Опыт квантитативного исследования Пантелеймонова евангелия конца XII - начала XIII в. (три статистических эксперимента)
")
Автор: Баранов Виктор Аркадьевич, Зуга Оксана Владимировна
Журнал: Вестник Волгоградского государственного университета. Серия 2: Языкознание @jvolsu-linguistics
Рубрика: Главная тема номера
Статья в выпуске: 6 т.19, 2020 года.
Бесплатный доступ
Цель работы - выявление степени близости Пантелеймонова Евангелия (РНБ, Соф. 1) другим Евангелиям и средневековым славянским текстам других жанров, представленным в подкорпусах исторического корпуса «Манускрипт: славянское письменное наследие». Работа выполнена с помощью специализированных модулей статистики и n-грамм. Сопоставление перечней автоматически извлеченных их рукописи одно, двух- и трехкомпонентных лингвистических единиц с соответствующими перечнями нескольких подкорпусов позволяет определить такие количественно-статистические характеристики лингвистических компонентов рукописей, которые могут быть признаны существенными. Обобщены данные трех экспериментов. Первый эксперимент показал, что наименьшие отличия частотных списков существуют между Пантелеймоновым Евангелием и полными апракосами, а наибольшие - между анализируемой рукописью и краткими апракосами. Это позволяет признать, что состав перечней, порядок следования и относительная частота форм в них являются существенными характеристиками рукописи или подкорпуса. В ходе второго эксперимента, проведенного с применением статистической меры Weirdness, из Пантелеймонова Евангелия извлечены словоформы, претендующие на роль значимых - имеющие максимально высокий вес на фоне разножанровых подкорпусов. Установлено, что объем и состав контрастного подкорпуса не влияют на результат; применение в качестве контрастных подкорпусов коллекций полных и кратких апракосов позволило уточнить список таких форм. В ходе третьего эксперимента (анализ двух- и трехкомпонентных сочетаний, извлеченных с помощью статистической меры T-score) был установлен перечень устойчивых сочетаний (неизменяемых композиционных формул, цельных грамматических структур, устойчивых семантических комплексов и их частей), свойственных всем Евангелиям, и выявлены статистически значимые последовательности, имеющие в Пантелеймоновом Евангелии статистический вес значительно выше, чем в контрастных подкорпусах.
Древнерусские рукописи, пантелеймоново евангелие, статистические методы, ключевые слова, n-граммы
Короткий адрес: https://sciup.org/149131612
IDR: 149131612 | УДК: 811.161.1’04:27-247 | DOI: 10.15688/jvolsu2.2020.6.4
Quantitative investigation of the Panteleymon gospel dating from the late 12th to the early 13th centuries (three statistical experiments)
The work presents the results of the quantitative and statistical comparative analysis of the most frequent word forms and combinations of the Old Russian of the Panteleymon Gospel (RNB, Sof. 1). The work aims to reveal the degree of closeness of the Panteleymon Gospel to the other gospels and the medieval Slavonic texts of other genres, represented in sub-corpora of historical corpus “Manuscript: Slavic Written Heritage”. The work was carried out with the help of the special modules of statistics and n -grams. The comparison of the lists of single-, two- and three-component linguistic units, automatically extracted from the manuscripts, with the respective lists of several sub-corpora points to the presence of the quantitative-statistical characteristics of the linguistic components of the manuscripts which can be recognized as important. The data of the three experiments are summarized. The first experiment showed that the smallest differences of the frequency lists exist between the Panteleymon Gospel and the sub-corpus of complete aprakoses and the greatest differences between the manuscript being analyzed and the sub-corpus of short aprakoses. This makes possible to recognize that the composition of the lists, the order and the relative frequency of the forms in them are the important characteristics of the manuscript or the sub-corpus. The application of the Weirdness measure helped to extract from the Panteleymon Gospel the word forms which are supposed to be significant - those, having the highest weight within the sub-corpora of different genres ( вамъ , имъ , азъ , емоу , рече , аще ). It has been established that the volume and composition of contrasted sub-corpus do not influence the result, and the use of the collections of complete and short aprakoses as contrast sub-corpora helped to specify the list of such forms ( яко , къ , бо , о ( т ), имъ , есть , аще ). The investigation of two- and three-component combinations, extracted with the help of the statistical measure T-score, gave the following results: a list of fixed combinations - invariable composition formulas ( ев [ан]( г )[елие] ѡ ( т ) ма [т]( ѳ )[ея] etc.), inherent to all gospels, was made; entire grammatical structures ( ѧже далъ ѥси etc.) were listed, as well as stable semantic complexes and their parts ([да] любите дроугъ дроуга etc.). Statistically important sequences having in the Panteleymon Gospel a statistical weight, which is considerably higher than in the contrast sub-corpora - нѣсте ли чьли , имать животъ вѣчьныи etc. have been revealed.
Текст научной статьи Опыт квантитативного исследования Пантелеймонова евангелия конца XII - начала XIII в. (три статистических эксперимента)
DOI:
Citation. Baranov V.A., Zuga O.V. Quantitative Investigation of the Panteleymon Gospel Dating from the Late 12th to the Early 13th Centuries (Three Statistical Experiments). Vestnik Volgogradskogo gosudarstvennogo universiteta. Seriya 2. Yazykoznanie [Science Journal of Volgograd State University. Linguistics], 2020, vol. 19, no. 6, pp. 43-57. (in Russian). DOI:
Цитирование. Баранов В. А., Зуга О. В. Опыт квантитативного исследования Пантелеймонова Евангелия конца XII – начала XIII в. (три статистических эксперимента) // Вестник Волгоградского государственного университета. Серия 2, Языкознание. – 2020. – Т. 19, № 6. – С. 43–57. – DOI:
Средневековые славянские тексты как объект и предмет исследования
Статистический анализ давно и продуктивно используется для решения различных задач в области русской филологии и лингвистики 2. В настоящее время необходимый материал для этого предоставляют большие текстовые коллекции и корпусы. Создание машиночитаемых копий средневековых славянских текстов, их разметка и размещение в специализированных системах хранения и обработки данных дает возможность начать статистические эксперименты и на таком материале.
Одним из интернет-ресурсов, содержащих размеченные транскрипции средневековых славянских рукописей, является текстовый корпус «Манускрипт: славянское письменное наследие», в котором размещено более 130 рукописей и отрывков X–XV вв. объемом более 3,5 млн текстовых прецедентов и который снабжен специализированными инструментами для обработки, поиска и демонстрации лингвистических данных 3.
Самой большой коллекцией корпуса является собрание Евангелий XI–XIV вв., включающее и один из ранних русских списков полного апракоса – новгородское Пантелеймоново Евангелие, не часто привлекавшее внимание лингвистов.
Общая характеристика рукописи и ее электронное издание
Пантелеймоново Евангелие (далее – ЕП) было создано в конце XII – начале XIII (?) в. [Сводный каталог..., 1984, с. 167] (другая датировка – XII в. [Марков, 2001]) и названо по имени св. Пантелеймона, изображенного на л. 224. По содержанию и композиции представляет собой полный апракос, в котором имеются евангельские чтения на субботние, воскресные и будние дни недели. Памятник хранится в отделе рукописей Российской национальной библиотеки (РНБ), в Софийском собрании (Соф.), под № 1. Рукопись содержит 224 листа; не издавалась. Вследствие ветхости памятник недоступен широкому кругу читателей.
Интерес к ЕП не случаен: в ряду древнейших церковнославянских письменных памятников русского извода у него особое место как у одной из рукописей, в которой отразились значимые для истории русского языка особенности фонетики и грамматики [Зуга, 2009; Марков, 2001]. Сравнение текстов Остромирова и Пантелеймонова Евангелий дало возможность В.М. Маркову обнаружить яркие различия, свидетельствующие о происходивших в русском языке XII в. изменениях. Одним из достижений работы ученого стала демонстрация эффективности и результативности сопоставления рукописей, содержащих одни и те же тексты: «...даже прямолинейное сопоставление текстов приводит, как кажется, к достаточно значимым результатам, коль скоро дело касается источников, разнесенных во времени и, вместе с тем, представляющих однородный языковой материал» [Марков, 2001, с. 33].
Сказанное позволяет продолжить сопоставление ЕП и других евангельских списков с помощью иных методов, например корпусных и количественно-статистических. Дает ли их применение возможность обнаружить значимые характеристики текстов, можно понять, только проведя соответствующие эксперименты. В статье представлены результаты автоматического извлечения одно-, двух- и трехкомпонентных текстовых единиц из ЕП, сопоставление их с данными других евангельских текстов, объединенных в три подкорпуса, с целью выявления степени близости ЕП последним.
Возможность выполнить эксперименты предоставляют пользовательские сервисы корпуса «Манускрипт: славянское письменное наследие», в который включена интернет-версия электронного издания рукописи 4. Оно позволяет познакомиться с археографической, текстологической, лингвистической, библиографической информацией о рукописи и тексте, получить сведения об их структуре и составе, просмотреть полный текст рукописи (машиночитаемую транскрипцию, содержащую лингвистическую и аналитическую разметку) и текст дипломатического издания (преобразованный текст), построить прямые, обратные, количественные, сравнительные указатели слов и словоформ, конкордансы.
Эти данные послужили материалом нескольких статистических экспериментов для нахождения таких количественных характеристик Пантелеймонова Евангелия, которые отличают его от других рукописей корпуса. Объектом анализа стали автоматически извлеченные одно-, двух- и трехкомпонентные сочетания текстовых форм, статистическая значимость которых устанавливается с помощью сопоставления с коллекциями полных и кратких апракосов, а также коллекциями текстов других жанров 5.
Количественный и статистический анализ Пантелеймонова Евангелия
Общие сведения об объеме данных
Объем рукописи ЕП – 68 734 текстовые формы. Базовый подкорпус русских списков Евангелий XI–XIV вв.6: количество рукописей – 9, отрывков – 2; объем – 522 793 текстовые формы, а также два старославянских списка – Ассеманиево Евангелие и Саввина книга; объем – 76 644 формы.
Эксперимент 1. Наиболее частотные словоформы
В работе [Баранов, 2019в] показаны существенные различия между составом и порядком следования первых десяти наиболее частотных слов в подкорпусе русских списков Евангелий и в подкорпусах рукописей других жанров, а также между их статистическими оценками.
Единство текстов Евангелий с точки зрения количественных характеристик подтверждается составом, порядком следования и относительным количеством наиболее частотных словоформ ЕП и трех подкорпусов Евангелий – русских списков полного апракоса, русских списков краткого апракоса и старославянских списков (см. таблицу 17).
Таблица 1. Наиболее частотные словоформы в ЕП и подкорпусах Евангелий
Table 1. The most frequent word forms in the EP and subcorps of the Gospels
|
R |
ЕП |
Евангелия (АП) |
Евангелия (АК) |
Евангелия (ст.-слав.) |
||||||||
|
w |
F |
f |
w |
F |
f |
w |
F |
f |
w |
F |
f |
|
|
1 |
н |
5516 |
0,080 |
н |
17281 |
0,079 |
н |
12711 |
0,077 |
н |
5871 |
0,077 |
|
2 |
же |
2344 |
0,034 |
же |
9093 |
0,041 |
же |
6851 |
0,041 |
же |
3099 |
0,040 |
|
3 |
къ |
2186 |
0,032 |
къ |
6924 |
0,031 |
къ |
5118 |
0,031 |
къ |
1740 |
0,023 |
|
4 |
не |
1498 |
0,022 |
не |
4557 |
0,021 |
са |
3321 |
0,020 |
са |
1579 |
0,021 |
|
5 |
са |
1462 |
0,021 |
са |
4475 |
0,020 |
не |
3319 |
0,020 |
не |
1479 |
0,019 |
|
6 |
W |
1170 |
0,017 |
W |
3555 |
0,016 |
W |
2799 |
0,017 |
ъко |
988 |
0,013 |
|
7 |
ако |
1031 |
0,015 |
АКо |
2959 |
0,013 |
нл |
1854 |
0,011 |
на |
908 |
0,012 |
|
8 |
нл |
785 |
0,011 |
НА |
2462 |
0,011 |
реуе |
1743 |
0,010 |
ем^ |
755 |
0,010 |
|
9 |
реуе8 |
734 |
0,011 |
ре |
2266 |
0,010 |
км^ |
1618 |
0,010 |
реуе |
746 |
0,010 |
|
10 |
км^ |
626 |
0,009 |
км^ |
1941 |
0,009 |
АКО |
1605 |
0,010 |
отъ |
719 |
0,009 |
|
11 |
ксть |
585 |
0,009 |
кго |
1816 |
0,008 |
кго |
1408 |
0,008 |
АА |
586 |
0,008 |
|
12 |
АА |
530 |
0,008 |
ксть |
1795 |
0,008 |
АА |
1240 |
0,007 |
его |
579 |
0,008 |
|
13 |
къ |
523 |
0,008 |
АА |
1674 |
0,008 |
ксть |
1228 |
0,007 |
се |
578 |
0,008 |
|
14 |
кго |
493 |
0,007 |
се |
1437 |
0,007 |
се |
1074 |
0,006 |
естъ |
538 |
0,007 |
|
15 |
се |
450 |
0,007 |
Афе |
1372 |
0,006 |
къ |
1028 |
0,006 |
къ |
506 |
0,007 |
|
16 |
нмъ |
434 |
0,006 |
нмъ |
1376 |
0,006 |
кам |
934 |
0,006 |
нмъ |
387 |
0,005 |
|
17 |
камъ |
428 |
0,006 |
кам |
1299 |
0,006 |
съ |
912 |
0,005 |
Афе |
385 |
0,005 |
|
18 |
Афе |
414 |
0,006 |
къ |
1253 |
0,006 |
Афе |
870 |
0,005 |
бо |
363 |
0,005 |
|
19 |
БО |
396 |
0,006 |
съ |
1195 |
0,005 |
нмъ |
870 |
0,005 |
кам |
372 |
0,005 |
|
20 |
съ |
363 |
0,005 |
БО |
1185 |
0,005 |
а^ъ |
836 |
0,005 |
о |
367 |
0,005 |
|
21 |
а^ъ |
292 |
0,004 |
а^ъ |
911 |
0,004 |
бо |
775 |
0,005 |
а^ъ |
348 |
0,005 |
Примечание. Евангелия (АП) – списки полного апракоса, без ЕП (объем – 220 023); Евангелия (АК) – списки краткого апракоса (объем – 166 153); Евангелия (ст.-слав.) – два старославянских списка (объем – 76 644). R – ранг словоформы; w – словоформа; F – абсолютная частота; f – относительная частота 9. В случае вариативности текстовых прецедентов в качестве маски использовались регулярные выражения, например: ( h|i ), с ( а|а ), ( а|а|а ) к ( о|о|ш ), ( к|е|е ) с ( н|1 ), ( [oow]t.|w ), ( к|е|е ) м(оу|$|у|у|у ) и под. Различно переданные в транскрипциях корпуса са и же в постпозиции и не в препозиции, а также формы местоимения н в косвенных падежах ( км^/км^же, кго/кгоже ) в таблице приведены суммарно.
Сопоставление первых 10 наиболее частотных форм позволяет увидеть: а) полную идентичность состава ЕП и других полных апракосов и порядка следования форм в них; б) различия полных и кратких апракосов в порядке следования форм; в) отличия в порядке следования форм в старославянских списках по сравнению с русскими списками; г) заметно различную относительную частоту союза №ко в русских списках полных и кратких апракосов (0,015–0,013 vs 0,010) и предлога w/отъ в русских и старославянских списках (0,016–0,017 vs 0,009).
Перечни форм, имеющих ранги с 11-го по 21-й: а) в ЕП и полных апракосах идентичны по составу, близки по порядку следования и по относительному количеству (относительные значения 7 форм равны, 3 формы различаются на 0,001, 1 форма – на 0,002); б) в ЕП и в кратких апракосах также совпадают по составу, различаются порядком следования и относительной частотностью (относительные значения 2 форм равны, 7 форм различаются на 0,001, 2 форм – на 0,002); в) в кратких русских и старославянских апракосах различаются по составу (рус. съ, ст.-слав. о), близки по порядку следования и относительному количеству (относительные значения 6 форм не различаются, 3 форм отличаются на 0,001, 1 формы – на 0,002). Наименьшие различия находим в парах «ЕП – полные апракосы» и «краткие апракосы – старославянские списки», наи- большие – в «ЕП – краткие апракосы», что понятно: ЕП является полным апракосом.
Обнаруженные схожесть и контрастность между наиболее часто встречающимися формами, имеющими ранги с 1-го по 21-й, в ЕП, подкорпусах русских списков кратких и полных Евангелий и в старославянских рукописях позволяют сделать вывод о неслучайности существующих между подкорпусами совпадений и различий и признать, что состав, порядок следования и относительная частота форм в совокупности являются существенными характеристиками документа или подкорпуса.
Эксперимент 2. Значения наиболее частотных форм в соответствии с мерой Weirdness
Для извлечения из ЕП статистических значимых словоформ и выяснения влияния на этот перечень объема и жанра текстов в подкорпусах, привлекаемых к сопоставлению, используем меру Weirdness 10 [Ahmad, Gillam, Tostevin, 1999]. Как известно, эта мера позволяет оценить частотность словоформы в документе на фоне ее частотности в альтернативном подкорпусе.
Рассмотрим значимость («странность», контрастность) 21 наиболее частотной формы ЕП, сопоставив количество каждой с частотностью соответствующих форм в разножанровых подкорпусах разного объема и в подкорпусах полных и кратких апракосов.
В таблице 2 представлены формы ЕП, их статистический вес в соответствии с мерой
Таблица 2. Вес наиболее частотных словоформ в ЕП в соответствии с мерой Weirdness
Table 2. Weight of the most frequent word forms in the EP according to the Weirdness measure
|
R |
w |
F |
f |
R 1 |
Weirdness1 |
R 2 |
Weirdness2 |
R 3 |
Weirdness3 |
R 4 |
Weirdness4 |
|
1 |
н |
5516 |
0,080 |
14 |
1,722 |
15 |
1,216 |
12 |
1,022 |
10 |
1,049 |
|
2 |
же |
2344 |
0,034 |
12 |
1,934 |
14 |
1,269 |
21 |
0,825 |
21 |
0,827 |
|
3 |
къ |
2186 |
0,032 |
13 |
1,750 |
13 |
1,356 |
15 |
1,011 |
12 |
1,032 |
|
4 |
не |
1498 |
0,022 |
19 |
1,233 |
17 |
1,061 |
6 |
1,052 |
8 |
1,091 |
|
5 |
СА |
1462 |
0,021 |
21 |
0,636 |
21 |
0,649 |
7 |
1,046 |
9 |
1,064 |
|
6 |
W |
1170 |
0,017 |
11 |
2,061 |
8 |
1,834 |
5 |
1,054 |
16 |
1,010 |
|
7 |
ЫКО |
1031 |
0,015 |
16 |
1,368 |
10 |
1,510 |
2 |
1,115 |
1 |
1,553 |
|
8 |
НА |
785 |
0,011 |
18 |
1,252 |
18 |
0,956 |
13 |
1,021 |
14 |
1,024 |
|
9 |
peve |
734 |
0,011 |
2 |
29,911 |
2 |
7,487 |
8 |
1,044 |
13 |
1,025 |
|
10 |
нмоу |
626 |
0,009 |
6 |
14,702 |
5 |
3,188 |
10 |
1,032 |
18 |
0,935 |
|
11 |
КСТЬ |
585 |
0,009 |
8 |
4,888 |
9 |
1,814 |
9 |
1,043 |
5 |
1,152 |
|
12 |
АА |
530 |
0,008 |
9 |
3,618 |
11 |
1,507 |
14 |
1,013 |
11 |
1,033 |
|
13 |
къ |
523 |
0,008 |
15 |
1,582 |
16 |
1,077 |
1 |
1,336 |
3 |
1,230 |
|
14 |
нго |
493 |
0,007 |
10 |
2,161 |
12 |
1,382 |
20 |
0,869 |
19 |
0,846 |
|
15 |
се |
450 |
0,007 |
7 |
5,945 |
6 |
2,120 |
17 |
1,002 |
15 |
1,013 |
|
16 |
нмъ |
434 |
0,006 |
4 |
22,517 |
3 |
4,581 |
16 |
1,010 |
4 |
1,206 |
|
17 |
КАМЪ |
428 |
0,006 |
1 |
174,472 |
1 |
8,409 |
4 |
1,055 |
7 |
1,108 |
|
18 |
Афе |
414 |
0,006 |
3 |
27,797 |
7 |
2,073 |
19 |
0,966 |
6 |
1,150 |
|
19 |
БО |
396 |
0,006 |
17 |
1,359 |
19 |
0,779 |
3 |
1,070 |
2 |
1,235 |
|
20 |
съ |
363 |
0,005 |
20 |
0,877 |
20 |
0,664 |
18 |
0,972 |
17 |
0,962 |
|
21 |
А^Ъ |
292 |
0,004 |
5 |
17,542 |
4 |
3,371 |
11 |
1,026 |
20 |
0,844 |
Примечание. R , R 1, R 2 – ранги словоформ; w – словоформа; F – абсолютная частота; f – относительная частота; Weirdness1 – вес словоформы в ЕП при сравнении ее частотности в трех подкорпусах (списков майских служебных миней, миней на другие месяцы года и стихирарей); Weirdness2 – вес словоформы в ЕП при сравнении ее частотности в семи подкорпусах (списков майских служебных миней, миней на другие месяцы года, стихирарей, Апостолов, Паренесисов, Псалтырей и летописей 11); Weirdness3 – вес словоформы в ЕП при сравнении ее частотности в подкорпусе полных апракосов; Weirdness4 – вес словоформы в ЕП при сравнении ее частотности в подкорпусе кратких апракосов.
Weirdness, полученный при сравнении абсолютной частоты употребления формы в ЕП с ее количеством в различных подкорпусах, а также ранги словоформы – номер по порядку в каждом из сопоставлений.
Представим эти данные в виде диаграмм (рис. 1–4). На рисунках 1 и 2 показаны значения в соответствии с Weirdness1 и Weirdness2, на рисунках 3 и 4 – в соответствии с Weirdness3 и Weirdness4.
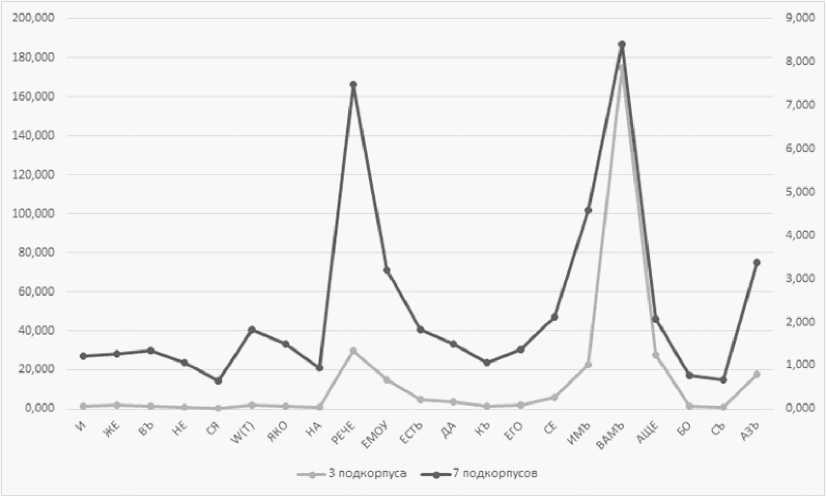
Рис. 1. Значения наиболее частотных словоформ ЕП в соответствии с мерой Weirdness при сравнении с тремя и семью разножанровыми корпусами
Fig. 1. Values of the most frequent EP word forms in accordance with the Weirdness measure when compared with three and seven different-genre corpora
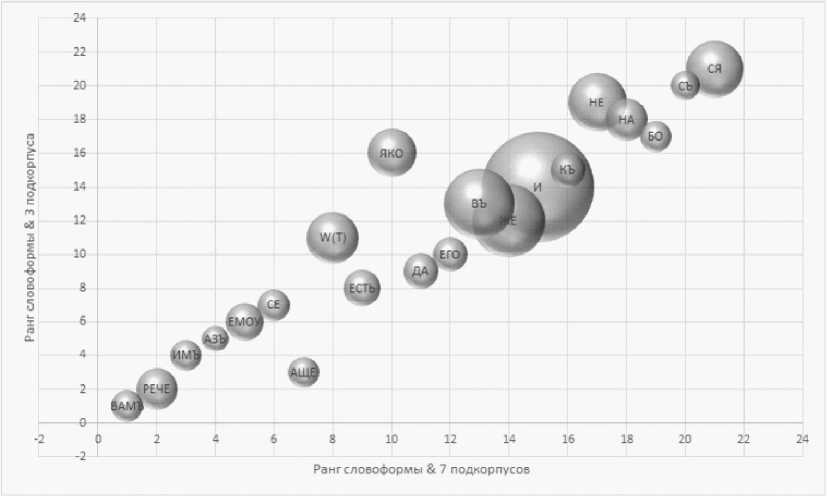
Рис. 2. Ранги наиболее частотных словоформ ЕП в соответствии с мерой Weirdness при сравнении с тремя и семью разножанровыми корпусами
Fig. 2. Ranks of the most frequent EP word forms according to the Weirdness measure when compared with three and seven different-genre corpora
На диаграммах хорошо видно, что изменение объема альтернативных подкорпусов и различия в их жанрах не приводят к принципиальному изменению значимости (веса, ранга) словоформ ЕП. Несмотря на то что величина меры Weirdness для некоторых форм может значительно отличаться при ее вычислении на основе различных альтернативных подкорпусов, степень значимости («странности») форм практически идентична (см. рис. 1: местоимения кдмъ , д^ъ , союз Афе , глагол peve и некоторые другие). Это демонстрируется также соответствием рангов одной и той же формы друг другу (см. рис. 2: местоимение кдмъ имеет ранги 1-1, глагол peve - 2-2 и т. д.).
Таким образом, данные диаграммы позволяют увидеть формы, характеризующие ЕП на фоне подкорпусов других жанров. В пределах 10 первых рангов находятся формы местоимений кдмъ , нмъ , д^ъ , км^ ,глагол peve , союз Афе , местоимение (союз-частица) ce .
Сравнение частотности словоформ в ЕП с их частотностью в полных и кратких апракосах демонстрирует как идентичную, так и существенно различающуюся оценку некоторых форм с помощью меры Weirdness.
Некоторая часть значений лежит в области значения 1,0 (см. рис. 3; на рис. 4 эти формы находятся на линии 0-0 – 24-24 и близко к ней), что свидетельствует об отсутствии значимых расхождений в частотности этих форм в ЕП и в двух альтернативных подкорпусах.
В то же время значения некоторых форм несколько или значительно превышают 1,0, что говорит об их большей относительной частотности в ЕП по сравнению с тем или иным подкорпусом: союз ьдко , предлог къ , частица но и имеют максимально высокий ранг (на рисунке 4 эти формы находятся в начале осей рангов). С большой долей вероятности можно считать, что частотность этих форм является особенностью именно ЕП на фоне других списков.
Одновременно видно, что оценка некоторых форм с помощью двух альтернативных подкорпусов (кратких и полных апракосов) существенно различна и даже противоположна. Так, предлог w имеет низкое значение (ранг 16) на фоне кратких апракосов и высокое (ранг 5) при сравнении с полными, и наоборот: словоформа нмъ , глагольная форма ксть , союз Афe высоко оцениваются при сравнении ЕП с краткими апракосами, но значительно ниже на фоне подкорпуса полных (см. рис. 4).
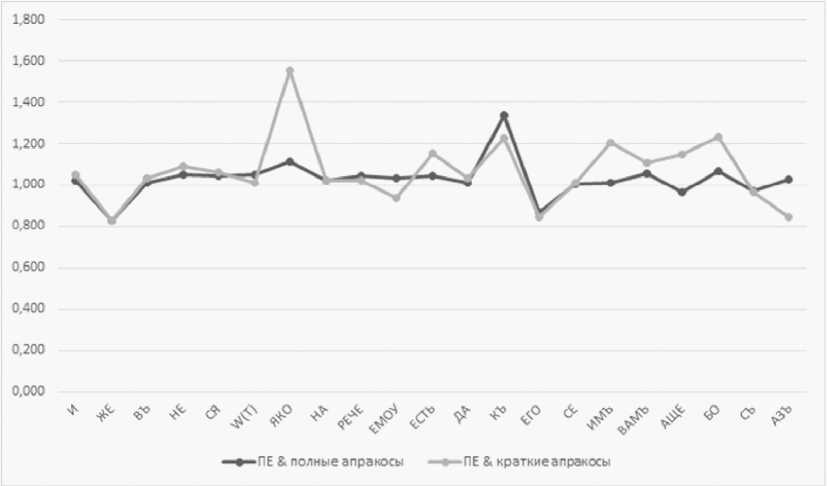
Рис. 3. Значения наиболее частотных словоформ ЕП в соответствии с мерой Weirdness при сравнении с подкорпусом полных и кратких апракосов
Fig. 3. Values of the most frequent EP word forms in accordance with the Weirdness measure when compared with the subcorpus of full and short aprakos
Таким образом, можно заключить, что союз №ко , предлог къ , частица ео , а также предлог w (на фоне других рукописей полного апракоса), местоимение нмъ , глагольная форма ксть , союз д^e (при сравнении с краткими апракосами) являются особенностью списка ЕП.
Подобные соотношения, демонстрирующие расхождения частотности служебных слов и некоторых форм местоимений и глагола еитн в ЕП и подкорпусах разного состава, позволяют говорить о значимых количественностатистических тенденциях, реализующихся в превышении средней частотности форм ЕП над средней частотностью аналогичных форм в контрастных подкорпусах.
Эксперимент 3. Извлечение статистически значимых сочетаний
Как известно, мера T-score дает возможность выявить в документе сочетания, частотность совместного использования компонентов которых выше статистически ожидаемой средней величины, иначе – найти такие сочетания, компоненты которых используются друг с другом чаще, чем с другими формами в тексте. Значение меры зависит от количества сочетаний компонентов и от количества каждого из компонентов в документе 12.
Приведем первые 20 биграмм ЕП, русских и старославянских списков (см. табл. 3 13).
Перечни близки по составу: 9 из 20 сочетаний трех выборок идентичны ( къ оно, гдк кдмъ, peve нмъ, peve гь, онъ же, peve км^, глД км^, онн же, ад не ), другие совпадают в двух группах (ЕП -др.-рус.: жe peve , съ ннмь, oyveHH^H кго ;ЕП-ст.-слав.: къ HeM^, w мдть^. глд нмъ, н peve ;др.-рус.-ст.-слав.: peve жe, жe еъ ).
Сама по себе подобная близость показательна и иллюстрирует жанровое единство сопоставляемых документов и подкорпусов.
Иная картина в начале перечней триграмм. Приведем первые 20 в ЕП, древнерусских и старославянских рукописях (см. табл. 4).
Состав статистически наиболее значимых триграмм так же, как и биграмм, безусловно, определен жанром и включает евангельские структурные, грамматические, семантические единства. Так, мерой высоко оценены композиционные формулы ^кд w мд , пдмA^"пpпEHдд%qд , по Eeлнqъ
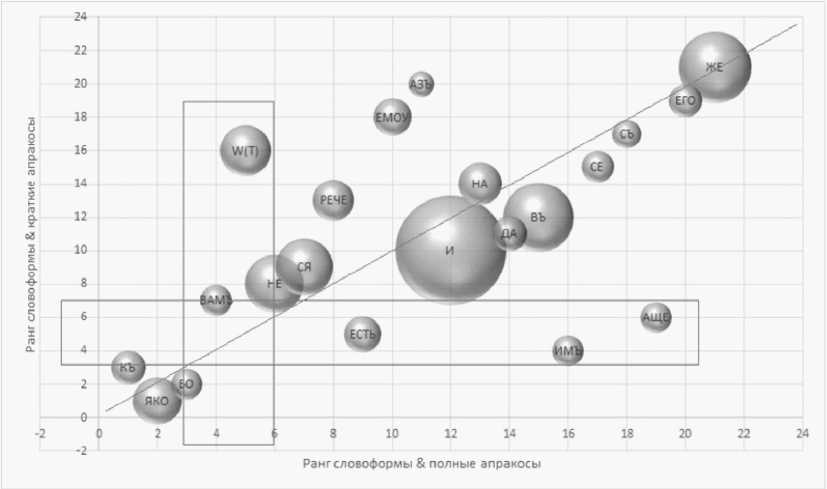
Рис. 4. Ранги наиболее частотных словоформ ЕП в соответствии с мерой Weirdness при сравнении с подкорпусом полных и кратких апракосов
Fig. 4. Ranks of the most frequent EP word forms according to the Weirdness measure when compared with the subcorpus of full and short aprakos
дне , [реуе] гь прнтъу» сни и под.), грамматически единые структуры ( нъсте лн уьлн -Мф. 12: 3, Мф. 22: 31, Мф. 19: 4, Мк. 12: 2 ЕП; дже дллъ есн - Ин. 17: 12
и др.), устойчивые семантические комплексы или их части ( нмъ^н ^шн елышлтн [дл слышнть] - Мф. 11: 15, Мф. 13: 9, Мк. 4:9, Лк. 8:8 и др.; [дл] ливнте другъ другл - Ин15:17 и нек. др.).
Некоторые триграммы являются со- ставной частью сочетаний, включающих большее количество грамматических или се- мантическихкомпонентов: об онъ полъ -онъ полъ морд - Ин. 6: 22, 25 и др., донъдеже положи Брлгъе - положи БрлгЪ! тК0№ - тК0№ подъножнк ноглмл - подънсжнк ноглмл тбонмл, Мф. 22: 44, Мк. 12: 36, Лк. 20: 43, къ ОБь^лМ ъ пог^въшнмъ —
ОБьцлМъ
пОРЫЕЪШнМЪ
дом^
[н^дрлнлекл] - Мф. 10: 06, Мф. 15: 24,
[peve] гь прнтъуи сни - Мф. 21: 33, Мф. 22: 1, Лк. 16: 1 и др.
Перечни ЕП и русского подкорпусов частично пересекаются. Так, в список 20 наиболее частотных форм вхоодят нмъ^н оушн слышлтн [дл слмшнть] , [дл] ливнте дроугъ дроугл , триграммы фраз донъдеже положи Брлгъе ткога подъножнк ноглмл тбонмл , об онъ полъ морд / нордлнл и др.
Увеличение количества анализируемых триграмм, получивших высокое значение меры T-score, до 50 позволяет выявить и другие семантически цельные сочетания. Например, в ЕП и русских списках - [не тръБуить] съдрлкнн крлул нъ БОЛА^нн -Лк.5:31;Бндъ рн^ъе кднны [лежл^л]-Лк. 24: 12; нмуже нъсмь достоннъ [отръшнтн ремень слпогу его] -Ин. 1: 27; в русских и старославянских списках – л^ъ нсмь ло^л нстнньнл^ - Ин. 15:1.
Таблица 3. Перечень первых 20 статистически значимых биграмм (мера T-score)
Table 3. List of the first 20 statistically significant bigrams (T-score measure)
|
№ п/п |
ЕП |
Древнерусские списки |
Старославянские списки |
||||||
|
Биграмма |
F |
T-score |
n -грамма |
F |
T-score |
Биграмма |
F |
T-score |
|
|
1 |
бъ оно |
194 |
13.467 |
онъ же |
597 |
23.640 |
еБгл w |
157 |
12.497 |
|
2 |
гли Блмъ |
129 |
11.247 |
реуе же |
621 |
22.021 |
реуе же |
175 |
11.976 |
|
3 |
реуе нмъ |
130 |
11.001 |
гли Блмъ |
469 |
21.469 |
реуе гь |
122 |
10.724 |
|
4 |
реуе гь |
125 |
10.997 |
бъ оно |
501 |
21.456 |
онъ же |
106 |
9.982 |
|
5 |
онъ же |
123 |
10.724 |
оно БрЪМА |
418 |
20.405 |
реуе ему |
105 |
9.629 |
|
6 |
къ нему |
112 |
10.502 |
реуе нмъ |
431 |
20.007 |
реуе нмъ |
91 |
9.168 |
|
7 |
реуе нму |
93 |
9.062 |
же р*^ |
466 |
19.311 |
глж Блмъ |
83 |
8.835 |
|
8 |
гл~л нму |
77 |
8.557 |
ууеннцн нго |
329 |
17.895 |
кь нему |
102 |
8.357 |
|
9 |
w млть* |
74 |
8.501 |
р^е нмъ |
319 |
17.265 |
же П |
74 |
7.887 |
|
10 |
же реуе |
105 |
8.358 |
сбонмъ ууеннкомъ |
292 |
17.062 |
же бъ |
76 |
7.875 |
|
11 |
глл нмъ |
64 |
7.805 |
онн же |
306 |
17.025 |
бъ оно |
63 |
7.758 |
|
12 |
w лукы |
62 |
7.782 |
же бъ |
367 |
16.846 |
ш'мл'” |
59 |
7.662 |
|
13 |
н реуе |
149 |
7.384 |
л^ъ нсмь |
287 |
16.813 |
н реуе |
155 |
7.537 |
|
14 |
онн же |
57 |
7.344 |
дл не |
384 |
16.465 |
гл~л ему |
56 |
7.272 |
|
15 |
съ ннмь |
54 |
7.303 |
бъ шно |
280 |
16.216 |
лкоу гл^л |
50 |
7.040 |
|
16 |
ууеннцн нго |
53 |
7.191 |
реуе нму |
299 |
16.180 |
онн же |
52 |
7.036 |
|
17 |
къннмъ |
48 |
6.866 |
р\ гь |
266 |
16.155 |
дл не |
67 |
6.927 |
|
18 |
дл не |
66 |
6.824 |
гл~л нму |
272 |
16.088 |
глл ему |
49 |
6.836 |
|
19 |
лмннъ гли |
45 |
6.672 |
съ ннмь |
261 |
16.019 |
же нсъ |
56 |
6.740 |
|
20 |
бъ домъ |
48 |
6.621 |
ннкто же |
270 |
16.007 |
глл нмъ |
37 |
5.937 |
Таблица 4. Перечень первых 20 статистически значимых триграмм (мера T-score) 14
Table 4. List of the first 20 statistically significant trigrams (T-score measure)
|
№ п/п |
ЕП |
Древнерусские списки |
Старославянские списки |
||||||
|
n -грамма |
F |
T-score |
n -грамма |
F |
T-score |
n -грамма |
F |
T-score |
|
|
1 |
нъсте АН УЬАн |
7 |
2.402 |
ПрПБНАА^ОЦА нАше^ |
52 |
6.780 |
еБГА W МА* |
53 |
3.626 |
|
2 |
нмлть жньотъ ВЪУЬНЫН |
8 |
2.327 |
ПАМА^ ПрПБНАА ОЦА |
57 |
6.700 |
ГЬ ПрнтЪУЖ сн^ |
12 |
3.324 |
|
3 |
нмъ^н оушн САЫШАТН |
5 |
2.206 |
СтрА стго МУНКА |
56 |
6.551 |
по БеАнцъ дне |
10 |
2.922 |
|
4 |
ОНЪ ПОАЪ морА |
5 |
2.140 |
нм^^н оушн САЫШАтн |
22 |
4.405 |
АМНн АМНн РАЖ |
14 |
2.745 |
|
5 |
ОБ ОНЪ ПОАЪ |
5 |
2.124 |
АНБнте другъ ДруРА |
22 |
4.303 |
ОБ ОНЪ ПОАЪ |
8 |
2.698 |
|
6 |
ГЬ ПрнтЪУН снн |
10 |
2.014 |
СтрАС стго СфНОМУНКА |
23 |
4.248 |
Но А-в еБ |
8 |
2.674 |
|
7 |
подъножнн НОГАМА ТЬОнМА |
4 |
1.999 |
СтрА стуъ МУНКЪ |
18 |
4.148 |
ГЬ СБО1МЪ ууеннкОМъ |
10 |
2.633 |
|
8 |
БЬсен дшек СБОеН |
4 |
1.995 |
прнШедъШнмъ к нъму |
21 |
3.835 |
снМОне нОНнНЪ АнБнШн |
5 |
2.233 |
|
9 |
ОБЬЦАМЪ ПОГ^БЪШнМЪ ДОМ^ |
4 |
1.994 |
еуА^нфн еептеМ |
52 |
3.757 |
Бее нМ^нне СБое |
5 |
2.153 |
|
10 |
ТКО^ подъножнн НОГАмА |
4 |
1.988 |
ПОАОжН БрАРЫ тбо^ |
15 |
3.675 |
АжеДААЪ еен |
6 |
2.149 |
|
11 |
донъдеже ПОАОжН БрАР'Ы |
4 |
1.980 |
МЬ^ДА БАША мНОГА |
15 |
3.579 |
нОНнНЪ АнБнШн Ан |
5 |
2.146 |
|
12 |
ПОАОжН БрАР'Ы тко^ |
4 |
1.979 |
снмоне нонннъ анбншн |
12 |
3.436 |
ГЬ Пр1тУЖ С1№ |
5 |
2.114 |
|
13 |
АНБнте другъ ДруРА |
4 |
1.968 |
к нъму нНД^ШМЪ |
20 |
3.428 |
еБГА W Ау^ |
13 |
2.107 |
|
14 |
бъстабъ ^АПрЪтн Б^тр^ |
4 |
1.966 |
А Другой ПАДе |
24 |
3.316 |
еБ^ wT м^а |
7 |
1.982 |
|
15 |
БЪрА тбо^ СПСе |
4 |
1.960 |
ОБ ОНЪ ПОАЪ |
20 |
3.270 |
ПрнтЪУЖ ен^ ПОДОБЬНО |
4 |
1.974 |
|
16 |
им^же нъсмь достоннъ |
4 |
1.940 |
КупнША нмь сеАО |
11 |
3.259 |
уБААЖ теБЪ БЪ^ДАЖ |
4 |
1.957 |
|
17 |
КЪ ОБЬЦАМЪ ПОРЫБЪШнМЪ |
4 |
1.939 |
нАн нНОГО УАНМЪ |
13 |
3.236 |
БеАнц^ дне м^ |
4 |
1.934 |
|
18 |
ДОМЪБАШЬ п^стъ |
4 |
1.924 |
ПрАБЫ тБОрнте СтЬ^А |
10 |
3.132 |
W Ау^р1 |
5 |
1.922 |
|
19 |
къ нему нКДЪОМЪ |
6 |
1.903 |
СтрА стон МУНКОу |
10 |
3.132 |
ОНЪ ПОАЪ нОрДАНА |
4 |
1.918 |
|
20 |
БЪ^БеДЪ ОYH СБОн |
4 |
1.900 |
нмеНА БАША НАПнСАНА |
10 |
3.127 |
а^ъ еемЬ АО^А |
5 |
1.916 |
Несмотря на ожидаемое достаточно большое количество пересечений трех выборок, состав триграмм в ЕП и в русском и старославянском подкорпусах Евангелий несколько различен. Так, среди триграмм, имеющих наибольшее статистическое значение в соответствии с мерой T-score, девять не повторяются в сопоставляе- мыхподкорпусах: h^ite лн уьлн, нмдть жнкотъ k^ykh^h, гь пpнтъYK сни, кьсеи диПи своей, еъстлкъ
^дпрътн ЕЪТ
роу , върд твои спсе ,
КЪ ОЕЬЦДМЪ ПОГ^ЕЪШНМЪ, ДОМЪ
кдшь п
стъ , къ немВ нндъомъ ,
0Y
еъ^еедъ oyh ceoh. Этот факт позволяет говорить и о специфике триграмм ЕП на фоне
подкорпуса древнерусских и старославянских списков.
Заключение
Результаты трех экспериментов по сопоставлению одно-, двух- и трехкомпонентных сочетаний ЕП и других евангельских списков исторического корпуса «Манускрипт» свидетельствуют о таких количественностатистических характеристиках лингвистических компонентов каждой из рукописей, которые могут быть признаны существенными.
Результаты первого эксперимента демонстрируют идентичность или близость порядка следования и относительного количества наиболее частотных форм ЕП и других полных апракосов при одновременных диагностируемых отличиях перечней ЕП от перечней кратких апракосов и старославянских списков: наименьшие различия обнаружены в парах «ЕП – полные апракосы» и «краткие апракосы – старославянские списки», а наибольшие – в «ЕП – краткие апракосы». Это убеждает в том, что состав перечней, порядок следования и относительная частота форм в них в совокупности являются существенными характеристиками рукописи или подкорпуса.
Второй эксперимент с использованием статистической меры Weirdness позволил установить, что состав статистически значимых форм ЕП (формы местоимений едмъ, нмъ, д^ъ, км^,глагол peYe, союз д^е, местоимение (союз-частица) се), выявляемых при сопоставлении с перечнями словоформ разножанровых подкорпусов, не зависит от объема констрастного подкорпуса; а сопоставление с подкорпусами кратких и полных апракосов дало возможность выявить формы, отличающие ЕП от других списков: союз ико, предлог къ, частицу но, а также предлог w (на фоне других рукописей полного апракоса), местоимение нмъ, глагольная форма ксть, союз д^е (при сравнении с краткими апракосами).
Текстовое единство Евангелий и одновременно специфику текста ЕП демонстрирует третий эксперимент, в котором, с одной стороны, из 20 биграмм, извлеченных с помощью меры T-score, половина идентична в ЕП и подкорпусах разных изводов, а триграммы с максимальным статистическим значением – это неизменяемые композиционные формулы ( екгд w мд^ и др.), цельные грамматические структуры ( лже ддлъ есн и др.), устойчивые семантические комплексы и их части ( [дд] линнте дроугъ дроугд и др.), с другой стороны, практически половина биграмм и триграмм ЕП отсутствует в перечне значимых сочетаний сопоставляемых подкорпусов ( нъсте лн Yьлн, нмдть жнкотъ e^ykh^h и др.).
Полученные результаты носят как общий, так и частный характер, позволяют говорить о результативности применения статистических методов к лингвистическому материалу славянских средневековых письменных памятников, о возможности обнаружения их неизвестных количественных характеристик.
Список литературы Опыт квантитативного исследования Пантелеймонова евангелия конца XII - начала XIII в. (три статистических эксперимента)
- Баранов В. А., 2019а. Создание и использование исторических корпусов славянских письменных памятников // Scripta & e-Scripta. Vol. 19. C. 33-57.
- Баранов В. А., 20196. Модуль статистики исторического корпуса «Манускрипт»: функции и демонстрация данных. 2 // И.А. Бодуэн де Куртенэ и мировая лингвистика. В 2 т. Т. 1 : Междунар. конф.: VII Бодуэновские чтения (Казан. федер. ун-т, 28-31 окт. 2019 г.) : тр. и материалы : Казань : Изд-во казан. ун-та. С. 24-30.
- Баранов В. А., 2019в. Опыт применения количественных и статистических методов для поиска значимых слов в историческом корпусе (на материале средневековых славянских гимнографических и евангельских кодексов) // Studia Hymnographica. Band II / hrsg. von H. Rothe, C. Schnell. Paderborn ; München ; Wien ; Zürich : Verlag Ferdinand Schoningh. P. 149-201. (Patrística Slavica ; Band 24).
- Зуга О. В., 2009. Из наблюдений над характером языковых разночтений в славянских списках Евангелия XII-XIII вв. (на материале «Притчи о блудном сыне») // Вестник Вятского государственного гуманитарного университета. № 3 (2). С. 40-46.
- Клышинский Э. С., Кочеткова Н. А., 2014. Метод извлечения технических терминов с использованием меры странности // Новые информационные технологии в автоматизированных системах. № 17. С. 365-370.
- Копотев М. В., 2014. Введение в корпусную лингвистику. Прага : Animedia Company. 230 с.
- Кочеткова Н. А., 2013. Статистические языковые методы. Коллокации и коллигации // Новые информационные технологии в автоматизированных системах. № 16. С. 301-305. URL: https://cyberleninka.ru/article/n7statisticheskie-yazykovye-metody-kollokatsii-i-kolligatsii (дата обращения: 31.05.2020).
- Литвинова Т. А., 2016. Судебная автороведческая экспертиза текста с целью установления пола его автора: проблемы и перспективы // Современное право. № 7. С. 111-115.
- Марков В. М., 2001. Из наблюдений над языком Пантелеймонова Евангелия (XII век) // Марков В. М. Избранные работы по русскому языка. Казань : ДАС. С. 31-56.
- Мартыненко Г. Я., 2014. Стилеметрия: возникновение и становление в контексте междисциплинарного взаимодействия // Структурная и прикладная лингвистика. № 10. С. 3-23.
- Мартыненко Г. Я., 2015. Стилеметрия: возникновение и становление в контексте междисциплинарного взаимодействия. Ч. 2. Первая половина XX века: расширение междисциплинарных контактов стилеметрии // Структурная и прикладная лингвистика. № 11. С. 9-28.
- Марусенко М. А., 1990. Атрибуция анонимных и псевдонимных литературных произведений методами распознавания образов. Л. : Изд-во Ленингр. ун-та, 164 с.
- Морозов Н. А., 1915. Лингвистические спектры : Средство для отличия плагиатов от истинных произведений того или другого известного автора : Стилеметрический этюд // Изв. Отд. рус. языка и словесности Имп. АН. СПб. Т. XX, кн. 4. С. 93-134.
- Пивоварова Л. М., Ягунова Е. В., 2014. От коллока-ций к конструкциям // Русский язык: грамматика конструкций и лексико-семантические подходы. СПб. С. 568-617. (Acta Linguistica petropolitana ; т. 10, № 2). URL: https://www. elibrary.ru/item.asp?id=23195921 (дата обращения: 31.05.2020).
- Прикладная и компьютерная лингвистика, 2016 / под ред. И. С. Николаева, О. В. Митрениной, Т. М. Ландо. М. : ЛАНАНД. 320 с.
- Сводный каталог славяно-русских рукописных книг, хранящихся в СССР: XI-XIII вв., 1984. М. : Наука. 406 с.
- Хохлова М. В., 2008. Экспериментальная проверка методов выделения коллокаций // Slavica Helsingiensia 34. Инструментарий русистики : Корпусные подходы. Хельсинки. С. 343-357. URL: https://www.elibrary. ru/item.asp?id=26581613 (дата обращения: 31.05.2020).
- Ягунова Е. В., Пивоварова Л. М., 2010. Природа коллокаций в русском языке. Опыт автоматического извлечения и классификации на материале новостных текстов // Сб. НТИ. Серия 2. № 6. С. 30-40.
- Ahmad K., Gillam L., Tostevin L., 1999. University of Surrey participation in Trec8: Weirdness indexing for logical documents extrapolation and retrieval // Proc. of Eighth Text Retrieval Conference (Trec-8). Gaithersburg : [s. n.]. P. 717-724.
- Baranov V., 2018. A Text Corpus of Medieval Manuscripts as a Goal and a Tool for Linguistic Research // Editing Mediaeval Texts from a Different Angle: Slavonic and Multilingual Traditions / ed. by L. Sels, J. Fuchsbauer, V. Tomelleri, I. de Vos. P. ; Bristol : Peeters Leuven. P. 283-308.
- Baranov V.A., Gnutikov R.M., 2019. The statistics and n-gram modules of the historical corpus "Manuscript" // Digital and Analytical Approaches to the Written Heritage : Proceedings of the 7th international conference El'Manuscript "Textual Heritage and Information Technologies" / comp. and ed. by A. Miltenova, V Baranov, H. Miklas, K. Hawkins, J. Fuchsbauer. Sofia : Gutenberg Publishing House. P. 9-28.
- Evert S., 2004. Association Measures // Computational Approaches to Collocations. URL: http:// collocations.de/AM/index.html (date of access: 31.05.2020).
- ЕП - Евангелие апракос полный («Пантелеймоново Евангелие») // РНБ. Соф. 1, кон. XII - нач. XIII (?) в. 224 л.
- Коллекция славянских Евангелий корпуса «Манускрипт». URL: http://manuscripts.ru/mns/portal. main?p1=30 (дата обращения: 31.05.2020).
- Корпус «Манускрипт: славянское письменное наследие». URL: http://manuscripts.ru/ (дата обращения: 31.05.2020).
- Модуль статистики корпуса «Манускрипт». URL: http://manuscripts.ru/mns/!cred2.stat (дата обращения: 31.05.2020).
- Модуль n-грамм корпуса «Манускрипт». URL: http://manuscripts. ru/mns/cred_ngr. stat (дата обращения: 31.05.2020).
- Электронное издание Пантелеймонова Евангелия. URL: http://manuscripts.ru/mns/portal. main?p1=21&p_lid=1 (дата обращения: 31.05.2020).
