Deep Learning and Digital Literacy: A Systematic Literature Network and Bibliometric Review

Author: Deep Learning, Digital Literacy, SLNA, Topic Modeling, LDA
Journal: International Journal of Modern Education and Computer Science @ijmecs
Article in issue: 3 vol.18, 2026.
Free access
This study examines the integration of computational deep learning and digital literacy from 2011 to June 2025. Employing a hybrid methodology of Systematic Literature Network Analysis and Latent Dirichlet Allocation topic modeling, 141 high impact documents were synthesized following the PRISMA 2020 protocol. Findings reveal a conceptual shift from technical exploration (2011–2018) toward human-centric, pedagogical deep learning frameworks (2019–2025). While publications peaked in 2024, Australia and South Korea emerged as leading centers of excellence in citation impact. Latent Dirichlet Allocation modeling identified ten topics, uncovering a significant research gap in using AI for fundamental research processes compared to its dominance in instructional assessment. This study provides a novel mapping of thematic evolution and offers strategic recommendations for longitudinal empirical studies and inclusive AI-driven pedagogical designs.
Deep Learning, Digital Literacy, SLNA, Topic Modeling, LDA
Short address: https://sciup.org/15020357
IDR: 15020357 | DOI: 10.5815/ijmecs.2026.03.05
Text of the scientific article Deep Learning and Digital Literacy: A Systematic Literature Network and Bibliometric Review
In recent years, the integration of deep learning approaches in the context of education has become a major focus
This work is open access and licensed under the Creative Commons CC BY 4.0 License.
of research, particularly due to its significant potential in enhancing digital literacy skills. Historically, digital literacy was conceptualized as the ability to understand and use information in multiple formats [1, 2, 3] As educational systems increasingly adopt digital transformation, deep learning is recognized as a key driver in shaping 21st-century competencies, such as critical thinking, problem-solving, and adaptive learning [4, 5, 6].
A meta-analysis review of empirical publications found that digital technology has a positive impact on students' deep learning outcomes. This effect varies depending on the type of digital tools used, but overall, it supports higher engagement and stronger conceptual understanding, with key components in the development of digital literacy [5, 7, 8, 9, 10, 11, 12]. Therefore, it is important to evaluate how specific technologies can contribute to enhancing learning outcomes. This shift is closely aligned with the theory of connectivism, which posits that learning in the digital age is a process of connecting specialized nodes or information sources [13]. Research also shows a strong correlation between pedagogical deep learning and higher-order thinking skills, both of which significantly support students' digital literacy [14]. These findings suggest that educators need to guide students in selecting and applying deep learning strategies to strengthen their digital competencies [15, 16, 17, 18]. The ability to transfer knowledge, synthesize information, and critically evaluate digital content becomes the foundation of effective digital literacy in the modern era.
The ongoing digitalization of the learning process makes digital literacy a key requirement for academic success and workforce competitiveness. Studies show that digital literacy is not only influenced by access to technology but also by broader educational factors such as 21st-century skills training and academic achievements [19, 20, 21, 22]. Therefore, integrating deep learning into the curriculum becomes a strategic pathway in preparing students to navigate the dynamic digital environment.
In addition to its cognitive benefits, pedagogical deep learning also fosters intrinsic motivation, the development of lifelong learning habits, as well as reflective and solution oriented thinking characteristics that align with education for sustainable development [23]. These skills enhance students' capacity to navigate digital complexities and adapt to the continuously evolving technological context. However, the implementation of deep learning is not without challenges. The level of students' digital experience plays a crucial role in determining the effectiveness of this approach. Therefore, contextualized learning design and continuous pedagogical support are essential to ensure that all students can derive optimal benefits from this advanced learning strategy [24].
Looking toward the future, recent studies highlight the potential of intelligent systems in creating adaptive learning environments and dynamic evaluation models. These technologies, including learning analytics and generative AI, offer promising new frameworks for enhancing digital literacy through personalized instruction [23, 25]. This vision follows the foundational argument that AI possesses the capacity to 'unleash' human intelligence by providing deeper pedagogical insights [26] . Furthermore, improving digital literacy among adult learners is becoming an increasing focus. Further research, policies, and educational programs are essential to provide large-scale solutions that extend beyond the boundaries of formal education systems [27]. In this context, AI-based deep learning offers a flexible foundation that can be leveraged in various digital literacy initiatives, especially when linked to broader digital inclusion agendas.
To address this gap, this study uses the combined methodology of Systematic Literature Network Analysis (SLNA) and content analysis. The adoption of bibliometric mapping is guided by established frameworks for conducting rigorous literature evaluations, utilizing specialized software tools for visual exploration [28]. This study examines publications from 2011 to June 2025; the inclusion of 2025 publications is justified as these represent 'Early Access' or 'In-Press' articles that have been peer-reviewed and indexed in the Scopus database.
In clarifying the conceptual framework, it is important to distinguish between two different epistemological constructions of 'Deep Learning'. In the pedagogical domain, pedagogical deep learning is defined as an approach where students critically analyze and integrate new information to foster high-level thinking. In contrast, in the computing domain, computational deep learning refers to an advanced subset of Artificial Intelligence (AI) based on multi-layered Artificial Neural Networks (ANNs). This manuscript specifically focuses on how the integration of computational Deep Learning (AI) in educational frameworks can enhance students' pedagogical deep learning and digital literacy.
2. Methodology
This study employs a combined approach of Systematic Literature Network Analysis (SLNA) and content analysis to conduct a thorough review of the application of deep learning approaches in enhancing digital literacy. The integration of these two methodologies is considered more effective and in-depth compared to relying solely on a systematic literature review (SLR) or bibliometric analysis (BA) individually [29]. SLNA is applied to identify research trends that have evolved both in the past and present, uncover the key topics within the field, and analyze potential research gaps that can be explored further in the future [30]. Meanwhile, content analysis allows for a deeper understanding of emerging global research themes and the latest relevant findings [31].
The research begins with metadata collection according to the PRISMA 2020 protocol, followed by bibliometric network analysis using VOSviewer [28], and mapping and classification of qualitative content through Orange Data Mining [32]. An overview of the methodology flow is shown in Figure 1, illustrating the main stages of SLNA and content analysis applied in this study.
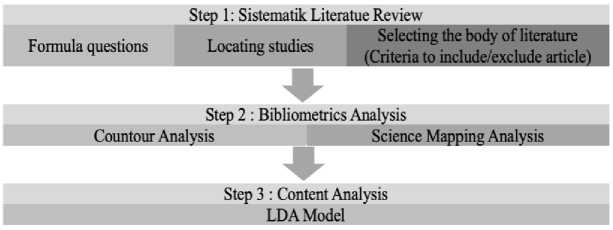
Fig. 1. Stage Of SLNA.
The initial stage involves the application of PRISMA 2020, which serves as the standard framework for conducting a systematic review [33]. The search was conducted through the Scopus database, chosen for its extensive coverage and high academic credibility [34]. Scopus was selected as the primary data source due to its comprehensive indexing of high-impact journals across both social sciences and engineering, which is essential for a study intersecting pedagogy and deep learning technology. Furthermore, Scopus provides robust metadata that ensures high compatibility with bibliometric analysis tools, maintaining data integrity during citation mapping.
The literature search spanned from 2011 to June 2025. The inclusion of publications through mid-2025 is justified as it captures 'Early Access' or 'In-Press' articles that were peer-reviewed and indexed prior to the manuscript finalization. This ensures the inclusion of the most contemporary trends in Deep Learning and Digital Literacy. The search utilized a specific keyword string:
(“Digital Literacy" OR "Digital literacy education" OR "Digital" OR "Literacy") AND ("Deep Learning" OR "Deep Learning Education") AND ("Education" OR "Teach" OR "Learn").
The systematic selection process followed PRISMA 2020 guidelines to ensure transparency, as illustrated in Figure 2. Initially, 2,984 records were identified. After removing 412 duplicates, 2,572 articles underwent title and abstract screening. Of these, 2,385 were excluded due to a lack of alignment with research goals. Subsequently, 187 reports were sought for full-text assessment, where 46 articles were excluded based on specific criteria:
-
i. Lack of educational setting focus n = 22
-
ii. Purely technical AI algorithm focus without pedagogical application n = 14
-
iii. Non-English publications n = 10

Records identified from *:
Scopus Database (n= 2,984)

Records Remove before screening - Duplicate records removed (n=412)
- Records marked as ineligible by automation tools (n=0)

Reports sought for retrieval (n=187) Reports assessed for eligibility (n=187)
Reports excluded
(n=46)
- Not in educational context (n—22)
- Technical algorithm focus (n=14)
- Non English (n=10)


-
3. Result and Discussion
-
3.1. Peformance Analysis
This section presents a quantitative and qualitative assessment of the research landscape based on metadata retrieved from the Scopus database. A total of 141 eligible articles investigating the intersection of computational deep learning and digital literacy were analyzed. As illustrated in Figure 4, the publication volume experienced notable fluctuations before entering a period of rapid growth. Between 2011 and 2018, the field remained in its nascent stage, with document counts ranging sporadically between 1 and 5 per year. However, a significant upward trajectory began in 2019 with 10 documents, followed by steady growth reaching its zenith in 2023 (25 documents) and 2024 (28 documents). Interestingly, 2025 has already recorded 25 documents by mid-year, indicating that the annual total is poised to exceed previous records. This sustained growth reflects the heightening academic urgency and global interest in utilizing AI-based deep learning to enhance pedagogical outcomes in digital literacy.
-
Fig. 2. PRISMA Flow diagram outlining the systematic literature search and selection process for Deep Learning in Digital Literacy.
To ensure methodological rigor and minimize selection bias, the screening of titles and abstracts was performed independently by the authors responsible for data curation and literature review (Author 2 and Author 5). The full-text eligibility assessment was further validated by the author in charge of model validation (Author 3). Any discrepancies during the selection process were resolved through consultation with the supervisor (Author 1), who acted as a third-party adjudicator. This rigorous double-blind screening and validation process ensured high inter-rater reliability, resulting in a final selection of 141 eligible articles.
After the filtering process, the data set was exported in .ris format and processed in two main stages: Systematic Literature Network Analysis (SLNA): Conducted using VOSviewer software to generate a bibliometric map based on publication sources, affiliated countries, and keyword co-occurrence patterns. Content Analysis and Topic Modeling: Carried out using the Orange Data Mining platform. This stage involved text preprocessing, word frequency distribution, and the application of the LDA (Latent Dirichlet Allocation) model to explore core research themes, as visualized in the technical workflow in Figure 3.
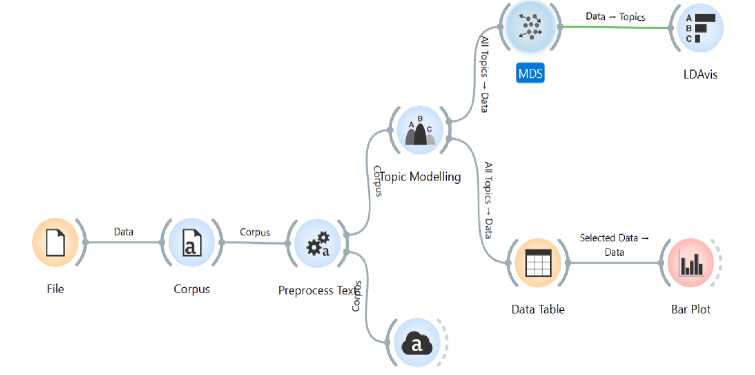
Word Cloud
Fig. 3. Topic Modelling Through The Corpus: Title and Abstract
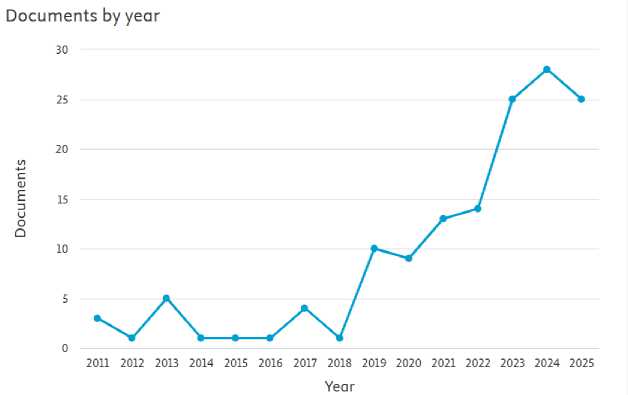
Fig. 4. Number of Publications Each Year.
Beyond annual trends, this study identifies the journals driving the thematic evolution of the field. Based on Figure 5, five journals emerged as the most productive. Computers and Education led with 6 publications, maintaining a consistent presence since 2012. Education and Information Technologies followed with 6 publications, notably contributing 4 articles in 2024 alone. Other key contributors include Artificial Intelligence Review (5 articles), BMC Medical Education (4 articles), and Education Sciences (4 articles). The distribution across these venues suggests that deep learning in education is no longer confined to technical computer science journals but has successfully permeated medical education and general social sciences, reflecting a truly interdisciplinary adoption.
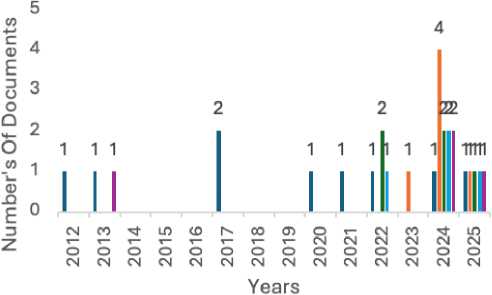
Fig. 5. Articles each year that match the topic and top journals.
-
■ Computers and Edu cation
-
■ Education and Information Technologies
-
■ Education and Information Technologies
-
■ BM C Med ical Education
-
■ Education Sciences
From the 141 analyzed articles, ten countries were identified as the most active contributors. Table 1 integrates the Citation per Document (CPD) ratio to provide a more rigorous assessment of intellectual impact beyond simple document counts. While China and the United States dominate in terms of total publication volume (30 and 17 documents, respectively), the CPD analysis reveals a shift in research influence. Notably, Australia (CPD = 97.60) and South Korea (CPD = 94.28) exhibit disproportionately high impact ratios. This suggests that while these nations produce a lower quantitative output, their research serves as foundational, highly-cited references in the field. Conversely, nations with emerging output like Indonesia (CPD = 4.40) indicate a need for greater international collaboration to boost research visibility and quality.
Table 1. Document from each country.
|
Country |
Document (TP) |
Citation (TC) |
CPD (TC/TP) |
|
China |
30 |
318 |
10,60 |
|
United States |
17 |
420 |
24,70 |
|
India |
12 |
267 |
22,25 |
|
Australia |
10 |
976 |
97,60 |
|
Hong Kong |
9 |
188 |
20,88 |
|
South Korea |
7 |
660 |
94,28 |
|
Sweden |
6 |
324 |
54,00 |
|
United Kingdom |
6 |
301 |
50,16 |
|
Indonesia |
5 |
22 |
4,40 |
|
Taiwan |
6 |
181 |
30,16 |
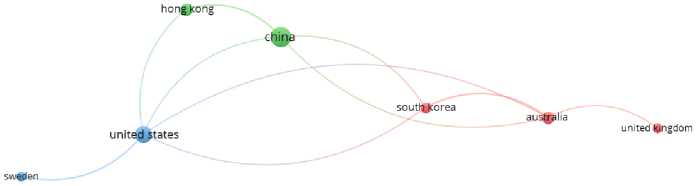
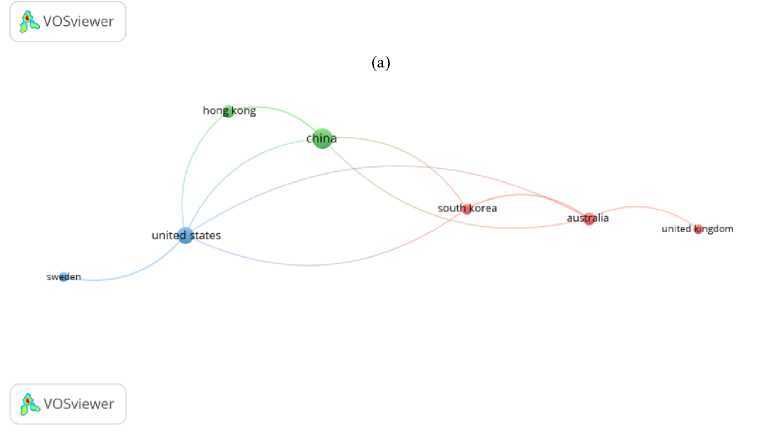
The analysis of country-based co-authorship, visualized in Figures 6 (a) and (b) , reveals the formation of a robust international research network. The network is characterized by three distinct clusters representing regional and strategic partnerships: Cluster 1 (Green): Focuses on high-impact collaboration between Australia, South Korea, and the United States, which correlates with the high CPD ratios observed in Table 1. Cluster 2 (Red): Represents a dominant Asian hub, primarily centered on China and Hong Kong, showing the highest centrality and document volume. Cluster 3 (Blue): Highlights a strategic link between the United States and Sweden, focusing on Western pedagogical contexts. The high level of connectivity between these clusters suggests that the integration of computational deep learning into digital literacy is a global phenomenon, driven by cross-continental knowledge exchange.
(b)
Fig. 6. (a) Co-authorship Based on Affiliation Countries (Overlay) and (b) Co-authorship Based on Affiliation Countries (network visualization).
-
3.2. Mapping Science
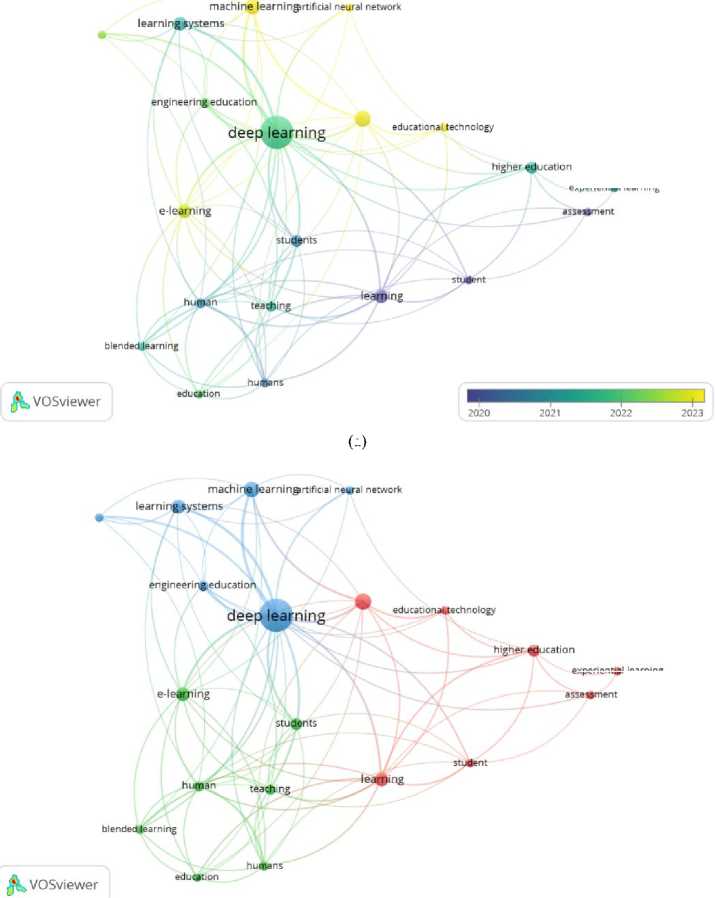
Based on the co-occurrence analysis of keywords visualized in Fig. 7(a) and (b), this study identifies the intellectual pillars and thematic transitions within the research landscape. To ensure a high signal-to-noise ratio, a minimum threshold of n ≥ 5 occurrences was applied. This threshold was strategically chosen to filter out idiosyncratic or peripheral terms that do not significantly contribute to the core thematic structure, thereby ensuring clarity in the data visualization. From an initial pool of over 1,000 extracted keywords, the top 20 keywords were selected based on their Total Link Strength (TLS) to prevent excessive visual fragmentation. This selection allows for a focused interpretation of the most dominant conceptual pillars integrating computational deep learning and digital literacy.
This analysis yielded three primary clusters that reflect the broad thematic structure of the discourse. The first cluster represents the foundational pillars, dominated by terms such as "Artificial Intelligence," "Educational Technology," and "Education," where network centrality measures identify "Digital Literacy" and "Artificial Intelligence" as the primary bridges connecting diverse research clusters. This indicates that these two terms serve as the bedrock integrating pedagogical theory with computational advancements. The second cluster is more process-oriented, marked by the emergence of keywords such as "AI-based deep learning," "experiential learning," and "machine learning," signifying a shift in research direction toward practical applications, including automated assessment and personalized learning environments. Meanwhile, the third cluster the largest group emphasizes technical and systemic dimensions through terms such as "computational deep learning," "artificial neural networks (ANN)," and "learning systems".
A significant thematic evolution is also observed from 2011 to 2025, which can be broadly categorized into two developmental phases. The technical exploration phase (2011–2018) was largely characterized by the use of computational deep learning as a pure computing tool for ICT infrastructure and assessment automation. However, entering the human-centric integration phase (2019–2025), there has been a clear conceptual shift toward critical digital literacy. Recent trends in the 2023–2025 period emphasize ethical AI implications and the use of computational deep learning models to foster higher-order thinking skills, or pedagogical deep learning. This transformation indicates that the field has matured from mere technical implementation into a complex integration of advanced technology and profound educational theory.
experiential learning
(a)
experiences learning
(b)
Fig. 7. (a) Co-occurence (Overlay) and (b) Co-occurence (Network Visualization).
-
3.2.1. Green Cluster: Implementation of Deep Learning and Artificial Neural Network in Adaptive Learning System for Engineering Education
-
3.2.2. Yellow Cluster: The Role of Artificial Intelligence in Personalizing Student Learning and Assessment in the Digital Age
The Green Cluster, which reflects the integration of AI-based Deep Learning and Artificial Neural Networks (ANN) within adaptive learning systems, demonstrates significant potential for enhancing technical education. These technologies facilitate personalized learning experiences by tailoring content through Computational Deep Learningalgorithms. While several studies, such as [35, 36, 37], report that these AI-driven platforms can increase student grades and engagement by up to 25%, we argue that this figure must be interpreted with academic caution.
As researchers, we contend that such substantial gains are likely contingent upon the institutional technical maturity and the students' initial digital literacy levels. A 25% increase may represent an 'ideal-case' scenario in high-resource environments, but it may not be universally replicable without adequate pedagogical scaffolding. Our analysis suggests that the true value of these systems lies not merely in numerical grade inflation, but in the shift toward Pedagogical Deep Learning specifically the attainment of higher-order thinking skills enabled by the platform's adaptive nature.
Furthermore, the application of Natural Language Processing (NLP) within automated evaluation systems [38, 39, 40] addresses the limitations of conventional assessment. However, this transition toward automated feedback should not be viewed as a replacement for human mentorship. While the efficiency of Computational Deep Learning is undeniable, our synthesis indicates that the most effective models are 'human-in-the-loop' systems, where AI-generated insights inform rather than dictate Deep Learning approaches.
Regarding existing challenges, the emergence of neuro-symbolic AI as a solution to algorithmic bias [41] is a promising development. Nevertheless, technical solutions alone are insufficient. The ethical and privacy concerns identified in [42] necessitate a 'Digital Ethics Framework' within the curriculum. Therefore, we emphasize that for these AI-based Deep Learning technologies to be truly transformative, the focus must shift from pure technical implementation toward building the digital readiness of educators [43, 44]. This ensures that Computational Deep Learning serves as an inclusive tool that fosters Pedagogical Deep Learning rather than creating a new digital divide.
The yellow cluster reflects a growing consensus that AI-based Deep Learning is a cornerstone for personalizing learning in the digital age. Technologies such as Natural Language Processing (NLP) and Computational Deep Learning models enable adaptive feedback and customized experiences [45, 46]. However, as researchers, we argue that the mere presence of these tools does not guarantee engagement. While these AI-bases Deep Learning tools can theoretically increase student involvement [47], our analysis suggests that the effectiveness of such tools is heavily moderated by the quality of the pedagogical design. Technology should be viewed as an 'amplifier' of teaching quality, not a substitute for the human element in fostering Pedagogical Deep Learning.
Advanced algorithms, particularly Artificial Neural Networks (ANNs), play a crucial role in predicting knowledge gaps and offering targeted learning paths [48, 49]. While the ability of Computational Deep Learning to adjust question difficulty in real-time [50, 51]. offers a more development-oriented evaluation, we must scrutinize the risk of 'algorithmic reductionism.' If systems only adjust based on quantifiable data, there is a danger of overlooking the qualitative, nuanced aspects of human creativity and critical thinking. Therefore, the implementation of Generative AI [52] must be carefully balanced to ensure it encourages Pedagogical Deep Learning specifically independent and critical thinking rather than creating a dependency on automated outputs.
Furthermore, we emphasize that digital literacy is not just a 'key prerequisite' [52, 53], but the deciding factor between the success and failure of AI-based Deep Learning integration. Our synthesis indicates a 'competency paradox': students with low digital literacy are the most vulnerable to algorithmic bias, yet they are also the group least likely to identify it. This underscores the urgent need for institutional policies that go beyond data security [54] to include 'algorithmic transparency.' We advocate for a framework where the deployment of Computational Deep Learning is inseparable from a critical digital literacy curriculum, ensuring that fairness and equality are maintained as students transition toward more complex Deep Learning approaches.
-
3.2.3. Tosca Cluster: How Deep Learning Integration in Blended Learning Affects Student Engagement and Digital Literacy.
-
3.3. Content Analyze
The Tosca Cluster highlights the synergy between Blended Learning and AI-Deep Learning (DL) technologies as a catalyst for educational flexibility [55, 56]. While this approach is often lauded for fostering collaboration, as researchers, we argue that the success of this integration is heavily contingent upon the students' ability to engage in Pedagogical Deep Learning. Our analysis suggests that without a robust digital literacy foundation, AI-based Deep Learning platforms may lead to cognitive overload rather than meaningful knowledge construction. Therefore, digital literacy should be viewed as the primary 'gatekeeper' that enables students to transition from surface learning to more profound Deep Learning approaches.
AI-based Deep Learning technologies further refine the blended environment by providing predictive analytics and adaptive paths [57, 58]. However, we must critically evaluate the 'immersion' claim [59, 60]. While Computational Deep Learning creates adaptive experiences, there is a risk that students may become passive consumers of automated content. We contend that true digital literacy requires students to move beyond technical usage and adopt Pedagogical Deep Learning strategiesspecifically the ability to critically deconstruct AI-generated outputs.
Despite these advancements in AI-based Deep Learning, the human element remains irreplaceable. Based on our synthesis, we posit that the ideal learning environment is not one where technology leads, but one where Computational Deep Learning handles administrative complexity, freeing the educator to facilitate Deep Learning approaches. Ultimately, readiness for the digital workforce [61, 62] depends on a hybrid competence: the technical mastery of AI-based Deep Learning tools combined with the cognitive depth of Pedagogical Deep Learning.
Before performing topic modeling using the Latent Dirichlet Allocation (LDA) method, the initial stage of content analysis involves creating a word cloud visualization to ensure that the text-preprocessing steps including cleaning, normalization, and tokenization are properly executed. The word cloud serves as a heuristic tool to identify the most frequently occurring terms extracted from titles and abstracts, while validating the thematic relevance aligned with the research goals.
As illustrated in Figure 8, several dominant terms were identified throughout the corpus. Beyond the predefined search strings, the five most frequent words were "learning" (843 occurrences), "students" (295), "deep" (252), "education" (217), and "digital" (213). The prominence of these terms confirms that the dataset is heavily saturated with core concepts essential to this study. Additionally, terms such as "AI" (172), "technology" (113), and "literacy" (83) indicate that these elements are central to the current academic discourse. To ensure transparency, a rigorous pipeline removed domain specific noise (e.g., 'research', 'study') and applied lemmatization to standardize linguistic variations.
software enhanced integrating especially instructional traditional environments native integration ltd techniques various impact focus showed positive 9p understanding communication®'™ factors ih interaction effective. , a . machine proposed within become develnnAd human fpgmeWOfk methodsmethod prediction course opecl process nlell'°^^ training provides significantly . ^ huture educational Performance^ ^ reserved across teacher learners lutuie ЯППГЛЛгН C09nmve physical 2022
identify work different PA ГСП. rfte^a jnformationvirtual related develop2021 Schoso^n°ceteachina pHI ITЛtinП hiahet^ people enhanc6^ ^ I и J I.hl9her theory developing inquiry survey develо p ment Л p p Пxusf J aesIgQyS ;hre^ rights publicvalue ar9ua9° R SIU QVskillSauthor provide й5к5
sh^S 6 a seal ear ПШ q a i £udent"=es strategy 2024 field kJ ОЭС .4 USSd ” j i teachers among well imaglt^ results 0ПНпе CT Cl □ А ПSOCial PaPerpoterWrt visual a^^ | Г5" ^в^ iS5UeS metavers^art'f'™1 IlteracyCI 10113 ^Sing image*™^^
