Об одном подходе к извлечению именованных сущностей из неструктурированных текстов

Автор: А. А. Ворошилова, С. Ю. Пискорская
Журнал: Informatics. Economics. Management - Информатика. Экономика. Управление.
Рубрика: Образование
Статья в выпуске: 2 (3), 2023 года.
Бесплатный доступ
В статье рассматривается один их возможных подходов к извлечению именованных сущностей из неструктурированных текстов. Отмечается сложность и трудоемкость наиболее распространенных методов решения данной задачи, базирующихся на использовании создаваемых вручную конечных автоматов. Возникает ряд сложностей при реализации данного подхода при обработке мультилингвистических текстов, так как для каждого нового языка и для каждого нового класса сущностей требуется вмешательство человека для создания вручную нового набора шаблонов для работы с новыми языками и новыми классами. Предлагаемый подход предполагает использование принципов машинного обучения. Дана постановка задачи и описана используемая модель марковской цепи при распознавании именованных сущностей. На основе данной модели для выделения именованных объектов ставится задача нахождения наиболее вероятной последовательности состояний, генерирующих последовательность лексем. В статье описан лексический материал, включающий состав признаков и их описания, представлена методика декодирования и оценка параметров модели. В данной работе для решения задачи используется алгоритм Витерби, который предназначен для нахождения последовательности состояний, для которых вероятность порождения наблюдаемой цепочки символов максимальна. В качестве экспериментальных результатов представлены характеристики точности распознавания типов лексем при различных размерах обучающей выборки и диаграмма количества ошибок по классам лексем.
Обработка информации, неструктурированный текст, именованная сущность, лексема, скрытая марковская цепь
Короткий адрес: https://sciup.org/14127464
IDR: 14127464 | УДК: 004.912 | DOI: 10.47813/2782-5280-2023-2-2-0301-0313
Текст статьи Об одном подходе к извлечению именованных сущностей из неструктурированных текстов
DOI:
Извлечение информации – это задача из области обработки естественноязыковых текстовых массивов, которая включает автоматическое извлечение предопределенных типов информации из текста [1-4]. Примером задачи извлечения информации может служить задача получения сведений об организации из массивов информации, представленной в текстовом виде [5]. Входными данными системы извлечения информации является неструктурированный или слабоструктурированный текст на естественном языке; на выходе - заполненные структуры данных, позволяющие проводить дальнейшую автоматическую или ручную обработку информации.
В качестве частного случая данной задачи можно рассмотреть задачу извлечения именованных сущностей (примером может служить выявление в неструктурированном или слабоструктурированном тексте всех вхождений упоминаний о различных организациях, персонах, географических названий и т.д.) [6, 7]. Ряд авторов, например, в [8-11] используют внутриязыковые ассоциативные поля в мультилингвистической адаптивно-обучающей технологии, а также исследуют системы поиска, анализа и обработки мультилингвистических текстов, интегрированные с информационнопоисковыми системами [12].
Распространенные подходы к решению задачи извлечения именованных сущностей из неструктурированных текстов основываются на использовании создаваемых вручную конечных автоматов (patterns) [13]. Однако для каждого нового языка (в рамках мультилингвистической технологии [11]) и для каждого нового класса сущностей требовалось вмешательство человека для создания вручную нового набора шаблонов для работы с новыми языками и новыми классами. Предлагаемый подход предполагает использование принципов машинного обучения.
Процесс извлечения информации состоит из двух этапов: первый – поиск возможных кандидатур лексем, представляющих интерес, второй – определение типа каждой из кандидатур . Алгоритм распознавания типа лексемы на выходе должен выдавать единственный и однозначный тип для каждой лексемы в тексте.
Задача автоматического распознавания некоторых типов лексем достаточно тривиальна, в то время как для ряда лексем могут возникнуть неоднозначные толкования. Например, автоматическое распознание лексем адресов электронной почты и дат может осуществляться при помощи механизмов стандартных регулярных выражений. Однако использование регулярных выражений для некоторых типов лексем, например имен, довольно затруднительно. Например, для лексемы “Владимир” может возникнуть неоднозначность - к какому типу отнести эту лексему: имя человека или название города? В естественных языках, как правило, не существует каких-либо конкретных ограничений на правила формирования названий именованных объектов.
ПОСТАНОВКА ЗАДАЧИ
Будем рассматривать входной текст как выход некоторой порождающей системы, которая порождает текст, состоящий из лексем, причем у каждой лексемы имеется набор характеристик, включающих семантический тип лексемы. Типам лексем в рассматриваемой модели соответствуют такие типы именованных сущностей как: географические названия, названия организаций, персоны и т. д. Можно ввести следующую аналогию: при прохождении текстовой информации через некоторый зашумленный канал информация о семантических типах утратилась. Таким образом, задача состоит в восстановлении этой информации.
Соотнесем набор состояний S = {S 1 ,..., Sw} с введенным набором семантических типов, то есть каждое состояние S i будет соответствовать некоторому семантическому типу лексемы. Так как входной текст представляет собой последовательность лексем, которую обозначим как О = 0 1 0 2 , ..., 0 т , причем у каждой лексемы имеется свой семантический тип, мы можем представить систему, которая в каждый момент времени t= 1 ...,T находится в одном из состояний Si...S n .
В данной работе в качестве модели системы используются скрытые марковские цепи: переход системы из одного состояния в другое происходит в моменты времени t =1, 2, ... в соответствии с вероятностями перехода, соотнесенными с состояниями. Вероятность перехода из состояния S i в S j определяется матрицей A, состоящей из следующих элементов:
ai j = P[qt = S j lqt - 1 = SiA,1
Для элементов матрицы A выполняются стандартные ограничения: a ij > 0, и условие нормировки вероятностей £ [=1 a ij = 1.
Полностью модель скрытой марковской цепи определяется следующими элементами:
-
1. Набор из N состояний S = {S 1 ,... , SN}
-
2. Алфавит, состоящий из M символов V = {v 1 , ...,vM].
-
3. Вероятности перехода из состояния S i в S j определяемые элементами матрицы A , где a ij = P[q t = S j lq t-i = S i ], 1 < i,j < N.
-
4. Вероятности порождения символа алфавита v ^ , если система находится в состоянии S j , определяются элементами матрицы B , где b i (k) = P[v ^ lqt = S i ], 1 < j < N,1
-
5. Вероятности начальных состояний H i = P[q 1 = S i ], 1 < i < N.
Данный вид цепей называют скрытыми, так как наблюдается только последовательность порожденных символов О = 0 1 0 2 , ...,От , где 0 i G V, при этом, последовательный набор состояний, породивший данную последовательность, остается скрытым.
Для краткости, совокупность параметров модели обозначим Л = (А, В,к).
На основе этой модели для скрытых марковских цепей возможно оценить:
-
• вероятность, с которой модель Л порождает последовательность О = 0 1 02,...,0т , где 0^V;
-
• наиболее вероятную последовательность состояний, генерирующую последовательность O ;
-
• параметры Л = (А, В, к), которые максимизируют вероятность порождения последовательности O : max Р (0|Л).
Используемая модель марковской цепи при распознавании именованных сущностей представлена на рисунке 1.
Здесь для каждого типа лексемы предусмотрено соответствующее состояние в марковской модели.
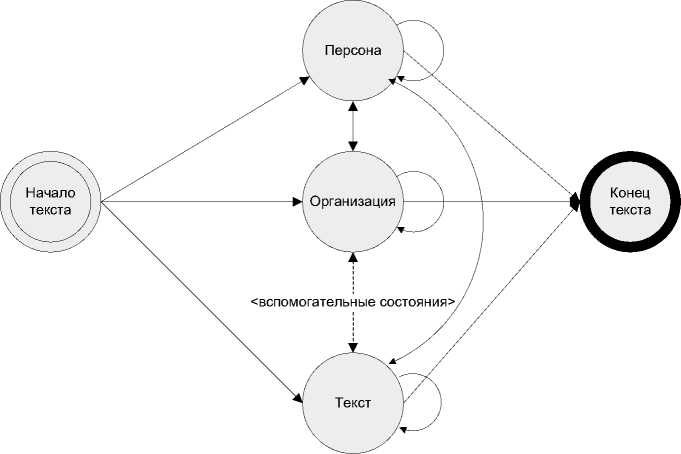
Рисунок 1. Модель марковской цепи при распознавании именованных сущностей.
Figure 1. Markov chain model for named entity recognition.
В данном случае, для выделения именованных объектов, ставится задача нахождения наиболее вероятной последовательности состояний, генерирующих последовательность O .
ЛЕКСИЧЕСКИЙ МАТЕРИАЛ
При распознавании лексем, алфавит V включает в себя лексемы, полученные на этапе обучения, а также ряд признаков лексем, составленных из набора базовых признаков. Состав признаков и их описание представлено в таблице 1.
Таблица 1. Состав признаков и их описание.
Table 1. Composition of features and their description.
|
Признак |
Описание |
|
FIRST_CAP |
Первая буква заглавная. |
|
ALL_CAP |
Все буквы заглавные. |
|
IN_QUOTES |
В кавычках. |
|
NON_VOCAB |
Неизвестное слово русского языка. |
|
LETTER_WITH_DOT |
Заглавная буква с точкой. |
LETTER_THEN_DOT_THEN_CAP Две заглавные буквы, разделенные
|
точкой. |
|
|
PREFIX1 |
Словарный префикс. |
|
SUFFIX1 |
Словарный суффикс. |
|
OTHER |
Другое. |
Исходя из данного набора элементарных признаков видно, что одной лексеме может соответствовать несколько элементарных признаков. В таком случае происходит их объединение в новый признак, который добавляется в словарь.
Набору состояний соответствуют семантические типы лексем вида:
-
• ORG – название организации (АО “ОКБ”);
-
• PERSON – упоминание о человеке (Владимир Баранов);
-
• GEOGRAPHIC – географическое название (Усть-Илимский район);
-
• PLAIN_TEXT – обычный текст.
При обучении для разметки лексем используется расширяемый язык разметки XML.
Пример разметки текста выглядит следующим образом.
Как отмечает начальник отдела продаж
PERSON>, подъем курса акций
Элементы матрицы A определяет вероятность того, что текущая лексема принадлежит классу j , учитывая, что предыдущая лексема принадлежала классу i .
Элементы матрицы B определяют вероятность того, что лексема с определенным набором элементарных признаков принадлежит определенному классу.
МЕТОДИКА ДЕКОДИРОВАНИЯ
Предположим, что имеется некоторая последовательность О = 0 1 0 2 ,...,0т, где 0 [ G У, также известны элементы матриц A, B, п .
Задача нахождения наиболее вероятного набора состояний Q = Q 1 Q 2 ,..., QT , Q t G 5 называется декодированием.
В данном случае, для решения этой задачи используется алгоритм Витерби [15], который предназначен для нахождения последовательности состояний, для которых вероятность порождения наблюдаемой цепочки символов максимальна.
Максимальную вероятность того, что на t -м моменте времени символ o t был порожден состоянием S j , обозначим как:
В рекуррентном виде данное соотношение может быть записано как:
St+i(D = [max8t(i) • atj] • bj(ot+i),(2)
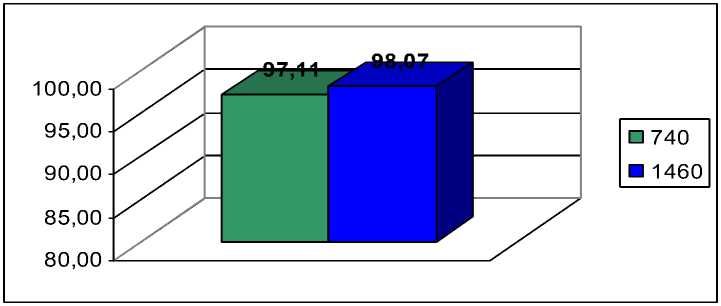
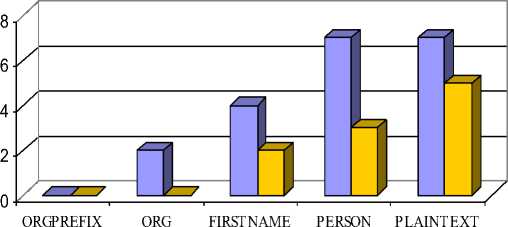
1 1 В начальный момент времени 8i(j) = ^j • bj(oi).(3) Таким образом, алгоритм начинается с вычисления 81 (j') для 1< j < N, затем, используя рекуррентную формулу (2) вычисляются значения последующих δt(j) до t=T, для получения оптимальной последовательности состояний. Последнее состояние j определяется как: j = arg max Зт(Т). (4) 1 Критерий оптимальности для алгоритма Витерби может быть записан следующим образом: Q* = max Пе=1-Р[<7е = SyVk-i = S] • P[ot = vk\qt = Sy] , (5) ОЦЕНКА ПАРАМЕТРОВ МОДЕЛИ Элементы матриц A и B – вероятности переходов состояний и вероятности порождения символов алфавита V возможно оценить при наличии обучающей выборки. Обучающая выборка представляет собою размеченный текст, где при помощи тэгов XML разметки указан тип лексемы. На основании обучающей выборки элементы матрицы A можно оценить следующим образом [14]: c(Si^Sj) a = ——^ . ij Для элементов матрицы B имеем: c(V kTS j) >№ = Элементы вектора π имеют следующий вид: c(Start^S j) ^ = ---77----, j c(Start) В данных формулах введены следующие обозначения: • c(X) – число появления события X; • Si ^ Sy - переход системы из состояния i в состояние j; • Vk Т Sy - порождение символа Vk , когда система находится в состоянии S/; • Start ^ Sy - появления в качестве первого состояния системы состояния j. ЭКСПЕРИМЕНТАЛЬНЫЕ РЕЗУЛЬТАТЫ В качестве источников данных для обучения и тестирования использовались новостные ленты из агентства РосБизнесКонсалтинг и Характеристики точности распознавания типов лексем при размере обучающей выборки 740 и 1460 лексем соответственно представлены на рисунке 2. Рисунок 2. Характеристики точности распознавания типов лексем при различных размерах обучающей выборки. Figure 2. Characteristics of the accuracy of recognition of types of lexemes for different sizes of the training sample. Диаграмма количества ошибок для различных классов лексем представлена на рисунке 3. Рисунок 3. Диаграмма количества ошибок по классам лексем. Figure 3. Diagram of the number of errors by token class. ЗАКЛЮЧЕНИЕ На основе лексического материала, представленного в статьи и включающего состав признаков и их описание, разработана методика декодирования и оценка параметров модели для извлечения именованных сущностей из неструктурированных текстов. Для решения задачи использован алгоритм Витерби, который предназначен для нахождения последовательности состояний, для которых вероятность порождения наблюдаемой цепочки символов максимальна. Критерий оптимальности для алгоритма Витерби представлен в работе в виде формулы (5). Экспериментальные результаты продемонстрировали высокий уровень точности распознавания типов лексем при различных размерах обучающей выборки: 97,11% для 740 лексем и 98,07% для 1460 лексем. Также продемонстрирован достаточно низкий уровень количества ошибок по всем классам лексем (см. рисунок 3). Предложенный подход может быть расширен для мультилингвистического базиса лексем, принадлежащих разным языкам, в рамках мультилингвистической адаптивно-обучающей технологии [16].