Multimodal Assessment of Student Engagement by Fusing EEG, Facial Expressions, and Body Posture in an Offline Classroom

Author: Min Song, I Gusti Putu Sudiarta, Putu Kerti Nitiasih, Putu Nanci Riastini, Zhang Wang, Junyi Chai
Journal: International Journal of Modern Education and Computer Science @ijmecs
Article in issue: 3 vol.18, 2026.
Free access
An accurate and comprehensive assessment of student engagement in classrooms is crucial for enabling data-driven teaching and personalized education. Current approaches primarily rely on teacher observation or student self-reports, which are often subjective, delayed, and unable to capture cognitive engagement. To address these limitations, this study proposes a Multimodal Cognitive-Attention Fusion (MCA Fusion) framework, grounded in Fredricks’ three-dimensional engagement model. The framework integrates electroencephalography (EEG), facial expressions, and body posture to simultaneously quantify cognitive, emotional, and behavioral engagement. Built on a Transformer architecture, it employs self-attention to extract temporal features within each modality and introduces a cognition-guided cross-attention mechanism to dynamically integrate multimodal signals. To validate the framework, experiments were conducted with 36 undergraduate students in real classroom settings. The results demonstrate that our framework significantly outperforms all single-modality baselines, achieving an accuracy of 92% and an F1-score of 94.87%. Compared with the best single-modality model (EEG), the F1-score improves by 34.58 percentage points. Ablation studies further confirm the critical role of the cognitive modality (EEG) and the MCA Fusion mechanism, the removal of which leads to F1-score reductions of 62.58 and 56.16 percentage points, respectively. The proposed approach not only provides a theoretically informed and technically evaluated framework for engagement recognition but also provides a methodological foundation for future closed-loop “perception–assessment–feedback” systems in intelligent learning environments.
Student Engagement, multimodal fusion, MCA Fusion, EEG, Facial Expression Recognition, Body Posture Analysis
Short address: https://sciup.org/15020364
IDR: 15020364 | DOI: 10.5815/ijmecs.2026.03.12
Text of the scientific article Multimodal Assessment of Student Engagement by Fusing EEG, Facial Expressions, and Body Posture in an Offline Classroom
The digital transformation of education has intensified the demand for data-driven teaching and personalized interventions. At the heart of this shift lies a central challenge: the real-time, comprehensive, and objective assessment of student learning states [1,2]. Among these states, student engagement stands out as particularly crucial, given its well-established influence on learning outcomes and educational quality [3-5]. Traditionally, engagement has been assessed through teacher observation and student self-reports. These approaches, however, are highly subjective, lack timeliness, and are difficult to adapt to large-scale dynamic classroom environments, leading to growing concerns over their reliability [6]. Consequently, the adoption of automated and objective technologies has become an inevitable trend.
A powerful lens for analyzing this challenge is Fredricks' widely applied three-dimensional engagement framework from educational psychology, which conceptualizes student engagement across cognitive, emotional, and behavioral dimensions [7]. This theoretical perspective not only provides a structured taxonomy but also immediately reveals the inherent limitations of approaches relying on a single type of measurement. Consequently, existing automated studies have made progress from different, yet often isolated, angles. Computer vision-based methods analyze facial expressions and body posture to infer emotional and behavioral engagement, offering advantages of being non-invasive and easy to deploy [8-10]. However, such methods struggle to detect deeper cognitive states, such as “ pseudo-engagement ” [11]. To overcome this, some researchers have turned to physiological signals like electroencephalography (EEG), often regarded in prior laboratory-based research as a “gold standard” for assessing cognitive load and attention [12], particularly when implemented with multi-channel research-grade systems [13,14]. Nevertheless, EEG also has notable limitations, including its intrusiveness, complex signal interpretation, and lack of behavioral context [15].
Multimodal Learning Analytics (MMLA) has gradually emerged as a promising research direction to address these gaps [16-19]. Yet, existing studies still reveal significant shortcomings [20]. Some focus only on integrating external behavioral modalities without delving into the cognitive dimension [9,21,22], while others incorporate physiological signals but neglect emotional aspects [23-25]. Therefore, constructing a unified framework that effectively integrates cognitive physiological signals (EEG), emotional visual cues (facial expressions), and behavioral dynamics (body posture) remains an urgent and unmet research need.
In response, this study develops a novel Transformer-based multimodal fusion model and makes three key contributions:
• Providing a comprehensive assessment framework that integrates EEG, facial expressions, and body posture, directly mapping these modalities to the three dimensions of engagement.
• Proposing a novel cognition-guided cross-attention mechanism, which uses EEG features as queries to dynamically filter and weight emotional and behavioral signals, enabling a more informed fusion process.
• Offering empirical validation in real classroom settings, demonstrating superior performance over established unimodal and multimodal baselines, thereby enhancing the ecological relevance of the approach within authentic classroom settings.
2. Methodology2.1. Overall Framework Design
2.2. Data Collection and Preprocessing
2.2.1. Experimental Design and Data Collection
The methodology elaborates on the multimodal framework for student engagement assessment, which is grounded in Fredricks’ three-dimensional engagement theory. The framework integrates electroencephalography (EEG), facial expressions, and body posture data to construct an end-to-end deep learning system. In accordance with ethical principles, our study was approved by the institutional review board of our organization. Furthermore, all data were anonymized after collection to protect participant privacy.
A preliminary experiment was conducted in this research. The overall architecture, as illustrated in Figure 1, comprises four main stages: (1) data acquisition and preprocessing, (2) single-modality feature representation, (3) multimodal data fusion, and (4) engagement classification. The central idea is to build a three-dimensional representation space that comprehensively reflects students’ classroom engagement by leveraging the collaborative perception and dynamic fusion of EEG and visual behavioral data. The visual behavioral data are processed through two parallel streams: Facial Expression Recognition (FER) and Body Posture Recognition (BPR).
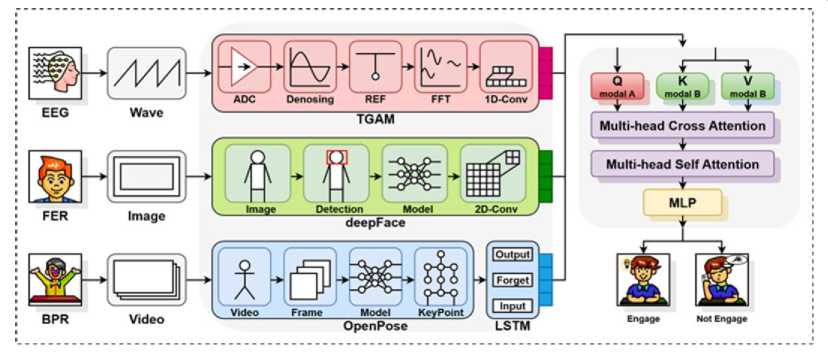
Fig. 1. Framework of the multimodal engagement assessment system.
This study was carried out within a smart classroom located at a Chinese university. Visual behavioral data were collected non-intrusively via a front-facing HD camera permanently installed above the blackboard, while cognitive data were obtained through a wearable EEG headset. All other intelligent functions were disabled to preserve ecological validity during the regular class sessions [26].
-
• Participants: Thirty-six first-year undergraduate students majoring in Software Engineering participated in the study (mean age = 18.9 ± 0.7 years; 19 males, 17 females). All participants reported normal or corrected vision, without any neurological or psychological conditions, and each gave written informed consent before participation.
All participants were first-year undergraduate students majoring in Software Engineering from a single university. Although the data were collected in authentic classroom settings, the homogeneity of the sample may limit the generalizability of the findings across different disciplines and institutions. Future studies will extend validation to more diverse and multi-institutional populations.
-
• Experimental Task: Participants attended their regular compulsory Python programming course. Data were recorded during six standard instructional sessions (40 minutes each), randomly selected from the curriculum. The pedagogical design of these sessions—which included lectures, programming practice, and group discussions—was intentionally varied to naturally elicit a wide spectrum of student engagement states.
-
• Data Acquisition and Annotation Protocol: The specifications for multimodal data collection and the engagement labeling scheme are detailed in Table 1.
-
2.2.2. Multimodal Data Preprocessing and Feature Engineering
Table 1. Data Acquisition and Annotation Protocol.
|
Category / Component |
Device/Platform |
Key Parameters / Description |
|
EEG |
TGAM dry electrode module |
Single channel (Fp1); 512 Hz sampling rate; 0.5–50 Hz bandwidth |
|
Facial Expression |
HD camera + DeepFace |
1920×1080 resolution; 30 fps; realtime valence analysis |
|
Body Posture |
Same camera + OpenPose |
2D skeletal keypoint detection (18 keypoints) |
|
Annotation (Ground Truth) |
Label Studio 1.18 |
Manual annotation; 10-second window; based on the threedimensional engagement framework |
The single-channel Fp1 dry-electrode configuration was adopted to minimize classroom disruption and ensure deployment feasibility in authentic instructional environments. Although this setup does not provide high-resolution spatial brain mapping comparable to multi-channel research-grade EEG systems, it is sufficient for capturing coarsegrained frontal attentional fluctuations relevant to engagement modeling. The design prioritizes ecological consistency and practical applicability over laboratory-level spatial precision.
Following Fredricks’ three-dimensional framework, cognitive, emotional, and behavioral features were extracted. All features were computed within a 10-second sliding window (stride = 5 seconds) to ensure temporal alignment and cross-modal consistency [27]. The process included signal preprocessing, feature encoding, and vector representation for each modality.
-
i. Cognitive Engagement via EEG
Cognitive engagement, reflecting the level of attention and mental resource allocation, was assessed through EEG spectral analysis. In line with established methodologies, this study employed the ratio of beta (13–30 Hz) to theta (4–8 Hz) band power as an indicator of attention and cognitive load [28]. The detailed procedure is as follows:
-
a. Filtering:
The EEG signals were first detrended and mean-centered, followed by a 50 Hz notch filter to suppress power-line interference, and then subjected to an infinite impulse response (IIR) band-pass filter with a range of 0.5–50 Hz to eliminate low-frequency drift and high-frequency disturbances while retaining physiologically relevant components.
To further mitigate ocular and muscle artifacts commonly present in frontal single-channel recordings, discrete wavelet transform (DWT)-based denoising with adaptive soft-thresholding was performed on overlapping signal windows. In addition, a signal-quality mask was applied to exclude segments with abnormal amplitude or abrupt fluctuations before spectral feature computation.
-
b. Frequency Decomposition:
Perform a Fast Fourier Transform (FFT) on the preprocessed EEG signals to calculate the relative power spectral density (PSD) across four standard frequency bands: δ (0.5–4 Hz), θ (4–8 Hz), α (8–13 Hz), and β (13–30 Hz).
-
c. Convolutional Encoding:
The extracted band-power features were processed using a one-dimensional convolutional neural network (1D-CNN) to learn short-term temporal dependencies along the time sequence [29]. The operation for the i -th convolutional channel is given by:
У ( i ) [ t ] =f (l K10 ™ ( i ) [ k] х [ t-k ] +b ( i ) / (1)
where x[t] is the input sequence, w(1)[/c] represents the convolution kernel weights, b(1) is the bias term, and f(-) denotes a nonlinear activation function.
-
d. Feature Representation:
All convolutional channel outputs were integrated through global average pooling (GAP) and concatenated to construct the final cognitive feature vector:
h eeg=Concat ( GAP ( y ( 1 ) ) ,GAP ( y ( 2 ) ) , ...,GAP ( y ( n ) )/ (2)
The resulting h eeg serves as a high-level representation of students' cognitive engagement for subsequent multimodal fusion.
-
ii. Emotional Engagement via Facial Expression
Emotional engagement, reflecting students' emotional states, was operationalized as continuous emotional valence. The detailed procedure is as follows:
-
a. Face Preprocessing:
-
Facial regions were detected and aligned using YOLOv11n and MTCNN.
-
b. Emotion Feature Extraction:
2D-CNN was utilized to extract salient features from the facial images for emotion recognition. This network learns hierarchical representations of expressions by sequentially applying multiple layers of convolution and pooling operations [30]. Let the к-th local receptive field of the input image be x[ k], the convolution kernel weights be w(1)[ k], the bias term be b)l\ and the nonlinear activation function be f(-). The activation value for the i -th filter at a specific location is given by:
z ( i ) =f (l K'=o w ( i ) [ k ] -X [k ] +b ( i ) ) (3)
-
c. Feature Representation:
The CNN outputs were aggregated via GAP to obtain a fixed-dimensional emotional feature vector:
z enoton ^Concat ( gap ( z ( 1 ) ) ,gap ( z ( 2 ) ) , _,gap ( z ( n ) )) (4)
The resulting feature vector was subsequently processed by a fully connected regression layer to predict a continuous valence score vE [-1,1]. In this scale, higher scores correspond to positive emotional states (e.g., enjoyment, satisfaction), whereas lower scores represent negative emotional responses (e.g., confusion, frustration). This score was treated as the representation of students’ emotional engagement in classroom contexts and subsequently fed into the multimodal fusion model for integrated analysis.
-
iii. Behavioral Engagement via Body Posture
Behavioral engagement reflects students’ outward participation in classroom activities and is often manifested through their posture stability, attention direction, and movement amplitude. In this study, students’ body movements were quantitatively analyzed using OpenPose to extract skeletal keypoints and construct a temporal representation of postural dynamics. The main procedure involved three stages:
-
a. Keypoint Extraction:
Each video frame was processed using OpenPose to identify the two-dimensional coordinates of major skeletal keypoints—such as the head, shoulders, and hands—denoted as pt E R d. By arranging these coordinates over time, a temporal posture sequence {p,, p 2 ,^,p r}was generated, providing a continuous description of students’ movement trajectories during classroom learning.
-
b. Temporal Feature Modeling:
Inputting pose sequences into a Long Short-Term Memory (LSTM) network to capture dynamic pose patterns through its recurrent structure [31]. The recurrent process can be expressed as:
s t ,c t =LSTM (pfS t-i >c t-i ) (5)
where st is the hidden state and c t is the memory cell state at time t .
-
c. Feature Representation:
-
2.2.3. Engagement Label Definition and Annotation
The sequence of hidden states was summarized using GAP to produce a compact behavioral feature vector:
h pose GAP ( s 1 ,s 2 ,^,s T ) (6)
This vector encodes the temporal and spatial characteristics of students’ posture changes, serving as the representation of behavioral engagement. It was subsequently integrated with EEG and facial expression features in the multimodal fusion stage for comprehensive engagement assessment.
This study employed a manual annotation methodology to establish robust engagement labels. The coding framework was operationalized based on Fredricks' theoretical model of engagement, which was adaptively refined to accurately capture student participation in the observed learning context, thereby ensuring both the construct validity and coding consistency of the labels.
-
i. Label Definition
The student engagement status for each data segment was categorized into three classes based on Fredricks' threedimensional engagement framework. The definitions for each category are provided in Table 2. For detailed operational criteria and behavioral indicators, annotators referred to a comprehensive annotation manual to ensure consistent and objective labeling.
Engagement labeling was grounded in task-aligned behavioral consistency rather than isolated visual features. Annotators evaluated whether students’ behaviors were continuously aligned with the ongoing instructional task, including sustained task focus, synchronization with instructional events, responsiveness to learning content, and absence of non-learning activities. Observable cues such as gaze direction, posture, or facial expression served only as evidence carriers to support holistic behavioral interpretation and were not treated as independent labeling rules.
Table 2. Student engagement label definitions.
|
Category |
Definition |
|
Engaged (Task-related) |
The student remains focused on the current learning task and exhibits positive emotions or sustained classroom behaviors, such as attentive gaze, nodding responses, active gestures, or stable posture. |
|
Not engaged (Task-unrelated) |
The student demonstrates behaviors or emotional states unrelated to the learning task, such as daydreaming, chatting with peers, using a mobile phone, or showing obvious boredom or resistance. |
|
Unidentifiable |
Due to occlusion, missing frames, or highly ambiguous postures, annotators cannot reliably determine the learning state. |
For experimental validity and model reproducibility, only Engaged and Not engaged samples were retained in the classification task. Segments labeled as Unidentifiable were excluded from both training and testing, as they lacked discernible features for reliable modeling. These segments were excluded to prevent label noise rather than to simplify the classification boundary.
-
ii. Annotation Procedure
To ensure the consistency and reliability of the ground-truth labels, a rigorous multi-step annotation procedure was implemented.
-
a. Preparation and Training:
A standardized annotation manual was developed, detailing label definitions, operational criteria, and visual examples. All annotators underwent unified training and were required to pass a consistency test before formal annotation.
-
b. Annotation Process:
During formal annotation, a 10-second time window with a 5-second stride was used. For each window, annotators made a comprehensive assessment by integrating cues from students' gaze, facial expressions, body posture, and the classroom context. Importantly, annotators did not have access to model-derived features or EEG signals during the labeling process.
-
c. Reliability Assessment:
To quantify inter-rater reliability, each data segment was independently annotated by two raters. The agreement was assessed using Cohen's Kappa statistic, yielding an average value of 0.88, which indicates almost perfect agreement [32].
-
d. Adjudication:
2.3. Model Architecture
-
2.3.1. Modality-Specific Encoders
In cases of disagreement, a third expert rater provided a final adjudication. The resolved label was used as the definitive ground truth for model training and evaluation.
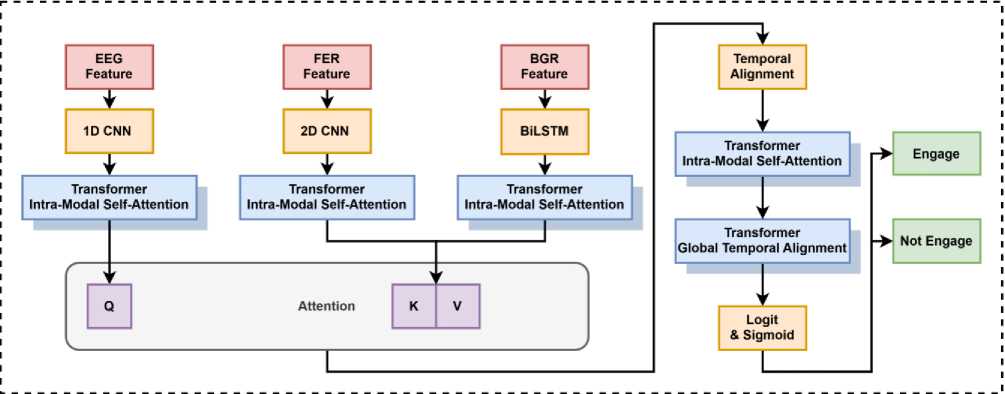
Fig. 2. Overall architecture of the Multimodal Cognitive-Attention Fusion (MCA Fusion) framework.
This study adopts a Multimodal Cognitive-Attention Fusion (MCA Fusion) framework. The framework follows a late fusion paradigm, where high-level features are first extracted from each modality and then integrated through a dedicated cognition-guided fusion module. This approach preserves the unique spatiotemporal characteristics of each modality while enabling dynamic interaction. The overall architecture, illustrated in Figure 2, consists of three core components: modality-specific encoders, the MCA Fusion module, and an engagement classification module.
Each modality input is processed by an independent sub-network to extract high-level semantic features:
-
i. EEG Branch
This branch models the preprocessed EEG signals using a 1D-CNN to capture local temporal patterns and spatial correlations across different frequency bands. The network outputs the cognitive feature vector heeg.
-
ii. Facial Expression Branch
This branch takes aligned facial images as input. 2D-CNN is applied to extract deep, multi-level emotional representations. The network outputs the emotional feature vector ^emotion along with the corresponding continuous valence score V .
-
iii. Body Posture Branch
This branch analyzes the sequential dynamics of body posture by processing skeletal keypoints from successive video frames using a LSTM network. The network outputs the behavioral feature vector hpose . The detailed architecture of this branch is illustrated in Figure 3.
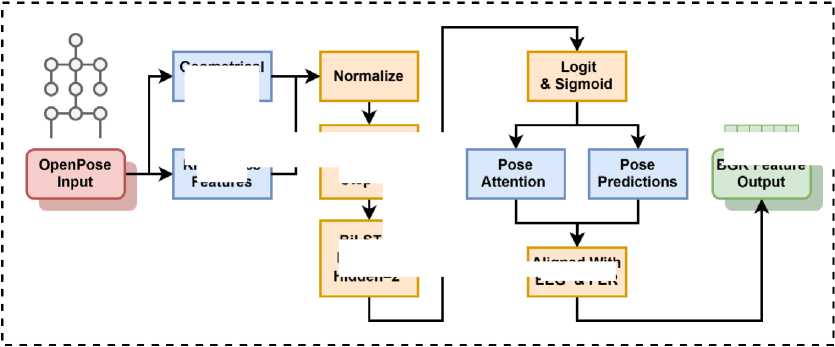
Fig. 3. Architecture of the Body Posture Branch.
Geometrical Features
Kinematics Features
Slide Window Lenth=30 Step=1S
BGR Feature
BiLSTM Layer=64 Hidden=2
-
2.3.2. Cross-Modal Fusion Module
-
2.3.3. Engagement Classification Module (Classifier Design)
This module is constructed using a Transformer-based architecture, employing self-attention and cross-attention mechanisms to enhance inter-modal interaction and collaborative representation learning [33-35]. Specifically, in this study, the EEG feature vector h eeg is designated as the query vector (Q), while the feature vectors derived from facial expressions and body posture are used as keys (K) and values (V), respectively.
This design is motivated by the central assumption that internal cognitive states are the core of engagement and should therefore serve as a guiding signal to filter and modulate the relative importance of external behavioral and emotional features. The corresponding attention mechanism is mathematically expressed as:
Attention(Q,K,V)=Softmax
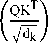
where d^ denotes the dimensionality of the key vectors. The final output is a cross-modal fused representation modulated and enhanced by cognitive signals.
It should be clarified that the three-dimensional engagement framework serves as representational grounding for multimodal feature modeling rather than as the direct prediction label space. The cognitive, emotional, and behavioral dimensions are preserved in the internal representation learning stage, while the final binary classification functions as a decision-level objective to ensure stable model optimization under limited sample conditions.
The integrated multimodal representations were processed through a dense layer that employed a Softmax activation mechanism to generate the final engagement classification outcomes. The model was optimized using a Weighted Binary Cross-Entropy (BCE) Loss function to address the challenge of imbalanced class distributions, which is common in authentic classroom recordings [36]:
L=-1 H =i (w i -y • log p i +w 0 •( 1 -y i )• log( 1 -p i )) (8)
Here, yt £ {0,1} denotes the ground-truth engagement state for the i-th sample(0= not engaged, 1= engaged), pt represents the predicted probability of engagement, and W ! and w0 are the weights for positive and negative samples, respectively, to mitigate class imbalance.
While the MCA Fusion model introduces additional cross-attention layers, the overall architectural depth and feature dimensionality remain within a comparable scale to the baseline fusion models. This design ensures that performance differences primarily reflect differences in fusion strategy rather than arbitrary increases in model capacity.
A standard 70/15/15 split was applied to partition the dataset for training, validation, and testing. To prevent subject-level data leakage and ensure a realistic evaluation setting, the dataset was partitioned following a subjectindependent protocol rather than a random window-level split. Specifically, all samples belonging to a single participant were assigned exclusively to only one subset. The training process utilized the Adam optimizer with an initial learning rate of 0.001 and a batch size of 32 [37], coupled with a Cosine Annealing Scheduler for adaptive learning rate decay [38]. Additionally, early stopping based on the validation F1-score (patience = 15 epochs) was applied to reduce the risk of overfitting [39].
3. Results and Discussion
This section is organized into a systematic assessment of the MCA Fusion model's performance. The empirical assessment includes comparative analysis with baseline models and ablation experiments. These quantitative results offer a robust foundation for the subsequent discussion of the model's efficacy and behavioral implications.
-
3.1. Model Performance Comparison
An empirical validation was conducted to assess the efficacy of the MCA Fusion model by comparing it against several baseline approaches on an identical test set. The baseline models included three unimodal models (EEG, facial expression, and body posture), an early fusion model (feature concatenation + MLP), and a benchmark late fusion model (direct concatenation of modality-specific feature vectors followed by classification). The performance of all these models, as measured by Accuracy, Precision, Recall, and F1-Score, is comprehensively compared in Table 3.
To ensure the robustness of the experimental results, all models were trained and evaluated five times using different random seeds under the same subject-independent data partition protocol, and the results are reported as mean ± standard deviation.
For the early fusion model, features from EEG, facial expression, and body posture are concatenated into a single vector and fed into a three-layer MLP for classification. For the late fusion model, each modality is encoded separately, weighted via a gating network, and combined with pairwise cross-modal interaction features. A residual projection preserves modality-specific information before the final MLP produces the binary classification output.
Table 3. Classification Results of the MCA Fusion versus Baseline Models (Note: Bold values indicate the best performance in each column. Results are reported as mean ± standard deviation across five runs.).
|
Model Type |
Accuracy (%) |
Precision (%) |
Recall (%) |
F1-score (%) |
|
EEG (Unimodal) |
46±0.84 |
87.23±1.12 |
46.07±0.95 |
60.29±0.88 |
|
Facial Expression (Unimodal) |
66.63±0.76 |
21.7±0.91 |
30.54±1.03 |
25.37±0.94 |
|
Body Posture (Unimodal) |
66.41±0.81 |
32.92±1.05 |
67.7±0.92 |
44.3±0.89 |
|
Early Fusion |
86.7±0.65 |
85.9±0.72 |
85.0±0.68 |
85.4±0.71 |
|
Late Fusion |
60±0.91 |
63.79±0.86 |
66.07±0.79 |
64.91±0.82 |
|
MCA Fusion |
92±0.48 |
93.67±0.53 |
96.1±0.44 |
94.87±0.79 |
The results presented in Table 3 reveal several key observations:
-
• Performance of Multimodal vs. Unimodal Models: All multimodal fusion models (Early Fusion, Late Fusion, and MCA Fusion) all recorded higher F1-scores than the best-performing unimodal model (EEG, F1-score = 60.29%).
-
• Comparison of Fusion Strategies: The benchmark Late Fusion model (F1-score = 64.91%) yielded a lower F1-score than the Early Fusion model (F1-score = 85.40%).
-
• Performance of the MCA Fusion Model: The MCA Fusion model achieved the highest values across all four evaluation metrics. Its F1-score (94.87%) shows an improvement of 29.96 percentage points over the benchmark late fusion model and 34.58 percentage points over the best unimodal model.
-
3.2. Ablation Study
To further analyze the fairness of the comparison, the parameter sizes of the fusion models were examined. The Early Fusion and Late Fusion models contain 13,441 and 11,664 parameters respectively, while the proposed MCA Fusion model contains 96,547 parameters. The increase in parameters mainly comes from the cross-modal attention module used in the MCA Fusion architecture.
Although the MCA Fusion model introduces additional parameters, the improvement in performance cannot be attributed solely to increased model capacity. The cross-modal attention mechanism enables the model to capture interactions among EEG, facial expression, and body posture features more effectively than simple concatenation-based fusion strategies. This allows the MCA Fusion model to better exploit complementary multimodal information.
A comprehensive ablation study was conducted to deconstruct the contributions of core components within the MCA Fusion architecture. In this process, particular modules were selectively excluded or replaced with simplified alternatives, and the resulting variations in model performance were examined. All ablation experiments were repeated five times with different random seeds under the same subject-independent data partition protocol, and the mean performance is reported. The relatively small variation across runs (see F1 ± std) indicates that the observed performance gaps are not caused by random fluctuations or training instability. The corresponding results from this experimental procedure are documented in Table 4.
Table 4. Ablation Analysis on the Contributions of Model Components (Note: Δ F1 indicates the drop in F1-score compared with the full model. Results are reported as mean ± standard deviation across five runs.).
|
Ablation Setting |
Accuracy (%) |
F1-score (%) |
Δ F1 (pp) |
|
Full Model (MCA Fusion) |
92±0.48 |
94.87±0.79 |
— |
|
(a) Removing EEG modality |
63.43±1.12 |
32.29±1.36 |
-62.58 |
|
(b) Removing cross-attention mechanism |
81±0.95 |
38.71±1.18 |
-56.16 |
|
(c) Replacing with simple feature concatenation |
64.68±1.07 |
43.14±1.25 |
-51.73 |
The ablation study led to the following findings:
-
• Effect of EEG Modality Removal: The exclusion of the EEG modality (setting a) resulted in the most severe performance drop, with the F1-score decreasing by 62.58 percentage points. This result highlights the dominant role of cognitive-state information in engagement modeling and confirms that the multimodal framework cannot rely solely on affective or behavioral cues.
-
• Effect of Fusion Mechanism Alteration: Both the removal of the cross-attention mechanism (setting b) and its replacement with simple feature concatenation (setting c) led to substantial performance degradation, with F1-scores falling by 56.16 and 51.73 percentage points, respectively. The cross-attention module explicitly models conditional dependencies between cognitive and affective modalities, enabling dynamic modality alignment and noise suppression. When this interaction modeling is removed, the network loses its ability to capture cross-modal semantic dependencies, leading to a non-linear degradation in discriminative representation quality. The relatively small standard deviations further confirm that the large performance gaps are structurally induced rather than caused by overfitting or instability.
-
3.3. Discussion
-
3.3.1. Interpretation of Results and Theoretical Implications
-
3.3.2. Methodological Contributions and Practical Implications
-
3.3.3. Comparison with Existing Studies
This section provides an in-depth interpretation of the experimental results, explores their theoretical and practical implications, compares them with existing research, and objectively discusses the study’s limitations and future directions.
The experimental findings demonstrate that the MCA Fusion model, which integrates cognitive, emotional, and behavioral information, significantly outperforms all unimodal models and conventional multimodal baselines. This result is consistent with the multidimensional perspective of engagement proposed by Fredricks et al. [7], which posits that classroom engagement is a complex, multi-faceted construct that cannot be fully captured by a single modality. Among unimodal models, the behavioral (posture) and emotional (facial expressions) modalities performed relatively poorly, suggesting that relying solely on external observations is susceptible to “pseudo-engagement”. In contrast, the
EEG unimodal model achieved the best baseline performance, underscoring the central role of the cognitive dimension in engagement assessment.
More importantly, the MCA Fusion yielded significant performance gains compared with simple feature concatenation and standard late fusion. This finding indicates that effective multimodal fusion is not a mere aggregation of information but rather a dynamic and selective decision-making process. By using EEG features as the query, the model actively retrieves emotional and behavioral signals relevant to the current cognitive state, thereby shifting from “static fusion” to “cognition-driven dynamic fusion.” This introduces a new paradigm for learning analytics, in which internal physiological signals serve as anchors to interpret external behaviors.
The ablation study further reinforced these conclusions. Removing the EEG modality led to the largest performance drop, highlighting the indispensable role of cognitive signals in accurate assessment. Removing the crossattention mechanism confirmed that the fusion strategy itself—rather than the mere increase in parameters—contributes to the performance improvement.
From a practical perspective, this study translates a psychological theory into a feasible technological pathway for supporting intelligent teaching systems. The proposed framework enables earlier and more accurate identification of students' disengagement, thereby offering objective data support for personalized instructional interventions. Furthermore, the collection and validation of data in real classroom environments significantly enhance ecological validity, demonstrating strong potential for real-world application.
This study shares a common goal with recent influential works [23,24,40,41], which aim to enhance the accuracy of student engagement assessment through multimodal fusion. However, it makes differentiated contributions in three key aspects:
-
• Theoretical integrity: Guided by Fredricks' model of student engagement, the study simultaneously collected cognitive, emotional, and behavioral data, avoiding the limitation of missing dimensions found in some prior research.
-
• Architectural advancement: By introducing a Transformer-based cross-attention mechanism, the model achieved asymmetric and dynamic fusion across modalities, surpassing commonly used symmetric or static fusion approaches.
-
• Authenticity of validation: Unlike studies relying on controlled laboratory tasks, the data in this study were collected from continuous real classroom teaching, making the conclusions more reflective of authentic classroom dynamics within the investigated context.
-
3.3.4. Limitations and Future Work
Although this study has yielded positive results, several limitations must be acknowledged, which also illuminate productive pathways for future research.
• Sample size and generalizability: All participants came from the same major and grade, with a limited sample size (N = 36). Future research should validate the model’s generalizability across larger and more diverse populations.
• Data quality and equipment trade-offs: Although portable dry-electrode EEG systems improved ecological validity, their signal-to-noise ratio remained lower than that of laboratory-grade wet electrodes. Future studies could explore advanced signal processing methods (e.g., deep denoising) or high-precision devices.
• Challenges in real-time application: The current system relies on offline analysis. To enable real-time feedback, further research is required on model lightweighting and distributed computing to meet the low-latency requirements of classroom use.
• Granularity of state analysis: The present study focused on binary classification (engaged vs. disengaged). Future work could extend to multi-level engagement (high/medium/low) or finer-grained learning states (e.g., confusion, focus, boredom) to provide more precise instructional support.
4. Conclusion
This study comprehensively investigated intelligent student engagement analysis by developing and empirically evaluating a novel multimodal fusion framework informed by Fredricks et al.’s multidimensional engagement theory. The core of this work lay in operationalizing this theoretical structure into a computational model, where EEG signals, facial expressions, and body postures were strategically selected to represent cognitive, emotional, and behavioral dimensions, respectively. The proposed MCA fusion model leveraged a cognition-guided cross-modal attention mechanism, which was empirically demonstrated to be highly effective in assessing student classroom engagement.
Experimental results confirmed that the proposed approach not only outperformed both unimodal and traditional multimodal baselines but also validated the indispensability of the cognitive dimension and the advantages of dynamic, asymmetric fusion over static fusion strategies.
The findings of this study hold significant theoretical and practical implications. Theoretically, this work demonstrates how a well-established psychological framework can inform the design of a data-driven computational system, contributing an operational perspective to multidimensional engagement research. Practically, it offers a feasible and robust technical pathway for developing next-generation learning analytics tools capable of delivering granular, objective assessments of student engagement in real classroom settings.
Looking ahead, this work opens several promising research avenues. Future studies will focus on extending the validation of this paradigm to diverse educational contexts and larger populations. The natural evolution of this technology will involve progressing from binary classification toward modeling a continuous spectrum of engagement and more nuanced learning-centered states. Furthermore, efforts will be directed at advancing the system toward practical, real-time classroom applications, with the ultimate goal of empowering educators with precise, actionable insights to enhance teaching and learning outcomes.
All the Declarations and StatementsAuthor Contributions Statement
Min Song – Conceptualization, Methodology, and Writing – Original Draft: Proposed the research idea, designed the overall research framework, and prepared the initial manuscript.
I Gst. Putu Sudiarta – Supervision, Review and Editing: Provided academic supervision, reviewed the manuscript, and contributed to improving the clarity and quality of the paper.
Putu Kerti Nitiasih – Methodology and Academic Guidance: Provided methodological guidance and academic suggestions during the research process.
Putu Nanci Riastini – Validation and Educational Analysis: Contributed to the validation of the research results and provided educational analysis related to the study.
Zhang Wang – Software Implementation and Experimental Design: Assisted with software implementation and the design of experimental procedures.
Junyi Chai – Data Processing and Visualization: Responsible for data preprocessing and visualization of experimental results.
All authors have read and agreed to the published version of the manuscript.
Conflict of Interest Statement
The authors declare no conflicts of interest.
Funding Declaration
None.
Data Availability Statement
The datasets generated and analyzed during the current study are available from the corresponding author upon reasonable request.
Ethical Declarations
This study was conducted in accordance with institutional ethical standards. All participants were informed about the purpose of the study and consent was obtained prior to participation.
Acknowledgments
We sincerely thank the experts for their professional evaluation and valuable recommendations, which have contributed to improving the quality of the experiment and the reliability of its results.
Declaration of Generative AI in Scholarly Writing
During the preparation of this manuscript, the authors used ChatGPT to assist with English language editing and grammar refinement. The authors carefully reviewed and revised the generated content and take full responsibility for the final manuscript.
Abbreviations
The following abbreviations are used in this manuscript:
MCA Fusion-Multimodal Cognitive-Attention Fusion
EEG- Electroencephalography
FER-Facial Expression Recognition
BPR-Body Posture Recognition
Appendix
None.
