Система семантического анализа ответных текстов обучаемого на естественном языке

Автор: Сулейманов Д.Ш.
Журнал: Онтология проектирования @ontology-of-designing
Статья в выпуске: 1 (11) т.4, 2014 года.
Бесплатный доступ
В статье описывается двухуровневая модель контроля ответа обучаемого, лежащая в основе построения системы семантического анализа ответных текстов на естественном языке в диалоговом контексте. Дается описание двух важных методологических принципов: «детерминированности контекста» и «ожидаемости смысла ответа», за счет которых достигается эффективность системы. Описываются архитектура системы и шесть базовых принципов реализации: выделение системы семантических единиц; семантическая классификация вопросно-ответных текстов на основе типовых отношений; разработка индивидуальных концептуальных грамматик семантических классов; сегментация вопросно-ответных текстов; релевантность представления знаний (модели ответа); открытости системы. Работа системы демонстрируется на примере анализа ответа класса Функция.
Семантическая типизация вопросно-ответных текстов, концептула, индивидуальные концептуальные грамматики, модель ответа, тип вопроса
Короткий адрес: https://sciup.org/170178496
IDR: 170178496
The system of semantic analysis of response texts in natural language
This article describes a two-level model of students answers evaluation, which serves as a basis for the creation of the system of semantic analysis of response texts in natural language in a dialog context. Two important methodological principles that make this system efficient are explained: «determinism of context» and «expectedness of the meaning of the answer». This article outlines the architecture of the system and six basic principles of its implementation: marking out of semantic units system, semantic classification of question-answer texts based on standard relations, development of individual conceptual grammars of semantic classes, segmentation of question-answer texts, relevance of knowledge representation (of the response model), openness of the system. The performance of the system is shown on the example of the analysis of an answer of the «Function» class.
Текст научной статьи Система семантического анализа ответных текстов обучаемого на естественном языке
Как известно, современные автоматизированные системы контроля ответов обучаемого основаны, главным образом, на модели выборочного типа ответов и практически не обладают возможностями диагностирования ответа, конструируемого самим обучаемым, что, очевидно, ограничивает обучаемого в свободном изложении мысли при ответе на вопрос [1]. Соответственно, построение автоматизированной системы анализа ответов обучаемого на естественном языке (ЕЯ) в произвольной форме является весьма важной и актуальной задачей, решение которой способно существенно повысить качество образовательного процесса.
Построение системы семантического анализа текстов в контексте, управляемом вопросом системы к пользователю, имеет свою специфику, выгодно отличающую его от других ЕЯ-диалоговых систем и создающую реальные предпосылки для построения эффективной системы контроля ответов обучаемого на ЕЯ [2].
Возможность создания такой системы и ее эффективность обеспечиваются за счет реализации двух важных методологических принципов: «детерминированности контекста» и «ожидаемости смысла ответа». Очевидно, контекст тестирования, в котором задача ученика -дать ответ на заданный вопрос как можно ближе к ответу, ожидаемому учителем, чтобы получить хорошую оценку, побуждает его отвечать максимально точно, используя те термины, понятия и даже формы определений и фраз, которые дал учитель. Одновременно, задавая вопрос, учитель (система) заранее знает множество значений вопроса (возможные ответы) и может с большой точностью и полнотой сформировать модель ответа, который является ожидаемым по заданному вопросу.
Смысловая типизация вопросов и соответствующая семантическая классификация ответных текстов дают возможность противопоставить каждому типу вопроса ограниченный на- бор допустимых, т.е. логически правильных, смысловых конструкций (ответных формул). Можно рассматривать совокупность этих формул, соответствующих конкретному типу вопроса, как некоторую грамматику, кодирующую конструкции, передающие правильный смысл ответа в контексте, заданном вопросом. Нами была поставлена и решена задача такой классификации вопросно-ответных текстов, когда форма и смысл соответствующего входного текста напрямую зависят от типа вопроса.
Введем определения ряда понятий, далее используемых в статье.
Концептула - это элементарная смыслообразующая единица семантической структуры текста, отражающая роль лексем в значении вопроса и в определенном их сочетании формирующая смысл ответа в контексте, детерминированном заданным вопросом.
Схемы сочетания концептул, соответствующие правильной передаче ожидаемого смысла ответов определенного класса, будем называть индивидуальными концептуальными грамматиками (ИКГ) . Таким образом, каждая ИКГ представляет собой некий семантический синтаксис, отображающий ролевую структуру ответного текста. Использование понятия концептуальной грамматики дает возможность сводить семантический анализ содержания ответа к анализу соответствия его ролевой структуры некоторой ИКГ, ожидаемой по заданному вопросу.
Семантическая типизация вопросов позволяет разбить множество ответов обучаемого на семантические классы, в каждом из которых требуется раскрытие некоторого смысла, определенного типом вопроса и независимого от формы задания и лексического наполнения вопроса.
В статье раскрываются базовые принципы построения и архитектура системы семантического анализа ответных текстов на естественном языке в диалоговом (вопросно-ответном) контексте. На конкретном примере демонстрируется работа системы, которая на входе получает ответ обучаемого на заданный вопрос и на выходе формирует диагностический вектор ситуаций, характеризующий степень правильности ответа.
1 Архитектура и принципы построения системы
Система семантического анализа ответов предназначена для анализа ответа обучаемого на естественном языке без дополнительных ограничений на форму и объем ответного текста и имеет декларативно-процедурное представление. В процедурную часть входят лексический процессор (ЛексП) и семантический интерпретатор (СемИ). Декларативная часть представлена двухуровневой моделью ответа (МО). Соответственно, системой осуществляется двухуровневый анализ ответов: на первом (поверхностном) уровне - лексический, когда происходит анализ используемых лексем и их канонизация (категоризация), и на втором, глубинном (каноническом) - семантическая интерпретация, когда устанавливается соответствие канонического представления ответа ожидаемой семантической схеме. Анализ производится на основе двухуровневой модели ответа. В результате анализа вырабатывается диагностический вектор ситуаций, представляющий собой последовательность кодов, характеризующих типы ошибок в ответе.
Архитектура системы семантического анализатора ответных ЕЯ-текстов в контексте, управляемом вопросом, показана на рисунке 1.
Обработка ответного текста происходит следующим образом. Ответ обучаемого на конкретный заданный вопрос поступает в ЛексП, который осуществляет полную лексическую обработку текста на основе МО. МО представляет собой двухуровневую базу знаний, включающую таблицу ролей лексем (концептул) в оцениваемом ответе на первом (поверхностном) уровне, и комплекс ИКГ, соответствующих ожидаемому классу ответов, на втором
(глубинном) уровне. Модель ответа строится и заполняется либо специалистом по предметной области (инженером по знаниям, учителем), либо самой системой по задаваемому вопросу на основе информации в базе знаний, когда база знаний включает онтологическую модель предметной области.
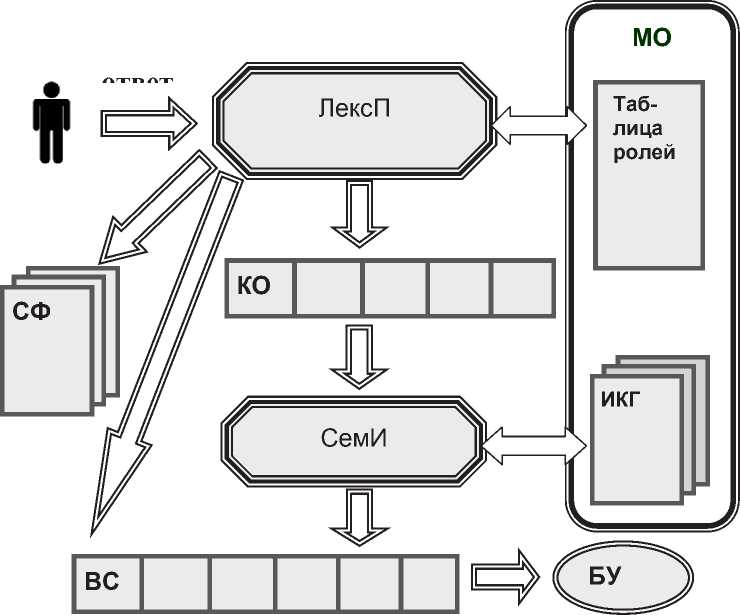
Рисунок 1 - Система семантического анализа ответных ЕЯ-текстов
Последовательно анализируя каждое входное слово на основе таблицы ролей МО на первом уровне, ЛексП переводит лексемы в соответствующие им роли (концептулы) и в итоге получает каноническое описание смысла ответа (КО) в виде последовательности концептул. Те лексемы в ответе, которые, возможно, не будут идентифицированы на основе МО, также могут представлять ценность с точки зрения корректности оценки ответа (например, для дальнейшей проверки их на непротиворечивость с ожидаемым смыслом ответа), поэтому накапливаются в специальных файлах (СФ). Вся информация, получаемая в процессе анализа ответа на уровне ЛексП, регистрируется в векторе ситуации (ВС). Далее, на втором (глубинном) уровне, КО поступает в СемИ и анализируется с привлечением специальных семантических схем - ИКГ, представленных на втором уровне МО. ИКГ реализованы декларативно. Это позволяет изменять (например, дополнять или исправлять, сортировать сочетания кон-цептул по частоте использования их в ответах) и расширять концептуальную грамматику новыми ИКГ без изменения процедурной части системы.
Результат формируется в виде дополнения вектора ситуации, частично заполненного на первом уровне. Полный вектор ситуации, как результат анализа ответа двухуровневым лингвистическим процессором, является той информационной базой, на основе которой принимается решение блоком управления (БУ) по дальнейшему управлению процессом обучения.
Рассмотрим детально ряд утверждений и содержание блоков, приведенных выше и представленных на рисунке 1. Построение системы семантического анализа базируется на следующих двух методологических принципах и шести принципах реализации.
Методологические принципы:
Принцип детерминированности контекста. В силу активности, система «погружает» пользователя в определенный контекст, который определяется заданным вопросом. Соответственно, содержание ответа, его лексикон и даже форма и, отчасти, объем предопределены, и пользователь с необходимостью отвечает на вопрос в определенных рамках.
Принцип ожидаемости смысла ответа. По заданному вопросу система знает пространство значений вопроса, т.е. ей заранее известен контекст, в котором будет происходить интерпретация ответа и достаточно легко может быть сформирована модель текста, адекватная ожидаемому ответу как по лексике, так по форме изложения и семантической конструкции.
Принципы реализации:
Принцип 1 . Выделение системы смыслообразующих единиц - концептул, с целью трансформации проблемы семантического анализа вопросно-ответного текста в проблему синтаксического анализа в условиях использования детерминирующей роли контекста.
Принцип выделения концептул приводит к необходимости провести типизацию понятий, отношений, грамматических признаков и специальных ролей лексем и установления соответствия между ними и концептулами в управляемом контексте, т.е. в контексте заданного вопроса. Выделение концептул производится на основе анализа типов лексем и их ролей в вопросно-ответных текстах.
Принцип 2 . Семантическая классификация вопросно-ответных текстов на основе типовых отношений: выделение конкретных типов отношений, типов вопросов и классов ответов для реализации детерминирующей роли контекста.
В условиях определенного контекста существует возможность упростить способы кодирования смысловой информации, а, следовательно, и способы ее декодирования. При анализе текста в процессе общения оказывается важным фиксирование контекста и установление зависимости формального выражения смысла (т.е. грамматической конструкции) от этого контекста. В вопросно-ответном диалоге система функционирует в условиях такого определенного контекста, и она способна четко очертить круг ожидаемых возможных ответов, т.е. значений вопроса, и декодировать ожидаемый смысл из многообразия грамматически правильно построенных фраз в соответствии с этим предварительным знанием. Смысловая типизация вопросов и семантическая классификация значений вопроса дают возможность противопоставить каждому типу вопроса ограниченный набор допустимых ответных формул, т.е. логически правильных смысловых конструкций. Можно рассматривать совокупность этих формул, соответствующих конкретному типу вопроса, как некоторую грамматику, кодирующую конструкции, передающие правильный смысл ответа. Следовательно, при семантическом подходе к типизации вопросов и классификации ответов имеется прямая связь между типом вопроса и классом ответа. Принадлежность ответа к некоторому классу ответов определяется не по его объему и содержанию, и не по форме вопроса, а по типу вопроса системы и по ожидаемому смыслу.
Принцип 3. Разработка ИКГ семантических классов, отражающих смысловые конструкции ответов соответствующих классов и в совокупности составляющих концептуальную грамматику (КГ) как схему реализации принципа трансформации семантики в синтаксис, служащей формальной основой для построения семантического интерпретатора, ориентированного на «слушающего».
Сочетания понятий и отношений в текстах, соответствующих определенным семантическим классам, имеют достаточно устойчивые частотные характеристики. Следовательно, при создании системы семантической интерпретации логично ожидать в анализируемом тексте семантические конструкции, имеющие наиболее высокие частотные характеристики для рас- сматриваемого контекста. Схемы сочетания концептул, соответствующие правильной передаче ожидаемого смысла, названы нами ИКГ.
Принцип 4. Сегментация вопросно-ответных текстов по минимальным смысловым конструкциям для рекурсивного применения правил концептуальной грамматики (базовых смысловых формул).
Этот принцип обосновывается тем, что любой осмысленный текст допускает актуальное членение на синтагматические группы, линейные или иерархические, а также очевидным утверждением, что любой осмысленный текст полностью «покрывается» линейной или иерархической последовательностью сегментов, отражающих его глубинное каноническое описание. В проблематике семантического анализа текстов на ЕЯ, особенно для практической реализации разработок, оказывается важной задача членения входного текста на такие части, к которым рекурсивно применимы простые формулы. Сложный текст представляет собой линейную и/или иерархическую последовательность смысловых частей, относящихся к тому или иному семантическому классу ответов. Сегмент есть часть сложного текста, или полный текст, соотносящийся с определенным семантическим классом. Следовательно, сложный текст, с точки зрения структурного образования, является линейно и/или иерархически организованной последовательностью сегментов, которые рекурсивно распознаются на основе соответствующих ИКГ.
В известных системах понимания ЕЯ практически отсутствуют эффективные механизмы выделения сегментов в анализируемом связном тексте для применения к ним ограниченного набора унифицированных правил анализа. Глубинные причины такого положения лежат в сложности самой проблемы членения входного текста на соответствующие смысловые части. Это посильно только действительно интеллектуальной системе, способной на основе плавающего (уточняющего смысл части текста по месту чтения) контекста выделять смысловые конструкции, рекурсивно идентифицируемые с правилами ИКГ соответствующих классов ответов.
В нашем случае, с одной стороны, из-за требований высокой реактивности семантического анализатора в автоматизированной обучающей системе (АОС), с другой стороны, в силу выгодных особенностей проблемной области, позволяющих использовать два введенных выше методологических принципа - «ожидаемости ответа» и «детерминированности контекста», мы сознательно идем на некоторое упрощение ситуации, допуская, что входной текст, т.е. ответ обучаемого, однозначно попадает в рассматриваемый контекст и фактически содержит ожидаемый смысл (вернее, должен содержать, иначе текст не является ответом на вопрос или не распознается нашей системой). Для применения соответствующих ИКГ, требуется определить, к какому семантическому классу ответов относится вводимый текст. В случае вопросно-ответного текста автор курса способен заранее по задаваемому вопросу предопределить семантический класс ожидаемого ответа, тем самым, предопределяя и соответствующую цепочку ИКГ, применяемую для его смыслового анализа.
Семантическая классификация вопросно-ответных текстов производится от простого к сложному. Вначале определяются простые семантические классы ответов, т.е. ответы, в которых раскрывается смысл вида «понятие-отношение-понятие». Затем из таких конструкций строятся более сложные семантические классы, представляющие собой комбинации простых классов, как линейные, так и иерархические, отражающие существование связных текстов из простых, сложносочиненных и сложноподчиненных предложений. Соответственно, сегментация текстов приводит к построению как линейных, так и иерархических представлений, которые рекурсивно распознаются на основе определенных ИКГ.
Принцип 5. Релевантность представления знаний (модели ответа) по смысловой структуре и лексическому наполнению ожидаемому ответному тексту. Очевидно, что наиболее эффективный диалог, т.е. достаточно адекватная и реактивная интерпретация входного текста, будет осуществляться при соблюдении принципа релевантности представления знаний (модели ответа) по смысловой структуре и лексическому наполнению ожидаемому ответному тексту. Это является естественным требованием к системе интерпретации, моделирующей человеко-машинный интерфейс, так как в управляемом контексте активный участник диалога всегда имеет возможность заранее построить модель ответа адекватно ожидаемому контексту по своему вопросу.
Принцип 6. Принцип открытости системы, обеспечивающий развитие системы путем накопления новых знаний на основе устойчивых статистических характеристик, в том числе, путем расширения множества обобщенных семантических единиц (концептул), введения новых типов вопросов и классов ответов, сортировки и расширения правил концептуальной грамматики как совокупности всех ИКГ, введения новых ИКГ.
2 Семантическая классификация вопросно-ответных текстов
Любая предметная область (ПрО) содержательно представляет собой совокупность значимых понятий и отношений между этими понятиями, которая изложена в определенной последовательности. Множество конкретных понятий и отношений по определенным признакам можно разбить на конечное число типов понятий и типов отношений . Назовем эти типы, семантические единицы, концептулами . Каждое осмысленное предложение ПрО можно перевести в текст, составленный из типов понятий и типов отношений, т.е. семантических единиц, без детального учета грамматических признаков лексем, соотнося каждое понятие или отношение с определенным типом.
Полный отказ от элементов классической грамматики ЕЯ оправдан не во всех случаях. В передаче смысла предложения в определенных ситуациях важную роль играют такие грамматические признаки как падежные окончания слов, предлоги и др., и их учет позволяет существенно упростить семантическую интерпретацию ответного текста. Поэтому нами введена дополнительная семантическая единица (концептула) - грамматическая роль лексем или их частей для указания соответствующих грамматических признаков естественного языка, значимых для более эффективного контроля правильности ответа.
Смысл анализируемого ответного текста зависит также от специфики проблемной области. Этим вызвано введение третьего типа концептул - специальных ролей лексем в ответе пользователя.
Таким образом, в исследуемой модели канонический смысл текста определяется сочетанием концептул четырех указанных типов, соответственно, четырьмя группами концептул.
Первая группа концептул - множество концептул, отражающих различные типы понятий . Обозначим, K S = { SS, SS ( i ) , SO, SОП, SA, SP }. Здесь SS - концептула, отражающая главное понятие (первая буква S - признак того, что концептула отражает понятие), т.е. поня-тие/понятия, относительно которого/которых задан вопрос. Сложные тексты могут содержать несколько понятий, связи которых раскрываются в анализируемых предложениях, каждое понятие в процессе анализа определенной части предложения может, в свою очередь, выступать в роли главного понятия. Для их различения в пределах анализируемого текста вводится обозначение: SS ( i ) - концептула, отражающая i-е главное понятие ; SO - концептула, отражающая понятие, состоящее в некотором определенном отношении с главным понятием; SОП - концептула, отражающая обобщенное понятие (ОП). ОП - это понятие, находящееся по отношению к главному на более высоком уровне в иерархии понятий предметной области (т.е. интенсионал, например, понятие «человек» есть ОП по отношению к понятию
«студент»); SA - концептула, отражающая понятие-аргумент; SP - концептула, отражающая понятие-результат .
Вторая группа концептул - множество концептул, отражающих различные типы отношений. Обозначим, K r ={ R c , R coct ,Rвкл ,Rд ,R bpo , Rпpo, Rклo, R k4o , R so , R os , R a , R p } . Здесь Rc - это концептула, соответствующая типовому отношению Состояние, Rcoct - Состав, RВКл - Включение, Rд - Действие, RBP0 -Временное Отношение, RПРО - Пространственное Отношение, RКлО - Количественное Отношение, RK40 - Качественное Отношение, RSO - концептула, отражающая отношение SS к SO , ROS - концептула, отражающая отношение SO к SS , R A -концептула, отражающая отношение SS к SA , R P - концептула, отражающая отношение SS к SP .
Третья группа концептул - Грамматические роли лексем и их частей, отражает грамматические признаки естественного языка (элементы грамматики, например, суффиксы, союзы, предлоги и др.). Обозначим, K G = { GPa, GPp, Gm, Gf 1 , Gf 2 } . Здесь G - признак грамматических ролей; GPa - предлог перед SA (например, для русского языка предлоги из, от, с и т.п.); GPР - предлог перед SP (например, предлоги в, на, к и т.п.); Gm - грамматические модификаторы : лексемы типа «чем», «нежели» и т.п. после лексемы, выражающей отношение, или падежные окончания слова после лексемы, выражающей понятие; Gf 1 - функциональная лексема, обозначающая признак начала причинной части ответа , в котором раскрывается причинно-следственное отношение. Например, лексемы « потому что», «так как», «если» и т.п.; Gf 2 - функциональная лексема, обозначающая признак начала следственной части ответа , в котором раскрывается причинно-следственное отношение. Например, лексемы « то», «тогда», «значит» и т.п.
Четвертая группа концептул - специальные роли лексем, отражающие специфику элементов ответа на конкретный вопрос, т.е. в определенном контексте. Обозначим, K L = { LN, LZ, LNE, LI S , LI O , LI A , LI P , LI R }. Здесь L - признак ролей специальных лексем, LN - необязательная лексема , т.е. лексема, отсутствие или наличие которой в ответе не влияет на смысл ответа; LZ - запрещенная лексема , т.е. лексема, наличие которой в ответе недопустимо (рассматривается как ошибка); LNE - неопределенная лексема , т.е. лексема, не предусмотренная разработчиком курса; LI - интервальная лексема , т.е. лексема, которая накладывает некоторое ограничение на понятие или отношение (указывает область действия, например, «2K памяти», «все операторы» и т.д.). Интервальная лексема при SS отражается концептулой LI S . Аналогично записываются другие концептулы для интервальных лексем: LI O - при SO, LI A -при SA, LI P - при SP, LI R - при отношениях.
Далее, на основе введенной классификации концептул, проведем семантическую классификацию вопросно-ответных текстов.
На форму задания вопросов не накладывается специальных ограничений. Ограничения естественным образом исходят из того требования, что вопрос должен быть однозначно понят обучаемым (т.е. по тексту вопроса должно быть понятно, раскрытие какого понятия и смысла требуется в ответе). Так, выделяются следующие типы вопросов и соответствующие им классы ответов.
-
I. Вопросы, требующие явного задания в ответе ключевых понятий (отношения явно заданы в вопросе).
Сюда относятся вопросы типа: «Напишите программу вычисления функции на С++ », «Назовите состав компилятора ».
Этому типу вопросов соответствуют классы ответов, в которых обязательно явно содержатся ключевые понятия. Например, ответы выборочного типа (даны несколько ответов, необходимо указать правильный ответ); ответы типа «ДА/НЕТ»; ответы фиксированно- конструируемого типа (когда дается часть ответа и необходимо дописать недостающие лексемы); численные ответы и т.п.
-
II. Вопросы, требующие раскрытия в ответе типового отношения одного главного понятия.
Это вопросы следующего типа: «Что выполняется раньше: компиляция или загрузка? », «Что легче - железо или дерево? » и т.п.
Можно указать следующие классы ответов, раскрывающие одноименные типовые отношения: Состав, Включение, Действие, Состояние, Временное отношение, Пространственное отношение, Количественное отношение, Качественное отношение и др.
-
III. Вопросы, требующие раскрытия в ответе составного отношения одного главного понятия.
Составное отношение может состоять из нескольких простых отношений. Например, таким составным отношением является отношение Функция, которая в ответном тексте одновременно отражает отношение главного понятия и к аргументу, и к результату. К этому типу относятся вопросы типа: «Какую функцию выполняет компилятор? », «Назовите предназначение загрузчика», «Что делает мельница» и т.п.
Такому типу вопросов соответствуют классы ответов, в которых главное понятие раскрывается через составное отношение. Например, ответ: « Мельница перемалывает зерно в муку » относится к классу ответов Функция , в котором отражено отношение главного понятия «мельница» к понятию-аргументу «зерно», а также и к понятию-результату «мука».
-
IV. Вопросы, требующие раскрытия в ответе произвольной комбинации простых типовых и/или составных отношений одного главного понятия.
К данному типу относятся вопросы: «Дайте описание химического вещества К », « Что Вы знаете о кибернетике? », «Дайте определение компилятора ».
Этим вопросам соответствуют классы ответов, в которых главное понятие раскрывается через его простое типовое отношение и/или составное отношение . Можно выделить, например, следующие классы ответов:
-
1) Описание - класс ответов, в которых раскрываются произвольные комбинации типового отношения и/или составного отношения главного понятия с другими понятиями: S i состоит из S i +3 , S i +4 , S i +5 , переводит S i +6 и S i +7 и выполняется раньше S i +1 , где S i , S i +7 , S i +3 , S i +4 , S i +5 , S i +6 - понятия ПрО.
-
2) Определение - класс ответов, в которых главное понятие раскрывается через ОП -обобщающее понятие (т.е. понятие на более высоком уровне в иерархии, интенсионал) и класс Описание. Например, к этому классу можно отнести ответ: «Студент - это человек, который обучается в ВУЗе ».
-
3) Причина - класс ответов, в которых раскрывается условие существования некоторых отношений главного понятия с другими понятиями. Предполагается, что главное понятие следствия и его отношения с другими понятиями заданы в вопросе. Например, рассмотрим текст ответа: «Дерево не тонет в воде, потому что удельный вес дерева меньше удельного веса воды ». Если это ответ на вопрос: «Почему дерево не тонет в воде? », то ответ относится к классу Причина . Здесь главное понятие следствия «дерево» и его отношение с объектом « вода » дается в самом вопросе. Часть ответа «Потому что удельный вес дерева меньше удельного веса воды » раскрывает условие существования указанного следствия.
-
4) Следствие - класс ответов, в которых раскрывается следствие от существования некоторых отношений главного понятия с другими понятиями . Тот же пример в этом случае демонстрирует ответ на вопрос: «Что следует из того, что удельный вес дерева меньше удельного веса воды? ». Здесь главное понятие причины «удельный вес дерева» и
- его отношение «меньше» к другому понятию «удельный вес воды» даются в вопросе. В части ответа: «Дерево не тонет в воде» раскрывается следствие от существования указанного условия.
В ответах на вопросы типа I-IV главное понятие не меняется в процессе просмотра текста (т.е. предполагается, что ответы содержат информацию только относительно одного главного понятия ).
-
V. Вопросы, требующие раскрытия в ответе более чем одного главного понятия.
Например, к ним относятся вопросы следующего типа: « Расскажите о Казанском федеральном университете », « Докажите теорему Пифагора » и т.п.
Этому типу вопросов могут соответствовать ответы, в которых главное понятие меняется в процессе просмотра ответа, т.е. роль главного понятия переходит на то понятие, отношения которого с другими понятиями раскрываются далее в ответном тексте. Нами выделены следующие классы ответов, в которых содержатся главные понятия , связанные только общим контекстом. Например, детализация. В ответах этого класса происходит детализация понятий, состоящих в некотором отношении с главным понятием.
Пример вопроса V типа: « Какая связь существует между институтом и заводом? ». Ответом может быть следующий текст, относящийся к классу детализация: « В институте разработана САПР, которая используется для проектирования токарных приспособлений, которые внедряются на заводе ». В этом ответе три главных понятия – «институт», «САПР», «токарные приспособления». Последовательно раскрываются следующие отношения этих понятий с другими понятиями: разработал – «институт разработал САПР», проектирует -«САПР проектирует токарные приспособления», внедряются – «токарные приспособления внедряются на заводе».
Разбиение текстов на семантические классы осуществляется по типу отношения главного понятия , раскрываемого в данном ответе, и не зависит ни от конкретной ПрО, ни от понятий данной ПрО, ни от конкретного языка общения с системой. Это позволяет строить эффективные предметно-независимые анализаторы, ориентированные на раскрытие определенного типа отношения главного понятия в рамках соответствующего класса ответов.
При семантическом подходе к типизации вопросов и классификации ответов имеется прямая связь между типом вопроса и классом ответа. Принадлежность ответа к некоторому классу ответов определяется не по его объему и содержанию, и не по форме вопроса, а по типу вопроса преподавателя и по ожидаемому смыслу.
3 Индивидуальные концептуальные грамматики. Модель ответа.Описание вектора ситуаций. Сегментация ответных тестов
Семантическим классам ответов соответствуют присущие им схемы сочетания концеп-тул, передающие характерный (обобщенный) смысл ответов данного класса (значений вопросов). Как было определено выше, схемы сочетания концептул, соответствующие правильной передаче ожидаемого смысла, названы ИКГ. Смысл введения ИКГ заключается в сведении семантического анализа текста к синтаксическому анализу его канонического представления в условиях, определенных некоторым контекстом.
Рассмотрим, например, ИКГ класса ответов Функция и технологию ее построения.
Пусть задан вопрос типа III: «Какую функцию выполняет компилятор?» Очевидно, значением данного вопроса (т.е. ответами) может быть множество следующих поверхностных форм:
-
1) переводит исходный текст на языке высокого уровня в объектный текст в машинных кодах ,
-
2) получает ЯМК из ЯВУ ,
-
3) компилятор переводит ЯВ У в ЯМК .
Здесь отношение « переводит » есть R A , отношение « получает » - Rp , понятия « текст на языке высокого уровня », «ЯВУ » - SA , «текст в машинных кодах », «ЯМК » - SP , предлог «из» - GP a , предлог « в» - GPp , понятие « компилятор» есть главное понятие - SS.
Формализованное представление ответов, соответственно, имеет вид:
-
1) R A —> SA —> GP P —> SP
-
2) R P —> SP —> GP A —> SA
-
3) SS—> R A —> SA —> GP P —> SP
Исследуя, таким образом, всевозможные варианты поверхностных, а далее и глубинных представлений ответов, в которых ожидается раскрытие составного отношения Функция одного главного понятия, мы получаем следующее описание ИКГ классов ответов ФУНКЦИЯ :
-
<ИКГ ФУНКЦИЯ>:: = [ SS* —> ](( R a * —> ( GP p —> SP* —> SA* | SA* —> GP p —> SP* ) | rp* -> ( GP a -> sa* —> SP* | SP* —> GP a —> SA* )) | (( GP p —> SP* —> R a * —> SA* | SA* —> RA* —> GP p —> SP* ) | ( GP a —> SA* —> R p * —> SP* | SP* —> R p * —> GP a —> SA* ))
Знак «|» обозначает альтернативное вхождение сочетаний концептул. Круглые скобки служат для объединения концептул разных типов. Квадратные скобки означают необязательное вхождение.
Модель ответа
строится на основе задаваемого вопроса и представляет собой пару
Например, МО для класса Функция имеет следующее описание:
ФУНКЦИЯ: SS=
GP
a
=
LI
a
=
Для вопроса типа III: «Какую функцию выполняет компилятор? » - формируется F(3) по оператору:
ОТВЕТ: КЛАСС = ФУНКЦИЯ ;
-
F: SS=&комп&, &транс&; R A = переводит,преобр&т; SA=&ЯВУ&; R P =получает;
-
G: ИКГ Функ ция
Для каждого класса ответов формируется отдельный вектор ситуаций (ВС). Покажем в качестве примера структуру векторов ситуаций для классов ответов на вопросы типов II и III.
ВС для классов ответов на вопросы типа II (ВС2) имеет следующее представление: КЛАСС = < Название класса ответов > S 1 S 2 S 3 S 4 S 5 S 6 S 7.
Здесь, S 1 - это код, характеризующий лексическую полноту ответа. Значением S 1 является соотношение количества лексем, использованных в ответе, и лексем, предусмотренных моделью ответа.
-
S 2 - код, указывающий на наличие в ответе запрещенных лексем. Значением S 2 является число, характеризующее количество LZ в ответе обучаемого.
-
S 3 - код, указывающий на использование в ответе неопределенных лексем, т.е. лексем, непредусмотренных моделью ответа. Значением S 3 является количество неопределенных лексем.
S 4 - код, характеризующий модальность ответа: а) неуверенность, т.е. присутствие в ответе лексем типа «возможно», «наверное» и т.п., улучшающих оценку неверного и принижающих оценку верного ответа; б) категоричность, т.е. присутствие в ответе лексем типа « конечно», «безусловно», «непременно» и т.п., усиливающих, подтверждающих правильный или еще более принижающих слабый, неверный ответ; в) нейтральность, т.е. отсутствие в ответе лексем типа а) и б). Таким образом, значением S 4 является 0, 1 или 2, соответственно, для случаев а), б) и в).
S 5 - код, характеризующий правильность использования интервальных лексем, т.е. лексем-ограничителей, накладывающих определенные ограничения на другие лексемы в ответе. Например, количественные характеристики или слова типа «не», «нет» и т.п. Значением S 5 является 0 или 1 (верно/неверно).
S 6 - код, характеризующий правильность глубинного смысла ответа, т.е. соответствие его канонизированного представления определенной схеме ИКГ. Значением S 6 является: а) 0, если канонизированное представление соответствует ИКГ; б) 1, если в ответе отсутствует отношение; в) 2, если канонизированное представление не соответствует ИКГ, т.е. нарушен глубинный смысл.
S 7 - код, характеризующий смысловую полноту ответа, т.е. степень соответствия канонизированного представления ответа определенному сочетанию концептул в ИКГ по длине: а) полное соответствие; б) канонизированное представление короче; в) канонизированное представление длиннее. Значением S 7 является: 0, для случая (а); 1, для случая (б); 2, для случая (в).
ВС для классов ответов на вопросы типа III (ВС3) имеет следующий вид (на примере класса Функция ):
КЛАСС = ФУНКЦИЯS 1 S 2 S 3 S 4 S 5 S 6 S 7.
ВС3 отличается от ВС2 содержанием кода S 6. Код S 6 ВС3 характеризуется следующими значениями: а) 0, если канонизированное представление соответствует ИКГ; б) 1, если в ответе отсутствуют отношения; в) 2, если канонизированное представление не соответствует ИКГ; г) 3, если указано только одно отношение; д) 4, если в ответе отсутствует SA ; е) 5, если в ответе неверно указан SA ; ж) 6, если в ответе отсутствует SP ; з) 7, если в ответе неверно указан SP .
Коды S 1,..., S 5 и S 7 такие же, что и в ВС2.
В соответствии с моделью ответа во входном тексте выявляется главное понятие, определяется либо контекст, либо часть контекста, в котором определено это понятие и его взаимосвязи с другими понятиями. Затем выявляются отношения главного понятия с другими понятиями и далее - сами эти понятия. Таким образом, выделяется сегмент (параллельно происходит канонизация текста). Этот процесс продолжается до завершения входного текста или пока не встретится признак начала другого сегмента. Новый сегмент определяется по следующим признакам.
Первый признак - поверхностный, признак начала сегмента в тексте. Как правило, обозначается в письменном тексте явно: либо знаком и конкретной функциональной лексемой, либо просто знаком пунктуации. Это символы типа «,» - запятая, «.» - точка, «—» - тире и т.п. К функциональным лексемам относятся лексемы типа «который», «что», «такой, что» и т.п.
Второй признак - глубинный, содержательно определяющий новый сегмент. Это лексема, отражающая новое отношение, т.е. отношение между понятиями из другого контекста в модели ответа. Это может быть либо новое отношение главного понятия с другими понятиями (линейная структура), либо отношение между другими понятиями (линейная или иерархическая структура). Таким образом, благодаря принципу «ожидаемости» определенных се- мантических классов и на основе модели ответа производится сегментация входных текстов, и рекурсивно применяются к ним соответствующие цепочки ИКГ. Очевидно, даже для весьма ограниченной ПрО нереально предопределить все возможные семантические классы для адекватной сегментации текста и применения к ним соответствующих ИКГ. Всегда будут возможны тексты, которые верны по смыслу, но не поддаются корректной сегментации в рамках данной модели ответа. Однако это не приводит к перестройке базовых концепций, так как система является открытой, знания и обрабатывающие процедуры в ней отделены друг от друга и образование нового семантического класса приводит не к пересмотру и изменению всей совокупности ИКГ, а только к изменению схемы ИКГ или дополнению ее новой ИКГ.
Заключение
Известно, что в настоящее время задача построения автоматизированной интеллектуальной системы анализа ответа обучаемого на ЕЯ в произвольной форме далека от своего полного решения. Система автоматизации анализа ответа обучаемого, описанная в данной статье, также не является в полной мере той полноценной интеллектуальной системой, которая способна анализировать и оценивать по смыслу произвольные ответные тексты любой сложности, соответственно, оценивать мыслительные, аналитические способности тестируемого на уровне самого учителя.
Тем не менее, эта разработка является качественным шагом к интеллектуализации автоматизированного контроля ответа обучаемого за счет возможности ввода обучаемым ответа на заданный вопрос на ЕЯ в произвольной форме, без специальных ограничений, и за счет расширения спектра диагностирования ответа, учитывающего также такие характеристики, как семантическая полнота и корректность. Такая возможность обеспечивается за счет реализации двух базовых концептуальных принципов: «детерминированности контекста» и «ожидаемости смысла ответа», описанных в статье.
Данная работа в настоящее время получила развитие в направлении унификации представления концептуальных грамматик на основе математического аппарата алгебры кортежей [3], обеспечивающего использование алгебраических моделей для представления и обработки вопросно-ответных текстов при автоматизации этапа генерации учебных вопросов и соответствующих моделей ответов.
Работа выполнена при поддержке гранта РФФИ (проект № 12-07-00550).
Список литературы Система семантического анализа ответных текстов обучаемого на естественном языке
- Сулейманов, Д.Ш. Исследование базовых принципов построения семантического интерпретатора вопросно-ответных текстов на естественном языке в АОС / Д.Ш. Сулейманов // Международный журнал «Образовательные технологии и общество». - 2001. - Т.4. - №3. - С.178-193. http://ifets. ieee.org/russian/periodical/v_43_2001EE.html
- Бухараев, Р.Г. Семантический анализ в вопросно-ответных системах / Р.Г. Бухараев, Д.Ш. Сулейманов - Казань: Изд-во Казан.ун-та, 1990. - 123 c.
- Аюпов, М.М. Подход к построению вопросно-ответных обучающих систем на базе сетей многоместных отношений / М.М. Аюпов, Б.А. Кулик, О.А. Невзорова, Д.Ш. Сулейманов, А.Я. Фридман // Труды тринадцатой нац. конфер. по искусственному интеллекту с международным участием КИИ-2012 (16-20 октября 2012 г., г. Белгород, Россия). Т.1. - Белгород: Изд-во БГТУ, 2012. - С. 152-159.
