Object Oriented Software Effort Estimate with Adaptive Neuro Fuzzy use Case Size Point (ANFUSP)
")
Author: Mohammad Saber Iraji, Homayun Motameni
Journal: International Journal of Intelligent Systems and Applications(IJISA) @ijisa
Article in issue: 6 vol.4, 2012.
Free access
Use case size point (USP) method has been proposed to estimate object oriented software development effort in early phase of software project and used in a lot of software organizations. Intuitively, USP is measured by counting the number of actors, preconditions, post conditions, scenarios included in use case models. In this paper have presented a Adaptive fuzzy Neural Network model to estimate the effort of object oriented software using Use Case size Point approach. In our proposed system adaptive neural network fuzzy use case size point has less error and system worked more accurate and appropriative than prior methods.
Use case size point, effort, adaptive neuro fuzzy, object oriented effort
Short address: https://sciup.org/15010267
IDR: 15010267
Text of the scientific article Object Oriented Software Effort Estimate with Adaptive Neuro Fuzzy use Case Size Point (ANFUSP)
Published Online June 2012 in MECS
Today the software industry experience and training data in order to estimate the effort of software is important.
Estimation of object oriented software cost and effort is an important and hard management activity. This is due to the lack of information to making decisions in the early phases of the development, frequently characterized by uncertainty. To help the managers in this task, there are in the literature many estimation models that usually include two main metrics: Lines of Code (LOC) and Function Points (FP) [2], both of them with skills and limitations. LOC is dependent on the programming language and the FP Analysis (FPA) is subjective and based on human decisions [3].
As the most popular technique for object-oriented software cost estimation, Use Case Points (UCP) method, however, has two major drawbacks: the uncertainty of the cost factors and the abrupt classification [4]. Software cost estimation is vital for project bidding, budgeting, controlling and planning. Although in the literature many estimation models like Constructive Cost Model (COCOMO), Function Points (FP) have been proposed to help manager in estimation task, there is no obvious evidence shows that the accuracy is improved in last decades [5]. Achieving a highly accurate estimation is still a challenging issue in software engineering [4].
The subjects of estimation in the area of software development are size, effort invested, development time, technology used and quality. Particularly, development effort is the most important issue. So far, several effort models [6][7][8] have been proposed and most of them include software size as an important parameter. Function point is a measure of software size that uses logical functional terms business owners and users more readily understand [9]. Since it measures the functional requirements, the measured size stays constant despite the programming language, design technology, or development skills involved. To estimate the effort in earlier phase, use case point method has been proposed [10]. Use case point (UCP) is measured from a use case model that develops the functional scope of the software system to be developed. It is intended by the function point methods and is based on analogous use case point. There are several experience reports that show the usefulness of use case point for early estimation of software size.
Unified Modeling Language (UML) is a graphical modeling language that is used for visualizing, specifying, constructing and documenting software systems. To capture the functional requirements of a software project use case models are often employed. Use case modeling is a technique that has been widely used throughout the industry/research to describe and capture the functional requirements of a software system [11]. Since use cases and scenarios are developed as a normal part of requirements gathering and analysis they capture an accurate representation of the user’s requirement.
The use case point’s method adjusts the size of the functionality of the system based on a number of technical and environmental factors. The technical factors are related to non-functional requirements on the system, while the environmental factors characterize the development team and its environment. The influence of these factors on the estimate was in this case much smaller (a 16% increase in the estimate) than the increase in actual effort spent by the companies that emphasized the development process and the quality of the code (an increase in actual effort of more than 100%) [1].
Software estimation models combining algorithmic models with machine learning approaches, such as neural networks and fuzzy logic, have been viewed with skepticism by the majority of software managers [12]. Briefly, neural network techniques are based on the principle of learning from historical data, whereas fuzzy logic is a method used to make rational decisions in an environment of uncertainty and vagueness. However, fuzzy logic alone does not enable learning from the historical database of software projects. Once the concept of fuzzy logic is incorporated into the neural network, the result is a neuro-fuzzy system that combines the advantages of both techniques [13].
Many metrics exist based on use case model in object oriented software .we Consider use case size point (USP) metric in this paper .
However, our proposed neuro-fuzzy model goes even further: it is a unique combination of neural networks and fuzzy logic. Specifically, we obtained equation 4 , defined a suite of fuzzy sets to represent human judgment, and used a neural network to learn from a comprehensive historical database of software projects. A Neuro-Fuzzy use case size Points Calibration model that incorporates the learning ability from neural network and the ability to capture human knowledge from fuzzy logic is proposed and further validated in this paper.
The paper is organized in six sections. After the introduction in Section I, Section II which also introduces the related works of effort estimation. Section II continues with explanations of use case point and use case size point approaches effort estimation in section III, IV. in Section V is proposed Effort estimate with adaptive neuro fuzzy use case size point. It continues with discussions on the architecture of hybrid learning and fuzzy model validation, the error of observations for training data sets. Section VI presents the conclusions of the research. The paper ends with a list of references.
-
II. Software Effort Estimate Algorithms
The use case points method was proposed by Karner in 1993, who also validated it on three projects [14].The method is an extension of MKII Function Points Analysis [15]. The use case points method adjusts the use case points based on a number of technical and environmental factors. This is similar to MKII Function Points, which also adjusts the size based on a number of calibration factors [1,15]. These factors have been criticized for not improving the precision of the estimate [16]. The criticism relates both to the chosen set of factors and to their influence, but little investigation has been done on the effects on effort of the individual factors. Use cases
are often used as input for estimating software development effort. Several studies show that a particular estimation method based on use cases, the use case points method, performs well early in aproject [17-18,19,42,21].
In [22, 23, 24, 25] authors have used different neural network models for cost estimation. In [26, 27, 28, 29] the authors have used different case studies for estimating the effort of the software development using use case point approach. Neural Network is an area which is leading the promise of producing consistently accurate estimate. The system effectively learns how to estimate from training set of completed projects [11]. In [11] authors have used neural network models for effort estimation using use case point approach.
Dealing with simple ‘black’ and ‘white’ answers is no longer satisfactory enough; degree of membership (suggested by Prof. Zadeh in 1965) became a new way of solving problems by treating data as imprecise or in a fuzzy form, there rule-based allowing the fuzzy system to handle certain degree of randomness without compromising on the efficiency of the system. Fuzzy set is more powerful than classic set, because in real life most of the membership of the set is not a simply absolute “in or out” and fuzzy set mimic the way in which human interprets the terms, so it make is possible to deal with vagueness, imprecise and uncertainty when identifying the category. Fuzzy set theory has been applied software cost estimation for a long time.
Belchior et al [30] show that the metric FP does not have a continuous classification of the functionalities. They propose the Fuzzy Function Point Analysis (FFPA), that introduces a continuous and gradual classification of the system functionalities by using fuzzy numbers to perform the role of the traditional classification tables.
Rodrigo extended Use case Size Points(USP) to Fuzzy Use case Size Points(FUSP) by using fuzzy set theory[31]. Ryder researched on the application of fuzzy logic to COCOMO and Function Points models [32].Some techniques like fuzzy set and BBNs are introduced for software cost model. Fuzzy set use the degrees of membership in set to replace the absolute “in or out” membership in classic set, which results more precise assessments in software cost estimation[31,32,33].
Neuro-fuzzy systems are one of the most successful and visible directions of that effort. Neuro fuzzy hybridization is done in two ways [34]: a neural network equipped with the capability of handling fuzzy information (termed fuzzy neural network) and a fuzzy system augmented by neural networks to enhance some of its characteristics like flexibility, speed, and adaptability (termed neuro-fuzzy system(NFS) or ANFIS). An adapted neuro-fuzzy system (NFS) is designed to realize the process of fuzzy reasoning, where the connection weights of network correspond to parameters of fuzzy reasoning [34, 35]. These methodologies are thoroughly discussed in the literature [34].A second and distinct approach to hybridization is the genetic fuzzy systems (GFSs) [36]. A GFS is essentially a fuzzy system augmented by a learning process based on genetic algorithms (GAs). The parameter optimization has been the approach used to adapt a wide range of dissimilar fuzzy systems,as in genetic fuzzy clustering or genetic fuzzy systems [36].However, genetic fuzzy systems are not subject of this work.
Marcio Rodrigo Braz, Silvia Regina Vergilio in[3] porposed FUSP (Fuzzy Use Case Size Points), considers concepts of the Fuzzy Set Theory to create gradual classifications that better deal with uncertainty. Results from an empirical evaluation show the applicability and some advantages of the proposed metrics.
Wei xia et al.[13] introduce a new calibration for Function Point complexity weights. A FP calibration model called Neuro-Fuzzy Function Point Calibration Model (NFFPCM) that integrates the learning ability from neural network and the ability to capture human knowledge from fuzzy logic is proposed. The empirical validation using International Software Benchmarking Standards Group (ISBSG) data.
-
III. Use Case Point Approach
Use case point (UCP) is calculated from use case model in[26]. Table 1 gives a brief overview of the steps of the method.
Table 1 The UCP estimation method [26]
|
Step |
Rule |
Output |
|
1 |
Classify actors: a)Simple , WF (Weight Factors)=1 b)Average , WF=2 c)Complex , WF=3 |
Unadjusted Actor Weight (UAW)= ∑(#Actors * WF) |
|
2 |
Classify Use Cases: a)Simple- 3 OR Fewer transactions, WF=5 b)Average- 4 to 7 transactions, WF=10 c)Complex-more then7 transactions, WF=152 |
Unadjusted Use Case Weight (UUCW)= ∑(#Use Cases * WF) |
|
3 |
Calculate the Unadjusted Use Case Point (UUCP) |
UUCP = UAW + UUCW |
|
4 |
Assign values to the technical and environmental factors [0..5], multiply by their weights[ -1..2], and calculate the weighted sums (TFactor and Efactor). Calculate TCF and EF as shown |
Technical Complexity Factor (TCF) = 0.6 + (0.01*TFactor) Environmental Factor (EF) = 1.4 + (-0.03 + EFactor) |
|
5 |
Calculate the Unadjusted Use Case Point (UCP) |
UCP = UUCP * TCF * EF |
|
6 |
Estimate Effort (E) in Person-hours |
E = USP * PHperUCP |
In step 4, there are 13 technical factors, which are basically non-functional requirements on the system, see Table 2. There are also eight environmental factors that relate to the efficiency of the project in terms of the qualifications and motivation of the development team, see Table 3. The weights and the formula for technical factors are borrowed from the Function Points method proposed by Albrecht [20]. Karner himself proposed the weights and the formula for the environmental factors based on interviews with experienced developers and some estimation results. In step 6, the adjusted use case points (UCP) is multiplied by a productivity factor. The literature on the UCP proposes from 20 to 36 person hours per use case point (PHperUCP) depending on the values of the environmental factors [14,37].
Table 2 Technical factor [14]
|
Factor |
Description |
Weight |
|
T1 |
Distributed System |
2 |
|
T2 |
Response or throughput Performance objectives |
2 |
|
T3 |
End-user efficiency |
1 |
|
T4 |
Complex internal processing |
1 |
|
T5 |
Reusable Code |
1 |
|
T6 |
Easy to install |
0.5 |
|
T7 |
Easy to use |
0.5 |
|
T8 |
Portable |
2 |
|
T9 |
Easy to change |
1 |
|
T10 |
Concurrent |
1 |
|
T11 |
Includes security features |
1 |
|
T12 |
Provides access for third parties |
1 |
|
T13 |
Special user training facilities are required |
1 |
Table 3 Environmental factor [14]
|
Factor |
Description |
Weight |
|
F1 |
Familiar with Rational Unified Process |
1.5 |
|
F2 |
Application experience |
0.5 |
|
F3 |
Object-oriented experience |
1 |
|
F4 |
Lead analyst capability |
0.5 |
|
F5 |
Motivation |
1 |
|
F6 |
Stable requirements |
2 |
|
F7 |
Part-time workers |
-1 |
|
F8 |
Difficult programming language |
-1 |
-
IV. Use Case Size Point (USP)
USP measures the functionality by considering the structures and sections of a UC, counting the number and weight of scenarios, actors, precondition and post conditions [3]. To determine the USP, the sections of an expanded UC are analyzed and its elements must be classified. The USP for the whole system is given by the sum of the USP for each UC. The following steps show how to calculate USP [3].
Step1:
total complexity of actors(TPA), total complexity of the preconditions (TPPrC), complexity of the scenario (PCP), total complexity of the alternative scenarios (TPCA), total exceptions complexity (TPE) and total complexity of postconditions (TPPoC) calculates from tables 4-8 and computs Unadjusted Use-case Size Point (UUSP) value from Equation 1.
UUSP = TPA + TPPrC + PCP + TPCA + TPE + TPPoc (1)
Step2:
Technical Adjustment Factors calculate from table 9 by
Equation 2.( 0 ^ Ii ^ 5)
FTA = 0.65 + (0.01* Z Ц ) (2)
i = 1
Table 8 USP postcondition classification [3]
|
Complexity |
Entities |
UUSP |
|
Simple |
<3 |
1 |
|
Average |
4 to 6 |
2 |
|
Complex |
>6 |
3 |
Step3:
Environmental Adjustment Factor (FAA) calculate from table 10 by Equation3.
FAA = 0.01* Z It(3)
i=1
Step4:
The final value for a UC is given by Equation 4:
USP = UUSP* (FTA - FAA)
Table 4 UCP actor classification [3]
|
Complexity |
Tested Expressions |
UUSP |
|
Simple |
1 logical expression |
1 |
|
Average |
2 or 3 logical expressions |
2 |
|
Complex |
> 3 logical expressions |
3 |
Table 5 USP precondition classification [3]
|
Complexity |
Entities |
UUSP |
|
Simple |
<3 |
1 |
|
Average |
4 to 6 |
2 |
|
Complex |
>6 |
3 |
Table 6 USP scenario classification [3]
|
Complexity |
Entities + Steps |
UUSP |
|
Veiy Simple |
<5 |
4 |
|
Simple |
6 to 10 |
6 |
|
Average |
11 to 15 |
8 |
|
Complex |
16 to 20 |
12 |
|
Veiy Complex |
>20 |
16 |
Table 7 USP exception classification [3]
|
Complexity |
Tested Expression |
UUSP |
|
Simple |
1 logical expression |
1 |
|
Average |
2 or 3 logical expressions |
2 |
|
Complex |
3 logical expressions |
3 |
Table 9 Technical factors[45]
|
Factor |
Requirement |
Influence |
|
Pl |
Data communication |
II |
|
F2 |
Distributed processing |
12 |
|
P3 |
Performance |
13 |
|
F4 |
Equipment utilization |
14 |
|
F5 |
Transaction Capacity |
15 |
|
F6 |
On-line input of data |
16 |
|
F7 |
User efficiency |
17 |
|
F8 |
On-line update |
18 |
|
F9 |
Code reuse |
19 |
|
F10 |
Complex processing |
IIO |
|
Fil |
Easiness of deploy |
Ill |
|
F12 |
Easiness operation |
112 |
|
F13 |
Many places |
113 |
|
F14 |
Facility of change |
114 |
Table 10 Environmental factors [46]
|
Factor |
Description |
Influence |
|
El |
Fonnal development process existence |
II |
|
E2 |
Experience with the application being developed |
12 |
|
E3 |
Experience of the team with the used technologies |
13 |
|
E4 |
Presence on an experienced analyst |
14 |
|
E5 |
Stable requirements |
15 |
-
V. Study Objectives And Method
The objectives of this study are:
-
• calibration of the use case point factor weight values Exactly to fuzzy further enhanced
improvements in the software effort estimation process
-
• Artificial neural network approach to
calibrate the function point weight values provides improvement in the software size estimation process.
The weight values of Unadjusted use case size Point (UUSP) in Tables 4-8 are said to reflect the functional size of software [24], Karner determined them in 1993. Since 1993, software development has been growing steadily and is not limited to one organization or one type of software. Thus, there is need to calibrate these weight values to reflect the current software industry trend. The ISBSG Development and Enhancement repository has over 5,600 projects from 29 countries and 11 major industry types. This industry data can be used to estimate, benchmark and improve the planning and management of projects. Learning UUSP weight values helps for calibration to reflect the current software industry trend from ISBSG data repository using neural network.
Our Neuro-Fuzzy approach presented in this paper is a novel combination of the above three approaches. It obtains a simple equation 4 , defines a suite of fuzzy sets to represent human judgment Exactly, and uses neural network to learn the calibrated parameters from the historical project database. The equation from statistical analysis is fed into neural network learning. The calibrated parameters from neural network are then utilized in fuzzy sets and the users can specify the upper and lower bounds from their human judgment.
The first , the neural network technique is based on the principle of learning from previous data. This neural network is trained with a series of inputs and desired outputs from the training data so as to minimize the prediction error. Once the training is complete and the appropriate weights for the network links are determined, new inputs are presented to the neural network to predict the corresponding estimation of the response variable. The final component of our model, fuzzy logic, is a technique used to make rational decisions in an environment of uncertainty and imprecision. It is rich in its capability to represent the human linguistic ability with the terms of fuzzy set, fuzzy membership function, fuzzy rules, and the fuzzy inference process(figure 1). PHperUSP proposes 2.5 person hours per use case Size point .
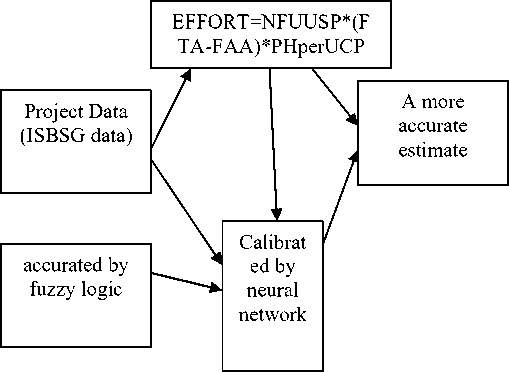
Figure 1. neuro fuzzy use case size point model
-
A. Neuro fuzzy
It immediately comes to mind, when looking at a neural network, that the activation functions look like fuzzy membership functions. Indeed, an early paper from 1975 treats the extension of the McCulloch-Pitts neuron to a fuzzy neuron (Lee & Lee, 1975; see also Keller & Hunt, 1985).
The one neuron in the output layer, with a rather odd appearance, calculates the weighted average corresponding to the center of defuzzification in the rule base. Backpropagation applies to this network since all layers are differentiable. Two possibilities for learning are apparent. One is to adjust the weights in the output layer, i.e ,all the singletons weight until the error is minimized. The other is to adjust the shape of the membership functions, provided they are parametric. also rule weight can be changed with training data. in Neuro fuzzy model is not necessary output be linear[43].
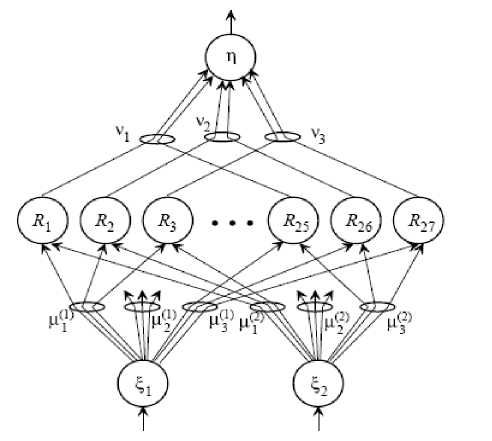
Figure 5. Neuro fuzzy model control system
A.1 Neural network
Developing a neural net solution means teaching the net a desired behavior. This is called the learning phase. Either sample data sets or a “teacher” can be used in this step. A teacher is either a mathematical function or a person that rates the quality of the neural net performance. Since neural nets are mostly used for complex applications where no adequate mathematical models exist and rating the performance of a neural net is difficult in most applications, most are trained with sample data(figure 2).
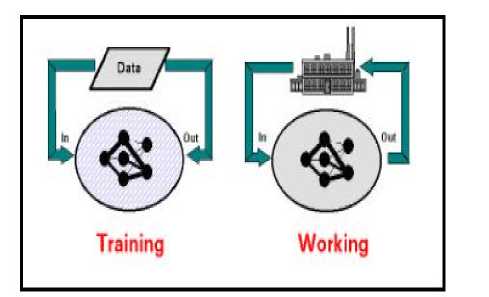
Figure 2. Training and working phase for supervised learning
A.1.1 Neuron Model
An elementary neuron with R inputs is shown figure 3. Each input is weighted with an appropriate w. The sum of the weighted inputs and the bias forms the input to the transfer function f. Neurons may use any differentiable transfer function f to generate their output.
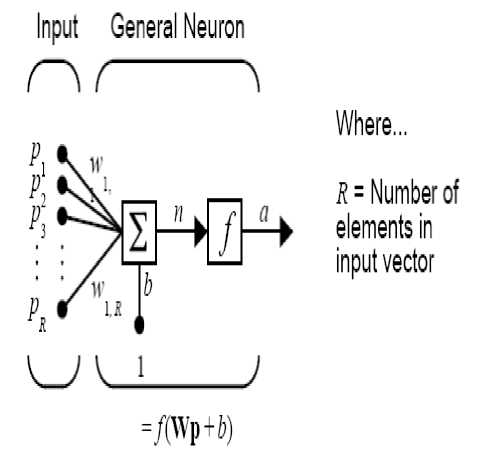
Figure 3.Structure a neuron
Feedforward networks often have one or more hidden layers of sigmoid neurons followed by an output layer of linear neurons. Multiple layers of neuronswith nonlinear transfer functions allow the network to learn nonlinear and linear relationships between input and output vectors(figure 4). The linear output layer lets the network produce values outside the range –1 to +1. On the other hand, if you want to constrain the outputs of a network (such as between 0 and 1), then the output layer should use a sigmoid transfer function (such as logsig). This network can be used as a general function approximator. It can approximate any function with a finite number of discontinuities, arbitrarily well, given sufficient neurons in the hidden layer[38].
A.1.2 Neural network step for estimating use case weight
Back-propagation feed forward neural network approach is used to predict the size of the software using USP approach. A neural network is constructed with 38 inputs and 1 output effort .
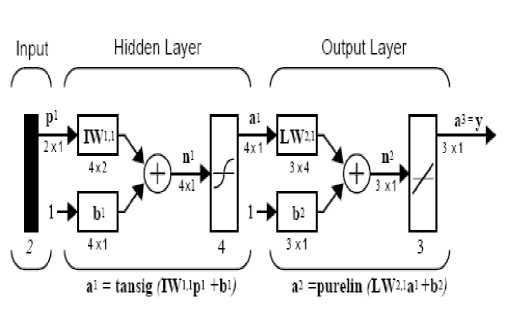
Figure 4. feed forward neural network with two layers
The input nodes represent the distinguishing parameters of use case size point approach and the output nodes represent the effort . The network is constructed by using MATLAB. In our experiment the training function we have considered is traingda, the adaptation learning function considered was learngdm, and the performance function used was Mean Square Error (MSE). The projects considered for this research are taken from the use case point ISBSG data . The input nodes represent the following features of software projects:
-
1. Number of simple actor
-
2. Number of average actor
-
3. Number of complex actor
-
4. Number of simple Precondition
-
5. Number of average Precondition
-
6. Number of complex Precondition
-
7. Number of very simple Scenario
-
8. Number of simple Scenario
-
9. Number of average Scenario
-
10. Number of complex Scenario
-
11. Number of very complex Scenario
-
12. Number of simple Exception
-
13. Number of average Exception
-
14. Number of complex Exception
-
15. Number of simple Post condition
-
16. Number of average Post condition
-
17. Number of complex Post condition
-
18. Technical cost Factor(FTA)
-
19. Environmental Factor(FAA)
-
20. Data communication - F1
-
21. Distributed processing- F2
-
22. Performance –F3
-
23. Equipment utilization - F4
-
24. Transaction Capacity - F5
-
25. On-line input of data - F6
-
26. User efficiency -F7
-
27. On-line update - F8
-
28. Code reuse - F9
-
29. Complex processing - F10
-
30. Easiness of deploy - F11
-
31. Easiness operation -F12
-
32. Many places -F13
-
33. Facility of change- F14
-
34. Formal development process existence - E1
-
35. Experience with the application being developed- E2
-
36. Experience of the team with the used technologies- E3
-
37. Presence on an experienced analyst -E4
-
38. Stable requirements -E5
A.2 Fuzzy Use Case Size Point (FUSP)
In use case size counting method, each component, such as actors is classified to a weight level determined by the numbers of its entities (step 1 of section 4), Such weight classification is easy to operate, but it may not fully reflect the true color of the software complexity under the specific software application. For example,a software project with two use cases, A with 10 entities and B with 6 entities. According to the weight matrix, A and B are classified as having the same complexity and are assigned the same weight value of 4. However, A has 4 transactions to more than B and is certainly more complex. They are now assigned the same complexity, which is recorded as Observation 1: ambiguous classification?[13]
The metric USP presents new elements for measuring the functionality of the UCs. However, it also uses a discrete classification of the functionalities complexity, like UCP and FPA[3]. The use of the classification tables does not allow a gradual change from one complexity category to another. To allow such gradual change, we extended the metric USP by adopting the same FFPA steps [39] with Learning ability of neural networks and The accuracy of the fuzzy system introduced a metric named NFUSP ( Neuro Fuzzy Use Case Size Points).
A.2.1 Fuzzy logic calibration step
The classification tables are transformed into a continuous classification, this process is called fuzzyfication (a more formal definition to fuzzyfication could be found in [40]). This can be made through the generation of a trapezoidal fuzzy number to each complexity category found on the classification tables. Then, each classification table for a UC (actors, preconditions, exceptions, etc) is represented by a graph, The graphs obtained for each USP classification table are present in Figure 5[3].
Membership functions for output actor weight are the triangular type, because these types of membership functions are appropriate to use in preserving the values in the complexity weight matrices (Figure 6).the fuzzy inference process using the Mamdani approach [41] is applied to evaluate use case component weight degree when the linguistic terms, the fuzzy sets, and the fuzzy rules are defined.
Fuzzy Logic Rules:
If Input =simple entities then weight output = simple If Input = average entities then weight output = average If input =complex entities then weight output= complex
The antecedent result as a single number implies the consequence using the min (minimum) implication method. Each rule is applied in the implication process and produces one consequence. The aggregation using the max (maximum) method is processed to combine all the consequences from all the rules and gives one fuzzy set as the output. Finally, the output fuzzy set is defuzzified to a crisp single number using the centroid calculation method.
An example of the complete fuzzy inference process is shown in Figure 10. Input values are set to entities: 10. The antecedent parts of the fuzzy rules whose degrees are not equal to zero are activated and represented by the light gray shades. Here, rules 2,3 are activated for the antecedent part inpute. Finally, the consequent fuzzy set is defuzzified, using the centroid calculation method, and the output is achieved as a single value of 4.36 the bold black line in the output fuzzy set located in the bottom right of the Figure 7.
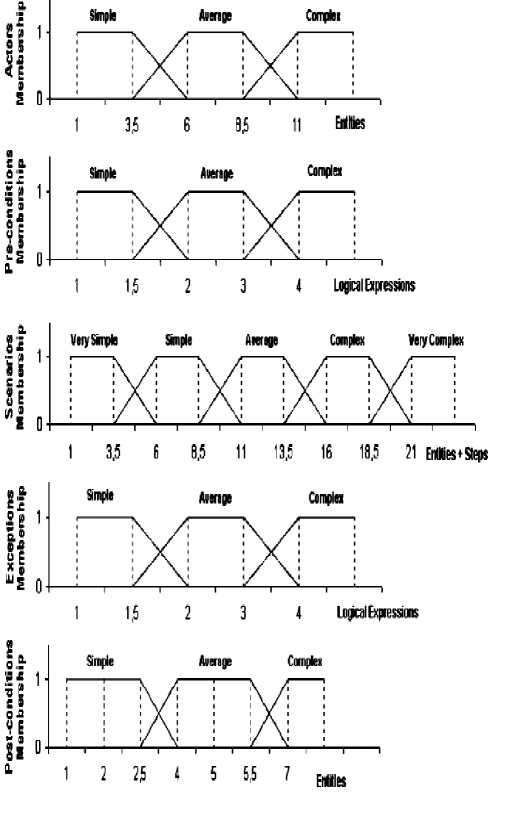
Figure 5. fuzzy graph for USP tables[3]
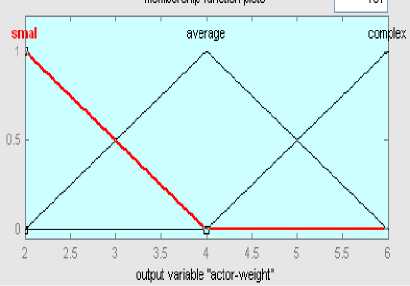
Figure 6. membership function for actor weights
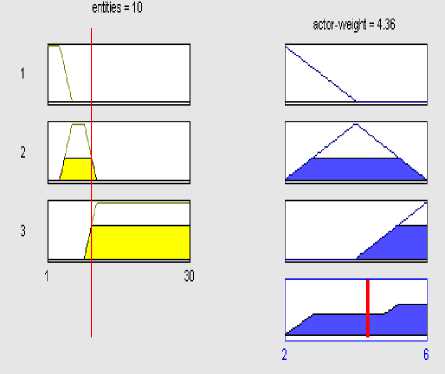
Figure 7. fuzzy inferece process of neuro-fuzzy use case size point model
Afterwards, a fuzzy complexity measurement system that takes into account all elements of use case size point in tables 4-8 is built after the fuzzy logic system for each use case size point component is established, as shown in Figure 8. Each USP element is into a Fuzzy Logic System (FLS). The outputs of all five FLS are summed up and become the neuro fuzzy Unadjusted Use Case Size Points(NFUUSP) Which is used to calculate effort(figure 8).
-
B. Sugeno model
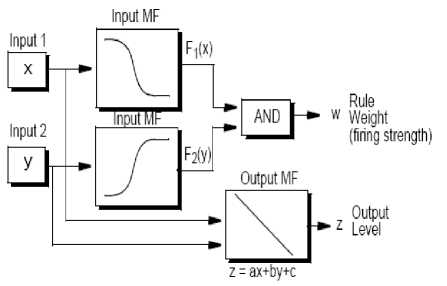
A typical rule in a Sugeno fuzzy model has the form If Input 1 = x and Input 2 = y, then Output is z = ax + by + c.
For a zero-order Sugeno model, the output level z is a constant (a=b =0).
The output level zi of each rule is weighted by the firing strength wi of the rule.For example, for an AND rule with Input 1 = x and Input 2 = y, the firing strength is wi=AndMethod (F1(x), F2(y)) ;where F1,2 (.) are the membership functions for Inputs 1 and 2. The final output of the system is the weighted average of all rule outputs, computed as:
N
.2 wizi
Final Output = i = 1 2 wj i = 1
A Sugeno rule operates as shown in the following diagram(Figure 6).ANFIS (Adaptive Neuro Fuzzy Inference System) is an architecture which is functionally equivalent to a Sugeno type fuzzy rule base (Jang, Sun & Mizutani, 1997;
Figure 6. Sugeno model
EFFORT = NFUUSP * (FTA - FAA) * PHperUSP
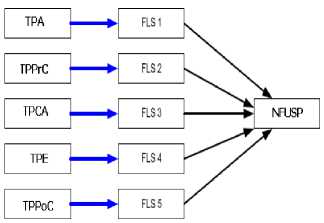
Figure 8: fuzzy inferece process of neuro-fuzzy use case size point model
B.1 Anfis
Consider the fuzzy neural network in figure 7. The output of the first layer nodes are the degree of membership of linguistic variables. Typically, in this layer bell –shaped functions are used. Bell-shaped function is shown in Relationship 6. The purpose of learning in this layer is adjusting the parameters of membership function of inputs.
f ( x ) = exp
- 1
x
-
( 2
b i1
a
1)2
The second layer is 'rules layer'. In this layer, the condition part of rules is measured by usually Min fuzzy logic operator, and the result will be the degree of activity of rule resultant. Learning, in this layer, is the change of the amount of activity of rules resultant, regarding to the 'training data', given to the network. In the third layer, we'll get the linear combination of rules resultant rate, and in order to determine the degree of belonging to a particular category, Sigmund function is used in layer 4 [44].
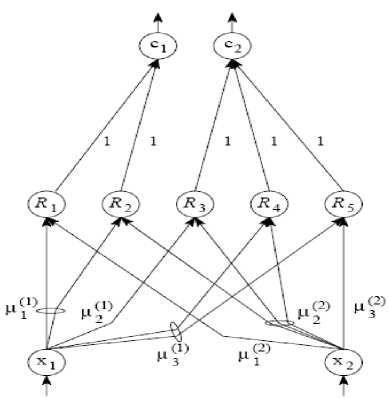
Figure 7.Adaptive neuro fuzzy Network(anfis)
If a series of training vectors is given to the network in the form of the formula 7:
{(xk, yk), k = 1,..., K}
Where xk refers to the K-th input pattern, then we have:
k if X belongs to class 1
k if belongs to class 2
The error function for K pattern can be defined by relationship 9:
Pr edicatedEffort.(9)
where y k is desired output, and Ok is computed output.
-
VI. Discussion And Conclusion
Several methods exist to compare cost estimation models. Each method has its advantages and disadvantages. In this work, The Magnitude of Relative Error (MRE) will be used. MRE for each observation i can be obtained as:
ActualEffort. - Pr edicatedEffort
MER- = ------------- i--------------------i (10)
i Pr edicatedEffort
MMRE can be achieved through the summation of MRE over N observations:
1 N
MMER = У MER
21 i
After training neural network by ISBSG data ,we have applied Our proposed neuro fuzzy system on seven samples of projects. The results are shown in the table below .
k (1,0)
y =
(0,1)
TABLE 11. EVALUATION RESULTS FROM SAMPLE PROJECTS
|
PROJECT # |
Actual effort |
effort in Use case size point |
Effort in Neuro fuzzy use case point(mamdani) |
Effort in Adaptive Neuro fuzzy use case point(sugeno) |
MER (USP) |
MER(NFUSP) |
MER(ANFUSP) |
|
1 |
2905 |
2610 |
2873 |
2880 |
0.113027 |
0.011138 |
0.008681 |
|
2 |
2200 |
2176 |
2196 |
2190 |
0.011029 |
0.001821 |
0.004566 |
|
3 |
1759 |
1591 |
1638 |
1751 |
0.105594 |
0.073871 |
0.004569 |
|
4 |
1542 |
1364 |
1538 |
1540 |
0.130499 |
0.002601 |
0.001299 |
|
5 |
1025 |
992 |
1015 |
1019 |
0.033266 |
0.009852 |
0.005888 |
|
6 |
2784 |
2600 |
2725 |
2783 |
0.070769 |
0.021651 |
0.000359 |
|
7 |
2961 |
2891 |
2927 |
2957 |
0.024213 |
0.011616 |
0.001353 |
|
MMER |
0.069771 |
0.018936 |
0.003816 |
As you can see in the table 11 Thus effort estimation with Adaptive neuro fuzzy Unadjusted Use Case Size Points(ANFUUSP) MMER is less and ANFUUSP accuracy further. For future work can be other different types of membership functions, different types of neural network and optimization algorithms like genetic algorithm considered.However, software development is a rapidly growing industry and these calibrated weight values will not reflect tomorrow’s software. The advantage of Neural Networks is it has the learning capability to adapt new data. On the other hand, Fuzzy Systems has the capability to handle numerical data and linguistic knowledge simultaneously.In the future, when modern project data is available, the USP weight values will again need to be re-calibrated to reflect the latest software industry trend. The Adaptive neuro-fuzzy USP model is a framework for calibration and the neuro-fuzzy USP calibration tool can automate the calibration process when data becomes available.
Acknowledgment
This work received support from the Department of Computer Engineering, Islamic Azad University, Sari Branch.
References Object Oriented Software Effort Estimate with Adaptive Neuro Fuzzy use Case Size Point (ANFUSP)
- Bente Anda, Hans Christian Benestad and Siw Elisabeth Hove,” A Multiple-Case Study of Software Effort Estimation based on Use Case Points”, ieee,2005
- A. Albrecht. Measuring Application Development Productivity. In Proc. of IBM Applications Development Symposium, pages 83–92, October 1979.
- Marcio Rodrigo Braz, Silvia Regina Vergilio,” Software Effort Estimation Based on Use Cases”, Proceedings of the 30th Annual International Computer Software and Applications Conference (COMPSAC'06),ieee,2006
- WANG Fan,YANG Xiaohu,ZHU Xiaochun, CHEN Lu” Extended Use Case Points Method For Software Cost Estimation”, 2009 IEEE
- K. Molokken and M. Jorgensen. A review of software surveys on software effort estimation. In Empirical Software Engineering, 2003. ISESE 2003. Proceedings. 2003 International Symposium on, pages 223–230.
- V. R. Basili and K. Freburger: \Programming measurement and estimation in the Software Engineering Laboratory", Journal of Systems & Software, 2, pp. 47-57 (1981).
- B. W. Boehm: Software Engineering Economics, Prentice-Hall(1981).
- C. E. Walston and C. P. Felix: \A method of program measurement and estimation", IBM SystemsJournal, 16(1), 54-73(1977).
- A.J. Albrecht: \Function Point Analysis", Encyclopedia of Software Engineering, Vol.1, pp. 518-524 (1994).
- G. Schneider and J. P. Winters: \Applying Use Cases, Second Edition", Addison Wesley (2001).
- S. Ajitha, T.V Suresh Kumar, Evangelin Geeth, K. Rajani Kanth,” Neural Network Model For Software Size Estimation Using Use Case Point Approach”, 5th International Conference on Industrial and Information Systems, ICIIS 2010, Jul 29 - Aug 01, 2010, India
- A. Idri, T.A. Khosgoftaar, A. Abran, Can neural networks be easily interpreted in software cost estimation? in: Proceedings of the IEEE International Conference on Fuzzy Systems (2002) 1162–1167
- Wei Xia , Luiz Fernando Capretz , Danny Ho , Faheem Ahmed ,” A new calibration for Function Point complexity weights”, Information and Software Technology 50 (2008) 670–683
- Karner, G. Resource Estimation for Objectory Projects. Objective Systems SF AB. 17.September, 1993.
- Symons, P.R. Software Sizing and Estimating MK II FPA (Function Point Analysis). John Wiley & Sons, 1991.
- Lokan., C. and Abran, A. Multiple Viewpoints in Functional size Measurement. Proc. of the
- International Workshop on Software measurement (IWSM’99), Lac Supérieur, Canada, September 8- 10, 1999.Anda, B. Comparing Use Case based Estimates with Expert Estimates. Proc. of Empirical Assessment in Software Engineering (EASE), Keele, United Kingdom, April 8-10, 2002.
- Anda, B., Dreiem, H., Sjøberg, D.I.K., and Jørgensen, M. Estimating Software Development Effort Based on Use Cases – Experiences from Industry. The 4th International Conference on the
- Unified Modeling Language, Concepts, and Tools (UML), Canada, October 1-5, LNCS 2185,Springer-Verlag. Arnold, P. and Pedross, P. Software Size Measurement and Productivity Rating in a Large- Scale Software Development Department. The 20th International Conference on Software Engineering (ICSE), Kyoto, Japan,, April 19-25, 1998, pp. 490-493.
- Albrecht, A.J. Measuring Application Development Productivity. In Proceedings of the IBM Applic. Dev. Joint SHARE/GUIDE Symposium, Monterey, CA, USA, pp. 83-92, 1979.
- Ribu, K. Estimating Object-Oriented Software Projects with Use Cases. MSc thesis, November2001
- Alice E. Smith, Anthony K. Mason, Cost Estimation Predictive Modeling: Regression versus Neural Network
- B. Tirimula Rao, B. Sameet, G. Kiran Swathi, K. Vikram Gupta, Ch. RaviTeja, S.Sumana A Novel Neural Network Approach for Software Cost Estimation Using Functional Link Artificial Neural Network (FLANN) IJCSNS International Journal of Computer Science and Network Security, VOL.9 No.6, June 2009
- K.K. Aggarwal, Yogesh Singh, Pravin Chandra, Manimala Puri, Evaluation of various training algorithms in a neural network model for software engineering applications. ACM SIGSOFT Software Engineering Notes Page 1 July 2005 Volume 30 Number 4.
- Man-Yi Chen, Ding-Fang Chen, “Early cost estimation of strip-steel coiler using BP neural network”, Proceedings of the first international conference on machine learning and cybernetic, Beijing 4-5 Nov.2002.
- G. Schneider and J. P. Winters: “Applying Use Cases, SecondEdition”, Addison Wesley (2001).
- Kirsten Ribu, Estimating object-oriented software projects with use cases
- Linda M.Laird, M.Carol Brennan,” Software Measurement and Estimation:” a prctical approach
- S. Kusumoto, F. Matukawa, K Inoue, S. Hanabusa and Y.Maegawa , “Estimating effort by Use Case Points: method, tooland case study”, Proceedings of the 10th International Symposium on Software Metrics. 2004.
- A. D. Belchior, O. S. L. Junior, and P. Farias. Fuzzy modeling for function points analysis. Software Quality Journal, 11(2):149–166, June 2003.
- M. Braz and S. Vergilio. Using fuzzy theory for effort estimation of object-oriented software. In 16th IEEE International Conference on Tools with Artificial Intelligence, 2004. ICTAI 2004, pages 196–201, 2004.
- J. Ryder. Fuzzy modeling of software effort prediction. In IEEE Information Technology Conference, 1998, pages 53–56.
- O. J´unior, P. Farias, and A. Belchior. A Fuzzy Model for Function Point Analysis to Development and Enhancement Project Assessments. CLEI Electronic Journal, 5:2, 1999.
- S.Mitra,Y.Hayashi. Neuro-fuzzy rule generation: Survey in soft computing framework. IEEE Transactions on Neural Networks,2000, 11(3), 748–768.
- H.R.Berenji, P.Khedkar, P.” Learning and tuning fuzzy logic controllers through reinforcements”. IEEE Transactions on Neural Networks, 1992, 3, 724–40.
- O.Cordon,F.Gomide,F.Herrera,F.Hofmann,L.Magdal na.“Ten years of genetic fuzzy systems: Current framework and new trends”.2004, Fuzzy Sets and Systems, 141, 5–31.
- Schneider, G. and Winters Jason P. Applying Use Cases – A practical guide. 2nd ed. Addison-Wesley, 2001.
- Howard Demuth,Mark Beale,” Neural Network Toolbox User’s Guide”,1992 - 2000
- A. D. Belchior, O. S. L. Junior, and P. Farias. Fuzzy modeling for function points analysis. Software Quality Journal, 11(2):149–166, June 2003.
- G. Klir and T. Folger. Fuzzy Sets, Uncertainty and Information. Prentice-Hall, 1998.
- E.H. Mamdani, Application of fuzzy logic to approximate reasoning using linguistic synthesis, IEEE Transactions on Computers 26 (12) (1977) 1182–1191.
- Mohagheghi, P., Anda, B. and Conradi, C. “Effort Estimation of Use Cases for Incremental Large-Scale Software “International Conference on Software Engineering (ICSE), St Louis, Missouri, USA, May 15-12, 2005, pp. 303-311.
- N.N.,"Fuzzy Logic Benchmarks for MCUs"http://www.fuzzytech.com/e_ftedbe.htm (1998).
- Ashish Ghosh, B. Uma Shankar, Saroj K. Meher ,“A novel approach to neuro-fuzzy classification”,Neural Networks, Volume 22, Issue 1, January 2009, Pages 100-109
- R. S. Pressman. Software Engineering. McGraw-Hill, fifth edition, 2002.
- G. Banerjee. Use Case Points - An Estimation Approach.Available from http://undergraduate. cs.uwa.edu.au/units/670.300/readings/usecasepoints.pdf, April,2004, August 2001.
