Анализ образовательных данных при обучении иностранному языку в вузе

Автор: Котюрова И.А.
Журнал: Известия Волгоградского государственного педагогического университета @izvestia-vspu
Рубрика: Методология и технология профессионального образования
Статья в выпуске: 10 (183), 2023 года.
Бесплатный доступ
Представлен пример анализа базы данных корпуса студенческих текстов на немецком языке. Языковые ошибки анализируются у одного студента и у одной группы с целью показать, как может быть реализована образовательная аналитика, чтобы ей мог пользоваться преподаватель, не имеющий навыков работы с базами данных и статистического анализа.
Образовательная аналитика, аналитика образовательных данных, корпус студенческих текстов, анализ ошибок
Короткий адрес: https://sciup.org/148327489
IDR: 148327489
The analysis of the educational data in the process of teaching the foreign language in university
The article deals with the example of the analysis of the database of the corpus of the students’ texts at the German language. The language mistakes of one student and one group are analyzed to demonstrate how the educational analytics is possible to realize so that the lectures without the skills of the work with the database and the static analysis can use it.
Текст научной статьи Анализ образовательных данных при обучении иностранному языку в вузе
Введение. В теме дигитализации образования одним из важных трендов последних нескольких лет стала тема анализа образовательных данных (АОД) с целью улучшения качества образования. Сложно не согласиться с исследователями, утверждающими, что «необходимо разрабатывать доступные инструменты АОД, а также культуру их применения для принятия обоснованных решений и повышения качества высшего образования» [4, с. 763].
Как правило, когда речь заходит о примерах анализа больших данных в высшем образовании, говорят об анализе электронных портфолио студентов [1; 3; 5 и др.] и об интерпретации цифрового следа, оставляемого студентом на разных обучающих платформах и сайтах [6; 7; 8 и др.] с целью прогнозирования успешности или неуспешности обучения, формулировки индивидуальных рекомендаций по направлению развития обучающихся, а также с целью эффективного управления образовательным процессом в учреждении в целом. Гораздо реже статистическому анализу подвергаются не оценки за учебные работы, а ошибки, допущенные в этих работах. При этом именно такая автоматическая обработка и вдумчивый экспертный анализ полученных данных может и должен быть реализован в учебном процессе, поскольку именно это может подсказать педагогу, на чем надо заострить внимание студентов, а где тему можно считать освоенной полностью.
Для обеспечения образовательных данных с целью подобного анализа требуются специальные образовательные платформы или иные пункты сбора студенческих работ, подвергающихся автоматической обработке и сохранению данных как о работе, так и о ее авторе. В Петрозаводском государственном университете, начиная с 2020 г., собирается корпус студенческих текстов, написанных на немецком и французском языках, которые студенты-бакалавры изучают в качестве одного из основных профилей подготовки. База данных, собираемая в этом корпусе, который носит название ПАКТ (Петрозаводский аннотированный корпус текстов)* и в котором реализована визуализация данных, позволяет легко оценивать процесс обучения языку и быстро реагировать на выявляемые проблемы.
В данной статье мы остановимся на примере анализа ошибок у одного студента и у одной академической группы с целью показать, как может быть реализована образовательная аналитика, чтобы ей мог пользоваться преподаватель, не имеющий опыта работы с базами данных и статистического анализа.
Методология. Корпус ПАКТ представляет собой платформу, на которую студенты самостоятельно загружают свои письменные работы на иностранном языке, выпол-
* Петрозаводский аннотированный корпус текстов (ПАКТ). [Электронный ресурс]. URL: ru/app (дата обращения 15.09.2023).
няемые ими дома или непосредственно на занятии в вузе. Каждый текст при загрузке студентом, входящим в систему под своим логином и паролем, автоматически получает следующую метаразметку: ФИО, № академической группы, курс, дата создания, язык и тип текста (эссе, пересказ, реферирование статьи и т. п.). Каждый загруженный текст автоматически разбивается на предложения и слова, к которым приписываются теги* с указанием части речи. После этого эксперты вручную размечают в текстах языковые ошибки, указывая на их тип, степень грубости, исправление и в соответствующих случаях причину (интерференцию с русским, с английским языком или опечатку), а также выставляют оценку за работу. По состоянию на 25 июня 2023 г. объем немецкоязычной части корпуса, о которой пойдет речь ниже, составлял более 473 тыс. токенов, что позволяет анализировать собранные данные, выявляя тенденции и исключения. Обратимся к примеру анализа ошибок у одного студента и у целой группы как частному случаю образовательной аналитики с помощью корпуса ПАКТ, позволяющей определять более эффективные траектории обучения.
База данных корпуса ПАКТ содержит среди прочего сведения о количестве текстов, загруженных студентом на платформу, об объеме этих текстов, о количестве и видах ошибок в этих текстах**. Поскольку первые тексты корпуса относятся к концу 2019 г., а регулярно он начал формироваться с 2020 г., мы можем проводить лонгитюдный анализ ошибок в текстах одного и того же обучающегося и одной и той же группы на протяжении нескольких лет. Для разметки ошибок в немецкоязычной части корпуса студенческих текстов была разработана классификация из 90 тегов, анализ частотности которых применительно к одному человеку, группе, курсу и всему корпусу в целом позволяет делать разные выводы о ходе освоения языка отдельным человеком, группой или обобщенно русскоговорящими студентами, если сравнить данные корпуса с аналогичными зарубежными учебными корпусами.
Накопленная и постоянно пополняемая база корпуса студенческих текстов позволяет фильтровать и комбинировать разные данные и метаданные, так что, составляя соответствующие запросы на языке SQL, можно получать необходимые результаты, такие как, например, количество ошибок в текстах одного жанра (эссе, пересказах или реферировании), одного года или месяца, распределение ошибок по степени грубости у отдельного студента или целой академической группы, количество и тип ошибок, вызванных интерференцией с родным или первым иностранным языком и т. д.
Однако, даже не владея языком запросов, преподаватель может посмотреть актуальные показатели количества ошибок у обучающихся. Для этого на сайте корпуса реализована автоматическая визуализация, что делает задачу преподавателя максимально простой: достаточно выбрать из списка интересующего студента, интересующую группу или интересующий курс, чтобы увидеть графики с указанием количества ошибок, распределенных по типам. Пользователь также выставляет степень детализации по шкале от 0 (7 основных веток классификации ошибок) до 4 (все 90 типов ошибок в классификации). Возможно также скачивание данных в виде таблицы Excell, что бывает нужно для дополнительных исследований и сопоставлений, а также для представления в публикациях, поскольку большие графики удобно смотреть, увеличивая отдельные фрагменты, на экране, но не на бумаге.
В ходе исследования мы сначала выбрали данные для одного и того же студента, чьи работы собирались в корпусе на протяжении 3 лет, с целью проследить динамику этих ошибок. Далее мы выбрали показатели одной группы и одного студента из этой группы, чтобы посмотреть, насколько общая картина по группе соотносится или не со относится с по казателями отдельно взятого студента. Наконец мы посмотрели на гра-
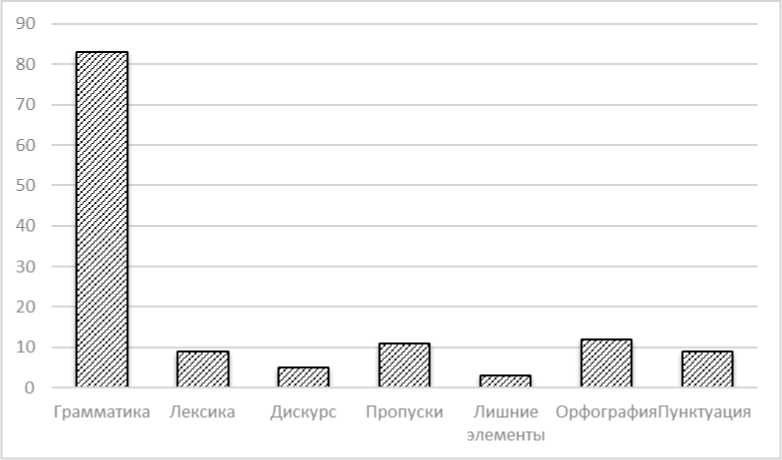
Рис. Ошибки студента N по основным категориям фик целой группы, сравнив его с показателями другой такой же целой группы, обучавшейся годом ранее.
Результаты и обсуждение. Сперва обратимся к статистике отдельного студента. С помощью фильтров дашборда на сайте корпуса выбираем студента N , выставляем уровень детализации 0 (распределение по основным веткам классификации) и смотрим на общую картину по всем работам данного студента (рис. на с. 78). Как было сказано выше, классификация ошибок в корпусе для немецкого языка включает 90 тегов. Все эти теги древовидно распределены по 7 основным веткам: грамматика, лексика, орфография, пунктуация, пропуски, лишние элементы и дискурс. Общая картина (рис. на с. 78) предсказуемо отражает сильное превалирование грамматических ошибок над всеми другими типами. Однако и разветвленность этой основной из 7 веток многократно выше: в раздел «Грамматика» входит 75 тегов, в то время как 15 оставшихся тегов распределены по другим 6 основным веткам, из которых орфография, пунктуация, пропуски и лишние элементы вообще не имеют внутренних разветвлений. Грамматике немецкого языка в учебном плане отводится большое внимание, поскольку этот раздел языка традиционно считается одним из самых сложных. Однако этот график показывает и значительное число орфографических ошибок, которых даже больше, чем лексических. Обучение орфографии в вузе обычно не проводится целенаправленно: нет специальных курсов по правописанию иностранного языка; написание слов студенты должны заучивать вместе со словом. Но являются ли орфографические ошибки следствием незнания, как пишется слово, или опечатки? Это вопрос, ответ на который также можно найти в статистике корпуса, однако это предмет отдельного исследования.
Чтобы посмотреть, какие именно грамматические ошибки есть у студента N , а также проследить их динамику в процессе обучения, обратимся к подробным таблицам Excell, где можно увидеть все 90 типов ошибок каждого студента на каждом курсе. В табл. 1 представлены типы ошибок, допущенных студентом N в 13 текстах на первом и
Таблица 1
Сравнение типов ошибок, допущенных в текстах одним и тем же студентом на 1 и на 3 курсе
|
1 курс |
3 курс |
||
|
Тег Ошибки |
Кол-во ошибок |
Тег Ошибки |
Кол-во ошибок |
|
Пунктуация |
8 |
Пунктуация |
16 |
|
Склонение им. прилагат. |
7 |
Склонение им. прилагат. |
6 |
|
Пропуски |
6 |
Пропуски |
7 |
|
Род им. сущ. |
6 |
Род им. сущ. |
1 |
|
Орфография |
6 |
Орфография |
10 |
|
Личные местоимения |
6 |
Личные местоимения |
2 |
|
Выбор лексемы |
5 |
Выбор лексемы |
5 |
|
Рамочная конструкция |
5 |
Рамочная конструкция |
1 |
|
Неопределенный артикль |
5 |
Неопределенный артикль |
2 |
|
Выбор предлога |
5 |
Выбор предлога |
2 |
|
Склонение им. сущ. |
3 |
Склонение им. сущ. |
3 |
|
Прямой порядок слов |
3 |
Прямой порядок слов |
3 |
|
Число им. сущ. |
3 |
Число им. сущ. |
4 |
|
Стиль |
3 |
Стиль |
1 |
|
Глаголы с отделяемой приставкой |
3 |
Глаголы с отделяемой приставкой |
1 |
|
Обратный порядок слов |
2 |
Обратный порядок слов |
1 |
|
Управление глаголов |
2 |
Управление глаголов |
2 |
|
Порядок слов |
2 |
Порядок слов |
1 |
|
Лишние элементы |
2 |
Лишние элементы |
6 |
|
Адвербиальные наречия |
1 |
Адвербиальные наречия |
2 |
|
Устойчивые обороты |
1 |
Устойчивые обороты |
1 |
|
Место второстепенного члена предложения |
1 |
Место второстепенного члена предложения |
2 |
|
Определенный артикль |
3 |
Логика |
3 |
|
Спряжение |
3 |
Презенс (выбор временной формы) |
3 |
|
Притяжательные мест. |
3 |
Соединительные элементы |
2 |
|
Инфинитивные констр. с zu |
1 |
Деривативные суффиксы |
1 |
|
Нулевой артикль |
1 |
Лексика |
1 |
|
Порядковое числительное |
1 |
Причастие II |
1 |
|
Предлоги с опред. падежом |
1 |
Перфект |
1 |
|
Возвратное местоимение |
1 |
Местоимение |
1 |
|
Тема-рематич. членение |
1 |
Сильные глаголы |
1 |
|
Выбор временной формы |
1 |
Словообразование |
1 |
|
Прочие числительные |
1 |
Порядок слов в придаточном предложении |
1 |
Таблица 2
|
Тип ошибки |
Количество ошибок на 100 токенов у одного студента |
Количество ошибок на 100 токенов в среднем в группе |
|
|
1 |
Пунктуация |
0,47 |
0,38 |
|
2 |
Орфография |
0,30 |
0,63 |
|
3 |
Пропуски |
0,21 |
0,32 |
|
4 |
Склонение прилагательного |
0,18 |
0,40 |
|
5 |
Лишние элементы |
0,18 |
0,19 |
|
6 |
Выбор лексемы |
0,15 |
0,55 |
|
7 |
Число |
0,12 |
0,19 |
|
8 |
Склонение |
0,09 |
0,34 |
|
9 |
Прямой порядок слов |
0,09 |
0,10 |
|
10 |
Логика |
0,09 |
0,05 |
|
11 |
Презенс |
0,09 |
0,02 |
|
12 |
Неопределенный артикль |
0,06 |
0,34 |
|
13 |
Личное местоимение |
0,06 |
0,10 |
|
14 |
Выбор предлога |
0,06 |
0,08 |
|
15 |
Соединительные элементы |
0,06 |
0,05 |
|
16 |
Управление глаголов |
0,06 |
0,04 |
|
17 |
Место второстеп. членов предложения |
0,06 |
0,04 |
|
18 |
Наречия |
0,06 |
0,03 |
|
19 |
Род |
0,03 |
0,22 |
|
20 |
Порядок слов в придат. предложении |
0,03 |
0,19 |
|
21 |
Обратный порядок слов |
0,03 |
0,17 |
|
22 |
Рамочная конструкция |
0,03 |
0,05 |
|
23 |
Устойчивые обороты |
0,03 |
0,04 |
|
24 |
Сильный глагол |
0,03 |
0,03 |
|
25 |
Стиль |
0,03 |
0,03 |
|
26 |
Местоимение |
0,03 |
0,03 |
|
27 |
Перфект (образование формы) |
0,03 |
0,02 |
|
28 |
Лексика |
0,03 |
0,02 |
|
29 |
Словообразование |
0,03 |
0,02 |
|
30 |
Словообразовательные суффиксы |
0,03 |
0,02 |
|
31 |
Глагол с отделяемой приставкой |
0,03 |
0,02 |
|
32 |
Порядок слов |
0,03 |
0,01 |
|
33 |
Причастие II |
0,03 |
0,01 |
|
34 |
Определенный артикль |
0,00 |
0,16 |
Продолжение таблицы 2
Сопоставление статистики студента N с показателями академической группы, в которой он занимается
Типы ошибок в таблице выстроены в порядке убывания частотности на 1 курсе, при этом сначала представлены те ошибки, которые были как на первом, так и на третьем году обучения. Диагональной штриховкой выделены те ошибки, которые не встречаются на другом курсе. Так, если в начале обучения студент допускал ошибки на использование определенного артикля, притяжательных местоимений, числительных и на спряжение глаголов, то на третьем курсе таких ошибок не встретилось ни одной. Зато появились ошибки на словообразование, логику, соединительные элементы и т. п.
Сравнение количественных показателей тех ошибок, которые присутствуют в обеих частях таблицы, позволяют судить о том, какие темы студент осваивает лучше, а какие хуже. В большинстве строчек наблюдается снижение или сохранение частотности, однако в трех темах заметен явный рост количества ошибок (выделены светло-серым фоном): втрое вырос показатель в ошибках «Лишние элементы», вдвое – на пунктуацию, и в полтора раза – на орфографию. Надо отметить, что все три пункта не относятся к темам, которые специально изучаются на занятиях. Лишние элементы почти всегда являются следствием невнимательности, когда студент дважды повторяет один и тот же фрагмент предложения. Орфографические ошибки в работах конкретно этого студента тоже чаще вызваны опечатками, чем незнанием, как правильно пишется слово. Таким образом, в данном случае можно рекомендовать студенту более внимательно относиться к выполнению задания и обязательно перечитывать работу перед загрузкой в корпус.
Полезную информацию дает также сопоставление статистики этого студента с показателями академической группы, в которой он занимается. Для объективности сравнения необходимо выбрать не абсолютные, а пропорциональные значения, т. е. сравнить таблицы значений, где указано количество ошибок на каждые 100 токенов (табл. 2).
Сравнительная таблица, выстроенная по убыванию количества ошибок в работах студента N , написанных на 3 курсе, свидетельствует о том, что его показатели почти везде отличаются от средних показателей по группе. При этом отличие это есть как в большую сторону – по 16 типам ошибок (выделены штриховкой), так и в меньшую (в 48 типах ошибок). И хотя разница в значениях очень незначительная, все же определение мест, где показатели выше среднего по группе, четко указывает на те аспекты, которые требуют особого внимания именно этого студента.
Кроме высвечивания относительно слабых мест в знании конкретного студента N , табл. 2 позволяет сделать еще один вывод. Она статистически подтверждает интуитивный опыт преподавателей в том, что, несмотря на одно и то же обучение, разные студенты по-разному осваивают те или иные темы. Субъективные мнения о том, что какой-то студент «сильный» или «слабый», нередко распространяются и на группу. Чтобы подтвердить или опровергнуть этот тезис на уровне не одного студента, а целой группы, сопоставим статистику ошибок в работах первокурсников двух разных лет набора, обучавшихся у одного и того же преподавателя, по одним и тем же учебным материалам и идентичным рабочим программам.
В табл. 3 приводятся показатели из базы данных для студентов первого курса двух разных лет приема.
Из табл. 3 были удалены все типы ошибок, где показатель частотности на каждые 100 токенов был ниже 0,01, поэтому общее количество типов ошибок, встретившихся на первом курсе в два разных учебных года, составляет только 52. Как видно из таблицы, практически все значения во второй колонке ниже значений в первой колонке. Исключения составляют только «Логика», «Адвербиальные наречия», «Сложные слова» и «Порядок слов при отрицании», где показатель оказался на 0,01 выше значения в группе, занимавшейся годом ранее. Таким образом, можно утверждать, что вторая группа
Таблица 3
Количество ошибок на каждые 100 токенов в работах первокурсников разных лет приема
|
Тип ошибки |
Количество ошибок на 100 токенов в 1 группе |
Количество ошибок на 100 токенов в 2 группе |
|
|
1 |
Выбор лексемы |
0,92 |
0,32 |
|
2 |
Пунктуация |
0,54 |
0,19 |
|
3 |
Орфография |
0,52 |
0,19 |
|
4 |
Склонение |
0,38 |
0,17 |
|
5 |
Неопределенный артикль |
0,27 |
0,19 |
|
6 |
Склонение им. прилагательного |
0,26 |
0,14 |
|
7 |
Логика |
0,22 |
0,03 |
|
8 |
Пропуски |
0,22 |
0,21 |
|
9 |
Претерит |
0,19 |
0,00 |
|
10 |
Лишние элементы |
0,17 |
0,11 |
|
11 |
Порядок слов в придат. предложении |
0,16 |
0,06 |
|
12 |
Обратный порядок слов |
0,15 |
0,03 |
|
13 |
Определенный артикль |
0,13 |
0,05 |
|
14 |
Род |
0,11 |
0,05 |
|
15 |
Личное местоимение |
0,10 |
0,06 |
|
16 |
Выбор предлога |
0,10 |
0,04 |
|
17 |
Число |
0,09 |
0,05 |
|
18 |
Прямой порядок слов |
0,08 |
0,03 |
|
19 |
Спряжение |
0,08 |
0,04 |
|
20 |
Рамочная конструкция |
0,08 |
0,02 |
|
21 |
Нулевой артикль |
0,07 |
0,01 |
|
22 |
Притяжательное местоимение |
0,06 |
0,01 |
|
23 |
Инфинитивные конструкции с zu |
0,06 |
0,02 |
|
24 |
Соединительные элементы |
0,06 |
0,01 |
|
25 |
Дискурс |
0,06 |
0,01 |
|
26 |
Стиль |
0,06 |
0,01 |
|
27 |
Местоимение |
0,05 |
0,00 |
|
28 |
Устойчивые обороты |
0,05 |
0,01 |
|
29 |
Склонение местоимений |
0,05 |
0,04 |
|
30 |
Конъюнктив |
0,05 |
0,00 |
|
31 |
Управление глаголов |
0,04 |
0,00 |
|
32 |
Место второстепен. членов предложения |
0,04 |
0,03 |
|
33 |
Тема-рематич. членение предложения |
0,04 |
0,00 |
|
34 |
Презенс (образование формы) |
0,04 |
0,01 |
|
35 |
Предлог, управляющий двумя падежами |
0,03 |
0,02 |
|
36 |
Претерит (выбор временной формы) |
0,03 |
0,00 |
|
37 |
Инфинитивные конструкции без zu |
0,02 |
0,00 |
|
38 |
Сильный глагол |
0,02 |
0,01 |
Продолжение таблицы 3
Количество ошибок на каждые 100 токенов в работах первокурсников разных лет приема
Заключение. Дигитализация образования позволяет проще проводить образовательную аналитику и быстрее реагировать на выявляемые в ходе анализа данных проблемы. При этом целесообразно не только собирать базу данных для проведения исследований, но и реализовать автоматическую визуализацию этих данных, чтобы сделать задачу преподавателя максимально простой: достаточно выбрать из списка интересующего студента, интересующую группу или интересующий курс, чтобы увидеть графики с указанием количества и типа ошибок. Исследование показало, что, несмотря на определенные общие тенденции, количественное распределение ошибок по видам в отдельно взятой академической группе в сравнении с другой группой такого же курса и у отдельно взятого студента на фоне других студентов той же академической группы может сильно разниться. Анализ данных корпуса при этом позволяет гибко реагировать на такие особенности и определять индивидуальную траекторию обучения.
Несмотря на то что сформированная база корпуса ПАКТ уже показала себя как источник очень широких возможностей для образовательной аналитики, все же нельзя не отметить, что этот инструмент находится пока на начальной стадии разработки. Тре- буется большая работа по совершенствованию автоматической обработки и визуализации накапливаемых данных, а также по внедрению инструментов реагирования на выявляемые проблемы, например, в виде автоматических рекомендаций или предложения набора специально подобранных для каждого случая упражнений. Кроме того, одна из ключевых проблем внедрения новых технологий заключается в необходимости мотивирования и обучения кадров, которые будут применять эти методики в своей повседневной практике.
Список литературы Анализ образовательных данных при обучении иностранному языку в вузе
- Анализ учебной деятельности в электронном портфолио / Е.А. Ильина, М.М. Гладышева, Н.А. Дьяконов и др. // Азимут научных исследований: педагогика и психология. 2019. Т. 8. № 1(26). С. 137-140.
- Котюрова И.А., Щеголева Л.В. Корпус студенческих текстов на немецком языке как источник данных для образования и науки // Вопросы образования. 2022. № 4. С. 322-349.
- Попова Н.А., Егорова Е.С. Интеллектуальный анализ образовательных данных для прогноза успеваемости студентов вуза // Известия Кабардино-Балкарского научного центра РАН. 2023. № 2(112). С. 18-29.
- Семёнкина И.А., Прусакова П.В. Направления исследований в области анализа образовательных данных в высшей школе: теоретический обзор // Педагогика. Вопросы теории и практики. 2023. Т. 8. № 7. С. 761-770.
- Скиба И.Г., Тарасюк И.С., Нестеренков С.Н. Анализ образовательных данных в высших учебных заведениях // Информационные технологии и системы 2022 (ИТС 2022): материалы Международной научной конференции, Минск, 23 ноября 2022. Минск, 2022. С. 167-168.
- Сторожева С.П. Анализ образовательных данных обучающихся для мониторинга вовлеченности при использовании ресурсов электронной библиотеки // Информатизация образования и методика электронного обучения: цифровые технологии в образовании: материалы VI Международной научной конференции: в трех частях, Красноярск, 20-23 сентября 2022 года. Красноярск, 2022. С. 80-84. Т. 2.
- Токтарова В.И., Попова О.Г. Анализ образовательных данных взаимосвязи успешности обучения и поведения студентов в цифровой образовательной среде вуза // Информатика и образование. 2022. № 37(4). С. 54-63.
- Azcona D., Hsiao I.-H., Smeaton A.F. Detecting Students-at-Risk in Computer Programming Classes with Learning Analytics from Students' Digital Footprints // User Modeling and User-Adapted Interaction. 2019. Vol. 29. Iss. 2.
