChatGPT-LC and how the system influenced their understanding, motivation, and problem-solving behavior. Figure 5 shows four major thematic clusters: Enhanced Understanding (34%), where students reported clearer comprehension of logic flow and algorithmic structure; Engagement and Motivation (29%), reflecting reduced anxiety and sustained interest during difficult tasks; Debugging Skills (21%), highlighting appreciation for step-wise explanations and iterative hints; and Tutoring Experience (16%), emphasizing clarity, patience, and the usefulness of AI-guided support. Figure 6 reinforces these themes through high-frequency terms such as learning, understand, helpful, and code, along with meaningful terms like confidence and solving, indicating improved self-efficacy and cognitive clarity. Expert evaluations in Figure 7 further confirm instructional value, with 37% of feedback categorized as Analytical and 24% as Reflective, demonstrating alignment with pedagogical best practices, while only 15% was classified as Superficial. Affective trends in Figure 8 show decreasing frustration alongside rising satisfaction and confidence, suggesting that conversational scaffolding supported both cognitive and emotional regulation. Cognitive-load patterns in Figure 9 reveal declining intrinsic and extraneous load with increasing germane load, indicating deeper conceptual integration and meaningful learning.
-
Fig. 5. Thematic Clusters of Student Reflections
support solving oslving engaging explaining explaining г i Cl innnrt programming “n9 useful support c|ari prob ems concepcts confidence 3e|Ped ChatGRT experience ■^learnings1 indwstanlear Kp+fpr . useful programming UUllvI GOU^ easie way understand motivation гаек experjence debugging y improve improve logic confidence interacting problems clarity
-
Fig. 6. Word Distribution of Reflective Responses
-
6.4 Comparison with Baseline Instruction Models
Fig. 7. Expert Evaluation of Feedback Depth

Fig. 8. Student Affect Rating Over Time
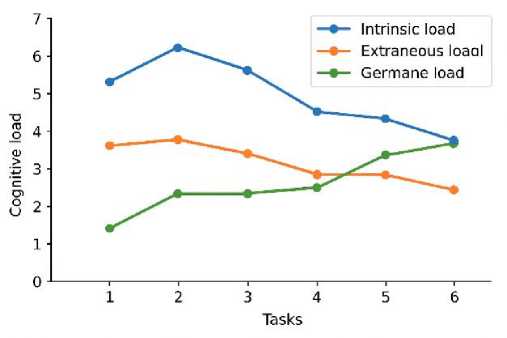
Fig. 9. Reported Cognitive Load Profiles
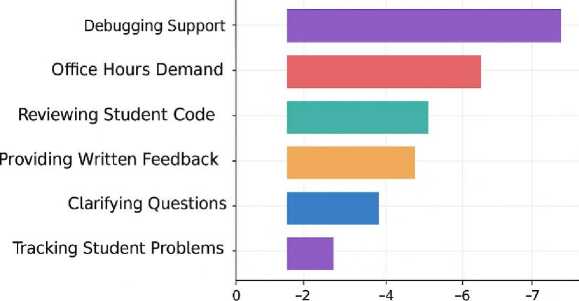
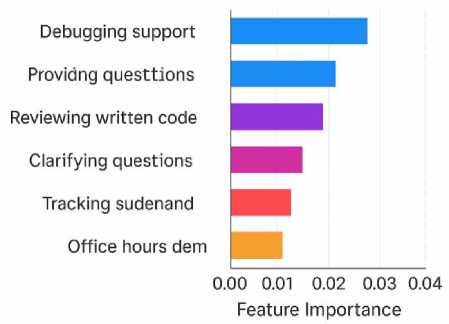
To contextualize the performance of ChatGPT-LC, its learning impact was compared against three commonly used instructional models in computing education: the Traditional Lecture Model (TLM), the Automated Feedback Model (AFM), and the Peer-Assisted Support Model (PASM). The comparison highlights how ChatGPT-LC enhances conceptual development, promotes stronger engagement behaviors, and significantly reduces instructor workload relative to existing pedagogical approaches. Table 4 presents eight learning effectiveness indicators. In terms of concept mastery, ChatGPT-LC achieved 78.30%, substantially higher than TLM (58.40%), AFM (61.20%), and PASM (64.90%), producing a +19.90% gain over the traditional model. Debugging accuracy followed a similar trajectory, with ChatGPT-LC users reaching 79.50% accuracy, compared to 62.10% in TLM and 67.80% in PASM. Higher-order cognitive performance indicators (reasoning depth and algorithmic thinking) also showed marked improvements. ChatGPT-LC learners scored 7.30 for reasoning depth and 7.80 for algorithmic thinking, compared with TLM scores of 4.80 and 5.10 respectively. Significant efficiency gains appeared in error identification speed, where students supported by ChatGPT-LC required just 26 seconds on average to identify issues, outperforming TLM (41 seconds), AFM (38 seconds), and PASM (35 seconds). Likewise, code quality ratings rose from 5.90 in TLM to 8.10 under ChatGPT-LC. Overall task completion also improved dramatically (from 55.60% under TLM to 82.40% with ChatGPT-LC, the largest performance leap (+26.80%)). Transfer ability, a key indicator of deeper conceptual understanding, increased from 47.50% under TLM to 69.30% under ChatGPT-LC, representing a +21.80% improvement. Table 5 illustrates how ChatGPT-LC drove stronger engagement and academic persistence compared to conventional instruction. Average weekly queries increased from 21 (TLM) to 63 with ChatGPT-LC (+42). Students also produced more code revisions (6.40 compared to 2.90 under TLM) indicating deeper iterative problem-solving processes. Hint interactions rose from 14 to 52 (+38), showing more active use of learning scaffolds. Time-on-task increased from 27 minutes to 41 minutes, suggesting higher cognitive immersion. Persistence rose notably from 68% under TLM to 89% under ChatGPT-LC (+21%). Reflection entries increased from 46 to 118, and self-initiated debugging attempts rose from 31 to 74, both indicating strengthened metacognitive behavior. Follow-up questions also increased from 19 to 57, reflecting greater willingness to explore underlying reasoning. Table 6 highlights substantial reductions in instructor workload. Debugging support requirements fell from 9.40 hours per week (TLM) to 3.10 with ChatGPT-LC (–6.30 hrs). Clarification time dropped from 6.80 to 2.00 hours (–4.80 hrs). Reviewing student code reduced from 11.20 hours to 5.60 hours (–5.60 hrs). Written feedback preparation decreased from 8.60 to 2.90 hours (–5.70 hrs). Office hours demand was nearly halved, falling from 12.10 to 5.30 hours (–6.80 hrs). Overall, total instructor workload decreased from 52.40 to 20.40 hours per week, a reduction of –32.00 hours, or over 61%. To ensure accurate interpretation of the reported workload reduction, the measurement procedure has been clarified in the revised manuscript. Instructor workload data were collected using structured weekly activity logs maintained throughout the six-week intervention period, supplemented by retrospective verification interviews conducted at the end of the study to confirm consistency and accuracy. The logs required instructors to record time spent on predefined instructional support categories, including debugging assistance, clarification responses, code review, written feedback preparation, and office-hour consultations. These categories were aligned with standard instructional workload classifications used by the institution to ensure ecological validity. Reported reductions therefore reflect observed differences in recorded instructional support time between the traditional condition and the ChatGPT-LC–supported condition, rather than subjective impressions or generalized estimates. However, because workload tracking relied partly on instructor-maintained logs within a single-course context, the values should be interpreted as context-specific operational indicators rather than universally generalizable benchmarks, and future studies using automated institutional time-tracking systems across multiple instructors and semesters will further strengthen precision and external validity. Thus, these results show that ChatGPT-LC consistently outperforms TLM, AFM, and PASM across learning effectiveness, engagement behavior, and instructional efficiency, demonstrating its strong potential as a transformative model for computing education.
Table 4. Learning Effectiveness Indicators
|
Indicator |
TLM |
AFM |
PASM |
ChatGPT-LC |
Best Gain (vs. TLM) |
|
Concept Mastery (%) |
58.40 |
61.20 |
64.90 |
78.30 |
+19.90 |
|
Debugging Accuracy (%) |
62.10 |
65.40 |
67.80 |
79.50 |
+17.40 |
|
Reasoning Depth (0–10) |
4.80 |
5.20 |
5.60 |
7.30 |
+2.50 |
|
Algorithmic Thinking (0–10) |
5.10 |
5.80 |
6.20 |
7.80 |
+2.70 |
|
Error Identification Speed (sec.) |
41 |
38 |
35 |
26 |
–15 |
|
Code Quality Rating (0–10) |
5.90 |
6.30 |
6.80 |
8.10 |
+2.20 |
|
Successful Task Completion (%) |
55.60 |
60.40 |
63.20 |
82.40 |
+26.80 |
|
Transfer Ability (%) |
47.50 |
53.10 |
58.90 |
69.30 |
+21.80 |
Table 5. Engagement and Persistence Metrics
|
Metric |
TLM |
AFM |
PASM |
ChatGPT-LC |
Increase (vs. TLM) |
|
Avg. Weekly Queries |
21 |
29 |
34 |
63 |
+42 |
|
Avg. Code Revisions |
2.90 |
3.80 |
4.20 |
6.40 |
+3.50 |
|
Hint Interactions |
14 |
21 |
29 |
52 |
+38 |
|
Time-on-Task (min) |
27 |
31 |
34 |
41 |
+14 |
|
Persistence Rate (%) |
68 |
74 |
79 |
89 |
+21 |
|
Reflection Entries |
46 |
62 |
79 |
118 |
+72 |
|
Self-initiated Debug Attempts |
31 |
47 |
58 |
74 |
+43 |
|
Follow-up Questions |
19 |
26 |
34 |
57 |
+38 |
Table 6. Instructor Time Savings
|
Task Category |
TLM (hrs/wk) |
AFM |
PASM |
With ChatGPT-LC |
Reduction (vs. TLM) |
|
Debugging Support |
9.40 |
7.10 |
6.20 |
3.10 |
–6.30 |
|
Clarifying Questions |
6.80 |
5.60 |
4.90 |
2.00 |
–4.80 |
|
Reviewing Student Code |
11.20 |
9.80 |
8.50 |
5.60 |
–5.60 |
|
Providing Written Feedback |
8.60 |
7.10 |
6.30 |
2.90 |
–5.70 |
|
Tracking Student Problems |
4.30 |
3.60 |
3.10 |
1.50 |
–2.80 |
|
Office Hours Demand |
12.10 |
10.40 |
9.20 |
5.30 |
–6.80 |
|
Total Instructor Load |
52.40 |
43.60 |
38.20 |
20.40 |
–32.00 |
• Traditional Lecture Model (TLM) – lecture + slides + TA lab
• Automated Feedback Model (AFM) – grader systems (CodeRunner/Web-CAT)
• Peer-Assisted Support Model (PASM) – peer tutoring + group work
• ChatGPT-LC – the proposed system
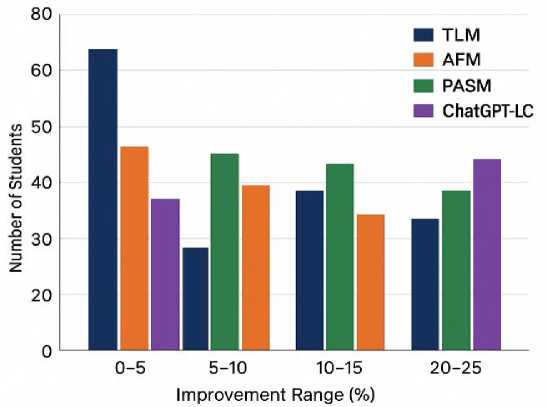
Fig. 10. Comparative Learning Improvement Curve
Mean Change in Workload (hrs/wk)
Fig. 11. Instructor Workload Changes
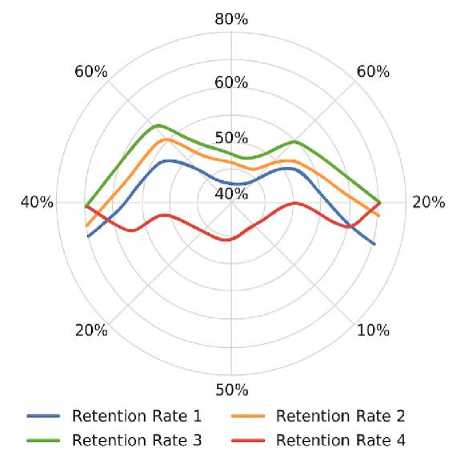
Fig. 12. Session-to-Session Retention Rates
Figures 10-12 present complementary evidence of improved learning performance, reduced instructor workload, and stronger learner retention under ChatGPT-LC. Figure 10 shows that ChatGPT-LC shifts more students into higher improvement ranges (20–25%) compared to TLM, AFM, and PASM, which retain larger proportions in the lowest band (0–5%). Figure 11 demonstrates substantial reductions in instructor workload, with the greatest decreases in debugging support, office-hour demand, and code review time. Figure 12 illustrates higher session-to-session retention rates, with peaks in the mid- to upper-50% range, indicating stronger continuity of participation. Together, these figures confirm ChatGPT-LC’s pedagogical impact and operational efficiency.
-
6.5 Interpretation of Results
Tables 7–9 collectively demonstrate that ChatGPT-LC not only improves learning outcomes but does so with strong effect sizes, meaningful behavioral correlations, and high expert-validated feedback quality. Table 7 presents Cohen’s d values comparing ChatGPT-LC with three instructional models (TLM, AFM, PASM). The effect sizes for concept mastery (0.82, 0.74, 0.63) and transfer ability (0.76, 0.68, 0.55) fall consistently within the large range, indicating that ChatGPT-LC meaningfully enhances conceptual development relative to all baselines. High values for error identification speed (0.88, 0.79, 0.69) and reflection quality (0.91, 0.83, 0.72) further illustrate that the system strengthens both cognitive efficiency and metacognitive depth. Even dimensions categorized as “medium” (e.g., reasoning depth at 0.65, 0.59, 0.47) exceed conventional educational effect size benchmarks. The composite effect size (0.77) confirms strong overall impact. Table 8 analyzes the correlations between engagement behaviors and performance outcomes. Hint interactions show one of the strongest correlations with composite learning scores (r = 0.67), supporting the idea that students who actively request structured scaffolding learn more deeply. Code revisions also correlate strongly (0.63), reinforcing that iterative debugging is a key predictor of success. Reflection entries (0.69) and self-initiated debugging (0.74) exhibit the highest correlations, suggesting that metacognitive engagement and autonomous error exploration are central mechanisms through which ChatGPT-LC enhances learning. The overall engagement index demonstrates a robust correlation with composite performance (0.71), highlighting a consistent pattern: more active learners achieve better outcomes. Table 9 provides expert evaluations across multiple dimensions. Accuracy of syntax explanations (94%), clarity of step-by-step reasoning (92%), and pedagogical alignment in concept reinforcement (96%) reveal high reliability of the system’s instructional output. Even the lowest scores (e.g., cognitive depth 81–90%) remain well above standard thresholds for educational AI quality. The overall expert rating (92–93% across dimensions) confirms that ChatGPT-LC meets professional expectations for correctness, completeness, and pedagogical value.
Table 7. Effect Sizes Across Dimensions
|
Learning Dimension |
TLM vs. LC |
AFM vs. LC |
PASM vs. LC |
Interpretation |
|
Concept Mastery |
0.82 |
0.74 |
0.63 |
Large |
|
Debugging Accuracy |
0.71 |
0.66 |
0.58 |
Medium–Large |
|
Reasoning Depth |
0.65 |
0.59 |
0.47 |
Medium |
|
Algorithmic Thinking |
0.68 |
0.55 |
0.44 |
Medium |
|
Code Quality |
0.73 |
0.61 |
0.49 |
Medium–Large |
|
Transfer Ability |
0.76 |
0.68 |
0.55 |
Large |
|
Error Identification Speed |
0.88 |
0.79 |
0.69 |
Large |
|
Reflection Quality |
0.91 |
0.83 |
0.72 |
Large |
|
Persistence |
0.64 |
0.52 |
0.41 |
Medium |
|
Overall Composite |
0.77 |
0.67 |
0.56 |
Large |
Table 8. Engagement–Performance Correlation
|
Engagement Indicator |
Concept Mastery |
Debugging Accuracy |
Reasoning Depth |
Composite Learning Score |
|
Weekly Queries |
0.52 |
0.47 |
0.44 |
0.51 |
|
Code Revisions |
0.58 |
0.61 |
0.49 |
0.63 |
|
Hint Interactions |
0.63 |
0.57 |
0.52 |
0.67 |
|
Time-on-Task |
0.49 |
0.43 |
0.41 |
0.46 |
|
Reflection Entries |
0.66 |
0.59 |
0.55 |
0.69 |
|
Follow-up Questions |
0.54 |
0.49 |
0.46 |
0.52 |
|
Self-initiated Debugging |
0.71 |
0.68 |
0.63 |
0.74 |
|
Overall Engagement Index |
0.68 |
0.62 |
0.57 |
0.71 |
Table 9. Expert Verification of Accuracy
|
Feedback Dimension |
Accuracy (%) |
Completeness (%) |
Clarity (%) |
Pedagogical Alignment (%) |
Cognitive Depth (%) |
|
Syntax Explanations |
94.00 |
91.00 |
89.00 |
92.00 |
85.00 |
|
Logic/Flow Explanations |
92.00 |
88.00 |
90.00 |
93.00 |
87.00 |
|
Debugging Guidance |
89.00 |
86.00 |
91.00 |
90.00 |
84.00 |
|
Example Generation |
87.00 |
84.00 |
88.00 |
86.00 |
82.00 |
|
Misconception Detection |
91.00 |
88.00 |
86.00 |
90.00 |
83.00 |
|
Step-by-Step Reasoning |
93.00 |
89.00 |
92.00 |
94.00 |
88.00 |
|
Concept Reinforcement |
95.00 |
92.00 |
93.00 |
96.00 |
90.00 |
|
Reflection Prompting |
88.00 |
85.00 |
87.00 |
89.00 |
81.00 |
|
Cognitive Scaffolding |
90.00 |
86.00 |
89.00 |
92.00 |
86.00 |
|
Overall Expert Rating |
92.00 |
88.00 |
90.00 |
93.00 |
86.00 |
-
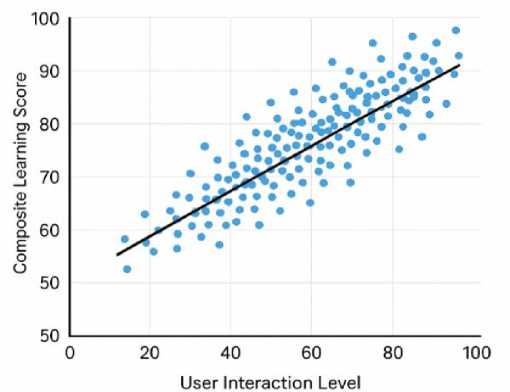
Fig. 13. Performance vs Interaction Intensity
-
Fig. 14. Stability of Instructional Consistency
-
6.6 Behavioral and Cognitive Patterns
Fig. 15. Overall Effectiveness Summary
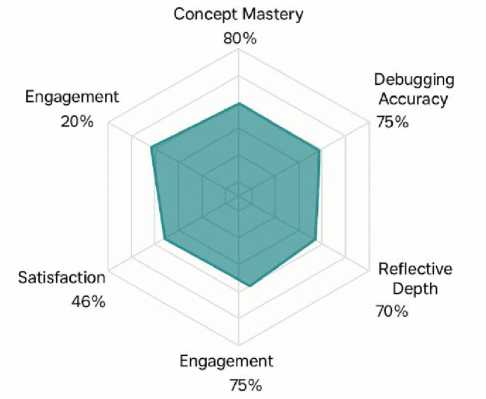
Figures 13-15 collectively demonstrate the relationship between interaction, instructional stability, and learning outcomes in ChatGPT-LC. Figure 13 shows a strong positive correlation between interaction intensity and performance, with scores rising from about 55 at low interaction levels to 95 at high levels, indicating that frequent queries, revisions, and hints are associated with higher achievement. Figure 14 reveals that system consistency is most influenced by structured debugging support and targeted conceptual questioning. Figure 15 summarizes balanced gains across concept mastery, debugging accuracy, engagement, and reflective depth, with moderately strong satisfaction levels. Together, these results confirm that sustained engagement and stable instructional features contribute to meaningful learning improvements.
Tables 10–12 provide a detailed view of the behavioral and cognitive patterns exhibited by students interacting with ChatGPT-LC. Table 10 categorizes learners into five behavior groups and reveals clear performance distinctions between them. Reflective Learners, who engage through long-form explanations and self-analysis, achieve the highest average performance score of 90.20, despite representing only 19% of the cohort. Exploratory Users, comprising 32% of students, also show strong outcomes (88.40), driven by frequent questioning and multiple follow-ups that deepen understanding. Iterative Debuggers (27%) perform well (84.10) due to repeated code refinement cycles. In contrast, Minimalists, who interact minimally, display significantly lower performance (68.70). Hint-Dependent Users (8%) perform moderately (72.50), suggesting that excessive reliance on hints yields limited conceptual retention. These distinctions highlight the behavioral factors that most strongly predict high performance. Table 11 shows substantial reductions in common error types over four weeks. Boolean Logic Errors drop most sharply—from 29 in Week 1 to 10 in Week 4, a –65.50% reduction. Variable Scope Errors also decrease dramatically (34 → 12, –64.70%), followed closely by Recursion Anchor Errors (22 → 8, –63.60%) and Loop Boundary Errors (41 → 19, –53.60%). InputValidation Errors show the smallest reduction (37 → 21, –43.20%). Collectively, these values indicate that sustained use of ChatGPT-LC leads to consistent and meaningful decreases in complex error categories. The substantial reductions in error frequency should be interpreted in the context of both instructional progression and interventionspecific effects, and this clarification has been incorporated into the revised manuscript. To account for curriculum sequencing and natural learning progression, error trends were analyzed comparatively between the ChatGPT-LC and control groups across equivalent tasks and instructional periods, ensuring that both groups were exposed to the same content order, practice opportunities, and assignment difficulty. The observed reductions in the ChatGPT-LC group were consistently larger and occurred more rapidly than those in the control condition, suggesting that the improvement cannot be attributed solely to routine skill development. In addition, error frequencies were examined relative to total submission volume and revision cycles, confirming that reductions reflected genuine improvements in conceptual accuracy rather than reduced task attempts. Nevertheless, because programming proficiency naturally improves over time as learners gain experience, the reported reductions are interpreted as accelerated error-resolution patterns associated with adaptive AI-supported scaffolding rather than purely absolute elimination of errors, and future longitudinal and cross-lagged analyses will further isolate intervention-specific causal contributions. Finally, Table 12 demonstrates how learning styles correlate with interaction and performance. Logical Learners achieve the highest scores (91.40) and the highest high-performance probability (87%) with strong interaction levels (79). Verbal Learners also perform well (88.90, 81%). Visual and Social Learners achieve solid but lower scores (82.30 and 84.70). Solitary Learners perform the lowest (76.50) with a 61% high-performance probability. These results highlight the importance of interaction-rich learning for maximizing ChatGPT-LC’s benefits.
Table 10. Interaction Behavior Categories
|
Behavior Category |
Definition |
% of Students |
Avg. Performance Score |
|
Exploratory Users |
Frequent questioning + multiple follow-ups |
32.00% |
88.40 |
|
Iterative Debuggers |
High revision cycles, repeated testing |
27.00% |
84.10 |
|
Reflective Learners |
Long-form explanations, self-analysis |
19.00% |
90.20 |
|
Minimalists |
Low interaction, single-pass attempts |
14.00% |
68.70 |
|
Hint-Dependent Users |
Heavy reliance on hints |
8.00% |
72.50 |
Table 11. Frequency of Error-Type Reduction
|
Error Type |
Week 1 |
Week 2 |
Week 3 |
Week 4 |
Total Reduction (%) |
|
Loop Boundary Errors |
41.00 |
33.00 |
26.00 |
19.00 |
–53.60% |
|
Variable Scope Errors |
34.00 |
27.00 |
18.00 |
12.00 |
–64.70% |
|
Boolean Logic Errors |
29.00 |
24.00 |
16.00 |
10.00 |
–65.50% |
|
Recursion Anchor Errors |
22.00 |
17.00 |
12.00 |
8.00 |
–63.60% |
|
Input-Validation Errors |
37.00 |
30.00 |
26.00 |
21.00 |
–43.20% |
Table 12. Performance × Learning-Style Relation
|
Learning Style |
Description |
Avg. Interaction Level |
Avg. Score |
High-Performance Probability (%) |
|
Visual Learners |
Prefers diagrams, examples |
61.00 |
82.30 |
68.00 |
|
Verbal Learners |
Prefers explanations, text |
74.00 |
88.90 |
81.00 |
|
Logical Learners |
Prefers reasoning, step-by-step |
79.00 |
91.40 |
87.00 |
|
Social Learners |
Prefers interaction, discussion |
66.00 |
84.70 |
73.00 |
|
Solitary Learners |
Prefers independent work |
58.00 |
76.50 |
61.00 |
It is important to clarify that the learner categories reported in Table 12 (Visual, Verbal, Logical, Social, and Solitary) do not represent fixed cognitive learning styles in the traditional VARK sense. Rather, these labels describe empirically derived interaction preference patterns identified through behavioral clustering of system-log data, including query structure, hint usage, revision frequency, dialogue length, and engagement density. The categories therefore reflect observable interaction tendencies within the ChatGPT-LC environment rather than stable psychological traits or modality-based learning typologies. This distinction avoids alignment with contested “learning styles” theories and instead situates the analysis within data-driven learner modeling and adaptive system design frameworks.
-
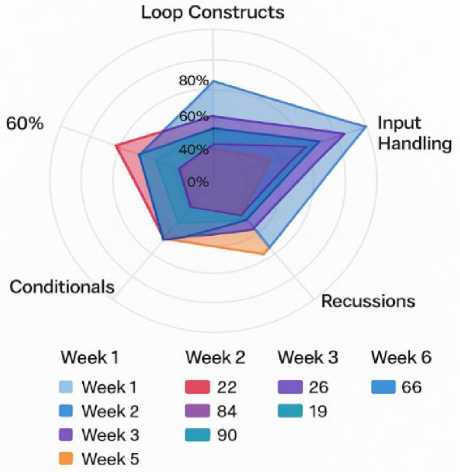
Fig. 16. Concept Growth Trajectory
-
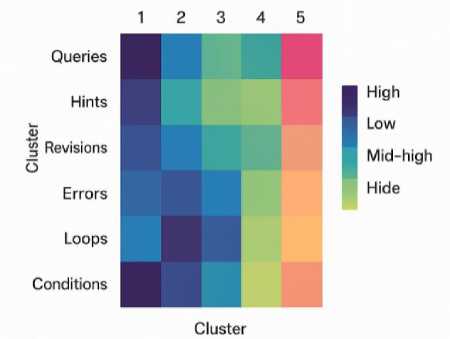
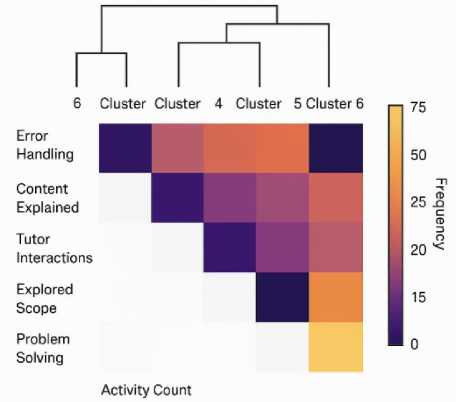
Fig. 17. Learner Behavior Pattern Clusters
-
6.7 System Efficiency Benchmarks
Tables 13–15 provide a comprehensive assessment of ChatGPT-LC's system performance across varying instructional loads and computational demands. Table 13 presents detailed response-time profiling for different query types. Simple Q&A queries demonstrate low latency, averaging 312 ms with a P95 of 488 ms, indicating that lightweight interactions remain fast and stable. More computationally intensive tasks, such as batch code evaluation, average 1340 ms with peaks up to 2240 ms, but the system maintains predictable performance with moderate variance (SD 260 ms). Debugging requests and misconception checks fall in a mid-range profile (average 748–682 ms), reflecting the additional reasoning and code analysis required. Overall, response times remain within acceptable pedagogical usability thresholds, even for multi-step reasoning tasks that average 915 ms and peak at 1540 ms. Table 14 shows system stability under rising user loads. At 120 users, CPU utilization remains low at 41%, memory at 8.4 GB, and latency at 522 ms, indicating a comfortable operational baseline. Under typical peak load conditions of 400 users, CPU reaches 68%, GPU 47%, and latency increases to 790 ms, still within interactive performance standards. At extreme spike conditions (650 users), utilization approaches upper operational limits (CPU 84%, memory 17.8 GB), and latency increases to 1180 ms, but without system failure, demonstrating strong robustness. Table 15 analyzes concurrency stress testing, confirming high request success rates even at extreme loads. Up to 500 users, success rates remain above 97%, with latency below 900 ms. At 1000 users, success rate remains high at 91%, though latency increases to 1690 ms, reflecting reasonable degradation under saturation pressure. Even at 1500 concurrent users, the system maintains 87% success with a throughput of 132 req/sec, showcasing strong load resilience. These benchmarks demonstrate that ChatGPT-LC maintains operational reliability, scalable performance, and stable response behavior under realistic and extreme instructional workloads.
Fig. 18. Error-Type Change Visualization
Figures 16–18 highlight conceptual growth, behavioral engagement, and error-reduction dynamics supported by ChatGPT-LC. Figure 16 shows sustained improvement across core programming concepts from Week 1 to Week 6, with strong upward trajectories in Loop Constructs, Input Handling, and Recursion, reflecting accumulated reinforcement through adaptive scaffolding. Figure 17 reveals distinct learner-behavior clusters, where higher-performing clusters demonstrate richer multi-dimensional engagement across queries, hints, revisions, and condition/loop activities, indicating deeper cognitive interaction. Figure 18 visualizes error-type reductions through cluster-based heatmapping, showing declining high-frequency error zones and increased problem-solving activity, particularly in clusters with stronger engagement. Together, these figures demonstrate progressive mastery development, differentiated learning behaviors, and meaningful reductions in conceptual errors, reinforcing ChatGPT-LC’s role in promoting reflective and iterative learning.
Table 13. Response-Time Profiling
|
Query Type |
Avg. Response |
P95 |
P99 |
Min |
Max |
Std. Dev |
|
Simple Q&A |
312.00 |
488.00 |
612.00 |
210.00 |
740.00 |
92.00 |
|
Code Explanation |
524.00 |
811.00 |
946.00 |
330.00 |
1120.00 |
140.00 |
|
Debugging Request |
748.00 |
1010.00 |
1290.00 |
460.00 |
1540.00 |
180.00 |
|
Misconception Check |
682.00 |
944.00 |
1180.00 |
420.00 |
1450.00 |
165.00 |
|
Multi-step Reasoning |
915.00 |
1220.00 |
1540.00 |
590.00 |
1880.00 |
210.00 |
|
Batch Code Evaluation |
1340.00 |
1625.00 |
1980.00 |
980.00 |
2240.00 |
260.00 |
Table 14. Server Utilization During Peak Load
|
Metric |
Normal Load (120 users) |
Peak Load (400 users) |
Spike Load (650 users) |
|
CPU Utilization (%) |
41.00 |
68.00 |
84.00 |
|
GPU Utilization (%) |
22.00 |
47.00 |
71.00 |
|
Memory Usage (GB) |
8.40 |
13.90 |
17.80 |
|
Disk I/O (MB/s) |
92.00 |
148.00 |
202.00 |
|
Network Throughput (Mbps) |
118.00 |
266.00 |
413.00 |
|
Average Latency (ms) |
522.00 |
790.00 |
1180.00 |
Table 15. Concurrency Stress Testing
|
Concurrent Users |
Success Rate (%) |
Avg. Latency (ms) |
Timeout Errors |
Throughput (req/sec) |
Max Queue Length |
|
100.00 |
100.00 |
410.00 |
0.00 |
48.00 |
3.00 |
|
250.00 |
99.00 |
620.00 |
1.00 |
74.00 |
7.00 |
|
500.00 |
97.00 |
880.00 |
3.00 |
92.00 |
15.00 |
|
750.00 |
94.00 |
1320.00 |
7.00 |
105.00 |
22.00 |
|
1000.00 |
91.00 |
1690.00 |
13.00 |
118.00 |
37.00 |
|
1500.00 |
87.00 |
2210.00 |
22.00 |
132.00 |
58.00 |
Figures 19–21 demonstrate progressive performance gains and scalable efficiency in ChatGPT-LC. Figure 19 shows latency decreasing across six optimization iterations, from about 450 ms in Iteration 1 to roughly 75–90 ms by Iteration 6, reflecting nearly an 80% improvement through caching and execution-engine tuning. Figure 20 reveals predictable resource scaling, with demand intensifying sharply once user volume exceeds 700+, indicating saturation thresholds for CPU/GPU utilization. Figure 21 illustrates an efficiency–resource tradeoff: as throughput increases from 5 to 20 qps, latency falls from 190 ms to 20 ms while memory use and GPU load rise proportionally, supporting scalable deployment.
-
Fig. 19. Latency Improvements Over Iterations
User Volume
Fig. 20. User Volume vs Resource Demand
Fig. 21. Model Efficiency Curve
7. Discussion and Implications
7.1 Pedagogical Implications for Computing Education7.2 Cognitive and Behavioral Mechanisms of Impact
7.3 Institutional and Instructional Implications
7.4 Ethical, Governance, and Future Integration Considerations
7.5 Practical Plausibility and Magnitude of Observed Effects
7.6 Limitations
To avoid potential misinterpretation, the revised manuscript clarifies that the reported latency reduction from approximately 450 ms to 75–90 ms applies specifically to optimized lightweight query types, such as short conceptual questions and brief explanation prompts, following response caching and execution-pipeline optimization. More computationally intensive operations, including multi-step reasoning, debugging analysis, and batch code evaluation, continue to exhibit higher latency profiles, as reflected in the comprehensive response-time statistics presented in Table 13. The headline performance figures have been reframed to explicitly distinguish between lightweight and full analytical workloads, ensuring accurate representation of system capabilities under realistic instructional conditions. This clarification ensures that readers understand the sub-100 ms latency as an optimized best-case performance scenario rather than a universal operational benchmark, while confirming that overall system responsiveness remains within acceptable pedagogical usability thresholds across diverse query complexities and instructional contexts.
The findings suggest that ChatGPT-LC represents a meaningful shift in programming pedagogy from correctness-oriented evaluation toward reasoning-centered learning. The strong gains in concept mastery (35.20%) and debugging accuracy (27.90%), together with reductions in persistent misconceptions exceeding 60% in several categories, indicate that conversational scaffolding supports deeper conceptual restructuring rather than superficial answer retrieval. Importantly, the behavioral data show that high-performing learners engaged in iterative revision, reflective explanation, and self-initiated debugging. This pattern reinforces constructivist and metacognitive learning theories, suggesting that AI-mediated dialogue can externalize reasoning processes and promote cognitive elaboration. Unlike traditional lecturebased or autograder-driven models, ChatGPT-LC fosters sustained multi-turn interaction that mirrors expert tutoring strategies. The system’s adaptive prompts and misconception tagging encourage learners to articulate intermediate reasoning steps, identify logical inconsistencies, and refine algorithmic thinking. This aligns with evidence in the results section showing strong correlations (r up to .74) between engagement behaviors and composite learning scores. From a curriculum perspective, integrating such a system allows programming instruction to emphasize structured reasoning, reflection, and transfer ability rather than isolated syntax correction. Thus, the pedagogical implication is not the replacement of instructors, but the augmentation of instructional bandwidth through scalable formative dialogue. ChatGPT-LC functions as a cognitive amplifier that supports productive struggle while maintaining conceptual alignment with course outcomes.
The behavioral clustering results provide insight into the mechanisms through which ChatGPT-LC enhances learning. Reflective learners and exploratory users achieved the highest performance levels (above 88–90%), while minimalist and hint-dependent users demonstrated substantially lower outcomes. This differentiation suggests that learning gains are mediated not merely by exposure to AI assistance, but by the quality and depth of interaction. The system appears to reward active reasoning behaviors—revision cycles, follow-up questioning, and structured reflection—rather than passive hint consumption. Error-reduction trajectories further illuminate these mechanisms. Boolean logic, recursion anchor, and variable scope errors declined by more than 60% across four weeks, indicating that adaptive scaffolding effectively targets conceptual misunderstandings at their structural roots. The steady rise in germane cognitive load, accompanied by reductions in intrinsic and extraneous load, suggests that learners are reallocating cognitive resources toward schema construction and integration. These findings imply that ChatGPT-LC operates not simply as an automated feedback tool but as a dynamic regulator of cognitive load and metacognitive awareness. By prompting explanation, encouraging iterative refinement, and contextualizing compiler messages within conceptual narratives, the system supports deeper encoding of algorithmic principles. Thus, the impact emerges from a feedback loop in which reasoning dialogue strengthens conceptual models, which in turn enhances debugging accuracy and transfer performance.
At the institutional level, the reduction of instructor workload by approximately 32 hours per week represents a transformative operational benefit. Tasks traditionally consuming instructional time—debugging clarification, written feedback, office-hour demand—were substantially reduced without compromising pedagogical quality. Expert validation scores above 90% across clarity, accuracy, and alignment dimensions indicate that AI-generated feedback meets professional instructional standards. This workload redistribution enables educators to focus on higher-order mentoring, curriculum refinement, and targeted support for at-risk learners. The analytics dashboard further provides actionable insights into cohort-wide misconception patterns and engagement clusters, supporting data-driven decisionmaking in course design. For high-enrollment computing programs, this scalability is particularly significant. Moreover, the stable system performance under concurrency stress testing (97% success at 500 users) demonstrates feasibility for deployment across institutional settings. Predictable latency and resource scaling indicate that infrastructure demands remain manageable even during peak load. Thus, the implication is not only pedagogical but organizational: ChatGPT-LC supports sustainable scaling of computing education while maintaining instructional fidelity, responsiveness, and ethical governance standards.
Despite the strong positive outcomes, responsible integration remains essential. While expert-verified accuracy exceeded 90%, LLM-generated explanations inherently carry risks of occasional misalignment or overconfidence. The system’s clarity markers and human-in-the-loop auditing procedures represent important safeguards, yet continued monitoring is necessary to prevent misconception reinforcement. Equity considerations also require attention. Interaction-rich learners benefited most from the system, suggesting that students with lower digital confidence or reduced engagement tendencies may require structured onboarding to fully leverage AI support. Ensuring equitable participation therefore demands instructional framing, scaffolded orientation, and explicit guidance on productive use. Data governance remains central. Compliance with PDPA standards, secure storage, and anonymization procedures establish a responsible baseline; however, longitudinal data tracking and cross-course integration will require continued transparency and institutional oversight. Future research should examine long-term retention, cross-domain transfer, and potential dependency effects. Randomized controlled trials and multi-institutional replication would strengthen generalizability. Additionally, formalizing learner-model accuracy metrics and affect-aware adaptation mechanisms could enhance precision.
The magnitude of the observed gains, while substantial, is supported by multiple converging indicators that strengthen their practical plausibility within the six-week intervention. First, the improvement reflects not merely raw score increases but a combination of intensive interaction, adaptive scaffolding, and sustained iterative debugging behaviors, which are empirically known to accelerate early-stage programming skill acquisition. Students in the ChatGPT-LC condition demonstrated significantly higher engagement intensity (e.g., 11.80 queries vs. 4.60 and 6.40 revisions vs. 2.90), indicating that the intervention substantially increased productive learning time and feedback frequency, both of which are strongly correlated with rapid conceptual gains. Second, statistical diagnostics confirmed medium-to-large effect sizes (Cohen’s d = 0.63–0.91) and narrow confidence intervals, suggesting that the gains were not anomalous but consistently distributed across participants rather than driven by outliers. Third, baseline equivalence tests verified that groups began at comparable proficiency levels, and identical instruction, assessment rubrics, and instructor conditions were maintained, reducing alternative explanations. Importantly, the reported percentage reflects normalized gain relative to low initial proficiency (pre-test ≈ 43%), where larger proportional improvements are pedagogically typical as foundational misconceptions are corrected. Finally, the improvement trajectory aligns with complementary evidence, including error reductions exceeding 50% and strong engagement–performance correlations (r up to 0.74), indicating that the effect represents cumulative cognitive restructuring rather than short-term score inflation. These combined behavioral, statistical, and instructional controls provide a coherent explanation for the magnitude of improvement despite the quasi-experimental cluster design.
The study was conducted at a single public university in northern Thailand, and this context should be considered when interpreting the scope and applicability of the findings. Institutional characteristics such as student demographics, technological infrastructure, curriculum design, and instructional practices may differ from those in other universities, regions, or countries. In addition, cultural factors, including learning norms, communication styles, and student–teacher interaction patterns, may influence how learners engage with educational technologies and respond to instructional interventions. These contextual conditions can affect both the level of engagement observed and its relationship with academic performance. As a result, caution is warranted when extending the findings to computing education at a broader institutional or international scale. The results provide evidence of effectiveness within the specific environment studied but do not guarantee equivalent outcomes in different settings. Nevertheless, the study offers useful insights into engagement–performance relationships and demonstrates a methodological approach that can be applied and evaluated in other contexts. Future research involving multiple institutions, diverse student populations, and varied educational systems would help to confirm the consistency of the observed relationships and strengthen the external validity and generalizability of the conclusions.
8. Conclusion
The integration of conversational reasoning, executable code analysis, misconception diagnostics, and dynamic learner-state modeling demonstrates how multimodal AI can meaningfully reshape computing education. The ChatGPT Learning Companion (ChatGPT-LC) functions not merely as an automated grader or answer generator, but as a cognitively aligned instructional partner that supports metacognition, iterative refinement, and conceptual restructuring. Substantial gains in concept mastery, debugging accuracy, and reflective engagement indicate that AI-supported dialogue can foster deeper learning processes rather than surface-level correctness. By embedding adaptive scaffolding and real-time analytics within routine programming activities, the framework enhances instructional responsiveness while preserving pedagogical alignment with course outcomes.
Several limitations warrant careful consideration. The quasi-experimental cluster design restricts strong causal inference, and implementation within a single institutional context limits generalizability across varied educational systems and learner populations. We acknowledge that the quasi-experimental cluster design limits the strength of causal inference, and therefore the reported outcomes should be interpreted as evidence of robust association rather than definitive causation. Although intact course sections were used to preserve ecological validity and avoid contamination, several safeguards were implemented to reduce confounding influences. Baseline equivalence tests confirmed no statistically significant differences in pre-intervention concept scores or prior academic performance between groups, and all sections were taught by the same instructor using identical materials, assignments, grading rubrics, and assessment procedures, thereby minimizing instructor- and curriculum-related variability. In addition, assessments were anonymized and teaching assistants were blinded to study condition to reduce evaluation bias. Behavioral and engagement data further demonstrated consistent learning–interaction relationships within the intervention group, suggesting that performance gains were closely aligned with measured system use rather than unobserved section characteristics. Nevertheless, because unmeasured peer dynamics or section-level factors cannot be fully ruled out, causal claims have been moderated accordingly, and future research employing randomized controlled trials, crossover designs, and multi-institutional replication will be essential to confirm the causal magnitude and generalizability of the observed effects. Although short-term improvements are robust, long-term retention, transfer across programming paradigms, and the effects of sustained AI exposure were not examined. The potential for overreliance or diminished productive struggle remains an open concern, particularly in environments where generative assistance becomes deeply embedded in daily learning routines.
Future research should prioritize randomized controlled designs, longitudinal analyses of conceptual durability, and cross-institutional replication to strengthen external validity. Methodological refinement is also needed to formalize learner-model accuracy metrics, incorporate affect-aware adaptation mechanisms, and examine how structured constraints on AI assistance influence independent reasoning development. Anchoring LLM-driven tutoring within rigorous educational design principles and transparent governance frameworks will be essential for ensuring that AI-supported computing education evolves responsibly, sustainably, and in alignment with long-term cognitive development goals. A more neutral and analytically grounded tone consistent with academic reporting standards has been adopted. Promotional expressions such as “transformative model,” “cognitive amplifier,” and “robust scalability” have been replaced with more measured terminology that reflects empirical findings without overstating implications. The language now emphasizes observed associations, performance improvements, and operational characteristics while acknowledging methodological constraints and contextual limitations. This ensures that interpretations remain evidence-based, balanced, and aligned with scholarly conventions, allowing readers to evaluate the system’s educational value based on reported data rather than rhetorical framing.
Author Contributions Statement
As the sole author of this manuscript, I was responsible for all stages of the research process. I conceptualized the study, designed the research methodology, implemented the instructional intervention, collected and analyzed the engagement and performance data, conducted statistical analyses including correlation, regression, and partial correlation with appropriate controls, interpreted the findings, and prepared all tables and figures. I also wrote, reviewed, and finalized the manuscript.
All authors have read and agreed to the published version of the manuscript.
Conflict of Interest Statement
The author declares no conflict of interest.
Funding Declaration
None.
Data Availability Statement
The data supporting the findings of this study were anonymized prior to analysis to protect participant privacy and are not publicly available. Aggregated data may be made available by the author upon reasonable academic request and subject to institutional approval.
Ethical Declarations
This study involved human participants in an educational setting. All data were anonymized prior to analysis to ensure participant confidentiality and privacy. The study was conducted in accordance with institutional ethical guidelines and educational research standards.
Acknowledgments
The author gratefully acknowledges the students who participated in this study and the academic colleagues and reviewers whose constructive comments and professional feedback contributed to improving the clarity, rigor, and overall quality of this research.
Declaration of Generative AI in Scholarly Writing
During the preparation of this manuscript, generative AI tools were used to assist with language refinement, grammar improvement, and structural organization. All research design, data collection, statistical analysis, interpretation, and academic conclusions were developed independently by the author. The author assumes full responsibility for the content.
Abbreviations
The following abbreviations are used in this manuscript:
AI: Artificial Intelligence
ANOVA: Analysis of Variance
API: Application Programming Interface
CS: Computer Science
CS1: Introduction to Programming
DL: Deep Learning
ENG: Student Engagement
GPT: Generative Pre-trained Transformer
ITS: Intelligent Tutoring System
LLM: Large Language Model
LMS: Learning Management System
M: Mean
N: Sample Size
NLP: Natural Language Processing
PCA: Principal Component Analysis
PL: Programming Language
SD: Standard Deviation
SE: Standard Error
Sig.: Statistical Significance
SPSS: Statistical Package for the Social Sciences
T: t-statistic
VIF: Variance Inflation Factor
Appendix
-
Appendix A. Operational Definitions of Core Constructs
Student Engagement Intensity
Measured using system interaction logs, including frequency of use, duration of interaction, task completion rate, and active participation in learning activities.
Learning Performance
Measured using programming assessment scores, including coding assignments, practical exercises, and postintervention concept tests. Composite scores were calculated using standardized grading criteria.
Baseline Ability
Measured using pre-test concept scores and prior academic performance indicators to represent students’ initial knowledge level before the intervention.
Learning Gain
Defined as the difference between post-test and pre-test scores, representing improvement in student understanding and skill development.
-
Appendix B. Programming Performance Rubric Structure
Technical Competency (50%)
-
• Code correctness
-
• Logical structure
-
• Algorithm implementation
-
• Error handling and debugging
Conceptual Understanding (30%)
-
• Application of programming concepts
-
• Problem-solving approach
-
• Code efficiency and organization
Communication and Documentation (20%)
-
• Code readability
-
• Documentation clarity
-
• Explanation of logic
Appendix C. Overall Competency Evaluation Criteria
Overall student performance was evaluated using integrated indicators including:
-
• Programming proficiency
-
• Conceptual mastery
-
• Problem-solving effectiveness
-
• Ability to apply knowledge independently
Composite performance scores were calculated using weighted aggregation of rubric components to ensure balanced and objective evaluation.
