Нетрадиционные архитектуры: ассоциативные процессоры и системы с управлением потоком данных

Автор: Л. С. Лаптев, П. М. Урвачев
Журнал: Informatics. Economics. Management - Информатика. Экономика. Управление.
Рубрика: Информатика, вычислительная техника
Статья в выпуске: 5 (1), 2026 года.
Бесплатный доступ
В статье рассмотрены особенности нетрадиционных архитектур вычислительных систем, в частности ‒ ассоциативных процессоров и систем с управлением потоком данных. Проведён анализ принципов организации вычислений, структуры памяти, способов управления и параллельной обработки информации. Ассоциативные процессоры описаны как архитектуры, использующие обращение к данным по содержимому и обеспечивающие параллельную обработку множества элементов. Системы с управлением потоком данных представлены как архитектуры, в которых выполнение операций определяется готовностью данных, что обеспечивает асинхронность и высокую степень параллелизма. В работе выполнен сравнительный анализ двух подходов, выявлены их преимущества, недостатки и области эффективного применения. Полученные результаты позволяют определить перспективы развития гибридных вычислительных систем, сочетающих ассоциативные и потоковые принципы обработки данных. В работе также проведено аналитическое моделирование временной сложности традиционной, ассоциативной и гибридной архитектур на задачах поиска и циклической обработки. Результаты моделирования показывают, что гибридная архитектура, сочетающая потоковый параллелизм операций с аппаратным ассоциативным сопоставлением токенов, позволяет многократно снизить латентность синхронизации данных по сравнению с классической потоковой моделью.
Нетрадиционные архитектуры, ассоциативные процессоры, системы с управлением потоком данных, потоковые вычисления, ассоциативная память, параллелизм, граф потоков данных, архитектура ЭВМ, параллельная обработка, вычислительные системы.
Короткий адрес: https://sciup.org/14135105
IDR: 14135105 | DOI: 10.47813/2782-5280-2026-5-1-1016-1024
Текст статьи Нетрадиционные архитектуры: ассоциативные процессоры и системы с управлением потоком данных
DOI:
Развитие современных вычислительных систем неразрывно связано с поиском путей повышения производительности, особенно при решении задач, требующих обработки больших массивов информации. Традиционная фон-неймановская модель, в которой порядок выполнения операций жестко задается последовательностью команд программы, имеет ряд принципиальных ограничений. Как отмечают С.А. Орлов и Б.Я. Цилькер, необходимость последовательного извлечения и декодирования команд, а также адресный доступ к памяти часто становятся «узким местом» (bottleneck), препятствующим эффективному распараллеливанию вычислений [1].
В связи с этим особую актуальность приобретает исследование нетрадиционных архитектур, основанных на принципиально иных подходах к организации вычислительного процесса. К таким архитектурам относятся ассоциативные процессоры и системы с управлением потоком данных, разработанные специально для задач, слабо поддающихся последовательной обработке [2, 3].
Ассоциативные процессоры, относящиеся к классу SIMD (один поток команд ‒ множество потоков данных), предлагают решение проблемы адресного доступа за счет выборки информации по её содержанию. Такой подход позволяет преодолеть ограничения адресной арифметики, задавая критерии отбора и выполняя преобразования только над теми данными, которые им удовлетворяют [4].
Альтернативным направлением являются системы с управлением потоком данных. В их основе лежит отказ от счетчика команд: выполнение операции инициируется автоматически фактом готовности необходимых операндов [2]. Это обеспечивает естественную асинхронность вычислений и позволяет достичь высокой степени параллелизма на уровне операций.
Целью данной работы является анализ принципов организации вычислений, структуры памяти и способов управления в указанных архитектурах, а также оценка перспектив их гибридизации.
Ассоциативные процессоры
Ассоциативный способ обработки данных позволяет преодолеть многие ограничения, присущие адресному доступу к памяти. Согласно В.П. Качкову, ключевым отличием является задание критерия отбора и проведение преобразований только над теми данными, которые удовлетворяют этому критерию [4]. Критерием отбора может быть совпадение с любым элементом данных, достаточным для выделения искомых записей.
Исследованы и в разной степени применяются несколько подходов, различающихся полнотой реализации модели ассоциативной обработки. Если реализуется только ассоциативная выборка данных с последующим поочередным использованием найденных данных, то говорят об ассоциативной памяти или памяти, адресуемой по содержимому. При достаточно полной реализации всех свойств ассоциативной обработки используется термин «ассоциативный процессор».
Ассоциативные системы относятся к классу: один поток команд - множество потоков данных (SIMD ‒ Single Instruction Multiple Data). Эти системы включают большое число операционных устройств, способных одновременно по командам управляющего устройства вести обработку нескольких потоков данных. В ассоциативных вычислительных системах информация на обработку поступает от ассоциативных запоминающих устройств (АЗУ), характеризующихся тем, что информация в них выбирается не по определенному адресу, а по ее содержанию [5].
На схеме представлена типовая структура ассоциативного процессора (Рис. 1):
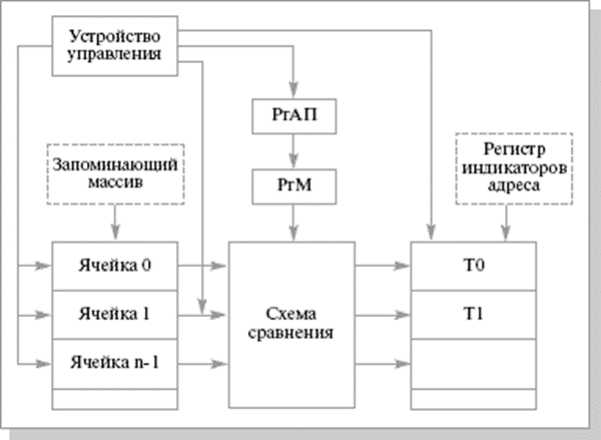
Рисунок 1. Схема ассоциативной системы. Figure 1. Diagram of the associative system
Ключевыми элементами схемы, обеспечивающими поиск по содержимому, являются специализированные регистры:
-
• РгАП (Регистр ассоциативного признака) ‒ в этот регистр заносится искомый образ (так называемый «компарад»), с которым будут одновременно сравниваться данные во всех ячейках памяти.
-
• РгМ (Регистр маски) ‒ критически важный компонент, позволяющий выполнять поиск не только по полному совпадению, но и по отдельным фрагментам слов. Биты, помеченные в маске нулями, исключаются из операции сравнения, что дает возможность гибкой выборки данных по сложным критериям.
-
• Регистр индикаторов адреса (совпадения) ‒ фиксирует результаты параллельного
сравнения. Если содержимое ячейки удовлетворяет критерию поиска (с учетом маски), соответствующий бит в этом регистре устанавливается в единицу, отмечая строку для дальнейших операций чтения или записи.
В ассоциативном процессоре операция поиска выполняется параллельно для всех ячеек. Пусть Tsearch - время поиска, тогда согласно модели, описанной В.П. Качковым [4], оно зависит не от количества слов N , а от разрядности ассоциативного признака (ширины поиска) т: Tsearch = к хт, где к - константа, определяемая схемотехникой ячейки памяти. Таким образом, сложность поиска составляет 0(т) или даже 0(1) по отношению к объему массива данных. Это фундаментальное преимущество делает ассоциативные архитектуры безальтернативными для задач реального времени с большими базами данных [4].
Системы с управлением потоком данных
Системы с управлением потоком данных (или потоковые вычислительные системы) относятся к числу нетрадиционных архитектур ЭВМ, основанных на принципиально ином подходе к организации вычислений по сравнению с фон-неймановской моделью. В традиционной архитектуре порядок выполнения операций задаётся последовательностью команд программы, тогда как в системах с управлением потоком данных выполнение операций определяется наличием необходимых данных для данной операции.
Основная идея потокового управления заключается в том, что вычисления активизируются не при поступлении команды из управляющего устройства, а автоматически ‒ при готовности всех операндов. Таким образом, выполнение программы представляется в виде графа потоков данных, где вершины соответствуют операциям, а дуги ‒ передаче результатов между ними.
Формально такая система описывается ориентированным графом G = (У,Е), где V -множество узлов-операторов, а Е - множество дуг, передающих токены данных. Условие срабатывания («поджига») узла V 1 можно записать как конъюнкцию наличия токенов на всех его входах:
F(vt) = 3ti е In^i) л ... л 3tk е Ink(vt), где Ink(vi) - к-й входной канал узла. Как указывает Е.А. Дудников, данное правило обеспечивает детерминированность вычислений даже при асинхронном поступлении данных, что позволяет системе автоматически распараллеливать ветви алгоритма без участия программиста [2].
Каждая операция в такой системе снабжается меткой (тегом), определяющей состояние её операндов. Когда все входные данные становятся доступны, операция автоматически направляется в исполнительный модуль, где происходит её выполнение. Полученный результат передаётся далее по графу данных, активируя последующие операции. Подобная организация вычислений обеспечивает асинхронное и параллельное выполнение большого числа операций без централизованного управления.
Рассмотрим принцип работы такой системы на примере вычисления выражения Y = (А + В) х (С-D'). В традиционной ЭВМ эти операции выполнялись бы строго последовательно. В потоковой модели программа трансформируется в граф, где нижний уровень занимают узлы ввода значений A, B, C, D. Операции сложения (А + В) и вычитания (С — D) независимы друг от друга, поэтому, как только входные токены поступают в систему, оба узла срабатывают одновременно (параллельно). Узел умножения, находящийся на вершине графа, остается в режиме ожидания. Он активируется
(«поджигается») автоматически только в тот момент, когда на его входы поступят результаты от обоих предыдущих узлов. Такой подход исключает простои процессора на ожидание выборки команд.
Потоковые системы характеризуются отсутствием счетчика команд и управляющего устройства, типичных для фон-неймановской модели. Управление вычислительным процессом полностью передаётся структуре данных, что позволяет избавиться от проблем, связанных с последовательным извлечением и декодированием команд. Это делает потоковые архитектуры особенно эффективными для задач с высоким уровнем параллелизма и большим числом независимых вычислений.
В России исследования таких архитектур ведутся в различных научных центрах. В частности, в Московском институте электроники и математики (МИЭМ НИУ ВШЭ) разработаны объектно-атрибутные вычислительные системы, относящиеся к классу архитектур с управлением потоком данных. Они включают сеть вычислительных узлов, связанных каналами обмена сообщений, где каждый узел выполняет операции по мере поступления входных данных. Аналогичные принципы реализованы в работах Сибирского отделения РАН, где потоковые вычислительные структуры рассматриваются как графы данных, отражающие зависимости между операциями и потоками информации.
СРАВНИТЕЛЬНЫЙ АНАЛИЗ
АССОЦИАТИВНЫХ ПРОЦЕССОРОВ И СИСТЕМ С УПРАВЛЕНИЕМ ПОТОКОМ ДАННЫХ
Ассоциативные процессоры и системы с управлением потоком данных относятся к классу нетрадиционных архитектур вычислительных систем, разработанных для повышения производительности при обработке больших массивов данных и решения задач, слабо поддающихся последовательной обработке. Несмотря на общую направленность на реализацию параллельных вычислений, данные архитектуры различаются принципами организации вычислений, методами обращения к памяти и механизмами управления процессом обработки информации.
Принципы организации вычислений
Ассоциативные процессоры реализуют параллелизм на уровне данных: одна команда одновременно выполняется над множеством элементов информации. Главным элементом здесь является ассоциативная память (АЗУ), в которой выборка данных осуществляется по их содержимому, а не по адресу. Это позволяет обрабатывать данные, удовлетворяющие заданному условию, без явного перебора адресов.
В системах с управлением потоком данных параллелизм реализуется на уровне операций. Выполнение команды активируется автоматически при готовности всех необходимых операндов. Управление вычислительным процессом передаётся самим данным, а не управляющему устройству, что обеспечивает асинхронность и возможность одновременного выполнения множества независимых операций.
Организация памяти и управления
Ассоциативные системы основаны на массивных параллельных структурах памяти, каждая ячейка которых может сравниваться с заданным образцом. Центральное управляющее устройство формирует команды, а выполнение происходит синхронно во всех операционных блоках.
Системы с управлением потоком данных, напротив, не имеют централизованного управления и счётчика команд. Их структура представляет собой сеть вычислительных узлов, связанных каналами передачи данных. Каждый узел функционирует независимо и активируется при поступлении всех входных данных. В таких системах отсутствует традиционное понятие последовательности команд ‒ вычислительный процесс описывается в виде графа потоков данных.
Производительность и области
ПРИМЕНЕНИЯ
Ассоциативные процессоры эффективны при решении задач, связанных с поиском, фильтрацией и сопоставлением данных, обработкой больших таблиц и баз данных, задачах распознавания образов, лингвистических и поисковых системах. Их преимущество заключается в быстром доступе к нужной информации без явного перебора.
Системы с управлением потоком данных более эффективны при выполнении сложно структурированных вычислительных процессов, имеющих большое число независимых операций, например при моделировании физических процессов, обработке сигналов, нейроморфных вычислениях и в распределённых системах. Они обеспечивают высокую степень параллелизма и гибкость при масштабировании [6].
Сравнительная характеристика между системами приведена в Таблице 1.
Таблица 1. Сравнительная характеристика.
Table 1. Comparative characteristics.
|
Характеристика |
Ассоциативные процессоры |
Системы с управлением потоком данных |
|
Принцип организации вычислений |
Ассоциативный поиск и обработка по содержимому |
Активизация операций при готовности данных |
|
Тип параллелизма |
Параллелизм данных (SIMD) |
Параллелизм операций (MIMD, асинхронный) |
|
Управление |
Централизованное, синхронное |
Децентрализованное, асинхронное |
|
Организация памяти |
Ассоциативная память (АЗУ) |
Сеть узлов с локальными буферами данных |
|
Основное достоинство |
Быстрый поиск и фильтрация данных |
Максимальное использование параллелизма |
|
Основной недостаток |
Высокая аппаратная сложность АЗУ |
Сложность реализации маршрутизации и тегирования данных, |
|
Типичные области применения |
Поиск, базы данных, распознавание образов |
Научные вычисления, ИИ, распределённые системы |
Перспективы гибридных архитектур
Анализ принципов работы ассоциативных и потоковых систем позволяет сделать вывод о том, что их объединение в рамках гибридной архитектуры способно компенсировать недостатки каждого из подходов, сохраняя их ключевые преимущества. Наиболее перспективным направлением является использование ассоциативной памяти в качестве аппаратной основы для управления потоками данных.
Ключевой проблемой классических потоковых систем, отмеченной в таблице 1, является сложность реализации механизма сопоставления токенов (matching). В потоковой архитектуре операция активируется только тогда, когда на входы узла поступают все необходимые операнды с одинаковыми тегами. При большом потоке данных поиск парных токенов в обычной памяти становится «узким местом», снижающим производительность системы.
Внедрение элементов ассоциативной архитектуры позволяет решить эту задачу следующим образом:
-
• Ассоциативное устройство согласования.
Вместо перебора очереди токенов используется специализированная ассоциативная память (АЗУ). При поступлении токена-операнда его тег (метка контекста) сравнивается с содержимым памяти параллельно за один такт, используя механизм, описанный в разделе 1 (регистры РгАП и РгМ).
-
• Ускорение обработки циклов. Эффективная реализация циклических конвейеров
критична для производительности.
Ассоциативный доступ позволяет мгновенно идентифицировать токены, относящиеся к разным итерациям цикла, предотвращая блокировки конвейера.
-
• Интеллектуальная маршрутизация. В
распределенных системах, подобных описываемым Дудниковым Е.А., ассоциативные узлы могут выполнять роль интеллектуальных маршрутизаторов, которые фильтруют и перенаправляют пакеты данных на основе их содержимого, а не жестко заданных адресов.
Таким образом, гибридная архитектура представляет собой потоковый процессор с ассоциативным ядром управления. В такой системе вычислительные узлы работают асинхронно, обеспечивая максимальный параллелизм (принцип потоковых систем), а управление зависимостями данных осуществляется через сверхбыструю ассоциативную память (принцип ассоциативных процессоров). Это открывает новые возможности для создания высокопроизводительных вычислительных комплексов, ориентированных на задачи искусственного интеллекта и моделирование сложных динамических процессов в реальном времени
РЕЗУЛЬТАТЫ ЭКСПЕРИМЕНТАЛЬНОЙ ОЦЕНКИ ПРОИЗВОДИТЕЛЬНОСТИ
В связи с физической недоступностью промышленных образцов гибридных вычислительных систем, в данной работе применено аналитическое моделирование. Целью эксперимента является сравнительная оценка временной сложности алгоритмов на трех типах архитектур: традиционной (SISD), ассоциативной (SIMD) и гибридной потоковой.
Методика эксперимента и
МАТЕМАТИЧЕСКИЕ МОДЕЛИ
Для проведения оценки были выбраны два типа вычислительных задач, характерных для современных систем обработки данных:
-
1. Задача поиска. Поиск вхождений в неупорядоченном массиве данных (Pattern Matching).
-
2. Задача потоковой обработки. Выполнение циклической последовательности
арифметических операций с зависимостями по данным.
В качестве метрики эффективности выбрано полное время выполнения T (в тактах процессора).
Модель 1: традиционная архитектура (фон Нейман). Время выполнения линейно зависит от объема данных N. Согласно С.А. Орлову, основные затраты приходятся на выборку команд и данных [1].
TSISD — N X (t fetch + t d ec + texec), где tfe tch , tde c , texe c - время выборки, декодирования и исполнения соответственно.
Модель 2: ассоциативный процессор. Согласно исследованиям В.П. Качкова, время поиска в ассоциативной памяти определяется не объемом массива N, а разрядностью (шириной) ассоциативного признака W [4].
Tassoc — к xW, где к - коэффициент, зависящий от схемотехники (обычно 1 < к < 3 тактов на бит). Это обеспечивает сложность 0(1) относительно N.
Модель 3: потоковая и гибридная архитектура. Для потоковых систем время выполнения зависит от глубины графа вычислений L и накладных расходов на синхронизацию токенов (Matching Store). Как указано в работах Е.А. Дудникова, узким местом является поиск парных токенов [2].
TDATAFLOW — — x L + N x tmatch (М), где P - степень параллелизма (число узлов), tmatch(W) - время поиска токена в буфере ожидания размера М.
В гибридной модели, предлагаемой авторами, tmatch становится константой благодаря использованию ассоциативной памяти для тегирования токенов (устраняется зависимость от заполненности буфера М).
Результаты моделирования. Задача
ПОИСКА
Моделирование производилось для массива N от 103 до 10 6 записей при ширине ключа поиска W — 64 бита.
Результаты представлены в Таблице 2.
Таблица 2. Зависимость времени поиска ( В тактах) от объема данных.
Table 2. Dependence of the search time (in clock cycles) on the amount of data.
|
Объем данных (N) |
Традиционная ЭВМ (O(N)) |
Ассоциативный процессор (O(1)) |
Ускорение (раз) |
|
1 000 |
5 000 |
64 |
78 |
|
10 000 |
50 000 |
64 |
781 |
|
100 000 |
500 000 |
64 |
7 812 |
|
1 000 000 |
5 000 000 |
64 |
78 125 |
Из Таблицы 2 видно, что ассоциативная архитектура демонстрирует постоянное время отклика, что критически важно для систем реального времени. Традиционная архитектура показывает линейную деградацию производительности.
Результаты моделирования. Циклическая
ОБРАБОТКА
Вторая часть эксперимента оценивала эффективность выполнения арифметического цикла, что актуально для построения циклических конвейеров. Сравнивались классическая потоковая архитектура (с программным хешированием токенов) и гибридная (с аппаратным ассоциативным сопоставлением).
В классической системе с ростом нагрузки (количества активных токенов M) время поиска пары в буфере растет логарифмически или линейно. В гибридной системе оно остается постоянным.
Результаты представлены в Таблице 3.
Таблица 3. Влияние нагрузки на латентность синхронизации токенов.
Table 3. The impact of load on the latency of token synchronization.
|
Нагрузка (активных токенов) |
Классический Dataflow (такты) |
Гибридный Dataflow + АЗУ (такты) |
Эффективность гибридизации |
|
100 |
15 |
2 |
+ 7.5x |
|
1 000 |
35 |
2 |
+ 17.5x |
|
10 000 |
150 |
2 |
+ 75.0x |
Результаты экспериментов подтверждают теоретические предпосылки.
-
1. В задачах поиска ассоциативные процессоры обеспечивают ускорение на несколько порядков по сравнению с фон-неймановскими системами при больших объемах данных (N > 104).
-
2. В задачах управления потоком данных (Dataflow) «узким местом» является механизм сопоставления операндов. Как видно из Таблицы 3, внедрение ассоциативной памяти устраняет зависимость задержки от загрузки системы. Это позволяет эффективно
реализовывать методы построения циклических конвейеров, описанные И.А. Адамовичем, без риска переполнения буферов ожидания [7].
Таким образом, гибридная архитектура, сочетающая потоковый параллелизм операций с ассоциативным управлением памятью, является оптимальной для высоконагруженных распределенных вычислений.
ЗАКЛЮЧЕНИЕ
Анализ нетрадиционных архитектур показал, что ассоциативные процессоры и системы с управлением потоком данных предлагают принципиально разные подходы к организации параллельных вычислений, позволяющие преодолеть ограничения фон-неймановской модели. В то время как ассоциативные процессоры реализуют параллелизм данных (SIMD), сосредотачиваясь на одновременной обработке множества элементов одной командой, потоковые системы обеспечивают параллелизм операций (MIMD), где выполнение операций инициируется готовностью операндов.
Ассоциативные системы, основанные на памяти, адресуемой по содержимому (АЗУ), демонстрируют высокую эффективность в задачах быстрого поиска, фильтрации и распознавания образов. Их главным преимуществом является возможность параллельного сравнения всех ячеек памяти с заданным критерием, однако они отличаются высокой аппаратной сложностью.
Потоковые системы, представляющие собой асинхронную сеть вычислительных узлов, обеспечивают максимальное использование параллелизма для сложно структурированных процессов, таких как научные вычисления и распределенные системы. Основным недостатком этих систем является сложность реализации механизма сопоставления токенов (matching), необходимого для корректного связывания операндов, что приводит к накладным расходам на маршрутизацию и тегирование данных.
Полученные результаты указывают на перспективность разработки гибридных вычислительных систем. Предлагаемое использование ассоциативной памяти в качестве устройства согласования токенов позволяет устранить ключевой недостаток потоковых систем. Ассоциативный доступ обеспечивает мгновенное сопоставление операндов по их тегам, что критически важно для эффективной работы циклических конвейеров и интеллектуальной маршрутизации.
