Задача оптимизации времени выполнения проекта в вычислительной сети из персональных компьютеров

Автор: Румянцев Александр Сергеевич
Журнал: Программные системы: теория и приложения @programmnye-sistemy
Рубрика: Программное и аппаратное обеспечение распределенных и суперкомпьютерных систем
Статья в выпуске: 1 (19) т.5, 2014 года.
Бесплатный доступ
Рассмотрена модель процесса выполнения одного проекта в вычислительной сети из персональных компьютеров при условии равного времени выполнения подзаданий. Исследованы условия, при которых репликация подзаданий между узлами сети сокращает общее время выполнения проекта в двух частных случаях модели: при выполнении пачек подзаданий, а также при ненулевом штрафе за невыполнение подзадания.
Стохастическое моделирование, вычислительные сети, оптимизация
Короткий адрес: https://sciup.org/14335970
IDR: 14335970 | УДК: 004.75
Optimizing the execution time of a desktop grid project
A model of computation time of a project in a Desktop Grid is viewed, under the following restrictions: the number of nodes is stationary, it takes each task the same time equal to deadline to complete, under the condition of deadline violation the task is to be calculated again. An inequality connecting probability of a single error in calculation of a task, number of replicas and number of tasks is concluded that shows when replication is necessary. An inequality connecting number of replicas, probability of a single error and penalty for error is concluded, which shows when replication is profitable. (\emph{in Russian}).
Текст научной статьи Задача оптимизации времени выполнения проекта в вычислительной сети из персональных компьютеров
Наряду с суперкомпьютерами, высокопроизводительные вычислительные сети из персональных компьютеров (ВСПК) типа Desktop Grid являются важным средством ускорения вычислений. Гибкость и простота реализации проектов являются привлекательными для исследователей, что отражается в широте спектра прикладных задач, решаемых с помощью распределенных вычислений, см., напр. [1 –4] . В то же время для ВСПК достаточно остро стоит задача оптимизации времени выполнения проекта [5 , 6] .
Существенным отличием ВСПК от вычислительных кластеров является территориальная распределенность первых, а также неста-ционарность во времени вычислительных узлов сети. Это связано с тем, что значительная часть ВСПК основана на принципах добровольных вычислений, когда участники ВСПК на безвозмездной основе предоставляют авторам проектов простаивающие вычислительные мощности своих персональных компьютеров. При этом приложения, связанные с проектом, имеют более низкий приоритет по сравнению
Работа поддержана грантом РФФИ, проект 13-07-00008.
○c А. С. Румянцев, 2014
○c Программные системы: теория и приложения, 2014
с программами пользователя, работающего на этом компьютере. В случае превышения пользовательской нагрузкой некоторого порогового значения, связанные с проектом вычисления приостанавливаются, чтобы исключить воздействие на производительность компьютера в момент решения задач пользователя. При этом вычисление нарушивших так называемый дедлайн (предельное время выполнения) подзаданий останавливается. Кроме того, в отличие от ресурсов вычислительных кластеров, компьютеры пользователей доступны, как правило, не круглосуточно. Таким образом, наиболее частой причиной остановки выполнения подзаданий проекта является нарушение дедлайна по причине отсутствия свободных вычислительных ресурсов и/или недоступности компьютеров [7, 8] .
Для борьбы с излишне частыми нарушениями дедлайна применяют репликацию подзаданий проекта, когда подзадание с одними и теми же исходными данными рассылается одновременно нескольким участникам [9] . При этом в качестве канонического может приниматься результат, полученный первым по времени, либо может использоваться схема кворума, когда необходимо совпадение полученных результатов с заданной точностью от нескольких вычислительных узлов. Репликация позволяет повысить надежность получаемых результатов, в то же время такой метод может увеличивать общее время вычисления проекта. Таким образом, актуальной является задача нахождения условий, при которых репликация не ухудшает ключевых показателей эффективности проекта, среди которых чаще всего рассматривается общее время выполнения проекта [10] .
В данной работе рассматривается вероятностная модель выполнения одного проекта на одном сервере ВСПК. Целью работы является нахождение условий для модели ВСПК, при которых репликация приводит к снижению общего времени вычисления проекта. В модели предполагается, что количество участников ВСПК неизменно (новые участники не добавляются, а старые не покидают проект). Кроме того, для простоты предполагается, что все подзадания проекта вычисляются одно и то же детерминированное время (такт, равный дедлайну). Это упрощение справедливо для тех систем, в которых проект состоит из решения достаточно вычислительноемких подзаданий при условии, что для различных исходных данных время вычисления подзаданий различается незначительно. Предполагается также, что причиной остановки подзадания на узле является нарушение дедлайна (по причине отсутствия свободного времени для вычислений или в связи с выключением узла). Таким образом, в рассматриваемой модели за один вычислительный такт каждое подзадание гарантированно либо получает верный результат, либо останавливается в связи с истечением времени, отведенного на расчет. В случае остановки подзадания сервер ВСПК вынужден отправлять подзадание с теми же исходными данными на повторный расчет.
-
1. Оценка необходимости репликации
Пусть р е (0, 0.5) есть вероятность остановки одного подзадания. Для снижения вероятности остановки подзадания в процессе вычислений сервер может посылать одно и то же подзадание v узлам одновременно. При этом для получения канонического результата сервер ожидает кворум из v q > 1 ответов, полученных до дедлайна (в случае v o = 1 сервер ожидает любой из ответов, полученный первым по времени). Тогда вероятность успешного достижения кворума за один такт равна
q* := ^ (V)P ^ — 4 (1 — Р)1 > (1 — Р) = Q. i = vo ' 7
Отметим, что репликация замедляет вычисления в v раз, однако при этом вероятность удачного вычисления подзадания за такт возрастает. Поскольку сервер отправляет остановленные подзадания повторно неограниченное число раз, то процесс вычисления подзадания представляет собой классическую схему Бернулли. При этом среднее число передач одного и того же подзадания до первого успеха составит 1/q тактов для схемы без репликации и 1/q * тактов для схемы с репликацией. С учетом замедления вычислений при использовании репликации, разность между средним временем вычисления N подзаданий проекта в двух рассматриваемых схемах равна
A N vN o(q, v, v q ) := - .
Тогда репликация была бы оправдана для тех значений р, v, v q , для которых 5(q, v, v 0 ) > 0, т. е.
q * — vq> 0.
p
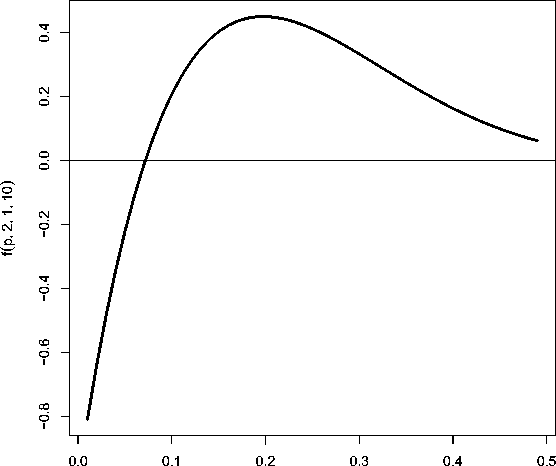
Рис. 1. Значения функции / (р, и, и 0 ,п) при и = 2, и 0 = 1, п = 10 для 0 6 р 6 0 . 5; положительность функции означает оправданность репликации
Однако, поскольку q > 0.5, v > 2,q * 6 1, то в области допустимых значений параметров нет значений, удовлетворяющих неравенству (1) . Таким образом, репликация в данном случае невыгодна.
Рассмотрим модификацию модели, в которой в целях экономии трафика сервер при отправке подзаданий группирует подзадания в пачки по п штук с одними и теми же исходными данными, при этом ненулевое число остановок в пачке приводит к повторной отправке целой пачки (по аналогии с моделью, предложенной в [11], где ошибка одного из процессов в параллельно выполняемой задаче на вычислительном кластере приводила к остановке всей задачи). Вероятность успешного завершения вычисления пачки за один такт есть qn, а среднее число тактов до удачного вычисления всей пачки равно 1/q”. Рассмотрим одновременно схему с репликацией, предполагая, что сервер ожидает кворум из не менее, чем vo ответов, в каждом из п подзаданий пачки. Тогда среднее число повторных передач в схеме с репликациями равно 1/q”. С учетом замедления вычислений, по аналогии с неравенством (1), репликация при отправке пачек подзаданий оправдана для тех значений параметров р, v, vo, п, для которых
-
(2) /(Р, v, v o , п) := q ” - q ” v > 0.
-
2. Репликация при штрафе за ошибку
Множество решений неравенства (2) для п > 2 не пусто. Для иллюстрации соотношения (2) на рис. 1 приведена зависимость / (р, v, v 0 , п) для v = 2, v o = 1, п =10 при 0 6 р 6 0.5.
В качестве развития модели можно предложить нахождение в явном виде асимптотических неравенств для вероятности остановки вычисления р при большом размере пачки п. Также отметим, что стратегия получения канонического результата в случае вычисления пачки может быть иной, а именно, сервер может ожидать окончания вычисления пачек целиком, и лишь затем сравнивать результаты внутри пачек [12] .
Вернемся к условиям модели без использования пачек. Пусть также v o = 1, т. е. сервер ожидает любой ответ в качестве канонического. Предположим, что в случае остановки расчета всеми v репликациями сервер вынужден выполнять дополнительную работу (по пересылке подзадания новому вычислительному узлу, обновлению базы данных и т.п. [7] ) длительностью М тактов. Обозначим р „ := р ^ . Вычислим среднее время выполнения одного подзадания проекта с учетом за-
(S‘?‘d)6-(s4‘d)6
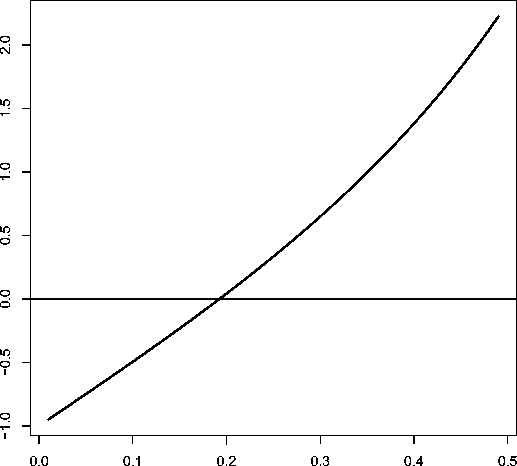
Рис. 2. Значения разности функций д(р, 1 , М) - д(р, v, М ) при v = 2, М = 10 для 0 6 р 6 0 . 5; положительнось функции означает оправданность репликации
медления и штрафа:
∞
д(р, v, М ) := f v(]M + 1)р - (1 - р - ) =
3=0
= v (1 - р „ ) ( м f „,; + f р - ) = \ 3=1 3 =0 /
=v(1 - р - ) (Мр - эр ; f2 р - + 1 - р -, )
= Mv-^ + v. 1 — р -
Тогда репликация целесообразна для тех р^М , для которых верно неравенство д(р, 1, М ) — д(р, v, М ) > 0, т. е.
-
(3) 1 - v + М ( — ) > 0.
-
1 — р 1 — р ^
-
3. Заключение
Для иллюстрации соотношения (3) на рис. 2 приведена зависимость д(р, 1, М ) — д(р, v, М ) для v = 2, М = 5 при 0 6 р 6 0.5.
В данной работе рассмотрена вероятностная модель выполнения одного проекта на одном сервере ВСПК. В неявном виде найдены условия необходимости репликации в случае вычисления пачки подзаданий и в случае штрафа за остановку вычисления подзадания.
Список литературы Задача оптимизации времени выполнения проекта в вычислительной сети из персональных компьютеров
- D. P. Anderson, C. Christensen, B. Allen. Designing a runtime system for volunteer computing//Proceedings of the SC 2006 Conference: ACM/IEEE, 2006. (english).
- Е. Е. Ивашко, Н. Н. Никитина. Организация квантовохимических расчетов с использованием пакета Firefly в гетерогенной Грид на базе BOINC//Труды Международной суперкомпьютерной конференции Научный сервис в сети Интернет: экзафлопсное будущее, 2011, c. 178-181. (russian).
- Н. Н. Никитина, Е. Е. Ивашко. Использование BOINC-грид в вычислительноемких научных исследованиях//Вестник НГУ. Информационные технологии, 2013. Т. 11, № 1, c. 53-57 (russian).
- Е. Е. Ивашко, А. С. Головин. Методы Data Mining для анализа больших массивов данных в гетерогенной грид на базе BOINC//Труды Международной суперкомпьютерной конференции «Научный сервис в сети Интернет: поиск новых решений», 2012, c. 196-199. (russian).
- Е. Е. Ивашко. Выполнение вычислительноемких научных исследований в использованием BOINC-ГРИД//Материалы 2-й научно-практической школы-семинара молодых ученых: Тольятти: ТГУ, 2012, c. 55-62. (russian).
- Е. Е. Ивашко, А. С. Головин. Вычислительная эффективность BOINCGRID//Proceedings of 2nd International Conference on High Performance Computing HPC-UA 2012, 2012, c. 183-187. (russian).
- D. Kondo, M. Taufer, C. L. Brooks, H. Casanova, A. A. Chien. Characterizing and evaluating desktop grids: An empirical study//Proceedings of the 18th International Parallel and Distributed Processing Symposium, 2004. (english).
- D. Kondo, G. Fedak, F. Cappello, H. Casanova, A. A. Chien. Characterizing resource availability in enterprise desktop grids//Future Generation Computer Systems, 2007. Vol. 23, p. 888-903 (english).
- D. P. Anderson. BOINC: A system for public-resource computing and storage//Proceedings of the Fifth IEEE/ACM International Workshop on Grid Computing, 2004, p. 4-10. (english).
- G. D. Ghare, S. T. Leutenegger. Improving Speedup and Responce Times by Replicating Parallel Programs on a SNOW//Job Scheduling Strategies for Parallel Processing. Lecture Notes in Computer Science: Springer Berlin Heidelberg, 2005. Vol. 3277, p. 264-287. (english).
- E. Heien, D. LaPine, D. Kondo, B. Kramer, A. Gainaru, F. Cappello. Modeling and tolerating heterogeneous failures in large parallel systems//International Conference for High Performance Computing, Networking, Storage and Analysis (SC), 2011, p. 1-11. (english).
- M. Silberstein, A. Sharov, D. Geiger, A. Schuster. GridBot: execution of bags of tasks in multiple grids//Proceedings of the Conference on High Performance Computing Networking, Storage and Analysis: ACM, 2009, p. 11. (english).
