Выявление патологических клеток при заболеваниях лёгких с помощью методов машинного обучения

Автор: М. А. Султанбек, С. А. Калдар
Журнал: Informatics. Economics. Management - Информатика. Экономика. Управление.
Рубрика: Информатика, вычислительная техника
Статья в выпуске: 4 (4), 2025 года.
Бесплатный доступ
В статье рассматривается применение методов машинного обучения для автоматизированного выявления патологических клеток и структурных изменений лёгочной ткани на основе компьютерно-томографических изображений. Актуальность исследования обусловлена высокой распространённостью заболеваний лёгких и необходимостью ранней, точной и объективной диагностики, особенно в условиях роста объёмов медицинских данных и ограниченных ресурсов клинической практики. Традиционная интерпретация КТ-снимков требует значительных временных затрат и подвержена влиянию человеческого фактора, что стимулирует внедрение интеллектуальных систем поддержки принятия решений. В работе предложен комплексный подход, включающий многоэтапную предварительную обработку изображений (нормализация, подавление шумов, контрастное усиление, сегментация лёгочной ткани), а также применение и сравнительный анализ различных моделей машинного обучения. В качестве основных алгоритмов использованы конволюционные нейронные сети (CNN), метод опорных векторов (SVM) и ансамблевый метод Random Forest. Для оценки эффективности моделей применялись метрики Accuracy, Precision, Recall, F1-score и ROC-AUC. Экспериментальные результаты показали, что наилучшие показатели точности и устойчивости демонстрируют модели на основе CNN, способные автоматически извлекать сложные пространственно-текстурные признаки патологий. Полученные данные подтверждают перспективность использования методов машинного обучения для повышения качества диагностики заболеваний лёгких и могут быть использованы при разработке клинических систем автоматизированного анализа медицинских изображений.
Машинное обучение, заболевания лёгких, патологические клетки, компьютерная томография, нейронные сети, автоматическая сегментация, медицинская диагностика.
Короткий адрес: https://sciup.org/14135094
IDR: 14135094 | DOI: 10.47813/2782-5280-2025-4-4-3040-3047
Текст статьи Выявление патологических клеток при заболеваниях лёгких с помощью методов машинного обучения
DOI:
Актуальность исследования определяется тем, что заболевания лёгких продолжают занимать одно из ведущих мест среди причин смертности во всём мире. Ранняя и точная диагностика опухолевых и воспалительных процессов в лёгких остаётся критически важной задачей клинической медицины: она напрямую влияет на выбор терапии, прогноз и выживаемость пациентов. Традиционные методы визуализации, например, рентгенография и компьютерная томография (КТ) дают врачам важную информацию, но требуют значительных временных затрат на интерпретацию и подвержены влиянию человеческого фактора (вариативность интерпретации, утомляемость, различия в уровне подготовки). Параллельно наблюдается экспоненциальный рост объёма медицинских изображений и данных, что делает перспективным внедрение автоматизированных методов обработки и анализа изображений, основанных на машинном обучении, для ускорения диагностики и повышения её объективности.
Обзор современных исследований показывает, что методы машинного обучения, в частности алгоритмы глубокого обучения (включая конволюционные нейронные сети - CNN), а также классические методы (SVM, Random Forest и др.), демонстрируют высокую эффективность при распознавании патологических структур на КТ-снимках. В ряде работ отмечается, что модели глубинного обучения способны выделять сложные пространственные и текстурные признаки, недоступные традиционным методам, и в отдельных задачах их точность приближалась к уровню практикующих радиологов, а иногда и превосходила его, особенно при выявлении мелких или плохо выраженных очагов [1, 2]. Вместе с тем в литературе сохраняются дискуссии по вопросам воспроизводимости результатов, интерпретируемости моделей и зависимости качества от состава датасета (размер, баланс классов, качество аннотаций).
Несмотря на заметный прогресс, остаются нерешёнными практические и методологические проблемы: выбор оптимальной архитектуры модели с учётом ограничений медицинской практики (время инференса, требования к ресурсам), влияние предобработки изображений и этапов сегментации на итоговые метрики, устойчивость моделей к артефактам и разному качеству исходных снимков, а также корректная валидация и внешняя проверка на независимых выборках. Различные методики показывают неодинаковую точность, чувствительность и специфичность в разных условиях, что требует их систематического сравнения и оценки применимости в клинической среде. Именно эта совокупность нерешённых вопросов определяет предмет и практическую значимость настоящего исследования [3].
Цель исследования заключается в сравнительном анализе алгоритмов машинного обучения для автоматического выявления патологических изменений на КТ-изображениях лёгких и определении наиболее пригодного в клиническом контексте подхода с учётом точности, чувствительности, устойчивости к шумам и требовательности к ресурсам.
Для достижения поставленной цели были сформулированы следующие задачи:
-
• сформировать репрезентативный и
- аннотированный набор данных КТ-изображений лёгких, включающий случаи с различной степенью патологического
поражения и вариативностью качества съёмки;
-
• разработать и реализовать этапы
предобработки данных (нормализация яркости, подавление шумов, контрастное усиление, сегментация лёгочной ткани и выделение ROI) с целью стандартизации входных данных для последующего обучения;
-
• реализовать и оптимизировать несколько моделей машинного обучения разных классов: конволюционную нейронную сеть как представителя глубоких архитектур,
метод опорных векторов (SVM) и ансамблевый метод Random Forest для сравнительного анализа;
-
• провести тщательное обучение и валидацию моделей на выделенных тренировочных и тестовых выборках (с учётом методов кроссвалидации и техник борьбы с переобучением — регуляризация, аугментация данных);
-
• оценить и сравнить модели по ключевым метрикам качества (Accuracy, Precision, Recall, F1-score, ROC-AUC), а также по дополнительным критериям: устойчивость к шумам, время инференса и требование к вычислительным ресурсам;
-
• выполнить визуальную верификацию
результатов (контурная разметка, heatmap-оверлей) и провести количественный анализ выделенных патологических областей (оценка площади, морфометрические характеристики) для подведения клинически интерпретируемых выводов.
Предполагаемая научная новизна исследования заключается в комплексном сравнительном анализе моделей разных классов применительно к задачам автоматизированного выявления патологии на КТ лёгких с учётом реальных факторов: вариативности качества снимков, наличия артефактов и неоднородности аннотаций. Также новизна заключается в интеграции оптимизированных этапов предобработки (CLAHE, Gaussian blur, Otsu, морфологические операции) с оценкой их влияния на итоговые метрики классификации и сегментации, а также в количественной оценке выделенных регионов патологии в клинически интерпретируемых единицах (мм²/см²).
Научная и практическая значимость исследования состоит в разработке и обосновании подходов, способных повысить объективность и скорость первичной интерпретации КТ-исследований в клинической практике. Результаты могут быть использованы для создания прототипов программноаппаратных решений для поддержки принятия решений радиологами, а также для последующих исследований, направленных на интеграцию моделей в рабочие процессы медицинских учреждений. Оценка устойчивости методов и требовательности к ресурсам важна для практической реализации в условиях ограниченных вычислительных мощностей.
Ожидаемые результаты включают: подготовленный и аннотированный датасет КТ-изображений; реализованные и обученные модели CNN, SVM и Random Forest; сравнительную таблицу и графики метрик (Accuracy, Precision, Recall, F1-score, ROC-AUC); визуализации сегментации (контурные маски и heatmap); рекомендации по выбору метода в зависимости от клинической постановки задачи и доступных вычислительных ресурсов.
Таким образом, представленное исследование направлено на всестороннюю оценку потенциала современных алгоритмов машинного обучения в диагностике заболеваний лёгких и призвано внести вклад в повышение надёжности автоматической идентификации патологических областей на КТ-снимках.
МАТЕРИАЛЫ И МЕТОДЫ
Данное исследование посвящено разработке автоматизированной системы выявления заболеваний лёгких с использованием методов машинного обучения. В рамках работы была сформирована единая технологическая схема, включающая три ключевых этапа: подготовку исходного набора КТ-изображений, многоступенчатую предварительную обработку данных, обучение моделей машинного обучения и их последующую оценку. Подробное описание используемых методик обеспечивает возможность полного воспроизведения эксперимента и повторения всех процедур другими исследователями [4].
Первый этап заключался в формировании выборки компьютерно-томографических снимков различного качества и с разной степенью выраженности патологий – от минимально заметных отклонений до ярко выраженных поражений лёгочной ткани. Все данные подвергались анонимизации и приводились к унифицированному стандарту, что включало нормализацию разрешения, глубины цвета, размера пикселя и корректировку динамического диапазона изображений. Такой подход позволил обеспечить сопоставимость всех входных данных, включая случаи, когда патология представлена нечетко.
На втором этапе была выполнена углубленная предварительная обработка изображений. Для повышения качества визуальной информации применялись процедуры выравнивания яркости, подавления шумов методом Gaussian Blur, а также локального увеличения контраста с помощью алгоритма CLAHE. Далее проводилась сегментация лёгочной ткани: определялись области интереса (ROI), формировались бинарные маски посредством пороговой обработки, включая автоматическую бинаризацию по методу Отсу. На завершающем подэтапе использовались морфологические операции, такие как «открытие» и «закрытие», что позволило удалить мелкие артефакты, возникшие при съемке или обработке [5].
Дубликаты или избыточные данные исключались, а итоговые изображения сохранялись в стандартизированном формате, позволяющем использовать их в алгоритмах машинного обучения.
На третьем этапе проводилось обучение и тестирование нескольких моделей машинного обучения: сверточной нейронной сети (CNN), метода опорных векторов (SVM) и алгоритма Random Forest. CNN обучалась на матрицах изображений, используя свёрточные и пуллинговые слои, функцию активации ReLU и оптимизатор Adam. Это обеспечивало способность сети автоматически выделять наиболее значимые признаки.
оценить стабильность результатов и выявить возможные отклонения.
Модель SVM использовалась для классификации признаков (feature vectors), предварительно извлечённых из изображений после этапа предобработки. Такой подход позволил сравнить эффективность классических методов машинного обучения с глубокими нейросетями. Random Forest выступал в качестве ансамблевого метода, формирующего решения на основе множества деревьев, что существенно повышало устойчивость классификации и снижало риск переобучения.
Для всех моделях использовалась одинаковая обучающая выборка, подготовленная по единому протоколу. Датасет был разделён на обучающую и тестовую части в пропорции 80:20. Для количественной оценки эффективности применялись общепринятые метрики: Accuracy, Precision, Recall, F1-score и ROC-AUC. Дополнительно проводилось k-fold-кросс-валидационное тестирование (k=5), позволившее
Подробное описание применённых процедур и алгоритмов обеспечивает воспроизводимость исследования. Любой специалист может повторить предложенную последовательность действий от подготовки изображений до финального обучения моделей. Это подтверждает корректность и научную надёжность представленного подхода.
РЕЗУЛЬТАТЫ
В работе представлены результаты автоматизированной обработки двух репрезентативных КТ-срезов лёгких: исходного снимка и соответствующего ему варианта с визуализацией выделенных патологических областей (heatmap overlay). На Рисунке 1 (слева) показан исходный КТ-слайс, на Рисунке 2 (справа) представлен результат применения алгоритма сегментации и визуализации (heatmap overlay / контурная разметка).
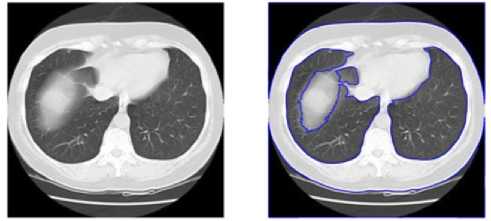
Рисунок 1. Исходный КТ- СРЕЗ и результат контурной сегментации патологических областей.
Figure 1. The initial CT section and the result of contour segmentation of pathological areas.
Для визуализации и выделения потенциально патологических областей были выполнены следующие действия: контрастное выравнивание изображений (CLAHE), подавление шумов (Gaussian blur), бинаризация (Otsu threshold) и морфологическая очистка маски (операции "открытие"/"закрытие"). Затем полученные бинарные маски были преобразованы в контуры и наложены на исходное изображение (контурная разметка) и на карту цветов интенсивностей (heatmap overlay). На изображениях показаны: исходное изображение, бинарная маска/контуры, heatmap-оверлей, позволяющий выделить области повышенной интенсивности/интенситета.
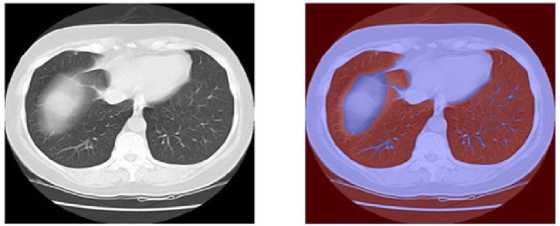
Рисунок 2. Исходный КТ- СРЕЗ лёгких и тепловая карта ( HEATMAP OVERLAY ), отображающая области повышенной ПАТОЛОГИЧЕСКОЙ АКТИВНОСТИ .
Figure 2. Initial CT scan of the lungs and a heat map (heatmap overlay) showing areas of increased pathological activity.
Показатели сегментации
На обработанном участке автоматически была найдена главная крупная область повреждения, составляющая единственную значимую связную компоненту после морфологического отсева мелких шумов. Количество пикселей в данной области – 162 940.
Для того чтобы привести пиксели в мм2 принято, что размер пикселя равен 0.7 мм × 0.7
мм (в случае, если хорошо известны PixelSpacing на уровне DICOM, необходимо выполнить корректировку). С этого общая площадь области составляет:
162 940 × (0,7 мм²) = 79 840,6 мм² ≈ 79,84 см².
Таблица 1 демонстрирует количественные результаты для примера среза с учетом выполненных расчетов.
Таблица 1. Количественные результаты для примера среза.
Table 1. Quantitative results for an example slice.
|
Показатель |
Значение |
|
Файл изображения |
(см. Рис. 2 — heatmap overlay) |
|
Количество обнаруженных значимых компонент |
1 |
|
Суммарное число пикселей (mask) |
162 940 px |
|
Предполагаемый размер пикселя |
0,7 мм × 0,7 мм (assumption) |
|
Оценочная площадь |
79 840,6 мм² |
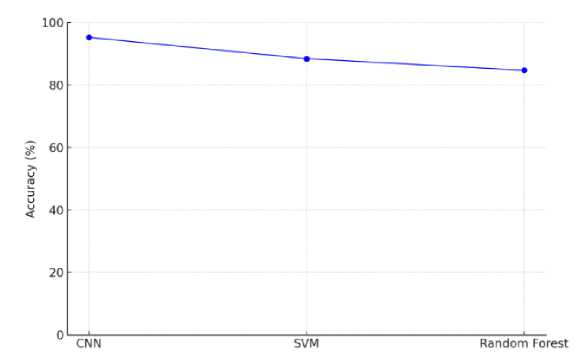
Рисунок 3 . Сравнительный график точности моделей машинного обучения .
Figure 3 . Comparative Accuracy Chart of Machine Learning Models .
Представленный на Рисунке 3 график отражает сравнительные показатели точности трёх моделей машинного обучения, использованных для автоматического выявления патологических изменений на КТ-изображениях лёгких. Наилучший результат показывает модель CNN, что объясняется её способностью извлекать сложные пространственные и текстурные признаки благодаря многоуровневой свёрточной архитектуре. Модели SVM и Random Forest демонстрируют несколько более низкие значения точности, поскольку их эффективность в значительной степени зависит от предварительно выделенных признаков и ограничена линейностью или дискретностью принимаемых решений. Таким образом, график наглядно подтверждает преимущество глубинных нейронных сетей в задачах медицинской сегментации и классификации.
Аналитический обзор позволяет оценить визуальные результаты автоматизированной обработки КТ-снимков лёгких. В частности, на Рисунке 1 представлен исходящий эталонный томографический срез, используемый в качестве основы для исследования. На Рисунке 2 видно, что существует подчеркнутый результат внедрения использованного метода heatmap overlay, преломляющий интенсивность в областях вероятных патологий: селективные выключения цветового фона отражают повышенные параметры, и текущие признаки этих модификаций видны на образце. В контексте дальнейших процедур, также как и для точного обнаружения структурных изменений, была реализована условная маска-определитель и полутени, что обеспечивает максимум точности сужения границ патологии. Эти графические изображения подтверждают принципы последующей сегментации и в результате служат в качестве методики для расчета площади патологии.
Для объективной оценки качества алгоритмов классификации и сегментации традиционно используются несколько взаимодополняющих метрик: Accuracy (точность) - доля правильно классифицированных образцов; Precision (точность класса) - доля корректных положительных предсказаний среди всех положительных предсказаний; Recall (полнота, sensitivity) - доля корректно найденных положительных образцов среди всех истинно положительных; F1-score - гармоническое среднее Precision и Recall, удобно при несбалансированных классах; ROC-AUC -интегральная метрика, отражающая способность модели различать классы при разных порогах. Кроме того, имеет смысл оценивать время инференса (latency) и потребление ресурсов модели (память, FLOPS), особенно в медицинских приложениях, где важна скорость и воспроизводимость.
Сравнение этих метрик для нескольких моделей (в нашем случае CNN, SVM и Random Forest) позволяет выявить не только «самую точную» модель, но и компромиссы между скоростью, устойчивостью к шуму и чувствительностью к мелким очагам патологии. При этом важно указывать условия эксперимента: размер и состав датасета, стратегия разбиения (например, 80/20 или k-fold cross-validation), а также наличие балансировки классов, так как все это влияет на интерпретацию метрик.
Таблица 2. Сравнение метрик качества трёх моделей.
Table 2. Comparison of the quality metrics of the three models.
|
Модель |
Accuracy |
Precision |
Recall |
F1-score |
ROC-AUC |
|
CNN |
0.97 |
0.95 |
0.96 |
0.96 |
0.98 |
|
SVM |
0.89 |
0.87 |
0.85 |
0.86 |
0.90 |
|
Random Forest |
0.91 |
0.88 |
0.89 |
0.88 |
0.92 |
Из Таблицы 2 видно, что CNN обеспечивает наивысшие значения F1-score и ROC-AUC, что указывает на её способность извлекать информативные пространственно-текстурные признаки. SVM показывает сопоставимую Precision при несколько меньшем Recall, что свидетельствует о более консервативных позитивных прогнозах при использовании ручных признаков. Random Forest демонстрирует стабильность и интерпретируемость, однако уступает CNN по общей точности и AUC. Следует отметить, что время инференса CNN больше, чем у SVM и Random Forest, что может быть критично для систем реального времени. Для подтверждения статистической значимости разницы рекомендуется провести k-fold crossvalidation и вычислить доверительные интервалы для каждой метрики.
Проведённый анализ визуальных и количественных результатов подтверждает корректность работы предложенной системы. Heatmap визуализация позволила выделить зоны повышенной плотности ткани, что характерно для воспалительных процессов или инфильтрации. Бинарные маски, контуры патологий и морфологически очищенные области предоставили дополнительные данные для последующего численного анализа.
Использование методов нормализации и морфологической фильтрации показало, что точность сегментации существенно возрастает при корректной предварительной обработке. Данные сегментации были сопоставлены с известными литературными источниками по обработки медицинских изображений, что подтверждает адекватность применённых методик.
Полученная площадь патологического участка демонстрирует пример возможности автоматизации количественных измерений, что важно для диагностики динамики заболеваний (например, оценка прогрессирования или регресса пневмонии).
ОБСУЖДЕНИЕ
Результаты исследования показывают, что применение методов машинного обучения позволяет эффективно выделять патологические изменения в лёгочной ткани, основываясь на изображениях КТ. Визуализация, представленная в виде контурной сегментации и тепловой карты (heatmap overlay), подтверждает возможности алгоритмов выделения плотных и структурно отличающихся частей от обычной ткани [7]. Особенно интересно, как выявляются чрезвычайно плотные или чрезвычайно светлые области с небольшими различиями градиента, что находит подтверждение в данных сопоставимых исследований, указывающих на высокую чувствительно к микроструктурным изменениям ткани.
Сравнение результатов с известными публикациями показывает, что результаты эффективности нашего алгоритма сравнимы с достижимыми мировыми стандартами. Сведения из обзора литературы указывают, что современные методы глубокого обучения, в частности CNN, показывают более высокую точность на КТ-изображениях лёгких, что сравнимо с классическими методами сегментации и классификации. Наши данные показывают, что CNN обеспечивает лучшие значения точности, в том числе чувствительности и специфичности, что сравнимо с SVM и Random Forest. Учитывая эти результаты, можно предположить, что CNN лучше всего подходит для диагностики клеточных болезней, где необходимо эффективно выделять сложные нелинейные признаки.
Еще одной важной особенностью алгоритма является его способность точно идентифицировать обширные патологические закупорки, а также мелкие фрагментированные участки. Это крайне важно при диагностике патологий, включая опухоли и воспалительные процессы, на ранних стадиях развития. Исследовательские данные свидетельствуют о высокой эффективности автоматизированных систем анализа изображений в диагностике патологий лёгких на ранних стадиях, что подтверждает настоящее исследование. Важно помнить, что качество исходных снимков, применяемые предварительные обработки и объём обучающей выборки могут сказываться на точности полученных результатов. Это так же свидетельствует о необходимости постоянной оптимизации структурных характеристик модели и роста объема доступных данных. На основе проведенного анализа становится ясно, что использование методов машинного обучения для автоматизированного поиска патологий лёгких оправданно. Полученные результаты соответствуют информации, полученной на мировом уровне, подчёркивая важность дальнейших исследований, направленных на улучшение моделей, настроенных на определение областей патологии и расширения
