Обнаружение неисправностей механического оборудования с использованием методов интеллектуального анализа данных

Автор: М. А. Ковито
Журнал: Informatics. Economics. Management - Информатика. Экономика. Управление.
Рубрика: Информатика, вычислительная техника
Статья в выпуске: 1 (2), 2022 года.
Бесплатный доступ
Дефектация механического оборудования на производственных предприятиях всегда была важным звеном в производственном процессе. Наряду с компьютерной техникой, технологии искусственного интеллекта и различные интеллектуальные датчики широко используются в обрабатывающей промышленности. Объем данных, производимых производственными машинами и оборудованием на всех этапах производственного процесса, также быстро растет, особенно важно анализировать данные, генерируемые этими устройствами для обнаружения и даже прогнозирования неисправностей. Технология интеллектуального анализа данных предоставляет расширенные методы анализа данных для этой цели. В статье представлены основные концепции интеллектуального анализа данных, его процессов и ключевой технологии интеллектуального анализа данных, а также даны рекомендации по применению интеллектуального анализа данных для обнаружения неисправностей оборудования.
Метод, интеллектуальный анализ данных, механическое оборудование, датчик, система, неисправность
Короткий адрес: https://sciup.org/14124347
IDR: 14124347 | УДК: 004.896 | DOI: 10.47813/2782-5280-2022-1-2-0121-0133
Текст статьи Обнаружение неисправностей механического оборудования с использованием методов интеллектуального анализа данных
DOI:
С внедрением интеллектуального производства, промышленность во всех странах мира быстро развивается [1], и сегодня широко используется новое интеллектуальное, автоматическое, сетевое и цифровое производственное оборудование. Эксплуатация этого оборудования сопровождается накапливанием больших объёмов данных [2]. В них содержится много потенциально ценной информации. Быстрое и эффективное получение данных из имеющегося объёма и обеспечение своевременного обнаружения неисправностей оборудования является неотложной задачей в современных реалиях. В то время как традиционный метод ручной обработки данных явно не в состоянии удовлетворить потребности, технология интеллектуального анализа данных позволяет успешно решить поставленную задачу. В рамках этой технологии анализируются данные, генерируемые производственным оборудованием, извлекаются содержащиеся в нем законы [3], и анализируется рабочее состояние производственного оборудования, основанное на этих законах, для достижения цели экономии затрат, повышения эффективности и снижения энергопотребления производства [4]. В представленной статье осуществлена попытка собрать воедино методы, использование которых возможно в рамках реализации технологии интеллектуального анализа данных в применении к различным производственным сферам.
АНАЛИЗ ДАННЫХ И ЕГО ОСНОВНЫЕ АЛГОРИТМЫ
Интеллектуальный анализ данных – это извлечение некоторых данных из большой базы для выявления неявных, ранее неизвестных, реально существующих, новых и потенциальных закономерностей. Кроме того, в некоторых источниках интеллектуальный анализ данных называется открытием новых знаний, углублением знаний о тех или иных процессах и т. д. [5].
Первое упоминание понятия Data Mining (Анализ Данных) было в 1989 году, и было связано с автоматизацией и оптимизацией запросов при работе с крупными базами данных. В свою очередь, понятие анализ данных (англ. Data Analysis) использовалось гораздо раньше и означало обработку и интерпретацию данных, собранных в результате экспериментов, преимущественно научного характера. С течением времени эти понятия расширялись и обобщались, стали очень близки друг к другу и в настоящий момент тесно связаны как с анализом больших объёмов данных (англ. Big Data), так и с понятием машинного обучения (англ. Machine Learning). Интеллектуальный анализ данных – это во многом прикладная теория, число приложений которой к реальным промышленным задачам растёт с каждым годом. В настоящее время методы и средства интеллектуального анализа данных используются при веб-разработке, в биоинформатике, в системах компьютерного зрения, в разработке компьютерных игр, в маркетинге, в медицинской диагностике, в методах оптимизации, при разработке поисковых систем, при распознавании образов, изображений, речи и сигналов и т.д. Востребованность специалистов по интеллектуальному анализу данных постоянно возрастает, как и доля финансирования разработок в этой области. Появляется всё больше программных решений для анализа данных, в том числе с открытым исходным кодом.
Понятие объекта интеллектуального анализа данных в общем виде является достаточно широким. Это преимущественно реляционная база данных, кроме того это может быть неструктурированное хранилище данных, например текстовая масса (текстовые неструктурированные или полу структурированные данные), мультимедийные данные (включая изображения, аудио, видео данные), интернет данные и сложные типы данных (в основном включают распределённую базу данных и базу данных временной последовательности) и т. д. Задача интеллектуального анализа данных состоит в том, чтобы выделить шаблоны из наборов данных.
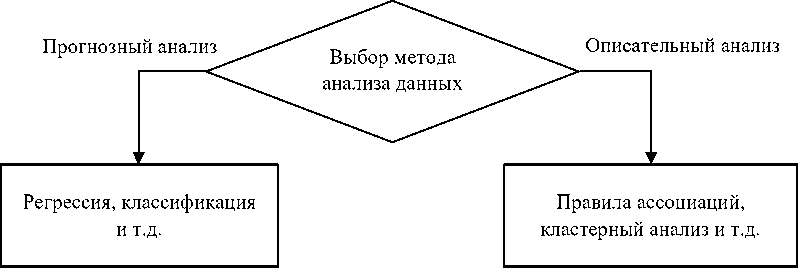
По функциональным закономерностям анализ данных в основном делится на описательный анализ и прогнозный анализ.
Акцент описательного анализа заключается в том, чтобы находить явные закономерности для описания данных и описывать их общие характеристики.
Предиктивный анализ основан на текущих и прошлых данных, с упором на создание прогнозирующих моделей.
В настоящее время основные задачи интеллектуального анализа данных обычно делятся на описание данных, оценка с помощью модели, предсказание, кластерный и корреляционный анализ в соответствии с практическими задачами. Описание данных представляет собой исследовательский анализ данных (Exploratory Data Analysis, EDA), который дополняет имеющуюся на текущий момент информацию [6]. Оценка с помощью модели заключается в том, чтобы построить модель исследуемого объекта, процесса или явления и оценить разницу между целевыми значениями исследуемых показателей и значениями, предсказанными с помощью модели на основе исходного набора данных. Обычно используется простая линейная регрессия или корреляция, нейронная сеть также может быть использована для оценки модели [7-9].
Классификация аналогична оценки модели, за исключением того, что целевым значением классификации является категория, а не число. Основные методы включают в себя дерево решений, нейронную сеть, логистическую регрессию, байесовскую сеть и др. [10-13].
Прогнозирование похоже на классификацию и оценку модели, но прогнозирование в основном нацелено на оценку ситуации в будущем.
Все данные в исследуемой базе, разделены на несколько классов, объекты одного и того же класса имеют максимальное сходство, различных классов, обладают минимальным сходством. Наиболее распространенные признаки, используемые для измерения сходства объектов – это расстояние между ними, плотность и т. д., обычно используют метод кластеризации с помощью k-ближайших соседей (KNN, англ. k Nearest Neighbor), сбалансированного итеративного сокращения и кластеризации с помощью иерархий (BIRCH, англ. balanced iterative reducing and clustering using hierarchies) [14] и т. д.
Ассоциативный анализ заключается в обнаружении корреляции между данными и определении того, какими свойствами они обладают. Как правило, степень поддержки и достоверности используются для измерения корреляции правил ассоциации. Распространенными алгоритмами поиска ассоциаций являются алгоритм «Априори» (англ. Apriori) и алгоритм индукции по обобщенным правилам [15-16].
КЛЮЧЕВАЯ ТЕХНОЛОГИЯ АНАЛИЗА ДАННЫХ
Интеллектуальный анализ данных состоит из трех этапов: предварительная обработка данных, интеллектуальный анализ и оценка и представление результатов анализа. На рисунке 1 показан весь процесс интеллектуального анализа данных.
Предварительная обработка данных
Предварительная обработка данных является очень важной частью всего процесса интеллектуального анализа данных. Когда мы интегрируем данные из различных источников, данные часто бывают неполными и содержат множество шумов и избыточности.
Качество данных напрямую влияет на надежность модели интеллектуального анализа данных и правильность принятого итогового решения. Для точности результатов интеллектуального анализа данных, данные необходимо предварительно обработать, что в основном включает три этапа: очистки данных, преобразования данных и уменьшение размерности данных.
Очистка данных
Содержание очистки данных в основном включает в себя обработку отсутствующих данных, выявление ошибочной классификации и выявление выбросов. Для набора данных, содержащего большое количество данных, потеря информации довольно распространена. Хотя данные с отсутствующей информацией могут быть обработаны быстрее, простой пропуск или отбрасывание может привести к отклонению и потере данных. Поэтому некоторые, вместо этого, используют константы или оценки, основанные на других функциях. Поиск и исправление ошибочной классификации также может повысить точность результатов. Выбросы — это экстремальные значения отклонение от других показателей тенденции. На некоторые методы интеллектуального анализа данных выбросы влияют сильно, что может привести к ошибкам в результатах. Поэтому очень важно выявить выбросы.
Преобразование данных
Диапазон различных значений часто сильно различается. Для некоторых алгоритмов анализа такая разница в диапазонах приводит к тому, что величина с большим диапазоном будет отрицательно влиять на результат. Поэтому нормализация данных является необходимой в процессе интеллектуального анализа данных.
Уменьшение размерности данных
Наборы данных, используемые при интеллектуальном анализе, могут содержать миллионы фрагментов данных и тысячи переменных, не все из которых независимы и не связаны друг с другом. В процессе интеллектуального анализа данных необходимо предотвратить корреляцию между прогностическими переменными, влияющими на стабильность результатов. Метод главных компонент (англ. Principle component analysis, PCA) [17] — это метод статистического анализа, который выбирает небольшой набор важных переменных для описания соответствующей структуры посредством линейной комбинации нескольких переменных. Метод главных компонент используется только для прогнозируемых переменных, а не для целевых переменных.
Анализ данных
Интеллектуальный анализ данных является наиболее важным звеном во всем процессе интеллектуального анализа данных, который обычно включает четыре аспекта:
-
• выбор и применение соответствующей технологии интеллектуального анализа данных;
-
• калибровка настроек модели для оптимизации результата;
-
• применение различных технологий;
-
• на четвертом этапе получаем выбранный алгоритм анализа в соответствии с целями интеллектуального анализа данных и сформированную в результате анализа данных структуру модели.
Оценка и представление результатов
Оценка модели требует всестороннего обзора процесса интеллектуального анализа данных, чтобы определить, какими факторами или задачами в данном конкретном случае можно пренебречь. Представление модели — это визуализация модели, которая позволяет представить её в дружественном, доступном для пользователей виде. Этот этап также важен для предоставления целевому пользователю легкого для понимания, визуального шаблонна модели.
Анализ данных
Сбор данных, подготовка данных
Обработка данных: очистка данных, преобразование данных, уменьшение размерности данных и т.д.
Оценка и представление результатов
Рисунок 1. Блок-схема обработки данных.
ПРИМЕНЕНИЕ ИНТЕЛЛЕКТУАЛЬНОГО АНАЛИЗА ДАННЫХ ДЛЯ ДЕФЕКТАЦИИ МЕХАНИЧЕСКОГО ОБОРУДОВАНИЯ
Обнаружение неисправностей механического оборудования поможет контролировать, диагностировать и прогнозировать состояние этого оборудования. Это обеспечит, в свою очередь, непрерывную и безопасную работу, что имеет большое значение для обеспечения эффективности производства и эксплуатации.
Например, механизмы больших туннельных буровых машин, эксплуатируемые в сложных условиях, склонны к сбоям, и их гидравлическая система является одной из основных причин отказа работы всего механизма. Факторы, влияющие на этот процесс, достаточно разнообразны. Оператору сложно точно выяснить причину и определить способы эффективного устранения неисправности. Из-за сложности гидравлической системы проходческого комбайна метод традиционного ручного диагностирования не способен удовлетворить требования эффективной эксплуатации оборудования, поэтому в данной ситуации должен быть применён метод интеллектуального анализа. В литературе [18] предлагается метод диагностики отказов, сочетающий нечеткую теорию с нейронной сетью для неисправности гидравлической системы проходческого комбайна. А VC++ и Matlab применяются как инструменты реализации ПО для диагностики неисправностей. В литературе [29] описан контроль состояния моторного оборудования на основе показаний данных с 6 датчиков. Эти показания анализируются и строятся правила диагностики неисправностей, чтобы система могла отслеживать свое техническое состояние в реальном времени. В одном из источников [20] говорится, что различные факторы неисправности имеют различное влияние на процесс диагностики, в этой статей предлагается алгоритм матрицы взвешенных ассоциативных правил, использующий веса коэффициентов неисправности для повышения точности диагностики неисправности. За счет увеличения плотности ряда коэффициента уменьшается масштаб генерации наборов элементов-кандидатов, тем самым повышая эффективность диагноза устранения неисправностей. В литературе [21] предложен метод FDC (Fault Detection and Classification – Обнаружение и классификация неисправностей). Во-первых, главный компонентный анализ использовался для сортировки обучающих данных и создания модульной нейронной сети для идентификации неисправности. Теория D-S используется для классификации отказов в случае неопределенности (например, множественных отказов). Метод FDC на основе модульной нейронной сети и теории D-S имеет возможность быстро идентифицировать аномалию и локализовать главный компонент аномалии, когда та появляется, так что соответствующий персонал может быстро найти неисправный компонент и принять соответствующие меры по его исправлению. В литературе [22] предложен усовершенствованный алгоритм построения дерева решений на основе набора переменных значений, который улучшил точность классификации и способность подавления шумовых данных, и был применён к оборудованию угольного завода, и показал хороший результат. Описанная в документе [23] система мониторинга состояния вращающегося оборудования, разработана на основе данных крупных вращающихся элементов, в сочетании с алгоритмом Apriori и использованием структуры B\S, показала хорошие результаты в практическом производстве и применении. В литературе [24] автор предложил визуализацию распределения матрицы распространенности и ковариации Римана для обнаружения аномалий механического оборудования, а также применил его для обнаружения неисправностей коробки передач ветряной турбины и получил неплохие результаты. В литературе [25] предложен алгоритм оптимизации роя частиц черных дыр (BPS-SA) по методу наименьших квадратов, метод опорных векторов в сочетании с алгоритмом имитации отжига, благодаря которому была улучшена скорость классификации, точность и уменьшены проблемы с экстремальными значениями.
В таблице 1 показано применение некоторых методов интеллектуального анализа данных для обнаружения неисправностей механического оборудования.
Таблица 1. Применение технологий интеллектуального анализа данных для обнаружения неисправностей механического оборудования.
Тип механического оборудования Технология анализа данных
Гидравлическая система проходческого комбайна [18]
Моторное оборудование [19] Гидравлическое оборудование для сталелитейного завода [20]
Полупроводниковое оборудование [21] Машины и оборудование для угольных складов [22]
Большое вращающееся оборудование [23]
Турбинный редуктор [24]
Редуктор вентилятора [25]
Нечеткое множество и нейронная сеть BP
Грубое множество
Матричные взвешенные правила ассоциации
Модульная нейронная сеть и метод D-S Грубые множества и деревья решений
Априорный алгоритм
Матрица распространенности и ковариации распределение Римана
SVM и алгоритм имитации отжига
Из таблицы видно, что в настоящее время технология интеллектуального анализа данных применяется к многим аспектам обнаружения неисправностей механического оборудования. В то же время при практическом применении, как правило, необходимо сочетание различных технологий интеллектуального анализа данных для достижения ожидаемого эффекта, и должны быть внесены целенаправленные улучшения в исходную технологию интеллектуального анализа данных.
ОБСУЖДЕНИЕ: ТЕНДЕНЦИИ И ТРУДНОСТИ
На конференции KDD 2019 г. [26] была предложена мобильная система прогнозирования событий, которая объединяет пространственно-временные данные. Эта структура обладает хорошей способностью к обобщению и может быть легко перенесена в другие области. При обнаружении механических неисправностей, если неисправность можно предсказать заранее, это значительно сократит потери предприятий.
Google [27] объединяет особенности имеющихся данных, чтобы сделать прогнозы парковки более эффективными. Использование различных данных, сочетание разных пользователей и разных сезонов в полной мере делает прогноз парковки на карте Google более продуктивным. В будущем, вероятно, можно будет более эффективно обнаруживать и прогнозировать неисправности механического оборудования путем объединения личной информации пользователей оборудования и других климатических и погодных факторов.
Тем не менее, применение технологии интеллектуального анализа данных для обнаружения неисправностей механического оборудования по-прежнему сталкивается со многими проблемами. С точки зрения технологии, результаты исследования, включенные в эту статью, в основном относятся к экспериментальным стадиям, а данные, использованные в экспериментах, в основном представляют собой высококачественные данные, проверенные и проанализированные вручную. Однако в реальной производственной среде возникает множество проблем с качеством данных. Кроме того, большое количество исследований проводится на основе уже имеющихся данных. Анализ готовых данных может привести к выработке довольно точных правил эксплуатации оборудования, но объем данных должен постоянно накапливаться и дополняться, что требует получения данных в реальном времени для отражения последних изменений состояния оборудования, а это задача достаточно нетривиальная. В то же время многие факторы, такие как универсальность, гибкость и надежность модели, а также реальная производительность алгоритма следует учитывать, когда описанная выше модель и алгоритм используются в реальной ситуации.
ЗАКЛЮЧЕНИЕ
Таким образом, в статье дан обзор соответствующих технологий и теорий в процессе интеллектуального анализа данных, изложено применение интеллектуального анализа данных при обнаружении неисправностей механического оборудования, и указано на его недостатки и тенденции развития. Одним словом, с быстрым развитием всех сфер жизни увеличивается объём данных, и интеллектуальный анализ данных, естественно, становится мощным инструментом для поддержки принятия решений. Очевидно, что современная промышленность уже не может обходиться без использования интеллектуального анализа данных.
