Разработка модели K-Means для выявления наиболее выгодных предложений на рынке недвижимости Москвы

Автор: М. А. Зуев, В. М. Шибаев, К. С. Баланев
Журнал: Informatics. Economics. Management - Информатика. Экономика. Управление.
Рубрика: Информатика, вычислительная техника
Статья в выпуске: 3 (2), 2024 года.
Бесплатный доступ
В статье рассматривается применение модели кластеризации K-Means для анализа рынка недвижимости Москвы. Основное внимание уделяется сегментации рынка с целью выявления наиболее выгодных предложений. Использованные данные включают параметры стоимости, площади, близости к метро, год постройки и другие характеристики объектов недвижимости. Метод "локтя" был применен для определения оптимального числа кластеров, которое впоследствии было увеличено до восьми для более точного сегментирования. Полученные результаты показали, что кластер 0 представляет собой наиболее доступные и выгодные предложения. Модель K-Means, разработанная в ходе исследования, может быть использована покупателями для оптимизации процесса выбора жилья, снижая временные и финансовые затраты.
Кластеризация данных, K-Means, анализ недвижимости, оптимизация выбора, машинное обучение, рынок недвижимости Москвы
Короткий адрес: https://sciup.org/14129610
IDR: 14129610 | УДК: 004.8 | DOI: 10.47813/2782-5280-2024-3-2-0212-0218
Текст статьи Разработка модели K-Means для выявления наиболее выгодных предложений на рынке недвижимости Москвы
DOI:
Рынок недвижимости Москвы является одним из наиболее динамично развивающихся и конкурентных в России. Высокая стоимость жилья, разнообразие предложений и быстрое изменение цен требуют от покупателей тщательного анализа и выбора наиболее выгодных предложений. В этих условиях необходимо использовать современные методы анализа данных, которые могут учитывать множество факторов и обеспечивать точное сегментирование рынка [1].
Традиционные методы анализа рынка недвижимости, такие как простая статистика или экспертные оценки, часто оказываются недостаточно эффективными при большом объеме данных и множестве переменных факторов. Применение методов машинного обучения, таких как кластеризация, становится особенно актуальным [2-4]. Кластеризация позволяет разделить объекты недвижимости на группы с похожими характеристиками, что упрощает анализ и принятие решений для покупателей.
МАТЕРИАЛЫ И МЕТОДЫ
Кластеризация является одной из ключевых ветвей машинного обучения без учителя. Она позволяет автоматически группировать объекты, основываясь на их сходстве, даже если у них нет явной классифицирующей характеристики. Алгоритм K-Means широко используется благодаря своей простоте и эффективности [5].
Алгоритм K-Means работает по следующему алгоритму [6]:
-
1. Инициализация центроидов: сначала случайным образом выбираются
-
2. Назначение объектов кластерам: для каждого объекта рассчитывается
-
3. Обновление центроидов: центроиды пересчитываются, основываясь на
-
4. Повторение: эти шаги повторяются до тех пор, пока центроиды не
начальные центроиды кластеров.
евклидово расстояние до каждого из центроидов, и объект присваивается к ближайшему центроиду.
среднем значении характеристик объектов, попавших в данный кластер.
перестанут изменяться или не будет достигнуто заданное количество итераций.
Основное преимущество алгоритма K-Means заключается в его способности быстро и эффективно группировать большие объемы данных, что делает его идеальным инструментом для анализа сложных и многомерных наборов данных. В результате работы алгоритма объекты, близкие по своим характеристикам, оказываются в одном кластере, а объекты с различными характеристиками — в разных [7].
Выбор набора данных
Для исследования был использован набор данных, содержащий информацию о недвижимости Москвы. В нем представлены следующие параметры: цена, время до метро, административный округ, общая площадь, жилая площадь, этаж, количество этажей в здании, год постройки, наличие статуса новостройки, классификация как апартаменты, высота потолков и количество комнат.
Предварительная обработка данных
Для корректной работы модели K-Means были предприняты следующие шаги [8]:
-
1. Заполнение пропущенных значений: пропущенные значения были
-
2. Преобразование категориальных данных: категориальные данные
заполнены медианными значениями, что позволило минимизировать влияние отсутствующих данных на модель.
(например, административный округ) были преобразованы в числовые с использованием метода LabelEncoder. Это позволило учитывать различия между районами Москвы при кластеризации.
Определение оптимального числа кластеров
Оптимальное количество кластеров было определено с помощью метода "локтя", который заключается в анализе инерции модели K-Means при разном числе кластеров и выборе числа, при котором происходит значительное уменьшение инерции [9]. На рис. 1 видно, что оптимальное количество кластеров равно 4. Однако, для более точной сегментации рынка недвижимости и учета большего количества характеристик, было принято решение увеличить количество кластеров до 8. Это позволило выделить более

специфические группы объектов, что улучшило интерпретацию результатов и выявление наиболее выгодных предложений.
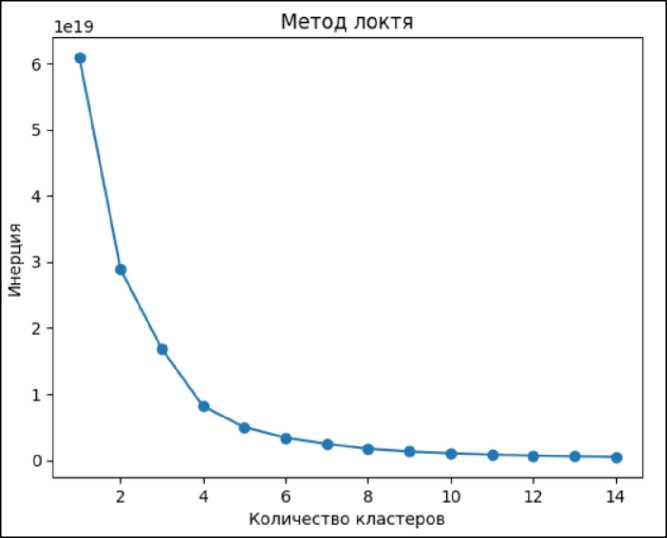
Рисунок 1. Применение метода локтя для набора данных.
Figure 1. Application of the elbow method to a data set.
РЕЗУЛЬТАТЫ
На основании анализа средних значений параметров для каждого кластера, выделим кластер, который представляет собой наиболее выгодные предложения на рынке недвижимости Москвы.
Кластер 0 характеризуется следующими параметрами: средняя цена объектов составляет около 20,319,055 рублей. Среднее время до ближайшей станции метро составляет 13.02 минут, что является комфортным для большинства покупателей. Объекты недвижимости в этом кластере расположены преимущественно в южном административном округе, что указывает на доступные районы Москвы. Средняя общая площадь объектов в этом кластере составляет 56 кв.м, с жилой площадью 33 кв.м. Средний этаж, на котором расположены эти объекты, составляет 9, а среднее количество этажей в здании – 18. Большинство объектов в данном кластере были построены около 2003 года. Примерно 27.19% объектов являются новостройками. Также 13.17% объектов классифицируются как апартаменты. Средняя высота потолков в этих объектах составляет 3 м. Среднее количество комнат – 2. Таким образом, кластер 0 представляет

собой наиболее выгодные и доступные предложения на рынке недвижимости Москвы, сочетая в себе комфортные условия проживания и оптимальную стоимость.
|
price |
min_to_metro |
regionofmoscow |
total_area \ |
|
|
cluster 0 |
20,319,055 |
13.020061 |
4.524192 |
55.738995 |
|
1 |
198,544,946 |
18.424623 |
1.025126 |
167.736281 |
|
2 |
3,737,636,000 |
10.000000 |
0.000000 |
530.000000 |
|
3 |
481,139,633 |
7.646154 |
0.246154 |
241.860308 |
|
4 |
118,899,765 |
8.933333 |
1.910569 |
134.626439 |
|
5 |
315,637,948 |
8.083916 |
0.741259 |
202.741259 |
|
6 |
741,009,153 |
8.222222 |
0.000000 |
310.685556 |
|
7 |
57,097,160 |
14.397742 |
4.005312 |
100.058088 |
|
livingarea |
floor number_of_floors construction_year |
|||
|
cluster 0 |
33.470309 |
9.387302 |
18.437102 |
2003.104319 |
|
1 |
60.778894 |
11.773869 |
17.597990 |
2012.140704 |
|
2 |
183.000000 |
6.000000 |
7.000000 |
2003.000000 |
|
3 |
71.541538 |
11.738462 |
14.784615 |
2014.076923 |
|
4 |
58.736423 |
11.913821 |
19.988618 |
2007.338211 |
|
5 |
76.776923 |
8.783217 |
12.776224 |
2011.671329 |
|
6 |
73.505556 |
6.055556 |
7.055556 |
2019.000000 |
|
7 |
50.564807 |
12.918991 |
23.930279 |
2010.918991 |
|
isnew is_ |
apartments ce |
.lingheight number_of_rooms |
||
|
cluster 0 |
0.271890 |
0.131697 |
2.933219 |
2.031390 |
|
1 |
0.150754 |
0.195980 |
3.215201 |
3.494975 |
|
2 |
0.000000 |
0.000000 |
3.000000 |
4.000000 |
|
3 |
0.153846 |
0.230769 |
3.289846 |
3.661538 |
|
4 |
0.186992 |
0.232520 |
3.186699 |
3.196748 |
|
5 |
0.146853 |
0.209790 |
3.353846 |
3.580420 |
|
6 |
0.277778 |
0.055556 |
3.666667 |
3.777778 |
|
7 |
0.328685 |
0.174635 |
3.119900 |
3.011952 |
Рисунок 2. Средние значения полученных кластеров.
Figure 2. Mean values of the obtained clusters.
ЗАКЛЮЧЕНИЕ
В результате исследования была разработана модель на базе алгоритма K-Means, позволяющая выявлять наиболее выгодные предложения на рынке недвижимости Москвы. Модель предоставляет покупателям ценный инструмент для оптимизации процесса выбора недвижимости, что позволяет существенно сократить время и затраты на поиск оптимального варианта. Основная сложность в данной работе заключается в интерпретации полученных кластеров.
