Оценка эффективности ансамбля нейросетей для маскирования облачности по данным спектрорадиометра AHI космического аппарата Himawari-8/9

Автор: Андреев А.И., Мальковский С.И., Кучма М.О., Шамилова Ю.А.
Журнал: Компьютерная оптика @computer-optics
Рубрика: Обработка изображений, распознавание образов
Статья в выпуске: 3 т.49, 2025 года.
Бесплатный доступ
В работе исследуется метод расчета маски облачности, основанный на использовании нескольких сверточных нейросетевых классификаторов с применением метода бутстрэпинга. Разработанный на его основе алгоритм позволяет обнаруживать облачность на спутниковых изображениях спектрорадиометра Advanced Himawari Imager, установленного на геостационарные космические аппараты Himawari-8 и 9, независимо от условий наблюдения и освещения на территории Азиатско-Тихоокеанского региона. Точность полученных результатов оценена с использованием маски облачности, предоставляемой Национальным управлением океанических и атмосферных исследований США, NOAA. Численная оценка и визуальный анализ показали достаточно высокую точность разработанного алгоритма, в том числе в сравнении с ранее представленной авторами версией классификатора. Среднее значение f1-меры в сравнении с масками NOAA составляет от 75% в сумеречное время суток до 85% в дневное время, что позволяет использовать предложенный алгоритм для расчета различной тематической продукции гидрометеорологического назначения.
AHI, Himawari, облачность, маска, нейронная сеть, бутстрэпинг, ансамбль классификаторов
Короткий адрес: https://sciup.org/140310487
IDR: 140310487 | DOI: 10.18287/2412-6179-CO-1525
An ensemble method for cloud mask calculation based on data from the AHI instrument onboard the Himawari-8/9 satellite using convolutional neural networks
The paper explores a method for calculating a cloud mask based on the use of several convolutional neural network classifiers trained for various observation conditions using a bootstrapping method. An algorithm developed on the basis of this method makes it possible to detect clouds in images obtained from the Advanced Himawari Imager (AHI) instrument onboard the Himawari-8/9 satellite, regardless of the Sun illumination conditions of the territory of the Asia-Pacific region under surveillance in the warm and cold seasons. The accuracy of the obtained results is assessed using a cloud mask provided by the US National Oceanic and Atmospheric Administration, NOAA. Numerical assessment and visual analysis show high accuracy of the developed algorithm, which is higher than the earlier classifier version offered by the present authors. When compared with the NOAA masks, the average F1-measure ranges from 75% at twilight to 85% during the daytime.
Текст научной статьи Оценка эффективности ансамбля нейросетей для маскирования облачности по данным спектрорадиометра AHI космического аппарата Himawari-8/9
Обнаружение облачности на изображениях метеорологических спутников является одной из ключевых задач дистанционного зондирования Земли, так как оно лежит в основе практически любого алгоритма расчета тематической продукции. Увеличение числа специализированных спутников и развитие методов и технологий обработки данных, основанных на возможностях современных гибридных вычислительных систем, открывают возможности по реализации эффективных решений этой важной и актуальной задачи.
Для оперативного мониторинга облачности и параметров атмосферы широко применяются геостационарные космические аппараты (КА), преимуществом которых является высокая частота получения информации для одной и той же территории (от 2 до 30 минут). Это, в свою очередь, позволяет использовать их для мониторинга осадков, наукастинга, определения векторов ветра и решения многих других задач гидрометеорологического обеспечения [1]. Одна- ко для решения этих задач требуется максимально точная маска облачности, в связи с чем продолжают непрерывно совершенствоваться алгоритмы для ее расчета. При этом сама облачность достаточно разнообразна и отражает огромное количество процессов, происходящих на поверхности Земли и в атмосфере, а разнообразие климатических условий существенно затрудняет решение задачи обнаружения облачности [2, 3]. Исследованию вопроса повышения качества маски посвящена настоящая работа.
В работе рассматривается усовершенствованный метод расчета бинарной маски для оптически плотной облачности всех ярусов по данным спектрора-диометра Advanced Himawari Imager (AHI) применительно к территории Азиатско-Тихоокеанского региона. В северной части рассматриваемого региона (в частности на юге Дальнего Востока России) сеть наземных метеорологических наблюдений распределена крайне неравномерно, поэтому результаты проведенных исследований и разработок имеют высокую практическую ценность и существенно дополняют и уточняют имеющуюся информацию об облачности, тем самым повышая качество предоставляемой гидрометеорологической продукции.
1. Современные подходы к обнаружению облачности
С момента появления первых метеорологических космических аппаратов и по настоящее время предложено большое количество методов и алгоритмов обнаружения облачности на спутниковых изображениях. Применительно к данным видимого и инфракрасного (ИК) спектра малого пространственного разрешения геостационарных КА наибольшее распространение получили методы на основе пороговых решающих правил и машинном обучении, использующие спектральные, текстурные и временные характеристики [3].
Пороговые методы представляют собой классический, основанный на физических принципах подход к обнаружению облачности, в котором явным образом задаются решающие правила на основе известных спектральных свойств облачности и подстилающей поверхности. Их преимуществом является относительная простота разработки алгоритмов и анализа получаемых результатов. Однако точность обнаружения облачности в сложных климатических условиях с большим территориальным охватом у таких методов остается невысокой, особенно в присутствии снега или льда [2, 3]. Чтобы повысить качество маски, современные методы используют адаптивные пороговые значения [4, 5], зависящие от локальных параметров для конкретных территорий, условий освещенности и климатических особенностей. Высоких результатов удается достичь за счет применения быстрых радиационных моделей переноса излучения для получения эталонных значений в спектральных каналах с целью сравнения с фактическими измерениями [6, 7]. Временной анализ изображений также позволяет повысить точность обнаружения облачности, например, путем сравнения с предыдущими сроками наблюдений [3, 8] или предварительно полученными безоблачными композитными картами [2]. Однако в этом случае подразумевается либо наличие готовой маски облачности достаточно высокого качества для предыдущих сроков наблюдений, либо как минимум однократное отсутствие облаков в каждом пикселе изображения [2, 9] с учетом незначительных изменений подстилающей поверхности, что гарантируется далеко не всегда. В целом можно отметить, что пороговые методы жестко ограничены заданными вручную решающими правилами и не в полной мере учитывают множество второстепенных факторов, играющих роль при обнаружении облачности в глобальных условиях наблюдений.
В то же время использование машинного обучения позволяет задействовать больше информации из спутниковых изображений, поскольку решающие правила здесь определяются автоматически на основе самих данных. Однако их существенным недостатком является проблема «черного ящика», когда затруднительно установить причину, по которой обученная модель приняла то или иное решение. Кроме того, таким моделям необходима высококачественная репрезентативная обучающая выборка большого объема. Отметим, что такие алгоритмы машинного обучения, как сверточные нейронные сети, способны учитывать текстурные характеристики рассматриваемых объектов и окружающий контекст (например, наличие тени от облака или горный рисунок [10, 11]), что делает их более приближенными к человеческому восприятию информации и повышает эффективность обнаружения облачности.
Алгоритмы машинного обучения имеют статистическую природу и в значительной степени зависят от качества обучающих данных [2, 3]. Нередко в обучающей выборке могут присутствовать противоречивые или неоднозначные примеры, шум, а также субъективная информация [12]. Кроме того, на эти ошибки может накладываться несовершенство самой модели классификатора, ее ограничения и эффект от возможного переобучения. Одним из вариантов решения этих проблем является использование ансамблевых методов, например, на основе деревьев решений [13, 14], для расчета маски облачности. Такие методы основаны на использовании большого количества слабых классификаторов с низкой точностью, путем усреднения результатов которых удается достичь более высокой точности [15, 16]. Чаще всего при создании ансамблей в качестве базового классификатора используются деревья решений [17] ввиду их невысокой вычислительной сложности. Развитие вычислительной техники в последние годы позволило применить более сложные модели классификации в составе ансамблей, такие как сверточные нейронные сети [18]. Последние являются одними из наиболее эффективных решений задачи обнаружения облачности [3]. Например, в работе [19] показано, что сверточная сеть имеет более высокую точность классификации в сравнении с ансамблевым методом на основе деревьев решений «Random Forest». Таким образом, перспективным является решение, предусматривающее совместное использование сверточных сетей и ансамблевого подхода к построению моделей классификации [20, 21].
Среди методов создания ансамблей можно выделить два основных направления: бутстрэпинг (бэггинг) и градиентный бустинг [17]. Многими авторами отмечается, что метод бустинга демонстрирует наибольший прирост точности в сравнении с бутстрэпингом [22, 23]. С другой стороны, принцип построения ансамбля на основе бустинга таков, что модели в нем зависят от результатов классификации друг друга, что несколько затрудняет возможность распараллеливания и, как следствие, может привести к увеличению времени классификации.
Преследуя цель оперативного расчета маски, авторами исследуется метод, позволяющий улучшить ее точность в различных условиях наблюдений и освещенности. Предлагаемый алгоритм использует преимущества ансамблевого подхода на основе бут-стрэпинга и сверточных нейросетевых классификаторов. При этом внимание уделено также вопросу скорости расчета маски.
2. Используемые данные
Для разработки, валидации и тестирования алгоритма использовались следующие источники данных.
2.1. Измерения спектрорадиометра AHI
2.2. Обучающая выборка
2.3. Эталонные маски облачности спектрорадиометра AHI
3. Алгоритм классификации
Предлагаемый в настоящей работе алгоритм в качестве входного источника информации использует данные спектрорадиометра AHI, установленного на борту КА Himawari-8 и 9. Данный прибор предоставляет с периодичностью 10 минут изображения облачности и подстилающей поверхности в 16 спектральных каналах с пространственным разрешением от 500 м до 2 км. В работе используются измерения, представленные в виде значений яркостных температур для ИК-каналов 3,85 – 12,4 мкм и коэффициентов спектральной яркости (КСЯ) на верхней границе атмосферы в диапазоне 0,65 – 1,61 мкм. Все спектральные изображения приведены к единому пространственному разрешению 2 км методом кубической интерполяции. Для КСЯ предварительно произведена коррекция по зенитному углу Солнца с использованием соотношения R CORR = R / cos(Q SZA ) , где R CORR – скорректированное значение, R – КСЯ, Q SZA – зенитный угол Солнца.
Для обучения нейросетевых классификаторов был сформирован набор данных, состоящий из текстур. Текстуры представляют собой небольшие участки изображений размером 5×5 пикселей, на которых представлены различные формы облачности и подстилающей поверхности, в том числе снега, песка, воды, переувлажненной почвы, гор, лесов и др. Каждая текстура промаркирована вручную опытными специалистами-дешифровщиками спутниковой информации в зависимости от того, что изображено в ее центре (облако или его отсутствие). Процесс маркировки осуществлялся для спутниковых изображений с помощью специально разработанного программного обеспечения путем присвоения метки класса отдельным пикселям, вокруг которых впоследствии формировались текстуры. Подробнее он описан в работе [24]. При ручном анализе изображений использовались цветосинтезированные RGB-изображения с каналами спектрорадиометра AHI. Для светлого времени суток применялся синтез R= 1,61, G=0,86 и B = 0,65 мкм, а для неосвещенных Солнцем участков – R=3,85, G= 11,20 и B= 12,35 мкм.
Текстуры являются многоканальными изображениями, где каждый канал представлен тем или иным классификационным признаком. В качестве таких признаков использовались спектральные каналы, вычисленные на их основе спектральные индексы, разности значений в этих каналах, географические координаты каждого пикселя текстуры, маска суши, а также значение зенитного угла наблюдения Q SAT . Данный набор признаков был сформирован исходя из анализа работ многих авторов (см. табл. 1), в которых они использовались для решения задачи обнаружения облачности в различных территориальноклиматических условиях. Отметим, что каждый признак был нормирован в диапазоне [0, 1] по всей выборке. Примеры текстур и способ их формирования более подробно описаны в работах [11, 25].
Общий объем выборки составил около 93 тыс. текстур. Указанный набор данных охватывает временной промежуток с 2016 по 2023 г. за каждый месяц в темное и светлое время суток по всей территории Азиатско-Тихоокеанского региона выше 30° с.ш.
Для сравнения различных подходов к расчету маски облачности в рамках измерений одного прибора в работе используются маски, предоставляемые Национальным управлением океанических и атмосферных исследований США (National Oceanic and Atmospheric Administration, NOAA) по данным спек-трорадиометра AHI КА Himawari-9. Маски облачности находятся в свободном доступе по адресу . Для их расчета используется пороговый алгоритм, основанный на использовании данных моделирования излучения для безоблачных условий с целью сравнения полученных значений с фактическими измерениями спектрорадиометра AHI [34].
Для расчета маски облачности предлагается алгоритм бинарной классификации с использованием трех групп классификаторов Base , Daytime и Nighttime , каждый из которых применяется в зависимости от условий освещения Солнцем. Общая блок-схема алгоритма представлена на рис. 1.
Наиболее универсальными являются приведённые на рис. 1 классификаторы базовой группы Base. Данная группа применяется для всех пикселей спутникового изображения независимо от условий освещения, однако в качестве классификационных признаков она не использует каналы видимого, а также ближнего и коротковолнового ИК-спектра до 3,85 мкм включительно (см. табл. 1). Классификаторы этой группы обучены на всем доступном наборе данных без ограничений по QSZA, включая условия сумерек вблизи линии терминатора. Напротив, классификаторы группы Daytime обучены с использованием выборки, сформированной при значениях QSZA < 80°, однако при этом в состав классификационных признаков включены спектральные каналы 0,65, 0,86, 1,61 и
-
3,85 мкм. Для классификаторов группы Nighttime используется выборка со значениями Q SZA > 93°, что обусловлено влиянием на канал 3,85 мкм солнечного излучения. В этом случае каналы видимого спектра не используются.
-
3.1. Сверточный нейросетевой классификатор
Табл. 1. Классификационные признаки, используемые для расчета маски. BT – яркостная температура; BTD – разность яркостных температур; R – КСЯ
|
Признак |
Base |
Daytim e |
Nighttime |
Информативность |
|
R(0,65 мкм), R(0,86 мкм), R(1,61 мкм) |
+ |
Облака на фоне темной подстилающей поверхности; обнаружение снега, льда и кристаллической облачности [26, 27] |
||
|
BT(3,85 мкм) |
+ |
+ |
Обнаружение туманов и облачности нижнего яруса [14, 28] |
|
|
BT(6,95 мкм) |
+ |
+ |
+ |
Водяной пар в средних слоях атмосферы, плотная облачность [26, 29] |
|
BT(7,35 мкм) |
+ |
+ |
+ |
Водяной пар в верхних слоях атмосферы [29, 30] |
|
BT(8,60 мкм) |
+ |
+ |
+ |
Фазовый состав облачности [14, 15] |
|
BT(11,20 мкм) |
+ |
+ |
+ |
Температура различных объектов [28, 31] |
|
BT(12,35 мкм) |
+ |
+ |
+ |
Температура различных объектов [14, 30] |
|
BTD(3,85-11,20 мкм) |
+ |
+ |
Перистая облачность, облачность нижнего яруса, снег и лед [27, 31] |
|
|
BTD(6,95-11,20 мкм) |
+ |
+ |
+ |
Облачность на фоне снега и температурных инверсий [27, 32] |
|
BTD(7,35-11,20 мкм) |
+ |
+ |
+ |
Облачность верхнего и среднего яруса в присутствии снега и температурных инверсий [14, 32] |
|
BTD(12,35-11,20 мкм) |
+ |
+ |
+ |
Тонкая кристаллическая облачность [7, 33] |
|
BTD(8,60-3,85 мкм) |
+ |
+ |
Излучательная способность песка [7, 33] |
|
|
BTD(8,60-7,35 мкм) |
+ |
+ |
+ |
Морская поверхность [32] |
|
BTD(8,60-11,20 мкм) |
+ |
+ |
+ |
Слоистая облачность, туман [15, 27] |
|
Ratio(0,86/0,65 мкм) |
+ |
Увлажненная почва, растительность, облачность над морской поверхностью [26, 32] |
||
|
NDVI, NDSI |
+ |
Нормализованные дифференциальные индексы растительности и снежного покрова [29, 33] |
||
|
Landmask |
+ |
+ |
+ |
Маска суши [28, 31] |
|
Lats, Lons |
+ |
+ |
+ |
Широта и долгота (географический признак) [15, 30] |
|
Qsat |
+ |
+ |
+ |
Зенитный угол наблюдения спутника [7, 33] |
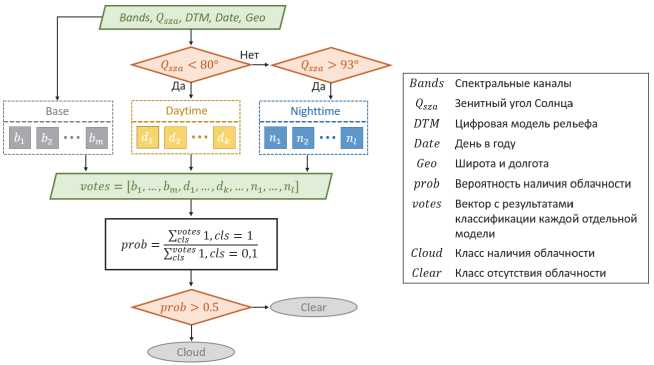
Рис. 1. Блок-схема алгоритма классификации облачности
В качестве классификаторов в работе используются две архитектуры сверточной нейронной сети, одна из которых ранее использовалась в работе [25]. Ее блок-схема представлена на рис. 2 под названием MetNet3v1. Схема имеет следующие обозначения: Input – вход нейронной сети, Conv – операция свертки изображения, MaxPool – операция подвыборки с максимумом в окне, ZeroPad – дополнение нулями по краям изображения, Concat – объединение тензоров вдоль первого измерения, DP – метод Dropout для контроля переобучения, Dense – полносвязный нейронный слой, ReLU – линейная функция активации, Sigmoid – сигмоидная функция активации, LN – нормализация весов слоя (Layer Normalization), BN – пакетная нормализация (Batch Normalization), GlobalAveragePool – усреднение весов нейронов. Размерности слоев Conv имеют обозначения (X, Y, N), где X, Y – размер ядер свертки, N – количество этих ядер. Подробное описание слоев и их назначение представлено в работах [25, 35].
Input
'------------------------J■
Conv(3x3x32) + ReLU
MaxPool + BN __I
Conv(3x3x32) + ReLU
ZeroPad Conv (1x1x32)
--------г--------7 4у-----
MaxPool + BN
——
Concat + BN J
DP
Conv(3x3x96) + ReLU 4/
Conv(lxlx32) + ReLU --------“/
Conv(lxlx9) + Sigmoid /
GlobalAvcragcPool
Рис. 2. Архитектура сверточной нейронной сети MetNet3v1, используемая для обнаружения облачности
Маска облачности с использованием данной архитектуры строится попиксельно. Методом скользящего окна для каждого пикселя спутникового изображения формируется текстура, подаваемая на вход классификатора. Выходной информацией при этом является метка класса, соответствующая наличию или отсутствию облачности в этом пикселе, являющемся центром текстуры.
Архитектура MetNet3v1 была специально разработана для задачи обнаружения облачности и показала высокую точность, однако в целях увеличения вариативности откликов каждого классификатора ансамбля в настоящей работе был осуществлен ряд модификаций.
В частности, было увеличено число ядер свертки с целью повысить прогностическую способность сети за счет большего количества используемых весовых коэффициентов. Поскольку исходная архитектура является полносверточной, где выходной отклик сети формируется путем усреднения результатов операций свертки и подвыборки, в новой версии добавлен блок полносвязных слоев, моделирующих классификационную функцию. Ввиду увеличения размеров архитектуры для снижения потенциального эффекта переобучения также были добавлены слои Dropout. Дополнительный слой Layer Normalization стабилизирует процесс обучения за счет нормализации весовых коэффициентов между сверточным и классификационным модулями архитектуры. Блок-схема модифицированной архитектуры MetNet3v2 представлена на рис. 3.
-
3.2. Метод бутстрэпинга для обучения классификаторов
Метод бутстрэпинга (англ. bootsraping или bagging) относится к ансамблевым методам построения моделей классификации [36]. Бутстрэпинг позволяет уменьшить ошибку классификации путем разбиения исходного набора обучающих данных на k подмножеств и обучения k классификаторов с последующим усреднением результатов прогнозирования [36]. В настоящей работе для усреднения результатов приме- няется метод прямого голосования, при котором в качестве итогового значения принимается мажоритарный класс. Каждое подмножество из выборки формируется путем случайных перестановок исходных элементов множества с последующим разбиением на тренировочный и валидационный наборы данных.
Метод бутстрэпинга позволяет улучшить точность для алгоритмов классификации стохастической природы, таких как деревья решений и нейронные сети. Для стабильных моделей (например, на основе классификатора k -ближайших соседей) данный метод, как правило, не дает никаких улучшений [37]. Обеспечение вариативности предсказаний (например, для метода «Случайный лес») обеспечивается разбиением выборки, а также большим количеством слабых базовых классификаторов [16]. С другой стороны, сверточные нейронные сети более требовательны к вычислительным ресурсам, что ограничивает их максимальное количество в ансамбле. Поэтому, чтобы повысить вариативность откликов классификаторов, в работе дополнительно применяются две отличающиеся друг от друга архитектуры нейронных сетей, описанные выше в подпараграфе 3.1.
Input
Conv (3x3x128) 4v-----
MaxPool + LN + ReLU

Conv (3x3x128) ---------V------
ZeroPad Conv (1x1x128)
—V—
MaxPool + LN + ReLU
Concat
---------T---------
LN + ReLU
'-------------------V-------------------'
DP + Dense + ReLU 4'
DP + Dense + ReLU
Dense + Sigmoid
Рис. 3. Архитектура сверточной нейронной сети
MetNet3v2, используемая для обнаружения облачности
3.3. Стратегия обучения классификаторов
3.4. Вычислительная эффективность
Авторы преследуют цель оперативного расчета маски облачности. Ввиду большого количества используемых нейросетевых классификаторов, алгоритм классификации оптимизирован для достижения минимального времени обработки без значимой потери точности получаемых масок. В частности, операции предварительной подготовки данных, в числе которых нормировка и формирование буфера текстур для каждого пикселя изображения, оптимизированы с использованием библиотеки NumPy для языка Python с учетом векторных операций. Нейросетевые модели классификации скомпилированы для запуска на графических процессорах с помощью библиотеки TensorRT с половинной точностью вычислений float16, не оказывающей влияния на качество рассчитываемых масок облачности. Расчеты для всех девяти классификаторов выполняются параллельно тремя потоками на графическом ускорителе NVIDIA RTX 2070. Полное время расчета маски без учета файловых операций составляет не более 60 с. для изображения AHI размером 3900×1300 пикселей с пространственным разрешением 2 км и территориальным охватом выше 30° с.ш. без ограничений по долготе. Для сравнения время работы каждого отдельного классификатора без учета распараллеливания составляет от 14 до 22 с. С учетом периодичности получения изображений Himawari (каждые 10 минут), данное время считается достаточным для оперативной работы в режиме времени, близком к реальному.
4. Оценка точности
Обучение осуществлялось для девяти классификаторов, по три в каждой из групп Base , Daytime и Nighttime . Для этого исходная обучающая выборка перемешивалась случайным образом, после чего разделялась в соотношении 1:2. Первая часть подмножества использовалась для валидации, тогда как остальные применялись непосредственно для обучения. Далее процесс повторялся для двух других классификаторов.
В каждой группе присутствовали два классификатора с более простой архитектурой (рис. 2), а также один с модифицированной (рис. 3). Здесь авторы исходили из следующих соображений. Модифицированная архитектура имеет большее количество весовых коэффициентов и должна обладать большей прогностической силой, однако вместе с тем требует вы- полнения большего объема вычислений. С другой стороны, более слабые классификаторы способны дать более вариативный отклик. Таким образом, в каждой группе формируется центральная модель и две вспомогательные.
В качестве основного критерия оптимизации при обучении в работе применялась среднеквадратичная ошибка MSE . Для минимизации этой ошибки использовался алгоритм оптимизации Adam [38], основанный на методе стохастического градиентного спуска и хорошо зарекомендовавший себя при решении подобных задач [25] как достаточно простой в настройке с относительно невысокими требованиями к вычислительным ресурсам.
Точность предлагаемого алгоритма для получения маски облачности оценивалась методом визуального дешифрирования спутниковых изображений, а также путем численной оценки качества с помощью ряда классификационных метрик. Обозначая под терминами TP , FP , FN , TN количество истинноположительных, ложноположительных, ложно-отрицательных и истинноотрицательных случаев соответственно, а также учитывая, что под положительным классом в работе принимается наличие облачности в пикселе, введем следующие метрики.
Precision = TP / ( TP + FP ), (1) Recall = TP /( TP + FN ). (2)
Метрика Precision обозначает долю подтвержденных обнаружений облачности среди всех случаев положительного класса, предсказанных алгоритмом. Чем выше этот показатель, тем меньше количество ложных обнаружений облачности. Однако с помощью данной метрики нельзя учесть нераспознанные пиксели облачности. С этой целью в работе рассматривается метрика Recall .
Метрика Recall соответствует тому, сколько от общего числа облачных пикселей было корректно распознано классификатором. Максимальное значение Recall говорит о том, что все пиксели облачности были обнаружены, однако при этом не исключаются ложные классификации в местах, где облачность фактически отсутствует. Поэтому комплексное рассмотрение метрик Precision и Recall позволяет судить об общем качестве классификации. Чтобы обобщить эти метрики, в работе также используется показатель F1:
F1 = 2 ⋅ ( Precision⋅Recall ) / ( Precision+Recall ). (3)
Для более корректной оценки точности случайным образом отбиралось равное количество облачных и безоблачных пикселей эталонной маски. Эти пиксели совмещались по координатам с аналогичными пикселями оцениваемой маски по всему рассматриваемому региону 35–80° с.ш. и 90– 180° в.д. в пределах Q SAT < 70°. В целях оценки качества рассматривались сроки наблюдений с 15 августа 2023 г. по 20 марта 2024 г., 1-й, 15-й и 28-й день каждого месяца за 0, 3, 6, 9, 12, 15, 18 и 21 час ВСВ. Общее количество изображений составило 176 шт.
Используя вышеописанные метрики, была рассчитана точность получаемых масок для различного времени суток, а также в сумеречное время вблизи линии терминатора (табл. 2). В таблице приведена точность как для отдельных классификаторов, так и для итогового ансамбля в целом. Также для сравнения приведены результаты для ранее представленного алгоритма из работы [25], где использовалось два классификатора – один для освещенных Солнцем участков и второй для остальных территорий. Из представленных результатов видно, что некоторые из классификаторов могут иметь наибольшее значение по одному из показателей метрик в сравнении с данными для ансамбля. Однако ввиду того, что метрики должны рассматриваться комплексно, наилучший показатель качества во всех ситуациях имеет ансамблевая модель, о чем можно судить по метрике F1.
Сравнение с ранее представленным в работе [25] алгоритмом также демонстрирует более высокую точность ансамблевого подхода с точки зрения комплексного показателя F1. В предыдущей работе [25] отмечались такие недостатки, как неполное выделение облач- ности нижнего яруса в темное время суток, а также проблемы при смене времени суток вдоль линии терминатора. Исходя из полученных результатов, ансамблевый алгоритм позволил значительно улучшить точ- ность распознавания облачности, особенно в сумеречное время вблизи линии терминатора (показатель F1 в данном случае улучшился с 74,56 % до 83,98 %). В других случаях прирост составил около 2 %.
Табл. 2. Оценка качества классификации с использованием маски NOAA-AHI в различное время суток
|
Q SZA <80° |
Q SZA <93° |
80°< Q SZA <93° |
|||||||
|
Precision |
Recall |
F1 |
Precision |
Recall |
F1 |
Precision |
Recall |
F1 |
|
|
Base1 |
89,33 |
76,33 |
82,32 |
85,62 |
77,52 |
81,37 |
83,75 |
74,37 |
78,78 |
|
Base2 |
94,72 |
69,52 |
80,19 |
91,64 |
70,34 |
79,59 |
90,61 |
68,56 |
78,06 |
|
Base3 |
94,29 |
67,38 |
78,60 |
91,38 |
71,22 |
80,05 |
90,58 |
66,61 |
76,77 |
|
Day1 |
92,04 |
80,90 |
86,11 |
- |
- |
- |
- |
- |
- |
|
Day2 |
92,23 |
80,05 |
85,71 |
- |
- |
- |
- |
- |
- |
|
Day3 |
96,10 |
78,79 |
86,59 |
- |
- |
- |
- |
- |
- |
|
Night1 |
- |
- |
- |
93,75 |
70,38 |
80,40 |
- |
- |
- |
|
Night2 |
- |
- |
- |
89,83 |
76,47 |
82,62 |
- |
- |
- |
|
Night3 |
- |
- |
- |
83,54 |
74,42 |
78,72 |
- |
- |
- |
|
Ансамбль |
95,93 |
80,51 |
87,55 |
91,63 |
77,52 |
83,98 |
91,15 |
70,60 |
79,57 |
|
Маска [25] |
96,48 |
76,09 |
85,08 |
93,36 |
62,06 |
74,56 |
90,81 |
67,92 |
77,71 |
Для визуальной оценки качества на рис. 4 и на рис. 5 приведены примеры масок облачности для различных условий наблюдения и освещения. Темные области на изображениях масок соответствуют наличию облачности.
На рис. 4 и рис. 5 видно, что обе представленные версии маски обладают достаточно высоким уровнем качества. Однако маска, по данным NOAA, имеет ряд недостатков, связанных с ложными обнаружениями облачности вдоль береговых линий (рис. 4 а и рис. 4 в , рис. 5 а и рис. 5 в ), ошибочной классификацией льда и снега (рис. 4 в , рис. 5 в ), а также переоценкой облачности над морем (рис. 4 а и рис. 4 б , рис. 5 а и рис. 5 б ).
С другой стороны, предложенный в работе алгоритм имеет тенденцию к небольшой недооценке оптически тонкой перистой облачности, что обусловлено особенностями обучающей выборки и предназначением маски облаков. Полупрозрачная облачность значительно затрудняет расчет многих видов тематической продукции, например, для обнаружения осадков или оценки высоты верхней границы облачности, поскольку подстилающая поверхность может сильно искажать измерения, особенно при наличии льда или снега. Таким образом, представленный алгоритм для расчета маски облачности в полной мере удовлетворяет предъявляемым к нему требованиям.
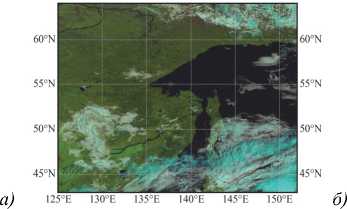
Рис. 4. Пример маски облачности за 28.08.2023 г. 00:00 UTC. (а) RGB-синтез каналов (R=0,65, G=0,86, B=1,61 мкм), (б) маска облачности по данным NOAA, (в) маска облачности, рассчитанная представленным в работе алгоритмом
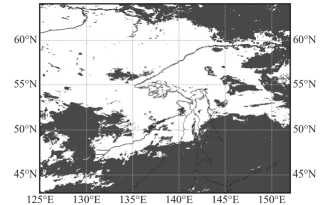
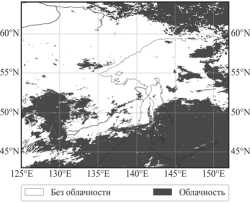
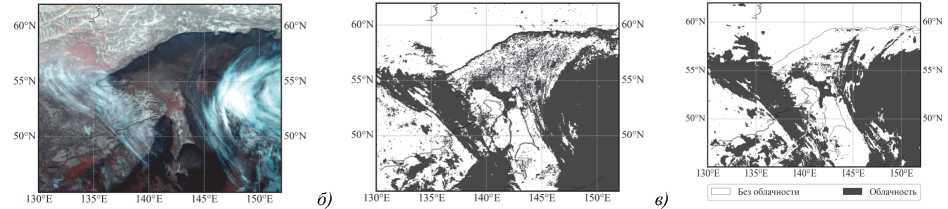
Рис. 5. Пример маски облачности за 28.02.2024. 21:00 UTC. (а) RGB-синтез каналов (R=3,85, G=11,20, B=12,35 мкм), (б) маска облачности по данным NOAA, (в) маска облачности, рассчитанная представленным в работе алгоритмом
Заключение
В работе представлен алгоритм расчета маски облачности для спектрорадиометра AHI КА Himawari-
8/9, основанный на использовании ансамблевого подхода с применением сверточных нейронных сетей. По сравнению с одиночным сверточным классификатором, представленным ранее в работе [25], ансамбль из нескольких таких моделей позволяет улучшить точность обнаружения облачности, особенно в темное время суток и вдоль линии терминатора. Достоинством алгоритма по сравнению с классическими ансамблевыми подходами на основе деревьев решений является возможность задействовать текстурные характеристики объектов, извлекаемые с помощью операции свертки изображений.
Недостатком представленного алгоритма является повышенное требование к вычислительным ресурсам. При этом время расчета может быть существенно сокращено, для чего должен быть изменен способ формирования обучающей выборки на вариант с полной разметкой всех пикселей каждого изображения. В дальнейшем эти изображения поступают на вход сегментирующей нейронной сети с архитектурой авто-энкодера. Cтоит отметить, что это сильно увеличивает трудозатраты по формированию обучающей выборки. Компромиссом может стать полуавтоматическое формирование выборки на основе существующих масок облачности с дальнейшей правкой ошибок специалистами. Такой подход может быть использован в целях дальнейшего улучшения представленного в работе алгоритма.
С целью изучения оптимальности предложенного алгоритма требуется дополнительный анализ эффективности используемых нейросетевых архитектур. Также дополнительного изучения требует применяемый метод усреднения результатов работы нескольких классификаторов. Например, возможен вариант взвешенного усреднения в зависимости от используемого типа классификатора и рассматриваемых условий наблюдения и освещения.
Исследование выполнено за счет гранта Российского научного фонда № 23-77-00011, В работе использовались ресурсы Центра коллективного пользования системами архивации, обработки и анализа данных спутниковых наблюдений Института космических исследований Российской академии наук для решения задач изучения и мониторинга окружающей среды (ЦКП «ИКИ-Мониторинг»).
