Потоконезависимое взаимодействие объектов как архитектурная парадигма

Автор: И. Д. Буторин
Журнал: Informatics. Economics. Management - Информатика. Экономика. Управление.
Рубрика: Информатика, вычислительная техника
Статья в выпуске: 5 (1), 2026 года.
Бесплатный доступ
В статье предлагается архитектурная парадигма потоконезависимого взаимодействия объектов в многопоточных C++ системах как ответ на «кризис конкурентности» и ограничения ООП с разделяемым состоянием. Исследуется гибридный подход, сочетающий событийно-ориентированную архитектуру и строгую инкапсуляцию потоков в ядре Node Manager. Ключевая идея заключается во введение состояния «потоконезависимости» как архитектурного инварианта, реализованного через hub-and-spoke топологию с централизованными lock-free очередями, типобезопасной маршрутизацией команд на основе type erasure и детерминированной обработкой событий in-process message broker’ом. Показано, что вынос планирования и синхронизации из бизнес-логики в инфраструктурное ядро снижает связанность модулей и когнитивную нагрузку, упрощает тестирование (включая record-and-replay), устраняет классы ошибок deadlock и race condition и обеспечивает стабильную латентность при высокой нагрузке и рост масштабируемости без потери детерминизма. Обсуждаются ограничения подхода, такие как единый узел отказа, backpressure, потеря причинности стека вызовов и возможные пути их инженерной компенсации. Статья предназначена архитекторам и ведущим разработчикам высоконагруженных C++ систем.
Потоконезависимость, node manager, событийно-ориентированная архитектура, hub-and-spoke топология, lock-free очередь.
Короткий адрес: https://sciup.org/14135109
IDR: 14135109 | DOI: 10.47813/2782-5280-2026-5-1-1042-1051
Текст статьи Потоконезависимое взаимодействие объектов как архитектурная парадигма
DOI:
Эволюция вычислительных систем в последнее десятилетие характеризуется фундаментальным сдвигом от увеличения тактовой частоты процессоров к увеличению степени параллелизма [1]. Закон Мура, в его классической интерпретации, уступил место закону Амдала, который диктует, что производительность системы ограничена ее последовательной частью [2]. В этом контексте разработка программного обеспечения столкнулась с так называемым «кризисом конкурентности», когда традиционные парадигмы объектно-ориентированного программирования (ООП), подразумевающие прямые вызовы методов и разделяемое изменяемое состояние, оказались недостаточно эффективными и безопасными.
Классическая модель взаимодействия объектов в многопоточной среде неизбежно требует механизмов синхронизации доступа к общим ресурсам. Использование примитивов синхронизации, таких как мьютексы (std::mutex), семафоры и условные переменные, вводит в систему понятие критических секций. Однако, как показывают исследования последних лет, интенсивное использование блокировок приводит к ряду негативных последствий: деградации производительности из-за конкуренции за кэш-линии процессора, инверсии приоритетов и сложности в верификации корректности кода [3]. Более того, это создает сильную связность не только на уровне интерфейсов, но и на уровне потоков исполнения: вызывающий объект неявно навязывает свой контекст исполнения вызываемому объекту.
В ответ на эти вызовы индустрия и академическое сообщество предложили ряд альтернативных моделей, таких как модель акторов и реактивное программирование [4]. Однако их внедрение часто сопряжено с необходимостью полной перестройки архитектуры приложения и использования специализированных фреймворков, что может быть избыточным для ряда задач.
Настоящая работа посвящена исследованию гибридной архитектурной парадигмы, которая сочетает в себе принципы событийной ориентированности (Event-Driven Architecture, EDA) и строгой инкапсуляции потоков. Центральным элементом этой парадигмы является Node Manager - архитектурное ядро, обеспечивающее маршрутизацию команд и данных между независимыми узлами (Nodes) через безопасные неблокирующие очереди. Основная гипотеза исследования заключается в том, что централизация логики межмодульного взаимодействия и его отделение от бизнес-логики позволяет достичь состояния «потоконезависимости», при котором компоненты системы могут разрабатываться и тестироваться без учета специфики многопоточного окружения, в котором они будут функционировать.
Целью данной статьи является всесторонний анализ предложенного архитектурного подхода, включая его теоретическое обоснование, детали низкоуровневой реализации на C++, а также оценку его влияния на метрики качества программного обеспечения и экономические показатели процесса разработки.
МАТЕРИАЛЫ И МЕТОДЫ
Исследование архитектурной парадигмы потоконезависимого взаимодействия объектов в многопоточных C++-системах выполнено как теоретико-инженерный анализ предложенного гибридного подхода, который сочетает событийно-ориентированную архитектуру с жёсткой инкапсуляцией контекста исполнения в ядре Node Manager. Материальную базу составили положения о смене индустриального вектора от масштабирования по частоте к масштабированию по ядрам и о предельной роли последовательной части вычислений в многопроцессорной системе [1, 2]. Для фиксации проблемного поля использованы результаты исследований о стоимости блокировочной синхронизации и эффектах конкуренции потоков за общий ресурс, включая деградацию из-за contention и усложнение доказательства корректности [3, 7]. Концептуальная рамка сопоставлялась с актороподобными моделями взаимодействия и их применимостью в современных вычислительных средах, что позволило уточнить место Node Manager как инфраструктурного медиатора сообщений в континууме между классическим ООП и реактивными подходами [4, 6].
Методология включала сравнительный архитектурный анализ топологий связности и механизмов доставки команд, где hub-and-spoke модель рассматривалась как инженерная альтернатива плотной mesh-связности и как средство локализации конкурентной сложности в едином ядре [5]. В части низкоуровневой реализации использовался разбор схем неблокирующего обмена данными через
MPSC/SPSC очереди с атомарными операциями и барьерами памяти, опирающийся на опубликованные результаты по wait-free структурам и практикам управления видимостью данных между producer и consumer [8]. Для оценки эксплуатационных свойств подхода анализировались сценарии детерминированной обработки событий, тестирования через record-and-replay и особенности отладки при разрыве причинности стека вызовов, что связывалось с наблюдениями о природе отладочных эпизодов в реальных инженерных практиках [9]. Интерпретация эффектов на процесс разработки и интеграцию модулей соотносилась с эмпирическими выводами о преимуществах слабосвязанных архитектур и метриках процессной результативности в непрерывной поставке [10, 11], при отдельном учёте ограничений, связанных с единым ядром отказа и backpressure как системными рисками централизованной диспетчеризации [3, 8].
РЕЗУЛЬТАТЫ
Архитектурный подход
Описываемая архитектура базируется на фундаментальном пересмотре способа связывания компонентов программной системы. В противовес традиционной mesh-топологии, где объекты хранят прямые ссылки друг на друга, предлагается строгая hub-and-spoke (звезда) топология, управляемая специализированным инфраструктурным слоем [5].
Концептуальная модель: Node и Node Manager
Архитектура оперирует двумя ключевыми абстракциями, которые вместе задают минималистичную объектную модель системы. Первая абстракция - Node (Узел). Это базовый класс для всех функциональных компонентов: Узел выступает атомарной единицей бизнес-логики. Его определяющее свойство -изолированность. Узел не знает о существовании других Узлов и не хранит на них прямых ссылок. Единственной внешней зависимостью Узла является указатель на Node Manager, что обеспечивает полное устранение прямых связей (decoupling) между компонентами и снижает взаимную связанность системы.
Вторая абстракция - Node Manager (Менеджер Узлов / Subscribe Manager). Это центральный управляющий компонент, который выполняет функции медиатора и маршрутизатора сообщений. Он рассматривается как «корень» системы, поэтому его жизненный цикл должен перекрывать жизненные циклы всех остальных объектов: Node Manager создается первым и уничтожается последним.
Взаимодействие в системе происходит исключительно через передачу сообщений (message passing). Когда Узел А хочет передать данные или команду Узлу Б, он не вызывает метод Узла Б. Вместо этого он формирует объект команды и передает его в Node Manager. Менеджер, используя внутренние таблицы маршрутизации (подписки), определяет получателя(ей) и доставляет команду в соответствующую очередь обработки.
Принцип потоконезависимости
Термин «потоконезависимость» в контексте данной работы означает архитектурное свойство, при котором код бизнес-логики (реализованный внутри наследников класса Node) инвариантен относительно потока, в котором он выполняется.
В традиционных системах разработчик должен заранее понимать, является ли конкретная функция потокобезопасной (thread-safe) и в каком потоке она будет вызвана, например в UI-потоке или в worker-потоке. В предлагаемой парадигме эта ответственность переносится на Node Manager, который берет на себя управление контекстом выполнения и тем самым снижает требования к знанию и контролю потоковой модели на стороне разработчика.
Генерация команды может происходить в любом потоке. Для этого в Node Manager используется метод publish, который является потокобезопасным и неблокирующим, то есть реализует модель wait-free/lock-free producer. При этом доставка команды выполняется в контролируемом контексте: Node Manager извлекает команды из очереди и вызывает обработчики подписчиков. Поскольку диспетчер вызывает обработчики последовательно в рамках одной очереди, внутри самого обработчика исчезает необходимость применять примитивы синхронизации для защиты внутреннего состояния Узла.
Это позволяет минимизировать использование мьютексов на уровне прикладного кода, перенося всю сложность синхронизации в инфраструктурное ядро, которое реализуется единожды и тщательно оптимизируется.
Сравнение с существующими паттернами
Для точного позиционирования подхода необходимо сравнить его с устоявшимися паттернами проектирования конкурентных систем. Рассмотрим паттерн медиатор. Node
Manager является классической реализацией паттерна Медиатор, описанного «Бандой четырех» [6]. Основная цель - инкапсуляция взаимодействия множества объектов. Однако классический Медиатор часто реализуется синхронно: вызов метода компонента А приводит к немедленному вызову метода компонента Б внутри Медиатора. В предлагаемой архитектуре Медиатор усилен асинхронной очередью, что превращает его в активный элемент планирования (Active Object pattern). Это решает проблему блокировки отправителя при длительной обработке сообщения получателем.
Рассмотрим модель Акторов. Предлагаемый подход имеет сильное сходство с моделью Акторов (реализованной в Erlang, Akka). Как и акторы, Узлы имеют приватное состояние и общаются сообщениями.
Однако существуют существенные отличия. Во-первых, различается механизм адресации. В акторных системах адресация обычно является явной: сообщение направляется конкретному актору по PID или ActorRef. В модели Node Manager применяется парадигма Pub/Sub (Publish-Subscribe), где адресация определяется типом сообщения или топиком, а не идентификатором получателя. За счет этого ослабляется связанность компонентов, поскольку отправителю не требуется знать, кто именно будет потребителем сообщения.
Во-вторых, отличается принцип управления очередями. В классической акторной модели каждый актор располагает собственным почтовым ящиком (mailbox), и обработка сообщений распределена по множеству независимых очередей. В архитектуре Node Manager очереди являются централизованными, используется одна глобальная очередь либо несколько тематических очередей. Такая централизация позволяет задавать глобально детерминированный порядок обработки сообщений, что значительно сложнее обеспечить в чистой распределенной акторной модели.
Топология очередей и детерминизм
Архитектура предусматривает две стратегии управления очередями, и каждая из них ориентирована на свой класс задач. Первая стратегия - единая очередь (Single Serialized Queue), при которой все команды всех типов поступают в одну FIFO-очередь. Ее ключевое преимущество состоит в глобальном детерминизме: порядок обработки событий строго соответствует порядку их поступления.
Это критически важно для систем, которым требуется воспроизводимость, например для финансовых транзакций или игровых движков. При этом данная стратегия имеет и ограничение: она может становиться узким местом (bottleneck), поскольку длительная обработка одной команды блокирует продвижение всей системы.
Вторая стратегия - множественные очереди (Multi-Queue / Type-Segregated), когда создается N независимых очередей для разных типов команд, то есть для отдельных каналов. В этом случае достигается параллелизм: обработка сетевых пакетов не блокирует рендеринг интерфейса, а разнородные операции не создают взаимных блокировок. Одновременно сохраняется важное свойство: хронологический порядок гарантируется внутри одного типа команд, однако относительный порядок между разными типами не гарантируется. Выбор между этими стратегиями позволяет балансировать между строгой консистентностью и максимальной пропускной способностью.
ПРАКТИЧЕСКАЯ РЕАЛИЗАЦИЯ
Реализация описанной парадигмы на языке C++ требует использования продвинутых механизмов метапрограммирования и низкоуровневой работы с памятью для обеспечения заявленных характеристик производительности и безопасности.
Ключевым технологическим компонентом является потокобезопасная очередь, реализующая модель Single Producer, Single Consumer (SPSC) или Multi-Producer, Single Consumer (MPSC), в зависимости от конфигурации потоков.
Использование блокирующих очередей (std::queue + std::mutex) в высоконагруженных системах приводит к значительным накладным расходам. Исследования показывают, что при высокой конкуренции (contention) потоки проводят больше времени в ожидании мьютекса, чем за выполнением полезной работы [7].
Реализация в данной архитектуре опирается на lock-free структуры данных, использующие атомарные операции (std::atomic, compare_exchange_weak/CAS). Для MPSC очередей (множество писателей, один читатель -типичный сценарий для Node Manager) эффективным решением является использование интрузивного связного списка или кольцевого буфера с атомарными индексами головы и хвоста [8].
Алгоритм помещения в очередь (enqueue) в упрощенном виде выглядит следующим образом:
-
1. Создается новый узел очереди с
-
2. Выполняется атомарная операция
-
3. Обеспечивается корректность ссылок
данными.
замены указателя Head (или Tail в зависимости от реализации) на новый узел.
(next pointer) с использованием барьеров памяти (std::memory_order_release / acquire) для гарантии видимости данных потребителем.
Такой подход обеспечивает свойство wait-free для производителя (операция push завершается за конечное число шагов) и минимизирует задержки.
Поскольку Node Manager должен обрабатывать разнородные команды без жесткой привязки к их типам на этапе компиляции самого Менеджера, используется техника стирания типов (Type Erasure). В C++ это стандартно реализуется через std::function и std::any (или void* с приведением типов) [8].
Механизм подписки можно описать следующим образом:
-
1. Узел регистрирует обработчик, указывая строковый идентификатор команды и передавая std::function, созданный через std::bind или лямбда-выражение.
-
2. Node Manager сохраняет этот
функциональный объект в карте: std::unordered_map
Использование std::function вводит определенные накладные расходы (косвенный вызов через vtable, возможная аллокация памяти). Однако в контексте архитектуры, где альтернативой является синхронизация потоков стоимостью в тысячи наносекунд, эти расходы пренебрежимо малы.
Процесс инициализации системы разделен на три этапа. На этапе инициализации (Initialization) выполняется создание объектов и формирование иерархии, при этом Node Manager аккумулирует информацию обо всех участниках. Затем следует этап регистрации (Registration), на котором Узлы объявляют, какие типы команд они обрабатывают. При этом важно, что вызов subscribe не выполняется мгновенно: он помещается в очередь в виде служебной команды, что предотвращает состояние гонки при инициализации.
После этого система переходит к этапу исполнения (Execution), где запускается основной цикл обработки команд (Event Loop). Такой подход решает проблему «Dependency Injection hell», поскольку зависимости разрешаются динамически через систему обмена сообщениями, а не фиксируются заранее через конструкторы с чрезмерно большим количеством параметров.
ОБСУЖДЕНИЕ
Опыт внедрения
Внедрение описываемой архитектурной парадигмы в реальные производственные процессы демонстрирует существенное изменение в профиле трудозатрат разработчиков. Традиционный процесс разработки многопоточных приложений характеризуется высокими затратами на этапе интеграции. Разработчики тратят до половины времени на отладку взаимодействия модулей, устранение состояний гонки и согласование интерфейсов [9].
При использовании архитектуры Node Manager наблюдается смещение фокуса в распределении усилий разработки. Подключение модуля занимает около 5% времени, поскольку интерфейс взаимодействия унифицирован через методы send и subscribe. В результате разработчику не требуется изучать API других модулей: достаточно понимать формат данных, то есть протокол обмена.
Основная часть времени, порядка 95%, уходит на реализацию логики. При этом разработчик может писать код так, как если бы он работал в однопоточном приложении, опираясь на гарантии, предоставляемые Node Manager. Это коррелирует с данными индустрии о том, что использование слабосвязанных архитектур значительно снижает время цикла разработки [10].
Одним из не очевидных, но важных преимуществ является упрощение рассуждений о системе. В запутанной паутине прямых вызовов сложно предсказать, в каком состоянии находится система в произвольный момент времени. Централизация потоков данных через Node Manager позволяет визуализировать логику приложения как набор транзакций или событийных цепочек. Это делает систему более понятной для новых разработчиков и упрощает code review.
Архитектура существенно повышает тестируемость (testability) кода за счет того, что взаимодействие компонентов формализовано и проходит через единый управляющий контур. В контексте модульного тестирования это означает, что каждый Узел можно проверять изолированно, подменяя Node Manager на mock-объект, который перехватывает исходящие команды и имитирует входящие. В результате отпадает необходимость поднимать полное окружение приложения, поскольку тест фокусируется на локальном поведении Узла и его реакциях на сообщения.
На уровне интеграционного тестирования ключевым становится механизм записи и воспроизведения (record and replay) потока команд, проходящих через Node Manager. Он позволяет строить детерминированные интеграционные тесты, поскольку воспроизводится одна и та же последовательность команд в одном и том же порядке. Такой подход практически недостижим в классических многопоточных системах, где результат часто определяется недетерминизмом планировщика операционной системы и, следовательно, плохо поддается воспроизводимому контролю.
Практические показатели
Эффективность архитектуры подтверждается как качественными, так и количественными метриками. Анализ производительности и стабильности показывает преимущества перед традиционными подходами. Сравнительный анализ задержек при передаче сообщений демонстрирует, что lock-free очередь в Node Manager обеспечивает стабильное время выполнения даже при высокой нагрузке, в отличие от решений на мьютексах. Ниже приведена таблица сравнения накладных расходов различных механизмов синхронизации.
Таблица 1. Сравнительный анализ задержек механизмов взаимодействия.
Table 1. Comparative analysis of interaction mechanism delays.
|
Механизм взаимодействия |
Низкая нагрузка (1 поток) |
Высокая нагрузка (4-8 потоков) |
Характеристика масштабируемости |
|
Прямой вызов (без синхронизации) |
< 2 нс |
N/A (Data Race) |
Неприменимо |
|
std::mutex (блокировка) |
~25 нс |
500 – 1500+ нс |
Экспоненциальная деградация (Context Switch) |
|
Node Manager (Lock-Free Queue) |
~15–40 нс |
~50–120 нс |
Линейная / Плоская (CAS Loop) |
|
std::function (overhead) |
~15 нс |
~15 нс |
Константа (не зависит от потоков) |
Как видно из таблицы, хотя накладные расходы Node Manager (lock-free + std::function) выше, чем у "голого" вызова функции, они остаются в пределах десятков наносекунд. В то же время, при возникновении конкуренции (contention), традиционный мьютекс приводит к задержкам на порядки выше (микросекунды) из-за вмешательства планировщика ОС. Node Manager сохраняет предсказуемую производительность, что подтверждает тезис о «предсказуемом конкурентном поведении». Для наглядности процесса обработки команд приведем диаграмму последовательности, иллюстрирующую цикл взаимодействия в архитектуре.
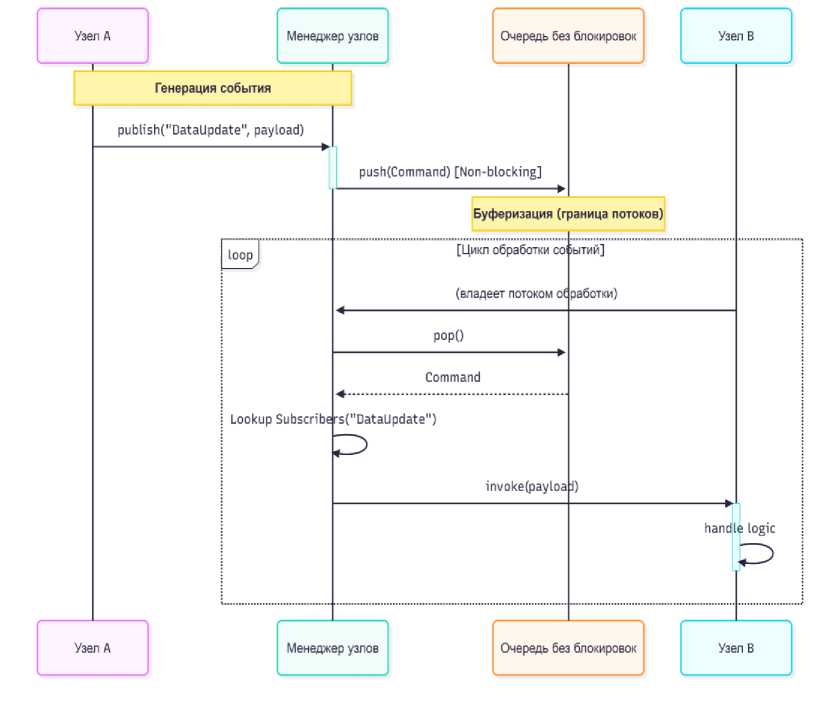
Рисунок 1. Поток обработки команды в N ODE M ANAGER .
Figure 1. Command processing flow in Node Manager.
Данная схема показывает полное разделение потока отправителя (Producer Thread) и получателя (Consumer Thread). Отправитель освобождается немедленно после помещения команды в очередь. Опыт внедрения в ключевых продуктах компании показал результаты, показанные в таблице 2.
Таблица 2. Влияние архитектуры на показатели разработки.
Table 2. The Impact of Architecture on Development Metrics.
|
Метрика |
Традиционная архитектура |
Node Manager Архитектура |
Изменение |
|
Время интеграции нового модуля |
20-30% от времени задачи |
~5% от времени задачи |
Снижение в 4-6 раз |
|
Частота критических сбоев (Deadlocks) |
Высокая |
Нулевая (by design) |
Полное устранение |
|
Reusability (Повторное использование кода) |
Низкая (сильная связность) |
Высокая (слабая связность) |
Рост эффективности |
|
Скорость обнаружения ошибок |
Поздняя (на этапе интеграции) |
Ранняя (изоляция модулей) |
Снижение стоимости исправления |
Данные из таблицы 2 коррелируют с отраслевыми отчетами, утверждающими, что модульные архитектуры с низкой связностью позволяют элитным командам развертывать код значительно чаще и с меньшим количеством сбоев [11, 12].
Архитектура демонстрирует высокую способность к вертикальному масштабированию. В конфигурации с множественными очередями (Multi-Queue), добавление новых ядер CPU позволяет линейно увеличивать пропускную способность системы, распределяя типы команд по разным аппаратным потокам. Поскольку очереди независимы, закон Амдала ограничивает производительность только в рамках одного типа команд, но не системы в целом.
ОГРАНИЧЕНИЯ
Несмотря на очевидные преимущества, предложенная архитектурная парадигма не лишена недостатков и ограничений, которые необходимо учитывать при проектировании. Управление в Node Manager централизовано, тем самым формируя риск единой точки отказа (Single Point of Failure). Если логика диспетчеризации Node Manager сломается, например, из-за ошибки при обработке очереди или нехватки памяти, вся система прекратит работу. В децентрализованных системах проявляется то, что отказ одного компонента может быть локализован в них. В отличие от них, надежность ядра становится критической из-за централизации. Следовательно, нужно исключительное качество для кода самого Node Manager и его плотное покрытие тестами.
Применение асинхронных очередей также вводит проблему с обратным давлением (backpressure). При систематическом превышении скорости генерации событий (Producer) над скоростью их обработки (Consumer), очередь станет неограниченно расти, что приведет к исчерпанию памяти (OOM) вместе с падением приложения. В синхронных системах замедление потребителя всегда тормозит производителя, в то время как в асинхронной модели Node Manager приходится реализовывать механизмы для сброса старых сообщений или сигналы о перегрузке.
Отдельным ограничением становится сложность отладки. Хотя рассуждения о системе в целом упрощаются, процесс пошаговой отладки (debugging) усложняется из-за того, что стек вызовов (call stack) разрывается в точке очереди. Когда разработчик ставит точку останова в обработчике события, он видит в стеке только цикл обработки Node Manager, но не видит код, который отправил это событие. Это явление, известное как «loss of causality», требует внедрения дополнительных инструментов трассировки, включая distributed tracing IDs, даже в рамках одного процесса.
Вдобавок, ради обеспечения полной потокобезопасности данные, передаваемые посредством очереди, зачастую должны копироваться (pass-by-value) или передаваться с помощью умных указателей (std::shared_ptr). Это создает накладные расходы на аллокацию памяти, а также атомарный подсчет ссылок. В системах с крайне низкой задержкой, например High-Frequency Trading, подобные издержки могут быть критичны, зато для большинства пользовательских приложений, включая UI и бизнес-логику, эти расходы обычно оказываются оправданными.
Показательно сравнение с cloud-native подходами. Описываемая архитектура «внутри процесса» (in-process) структурно повторяет паттерны, используемые в распределенных микросервисных архитектурах, такие как Service Mesh и Event Bus. Это подтверждает универсальность паттерна: Node Manager фактически выступает in-process Message Broker, то есть аналог RabbitMQ или Kafka, но реализованный в оперативной памяти. Тем самым архитектура оказывается готовой к потенциальному масштабированию в распределенную систему в будущем (CloudReady).
ЗАКЛЮЧЕНИЕ
Предложенная парадигма потоконезависимого взаимодействия объектов представляет собой архитектурный ответ на вызовы современной многопоточной разработки. Централизация логики взаимодействия в ядре Node Manager, подкрепленная использованием высокопроизводительных неблокирующих очередей и механизмов стирания типов C++, позволяет достичь баланса между производительностью и поддерживаемостью кода, причем этот баланс достигается не за счет компромисса в одном измерении, а за счет перераспределения ответственности между компонентами системы.
Ключевым следствием становится снижение сложности. Отделение генерации команд от исполнения этих команд устраняет нужду в ручной синхронизации бизнес-логики и, таким образом, предотвращает целый класс ошибок конкурентности, включая deadlocks и race conditions. В этой схеме разработчик оперирует событиями, а также их обработкой. При этом вместо тонкостей межпоточного доступа к состоянию поведение системы становится более объяснимым и устойчивым.
С экономической точки зрения, подход демонстрирует эффективность посредством сокращения времени интеграции модулей до 5% от общего времени разработки. Это подтверждает практическую целесообразность архитектуры, особенно в крупных проектах, где существенную роль играют высокая текучесть кадров или выраженное разделение труда. Унификация интерфейса взаимодействия снижает стоимость входа и уменьшает долю времени, уходящую на согласование и сопряжение компонент.
С точки зрения производительности использование lock-free алгоритмов обеспечивает предсказуемую латентность и высокую пропускную способность. В условиях высокой нагрузки такие механизмы способны превосходить традиционные решения на мьютексах, поскольку уменьшают накладные расходы на блокировки и снижают вероятность деградации из-за конкуренции потоков за общий ресурс. Тем самым повышается стабильность характеристик времени обработки, что важно для систем, чувствительных к задержкам.
Отдельно следует отметить универсальность архитектуры. Она применима как для систем жесткого реального времени, при использовании SPSC очередей и статической аллокации, так и для гибких пользовательских приложений, где допустима динамическая подписка. Иными словами, одна и та же парадигма допускает разные режимы конфигурации, позволяя адаптировать модель исполнения под требования конкретного домена.
В качестве путей для грядущего исследования уместно изучить формальную верификацию алгоритмов очередей, используемых в Node Manager, да плюс ко всему разработку инструментов статического анализа для осуществления проверки совместимости типов событий на этапе компиляции. Это значимо для устранения опасностей, сопряженных с Type Erasure. Нужно перенести часть возможных ошибок из рантайма в компиляцию, причём они проще выявляются и дешевле исправляются.
Для внедрения в данную парадигму требуется определенная культура разработки и смена менталитета, но долгосрочные выгоды в виде стабильности, масштабируемости и скорости разработки делают ее обоснованным выбором для современных C++ проектов высокой сложности.
