Automating text simplification using pictographs for people with language deficits

Author: Mai Farag Imam, Amal Elsayed Aboutabl, Ensaf H. Mohamed
Journal: International Journal of Information Technology and Computer Science @ijitcs
Article in issue: 7 Vol. 11, 2019.
Free access
Automating text simplification is a challenging research area due to the compound structures present in natural languages. Social involvement of people with language deficits can be enhanced by providing them with means to communicate with the outside world, for instance using the internet independently. Using pictographs instead of text is one of such means. This paper presents a system which performs text simplification by translating text into pictographs. The proposed system consists of a set of phases. First, a simple summarization technique is used to decrease the number of sentences before converting them to pictures. Then, text preprocessing is performed including processes such as tokenization and lemmatization. The resulting text goes through a spelling checker followed by a word sense disambiguation algorithm to find words which are most suitable to the context in order to increase the accuracy of the result. Clearly, using WSD improves the results. Furthermore, when support vector machine is used for WSD, the system yields the best results. Finally, the text is translated into a list of images. For testing and evaluation purposes, a test corpus of 37 Basic English sentences has been manually constructed. Experiments are conducted by presenting the list of generated images to ten normal children who are asked to reproduce the input sentences based on the pictographs. The reproduced sentences are evaluated using precision, recall, and F-Score. Results show that the proposed system enhances pictograph understanding and succeeds to convert text to pictograph with precision, recall and F-score of over 90% when SVM is used for word sense disambiguation, also all these techniques are not combined together before which increases the accuracy of the system over all other studies.
Natural language processing, pictographic communication, social inclusion, Text simplification, text summarization, word sense disambiguation
Short address: https://sciup.org/15016371
IDR: 15016371 | DOI: 10.5815/ijitcs.2019.07.04
Text of the scientific article Automating text simplification using pictographs for people with language deficits
Published Online July 2019 in MECS
Allowing children or people with cognitive disabilities to easily and smoothly use the internet or any other information resource helps reduce their social isolation and thus increases their quality of life. Augmentative and Alternative Communication (AAC) [1] helps people with communication disabilities to be more socially active in interpersonal communication, learning, education, community activities, employment, and care management. Some kinds of AAC are part of everyday communication even for normal people. For example, a human can wave goodbye or give a ‘thumbs up’ instead of speaking. However, some people have to rely on AAC most of the time. Pictographic communication systems are considered to be a form of AAC technology that relies on the use of graphics, such as drawings, pictographs, and symbols. Systems based on AAC include Blissymbolics1, PCS2, Beta3, and Sclera4 [2].
Text simplification for specific readers (e.g. children) can be defined more broadly to include conceptual simplification where the content is simplified as well as form, Elaborative modification where redundancy and explicitness are used to emphasize key points, Text summarization to reduce text length by omitting peripheral or inappropriate information.
The main objective of these operations is to make information more accessible to people with reduced literacy. Using imagery can make learning easier, more enjoyable and interesting. Representing information in visual form helps remembering it in the future due to the brain’s inherent preference of remembering images more easily than text.
This paper is organized as follows: section 2 presents a brief background about the approaches of text simplification and the related work. Section 3 gives a detailed description of the proposed system, followed by a motivational example and experimental evaluation in section 4. Finally, section 5 contains the conclusion and the future work.
-
1 http://www.blissymbolics.org/
-
2 http://www.mayer-johnson.com/category/symbols-and-photos
-
3 http://www.betavzw.be
-
4 http://www.sclera.be
-
II. Related Work
Text simplification (TS) is the process of modifying natural language to reduce its difficulty and enhance both understandability and readability. It may involve lexical and/or syntactic modifications. The automation of this process is a difficult problem which has been discussed from many perspectives [3]. Text simplification has been carried out in multiple ways as shown in Fig. 1. Many systems use some combined approaches to simplify text in different ways. These different methods of TS are largely independent and methodologically different from each other. These methods will be described in the following subsections, focusing on methods that are used in this work.
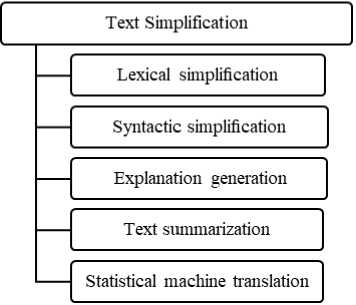
Fig.1. Text simplification approaches
-
A. Lexical Simplification
Lexical simplification is defined as the function of identifying and replacing complex words with simpler ones. This involves no effort to simplify the grammar of a text but instead focusses on simplifying complex sides of vocabulary. There are typically four main steps to lexically simplify the text as shown in Fig. 2 [3].
Identification of complex words
Substitution generation
V
Synonym ranking
Fig.2. Lexical simplification phases
-
B. Syntactic Simplification
Syntactic simplification deals with identifying grammatical complexities in a text and converting them into simpler grammatical constructs that help increase text readability and improve user understanding [4].
-
C. Explanation generation
Explanation generation focuses on simplifying difficult concepts in text by augmenting them with extra information, which puts it into context and improves user understanding. Pictographic communication and word sense disambiguation are the most common techniques used in explanation generation. [5]
-
a. Word Sense Disambiguation
There are a lot of words which have different meanings in different contexts. Word Sense Disambiguation (WSD) is defined as the ability to identify the exact sense of an ambiguous word based on its context. Word sense disambiguation is also seen as an AI-complete problem.
There are various WSD techniques; they are mainly categorized as either knowledge-based (unsupervised) WSD or supervised WSD [6].
-
b. Pictographic communication
Pictographs are known as an efficient means for text simplification. “A pictogram is better than a label, and recognizing image is easier than reading text”. Pictographic communication related work will be explained in detail in the next section. [7].
-
D. Text Summarization
Text summarization is defined as decreasing the length of a text document to create a short summary of the original document. Many variables should be taken into account to create a meaningful summary, such as writing style, syntax, and length [8].
-
E. Statistical machine translation
Statistical machine translation (SMT) is a machine translation paradigm where translations are generated on the basis of statistical models whose parameters are derived from the analysis of bilingual text corpora [3].
Few researchers have dealt with the task of translating text to pictographs till the time of writing this paper. Frommberge and Waidyanatha [9] show that pictographs can be an important means to communicate information about natural disasters to people that are lacking the capability to understand written text. This does not only include illiterates, but also foreigners who do not speak the local language.
Sevens et al. [10] introduce a text-to-pictograph conversion application using word sense disambiguation. They introduced a WSD application in a Dutch text-to-pictograph conversion system that converts text messages into a list of images. The system is used as an online environment for augmentative and alternative communication (AAC). In the old conversion process, the appropriate sense of a word was not disambiguated before converting it into an image. This often results in a wrong and ambiguous conversion. A better understanding and translation of the input text messages can be increased by adding a suitable WSD approach.
On the other hand, Vandeghinste and Schuurman [11] describe linking Sclera pictographs with synonym sets in a lexical-semantic database. Pavalanathan and Eisenstein [12] show that online writing lacks the non-verbal cues present in face-to-face communication, which provide additional contextual information about the speech, such as the speaker's intention. To fill this gap, a number of orthographic features, such as emoticons, expressive lengthening, and non-standard punctuation have become popular in social media services including Facebook and Twitter.
Korpi and Ahonen-Rainio [13] proved that pictographic symbols are widely used in different kinds of environments because of their potential in delivering complex messages easily. However, if these pictographic symbols are not properly designed, they fail to deliver the intended message. They formulate a set of graphic and semantic qualities that contribute to the overall quality of the symbols.
Dyches et al. [14]present a case study that focuses on skill generalization following instruction of an teenager girl with multiple disabilities using two augmentative and alternative communication (AAC) devices.
Leong et al. [15] describe a system for the automatic text to picture translation of simple sentences. They use Word-Net as a lexical database, but they do not use the WordNet relations between concepts. Furthermore, their proposed system does not translate the whole text and they make use of word sense disambiguation in a simple way. Moreover, the effectiveness of WSD within the context of a pictograph translation system was not evaluated. Authors of [16,17] show that WSD can enhance machine translation by using probabilistic methods that select the most likely translation phrase.
-
III. Proposed System
This paper introduces a system which enables people with language deficits to communicate with others. An overview of the architecture of this system is presented in Fig. 3. Given a text to be simplified, the proposed system performs text simplification through four main phases:
-
A. Text Summarization
In this work, we use the classical statistical approach based on significant words occurrence statistics to summarize input text. Sentences containing words that occur more frequently than others in the text have a higher weight. These sentences are considered more important than others and are hence extracted [18].
-
B. Shallow Linguistic Analysis
The summarized text undergoes shallow linguistic analysis including tokenization, part-of-speech tagging, sentence splitting, and lemmatization. We first perform sentence detection using the the nltk.tokenize.punkt package found in NLTK toolkit [19]. Then, the text goes through tokenization, splitting of all the punctuation signs from the words, apart from the hyphen/dash and the apostrophe, using a rule-based tokenizer in the nltk.tokenize package. Word-based spelling correction is then performed based on an altered version of Peter Norvig’s spelling corrector. Part-of-speech tagging is performed using nltk.pos_tag [20]. Apart from the lexicon lookup procedure, we use a rule-based lemmatizer [21] package that takes the token and part-of-speech tag as input and returns the lemma.
-
C. Determine the route
The system searches for the word in a database to determine the right route that should be taken for that word, a direct route or semantic route.
-
• Direct Route
In the direct route, lemmas are converted to pictures directly without any extra work. For example, subjects and pronouns will be translated directly to pictures.
-
• Semantic Route
On the other hand, the semantic route will handle words that are neither subjects nor pronouns, and hence need more work. Synonyms (synsets) of all word lemmas are extracted and a WSD technique is applied to determine the most appropriate synsnet for each word. WordNet is used as the lexical database for synset extraction.
Four word sense disambiguation techniques are compared in the context of our work [22]:
-
1. Simplified Lesk: disambiguates words in short phrases. The gloss (brief description) of each word sense in a phrase is compared to the glosses of every other word in the phrase. A word is assigned the sense whose gloss shares the greatest number of words in common with the glosses of the other word. Simplified Lesk relies on glosses existing in traditional dictionaries [23].
-
2. Adapted Lesk: is a modification of Lesk’s basic approach where relations between synonyms that WordNet offers are considered [22].
-
3. Max similarity: this technique depends on context. Glosses contexts are similar if they contain similar words. In addition, words are in a single similarity group if they appear in similar contexts [22].
-
4. Support Vector Machine (SVM): SVM is a large-margin classifier for machine learning based on vector space where the main goal is to get a decision boundary between two classes that are maximally far from any point in the training data [24].
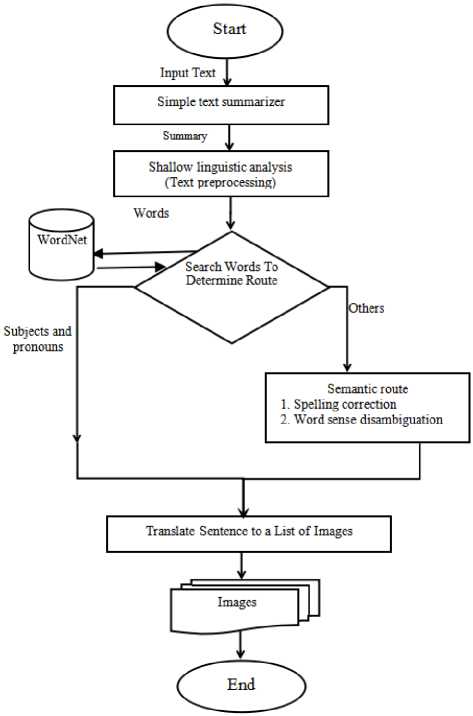
Fig.3. The proposed system
-
D. Sentence Translation
Sentences are translated into pictographs. We look up for the suitable image in ImageNet based on its offset id retrieved from WordNet. The mapping will be described in detail in section 5.2. The system also handles tenses and differentiates between singular and plural using specific images.
-
IV. Experiments and Results
This section starts with describing the dataset and tools used for conducting our experiments. An illustrative example is, then, presented to clarify the experiments. The results of using five approaches are compared using precision, recall and F-score.
-
A. Data Set
One of the problems of automated text simplification research is that there is no standard dataset that can be used for assessment. Because of the variety of the intended audience (for example: children, students learning a foreign language or people with intellectual disabilities) and data copyright protection, finding a suitable dataset is not easy. For the purpose of this study, a test corpus of 37 basic English sentences has been manually constructed [25].
-
B. Used Tools
-
a. Natural Language Toolkit (NLTK)
NLTK is a platform used for building natural language Python applications. It gives the user easy-to-use classes along with various packages that handle most of text processing functions such as tagging, tokenization, parsing, classification, stemming and semantic reasoning [26].
-
b. WordNet
WordNet is one of the largest lexical databases for English in which verbs, nouns, adjectives, and adverbs are classified into groups (sets) of cognitive synonyms which are called synsets [27]. Synsets are linked to each other by lexical relations and conceptual-semantics. The structure of WordNet makes it a useful tool for natural language processing and computational linguistic research.
-
c. Image Net
ImageNet is a large visual database project implemented for use in visual object recognition software research area. ImageNet contains a huge number of annotated images. The database of annotations of third-party image URLs is freely available through ImageNet. However, the actual images are not owned by ImageNet.
ImageNet is based on WordNet structure to easily identify a synset. WordNet ID (wnid) is used to differentiate between synsets. Wnid is the concatenation of synset-offset of WordNet and POS (part of speech). Currently, ImageNet considers only nouns, so every wnid starts with "n" [28]. Verbs are handled by the system separately because ImageNet does not contain images for verbs till the time of writing this paper. All the verbs that are used in the input dataset have been manually listed to complete the testing process. Some of those verbs (drink, drive, sing, draw, open, run, read) are shown in Fig. 4.

Drink
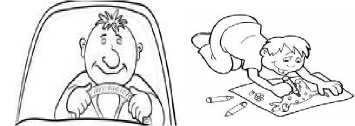
Drive
Draw

Sing

Run
Read
Fig.4. Sample images for verbs
-
C. Experiments and Evaluation
Experiments are conducted by presenting the list of images produced by our system to ten normal children aged from 7 to 11 as shown in the illustrative example below. The children are requested to guess the input statement. The correctness of their guessing is evaluated using precision, recall, and F-Score calculation, compared with the original sentence [29].
-
a. Illustrative Example
Illustrative examples have been presented in Table 1 to show sample sentences with their precession, recall and F-score values followed by a figure for each sentence to show resulted images.
-
• The first sentence “I read a book” is translated accurately since it does not include any words with multiple meaning, List of output images shown below in Fig.5
-
• However, in the second sentence “A cat eats a fish”, the word “cat” is translated into “leaf” as it is one of the meanings of “cat” in WordNet. The clock
represents the tense of the verb in the sentence, List of output images shown below in Fig.6.
-
• In the third sentence “I love my home”, the word “home” is translated into “baseball” as it is one of the meanings of “home” in WordNet. The clock represents the tense of the verb in the sentence, List of output images shown below in Fig.7.
-
• In the last sentence “I love dogs”, the word “dogs” is translated into “car wheels” as it is one of the meanings of “dogs” in WordNet. The clock represents the tense of the verb in the sentence, List of output images shown below in Fig.8.
-
b. Evaluation of Results
Precision, recall and F-Score are used for evaluating the results of our experiments. Precision is the fraction of relevant instances among the retrieved instances, while recall is the fraction of relevant instances that have been retrieved over the total amount of relevant instances. Both precision and recall are therefore based on an understanding and measure of relevance [30].
Table 1. Illustrative example
|
Example |
Input |
Output by kids |
Precision |
Recall |
FScore |
|
1 |
I read a book |
I read a book |
1 |
1 |
1 |
|
2 |
A cat eats a fish |
A tree leaf eats a fish |
.66 |
.8 |
0.727 |
|
3 |
I love my home |
I love baseball |
.66 |
.5 |
0.571 |
|
4 |
I love dogs |
I love car wheels |
.5 |
.66 |
0.571 |

Fig.7. output images

Fig.8. output images
For classification tasks, the terms true positives, true negatives, false positives, and false negatives compare the results of the classifier under test with trusted external judgments. The terms positive (P) and negative (N) refer to the classifier's prediction, and the terms true and false refer to whether that prediction corresponds to the external judgment. A true positive (TP) result refers to a hit while a true negative (TN) result refers to correct rejection. On the other hand, a false positive (FP) result reflects a false alarm and a false negative (FN) result reflects a miss.
Precision - Precision is the ratio of correctly predicted positive results to the total predicted positive results.
Precision =
TP
( TP + FP )
Recall - Recall is the ratio of correctly predicted positive results to the all results in actual class (sensitivity).
Recall =
TP
(TP + FN )
2 x ( Recall x Precision )
F Score =-------------------- (3)
( Recall + Precision )
Results of sample sentences are shown in tables 2 to 6.
Table 2 shows the results obtained when sentences are split into lemmas and without using any WSD technique. Table 3 to 6 show the results obtained for the same sample sentences using different WSD techniques. In tables 3 to 6, sentences are split into lemmas, the tense is preserved and both and singular nouns are considered. Then, four WSD techniques are applied; namely original lesk, adapted lesk, max similarity and Support vector machine (SVM). The word “cat”, for example, has multiple synonyms in WordNet and only one of them will be selected based on the used WSD technique. The synonyms include
-
• true cat (feline mammal usually having thick soft fur and no ability to roar)
-
• African tea (the leaves of the shrub Catha edulis which are chewed like tobacco or used to make tea.
-
• Caterpillar, cat (a large tracked vehicle that is propelled by two endless metal belts; frequently used for moving earth in construction and farm work)
-
• guy, cat, hombre, bozo, sod (an informal term for a
youth or man)
-
• big cat, cat (any of several large cats typically able to roar and living in the wild).
Table 7 presents the overall results of analyzing the translation quality of the data set using precision, recall, and f-score measurements for the five sets of experiments. Clearly, using WSD improves the results. Furthermore, when support vector machine is used for WSD, the system yields the best results.
F- Score is the weighted average of Precision and Recall.
Table 2. Sample test results when splitting the sentence into lemmas and without using WSD
|
Input sentence |
Output sentence |
Precision |
Recall |
F-Score |
|
A cat drinks some milk |
a, tree, leaves, select, a, milk |
0.50 |
0.60 |
0.545 |
|
I walk on the street |
I, walk, the, people |
0.75 |
0.60 |
0.667 |
|
It is a window |
It, is, a, glass |
0.75 |
0.75 |
0.75 |
|
A cat sleeps in the basket |
a, tree, leaves, slept,basket ball |
0.20 |
0.166 |
0.182 |
|
It is a cat |
It, is, a, tree, leaves |
0.60 |
0.75 |
0.667 |
|
I open the door |
I, opened, the, door |
0.75 |
0.75 |
0.75 |
|
A cat eats a fish |
a, tree, leaves,eats, a, fish |
0.66 |
0.80 |
0.727 |
|
I wear a t-shirt |
I, wear, a, t-shirt |
1 |
1 |
1 |
Table 3.Sample test results when using simplest WSD (original lesk) considering plural nouns and tenses
|
Input sentence |
Output sentence |
Precision |
Recall |
F-Score |
|
A cat drinks some milk |
a, youth, term, drinks, alcohol, milk |
0.6666 |
0.80 |
0.727 |
|
I walk on the street |
I, live,in ,the, street |
0.80 |
0.80 |
0.8 |
|
It is a window |
It, is, a, time, period |
0.75 |
0.75 |
0.75 |
|
A cat sleeps in the basket |
a, guy, sleeps, in , basketball ,net |
0.50 |
0.50 |
0.5 |
|
It is a cat |
It, is, a, guy |
0.75 |
0.75 |
0.75 |
|
I open the door |
I, open, the, door |
1 |
1 |
1 |
|
A cat eats a fish |
a, guy, eats, a, fish |
0.80 |
0.80 |
0.8 |
|
I wear a t-shirt |
I, wear, a, shirt |
1 |
1 |
1 |
Table 4.Sample test results when using Adapted lesk considering plural nouns and tenses
|
Input sentence |
Output sentence |
Precision |
Recall |
F-score |
|
A cat drinks some milk |
a, tree, leaves, select, a, milk |
0.50 |
0.60 |
0.545 |
|
I walk on the street |
I ,walk, on, the, street |
1 |
1 |
1 |
|
It is a window |
It, is, a, glass |
0.75 |
0.75 |
0.75 |
|
A cat sleeps in the basket |
a, tree, leaves, sleeps , basketball |
0.40 |
0.3333 |
0.364 |
|
It is a cat |
It, is, a, tree, leaves |
0.60 |
0.75 |
0.667 |
|
I open the door |
I, open, the, door |
1 |
1 |
1 |
|
A cat eats a fish |
a, tree, leaves, eats, a, fish |
0.6666 |
0.80 |
0.727 |
|
I wear a t-shirt |
I, wear, a, t-shirt |
1 |
1 |
1 |
Table 5. Sample test results when using Max Similarity considering plural nouns and tenses
|
Input sentence |
Output sentence |
Precision |
Recall |
F-Score |
|
A cat drinks some milk |
a, cat, drinks, alcohol, a milk |
0.833 |
1 |
0.909 |
|
I walk on the street |
I, walk, the, street |
1 |
1 |
1 |
|
It is a window |
It, is, a, hole |
0.84 |
1 |
0.89 |
|
A cat sleeps in the basket |
a, cat, sleeps, in, the, basketball |
0.90 |
1 |
0.95 |
|
It is a cat |
It, is, a , cat |
1 |
1 |
1 |
|
I open the door |
I, open, the, door |
1 |
1 |
1 |
|
A cat eats a fish |
a, cat, eats, a fish |
1 |
1 |
1 |
|
I wear a t-shirt |
I, wear, a, t-shirt |
1 |
1 |
1 |
Table 6. Sample test results when using SVM considering plural nouns and tenses
|
Input sentence |
Output sentence |
Precision |
Recall |
F-Score |
|
A cat drinks some milk |
a, cat, drinks, alcohol, a milk |
0.833 |
1 |
0.909 |
|
I walk on the street |
I, walk, the, street |
1 |
1 |
1 |
|
It is a window |
It, is, a, window |
1 |
1 |
1 |
|
A cat sleeps in the basket |
a, cat, sleeps, in, the, basket |
1 |
1 |
1 |
|
It is a cat |
It, is, a , cat |
1 |
1 |
1 |
|
I open the door |
I, open, the, door |
1 |
1 |
1 |
|
A cat eats a fish |
a, cat, eats, a fish |
1 |
1 |
1 |
|
I wear a t-shirt |
I, wear, a, t-shirt |
1 |
1 |
1 |
Table 7. comparison of used WSD techniques
|
Lemma |
Original Lesk |
Adapted Lesk |
Max Similarity |
SVM |
|
|
Precision |
0.71 |
0.73 |
0.79 |
0.90 |
0.95 |
|
Recall |
0.72 |
0.72 |
0.81 |
0.88 |
0.93 |
|
F-Score |
0.84 |
0.72 |
0.80 |
0.89 |
0.94 |

Fig.5. output images

Fig.6. output images
-
V. Conclusion and Future Work
Our study shows that social involvement of children, as well as people with intellectual disabilities, can be promoted by providing them with means to communicate with the outside world. The presented system improves the accuracy of text understanding by converting text into pictographs in terms of precision, recall and F-score.
Also, it is clear from the evaluation that our system provides an improvement in the communication possibilities, although further improvements are possible.
The proposed system proves the importance of using text summarization in text simplification. Results are improved using WSD. Four different approaches for WSD have been tested in the context of our system; namely original lesk, adapted lesk, max similarity and SVM. The results obtained using SVM outperformed the other approaches.
Our work can be enhanced by applying a better word sense disambiguation algorithm to increase the accuracy of the retrieved word as well as better spelling correction techniques. Searching time can also be decreased by using, for instance, the A* algorithm that is widely used in shortest path finding in graph-traversal.
References Automating text simplification using pictographs for people with language deficits
- Communication Matters accessed on https://www.communicationmatters.org.uk/page/what-is-aac
- V. VANDEGHINSTE, I. SEVENS, and F. VAN EYNDE, “Translating text into pictographs,” Natural Language Engineering, vol. 23, no. 2, pp. 217–244, 2017.
- M. Shardlow, “A Survey of Automated Text Simplification,” Int. J. Adv. Comput. Sci. Appl. Spec. Issue Nat. Lang. Process., pp. 58–70, 2014.
- Siddharthan, “Syntactic Simplification and Text Cohesion (Thesis),” J. Laparoendosc. Adv. Surg. Tech. A, vol. 20, no. 10, pp. 1–31, 2004.
- M. Molineaux, M. Molineaux, K. Com, D. Aha, and N. R. L. Navy, “Continuous Explanation Generation in a Multi-Agent Domain,” vol. 2015, no. Article 1, pp. 1–6, 2015.
- R. Antunes and S. Matos, “Supervised Learning and Knowledge-Based Approaches Applied to Biomedical Word Sense Disambiguation,” J. Integr. Bioinform., vol. 14, no. 4, pp. 1–8, 2017.
- Tijus, J. Barcenilla, B. Cambon de Lavalette, and J. Meunier. "Chapter 2: The Design, Understanding and Usage of Pictograms". In Written Documents in the Workplace, (Leiden, The Netherlands: BRILL, 2007) doi: https://doi.org/10.1163/9789004253254_003
- Das and A. F. T. Martins, “A Survey on Automatic Text Summarization,” Eighth ACIS Int. Conf. Softw. Eng. Artif. Intell. Netw. ParallelDistributed Comput. SNPD 2007, vol. 4, pp. 574–578, 2007.
- L. Frommberger and N. Waidyanatha, “Pictographs in Disaster Communication for Linguistically Challenged and Illiterate Populations,” Int. J. Inf. Syst. Cris. Response Manag., vol. 9, no. 2, pp. 37–57, 2017.
- L. Sevens, G. Jacobs, V. Vandeghinste, I. Schuurman, and F. Van Eynde, “Improving Text-to-Pictograph Translation Through Word Sense Disambiguation,” Proc. Fifth Jt. Conf. Lex. Comput. Semant., pp. 131–135, 2016.
- V. Vandeghinste and I. Schuurman, “Linking Pictographs to Synsets : Sclera2Cornetto,” pp. 3404–3410, 2008.
- U. Pavalanathan and J. Eisenstein, “Emoticons vs. Emojis on Twitter: A Causal Inference Approach,” 2015.
- J. Korpi and P. Ahonen-Rainio, “Design Guidelines for Pictographic Symbols : Evidence from Symbols Designed by Students,” Conf. Pap. EuroCarto 2015, no. November, pp. 1–19, 2015.
- T. Dyches, A. Davis, B. Lucido & J. Young. Generalization of skills using pictographic and voice output communication devices. 18. 124-131. 10.1080/07434610212331281211, 2002.
- W. Leong, R. Mihalcea, and S. Hassan, “Text Mining for Automatic Image Tagging,” Coling, no. August, pp. 647–655, 2010.
- M. Carpuat and D. Wu, “Improving statistical machine translation using word sense disambiguation,” Emnlp-2007, no. June, pp. 61–72, 2007.
- C. Chiang and Y. Chan, “Word Sense Disambiguation Machine Translation,” no. June, pp. 33–40, 2007.
- H. P. Luhn, "The Automatic Creation of Literature Abstracts," in IBM Journal of Research and Development, vol. 2, no. 2, pp. 159-165, Apr. 1958. doi: 10.1147/rd.22.0159 URL: http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=5392672&isnumber=5392664
- T. Kiss, & J. Strunk. Unsupervised Multilingual Sentence Boundary Detection. Computational Linguistics. 32. 485-525. 10.1162/coli.2006.32.4.485, 2006.
- S. Bird and E. Loper, “The natural language toolkit NLTK: The Natural Language Toolkit,” Proc. ACL-02 Work. Eff. tools Methodol. Teach. Nat. Lang. Process. Comput. Linguist., no. March, pp. 63–70, 2016.
- J. Plisson, N. Lavrac, and D. D. Mladenić, “A rule based approach to word lemmatization,” Proc. 7th Int. Multiconference Inf. Soc., no. November, pp. 83–86, 2004.
- A. Ranjan Pal and D. Saha, “Word Sense Disambiguation: A Survey,” Int. J. Control Theory Comput. Model., vol. 5, no. 3, pp. 1–16, 2015.
- M. Lesk, “Automatic Sense Disambiguation Using Machine Readable Dictionaries: How to Tell a Pine Cone from an Ice Cream Cone,” Proc. 5th Annu. Int. Conf. Syst. Doc., pp. 24–26, 1986.
- Y. K. Lee, H. T. Ng, and T. K. Chia, “Supervised word sense disambiguation with support vector machines and multiple knowledge sources,” Senseval-3 Third Int. Work. Eval. Syst. Semant. Anal. Text, no. July, pp. 137–140, 2004.
- “300 Basic English Sentences,” pp. 1–19. NLTK book accessed on https://www.nltk.org/book/
- G. a. Miller, “WordNet: a lexical database for English,” Commun. ACM, vol. 38, no. 11, pp. 39–41, 1995.
- Jia Deng, Wei Dong, R. Socher, Li-Jia Li, Kai Li, and Li Fei-Fei, “ImageNet: A large-scale hierarchical image database,” 2009 IEEE Conf. Comput. Vis. Pattern Recognit., pp. 248–255, 2009.
- [Online] precision and recall. Accessed on http://www.dcode.fr/precision-recall.
- P. Resnik and J. Lin, “Evaluation of NLP Systems,” Handb. Comput. Linguist. Nat. Lang. Process., pp. 271–295, 2010.
